Artificial Intelligence
1.핸즈온 머신러닝 (Hands-On Machine Learning with Scikit-Learn, Keras, and Tensorflow)

1.1 머신러닝이란?1.2 왜 머신러닝을 사용하나요?1.3 애플리케이션 사례1.4 머신러닝 시스템의 종류1.4.1 훈련 지도 방식지도 학습비지도 학습준비도 학습자기 지도 학습강화 학습1.4.2 배치 학습과 온라인 학습배치 학습온라인 학습1.4.3 사례 기반 학습과 모델
2.[Hands-On Machine Learning] 1장 한눈에 보는 머신러닝 🕒
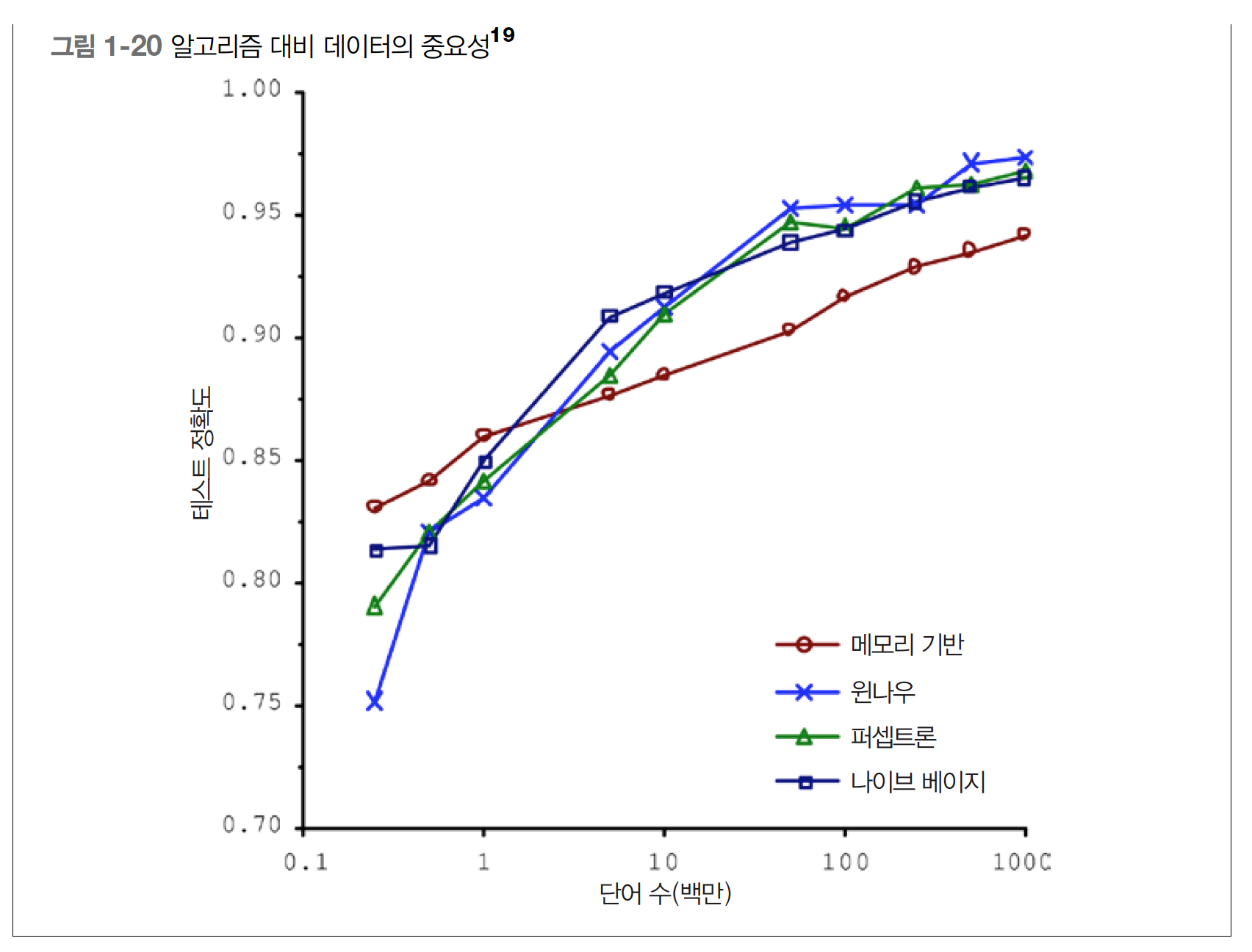
출처 1.1 머신러닝이란? 머신러닝은 데이터에서 학습하도록 컴퓨터를 프로그래밍하는 과학(또는 예술)입니다. 일반적인 정의 머신러닝은 명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구 분야다. - Arthur Samuel, 1959 공학적
3.[Hands-On Machine Learning] 2장 한눈에 보는 머신러닝 🕕
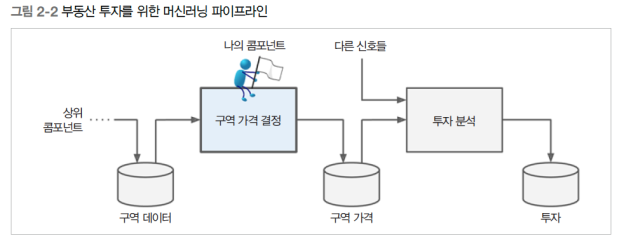
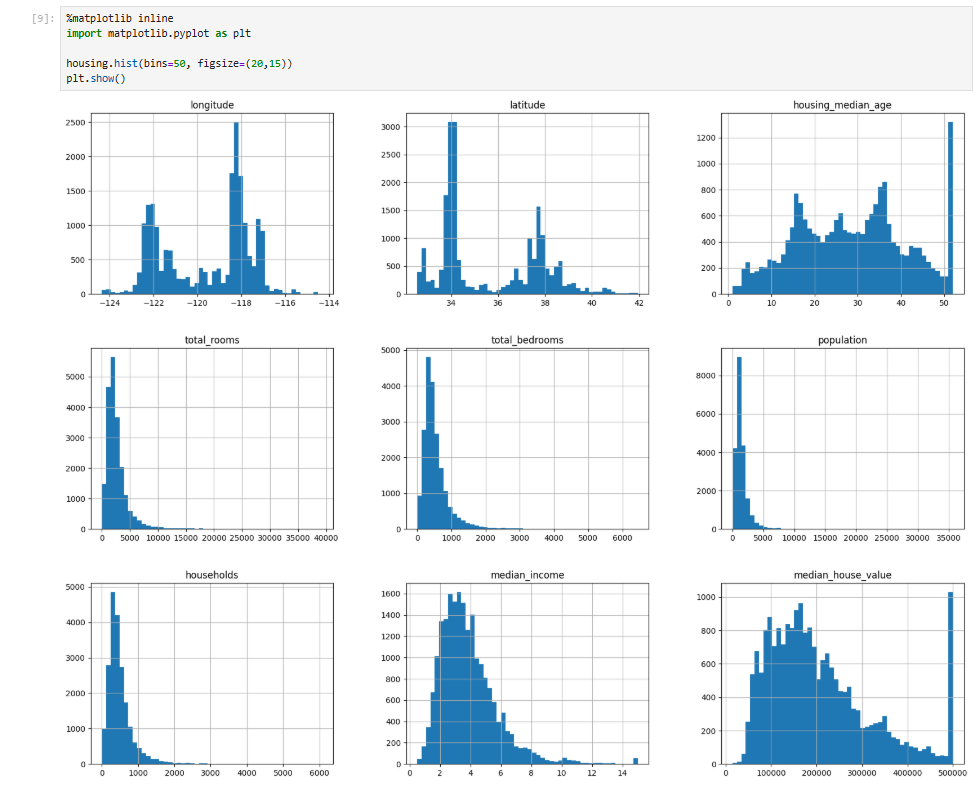
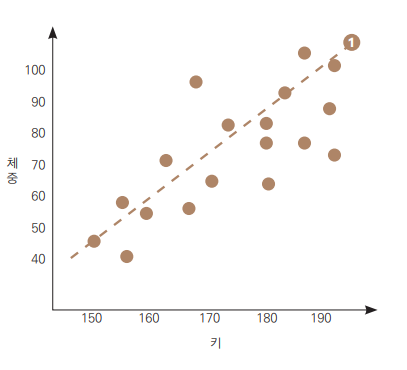
목표: 캘리포니아 인구조사 데이터를 바탕으로 캘리포니아의 주택 가격 예측 모델을 개발.데이터 특징캘리포니아의 블록 그룹(block group) 단위별로 인구, 중간 소득, 중간 주택 가격 등의 데이터를 포함.블록 그룹: 미국 인구조사국에서 사용하는 최소한의 지리적 단위
4.사이킷런 (Scikit-Learn), 텐서플로 (TensorFlow), 케라스 (Keras)
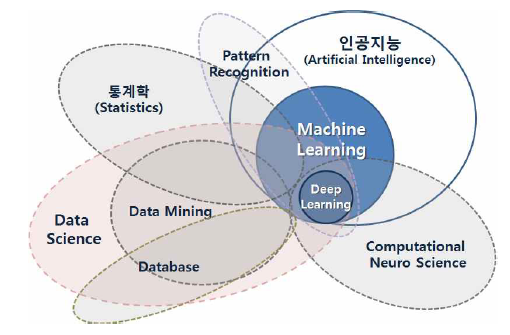
사이킷런은 파이썬 기반의 머신러닝 라이브러리로, 단순한 사용법과 폭넓은 알고리즘 지원을 제공.머신러닝 전 과정(데이터 전처리, 학습, 평가, 하이퍼파라미터 튜닝)을 지원.딥러닝(신경망)은 지원하지 않지만 대부분의 전통적인 머신러닝 모델을 제공.다양한 알고리즘 지원선형
5.머신러닝 개발환경 구축하기
참고
6.Python: 가상환경 관리, virtualenv와 venv
출처
7.[Hands-On Machine Learning] 2장 한눈에 보는 머신러닝 🕘

https://tensorflow.blog/%ed%95%b8%ec%a6%88%ec%98%a8-%eb%a8%b8%ec%8b%a0%eb%9f%ac%eb%8b%9d-1%ec%9e%a5-2%ec%9e%a5/
8.Rerank
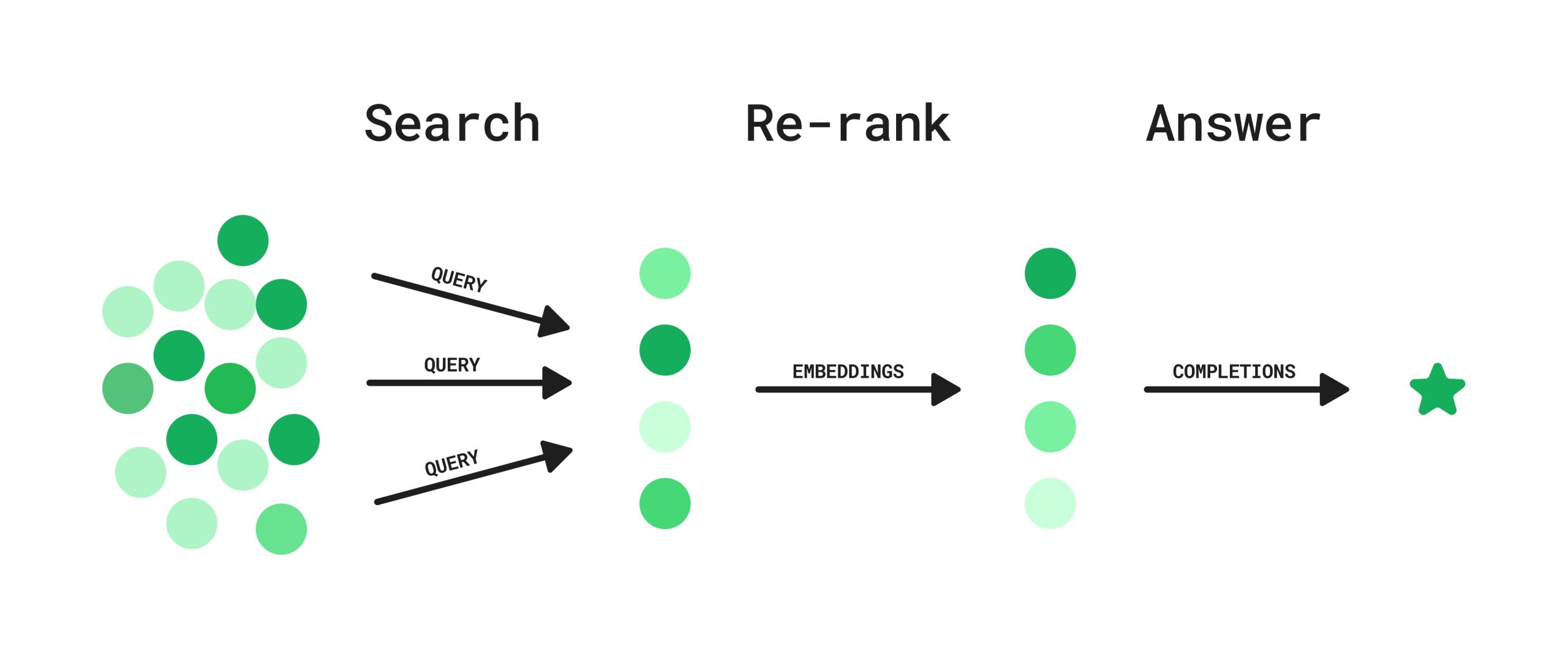
출처 Rerank 란? Rerank는 검색 결과의 순위를 재조정하는 과정을 말합니다. RAG 시스템에서 Rerank는 초기 검색 결과에서 가져온 문서들의 순위를 다시 매기는 역할을 합니다. 이를 통해 사용자의 질문과 가장 관련성 높은 문서들을 상위에 배치
9.[Must Have] 데싸노트의 실전에서 통하는 머신러닝
http://wikidocs.net/book/13311
10.특정 값을 예측하기 위한 수단의 머신러닝: 수치 예측(Numerical Prediction), 범주 예측(Categorical Prediction)
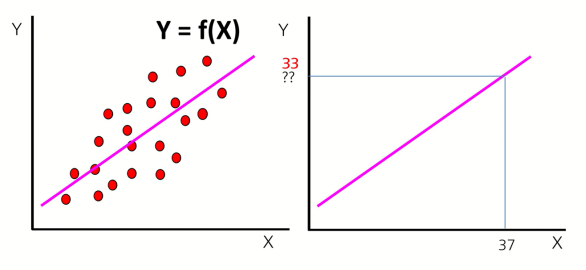
참고Machine Learning 은 주어진 X와 Y데이터를 이용하여 모델 F(x)를 추론하는 과정이라고 배웠다.그렇게 모델 F(x)를 추론하고 나면 새로운 데이터 X가 주어졌을 때, 모델에 입력 X를 넣어서 출력 Y값을 예측 할 수 있다.결국 Machine Learn
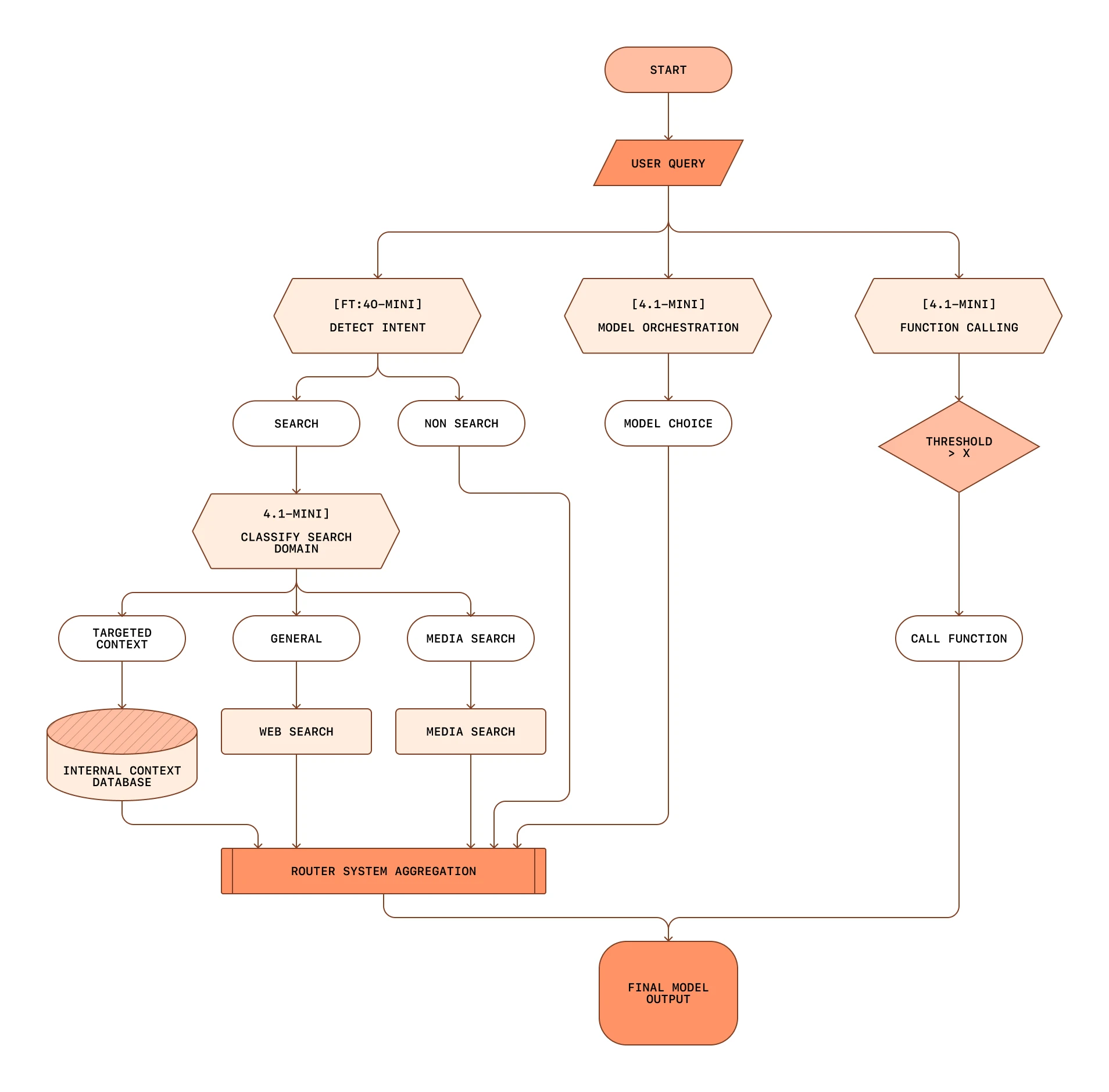
11.머신러닝 프로세스

출처
12.Frozen Lake 코드와 설명
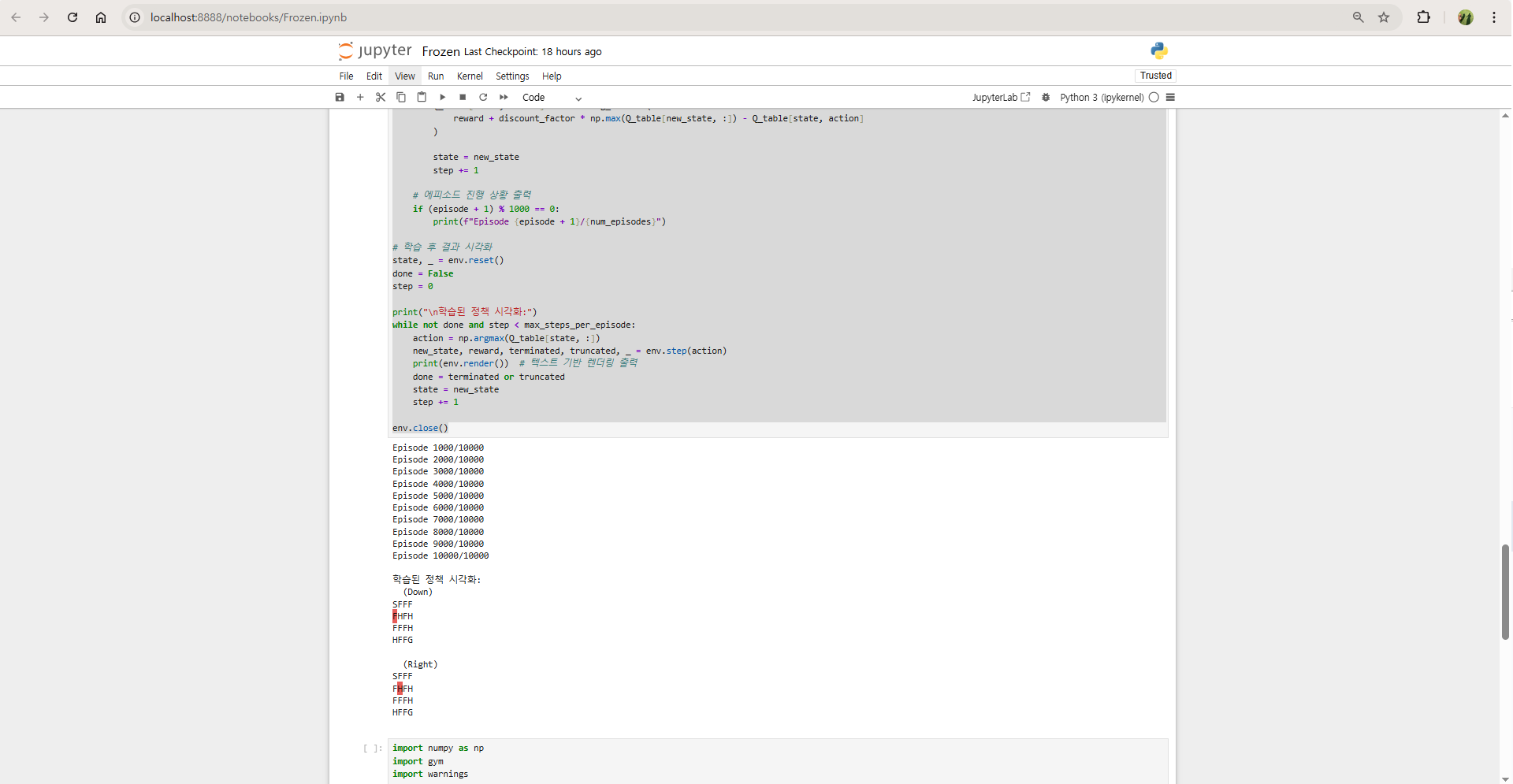
FrozenLake는 OpenAI Gym에서 제공하는 강화학습 환경 중 하나로, 간단한 그리드 기반 게임입니다. 에이전트가 얼어붙은 호수에서 미끄럽지 않은 곳을 지나 목표 지점(Goal)에 도달하는 것을 목표로 합니다. 에이전트는 장애물(구멍, Hole)을 피해야 하며
13.피처 엔지니어링(Feature Engineering)
피처 엔지니어링(Feature Engineering)은 데이터를 분석하고 모델링하기 전에 원시 데이터를 전처리하고 변환하여 모델이 데이터를 효과적으로 학습할 수 있도록 만드는 과정입니다. 이는 머신러닝 및 데이터 분석 단계에서 매우 중요한 역할을 하며, 좋은 피처 엔지
14.선형 회귀(Linear Regression) : 보험료 예측하기
출처 선형 회귀 : 보험료 예측하기 라이브러리 및 데이터 불러오기 파이썬에서 데이터를 다룰 때 기본으로 사용되는 라이브러리인 판다스(pandas)를 불러오겠습니다. 라이브러리를 불러오는 걸 프로그래밍 용어로 ‘임포트(한다)’라고 합니다. 판다스를 불러왔으니 데이
15.선형 회귀(Linear Regression): 릿지 회귀 (Ridge Regression), 라쏘 회귀 (Lasso Regression), 엘라스틱 넷 (Elastic Net)
1. 릿지 회귀 (Ridge Regression) 릿지 회귀는 선형 회귀(Linear Regression)에 L2 정규화(Tikhonov 정규화)를 적용하여 오버피팅(Overfitting)을 방지하는 방법입니다. 기본 선형 회귀는 잔차(residual)를 최소화
16.로지스틱 회귀 : 타이타닉 생존자 예측하기
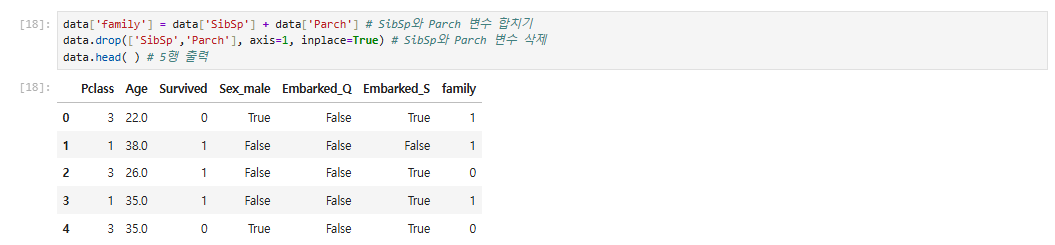
출처 로지스틱 회귀 : 타이타닉 생존자 예측하기 영화 〈타이타닉〉으로 유명한 타이타닉호는 북대서양 횡단 여객선입니다. 모두가 아는 것처럼 1912년 4월 10일 영국의 사우샘프턴에서 미국의 뉴욕으로 향하던 첫 항해 중에 빙산과 충돌하여 침몰했습니다. 안타깝게도
17.A2A(Agent-to-Agent) vs MCP(Model Context Protocol)
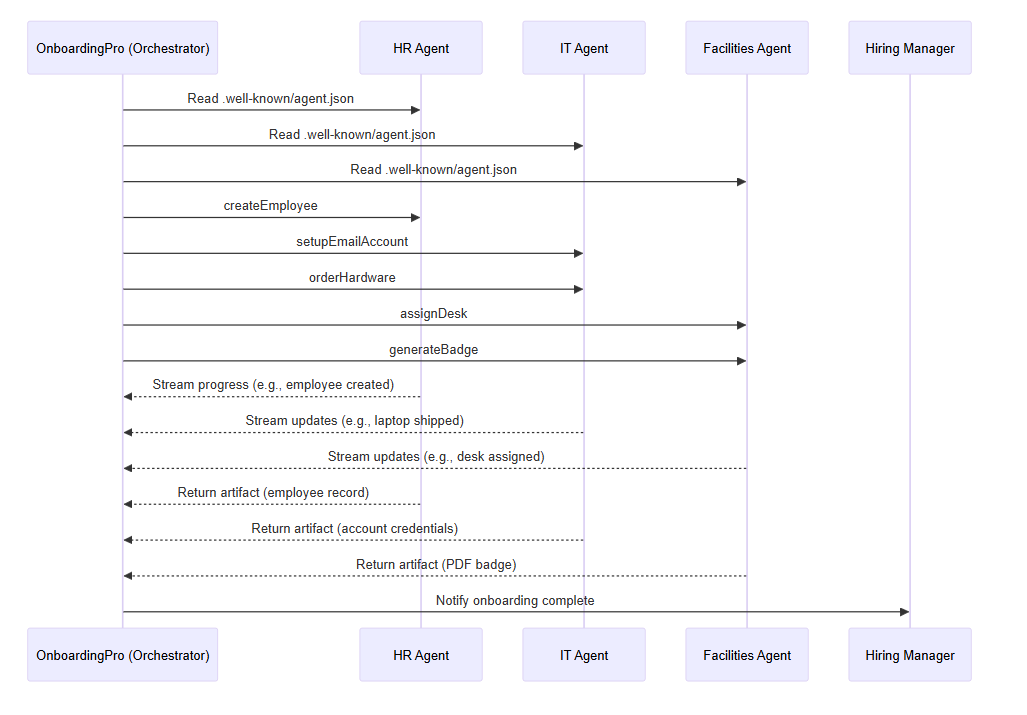
출처
18.K-최근접 이웃(KNN) : 와인 등급 예측하기
출처K-최근접 이웃(KNN) : 와인 등급 예측하기
19.모델 자가포식 장애(MAD: Model Autophagy Disorder)
출처이 글은 2024년 ICLR(국제 학습 표현 학회)에서 발표될 라이스대학교 AI 연구팀의 논문을 바탕으로, AI가 자체 생성 데이터를 반복적으로 사용해 새로운 AI를 학습시키는 방식의 위험성을 경고하는 내용입니다. 핵심 요점을 정리하면 다음과 같습니다.AI가 생성한
20.반복적 프롬프트의 부작용: 정보 다양성, 품질 저하
RAG(Retrieval-Augmented Generation)와 같은 “검색 기반 + 생성형 AI” 프레임워크에서, 동일 프롬프트를 반복 사용하거나 복사-붙여넣기 방식으로 반복 입력했을 때의 문제점을 MAD(MODEL AUTOPHAGY DISORDER) 현상, 그리고
21.Ollama 🦙
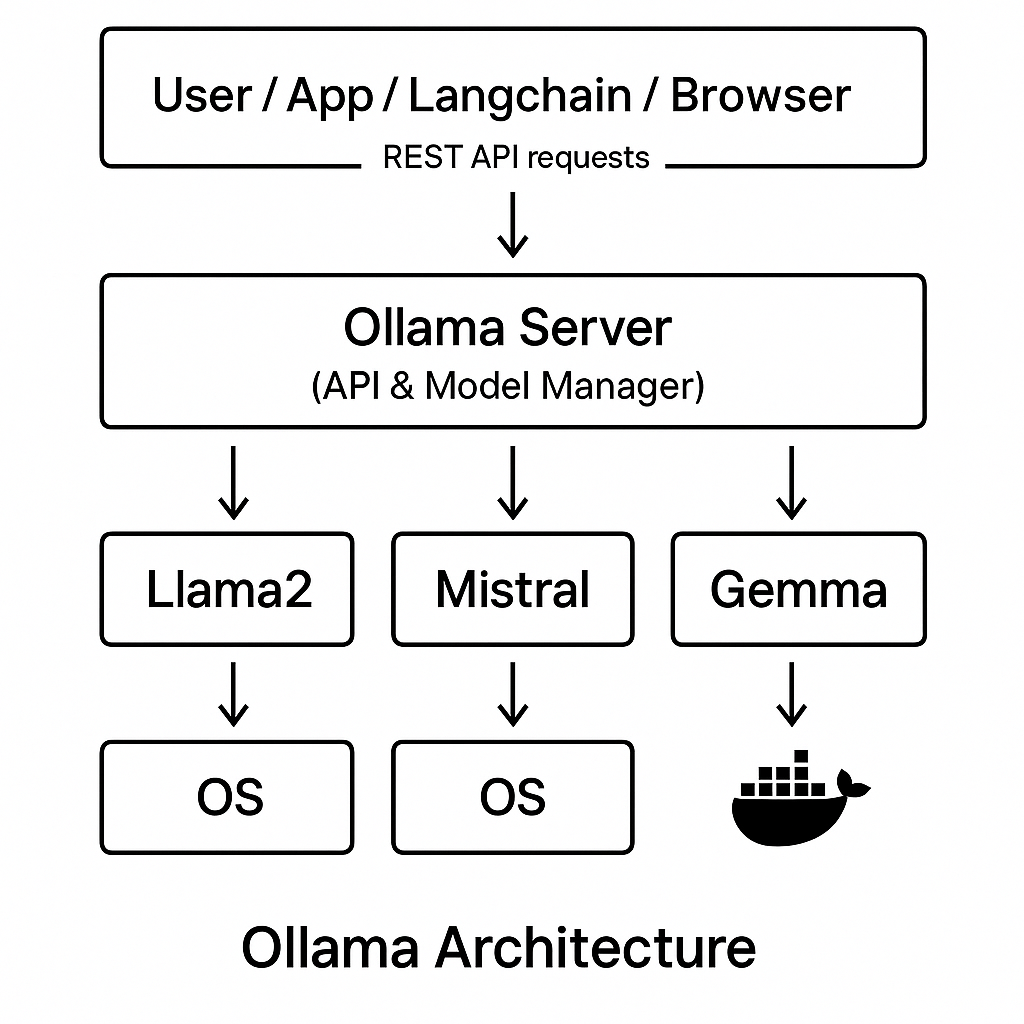
Ollama 란?
22.LangChain
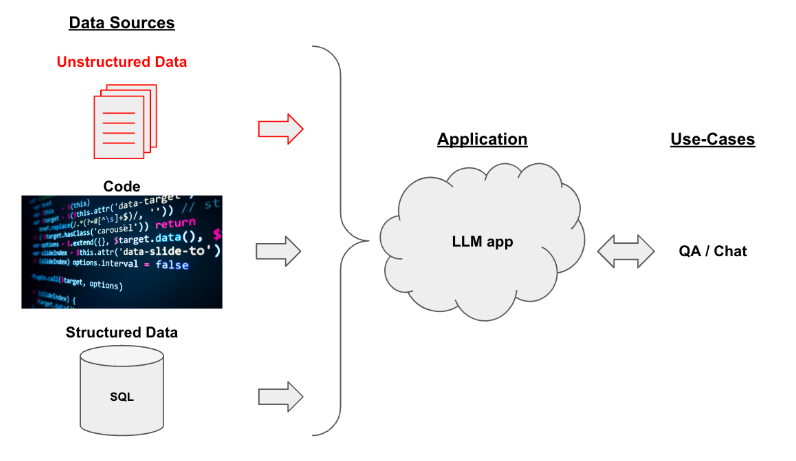
LangChain은 최근 AI/데이터/서비스 개발에서 매우 인기 있는 오픈소스 프레임워크로, 대형 언어 모델(LLM), 다양한 툴, API, 문서 데이터, 데이터베이스 등 여러 AI 구성요소를 조합하여 실제 서비스나 응용 프로그램을 빠르게 개발할 수 있도록 도와주는 라
23.AI 실습 첫걸음 모음.zip
https://yozm.wishket.com/magazine/collection/69749/
24.LangChain: 작업그래프(Workflow/Task Graph)
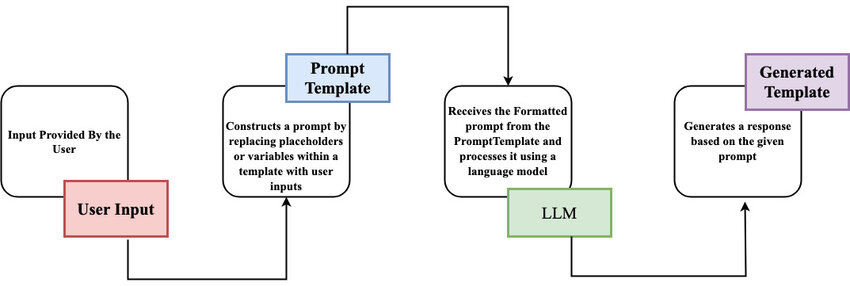
참고
25.LangGraph, LangSmith
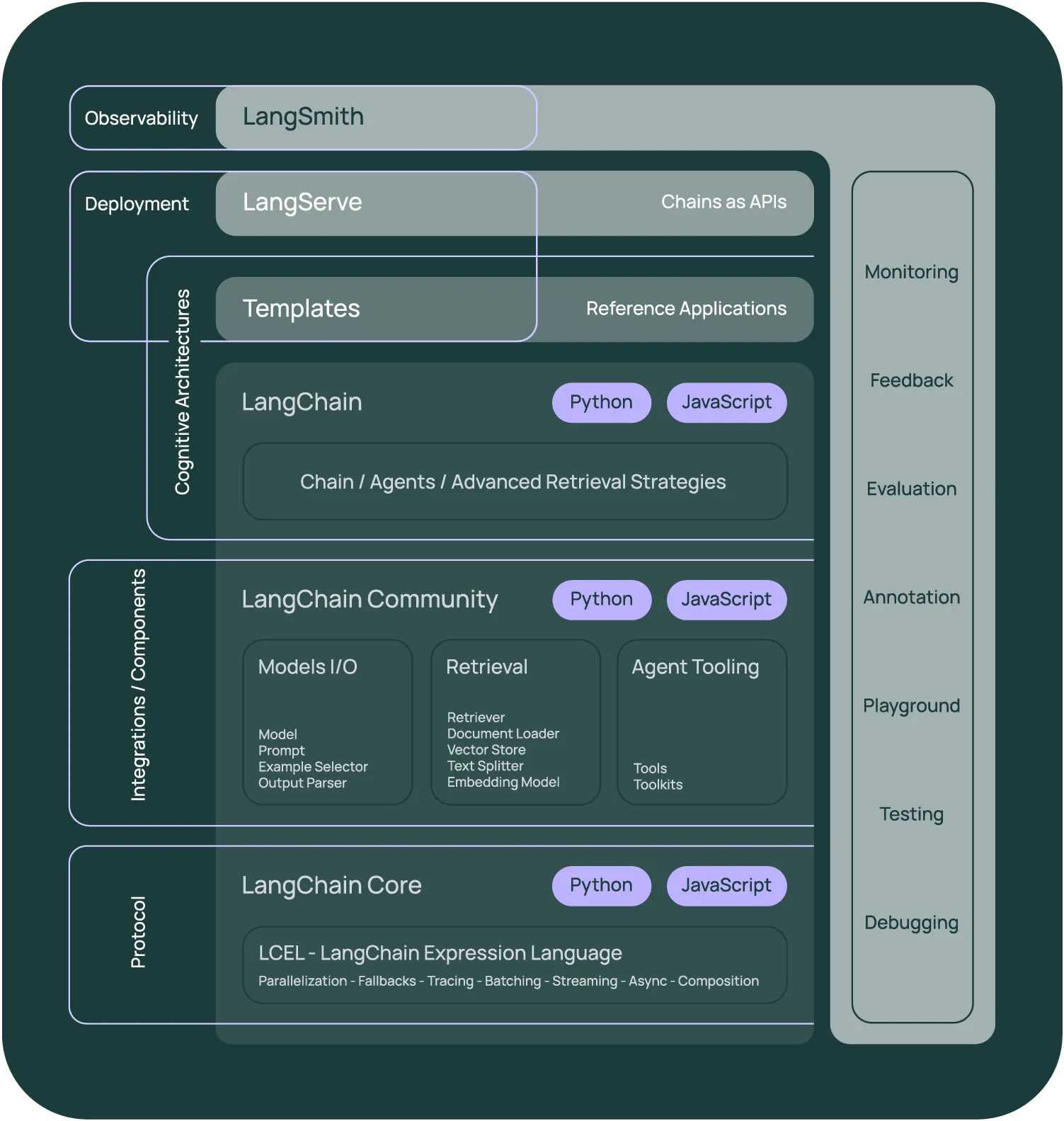
LangGraph는 LangChain 팀이 만든 "워크플로우(작업그래프)를 쉽게 만들고 제어할 수 있게 해주는 오픈소스 프레임워크"입니다.그래프(노드와 엣지) 형태로 LLM 기반 작업 플로우를 설계 → 기존 LangChain 체인(Chain) 기반의 '순서적 실행'을
26.LangChain: 간단한 번역 LLM 애플리케이션 구축
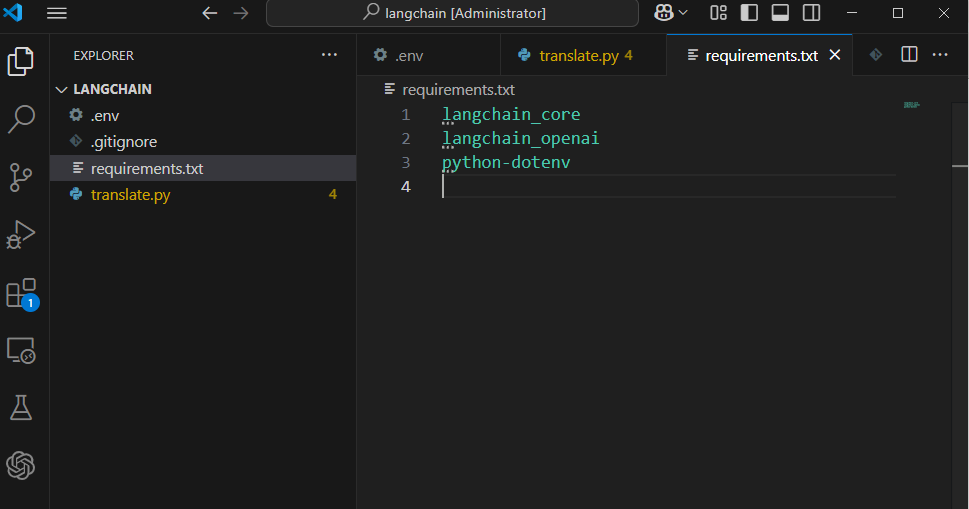
출처
27.OpenAI: API Connection Error
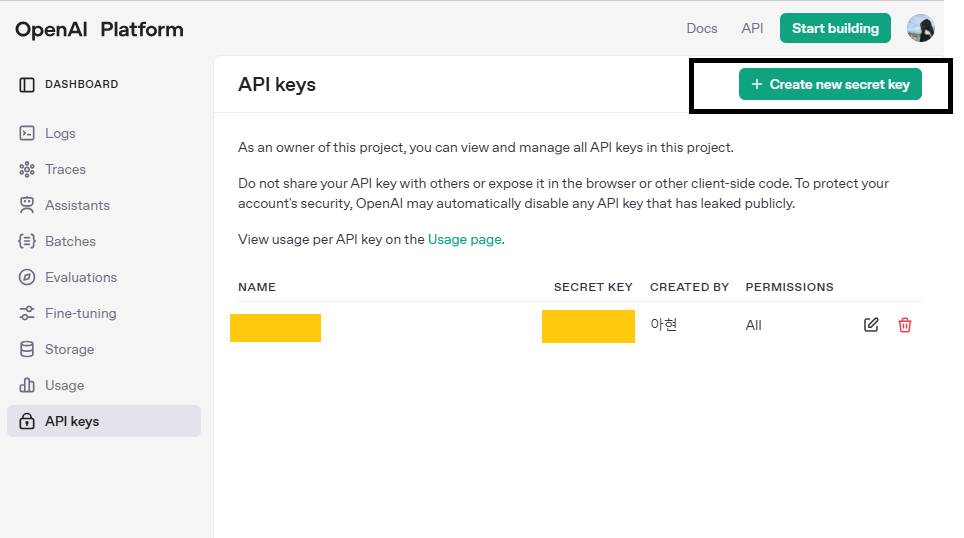
참고
28.AI(Narrow AI)와 AGI(Artificial General Intelligence)의 목적
https://www.samsungsds.com/kr/insights/artificial_general_intelligence_20240417.html
29.프롬프트 엔지니어링(Prompt Engineering)
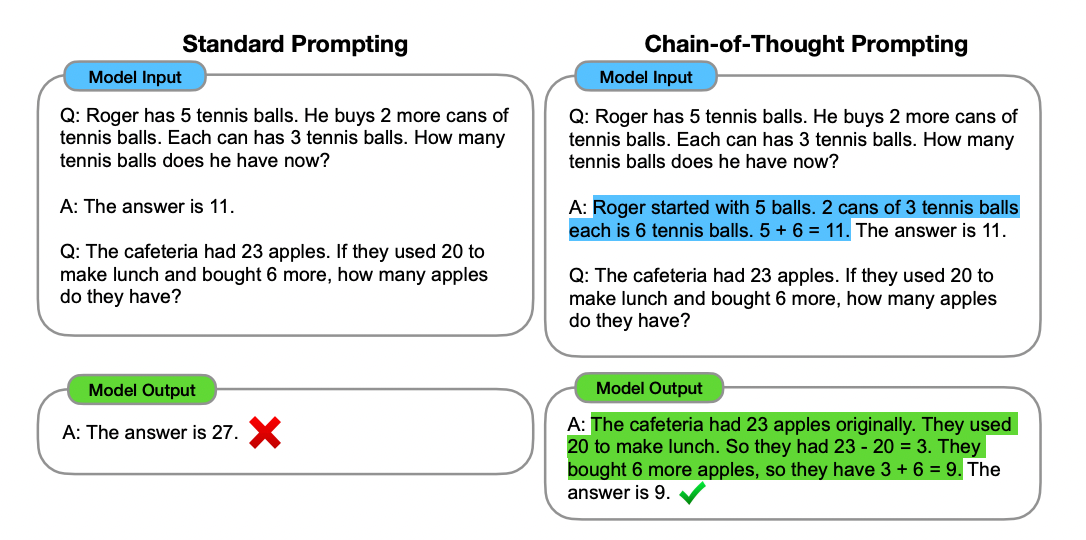
출처
30.OpenAI: temperature
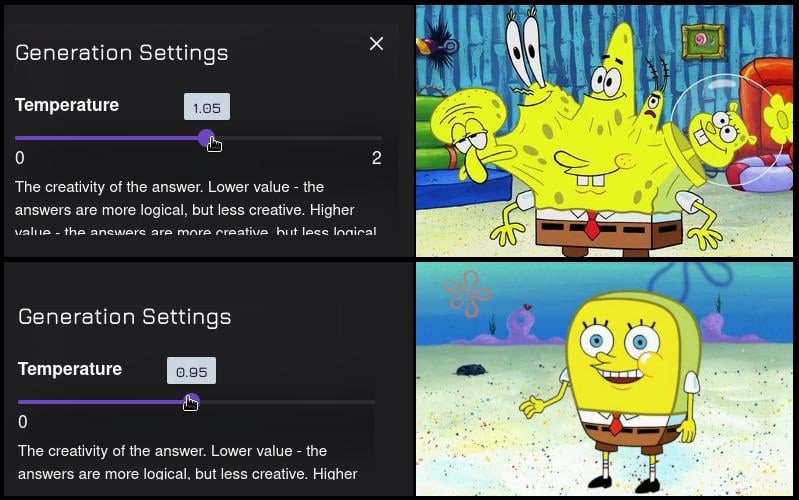
temperature 란? temperature는 텍스트 생성 모델의 출력 다양성을 조절하는 하이퍼파라미터야. 쉽게 말해, "모험을 얼마나 할지" 결정하는 스위치라고 생각하면 돼. 낮은 temperature (예: 0.2) → 결정적이고 보수적인 출력: 가장
31.주요 클라우드 AI 플랫폼의 기술적 비교 및 경쟁력 분석
IBM watsonx의 기술 우위와 경쟁사(AWS Bedrock, Microsoft Azure AI, Google Vertex AI 등)와의 비교 분석 자료를 아래에서 요약 정리해 드리겠습니다.IBM watsonx: 오픈 소스(Delta Lake, Iceberg 등)와
32.Copilot: What it's for?
Great question! Could you clarify what you're referring to with "this"? Are you asking about:This chat interface (what it's for)?A specific feature or
33.Copilot: How to Make a Chart
Actually,They can't make chart properly. right now.
34.신경망(Neural Networks): PyTorch를 활용한 전이학습 기반 이미지 불량/정상 분류 모델 예제
Tip:data/train/정상/이미지A.jpg, data/train/불량/이미지B.jpg 폴더 구조로 준비되어 있어야 합니다.GPU 사용 여부는 torch.cuda.is_available()로 자동 적용 (GPU 있으면 훨씬 빠름)폴더 구조 및 이미지 준비상태 확인실
35.클로드 코드(Claude Code)
https://yozm.wishket.com/magazine/detail/3162/?utm_source=stibee&utm_medium=email&utm_campaign=newsletter_yozm&utm_content=contents
36.온디바이스 AI(On-device AI)
온디바이스 AI란 “클라우드(서버)로 보내지 않고, 내 스마트폰, AR Glass, IoT 등 각 사용자의 기기 내에서인공지능 알고리즘이 입력신호(음성, 텍스트, 영상, 센서 등)를 즉시/즉각/프라이버시 침해 없이처리·판단하는 기술, 그리고 이를 뒷받침하는 각종 경량
37.OpenAI: Status 페이지 안내

OpenAI Status 페이지는 OpenAI에서 제공하는 각종 서비스(예: ChatGPT, API 등)의 현재 서비스 상태(가용성 및 장애 상황 등)를 실시간으로 확인할 수 있는 공식 시스템 운영 현황 대시보드입니다.서비스 가용성 상태표시각 OpenAI 제품(예: P
38.Backpropagation(역전파)
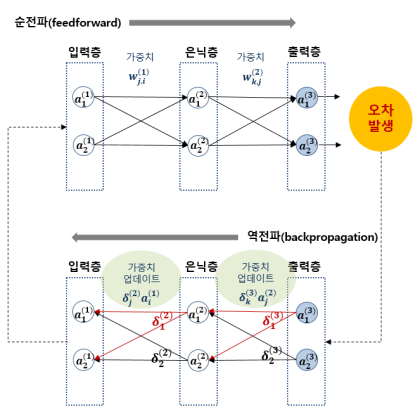
Backpropagation은 신경망의 학습과정에서 “오차를 뒤로 전달해가며 가중치를 수정하는 기법”입니다.딥러닝이 엄청난 규칙 복잡성을 쉽게 학습할 수 있는 비결이기도 해요!Backpropagation은 인공신경망(딥러닝)의 학습 과정에서 오차(Error)를 네트워크
39.Deep Learning: 역전파(BackPropagation) 이해하기
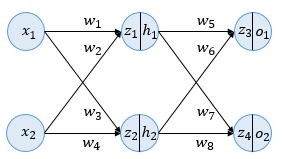
출처인공 신경망이 순전파 과정을 진행하여 예측값과 실제값의 오차를 계산하였을 때 어떻게 역전파 과정에서 경사 하강법을 사용하여 가중치를 업데이트하는지 직접 계산을 통해 이해해봅시다.인라인: $h = \\sigma(z) = \\frac{1}{1 + e^{-z}}$입력에서
40.LangChain: LangChain의 핵심 코드/로직 계층(Protocol, LangChain Core)
보통 LLM(또는 외부 API)에 여러 번 ‘질문’을 보내야 할 때, 이 요청들을 여러 개의 작업 스레드/프로세스가 동시에 실행해서 대기시간을 최소화합니다.대량의 데이터 처리(예: 문서 수십만 건 임베딩화, FAQ 1000개 답변 생성)여러 사용자의 요청을 동시에 응답
41.사고의 환상의 환상(The Illusion of the Illusion of Thinking) 논문

출처주장 LLM(대형 언어 모델)과 LRM(대규모 추론 모델, 더 체계적인 단계적 사고에 특화된 버전) 모두 아주 복잡한 퍼즐(예: 하노이탑 고난이도 문제)에서는 정확도가 0%에 가까울 만큼 무력하다. 방법 하노이탑 등 네 가지 추론 퍼즐에서 다양한 난이도로 모델
42.ChatGPT: 우선적으로 제시하는 기준
최근(2022~2025년)의 스프링/스프링 배치/부트 공식 가이드, 그리고 업계에서 권장하는 방식을 최우선으로 고려합니다.즉, 생성자 주입(@RequiredArgsConstructor + final)이 표준이면 기본적으로 그걸 우선 제공합니다.질문자가 주신 기존 코드/
43.그림으로 배우는 인공 신경망의 원리: 경사 하강법, 피드 포워드 신경망, 순환 신경망
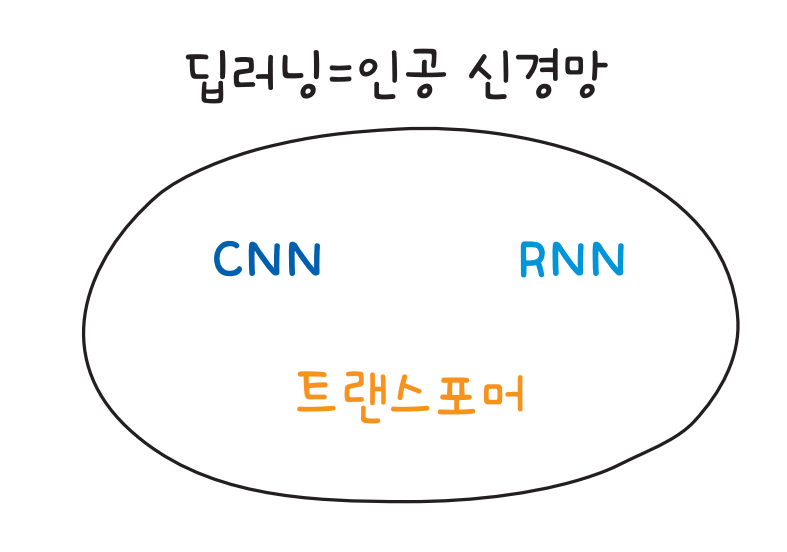
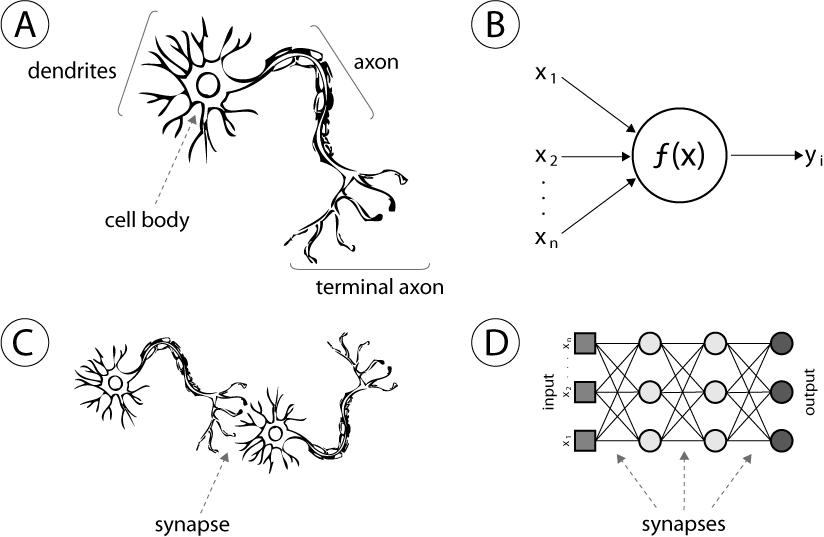
출처
44.순환 신경망(Recurrent Neural Network, RNN)
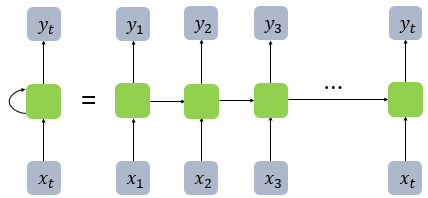
출처용어는 비슷하지만 순환 신경망과 재귀 신경망(Recursive Neural Network)은 전혀 다른 개념입니다. RNN(Recurrent Neural Network)은 입력과 출력을 시퀀스 단위로 처리하는 시퀀스(Sequence) 모델입니다. 번역기를 생각해보
45.The Complexity Cliff
https://blogs.cisco.com/innovation/network-operations-for-the-ai-ageBefore your first meeting of the day, the alerts have already started. A bran
46.LangChain: Vector Database와 Memory를 활용 예제
FAISSChromaPineconeWeaviate(기타: Qdrant, Milvus 등)아래는 Chroma + OpenAI Embeddings + LangChain Retriever 구현 예시입니다.LangChain의 Memory는 대화 기록이나 상태를 저장해 LLM이
47.LangChain: 번역 LLM 애플리케이션 업그레이드 (Vector DB + Memory)
사용자의 최근 번역 기록(질문/답변 쌍)을 저장해, 다음 번역에 참고하게 함 예: 사용자가 "그걸 영어로 다시 써줘" 등 맥락을 포함하는 요청 시 자연스럽게 처리사전에 등록한 “전문 용어/고유명사” 자료를 벡터DB(Chroma)에 저장 번역 전에 입력 문장과 유사한
48.LangChain: memory를 직접 장착할 수 없음
최신 LangChain 파이프라인(LCEL) 구조인데, 여기에선 chain.memory = memory 코드가 오류를 만듭니다. (memory를 직접 장착할 수 없음)즉, 아래와 같이 메모리는 직접 연결하지 말고(이 줄을 제거!),필요하다면 대화 내역을 직접 con
49.LangChain: “당장 망가지진 않지만, 코드에서 외부 라이브러리 import 방법을 곧 바꾸라는 의미”
본 메시지는 "코드 자체 에러"가 아니라, LangChain 최신버전(특히 0.2.x 부터)에서의 경고(DeprecationWarning)입니다.즉, “당장 망가지진 않지만, 코드에서 외부 라이브러리 import 방법을 곧 바꾸라는 의미” langchain 라이브러리
50.LangChain: 확장 적용 예시 (LangChain + Memory + VectorDB) 개선
지금 코드에서는 “영어” 같은 단어만 입력하면, 그대로 번역(즉 ‘English’)이라는 결과를 주는데 의도하신 건 아마 만약 사용자가 “영어,” “일본어” 등 언어만 입력하면 최근 번역했던 문장·답(혹은 질문)을 해당 언어로 다시 번역또, glossary.txt의 전
51.임베딩 모델(embedding model)
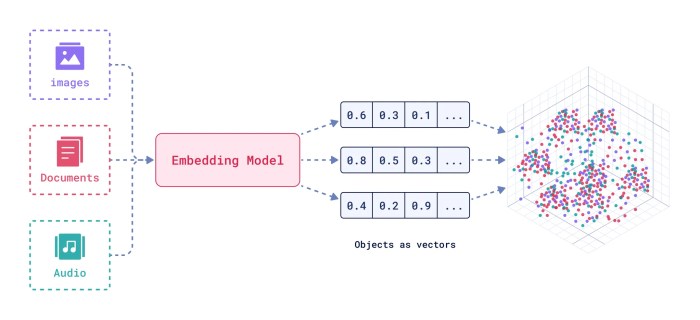
사람이 쓰는 텍스트(단어, 문장, 문서 등)를 컴퓨터가 이해할 수 있는 숫자 벡터(고차원 숫자 배열)로 변환하는 것.이 숫자 벡터가 바로 “임베딩(embedding)”입니다.컴퓨터 입장에서는 ‘강아지’, ‘고양이’라는 글자만 보고 두 단어의 “의미적 유사성”을 알 수
52.LangChain: LangChain Memory 종류
LangChain에서 Memory는 LLM 기반 애플리케이션의 “대화 컨텍스트” 유지에 핵심적인 역할을 합니다. 기본적으로 ConversationBufferMemory(단순히 대화 이력을 모두 저장)를 가장 많이 쓰고, 더 스마트한 컨텍스트 관리가 많아질수록 Summ
53.멀티모달(Multi Modal) AI: 인간처럼 사고하는 AI
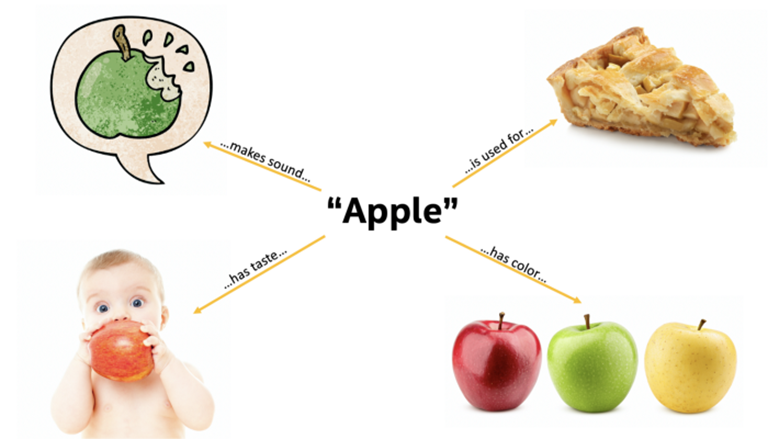
출처
54. 휴머노이드 로봇: 사랑의 조건
https://uppity.co.kr/category/cloumn/%ec%a0%84%eb%ac%b8%ea%b0%80-%ea%b8%b0%ea%b3%a0/economic-trends/%ed%9c%b4%eb%a8%b8%eb%85%b8%ec%9d%b4%eb%93%9c
55.정보 최신화의 중요성: 태양계에는 몇 개의 행성이 있나요? 9개? 땡, 8개? 정답
출처새로운 밀레니엄을 앞둔 1999년 출간되어 벌써 25년이 지난 빌 게이츠의 명저 “생각의 속도”에서는 “새로운 테크놀로지를 이해하기 위해서는 바로 그 이전의 기술에 대한 이해가 필요하고, 그 흐름을 한 번 놓치면 생각의 속도는 영원히 뒤처진다.”라는 구절이 나오는데
56.AI가 실제 기업 실적 개선으로 이어진 대표적인 사례
AI가 실제 기업 실적 개선으로 이어진 대표적인 사례와 근거는 다음과 같습니다.아마존: AI 기반의 개인화 추천 시스템과 생성형 AI 도구를 물류, 쇼핑, 엔터프라이즈 서비스 등에 적극 활용하고 있습니다. 그 결과, 2025년 회계연도 2분기에 매출 235조 5천억원,
57.OpenAI: GPT-5
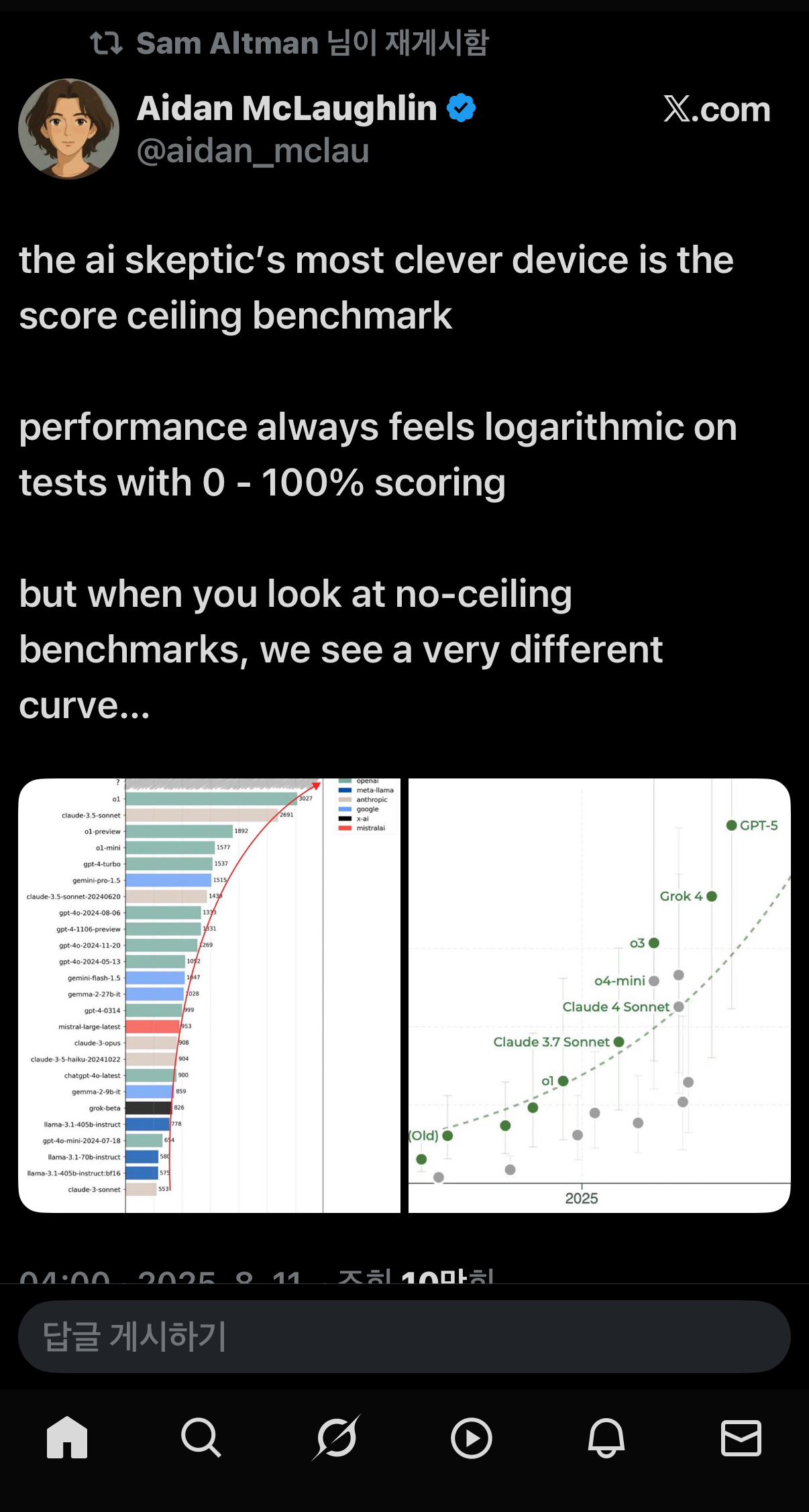
https://stibee.com/api/v1.0/emails/share/CfaMKfvaRo9uITS9DHgYmJANiwfpeDUBy. HEATHERⓒ 오픈AI🔎 핵심만 콕콕오픈AI가 2년 만에 인공지능 모델인 ‘GPT-5’를 공식 출시했습니다.GPT-5가
58.QWEN: Tongyi Qianwen, Alibaba Cloud Open-Source LLM Series
(QWEN: Tongyi Qianwen, Alibaba Cloud Open-Source LLM Series)QWEN(通义千问, Tongyi Qianwen)은 알리바바 클라우드가 개발한 오픈소스 대형 언어 모델(LLM) 시리즈로, 2023년 4월 베타 공개 후 같은 해
59.The Future Isn’t Horizontal: AI’s Vertical Revolution
Vertical AI refers to artificial intelligence (AI) systems tailored for specific industries or domains, rather than being broadly applicable across va
60.Anthropic: Constitutional AI의 작동 원리
Constitutional AI(CAI)는 Anthropic에서 개발한 AI 안전성 기술로, Claude가 더 신중하고 안전한 답변을 하도록 하는 핵심 기술입니다.개념적 구조도움성: 사용자에게 실질적 도움 제공무해성: "해로운 내용 생성 방지 정직성: "불확실한 정보에
61.AI Makes Tech Debt More Expensive
https://news.hada.io/topic?id=17775https://www.gauge.sh/blog/ai-makes-tech-debt-more-expensiveAI Makes Tech Debt More ExpensiveThere is an e
62.GPUaaS(GPU as a Service)
레드햇이 제시하는 GPU 공유부터 MLOps 자동화까지의 AI 인프라 관리 전략을 실무 관점에서 정리해 드리겠습니다.아래 내용은 단순 요약이 아니라, 활용 방법·장단점·적용 시 주의사항을 포함한 실무 가이드 형태입니다.온프레미스·하이브리드·퍼블릭 클라우드 환경에서 GP
63.Vector DB: 임베딩(Embedding)

https://gruuuuu.hololy.org/ai/vector-store/https://devocean.sk.com/blog/techBoardDetail.do?ID=164964데이터의 묶음은 여러의미의 데이터들로 이루어진 경우가 많은데, 이를 특정
64.Vector DB: a look at the AI database market
https://objectbox.io/vector-database/
65.VectorDB: 유사도(Similarity) 계산

VectorDB에서 유사도 계산은 쿼리 벡터(Query Vector)와 저장된 벡터(Stored Vector) 간의 거리(distance) 또는 각도(angle)를 측정하는 방식입니다. 대표적으로 Cosine Similarity, Euclidean Distance(L
66.Vector DB: 벡터 크기(Norm)와 Dot Product 관계
여기 참고: 노름(Norm)벡터의 길이(유클리드 노름, Euclidean Norm)$|A| = \\sqrt{a_1^2 + a_2^2 + ... + a_n^2}$특징: 각 차원의 값이 클수록 크기 증가예$A = 1, 1$ → $\\sqrt{2} \\approx 1.414
67.VectorDB: FIASS
그럼 가입 없이 바로 실행 가능한 Vector DB 예제를 만들어 드리겠습니다. FAISS (로컬 Vector DB, 가입 불필요) Hugging Face 무료 Embedding 모델 (sentence-transformers)즉, API 키도 필요 없고, 사이트 가
68.근사 최근접 이웃(ANN) 알고리즘 이해
https://www.elastic.co/kr/blog/understanding-ann
69.LLM 및 자율제어 시스템에서 할루시네이션(Hallucination) 억제와 답변 일관성 유지 방식 정리

LLM 및 AI 시스템에서 할루시네이션은 단순한 오류를 넘어 신뢰성, 안전성, 규제와 직결됩니다.특히 자율주행 같은 자동제어 영역에서는 물리적 안전 문제로 이어질 수 있으므로 다층적인 조정 전략이 필요합니다. 고품질 학습 데이터 강화: 신뢰성 있는 데이터셋으로 파인튜
70.n8n: 시작하기
오픈소스 업무 자동화 플랫폼드래그 앤 드롭으로 워크플로우 설계 가능400+ 서비스 연동 (Gmail, Slack, Notion, DB, API 등)셀프 호스팅 가능 → 데이터 보안 유리무료로 시작 가능, 필요 시 유료 클라우드 버전https://n8n.io 접
71.AI 확장에 필요한 추가 코어: 핵심 내용 정리
핵심 내용: 선형대수, 확률, 미적분활용 팁 CNN의 합성곱 연산은 행렬 곱으로 표현 가능 확률 분포를 이해하면 모델 출력의 신뢰도 해석 가능 핵심 내용: 데이터 → 모델 → 학습 → 추론활용 팁 데이터 전처리 품질이 모델 성능의 핵심 학습 시 Validatio
72.AI 확장에 필요한 추가 코어: 손글씨 숫자 인식(MNIST)

이 예제는 수학 기초, 모델 설계·학습, 최적화, 배포를 모두 포함합니다.MNIST 데이터셋: 28×28 픽셀의 손글씨 숫자 이미지 (0~9)선형대수: 이미지 → 행렬, CNN 합성곱 연산 이해확률: Softmax로 각 숫자 확률 계산미적분: 경사하강법으로 파라미터 업
73.VectorDB: OpenAI Embeddings 시각화 (PCA)
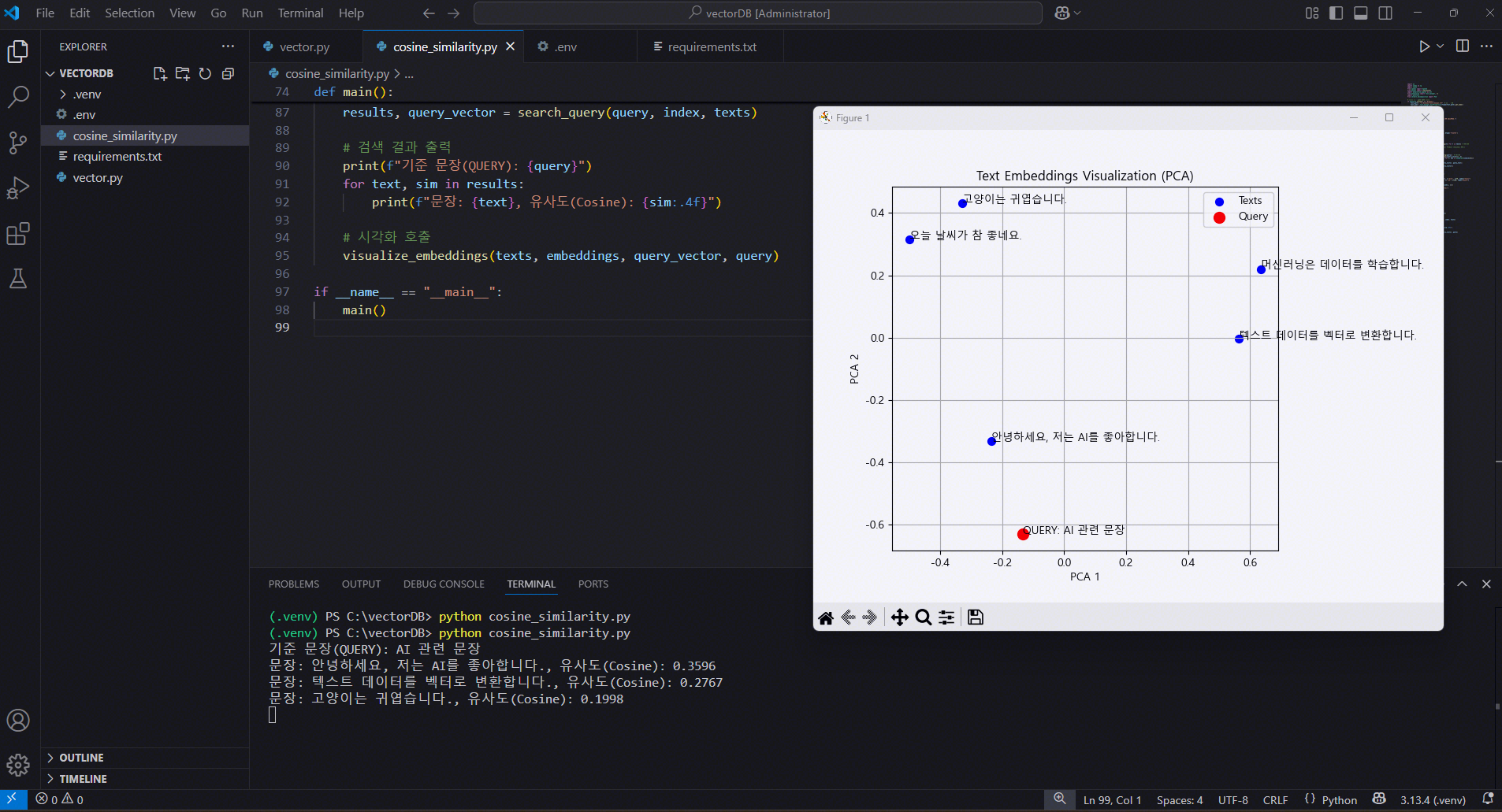
OpenAI Embeddings 시각화 (PCA) OPEN AI Embeddings 활용 버전 >환경구성 > requirement.txt >.env OpenAI Embeddings 시각화 (PCA) 거리(distance) 판단 방식 예를 들어 지금 검색 결
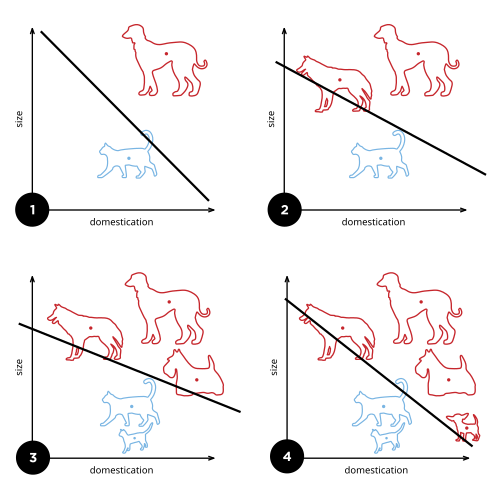
74.머신러닝 시스템의 종류 정리 문서
감독 유무: 지도 / 비지도 / 준지도 / 강화학습 시간축: 배치 / 온라인일반화 방식: 사례 기반 / 모델 기반필요에 따라 조합 가능 (예: 온라인 + 지도 + 모델 기반 스팸 필터)입력–정답(레이블)으로 학습 (분류/회귀)알고리즘: k-NN, 선형·로지스틱 회귀,
75.Open AI: ChatGPT 인스턴트 체크아웃(Instant Checkout)
기능: ChatGPT 내에서 상품 탐색 → 결제까지 한 번에 처리 (Stripe 기반 Agentic Commerce Protocol)현재 적용 범위: 미국 Etsy 단일 상품 구매확장 계획: 다중 장바구니, Shopify 등 타 플랫폼 지원 예정구조 변화: 기존 ‘검색
76.xAI: 챗봇이 안내해 준 피싱 사이트, 해킹 범죄 확산
https://www.mk.co.kr/news/it/11412844발생 플랫폼: X(구 트위터)관련 AI: xAI의 챗봇 Grok공격 방식해커가 자극적인 성인 콘텐츠가 포함된 광고성 게시물 업로드해당 게시물에 Grok을 태그하고 “이 영상 출처가 뭐냐” 등 질
77.TCO (Total Cost of Ownership, 총소유비용): 직접비용 (Direct Cost), 간접비용 (Indirect Cost), 숨은비용 (Hidden Cost)
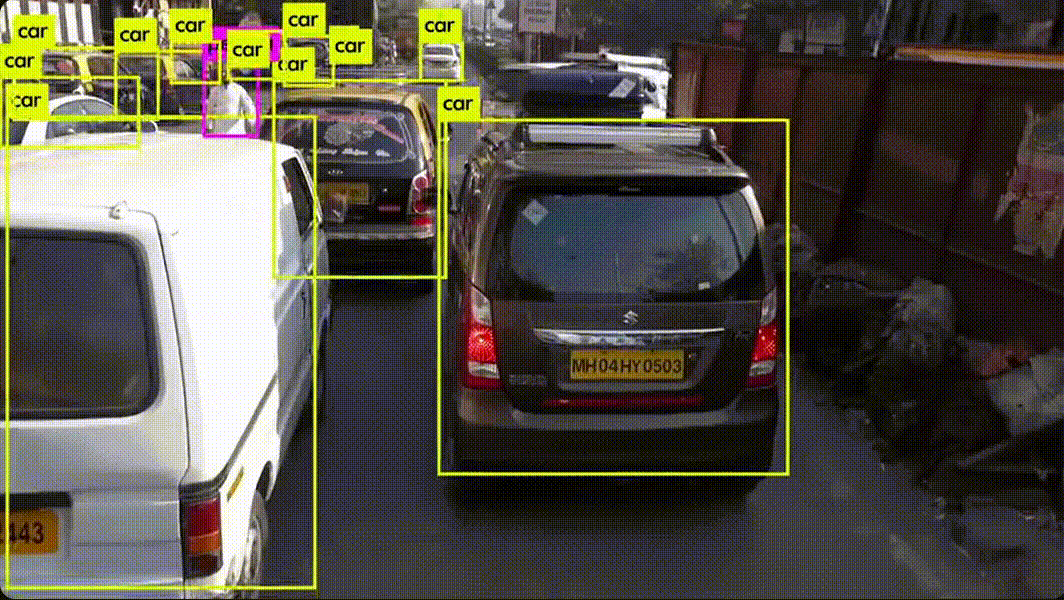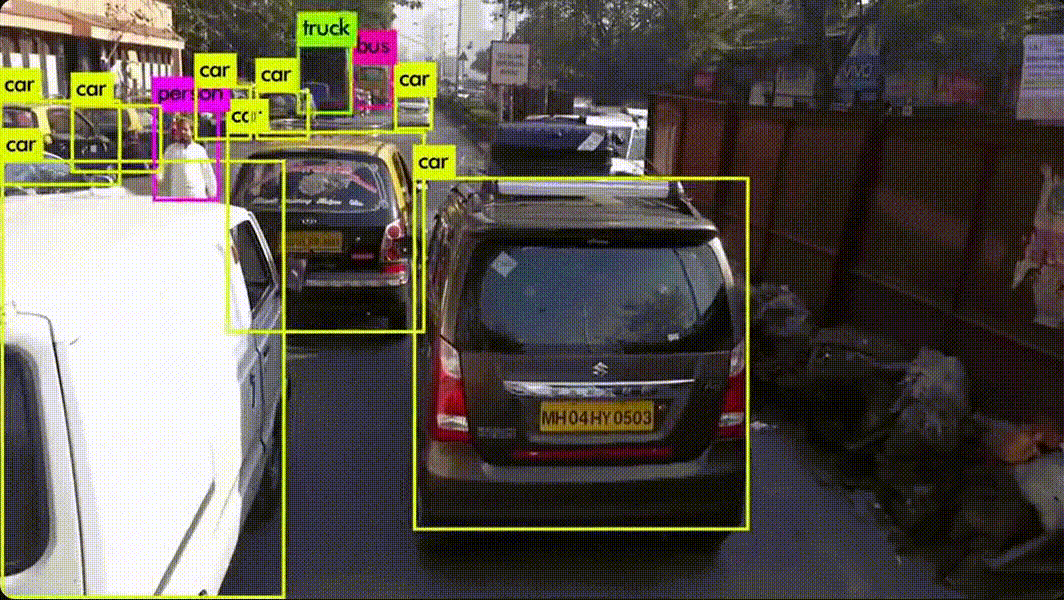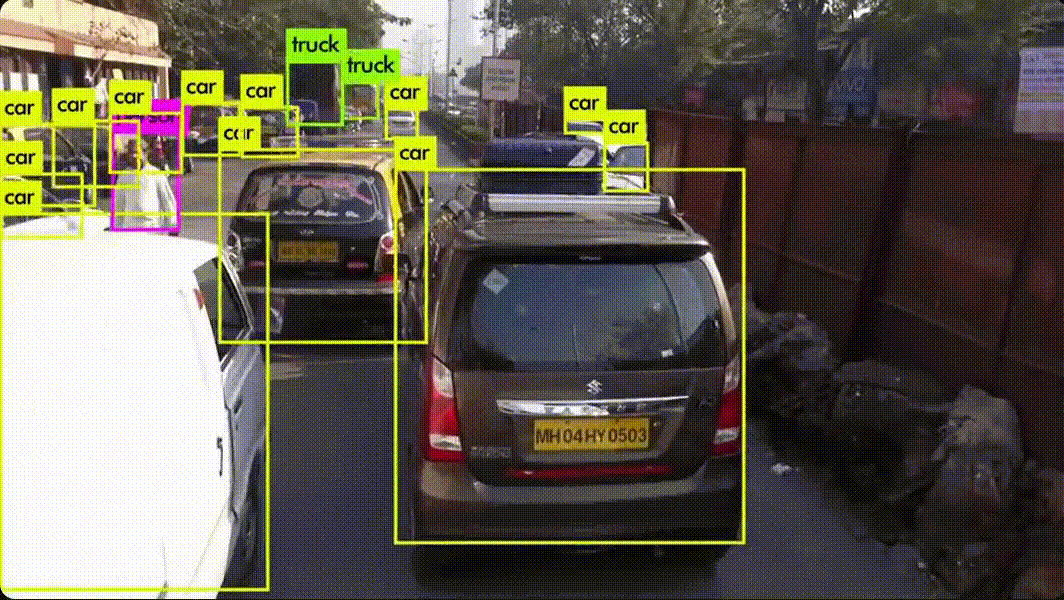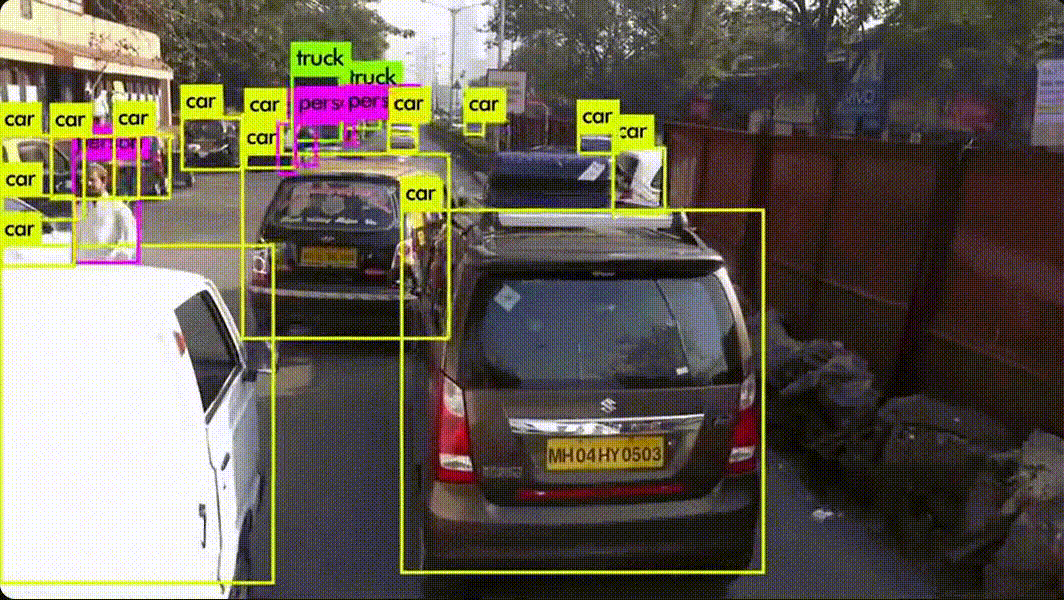
생산·운영 과정에서 바로 식별 가능하고, 해당 활동에만 발생하는 비용예시 (금융사 AI 도입 시) AI 소프트웨어 라이선스 비용 AI 서버·GPU 구매비 AI 모델 개발 인건비(프로젝트 전담팀 급여) 데이터 구매·수집 비용활용 포인트 ROI(투자수익률) 계산
78.NVIDIA: V100(Volta)와 H100(Hopper) GPU
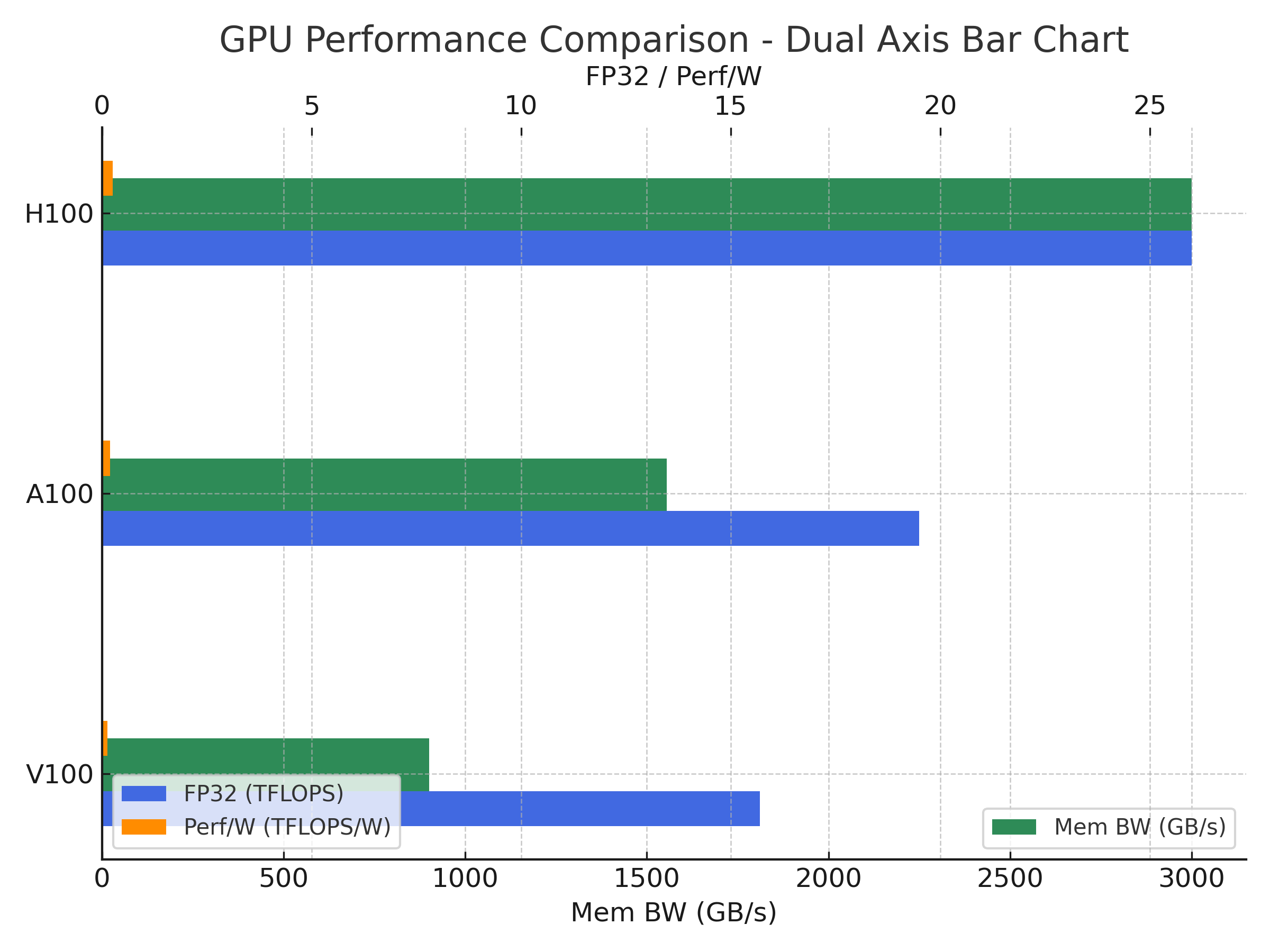
NVIDIA V100(Volta)와 H100(Hopper) GPU는 모두 데이터센터·AI·HPC(고성능 컴퓨팅)용이지만, 세대 차이가 크고 성능·아키텍처·지원 기능에서 큰 차이가 있습니다. V100: 대규모 모델 학습 가능하지만, 최신 대형 모델(예: GPT-3 이상
79.NVIDIA Hopper H100 아키텍처 분석
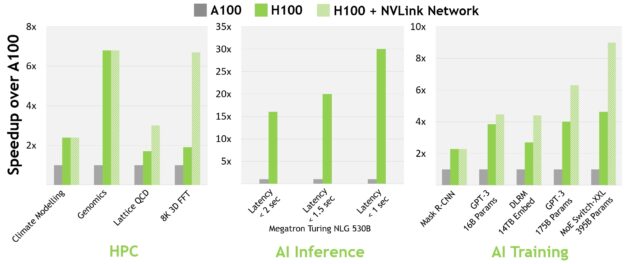
https://developer.nvidia.com/ko-kr/blog/nvidia-hopper-architecture-in-depth/
80.FastAPI: 저사양 환경 실행
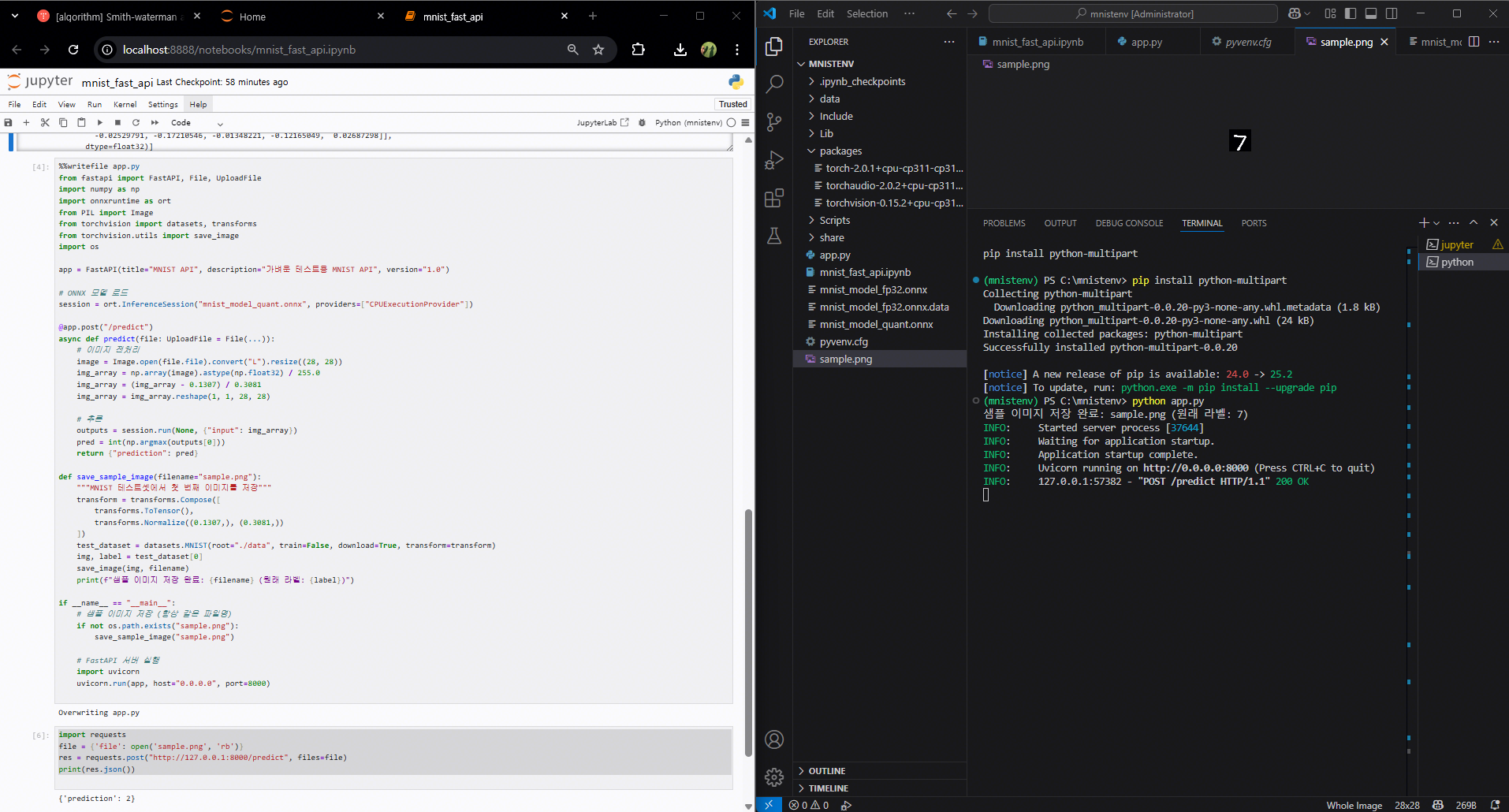
학습 없이 → 이미 학습된 PyTorch 모델 사용 (속도 절약)모델 구조 단순화 → 작은 CNN (Conv 1개 + FC 2개)ONNX 변환은 FP32 → 변환 호환성 100%ONNX Runtime에서 양자화 → CPUExecutionProvider에서 동작FastA
81.Pytorch
Pytorch 한국 사용자 모임: https://pytorch.kr/
82.ONNX
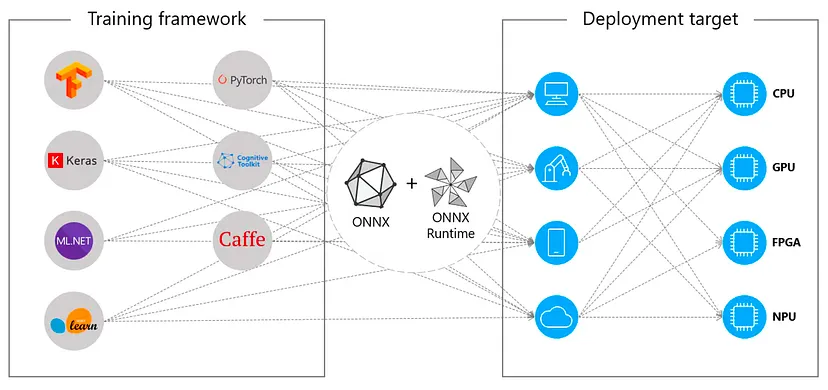
https://medium.com/@enerzai/onnx-%EB%84%88-%EB%88%84%EA%B5%AC%EC%95%BC-who-are-you-5c1435b997e2
83.멀티모달 RAG(Multi-modal Retrieval-Augmented Generation): 다양한 형태의 데이터 처리 방식

각 데이터의 구조·정보 표현 방식이 다르기 때문에, 텍스트로 변환하는 과정과 사용하는 모델이 달라집니다. 데이터 구조 차이 이미지: 픽셀 기반 → 시각적 패턴 인식 필요 표: 행·열 구조 → 구조화된 텍스트 변환 필요 오디오: 시간축 + 음성 → 음성 인식(ST
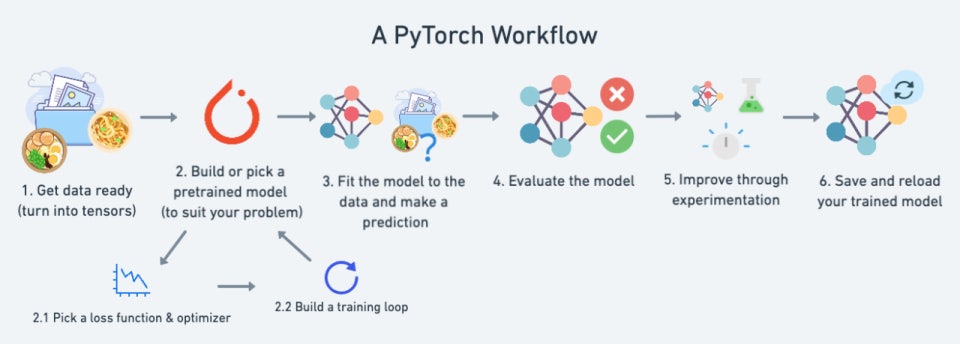
84.PyTorch: Workflow
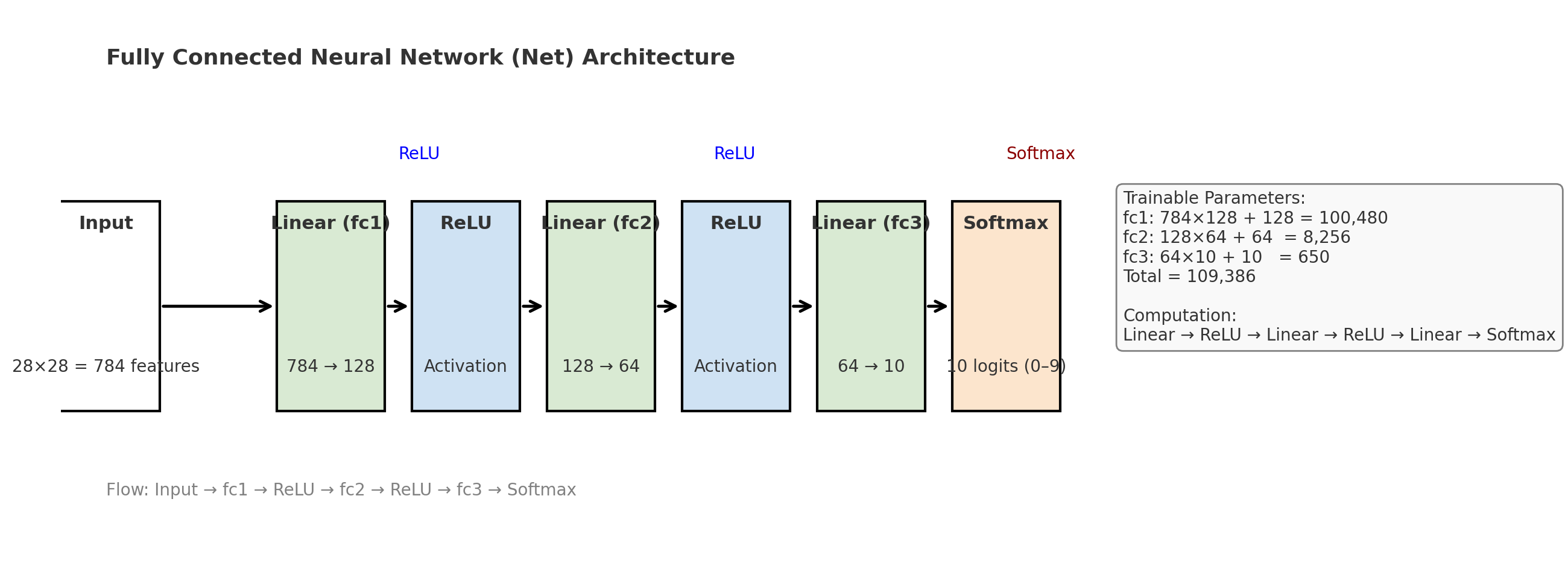
핵심 개념 설명epoch: 전체 데이터셋을 한 번 모두 학습하는 주기(예: MNIST 60,000장을 5번 학습 → 5 epochs)batch: 한 번에 학습하는 데이터 묶음 (여기선 64개)iteration: 한 epoch 내에서 batch 단위로 반복되는 횟수(60
85.epochs와 batch_size의 상관관계
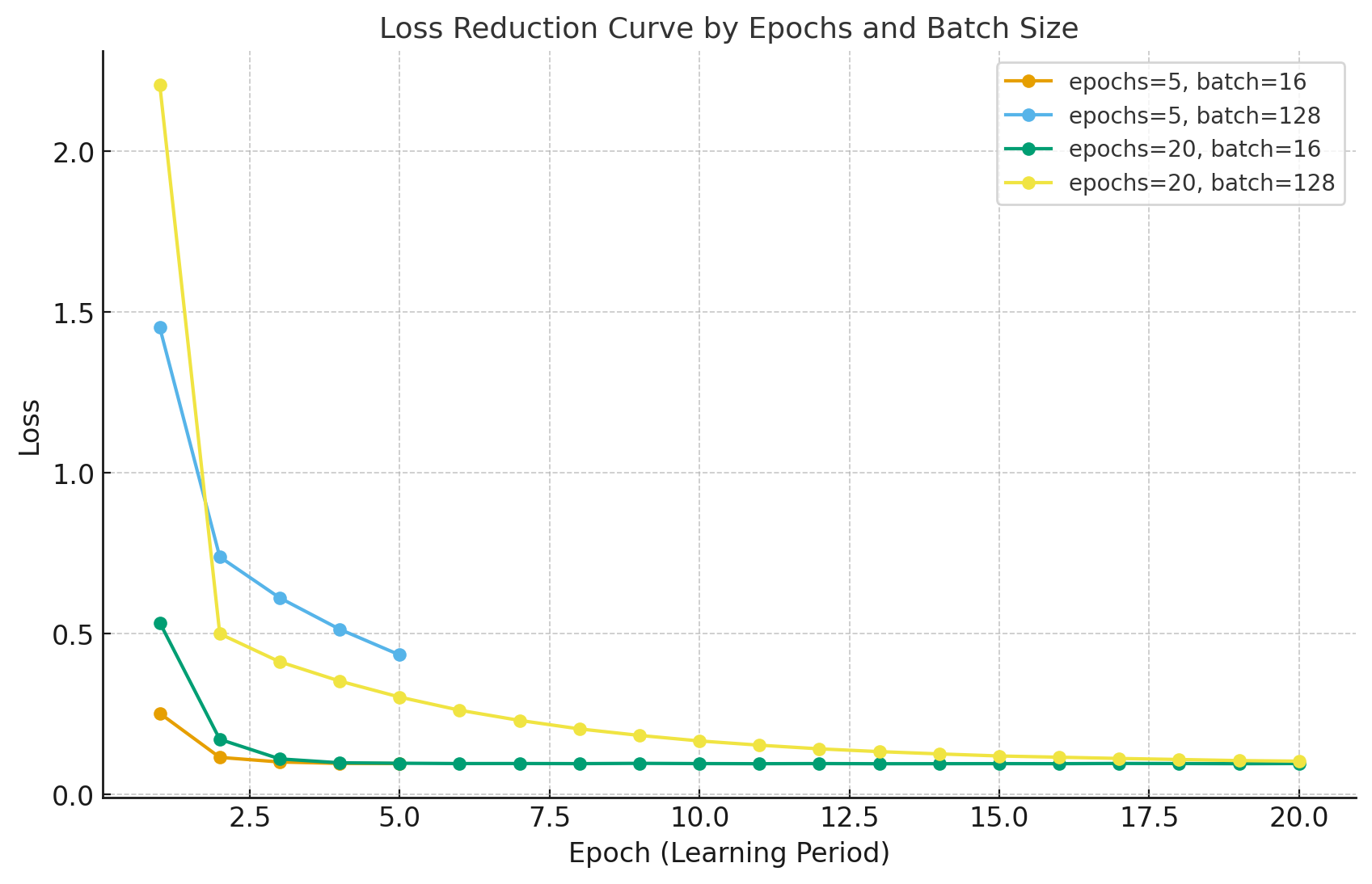
https://velog.io/@corone_hi/epochs-%EB%9E%80딥러닝 모델을 학습할 때, epochs와 batch_size는 학습 방식에 큰 영향을 미칩니다.이 두 매개변수는 데이터가 모델에 어떻게 전달되고, 모델이 얼마나 자주 가중치를 업데이
86.신경망(Neural Network): 신경망의 기본 구조
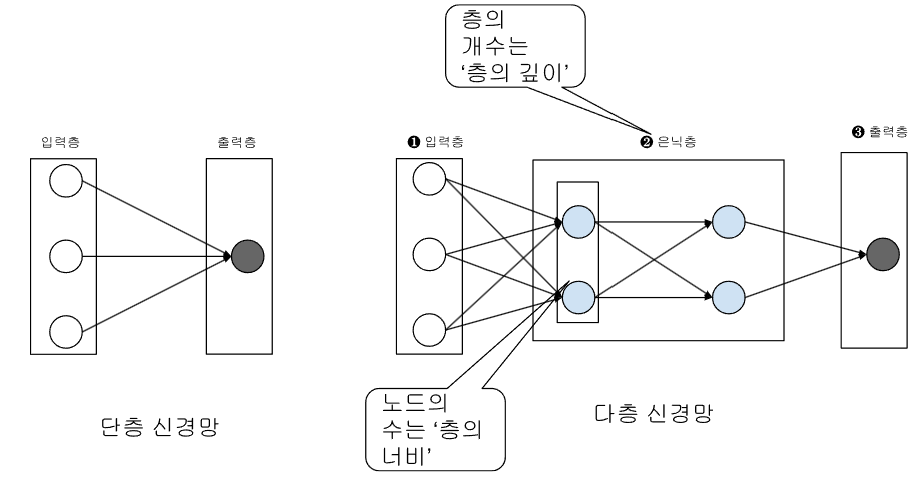
신경망(Neural Network) 신경망은 인간의 뇌가 수많은 신경세포(뉴런) 들이 서로 연결되어 정보를 주고받는 구조를 모방한 수학적 모델입니다. 뉴런들은 입력 신호를 받아 가중치(Weight) 를 적용한 후, 활성화 함수(Activation Function)
87.활성화 함수 (Activation Functions) : Leaky ReLU, Mish
https://wikidocs.net/163752
88.Reducing input and output features
Reducing input and output features is at the core of model design and optimization. Your model’s first layer (nn.Linear(784, 128)) takes 784 features,
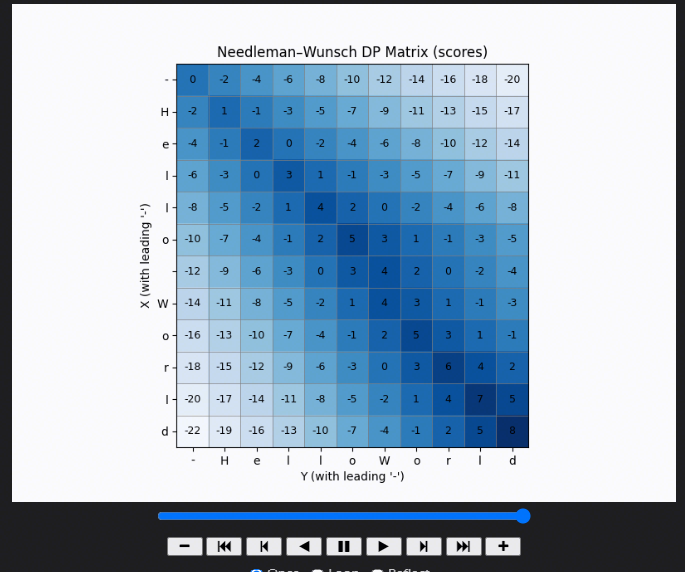
89.니들만-분쉬(Needleman-Wunsch) 알고리즘
https://mobuk.tistory.com/88 Needleman-Wunsch 알고리즘 Sequence Alignment는 한국어로 '서열 정렬'이라고 한다. 이에 대해 검색을 해보면 주로 '생물정보학'에서 DNA, RNA 사이의 기능적, 구조적 상관관계를
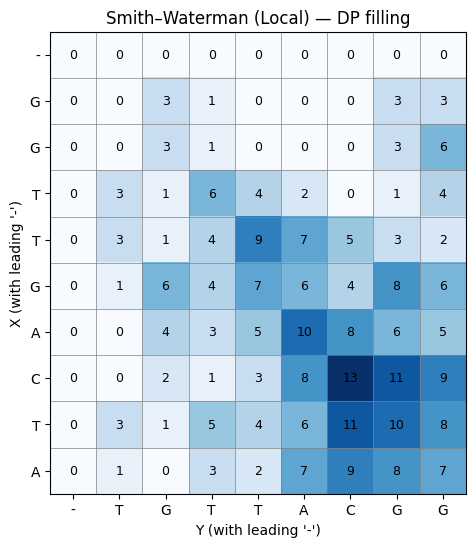
90.스미스-워터맨(Smith-Waterman) 알고리즘: DPX(Dynamic Programming eXtensions) 명령어

https://mobuk.tistory.com/90
91.Needleman-Wunsch: DP-filling Visualization
92.Smith-Waterman: DP-filling Visualization
93.[Deep Learning Bible] Hisotry of Artificial Intelligence
https://wikidocs.net/203720
94.온톨로지(Ontology): 인공지능의 지식 표현 체계
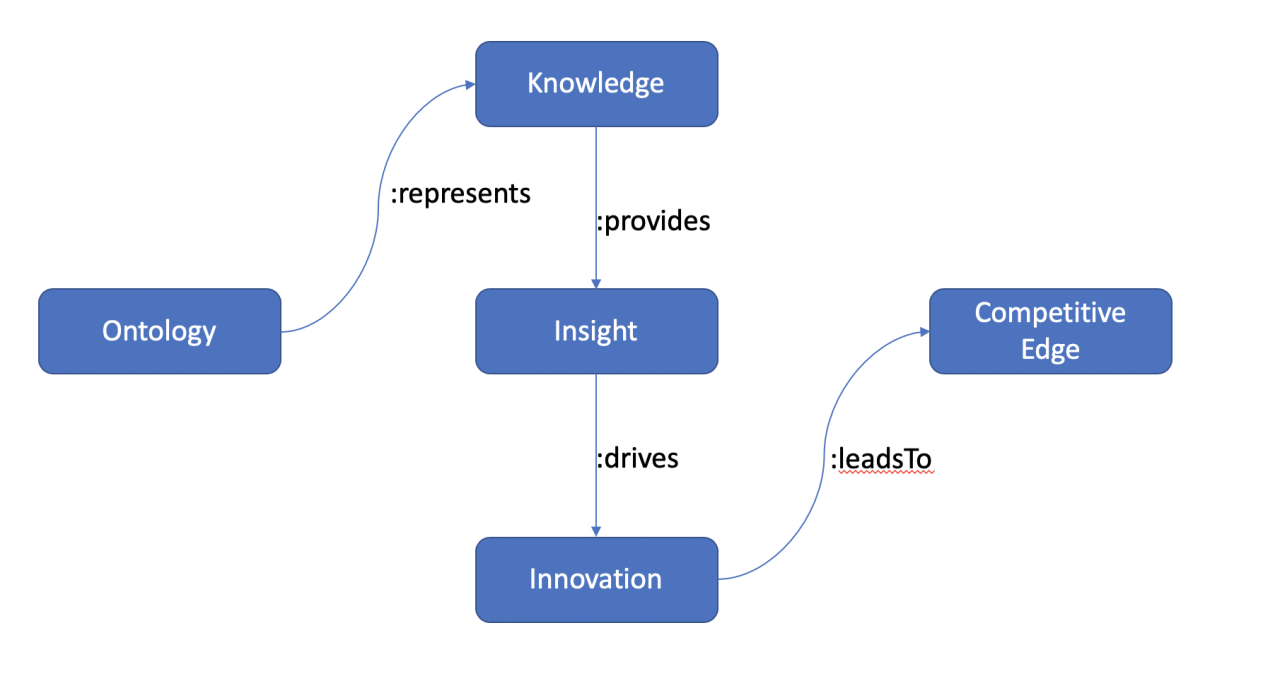
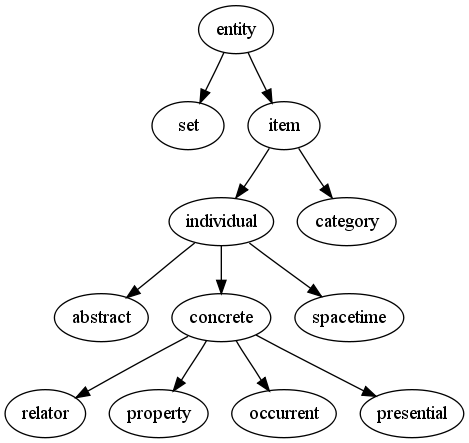
온톨로지(ontology) 란 “특정 분야에서 존재하는 개념들과 그 관계를 명시적이고 형식적으로 정의한 개념 체계” 를 말합니다.즉, 어떤 도메인(예: 의료, 법률, 교육, 교통 등)에서무엇이 존재하는지(개념),그것들이 어떻게 연결되는지(관계),어떤 규칙이 적용되는지(
95.Did You Know What You Really Need is an Ontology?
https://www.linkedin.com/pulse/did-you-know-what-really-need-ontology-mark-hall?utm_source=share&utm_medium=member_ios&utm_campaign=share_viaDid
96.활성화 함수(Activation Functions): 기울기(Gradient)와 학습 안정성
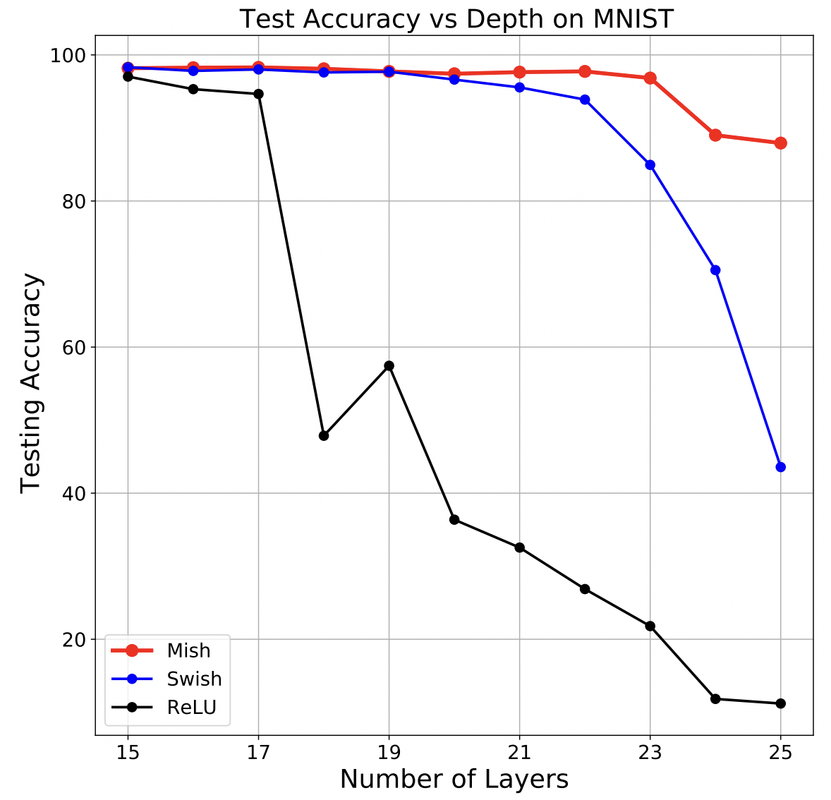
신경망은 역전파(Backpropagation)를 통해 손실함수의 기울기를 계산하고, 그 기울기를 사용해 가중치를 업데이트한다.따라서 활성화 함수의 기울기(미분값)가 안정적으로 잘 전달되는지는 학습 가능성 자체를 좌우한다.역전파에서 가중치 업데이트는 다음과 같이 계산된다
97.AI의 신뢰성(reliability): 통계적 정합성과 생물학적 타당성
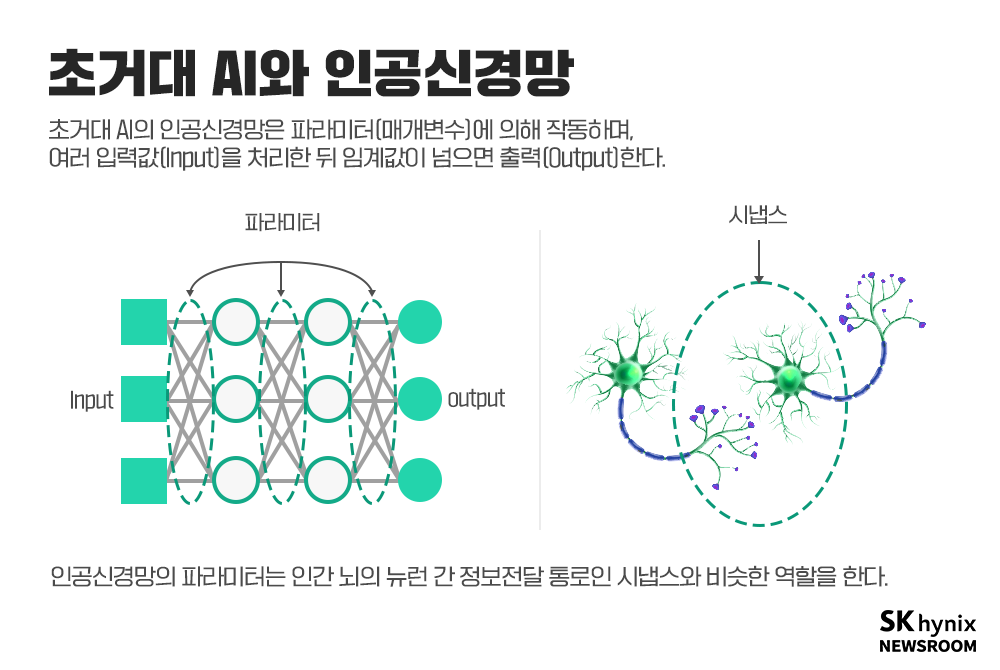
생물학적 타당성(Biological plausibility): 관찰된 현상이나 연구 결과가 기존 생물학·생리학·의학 지식과 일관되게 설명될 수 있는 정도를 의미한다.→ 단순 통계적 상관관계가 아니라, 실제 기전(mechanism) 으로 설명 가능한지 평가하는 기준이다.
98.Transformer Architecture
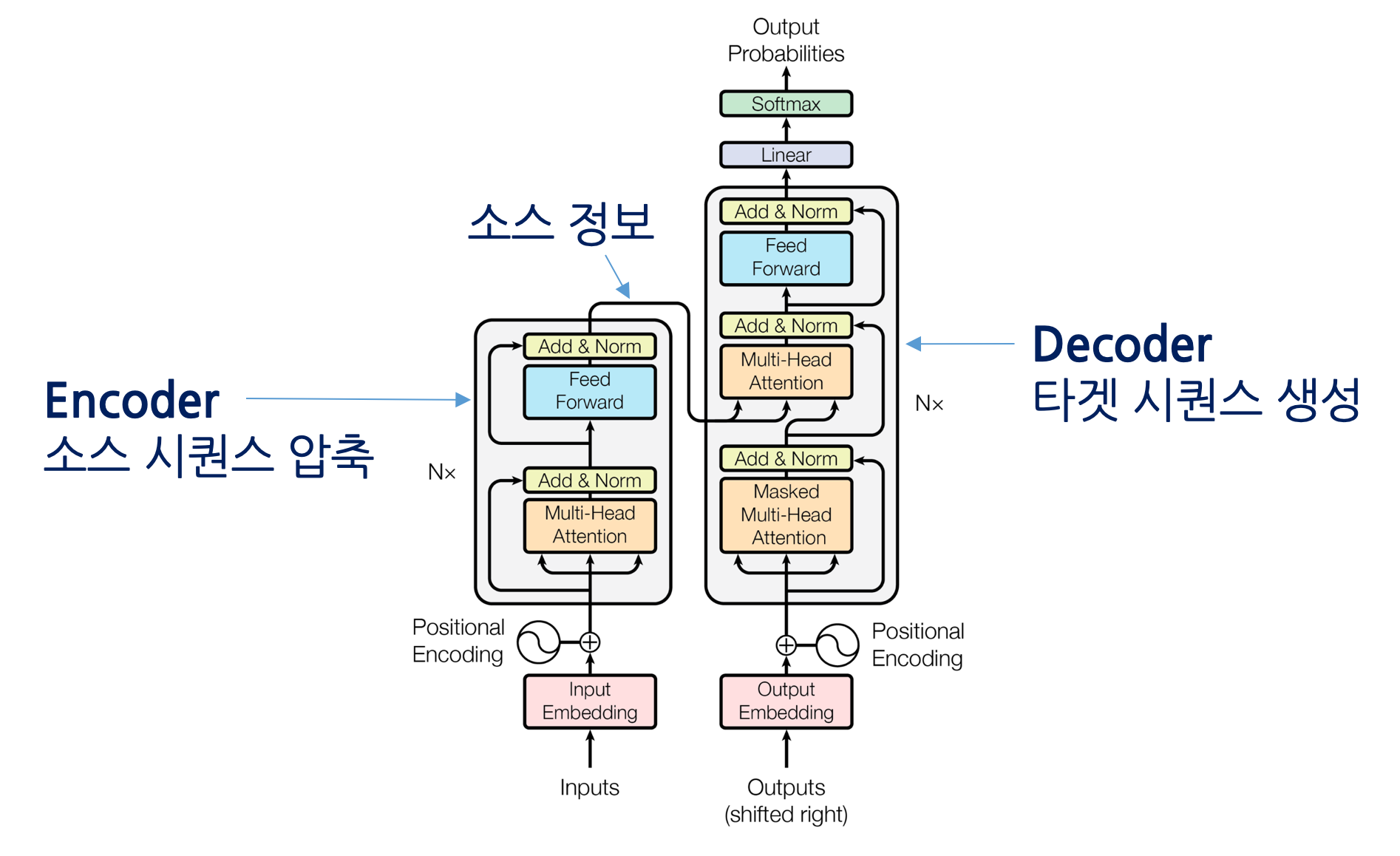
Transformer는 2017년 Google의 논문 “Attention Is All You Need” 에서 제안된 구조로,순차적 처리를 기반으로 하던 RNN, LSTM을 병렬적 Self-Attention 메커니즘으로 대체하며대규모 학습과 긴 문맥 이해를 가능하게 한
99.ChatGPT 이후, AI 기술은 어디로 향하고 있을까?
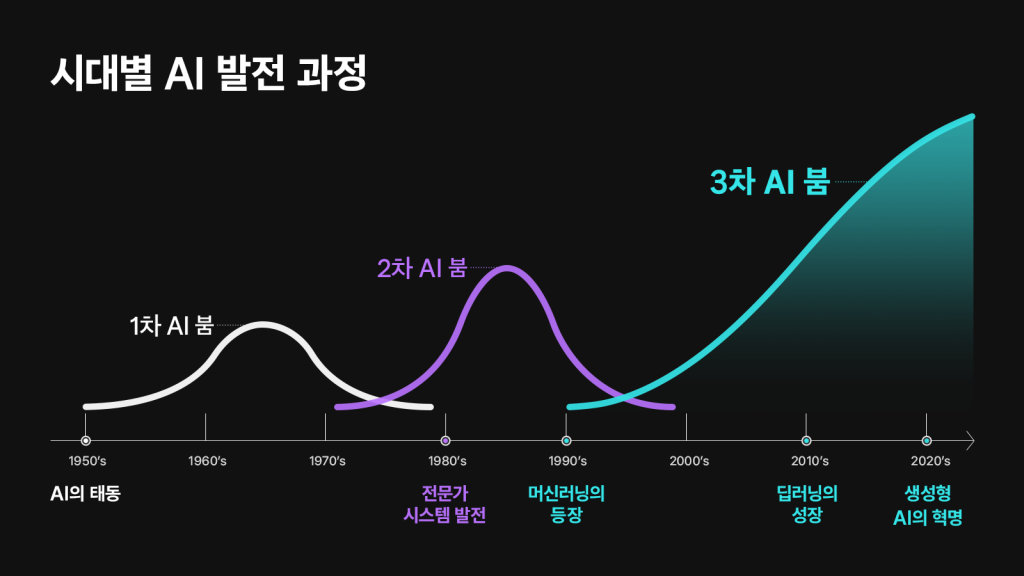
ChatGPT 이후 AI 기술 발전사https://blog.naver.com/fstory97/223862431036?trackingCode=rss
100.Transformer Architecture: 학습 과정 정리
https://forest62590.tistory.com/48
101.분류 성능 평가: ROC (Receiver Operating Characteristic) 및 AUC (Area Under the Curve)
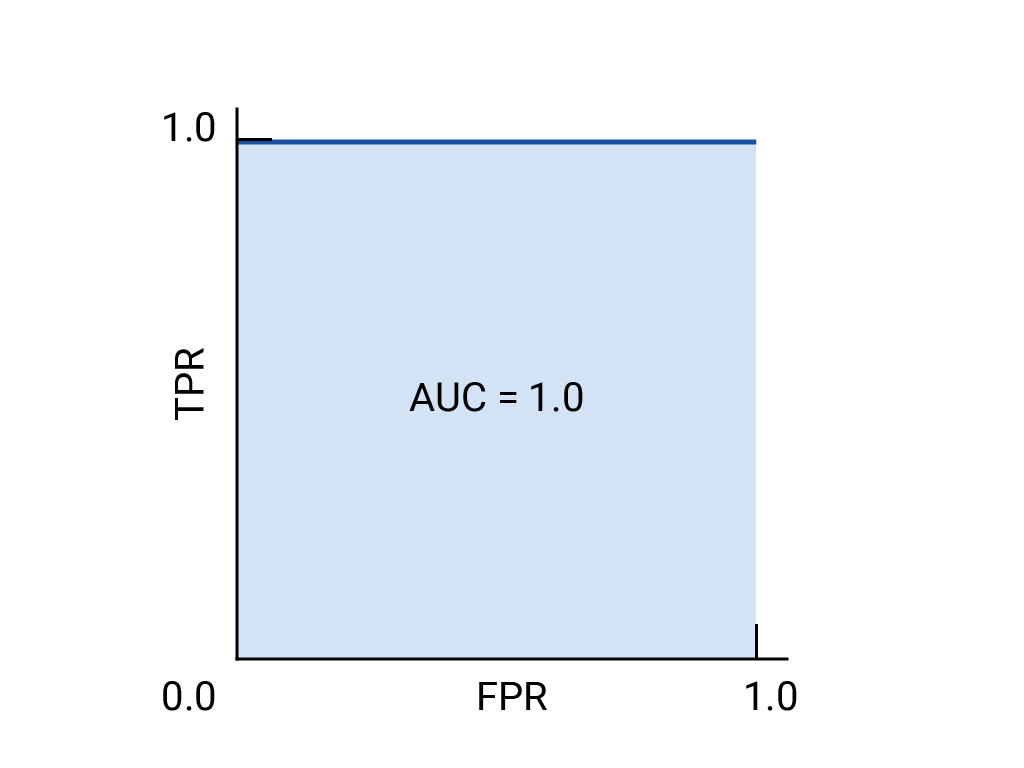
https://developers.google.com/machine-learning/crash-course/classification/roc-and-auc?hl=ko#:~:text=ROC%20%EA%B3%A1%EC%84%A0%20%EC%95%84%EB%9E%9
102.Comparing Model Ensembling: Bagging, Boosting, and Stacking
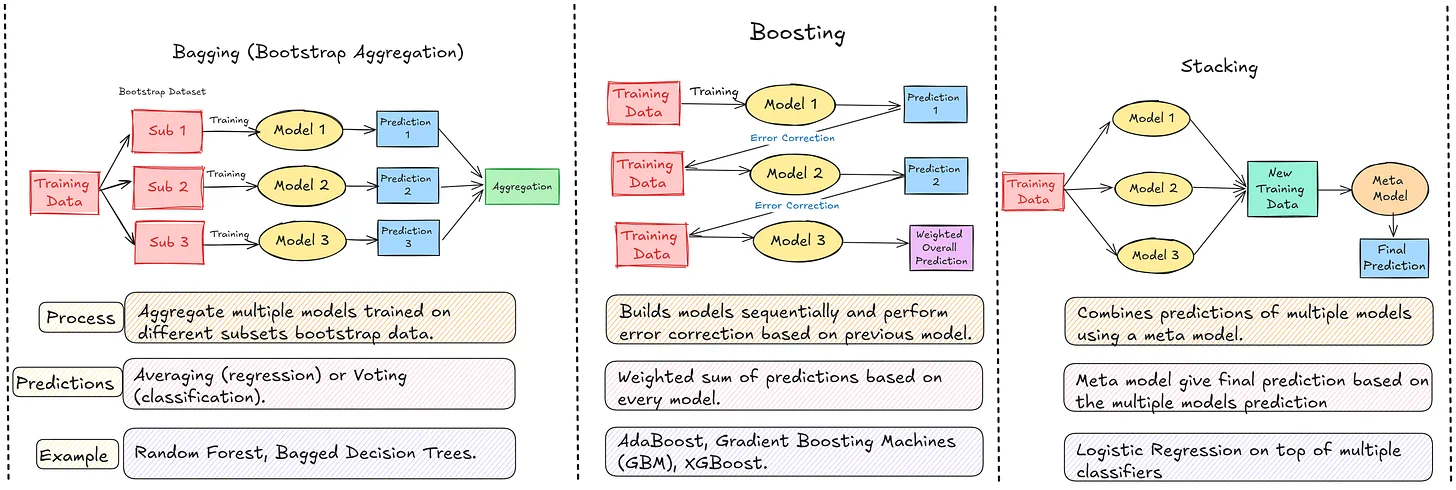
https://www.nb-data.com/p/comparing-model-ensembling-bagging업로드중..
103.[Python 완전정복 시리즈] 2편 : Pandas DataFrame 완전정복
https://wikidocs.net/book/7188
104.페르소나 기법: 단일 페르소나 기법, 멀티 페르소나 기법
https://openai.com/ko-KR/index/wrtn/https://brunch.co.kr/@ghidesigner/184페르소나 기법은 거대언어모델(LLM)이 특정 인물(전문가, 사용자, 이해관계자)의 역할을 시뮬레이션하도록 프롬프트를 설계
105.Grok Imagine: AI image generation

https://grokimagine.ai/ko
106.인공지능의 시초: 맥컬록-피츠 모델

https://brunch.co.kr/@plutoun/187
107.인공지능의 시작: 퍼셉트론(Perceptron)
https://sacko.tistory.com/10
108.AHHA Labs
https://ahha.ai/ Products > These names are so cute. DAISY Data CAMP LISA AIモデル性能最大化のための実務ガイド >アハラボ(AHHA Labs)のアプローチを参考に、AIモデルの性能を最大化するためのデータ品質
109.Performance Evaluation Metrics: Precision, Recall, and F1 Score

https://medium.com/@piyushkashyap045/understanding-precision-recall-and-f1-score-metrics-ea219b908093
110.Gemini 3: 신규 개발 플랫폼·강력한 초추론·멀티모달 통합
https://yozm.wishket.com/magazine/detail/3459/
111.Gemini: Create useful PPT with AI
!youtubez6hSWfBGmoc
112.계층적 샘플링 (Stratified Sampling)
계층적 샘플링(Hierarchical Sampling 또는 Stratified Sampling)은 모집단을 특정 기준(계층, 층, Strata)으로 나눈 뒤, 각 계층에서 샘플을 추출하는 방법입니다. 예: 고객 데이터를 성별, 연령대, 지역 등으로 나누고 각 그룹에서
113.분할기(Splitter)
데이터셋을 학습용(train), 검증용(validation), 테스트용(test)으로 나누는 도구 또는 알고리즘입니다. 올바른 분할은 모델 성능의 신뢰도와 일반화 능력 평가에 매우 중요합니다.대표 예 train_test_split KFold, StratifiedK
114.상관관계(Correlation)
상관관계(Correlation)는 두 변수 간의 선형적 관계의 강도와 방향을 나타내는 통계 개념입니다. 양의 상관관계: 한 변수가 증가하면 다른 변수도 증가하는 경향 음의 상관관계: 한 변수가 증가하면 다른 변수는 감소하는 경향 0에 가까움: 선형 관계가 거의 없
115.모델(Model): model.predict()와 accuracy_score 내부 동작 정리
학습된 모델이 X_test의 각 샘플(행)을 입력받아 예측 라벨을 생성함.모델 종류별 예측 방식 예결정트리(Tree): 분기 기준을 따라 내려가 리프 노드의 클래스를 선택로지스틱회귀(Logistic Regression): 시그모이드로 확률 계산 후 임계값 0.5 기준으
116.모델(Model): 종류별 정리
머신러닝 → 트리 계열 → 랜덤포레스트 → predict 방식머신러닝 → 선형 계열 → 로지스틱 회귀 → predict 방식딥러닝 → CNN → predict 방식시계열 → ARIMA → predict 방식 데이터의 규칙을 통계적/수학적으로 학습해트리, 회귀, 거리
117.StratifiedKFold 교차검증의 목적과 CV Scores 의미
StratifiedKFold를 사용하는 목적은 다음과 같습니다.단순한 Train/Test split은 데이터 분할의 운(luck)에 따라 성능이 달라짐 교차검증은 여러 번 나누어 훈련/검증을 반복한 뒤 평균을 내서 보다 객관적이고 안정적인 모델 성능을 측정할 수 있음
118.Pandas: DataFrame 컬럼 길이가 다를 때
pandas DataFrame 은 모든 컬럼의 길이가 동일해야만 생성됩니다. 길이가 다르면 에러(ValueError)가 발생합니다. 모델 입력(X)과 라벨(y) 의 개수도 반드시 동일해야 합니다. 다르면 학습 자체가 불가능합니다.예를 들어 age 가 8개, inco
119.상관관계(Correlation): 왜 상관관계를 보는가?
예:income 와 annual_salary 의 상관관계가 0.95 → 사실상 같은 변수 두 개.이런 변수가 여러 개 있으면 모델이 불필요한 변수에 가중치를 주고 노이즈가 늘어나고 과적합 위험이 올라감.실무에서는 보통피처 상관 > 0.8 이면 하나 제거하는 경우
120.모델(Model): XGBoost, LightGBM, CatBoost
XGBoost는 구조적 데이터 환경에서 성능, 안정성, 운영 편의성이 검증된 모델입니다.XGBoost는 다음과 같은 테이블형 데이터에서 성능이 안정적으로 높게 나옵니다.E-commerce 수요/전환 예측 고객 이탈(Churn) 금융 리스크 모델 추천·스코어링 모델
121.오차 지표 설명: MSE, RMSE, MAE
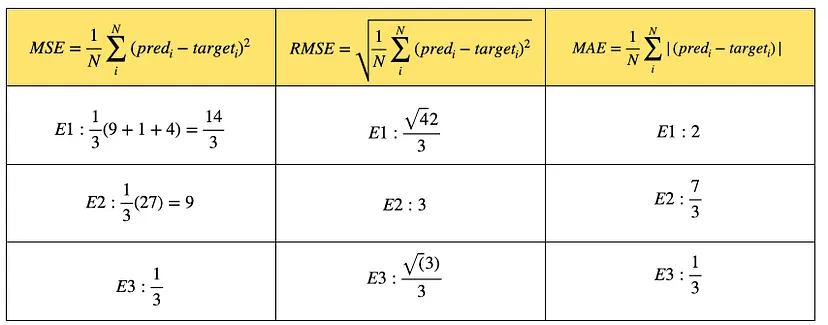
RMSE는 예측값과 실제값 간의 차이를 제곱한 뒤 평균을 구하고, 그 평균값에 제곱근을 취한 값입니다. 수식$\\text{RMSE} = \\sqrt{\\frac{1}{n} \\sum\_{i=1}^{n} (y_i - \\hat{y}\_i)^2}$$y_i$: 실제 값$\
122.Pandas: 피벗 변환 (pivot)
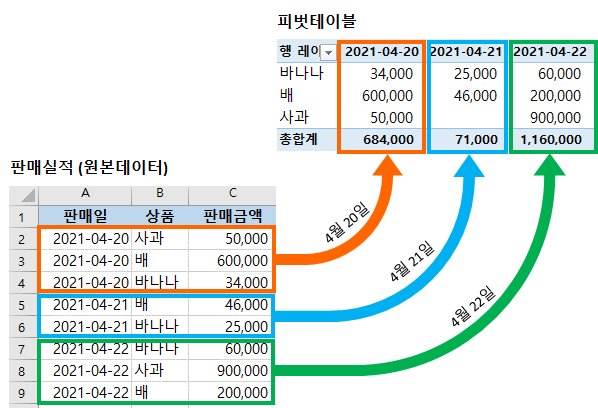
https://wikidocs.net/154073 1. df.pivot_table() pivot_table()은 그룹 집계(aggregation) + pivot 변환을 한 번에 처리하는 pandas 함수입니다. 복잡한 집계를 단 한 줄로 처리할 수 있어 분석/리포
123.Pandas: 피벗 예제(Classification, Regression, Time)
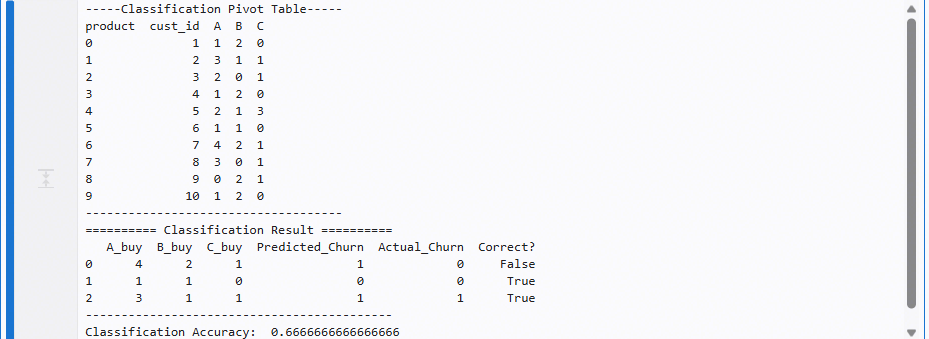
분류(Classification), 피벗 예제 회귀(Regression), 피벗(pivot) 테이블 시계열(Time Series), 15분 resample
124.Pandas: 인덱싱(indexing)
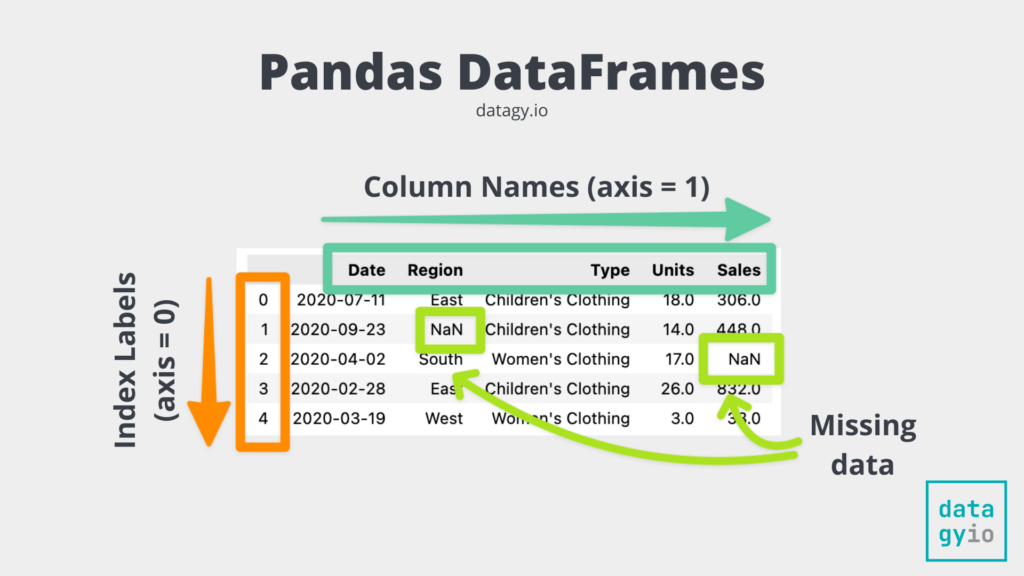
Pandas에서 데이터 작업의 핵심은 행/열을 어떻게 선택하느냐이다. 그중 가장 많이 쓰는 인덱싱 도구는 아래 네 가지:loc → 라벨(label) 기반 선택 iloc → 번호(position) 기반 선택 df\['col'] → 단일 컬럼 선택 (Series 반
125.모델(Model): HistGradientBoostingRegressor
Scikit-Learn HistGradientBoostingRegressor는 대용량 데이터에 최적화된 고속 Gradient Boosting 회귀 모델로, LightGBM의 핵심 아이디어(히스토그램 기반 분할)를 반영한 sklearn 내장 모델입니다.데이터가 커서 일반
126.모델(Model): ExponentialSmoothing
statsmodels.tsa.holtwinters.ExponentialSmoothing은 시계열 예측을 위한 고전적이면서도 실무적 활용도가 높은 지수평활법 모델입니다. 추세(Trend), 계절성(Seasonality)을 함께 다룰 수 있어 단기 예측에 특히 강합니다.
127.하이브리드 시계열 예측 시스템: ExponentialSmoothing + HGBR + FastAPI
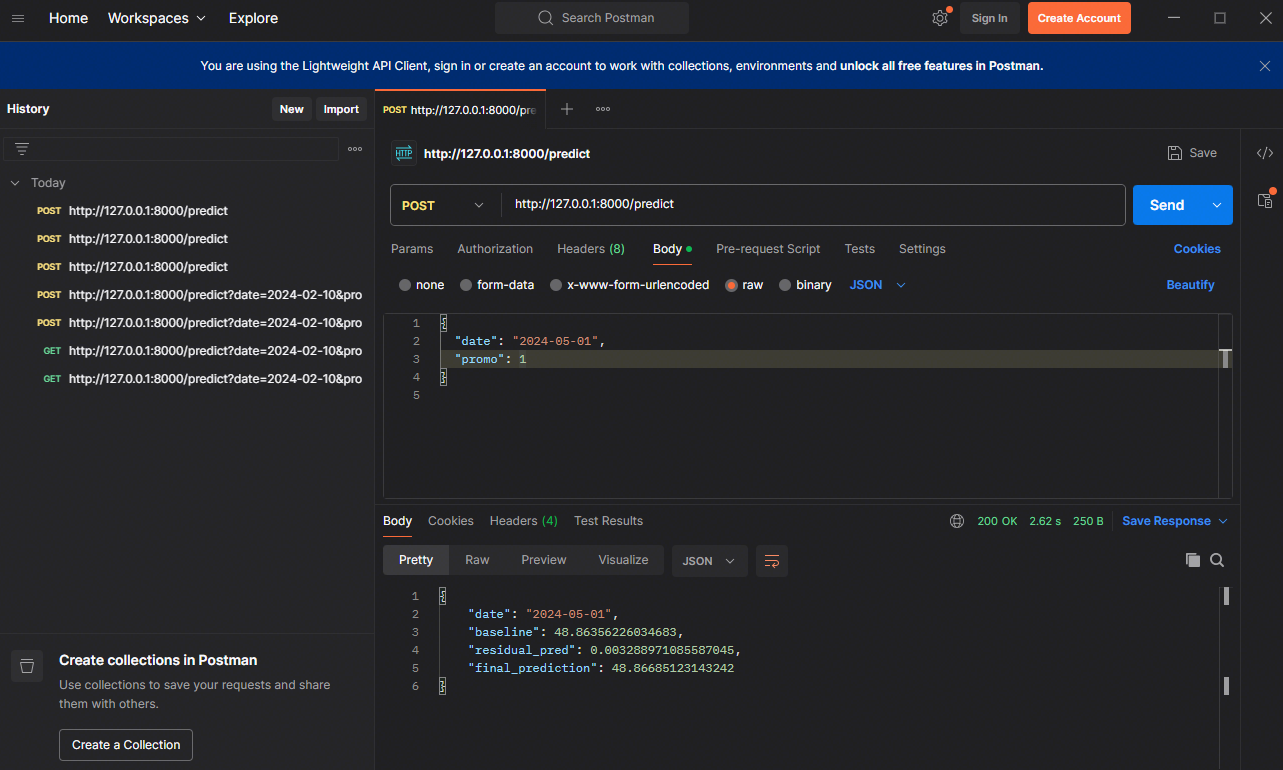
래는 당장 노트북에서 실행 가능한 수준으로 만든전처리 → 모델( HistGradientBoostingRegressor + ExponentialSmoothing ) 훈련 → FastAPI 서비스 구성까지 한 번에 보여주는 예제입니다.데이터: 간단한 가상 매출 시계열 +
128.산업용 시계열 이상감지 API 실습: ExponentialSmoothing + IsolationForest + FastAPI
ExponentialSmoothing + IsolationForest + FastAPIPOST /detect-anomaly 로sensor_name, sampling_rate, file(csv) 전송 가능.
129.Comparison of histogram-based gradient boosting classification machine, random Forest, and deep convolutional neural network for pavement raveling severity classification
https://www.sciencedirect.com/science/article/abs/pii/S0926580523000274
130.Pandas: dtype변경 (astype)
https://wikidocs.net/151412astype 메서드는 열의 요소의 dtype을 변경하는함수 입니다.dtype : 변경할 type입니다.copy : 사본을 생성할지 여부입니다.False로 할 경우 원본 데이터의 값이 변경 될 경우 원본 데이터를
131.모델(Model): Holt-Winters 계절성 기법 실습
https://woongsonvi.github.io/statistical%20analysis/SA3/
132.Residual Analysis: Plotting and Analysing Residuals
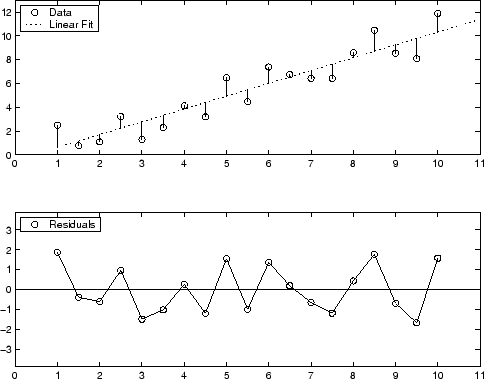
https://wikidocs.net/120321https://m.blog.naver.com/domodal/223130595694통계학 / 회귀분석:잔차(Residual): 관측값(실제 값)과 회귀 모델을 통해 얻은 예측값 사이의 차이를 말합니다. 모
133.구글 CEO가 치즈버거 제조법 이미지를 게시한 이유: '알 사람은 안다(If you know, you know)'
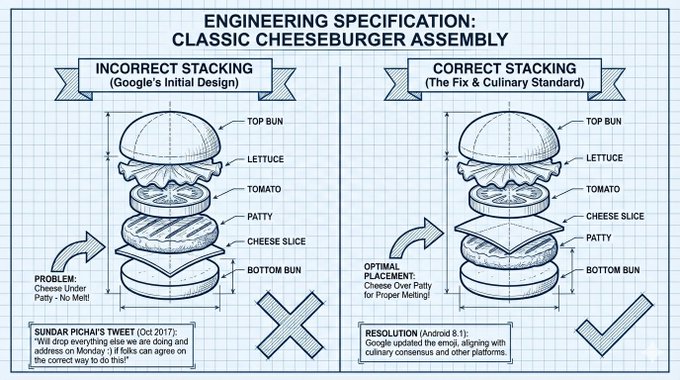
https://www.aitimes.com/news/articleView.html?idxno=204225
134.Wilson Score Interval 기반 보정 오류율(e)
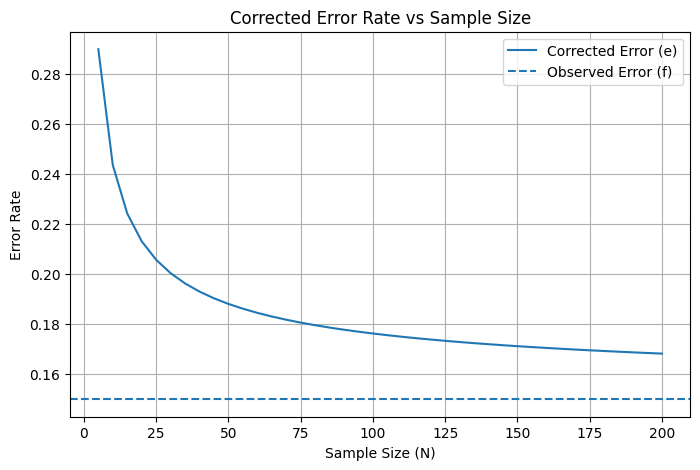
https://www.statisticshowto.com/wilson-ci/Wilson Score Interval은 비율 추정을 보다 안정적으로 만들기 위해 관측 오류율 $f$ 대신 보정 오류율 $e$ 을 사용한다.특히 표본 크기 $N$ 이 작을 때 효과가 크
135.Bayesian Estimation과 Wilson Score Interval
베이즈 추정(Bayesian Estimation)과 Wilson Score Interval은 모두 비율 추정의 신뢰도를 계산하는 방법이지만, 실제 머신러닝·통계 실무에서는 Wilson Score가 더 자주, 더 실용적으로 사용된다.베이즈 방식은 사전분포(prior)를
136.머신러닝(Machine Learning):
https://devhwi.tistory.com/category/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D#google_vignette
137.머신러닝(Machine Learning): Linear Regression(선형 회귀)
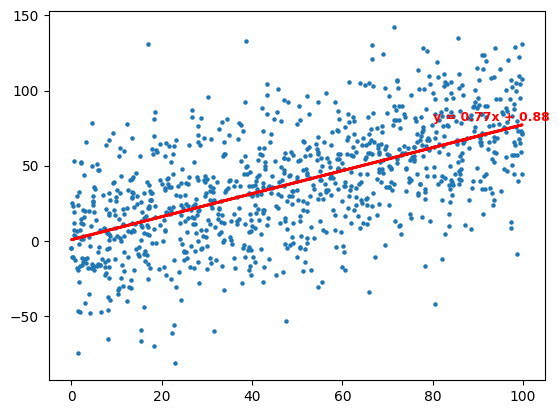
출처, 출처2AI의 복잡한 수식 뒤에는 언제나 “하나의 직선으로 세상을 설명하려는 시도”가 숨어 있다는 사실을 기억해보자.
138.다중공선성(multicollinearity): 변수 간 상관 관계와 변수 선택
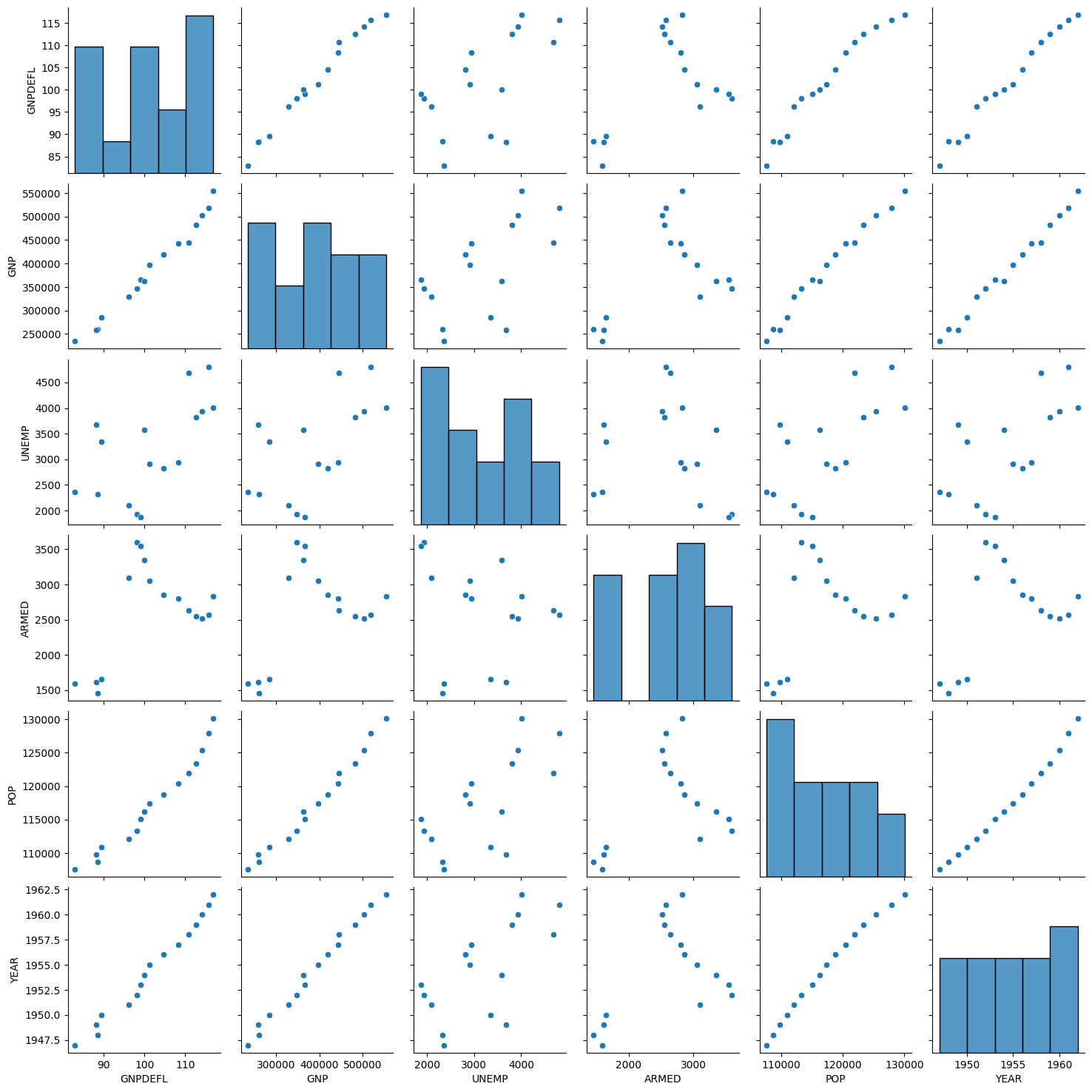
https://datascienceschool.net/03%20machine%20learning/06.04%20%EB%8B%A4%EC%A4%91%EA%B3%B5%EC%84%A0%EC%84%B1%EA%B3%BC%20%EB%B3%80%EC%88%98%20%EC%8
139.최소제곱법(Ordinary Least Squares, OLS): 최소제곱법(OLS)과 평균제곱오차(MSE)의 관계
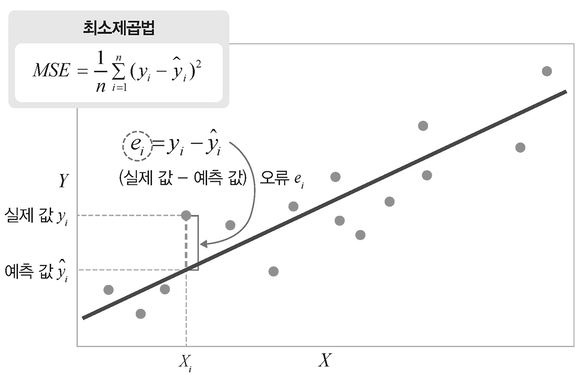
최소제곱법(Ordinary Least Squares, OLS)은 선형 회귀 모델의 파라미터를 추정하기 위해 사용되는 대표적인 최적화 기법이다. OLS의 목적은 데이터의 오차 제곱합(SSE) 또는 평균제곱오차(MSE)를 최소화하는 파라미터 조합을 찾는 것이다.한편 MSE
140.Machine Learning Math Full Roadmap
https://angeloyeo.github.io/2020/02/13/Students_t_test.html
141.OpenAI: GPT-5.2를 통해 과학과 수학 발전시키기
https://openai.com/ko-KR/index/gpt-5-2-for-science-and-math/
142.AAIF(Agentic AI Foundation)

AAIF는 리눅스 재단(Linux Foundation) 산하의 “중립적(벤더-뉴트럴) 오픈 거버넌스” 조직으로, 에이전틱 AI 생태계에서 핵심이 되는 프로토콜·형식·레퍼런스 구현체를 특정 기업 종속 없이 운영하기 위해 만들어졌습니다. (Linux Foundation)리
143.OpenAI: 언어 모델이 고백을 통해 정직성을 유지하는 방법
https://openai.com/ko-KR/index/how-confessions-can-keep-language-models-honest/ >https://cdn.openai.com/pdf/6216f8bc-187b-4bbb-8932-ba7c40c5553d/conf
144.MCP: Build an MCP server
(Windows · uv · PowerShell 기준)본 문서는 Windows 환경에서 MCP(Model Context Protocol) 서버를 설치하고, 실행 및 테스트까지 완료하는 최소 예제 흐름을 정리한다.목표는 다음 세 가지이다.MCP 서버가 정상적으로 기동되는
145.Google: Agentic Design Patterns
https://github.com/sarwarbeing-ai/Agentic_Design_Patterns/blob/main/Agentic_Design_Patterns.pdfTo my son, Bruno,who at two years old, brought a n
146.Google: Agentic Design Patterns 도서 소개

https://discuss.pytorch.kr/t/agentic-design-patterns-google-docs-424p/7661Antonio Gulli — Google CTO Office 수석 디렉터(Director), Distinguished Engin
147.모델(Model): YOLO(You Only Look Once) 시리즈 기술 진화 정리 (v1~v12)
https://blaewood.tistory.com/47YOLO는 단일 객체 탐지 모델이 아니라, “실시간 객체 탐지를 가능하게 한 설계 철학과 구현 계열”로 이해하는 것이 정확하다.공식 논문 계보: YOLOv1 ~ YOLOv4산업·커뮤니티 확장 계보: YOL
148.CSPNet : CNN의 학습능력을 향상 시킬 수 있는 새로운 Backbone
https://keyog.tistory.com/30
149.모델(Model): YOLO모델 및 버전별 차이점 분석 (~v9)
https://velog.io/@juneten/YOLO-v1v9 >https://hans-j.tistory.com/178 미디어쿼리로 반응형으로 만든거랑 더보기 기능 만든거;; 이게 그렇게 리드미에 자랑이 하고싶었나보다...진짜 가지가지하는 나 5MB이하만 허용된다길
150.Enough is not enough
https://eehoeskrap.tistory.com/category/AI%20Research%20Topic/Generative%20AI
151.Edge AI
1. 엣지 AI란? 엣지 AI는 인공지능(AI) 기술을 데이터가 발생하는 현장(=엣지, Edge)에서 바로 처리하는 기술을 말합니다. 즉, 데이터가 중앙의 클라우드 서버로 전송되어 처리되는 것이 아니라, 센서, 스마트폰, IoT 기기, CCTV 카메라 등 사용자와
152.R-CNN: R-CNN, Fast R-CNN, Faster R-CNN
https://wikidocs.net/148633R-CNN은 “금속탐지기로 바닥을 쪼개서 검사”땅을 작은 구역으로 나누고의심되는 구역을 하나씩 파보면서그 안에 뭐가 있는지 확인정확하지만 시간이 오래 걸립니다.YOLO는 “드론으로 한 번 촬영하고 지도에 표시”한
153.Computer Vision: IOU (Intersection Over Union)와 mAP (mean Average Precision)
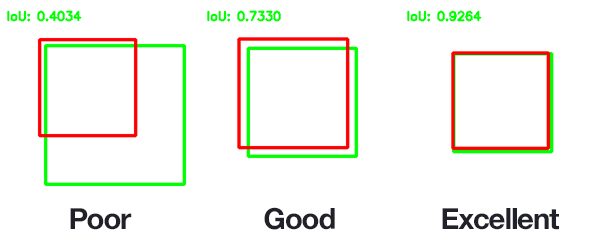
https://oniss.tistory.com/36 IOU (Intersection Over Union) IOU는 모델이 얼마나 object detection을 정확히 했는지(=예측 박스가 GT 박스를 얼마나 잘 맞췄는지) 측정하는 지표다. HOG + 선형 SVM
154.YOLO: Car · Truck · Person Object Detection Dataset
페이지 정보Car Object DetectionYOLO Object Detection Playground | 1000+ Videos링크https://www.kaggle.com/datasets(※ Kaggle 내 “Car Object Detection / YOL
155.텐서(Tensor)의 종류

텐서는 단순한 숫자 묶음이 아닙니다. 수학적 용어, 프로그래밍 구현체, 딥러닝의 문맥이 합쳐진 데이터 단위입니다.구현적 정의: CPU/GPU에서 계산 가능한 다차원 배열(Array).실무적 정의: 이미지, 음성, 텍스트 등 모든 데이터를 신경망이 이해할 수 있도록 좌표
156.텐서의 구조적 특성과 차원 조작(Transpose/Permute)
컴퓨터 비전 모델(CNN)이 학습하려면 모든 데이터를 숫자 묶음인 '텐서'로 변환해야 합니다. 자연어 처리가 단어를 벡터로 변환하는 복잡한 과정(Embedding)을 거치는 것과 달리, 이미지는 태생 자체가 격자 구조의 수치 데이터입니다.2D Tensor (Matrix
157.채널톡 탄생 비하인드 스토리: How They Use AI Tools to Work Smarter (w/ Cursor, MCP, Figma, OpenAI Codex)
!youtubeoEbtUeYSLKE!youtubePHWO5TKzIs4
158.중력과 싸우지 말자(Don’t fight gravity): Cursor를 더 똑똑하게 사용하고 싶은 분들을 위한 팁 12개
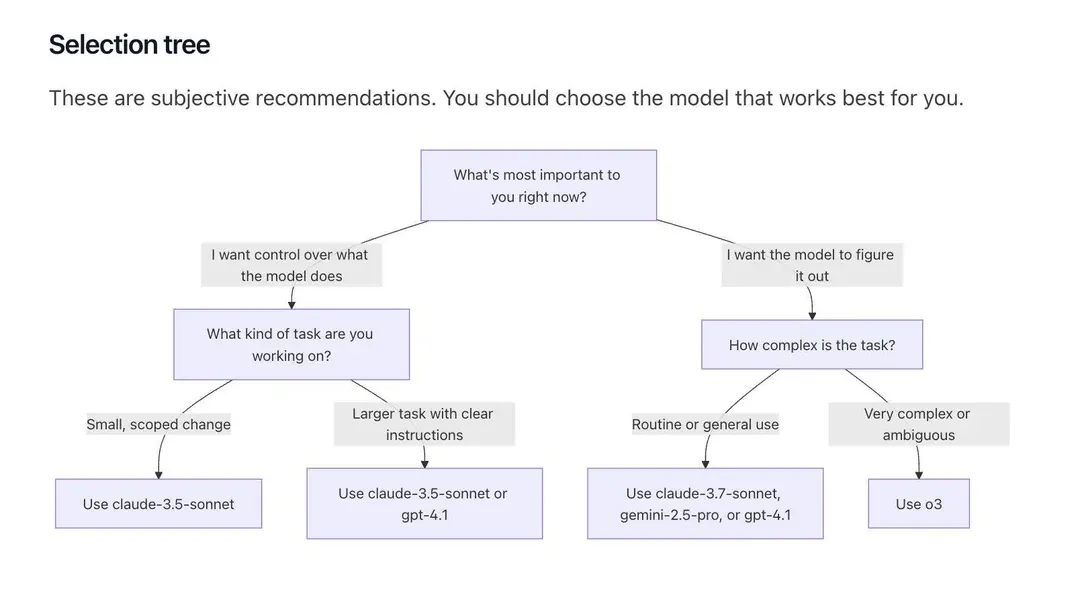
https://www.stdy.blog/12-tips-for-smarter-cursor-usage/본인이 잘 하고 익숙한 방법대로 더 많은 제약을 걸고 명령을 내리는 대신, 명확한 목표만 제시한 채 현존하는 최고의 모델이 어디까지 해낼 수 있는지 확인하는 태도
159.Cursor 써봤는데 프로그래밍 배우려는 의욕이 사라졌어요: 헬스장에서 PT가 대신 운동해 준다고 해서 내 근육이 생기는 건 아니에요
https://www.reddit.com/r/learnprogramming/comments/1j6k7f8/i_just_tried_cursor_my_motivation_to_learn/?tl=ko최근에 React를 사용하는 주니어 웹 개발자로 취업했어요. 자바스
160.데이터 라벨링: 'AI계 인형 눈 붙이기'
'AI계 인형 눈 붙이기' 데이터 라벨링 뭐길래… 메타도 13조 투자 추진: https://www.chosun.com/economy/tech_it/2025/06/10/NVCMHFALCNHHHHKWPN6Q6227SA/ https://www.comworl
161.이미지 캡셔닝(Image Captioning)

https://wikidocs.net/145420
162.YOLO: 객체 탐지 프로젝트 (저용량, CPU Only, Windows)

YOLO11 객체 탐지 프로젝트: 학습부터 추론까지 본 문서는 인공지능 모델의 이론적 학습 구조와 실제 업무 환경에서의 적용 과정을 단계별로 통합하여 설명합니다. 1단계: 데이터 준비 및 환경 구축 (Setup & Data) AI가 학습할 수 있는 환경을 만들고
163.Machine Learning과 Deep Learning의 신경망 계층 구조도 (ANN 기반 모델 계보 정리)
https://dbrang.tistory.com/1537
164.YOLO: 모델 인스턴스 메서드
Ultralytics YOLO 객체(모델 인스턴스)에서 사용할 수 있는 메서드(함수) 정리모델을 새로운 데이터셋에 맞춰 훈련시키는 함수입니다.주요 파라미터data: 데이터셋 설정 파일(.yaml) 경로epochs: 학습 반복 횟수imgsz: 입력 이미지 크기 (기본 6
165.MCP: FastMCP
https://gofastmcp.com/getting-started/welcome
166.Agent: LLM에이전트가 도구를 호출하는 방법
https://tmdqja75.github.io/llm/2025-08-01-llm-agent-tool-calling/
167.OpenAI: 멀티태스킹 기능
지금 보이는 “멀티태스킹 — 기다리는 동안 ChatGPT에게 다른 걸 물어보세요” 같은 메시지는 최근에 ChatGPT에 도입된 기능입니다. 이 기능은 긴 처리(예: Deep Research 또는 복잡한 응답 생성) 동안 대기하지 않고 동시에 다른 질문을 할 수 있게 허
168.Google: Antigravity
https://codelabs.developers.google.com/getting-started-google-antigravity?hl=kohttps://goddaehee.tistory.com/424https://yozm.wishket.co
169.AI 기본법: 인공지능 발전과 신뢰 기반 조성 등에 관한 기본법

https://yozm.wishket.com/magazine/detail/3568/?utmsource=stibee&utmmedium=email&utmcampaign=newsletteryozm&utm_content=contents 인공지능 발전과 신뢰 기반 조성 등에
170.Google: 제미나이 디퓨전(Gemini Diffusion)
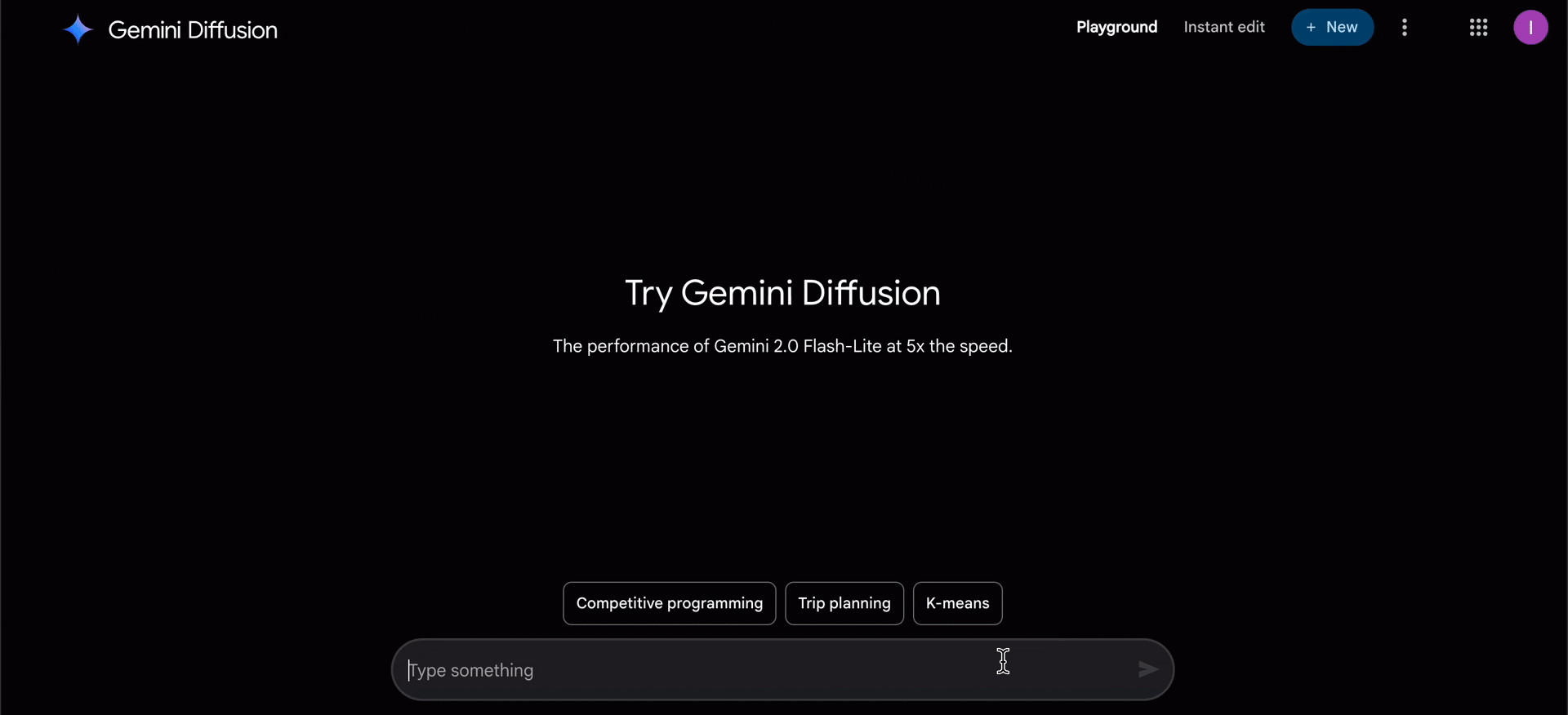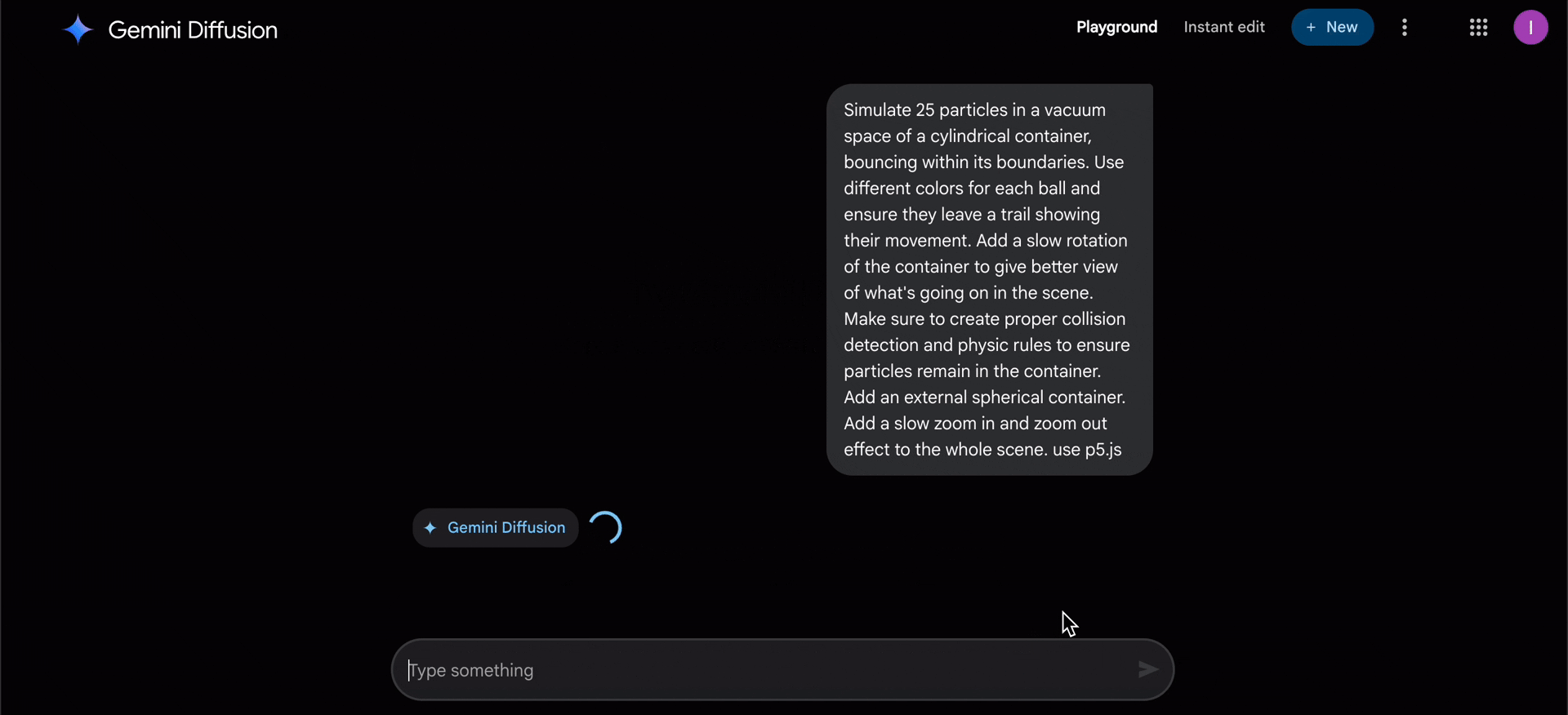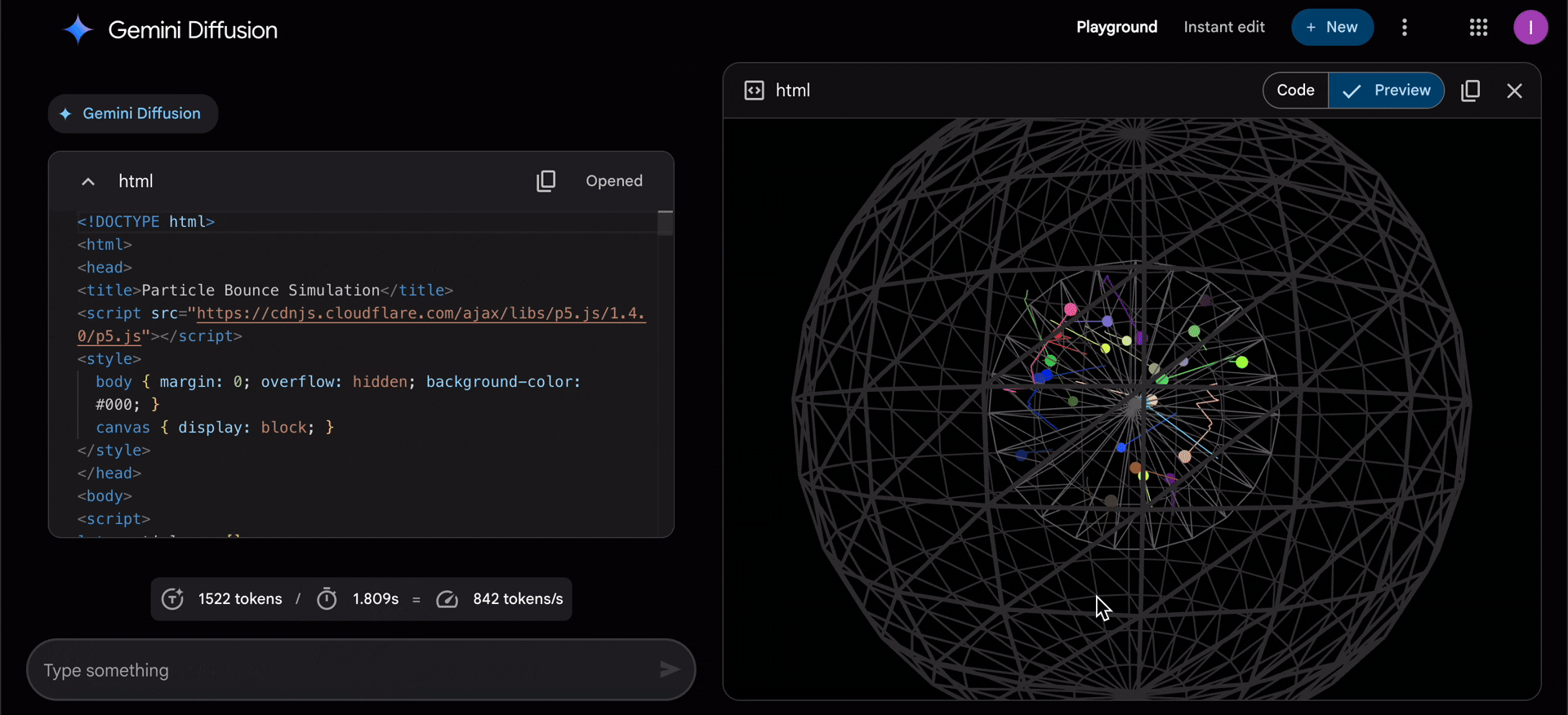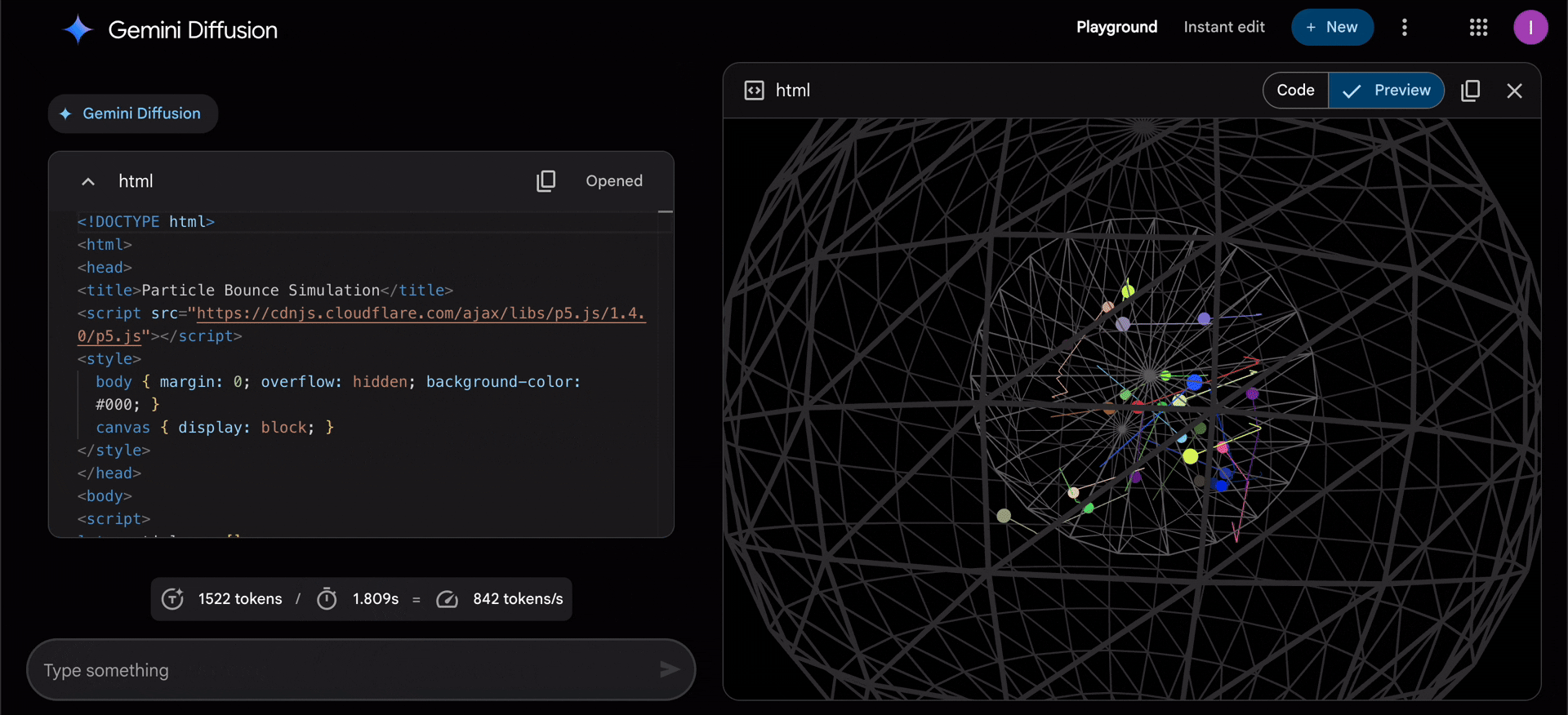
https://contents.premium.naver.com/banya/banyacompany/contents/250602100713286cxhttps://www.aitimes.com
171.Qdrant: Vector DB
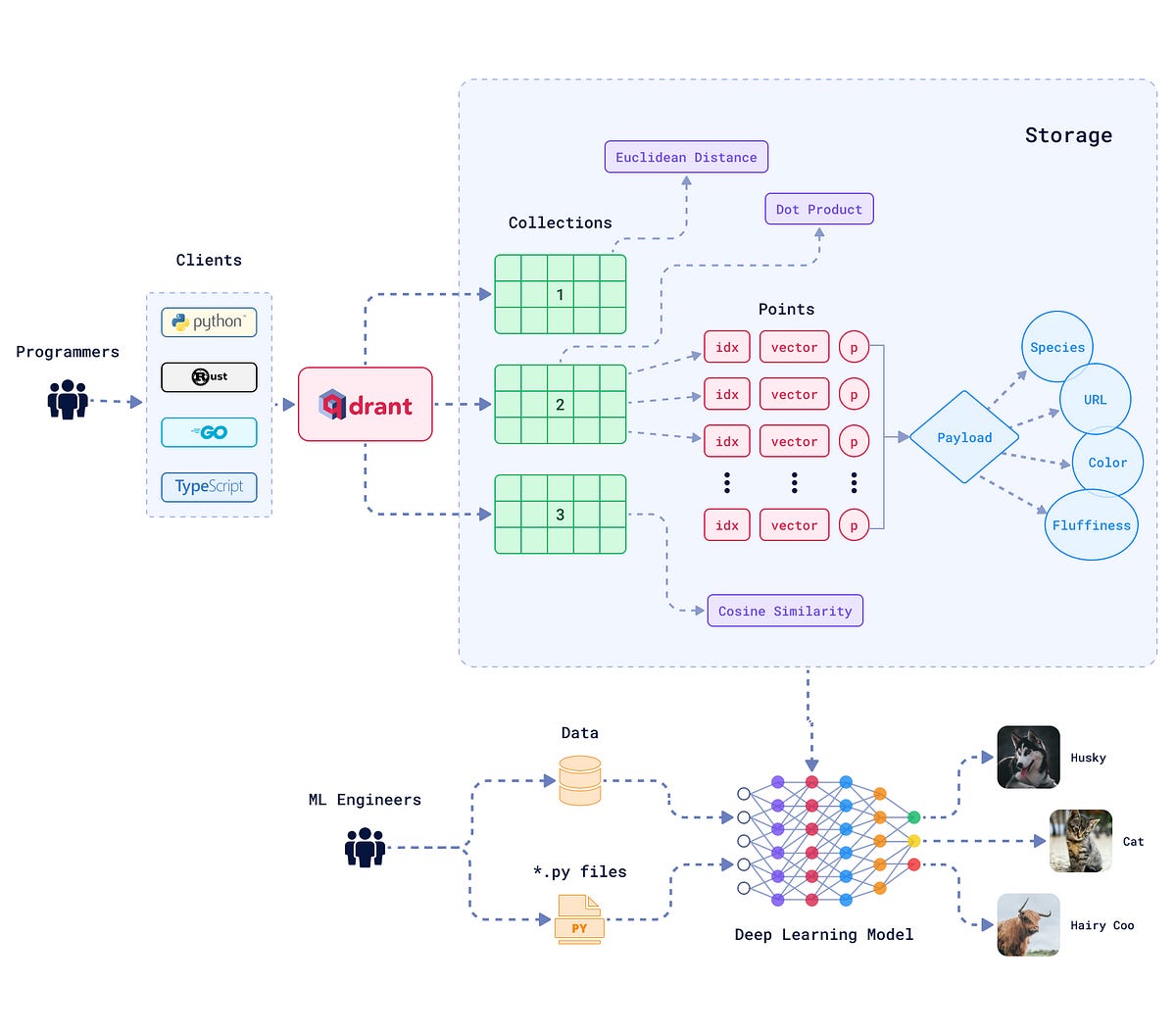
https://devocean.sk.com/blog/techBoardDetail.do?ID=166910&boardType=techBlog
172.MCP Server: stdio와 SSE 방식 차이점
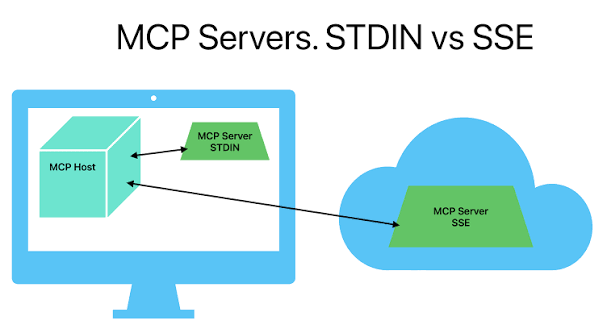
https://blog.choonzang.com/it/python/3341/
173.MCP Proxy: 서버 트랜스포트 간 전환을 위한 필수 도구
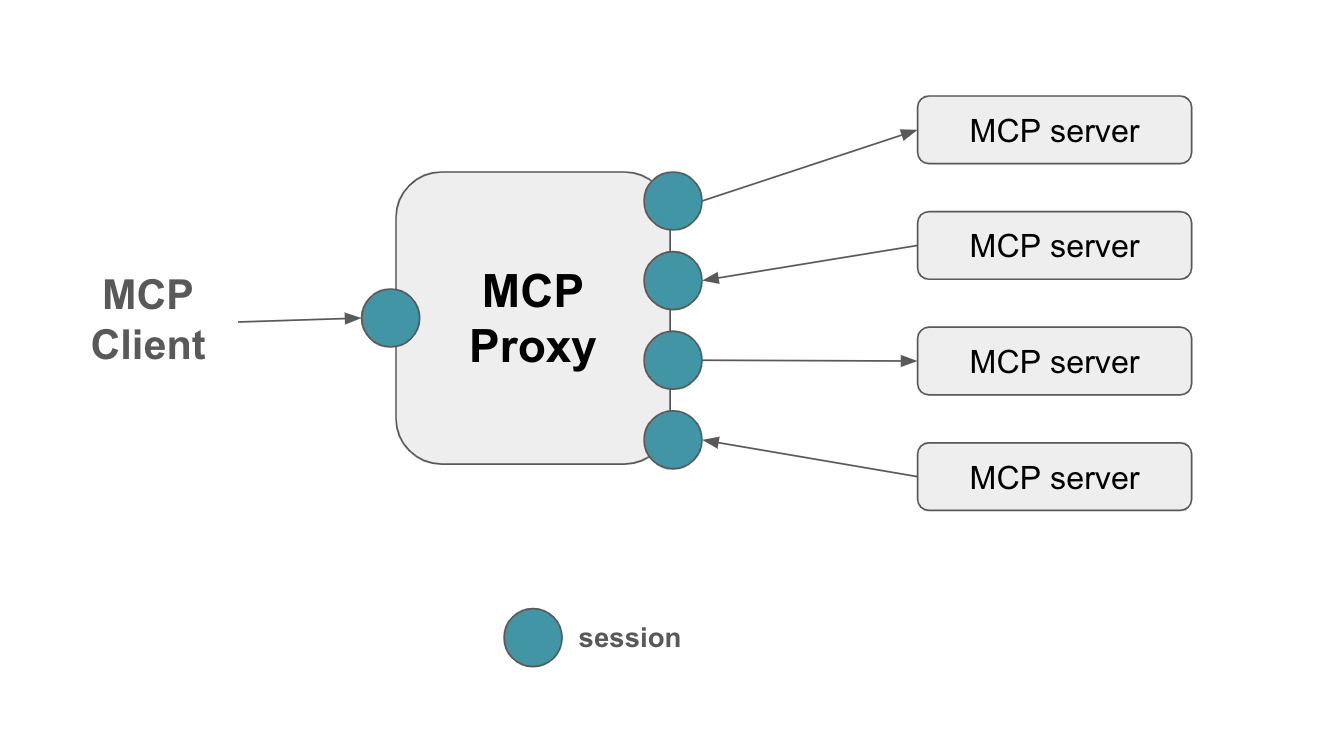
https://blog.choonzang.com/it/python/3341/
174.OpenClaw: 자기 개선적 자율 AI Agents
https://blog.naver.com/techref/224168138425?trackingCode=rss > https://ksmin.medium.com/%EC%9A%94%EC%A6%98-openclaw%EA%B0%80-%ED%95%AB%ED%95%9C%EB%8D%B0%EC%9A%94-e3daea4bc422 !youtube[CsHMm6t1QXI] ...
175.Anthropic: 16개 Claude Opus 4.6 AI 에이전트로 자율적으로 C 컴파일러 작성
앤트로픽의 Claude Opus 4.6 모델을 16개의 에이전트(team)로 병렬 동작하게 해서, Rust 기반 C 컴파일러를 자율적으로 개발했고, 이 컴파일러로 Linux 커널, Doom 등 실제 소프트웨어를 빌드할 수 있는 수준에 도달했습니다.왜 “저수준부터 다시
176.LLM: LLM(Large Langage Model) 작동 방식 및 원리
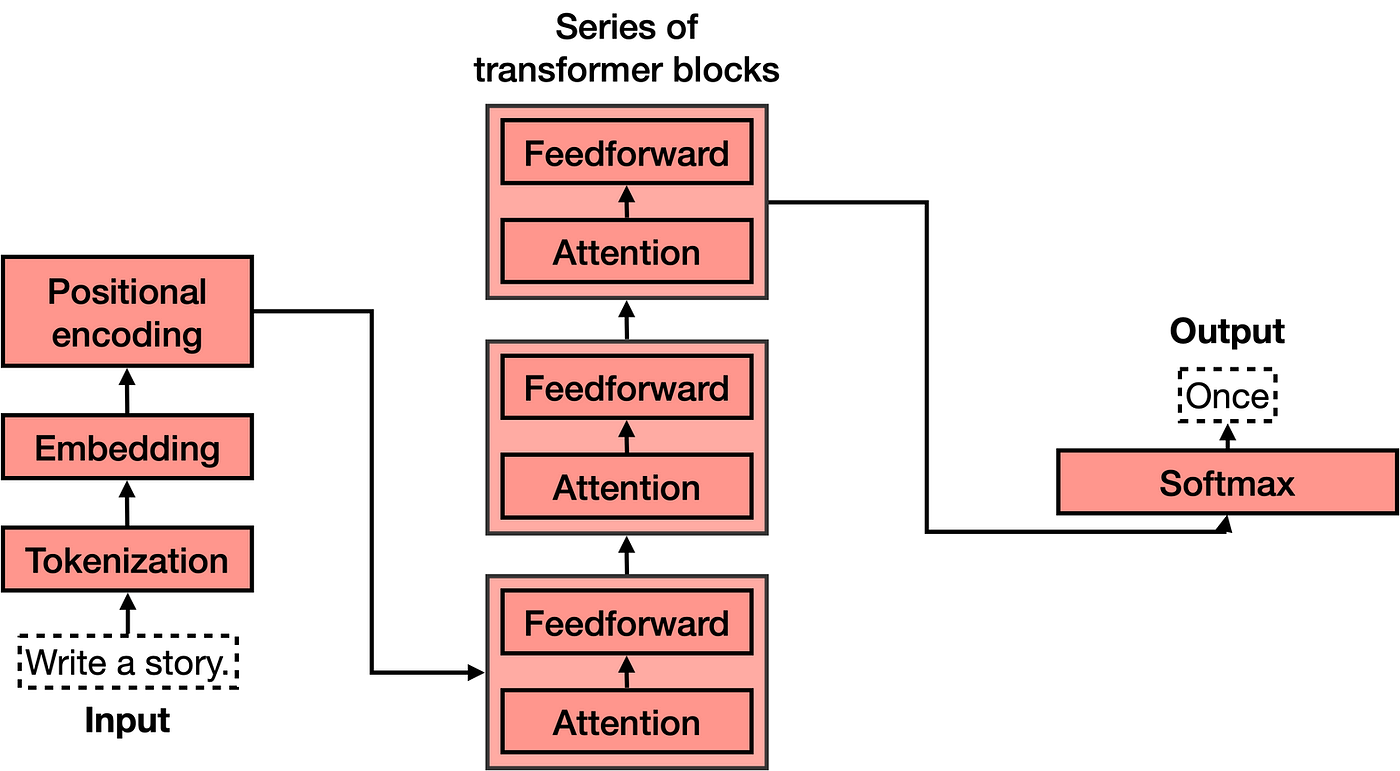
https://makenow90.tistory.com/59
177.LLM: English vs Non-English in LLMs
English and non-English languages differ in tokenization structure and efficiency, but multilingual LLMs align them within a shared embedding space, w
178.MCP: LLM(대형 언어 모델)이 이 API를 '언제, 왜, 어떻게' 써야 할지 스스로 판단하게 만드는 연결점
MCP: LLM(대형 언어 모델)이 이 API를 '언제, 왜, 어떻게' 써야 할지 스스로 판단하게 만드는 연결점 실무적인 관점에서 매우 날카로운 질문입니다. "결국 이것도 다 API 통신인데, 왜 굳이 MCP(Model Context Protocol) 같은 연결 규격
179.벡터(Vector)와 텐서(Tensor) 그리고 랭크( Rank)

벡터와 텐서는 물리량과 데이터 구조를 표현하는 수학적 객체입니다. 텐서(Tensor)는 스칼라, 벡터, 행렬을 모두 포함하는 가장 일반적이고 다차원적인 개념입니다.컴퓨터/딥러닝: 데이터를 나열한 1차원 배열(1D Array)을 의미하며, 이를 1차원 텐서(1D Tens
180.Neural Networks and Deep Learning (Nielsen)
https://eng.libretexts.org/Bookshelves/Computer_Science/Applied_Programming/Neural_Networks_and_Deep_Learning\_(Nielsen)/02%3A_How_the_Backpropag
181.Gemini Embedding 2: Our first natively multimodal embedding model
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/New modalities and flexible output dimensionsThe model
182.임베딩(Embedding)과 차원(Dimension)
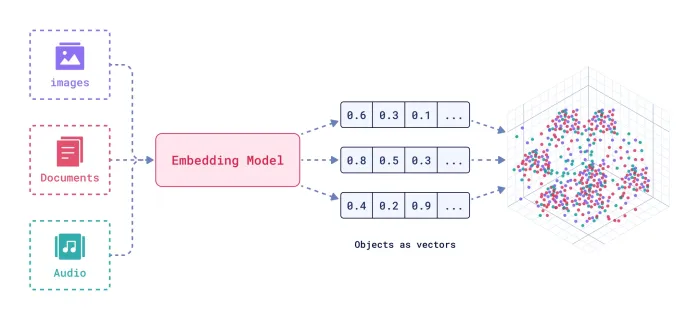
임베딩: 데이터(텍스트, 이미지 등)를 수치적 벡터로 변환하여 의미적 유사성을 측정할 수 있게 하는 기법.차원: 임베딩 벡터의 길이로, 데이터의 세부적인 특징을 표현할 수 있는 크기를 나타냄.차원의 중요성: 차원이 높으면 더 많은 정보를 담을 수 있지만, 계산 비용이
183.학습/트레이닝(Training) 또는 최적화(Optimization: 편미분 → 전미분 → 그래디언트 → 경사하강법 → 역전파
질문하신 과정을 '모델링(Modeling)'이라고 불러도 무방하지만, 더 정확하게는 '모델(구조)'과 '학습(메커니즘)'이 합쳐진 형태라고 이해하시면 완벽합니다.정의: 현실의 복잡한 문제를 수학적 함수($f(x, y, w)$)로 설계하는 단계입니다.포함: 레이어를 몇
184.Cross-Validation in Time Series
https://medium.com/@pacosun/respect-the-order-cross-validation-in-time-series-7d12beab79a1
185.CLIP: RAG + Vector DB 이미지 검색 흐름
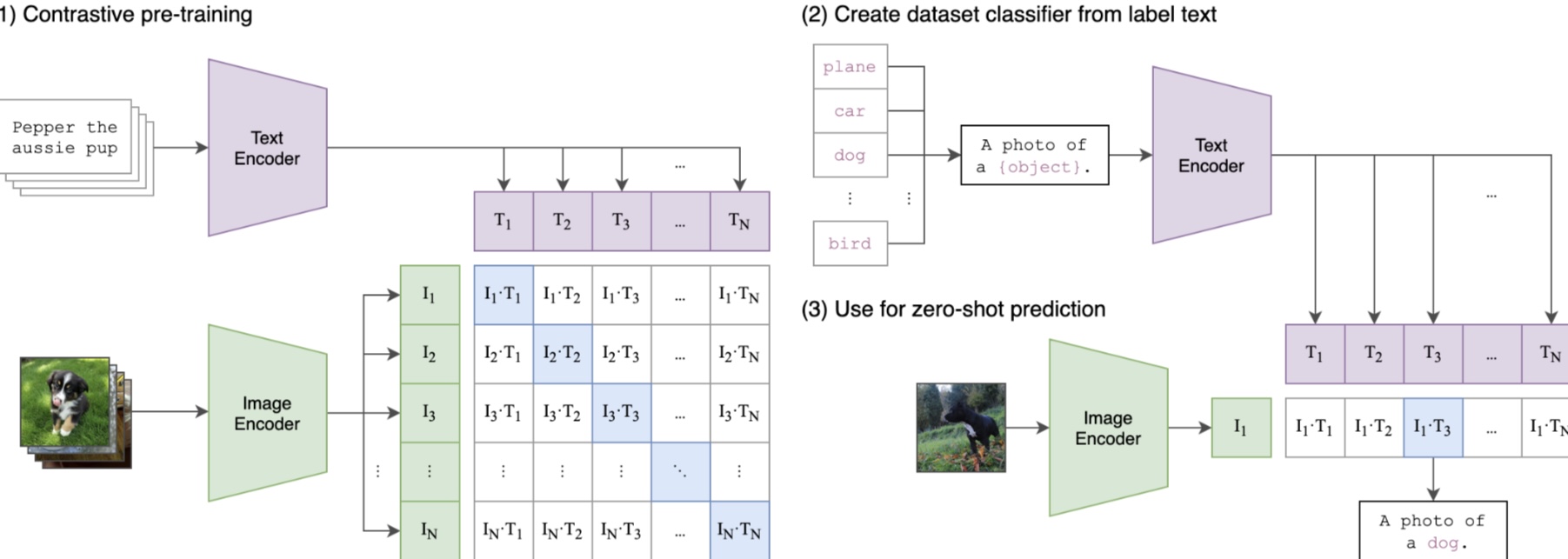
"바나나를 그려줘" 요청이 들어왔을 때, 이미지 벡터 DB에서 바나나를 찾는 전체 과정이야.사용자 입력 → 텍스트 임베딩 → 벡터 유사도 검색 → 이미지 반환"바나나를 그려줘" 입력이 들어오면 텍스트 전처리로 "banana" 또는 "바나나" 키워드를 추출하고, CLIP
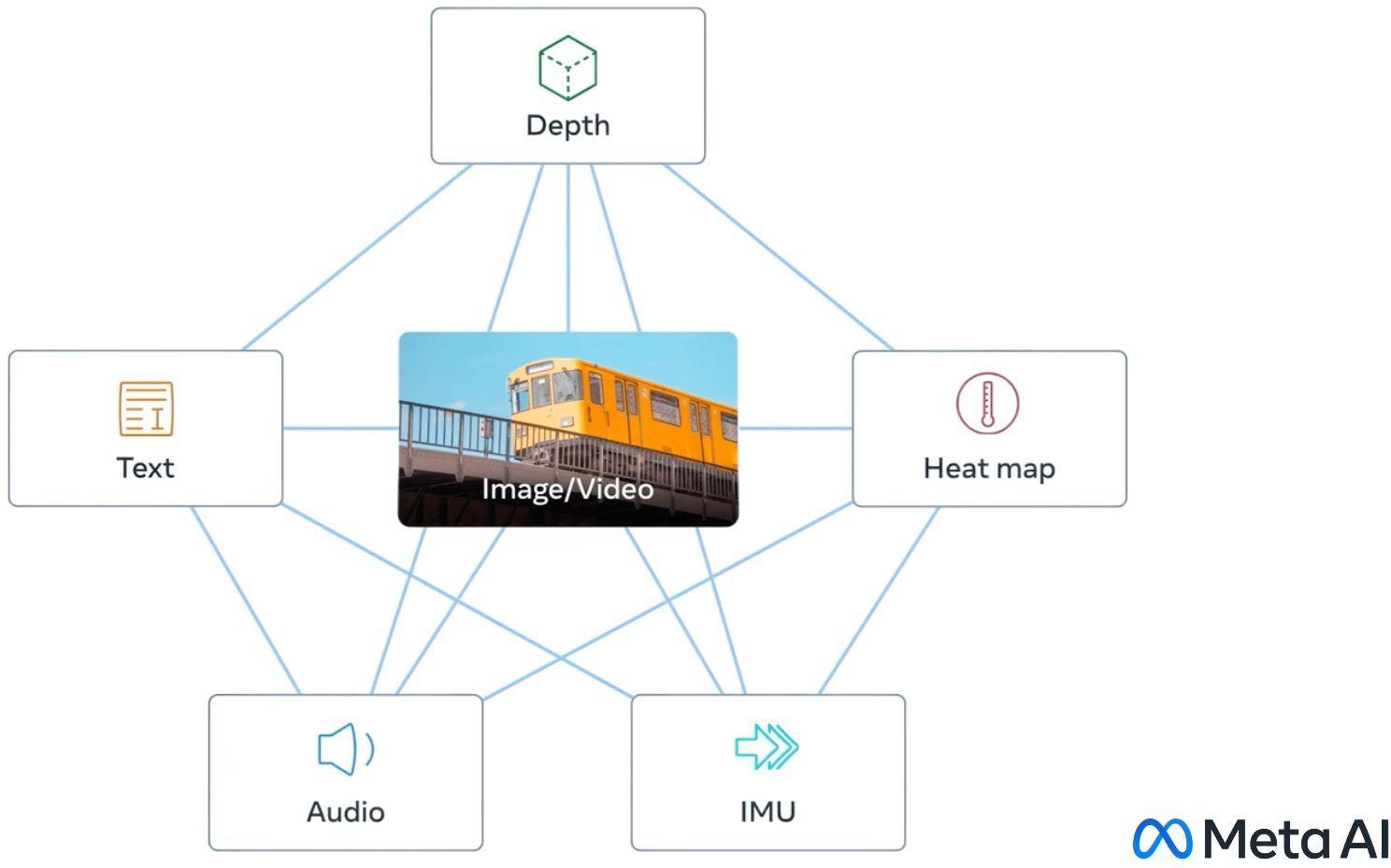
186.멀티모달 임베딩 검색의 발전: CLIP에서 ColPali까지
“바나나를 그려줘”라는 텍스트 쿼리로 이미지를 검색하는 기술은 CLIP의 등장 이후 빠르게 발전했다. 텍스트와 이미지를 동일한 임베딩 공간에 매핑하는 기본 아이디어에서 출발해, 현재는 멀티모달 확장, 검색 파이프라인 정교화, 패치 단위 세밀한 매칭까지 진화했다.