Computer Vision: IOU (Intersection Over Union)와 mAP (mean Average Precision)
Artificial Intelligence
IOU (Intersection Over Union)
- IOU는 모델이 얼마나 object detection을 정확히 했는지(=예측 박스가 GT 박스를 얼마나 잘 맞췄는지) 측정하는 지표다.
- HOG + 선형 SVM 객체 검출기와 CNN 기반 검출기(R-CNN, Faster R-CNN, YOLO, SSD 등)에서 공통적으로 사용된다.
- 이진분류처럼 단순히 “맞다/아니다”로 끝나는 문제가 아니라, object detection은 ‘어디에’(Localization)까지 맞춰야 하므로 정확도를 단순 계산하기 어렵다.
- 이 때 “예측 박스가 정답 박스와 얼마나 겹치는가”를 정량화한 것이 IOU다.

- Ground-truth bounding box : 실제 객체 위치(정답 박스)
- Predicted bounding box : 모델이 예측한 객체 위치(예측 박스)
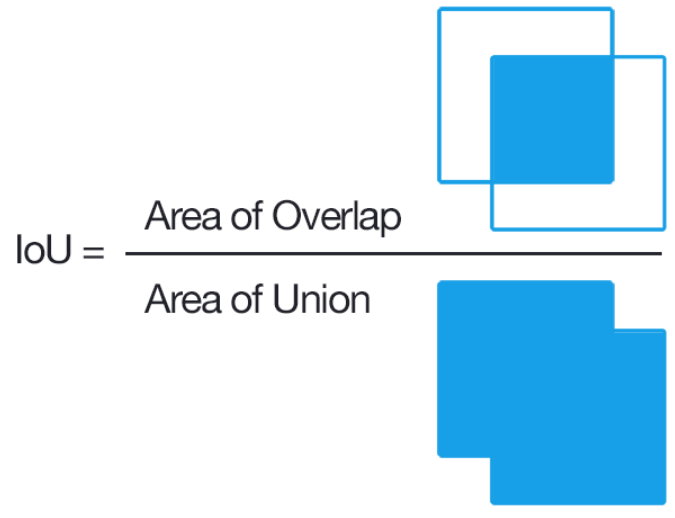
- Intersection(교집합)
- predicted bounding box와 ground-truth bounding box가 겹치는 영역
- Union(합집합)
- 두 박스가 커버하는 전체 영역(겹치는 영역을 중복 없이 합친 영역)
- Intersection Over Union (IOU)
- 교집합을 합집합으로 나눈 비율
수식으로 쓰면 다음과 같다.
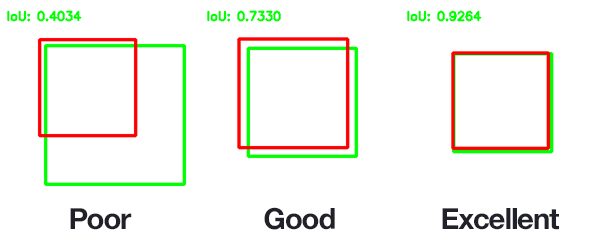
- 보통 IOU값이 0.5 이상이면 ‘good prediction’으로 보는 관행이 많아 threshold를 0.5로 두는 경우가 많다.
- 다만 데이터셋/벤치마크에 따라 더 엄격한 기준(예: 0.75, 혹은 COCO처럼 0.5~0.95 평균)을 쓰기도 한다.
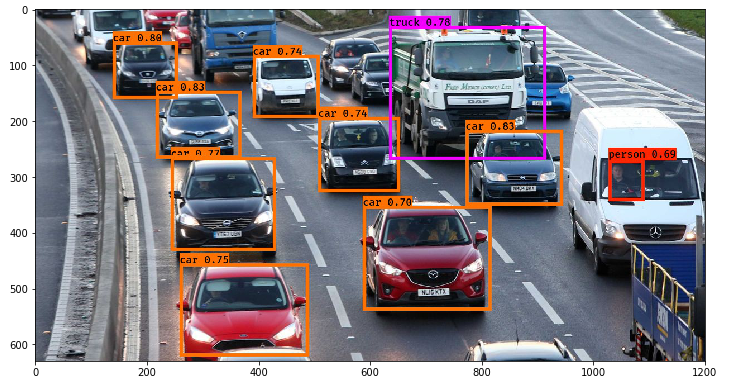
IOU로 TP/FP를 판단하는 방법(Detection 평가 규칙)
- object detection에서 TP/FP는 “클래스 일치 + IOU 기준”으로 판정한다.
- 일반적으로 한 prediction(예측 박스)은 최대 1개의 GT 박스에만 매칭되고, 반대로 한 GT도 최대 1개의 prediction만 TP로 인정한다(중복 매칭 방지).
| 상황 | 판정 |
|---|---|
| 클래스 맞고 + IOU ≥ threshold | TP |
| 클래스 맞지만 IOU < threshold | FP |
| 클래스 틀림 | FP |
| 실제 객체 있는데 못 찾음(예측 자체가 없음) | FN |
- TN(True Negative)은 object detection에서는 거의 의미 있게 쓰지 않는다.
- 이유: “배경”은 이미지 내 무한히 많아 TN을 정의하면 수치가 왜곡되기 쉽기 때문.
- IOU는 object detection 성능 평가 지표인 AP/mAP 계산의 TP/FP 판정 기준으로 사용된다.
mAP (mean Average Precision)
- Recall: “진짜 중에 내가 잡은 건?”
- Precision: “내가 잡았다고 한 것 중 진짜는?”
- AP: “Recall 전 구간에서 Precision의 질(면적/평균)”
- mAP: “클래스별 AP 평균”
- object detection 모델의 대표 성능 평가지표
- ex) R-CNN 모델 mAP가 35.1% → 53.7%로 향상 / SSD 모델 mAP = 0.34
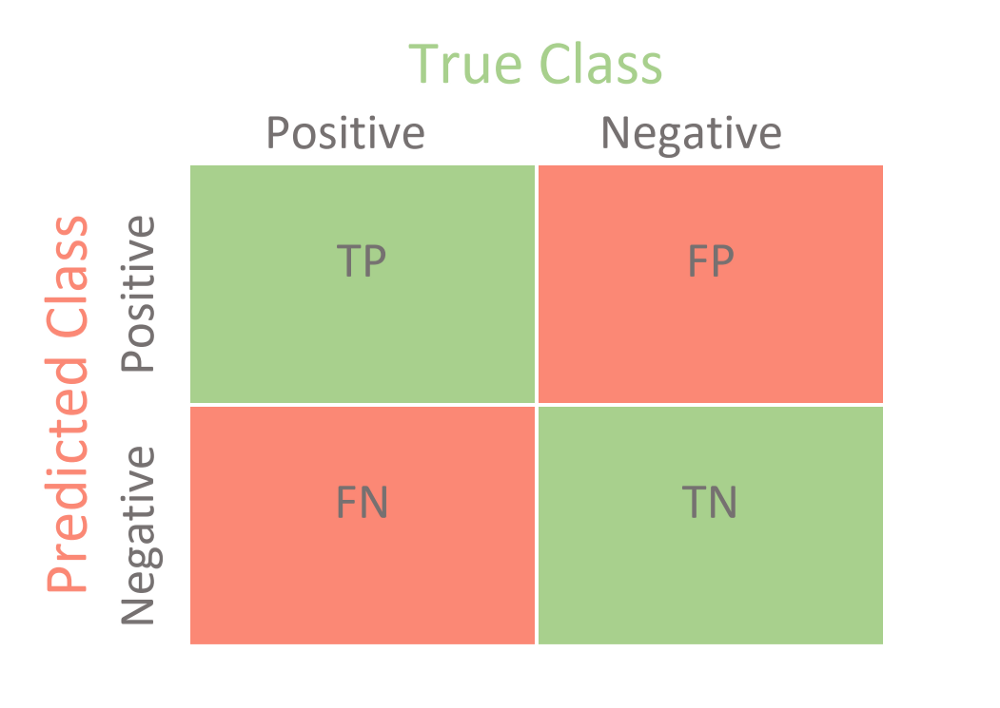
- Precision/Recall을 이해하기 위해 Confusion Matrix를 본다.
- classification에서는 TP/FP/FN/TN이 비교적 명확하지만,
- object detection에서는 IOU와 클래스 일치 여부로 TP/FP를 판정해야 한다.
(Object Detection 문맥에서) TP / FP / FN 정의
TP: 예측 박스가 클래스도 맞고, GT와의 IOU가 threshold 이상이며, 그 GT가 아직 다른 예측으로 TP 처리되지 않은 경우FP: 다음 중 하나- (1) 예측했지만 GT와 IOU가 threshold 미만
- (2) 클래스가 틀림
- (3) 이미 다른 예측이 해당 GT를 TP로 “선점”했는데 또 중복 예측함(중복 검출)
FN: GT가 존재하지만 모델이 해당 객체를 TP로 맞추지 못한 경우(누락)
앞글자는 예측이 맞았는지 아닌지, 뒷글자는 실제 정답값을 나타낸다고 생각하면 쉽다.
Recall (재현율)
“실제 객체 중에, 내가 얼마나 많이 잡았는가”
- “놓치지 않는 능력”
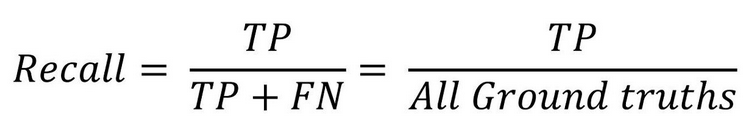
- 실제 정답(True) 중 True라고 예측한 비율
Precision (정밀도)

“잡았다고 한 것 중에, 진짜 맞은 비율”
- “쓸데없는 탐지”를 얼마나 줄였는가
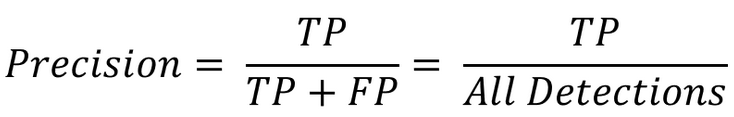
- True라고 예측한 것 중 실제 True인 비율
Confidence Score와 PR 곡선의 관계

-
object detection 모델은 보통 예측 박스마다 confidence score를 함께 출력한다.
-
confidence score는 모델/계열마다 정의가 조금 다르지만, “이 예측이 믿을 만한가”를 나타내는 점수다.
-
YOLOv1의 경우 대표적으로
-
(일반적 관점) objectness(객체 존재 가능성) + 위치/분류 신뢰가 혼합된 점수로 이해하면 된다.
-
-
PR 곡선은 confidence threshold를 움직이며 만들어진다.
-
threshold를 낮추면 더 많은 박스를 남김 → Recall은 올라가기 쉽지만 FP도 늘어 Precision이 떨어질 수 있음
-
threshold를 높이면 박스가 줄어듦 → Precision은 올라가기 쉽지만 FN이 늘어 Recall이 떨어질 수 있음
-
Precision–Recall Curve (PR 곡선)
-
Recall과 Precision은 보통 한쪽이 오르면 다른 쪽이 떨어지는 trade-off가 있어 둘을 함께 봐야 한다.
-
그래서 confidence threshold를 바꿔가며 (Precision, Recall) 점들을 찍고 곡선을 만든다.
왜 Precision과 Recall을 하나로 합쳐야 하나
- 모델 A: 박스를 1개만 쳐서 1개 맞힘 → Precision = 1.0, Recall 매우 낮음
- 모델 B: 박스를 100개 쳐서 50개 맞힘 → Recall 높지만 Precision 낮음
- 단일 숫자로는 비교가 어려움 → PR Curve와 AP를 사용
-
PR Curve 생성 절차
-
모델의 예측 박스들을 confidence score 내림차순으로 정렬
-
위에서부터 하나씩 누적하며 TP/FP를 판정
-
각 시점의 Precision, Recall을 계산
-
x축 Recall, y축 Precision으로 연결
-
-
중요한 점
-
threshold 하나 = 점 하나
-
threshold 여러 개 = 곡선
-
AP(Average Precision)
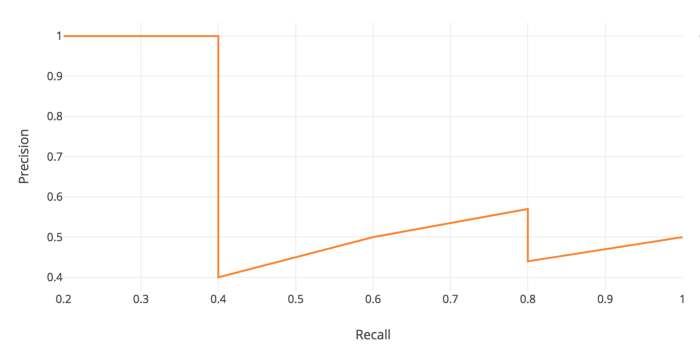
Precision–Recall 곡선 아래 면적(Area Under PR Curve)
-
직관: Recall 0~1 구간에서 Precision이 얼마나 높게 유지되는가
-
계산 방식은 벤치마크에 따라 다르지만, 보통 다음 아이디어를 사용한다.
-
PR 곡선을 “들쭉날쭉”한 그대로 쓰기보단,
-
Recall이 증가할수록 Precision이 감소하지 않게끔 단조 형태로 보정(interpolation) 후 면적을 계산한다.
-
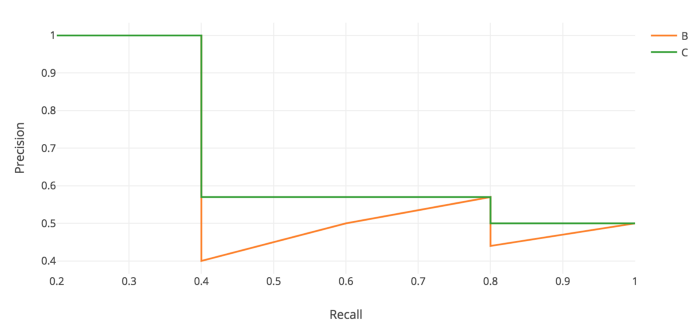
-
과거 VOC 2007은 11-point 방식(Recall을 0.0~1.0까지 0.1 간격으로 샘플링)도 사용했으나,
- 최근 표준(VOC 2010+, COCO 등)은 더 촘촘한 포인트/연속 적분에 가까운 방식으로 계산한다.
mAP (mean Average Precision)
-
mAP는 클래스별 AP의 평균
-
클래스가 하나면 AP = 성능
-
클래스가 여러 개면
-
클래스마다 AP 계산
-
평균
-
예:
-
person AP = 0.60
-
car AP = 0.50
-
dog AP = 0.40
COCO mAP의 대표 표기
- COCO에서는 보통 다음을 보고한다.
-
의미:
-
IOU threshold를 0.50, 0.55, …, 0.95 (총 10개)로 바꿔가며 AP를 구하고
-
그 평균을 다시 평균낸 값
-
-
그래서 VOC mAP@0.5보다 더 엄격하며 수치가 더 낮게 나오는 경향이 있다.
