AI가 활용하는 주요 학문 분야
현대 AI는 10~15개 이상의 학문 분야가 융합된 기술입니다.
특히 멀티모달 AI(언어+이미지+소리+행동)는
- 컴퓨터공학
- 수학
- 언어학
- 인지과학
- 철학
- 심리학
을 동시에 사용합니다.
-
Computer Science (컴퓨터공학)
- 알고리즘, 데이터 구조, 프로그래밍, 시스템 설계
-
Mathematics (수학)
- 선형대수(Linear Algebra): 행렬 연산, 벡터 공간
- 확률·통계(Probability & Statistics): 예측, 불확실성 처리
- 미적분(Calculus): 최적화, 경사하강법(Gradient Descent)
-
Electrical & Electronic Engineering (전기·전자공학)
- 센서, 하드웨어, GPU/TPU 설계
-
Data Science (데이터과학)
- 데이터 수집, 정제, 분석, 시각화
-
Linguistics (언어학)
- 자연어 처리(NLP), 의미론(Semantics), 구문론(Syntax)
-
Cognitive Science (인지과학)
- 인간의 학습·기억·문제 해결 방식 연구
-
Neuroscience (신경과학)
- 뇌의 뉴런 구조와 신호 전달 원리 → 신경망 설계에 영감
-
Psychology (심리학)
- 인간 행동 예측, 사용자 경험(UX) 설계
-
Philosophy (철학)
- 윤리(Ethics), 논리학(Logic), 인식론(Epistemology)
-
Pedagogy / Education (교육학)
- 학습 이론, 교육 방법 → AI 학습 알고리즘 설계에 적용
-
Robotics (로보틱스)
- 물리적 환경에서 AI를 적용하는 기술
-
Economics & Decision Science (경제·의사결정학)
- 최적화, 자원 배분, 게임이론(Game Theory)
-
Art & Design (예술·디자인)
- 시각적 창작, 인터페이스 디자인, 창의적 AI
인공 지능(AI)은 인간이 아닌 동물과 인간이 보여주는 지능과 달리 기계가 보여주는 지능(정보를 인식, 합성 및 추론)입니다. 이것이 수행되는 작업의 예로는 음성 인식, 컴퓨터 비전, (자연) 언어 간의 번역 및 기타 입력 매핑이 있습니다.
AI 애플리케이션에는 고급 웹 검색 엔진(예: Google 검색), 추천 시스템(YouTube, Amazon 및 Netflix에서 사용), 사람의 음성 이해(예: Siri 및 Alexa), 자율 주행 자동차(예: Waymo), 자동화된 의사 결정, 전략적 게임 시스템(예: chess and Go)에서 최고 수준의 게임을 만들고 경쟁합니다. 기계의 능력이 향상됨에 따라 "지능"이 필요한 것으로 간주되는 작업은 종종 AI 효과로 알려진 현상인 AI의 정의에서 제외됩니다. 예를 들어, 광학 문자 인식은 일상적인 기술이 되어 AI로 간주되는 것에서 자주 제외됩니다.
인공 지능은 1956년에 학문 분야로 설립되었으며 그 이후 몇 년 동안 여러 낙관론의 물결을 겪었고 실망과 자금 손실("AI 겨울"로 알려짐), 새로운 접근 방식, 성공 및 재투자가 뒤따랐습니다. AI 연구는 창립 이래 뇌 시뮬레이션, 인간 문제 해결 모델링, 형식 논리, 대규모 지식 데이터베이스 및 동물 행동 모방을 포함하여 다양한 접근 방식을 시도하고 폐기했습니다. 21세기의 첫 10년 동안 고도의 수학적-통계적 기계 학습이 이 분야를 지배했으며 이 기술은 매우 성공적인 것으로 입증되어 산업 및 학계 전반에 걸쳐 많은 어려운 문제를 해결하는 데 도움이 되었습니다.
AI 연구의 다양한 하위 분야는 특정 목표와 특정 도구의 사용을 중심으로 이루어집니다. AI 연구의 전통적인 목표에는 추론, 지식 표현, 계획, 학습, 자연어 처리, 지각, 물체를 이동하고 조작하는 능력이 포함됩니다. 일반 지능(임의의 문제를 해결하는 능력)은 이 분야의 장기 목표 중 하나입니다. 이러한 문제를 해결하기 위해 AI 연구자들은 검색 및 수학적 최적화, 형식 논리, 인공 신경망, 통계, 확률 및 경제학에 기반한 방법을 포함한 광범위한 문제 해결 기술을 채택하고 통합했습니다. AI는 또한 컴퓨터 과학, 심리학, 언어학, 철학 및 기타 여러 분야를 활용합니다.
이 분야는 인간의 지능이 "기계가 그것을 시뮬레이션하도록 만들 수 있을 정도로 정확하게 설명될 수 있다"는 가정에 기반을 두고 있습니다. 이것은 마음에 대한 철학적 논쟁과 인간과 같은 지능을 부여받은 인공 존재를 만드는 윤리적 결과를 제기했습니다. 이러한 문제는 고대부터 신화, 허구 및 철학에 의해 이전에 탐구되었습니다. 이후 컴퓨터 과학자와 철학자들은 인공지능의 합리적인 능력이 유익한 목표를 향하지 않는다면 인류에게 실존적 위험이 될 수 있다고 제안했습니다.
1. History
Figure 1. 인공 지능을 갖춘 고대 신화의 자동인형 탈로스를 묘사한 크레타 섬의 실버 디드라크마
지능을 가진 인공 존재는 고대에 스토리텔링 장치로 등장했으며 Mary Shelley의 Frankenstein이나 Karel Čapek의 R.U.R. 이러한 캐릭터와 그들의 운명은 현재 인공 지능 윤리에서 논의되는 것과 동일한 많은 문제를 제기했습니다.
기계적 또는 "형식적인" 추론에 대한 연구는 고대의 철학자와 수학자로부터 시작되었습니다. 수학적 논리에 대한 연구는 Alan Turing의 계산 이론으로 직접 이어졌습니다. 이 이론은 기계가 "0"과 "1"과 같은 간단한 기호를 섞음으로써 상상할 수 있는 모든 수학적 추론 행위를 시뮬레이션할 수 있다고 제안했습니다. 디지털 컴퓨터가 모든 형식적 추론 과정을 시뮬레이션할 수 있다는 이러한 통찰은 Church-Turing 논문으로 알려져 있습니다. 이는 신경 생물학, 정보 이론 및 사이버네틱스의 동시 발견과 함께 연구자들이 전자 두뇌를 구축할 가능성을 고려하도록 이끌었습니다. 현재 일반적으로 AI로 인식되는 첫 번째 작업은 McCullouch와 Pitts의 1943년 Turing-complete "artificial neurons"에 대한 formal design입니다.
1950년대에 기계 지능을 달성하는 방법에 대한 두 가지 비전이 나타났습니다. Symbolic AI 또는 GOFAI(Good Old-Fashioned Artificial Intelligence)로 알려진 한 가지 비전은 컴퓨터를 사용하여 세계에 대해 추론할 수 있는 세계와 시스템의 상징적 표현을 만드는 것이었습니다. 지지자에는 Allen Newell, Herbert A. Simon 및 Marvin Minsky가 포함되었습니다. 이 접근 방식과 밀접한 관련이 있는 "휴리스틱 검색" 접근 방식은 지능을 답에 대한 가능성의 공간을 탐색하는 문제에 비유했습니다. 연결주의 접근 방식으로 알려진 두 번째 비전은 학습을 통해 지능을 달성하고자 했습니다.
이 접근 방식의 지지자 중 특히 Frank Rosenblatt는 뉴런 연결에서 영감을 받은 방식으로 퍼셉트론을 연결하려고 했습니다. James Manyika와 다른 사람들은 마음(Symbolic AI)과 뇌(connectionist)에 대한 두 가지 접근 방식을 비교했습니다. Manyika는 부분적으로 Descartes, Boole, Gottlob Frege, Bertrand Russell 등의 지적 전통과의 연결로 인해 상징적 접근이 이 기간에 인공 지능에 대한 추진을 지배했다고 주장합니다. 사이버네틱스 또는 인공 신경망에 기반한 연결주의적 접근 방식은 배경으로 밀려났지만 최근 수십 년 동안 새로운 명성을 얻었습니다.
AI 연구 분야는 1956년 Dartmouth College의 워크숍에서 탄생했습니다. 참석자들은 AI 연구의 창립자이자 리더가 되었습니다. 그들과 그들의 학생들은 언론이 "놀라운" 것으로 묘사한 프로그램을 제작했습니다. 컴퓨터는 체커 전략을 배우고, 대수학의 단어 문제를 풀고, 논리 정리를 증명하고, 영어로 말했습니다. 1960년대 중반까지 미국의 연구는 국방부에서 막대한 자금을 지원받았고 전 세계에 연구소가 설립되었습니다.
1960년대와 1970년대의 연구원들은 상징적 접근 방식이 결국 인공 일반 지능을 갖춘 기계를 만드는 데 성공할 것이라고 확신했고 이것이 그들의 분야의 목표라고 생각했습니다. Herbert Simon은 "기계는 20년 이내에 사람이 할 수 있는 모든 일을 할 수 있게 될 것"이라고 예측했습니다. 마빈 민스키는 "한 세대 안에 ... '인공 지능'을 만드는 문제가 실질적으로 해결될 것"이라고 썼습니다. 그들은 나머지 작업 중 일부의 어려움을 인식하지 못했습니다. 진전이 둔화되었고 1974년 Sir James Lighthill 의 비판과 더 생산적인 프로젝트에 자금을 지원하라는 미국 의회의 지속적인 압력에 대응하여 미국과 영국 정부는 AI에 대한 탐색적 연구를 중단했습니다. 향후 몇 년은 AI 프로젝트에 대한 자금 조달이 어려운 기간인 "AI 겨울"이라고 불릴 것입니다.
1980년대 초, 인간 전문가의 지식과 분석 기술을 시뮬레이션한 AI 프로그램의 한 형태인 전문가 시스템의 상업적 성공으로 AI 연구가 부활했습니다. 1985년까지 AI 시장은 10억 달러에 달했습니다. 동시에 일본의 5세대 컴퓨터 프로젝트는 미국과 영국 정부가 학술 연구를 위한 자금을 복원하도록 영감을 주었습니다. 그러나 1987년 Lisp Machine 시장의 붕괴를 시작으로 AI는 다시 한 번 평판이 나빠졌고 두 번째로 오래 지속되는 겨울이 시작되었습니다.
많은 연구자들은 상징적 접근이 인간 인지의 모든 과정, 특히 지각, 로봇 공학, 학습 및 패턴 인식을 모방할 수 있을지 의심하기 시작했습니다. 많은 연구자들이 특정 AI 문제에 대한 "하위 기호" 접근 방식을 조사하기 시작했습니다. 로드니 브룩스(Rodney Brooks)와 같은 로보틱스 연구자들은 상징적 AI를 거부하고 로봇이 환경을 이동하고 생존하고 학습할 수 있도록 하는 기본적인 엔지니어링 문제에 집중했습니다. 신경망과 "연결주의"에 대한 관심은 1980년대 중반에 Geoffrey Hinton, David Rumelhart 및 다른 사람들에 의해 되살아났습니다. 소프트 컴퓨팅 도구는 신경망, 퍼지 시스템, 그레이 시스템 이론, 진화 계산 및 통계 또는 수학적 최적화에서 가져온 많은 도구와 같은 1980년대에 개발되었습니다.
AI는 특정 문제에 대한 구체적인 해결책을 찾아냄으로써 1990년대 후반과 21세기 초반에 점차 명성을 되찾았습니다. 좁은 초점을 통해 연구자는 검증 가능한 결과를 생성하고 더 많은 수학적 방법을 활용하며 다른 분야(예: 통계, 경제 및 수학)와 협력할 수 있었습니다. 2000년까지 AI 연구자들이 개발한 솔루션은 널리 사용되었지만 1990년대에는 "인공 지능"으로 거의 기술되지 않았습니다.
더 빠른 컴퓨터, 알고리즘 개선 및 대량의 데이터에 대한 액세스는 기계 학습 및 인식의 발전을 가능하게 했습니다. 데이터에 굶주린 딥 러닝 방법은 2012년경 정확도 벤치마크를 지배하기 시작했습니다.
Bloomberg의 Jack Clark에 따르면, 2015년은 Google 내에서 AI를 사용하는 소프트웨어 프로젝트의 수가 2012년의 "산발적인 사용"에서 2,700개 이상의 프로젝트로 증가하면서 인공 지능의 획기적인 해였습니다. 그는 이것이 클라우드 컴퓨팅 인프라의 증가와 연구 도구 및 데이터 세트의 증가로 인해 저렴한 신경망의 증가 때문이라고 생각합니다. 2017년 설문 조사에서 5개 회사 중 1개 회사는 "일부 오퍼링 또는 프로세스에 AI를 통합"했다고 보고했습니다. 2015-2019년에 AI에 대한 연구의 양(총 출판물 기준)이 50% 증가했습니다.
수많은 학술 연구자들은 AI가 더 이상 다재다능하고 완전히 지능적인 기계를 만드는 원래 목표를 추구하지 않는다는 점을 우려했습니다. 현재 연구의 대부분은 특정 문제를 해결하는 데 압도적으로 사용되는 통계적 AI와 딥 러닝과 같은 매우 성공적인 기술을 포함합니다. 이러한 우려는 2010년대까지 자금이 충분한 여러 기관이 있는 인공 일반 지능(또는 "AGI")의 하위 분야로 이어졌습니다.
2. Goals
지능을 시뮬레이션(또는 생성)하는 일반적인 문제는 하위 문제로 분류되었습니다. 이들은 연구원이 지능형 시스템이 표시할 것으로 기대하는 특정 특성 또는 기능으로 구성됩니다. 아래에 설명된 특성이 가장 주목을 받았습니다.
AI는 인간의 행동을 읽고 그 결과를 지능형 시스템 개발에 활용함으로써 달성할 수 있습니다. 예를 들어, 그들은 특정 상황에서 배우고 결정을 내리고 행동합니다. 간단한 작업으로 문제를 해결하면서 인간을 관찰하고 그 결과를 지능형 시스템 개발에 사용합니다.
인공 지능의 전반적인 연구 목표는 컴퓨터와 기계가 지능적으로 작동할 수 있는 기술을 만드는 것입니다. 지능을 시뮬레이션(또는 생성)하는 일반적인 문제는 하위 문제로 나뉩니다.
아래에 설명된 증상이 가장 주의를 기울입니다. 여기에는 연구원이 지능형 시스템이 보여줄 것으로 기대하는 특별한 특성이나 능력이 포함됩니다. Eric Sandwell은 주어진 상황에 적절하고 적용 가능한 계획 및 학습을 강조합니다.
2.1. Reasoning, problem-solving
초기 연구자들은 인간이 퍼즐을 풀거나 논리적 추론을 할 때 사용하는 단계별 추론을 모방하는 알고리즘을 개발했습니다. 1980년대 후반과 1990년대까지 AI 연구는 확률과 경제학의 개념을 사용하여 불확실하거나 불완전한 정보를 다루는 방법을 개발했습니다.
이러한 알고리즘 중 다수는 "조합 폭발 / combinatorial explosion"을 경험했기 때문에 큰 추론 문제를 해결하는 데 불충분한 것으로 판명되었습니다. 즉, 문제가 커질수록 기하급수적으로 느려졌습니다. 인간조차도 초기 AI 연구가 모델링할 수 있는 단계별 추론을 거의 사용하지 않습니다. 그들은 빠르고 직관적인 판단을 사용하여 대부분의 문제를 해결합니다.
2.2. Knowledge representation
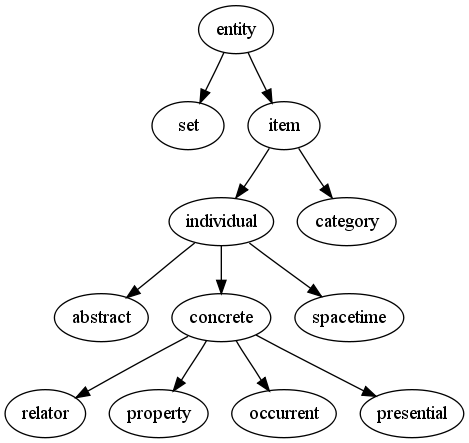
Figure 2. Ontology(존재론)는 도메인 내의 개념 집합과 이러한 개념 간의 관계로 지식을 나타냅니다.
지식 표현 및 지식 엔지니어링을 통해 AI 프로그램은 지능적으로 질문에 답하고 실제 사실에 대해 추론할 수 있습니다.
"존재하는 것"의 표현은 소프트웨어 에이전트가 해석할 수 있도록 공식적으로 설명된 객체, 관계, 개념 및 속성의 집합인 온톨로지입니다. 가장 일반적인 온톨로지는 상위 온톨로지라고 하며, 다른 모든 지식에 대한 기반을 제공하고 특정 지식 도메인(관심 분야 또는 관심 영역)에 대한 특정 지식을 다루는 도메인 온톨로지 간의 중재자 역할을 합니다. 진정으로 지능적인 프로그램은 상식에 대한 접근도 필요합니다. 보통 사람이 알고 있는 일련의 사실. 온톨로지의 의미 체계는 일반적으로 웹 온톨로지 언어와 같은 설명 논리로 표현됩니다.
AI 연구는 특정 도메인을 나타내는 도구를 개발했습니다, 예들들어, 개체, 속성, 범주 및 개체 간의 관계 ; 상황, 사건, 상태 및 시간; 원인과 결과; 지식에 대한 지식(다른 사람들이 알고 있는 것에 대해 우리가 알고 있는 것); 기본 추론(인간이 다르게 말할 때까지 사실이라고 가정하고 다른 사실이 변경되더라도 사실로 남을 것임) 입니다; 다른 도메인도 마찬가지입니다. AI에서 가장 어려운 문제는 다음과 같습니다. ; 상식의 폭(보통 사람이 알고 있는 원자적 사실의 수는 엄청납니다) ; 그리고 가장 상식적인 지식의 하위 상징적 형태(사람들이 알고 있는 것의 대부분은 말로 표현할 수 있는 "사실"이나 "진술"로 표현되지 않음) 입니다..
Formal knowledge representations은 콘텐츠 기반 인덱싱 및 검색, 장면 해석, 임상 의사 결정 지원, 지식 발견(대형 데이터베이스에서 "흥미로운" 및 실행 가능한 추론 마이닝) 및 기타 영역에서 사용됩니다.
2.3. Machine learning
기계 학습(ML)은 초기부터 AI 연구의 기본 개념으로 경험을 통해 자동으로 향상되는 컴퓨터 알고리즘에 대한 연구입니다.
비지도 학습은 입력 스트림에서 패턴을 찾습니다. 지도 학습은 사람이 먼저 입력 데이터에 레이블을 지정해야 하며 분류 및 수치 회귀의 두 가지 주요 종류가 있습니다. 분류는 어떤 항목이 속하는 범주를 결정하는 데 사용됩니다. 프로그램은 여러 범주에서 여러 가지 예를 보고 새 입력을 분류하는 방법을 배웁니다. 회귀는 입력과 출력 간의 관계를 설명하고 입력이 변경됨에 따라 출력이 어떻게 변경되어야 하는지를 예측하는 함수를 생성하려는 시도입니다.
분류기와 회귀 학습기 모두 알려지지 않은(아마도 암시적) 함수를 학습하려는 "함수 근사화기"로 볼 수 있습니다. 예를 들어 스팸 분류자는 이메일 텍스트에서 "스팸" 또는 "스팸 아님"의 두 범주 중 하나로 매핑하는 기능을 학습하는 것으로 볼 수 있습니다. 강화 학습에서 에이전트는 좋은 반응에 대해 보상을 받고 나쁜 반응에 대해 처벌을 받습니다. 에이전트는 문제 공간에서 작동하기 위한 전략을 형성하기 위해 응답을 분류합니다. 전이 학습은 한 문제에서 얻은 지식을 새로운 문제에 적용하는 것입니다.
컴퓨팅 학습 이론은 컴퓨팅 복잡성, 샘플 복잡성(얼마나 많은 데이터가 필요한지) 또는 기타 최적화 개념으로 학습자를 평가할 수 있습니다.
2.4. Natural language processing
Figure 3. 구문 분석 트리는 형식 문법에 따른 문장의 구문 구조를 나타냅니다.
자연어 처리(NLP)를 통해 기계는 인간의 언어를 읽고 이해할 수 있습니다. 충분히 강력한 자연어 처리 시스템은 자연어 사용자 인터페이스와 뉴스와이어 텍스트와 같은 사람이 작성한 소스에서 직접 지식을 얻을 수 있게 합니다. NLP의 일부 간단한 응용 프로그램에는 정보 검색, 질문 응답 및 기계 번역이 포함됩니다.
Symbolic AI는 형식적 구문을 사용하여 문장의 깊은 구조를 논리로 번역했습니다. 이것은 논리의 난해성과 상식의 폭으로 인해 유용한 응용 프로그램을 만드는 데 실패했습니다. 최신 통계 기술에는 동시 발생 빈도(한 단어가 다른 단어 근처에 나타나는 빈도), "키워드 발견"(정보를 검색하기 위해 특정 단어 검색), 변환기 기반 딥 러닝(텍스트에서 패턴 찾기) 등이 포함됩니다. 페이지 또는 단락 수준에서 허용 가능한 정확도를 달성했으며 2019년까지 일관된 텍스트를 생성할 수 있습니다.
2.5. Perception
Figure 4. Feature detection(사진: 가장자리 감지)는 AI가 원시 데이터에서 유익한 추상 구조를 구성하는 데 도움이 됩니다.
기계 인식은 센서(예: 카메라, 마이크, 무선 신호, 능동 라이더, 음파 탐지기, 레이더 및 촉각 센서)의 입력을 사용하여 세상의 측면을 추론하는 기능입니다. 애플리케이션에는 음성 인식, 안면 인식 및 객체 인식이 포함됩니다. 컴퓨터 비전은 시각적 입력을 분석하는 능력입니다.
2.6. Social intelligence
Figure 5. 기본적인 사회적 기술을 갖춘 로봇 Kismet
감성 컴퓨팅은 인간의 느낌, 정서 및 분위기를 인식, 해석, 처리 또는 시뮬레이션하는 시스템으로 구성된 학제간 우산입니다. 예를 들어, 일부 가상 비서는 대화식으로 말하거나 유머러스하게 농담을 하도록 프로그램되어 있습니다. 인간 상호 작용의 정서적 역학에 더 민감하게 보이거나 인간-컴퓨터 상호 작용을 용이하게 합니다. 그러나 이것은 순진한 사용자에게 기존 컴퓨터 에이전트가 실제로 얼마나 지능적인지에 대한 비현실적인 개념을 제공하는 경향이 있습니다. 정서적 컴퓨팅과 관련된 중간 정도의 성공에는 텍스트 감정 분석과 최근에는 다중 모드 감정 분석이 포함되며 AI는 비디오 녹화 대상이 표시하는 감정을 분류합니다.
2.7. General intelligence
일반 지능을 갖춘 기계는 인간 지능과 유사한 폭과 다양성으로 다양한 문제를 해결할 수 있습니다. 인공 일반 지능을 개발하는 방법에 대한 몇 가지 경쟁 아이디어가 있습니다. Hans Moravec과 Marvin Minsky는 서로 다른 개별 영역에서의 작업이 일반 지능을 갖춘 고급 다중 에이전트 시스템 또는 인지 아키텍처에 통합될 수 있다고 주장합니다. Pedro Domingos는 AGI로 이어질 수 있는 개념적으로는 간단하지만 수학적으로 어려운 "마스터 알고리즘"이 있기를 희망합니다. 다른 사람들은 인공 두뇌나 모의 아동 발달과 같은 의인화된 기능이 언젠가 일반 지능이 나타나는 중요한 지점에 도달할 것이라고 믿습니다.
3. Tools
3.1. Search and optimization
AI는 많은 가능한 솔루션을 지능적으로 검색하여 많은 문제를 해결할 수 있습니다. 추론은 검색 수행으로 축소될 수 있습니다. 예를 들어, 논리적 증명은 전제에서 결론으로 이어지는 경로를 찾는 것으로 볼 수 있으며, 각 단계는 추론 규칙의 적용입니다. 계획 알고리즘은 목표 및 하위 목표의 트리를 검색하여 대상 목표에 대한 경로를 찾으려고 시도하며 수단-목적 분석이라고 하는 프로세스입니다. 팔다리를 움직이고 물체를 잡는 로봇 알고리즘은 구성 공간에서 로컬 검색을 사용합니다.
단순한 철저한 검색은 대부분의 실제 문제에 거의 충분하지 않습니다. 검색 공간(검색할 장소의 수)은 빠르게 천문학적인 숫자로 증가합니다. 결과는 너무 느리거나 완료되지 않는 검색입니다. 많은 문제에 대한 해결책은 목표에 도달할 가능성이 더 높은 사람들을 위해 선택의 우선 순위를 지정하고 더 짧은 단계로 그렇게 하는 "휴리스틱" 또는 "경험 법칙"을 사용하는 것입니다. 일부 검색 방법론에서 휴리스틱은 목표로 이어지지 않을 가능성이 있는 일부 선택을 제거하는 역할을 할 수도 있습니다("검색 트리 가지치기"라고 함). 휴리스틱은 솔루션이 있는 경로에 대한 "최선의 추측"을 프로그램에 제공합니다. 휴리스틱은 솔루션 검색을 더 작은 샘플 크기로 제한합니다.
Figure 6. A particle swarm seeking the global minimum
1990년대에는 수학적 최적화 이론에 기반한 매우 다른 종류의 검색이 두드러졌습니다. 많은 문제의 경우 어떤 형태의 추측으로 검색을 시작한 다음 더 이상 구체화할 수 없을 때까지 점진적으로 추측을 구체화할 수 있습니다. 이러한 알고리즘은 맹목적인 언덕 오르기로 시각화할 수 있습니다. 우리는 풍경의 임의 지점에서 검색을 시작한 다음 점프 또는 단계를 통해 정상에 도달할 때까지 추측을 언덕 위로 계속 이동합니다. 기타 관련 최적화 알고리즘에는 랜덤 최적화, 빔 검색 및 시뮬레이션 어닐링과 같은 메타 휴리스틱이 포함됩니다. 진화 계산은 최적화 검색 형식을 사용합니다.
예를 들어, 유기체 집단(추측)으로 시작한 다음 돌연변이 및 재결합을 허용하여 각 세대에서 살아남을 수 있는 적자만 선택합니다(추측 정제). 고전적인 진화 알고리즘에는 유전 알고리즘, 유전자 발현 프로그래밍 및 유전 프로그래밍이 포함됩니다. 또는 분산 검색 프로세스는 군집 인텔리전스 알고리즘을 통해 조정할 수 있습니다. 검색에 사용되는 인기 있는 두 가지 군집 알고리즘은 입자 군집 최적화(새 무리에서 영감을 받음)와 개미 식민지 최적화(개미 흔적에서 영감을 얻음)입니다.
3.2. Logic
논리는 지식 표현과 문제 해결에 사용되지만 다른 문제에도 적용될 수 있습니다. 예를 들어 satplan 알고리즘은 계획을 위한 논리를 사용하고 귀납 논리 프로그래밍은 학습을 위한 방법입니다.
AI 연구에는 여러 가지 다른 형태의 논리가 사용됩니다. 명제 논리에는 "or" 및 "not"과 같은 진리 함수(truth functions)가 포함됩니다. 1차 논리는 수량사와 술어를 추가하고 개체, 해당 속성 및 서로 간의 관계에 대한 사실을 표현할 수 있습니다. 퍼지 논리는 "Alice is old"(또는 부자, 키가 크거나 배고픈)와 같은 모호한 진술에 "진실의 정도(degree of truth)"(0과 1 사이)를 할당합니다. 기본 논리, 비단조 논리 및 제한은 기본 추론 및 자격 문제를 돕기 위해 설계된 논리 형식입니다. 설명 논리와 같은 특정 지식 영역을 처리하기 위해 몇 가지 논리 확장이 설계되었습니다. ; 상황 미적분학, 사건 미적분학 및 유창한 미적분학(사건 및 시간을 나타내기 위한); 인과적 계산; 신념 미적분학(신념 수정); 및 모달 논리등 입니다. 다중 에이전트 시스템에서 발생하는 모순되거나 일관되지 않은 진술을 모델링하는 논리도 유사 논리와 같이 설계되었습니다.
3.3. Probabilistic methods for uncertain reasoning
Figure 7. Old Faithful 분출 데이터의 기대치 최대화 클러스터링은 임의의 추측에서 시작하지만 물리적으로 구별되는 두 가지 분출 모드의 정확한 클러스터링에 성공적으로 수렴됩니다.
AI의 많은 문제(추론, 계획, 학습, 인식 및 로봇 공학 포함)는 에이전트가 불완전하거나 불확실한 정보로 작동해야 합니다. AI 연구원들은 확률 이론과 경제학의 방법을 사용하여 이러한 문제를 해결하기 위해 여러 가지 도구를 고안했습니다. 베이지안 네트워크는 추론(베이지안 추론 알고리즘 사용), 학습(예상-최대화 알고리즘 사용), 계획(결정 네트워크 사용) 및 인식(동적 베이지안 네트워크 사용)을 포함한 다양한 문제에 사용할 수 있는 매우 일반적인 도구입니다. 확률적 알고리즘은 데이터 스트림에 대한 필터링, 예측, 평활화 및 설명 찾기에도 사용할 수 있으며, 인식 시스템이 시간이 지남에 따라 발생하는 프로세스(예: 숨겨진 Markov 모델 또는 Kalman 필터)를 분석하는 데 도움이 됩니다.
경제학의 핵심 개념은 지능형 에이전트에게 어떤 것이 얼마나 가치가 있는지를 측정하는 "효용성"입니다. 의사 결정 이론, 의사 결정 분석 및 정보 가치 이론을 사용하여 에이전트가 선택하고 계획하는 방법을 분석하는 정확한 수학적 도구가 개발되었습니다. 이러한 도구에는 Markov 결정 프로세스, 동적 결정 네트워크, 게임 이론 및 메커니즘 설계와 같은 모델이 포함됩니다.
3.4. Classifiers and statistical learning methods
가장 간단한 AI 애플리케이션은 분류자("빛나면 다이아몬드")와 컨트롤러("다이아몬드이면 줍는다.")의 두 가지 유형으로 나눌 수 있습니다. 그러나 컨트롤러는 행동을 추론하기 전에 조건을 분류하기도 하므로 분류는 많은 AI 시스템의 핵심 부분을 형성합니다. 분류자는 패턴 일치를 사용하여 가장 가까운 일치를 결정하는 기능입니다. 예제에 따라 조정할 수 있으므로 AI에서 사용하기에 매우 매력적입니다. 이러한 예를 관찰 또는 패턴이라고 합니다. 감독 학습에서 각 패턴은 미리 정의된 특정 클래스에 속합니다. 클래스는 내려야 할 결정입니다. 클래스 레이블과 결합된 모든 관측치를 데이터 세트라고 합니다. 새로운 관찰이 수신되면 해당 관찰은 이전 경험을 기반으로 분류됩니다.
분류자는 다양한 방법으로 훈련될 수 있습니다. 많은 통계 및 기계 학습 접근 방식이 있습니다. 의사 결정 트리는 가장 단순하고 가장 널리 사용되는 상징적 기계 학습 알고리즘입니다. K-최근접 이웃 알고리즘은 1990년대 중반까지 가장 널리 사용된 아날로그 AI였습니다. SVM(Support Vector Machine)과 같은 커널 방법은 1990년대에 k-최근접 이웃을 대체했습니다. 순진한 베이즈 분류기는 부분적으로 확장성 때문에 Google에서 "가장 널리 사용되는 학습기"라고 합니다. 신경망은 분류에도 사용됩니다.
분류기 성능은 데이터 세트 크기, 클래스 간 샘플 분포, 차원 및 노이즈 수준과 같이 분류할 데이터의 특성에 따라 크게 달라집니다. 모델 기반 분류기는 가정된 모델이 실제 데이터에 매우 잘 맞는 경우 잘 수행됩니다. 그렇지 않고 일치하는 모델을 사용할 수 없고 정확도(속도나 확장성보다)가 유일한 관심사인 경우 판별 분류기(특히 SVM)가 대부분의 실제 데이터 세트에서 "naive Bayes"와 같은 모델 기반 분류기보다 더 정확한 경향이 있다는 일반적인 통념이 있습니다.
3.5. Artificial neural networks / Deep learning
Figure 8. 신경망은 상호 연결된 노드 그룹으로 인간 두뇌의 방대한 신경망과 유사합니다.
신경망은 인간 두뇌의 뉴런 구조에서 영감을 받았습니다. 간단한 "뉴런" N은 다른 뉴런의 입력을 받아들이며, 각 뉴런은 활성화(또는 "발화")될 때 뉴런 N 자체가 활성화되어야 하는지 여부에 대해 가중 "투표"를 합니다. 학습에는 훈련 데이터를 기반으로 이러한 가중치를 조정하는 알고리즘이 필요합니다. 하나의 간단한 알고리즘("함께 발사, 함께 연결"이라고 함)은 하나의 활성화가 다른 뉴런의 성공적인 활성화를 트리거할 때 연결된 두 뉴런 사이의 가중치를 증가시키는 것입니다. 뉴런은 연속적인 활성화 스펙트럼을 가지고 있습니다. 또한 뉴런은 직접적인 투표에 가중치를 두지 않고 비선형 방식으로 입력을 처리할 수 있습니다.
최신 신경망은 입력과 출력 간의 복잡한 관계를 모델링하고 데이터에서 패턴을 찾습니다. 연속 기능과 디지털 논리 연산까지 배울 수 있습니다. 신경망은 수학적 최적화의 한 유형으로 볼 수 있습니다. 신경망을 훈련하여 만든 다차원 토폴로지에서 경사 하강법을 수행합니다. 가장 일반적인 훈련 기법은 역전파 알고리즘입니다. 신경망에 대한 다른 학습 기술은 Hebbian 학습("함께 실행하고, 함께 연결"), GMDH (Group Method of Data Handling) 또는 경쟁 학습입니다.
네트워크의 주요 범주는 비주기적 또는 피드포워드 신경망(신호가 한 방향으로만 전달되는 경우)과 순환 신경망(이전 입력 이벤트에 대한 피드백 및 단기 기억을 허용함)입니다. 가장 널리 사용되는 피드포워드 네트워크 중에는 퍼셉트론, 다층 퍼셉트론 및 radial basis 네트워크가 있습니다.
Deep learning
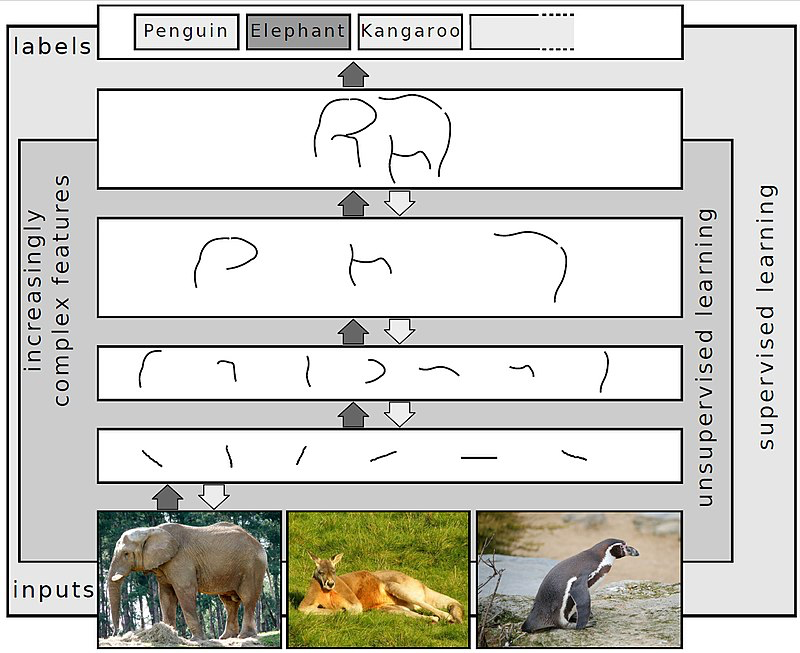
Figure 9. 딥 러닝에서 여러 추상화 계층에 이미지 표현
딥 러닝은 네트워크의 입력과 출력 사이에 여러 계층의 뉴런을 사용합니다. 여러 레이어는 원시 입력에서 더 높은 수준의 기능을 점진적으로 추출할 수 있습니다. 예를 들어 이미지 처리에서 하위 계층은 가장자리를 식별할 수 있고 상위 계층은 숫자나 문자 또는 얼굴과 같은 인간과 관련된 개념을 식별할 수 있습니다. 딥 러닝은 컴퓨터 비전, 음성 인식, 이미지 분류 등을 포함하여 인공 지능의 많은 중요한 하위 분야에서 프로그램의 성능을 크게 향상시켰습니다.
딥 러닝은 종종 많은 또는 모든 레이어에 대해 컨볼루션 신경망을 사용합니다. 컨볼루션 레이어에서 각 뉴런은 뉴런의 수용 필드라고 하는 이전 레이어의 제한된 영역에서만 입력을 받습니다. 이것은 뉴런 사이의 가중 연결 수를 상당히 줄일 수 있으며 동물 시각 피질의 조직과 유사한 계층 구조를 생성합니다.
순환 신경망(RNN)에서 신호는 레이어를 통해 두 번 이상 전파됩니다. 따라서 RNN은 딥 러닝의 한 예입니다. RNN은 기울기 하강법으로 훈련할 수 있지만 역전파되는 장기 기울기는 기울기 소멸 문제로 알려진 "사라지거나" (즉, 0이 되는 경향이 있음) "폭발"(즉, 무한대로 경향이 있을 수 있음)할 수 있습니다. LSTM(장단기 기억 , long short term memory) 기술은 대부분의 경우 이를 방지할 수 있습니다.
3.6. Specialized languages and hardware
Lisp, Prolog, TensorFlow 등과 같은 인공 지능을 위한 특수 언어가 개발되었습니다. AI용으로 개발된 하드웨어에는 AI 가속기와 뉴로모픽 컴퓨팅이 포함됩니다.
4. Applications
Figure 10. 이 프로젝트에서 AI는 르네상스 화가 라파엘의 색상과 붓놀림의 전형적인 패턴을 학습해야 했습니다. 초상화는 AI가 라파엘로 스타일로 "그린 (painted)" 여배우 오르넬라 무티의 얼굴을 보여줍니다.
AI는 모든 지적 작업과 관련이 있습니다. 현대 인공 지능 기술은 널리 퍼져 있으며 여기에 나열하기에는 너무 많습니다. 기술이 주류로 사용되면 더 이상 인공 지능으로 간주되지 않는 경우가 많습니다. 이 현상을 AI 효과라고 합니다.
2010년대 AI 애플리케이션은 상업적으로 가장 성공한 컴퓨팅 분야의 중심에 있었고 일상 생활의 유비쿼터스 기능이 되었습니다. AI는 검색 엔진(예: Google 검색), 대상 온라인 광고, 추천 시스템(Netflix, YouTube 또는 Amazon에서 제공), 인터넷 트래픽 유도, 대상 광고(AdSense, Facebook), 가상 비서(예: Siri 또는 Alexa), 자율 주행 차량(드론, ADAS 및 자율 주행 자동차 포함), 자동 언어 번역(Microsoft Translator, Google Translate), 안면 인식(Apple의 Face ID 또는 Microsoft의 DeepFace), 이미지 라벨링(Facebook, Apple의 iPhoto 및 TikTok에서 사용), 스팸 필터링 및 챗봇(예: Chat GPT)에 사용됩니다.
또한 특정 산업 또는 기관의 문제를 해결하는 데 사용되는 수천 개의 성공적인 AI 애플리케이션이 있습니다. 몇 가지 예는 에너지 저장, 딥페이크, 의료 진단, 군사 물류 또는 공급망 관리입니다.
게임 플레이는 1950년대 이후로 AI의 강점을 시험해 왔습니다. Deep Blue는 1997년 5월 11일 세계 체스 챔피언인 Garry Kasparov를 이긴 최초의 컴퓨터 체스 플레이 시스템이 되었습니다. 2011년에는 Jeopardy! 퀴즈 쇼 시범 경기, IBM의 질의 응답 시스템인 Watson이 두 명의 가장 큰 Jeopardy를 물리쳤습니다! 챔피언인 Brad Rutter와 Ken Jennings가 상당한 차이로 승리했습니다. 2016년 3월 AlphaGo는 바둑 챔피언 이세돌과의 경기에서 바둑 5게임 중 4게임을 이겼고, 컴퓨터 바둑 시스템 최초로 핸디캡 없이 프로 바둑 선수를 이겼습니다. 다른 프로그램은 불완전한 정보 게임을 처리합니다. ; 초인적 수준의 포커, Pluribus 및 Cepheus와 같은 것들 입니다. 2010년대 딥마인드는 다양한 아타리 게임을 스스로 학습할 수 있는 '일반화된 인공지능'을 개발했습니다.
2020년까지 거대한 GPT-3(당시 가장 큰 인공 신경망)과 같은 자연어 처리 시스템은 기존 벤치마크에서 사람의 성능과 일치했지만 시스템이 벤치마크 내용에 대한 상식적인 이해를 얻지는 못했습니다. DeepMind의 AlphaFold 2(2020)는 단백질의 3D 구조를 몇 달이 아닌 몇 시간 만에 근사화하는 능력을 보여주었습니다. 다른 응용 프로그램은 사법 결정의 결과를 예측하고 예술(시 또는 그림 등)을 만들고 수학 정리를 증명합니다.
Smart traffic lights
Figure 11. 인공 지능 신호등은 레이더, 초음파 음향 위치 센서 및 예측 알고리즘이 있는 카메라를 사용하여 교통 흐름을 개선합니다.
스마트 신호등은 2009년부터 Carnegie Mellon에서 개발되었습니다. Stephen Smith 교수는 이후 22개 도시에 스마트 교통 제어 시스템을 설치한 Surtrac 회사를 시작했습니다. 설치 비용은 교차로당 약
입니다. 주행 시간이 25% 단축되었으며 설치된 교차로에서 교통 체증 대기 시간이 40% 단축되었습니다.
5. Philosophy
5.1. Defining artificial intelligence
Alan Turing은 1950년에 "나는 '기계가 생각할 수 있는가'라는 질문을 고려할 것을 제안합니다."라고 썼습니다. 그는 기계가 "생각"하는지 여부에서 "기계가 지능적인 행동을 보이는 것이 가능한지 여부"로 질문을 바꾸라고 조언했습니다. 그는 기계가 인간의 대화를 시뮬레이션하는 능력을 측정하는 튜링 테스트를 고안했습니다. 우리는 기계의 행동을 관찰할 수만 있기 때문에 기계가 "실제로" 생각하고 있는지 문자 그대로 "마음"을 가지고 있는지는 중요하지 않습니다. Turing은 우리가 다른 사람들에 대해 이러한 것들을 결정할 수는 없지만 "모든 사람이 생각하는 정중한 관습을 갖는 것이 일반적"이라고 지적합니다.
Russell과 Norvig는 AI가 "사고"가 아니라 "행동"의 관점에서 정의되어야 한다는 Turing의 의견에 동의합니다. 그러나 테스트에서 기계와 사람을 비교하는 것이 중요합니다. 그들은 "항공 공학 교과서"에서 " '비둘기와 똑같이 날아서 다른 비둘기를 속일 수 있는 기계'를 만드는 것이 해당 분야의 목표를 정의하지 않습니다."라고 썼습니다. AI 창시자 John McCarthy는 "인공 지능은 정의상 인간 지능의 시뮬레이션이 아니다"라고 적으면서 동의했습니다.
McCarthy는 지능을 "세계에서 목표를 달성할 수 있는 능력의 계산적 부분"으로 정의합니다. 또 다른 AI 창시자 마빈 민스키(Marvin Minsky)는 이를 "어려운 문제를 해결하는 능력"으로 유사하게 정의합니다. 이러한 정의는 문제의 난이도와 프로그램의 성능이 모두 기계의 "지능"에 대한 직접적인 척도이며 다른 철학적 논의가 필요하지 않은 잘 정의된 솔루션이 있는 잘 정의된 문제의 관점에서 지능을 봅니다. 또는 가능하지 않을 수도 있습니다.
AI 분야의 주요 실무자인 Google에서도 채택한 정의입니다. 이 정의는 생물학적 지능에서 정의된 방식과 유사하게 정보를 지능의 표현으로 합성하는 시스템의 능력을 규정했습니다.
5.2. Evaluating approaches to AI
확립된 통합 이론이나 패러다임은 대부분의 역사에서 AI 연구를 안내하지 않았습니다. 2010년대 통계적 기계 학습의 전례 없는 성공은 다른 모든 접근 방식을 압도했습니다(특히 비즈니스 세계의 일부 출처에서는 "신경망을 통한 기계 학습"을 의미하기 위해 "인공 지능"이라는 용어를 사용함). 이 접근 방식은 대부분 하위 상징적이고 깔끔하며 부드럽고 좁습니다(아래 참조). 비평가들은 미래 세대의 AI 연구자들이 이러한 질문을 다시 검토해야 할 수도 있다고 주장합니다.
5.2.1. Symbolic AI and its limits
Symbolic AI(또는 "GOFAI")는 사람들이 퍼즐을 풀고 법적 추론을 표현하고 수학을 할 때 사용하는 높은 수준의 의식적 추론을 시뮬레이션했습니다. 그들은 대수학이나 IQ 테스트와 같은 "지능적인" 작업에서 매우 성공적이었습니다. 1960년대에 Newell과 Simon은 물리적 기호 시스템 가설을 제안했습니다.
그러나 상징적 접근은 학습, 사물 인식 또는 상식적 추론과 같이 인간이 쉽게 풀 수 있는 많은 작업에서 실패했습니다.
Moravec의 역설은 높은 수준의 "지능형" 작업은 AI에게 쉬웠지만 낮은 수준의 "본능적인" 작업은 극도로 어려웠다는 발견입니다. 철학자 Hubert Dreyfus는 1960년대부터 인간의 전문성은 의식적인 기호 조작보다는 무의식적인 본능에 의존하고 명시적인 상징적 지식보다는 상황에 대한 "느낌"을 갖는 데 달려 있다고 주장했습니다. 그의 주장이 처음 제시되었을 때 조롱과 무시를 받았지만 결국 AI 연구는 동의하게 되었습니다.
문제는 해결되지 않았습니다. 하위 상징적 추론은 알고리즘 편향과 같이 인간의 직관과 동일한 불가해한 실수를 많이 범할 수 있습니다. 노암 촘스키(Noam Chomsky)와 같은 비평가들은 상징적 AI에 대한 지속적인 연구가 일반 지능을 달성하기 위해 여전히 필요할 것이라고 주장합니다. 부분적으로는 하위 상징적 AI가 설명 가능한 AI에서 멀어지기 때문입니다. 특정 결정. 새롭게 떠오르는 신경 상징 인공 지능 분야는 두 가지 접근 방식을 연결하려고 시도합니다.
5.2.2. Neat vs. scruffy
"Neats"는 지능적인 행동이 단순하고 우아한 원칙(예: 논리, 최적화 또는 신경망)을 사용하여 설명되기를 바랍니다. "Scruffies"는 관련 없는 많은 문제를 해결해야 한다고 예상합니다(특히 상식적인 추론과 같은 영역에서). 이 문제는 70년대와 80년대에 활발히 논의되었지만 1990년대에는 수학적 방법과 확고한 과학적 기준이 표준이 되었고, Russell 과 Norvig 이 "니트의 승리"라고 부르는 전환이 되었습니다.
5.2.3. Soft vs. hard computing
증명할 수 있는 정확하거나 최적의 솔루션을 찾는 것은 많은 중요한 문제에 대해 다루기 어렵습니다. 소프트 컴퓨팅은 유전 알고리즘, 퍼지 논리 및 신경망을 포함하여 부정확성, 불확실성, 부분 진실 및 근사치를 허용하는 일련의 기술입니다. 소프트 컴퓨팅은 80년대 후반에 도입되었으며 21세기에 가장 성공적인 AI 프로그램은 신경망을 사용한 소프트 컴퓨팅의 예입니다.
5.2.4. Narrow vs. general AI
일반 인공지능(artificial general intelligence)과 초지능(superintelligence)의 목표를 직접 추구할 것인지(general AI), 아니면 이러한 솔루션이 간접적으로 해당 분야의 장기 목표로 이어지기를 바라며 가능한 한 많은 특정 문제를 해결(narrow AI)할 것인지에 대해 AI 연구자들은 의견이 분분합니다. 일반 지능은 정의하기 어렵고 측정하기 어려우며 현대 AI는 특정 솔루션으로 특정 문제에 집중함으로써 보다 검증 가능한 성공을 거두었습니다. 인공 일반 지능의 실험적 하위 분야는 이 영역을 독점적으로 연구합니다.
5.3. Machine consciousness, sentience and mind
마음의 철학은 기계가 인간과 같은 의미에서 마음, 의식 및 정신 상태를 가질 수 있는지 여부를 모릅니다. 이 문제는 외부 동작이 아닌 기계의 내부 경험을 고려합니다. 주류 AI 연구는 이 문제가 해당 분야의 목표에 영향을 미치지 않기 때문에 관련이 없다고 생각합니다. 스튜어트 러셀(Stuart Russell)과 피터 노빅(Peter Norvig)은 대부분의 AI 연구자들이 "[AI의 철학]에 대해 신경 쓰지 않는다. 프로그램이 작동하는 한, 그들은 당신이 그것을 지능 시뮬레이션이라고 부르든 실제 지능이라고 부르든 상관하지 않는다"고 관찰했습니다. 그러나 그 질문은 마음 철학의 중심이 되었습니다. 또한 일반적으로 소설 속 인공 지능에서 쟁점이 되는 핵심 질문이기도 합니다.
5.3.1. Consciousness
David Chalmers는 의식의 "어려운" 문제와 "쉬운" 문제라고 명명한 마음을 이해하는 데 있어 두 가지 문제를 확인했습니다. 쉬운 문제는 뇌가 신호를 처리하고 계획을 세우고 행동을 제어하는 방법을 이해하는 것입니다. 어려운 문제는 이것이 어떻게 느껴지는지 또는 왜 그렇게 느껴져야 하는지를 설명하는 것입니다. 인간의 정보처리는 설명하기 쉽지만 인간의 주관적 경험은 설명하기 어렵습니다. 예를 들어, 자신의 시야에서 어떤 물체가 빨간색인지 식별하는 법을 배운 색맹인 사람을 상상하기는 쉽지만, 그 사람이 빨간색이 어떻게 생겼는지 알기 위해 무엇이 필요한지는 명확하지 않습니다.
5.3.2. Computationalism and functionalism
계산주의(Computationalism)는 인간의 마음은 정보 처리 시스템이고 사고는 컴퓨팅의 한 형태라는 마음 철학의 입장입니다. 계산주의는 마음과 몸의 관계가 소프트웨어와 하드웨어의 관계와 유사하거나 동일하므로 마음-몸 문제에 대한 해결책이 될 수 있다고 주장합니다. 이 철학적 입장은 1960년대 AI 연구원과 인지 과학자들의 작업에서 영감을 얻었으며 원래 철학자 Jerry Fodor와 Hilary Putnam이 제안했습니다.
철학자 존 설(John Searle)은 이 입장을 "strong AI"라고 표현했습니다 : "올바른 입력과 출력이 있는 적절하게 프로그래밍된 컴퓨터는 인간이 마음을 가지고 있는 것과 똑같은 의미에서 마음을 가질 것입니다."
Searle은 기계가 인간의 행동을 완벽하게 시뮬레이션하더라도 여전히 마음이 있다고 가정할 이유가 없음을 보여주려고 시도하는 Chinese room argument으로 이 주장을 반박합니다.
5.3.3. Robot rights
기계에 마음과 주관적 경험이 있다면 감각(느낌)도 가질 수 있고, 그렇다면 고통도 받을 수 있으므로 특정 권리를 가질 수 있습니다. 모든 가상의 로봇 권리는 동물 권리와 인권의 범위에 있을 것입니다. 이 문제는 수세기 동안 소설에서 고려되었으며 현재 예를 들어 California의 Institute for the Future에서 고려하고 있습니다. 그러나 비평가들은 논의가 시기상조라고 주장합니다.
6. Future
6.1. 📍 Superintelligence
초지능(superintelligence), 초지능(hyperintelligence) 또는 초인간 지능(superhuman intelligence)은 가장 영리하고 가장 재능 있는 인간의 마음을 훨씬 능가하는 지능을 소유할 수 있는 가상의 에이전트입니다. 초지능(superintelligence)은 또한 그러한 에이전트가 소유한 지능의 형태 또는 정도를 나타낼 수 있습니다.
인공 일반 지능에 대한 연구가 충분히 지능적인 소프트웨어를 생산한다면 스스로를 재프로그래밍하고 개선할 수 있을 것입니다. 개선된 소프트웨어는 자체 개선에 훨씬 더 뛰어나서 반복적인 자체 개선으로 이어집니다. 그 지능은 지능 폭발로 기하급수적으로 증가하여 인간을 극적으로 능가할 수 있습니다. SF 작가 Vernor Vinge는 이 시나리오를 "singularity"이라고 명명했습니다. 지능의 한계나 초지능 기계의 능력을 아는 것이 어렵거나 불가능하기 때문에 기술적 특이점은 사건을 예측할 수 없거나 심지어 헤아릴 수 없는 사건입니다.
로봇 설계자 Hans Moravec, 인공두뇌학자 Kevin Warwick, 발명가 Ray Kurzweil은 미래에 인간과 기계가 합쳐져 더 유능하고 강력한 사이보그가 될 것이라고 예측했습니다. 트랜스휴머니즘이라고 불리는 이 아이디어는 올더스 헉슬리와 로버트 에팅거에 뿌리를 두고 있습니다.
에드워드 프레드킨(Edward Fredkin)은 "인공 지능은 진화의 다음 단계"라고 주장합니다. 이 아이디어는 사무엘 버틀러(Samuel Butler)의 "기계 사이의 다윈"이 1863년에 처음 제안했고 조지 다이슨이 1998년 같은 이름의 책에서 확장했습니다.
6.2. Risks (AI safety)
6.2.1. Technological unemployment
과거에는 기술이 총 고용을 줄이기보다는 증가하는 경향이 있었지만 경제학자들은 AI와 함께 "우리는 미지의 영역에 있다"고 인정합니다. 경제학자들을 대상으로 한 설문 조사에서는 로봇과 AI의 사용 증가가 장기 실업을 크게 증가시킬 것인지에 대해 의견이 분분했지만, 생산성 향상이 재분배되면 순이익이 될 수 있다는 점에는 대체로 동의했습니다. 위험에 대한 주관적인 추정치는 매우 다양합니다. 예를 들어, Michael Osborne과 Carl Benedikt Frey는 미국 일자리의 47%가 잠재적인 자동화의 "높은 위험"에 있다고 추정하는 반면, OECD 보고서는 미국 일자리의 9%만 "높은 위험"으로 분류합니다.
이전의 자동화 물결과 달리 많은 중산층 일자리는 인공 지능에 의해 제거될 수 있습니다. The Economist는 "산업 혁명 동안 증기력이 생산직에 영향을 미쳤던 것처럼 AI가 사무직에 미칠 수 있는 걱정"은 "진지하게 받아들일 가치가 있다"고 말했습니다. 개인 의료에서 성직자에 이르기까지 돌봄 관련 직업에 대한 직업 수요가 증가할 가능성이 있습니다.
인공 지능은 상상할 수 없는 방식으로 세상을 극적으로 개선했지만 고용과 노동력의 신뢰성에 미칠 수 있는 영향에 대해 많은 우려가 있습니다. 자동화 및 신경망으로 인해 향후 10년 동안 수백만 명의 사람들이 실업에 직면할 가능성에 대해 알려주는 예측이 있습니다. AI로 인해 비즈니스, 교육, 시장 및 정부 부문에 상당한 변화가 있습니다.
Sectors where AI can replace humans
운송: 향상된 자동화 및 머신 러닝을 통해 우리는 환경을 감지하고 사람의 개입 없이 안전하게 이동할 수 있는 차량을 설계하고 만들 수 있습니다. 이 차량은 자율 주행이며 이동을 위해 인간 운전자가 필요하지 않습니다. 이러한 자동화된 차량의 성장으로 자동차 운전자, 선원 및 조종사와 같은 전문가에 대한 수요가 급격히 감소할 것입니다.
전자 상거래: 전자 상거래는 AI로 인해 엄청난 변화를 겪을 것입니다. 제품을 수집하고 고객 주문을 실행하기 위해 공간을 탐색하는 로봇과 함께; 자율 드론과 자동차를 통해 자동으로 고객에게 보내거나 배달할 수도 있습니다. 따라서 영업 사원 및 네트워크 상점에 대한 수요가 감소합니다.
헬스케어: AI가 존재하기 전에는 간호사가 환자의 건강을 정기적으로 모니터링하고 환자의 건강에 대해 의사에게 알려야 했습니다. 그러나 이제 의사가 환자의 건강을 정기적으로 모니터링하여 환자의 건강에 필요한 결정을 내릴 수 있도록 환자의 몸에 부착된 AI 지원 장치의 도움으로. 따라서 간호사가 정기적으로 환자의 건강을 모니터링할 필요가 없습니다.
교육: 가상 비서는 소프트웨어 에이전트로 작업 기반 인간의 구두 명령에 대한 작업을 수행할 수 있습니다. 이제 가상 비서는 인간 교사처럼 학생들을 가르칠 수 있는 방식으로 설계되고 있습니다. 따라서 학생들은 저렴한 가격으로 가상 비서의 도움을 받아 온라인으로 공부할 수 있으며 곧 교사와 교수의 필요성이 줄어들 것입니다.
Here are some points to consider when thinking about AI and unemployment:
AI가 일부 일자리를 대체할 가능성이 있음: 일상적이고 반복적이거나 위험한 특정 작업은 AI를 사용하여 자동화될 수 있습니다. 이는 제조, 운송 및 고객 서비스와 같은 산업에서 실직으로 이어질 수 있습니다.
AI는 새로운 일자리를 창출할 것입니다: AI는 또한 데이터 분석, 소프트웨어 개발 및 AI 프로그래밍과 같은 분야에서 새로운 일자리를 창출할 것입니다. 이러한 작업에는 새로운 기술과 교육이 필요하며 근로자가 새로운 역할과 책임에 적응해야 할 수도 있습니다.
AI는 생산성을 높일 것입니다: AI는 이전에는 시간이 많이 걸리고 비효율적이었던 작업을 자동화하여 인간 작업자가 보다 복잡하고 창의적인 작업에 집중할 수 있도록 합니다. 이는 생산성 향상과 경제 성장으로 이어질 수 있습니다.
AI가 고용에 미치는 영향은 산업에 따라 다릅니다: 일부 산업에서는 자동화로 인해 상당한 일자리 손실이 발생할 수 있지만 다른 산업에서는 새로운 기술과 전문성을 갖춘 근로자에 대한 수요가 증가할 수 있습니다. AI가 고용에 미치는 영향은 AI가 얼마나 빨리 채택되고 기존 시스템에 어떻게 통합되는지에 따라 달라집니다.
Areas where AI is replacing human work
택배: 택배와 배달원은 이미 몇 년 안에 자동화가 이 분야를 지배하게 될 드론과 로봇으로 대체되고 있습니다. 이 공간은 2024년에 5% 성장할 것으로 예상됩니다.
정보 기술: 2024년에는 자동화가 12% 증가할 것으로 예상됩니다. 이전에는 소프트웨어 코드를 테스트하기 위해 사람이 필요했습니다. 그러나 이제는 자동화된 테스트가 수행되므로 인간 테스터가 필요하지 않습니다. 따라서 업계에서 IT 전문가의 필요성을 줄입니다.
부동산: 부동산은 주택 매매에 중요한 역할을 합니다. 정보화 시대에는 모든 것이 손끝에서 가능합니다. Magic Brick 및 99에이커와 같은 온라인 서비스는 고객이 자신의 부동산을 검색하는 데 도움이 됩니다. 따라서 기술에 정통한 판매자는 에이전트 없이도 고객에게 쉽게 도달할 수 있습니다.
제조: AI 지원 로봇은 인간보다 더 빠르고 정밀하게 조립 및 포장과 같은 작업을 수행할 수 있어 필요한 인간 작업자 수를 줄일 수 있습니다.
운송: 자율주행차는 사람의 개입이 거의 또는 전혀 없이 도로와 고속도로를 탐색할 수 있으므로 운송에 필요한 운전자 수를 줄일 수 있습니다.
고객 서비스: AI 기반 챗봇은 고객 문의 및 지원 요청을 처리할 수 있으므로 인간 고객 서비스 담당자의 필요성이 줄어듭니다.
데이터 입력 및 분석: AI는 대량의 데이터 처리를 자동화하여 사람이 데이터를 입력하고 분석할 필요성을 줄입니다.
소매 및 판매: AI 기반 추천 시스템은 고객의 선호도 및 구매 이력을 기반으로 고객에게 제품을 제안할 수 있으므로 영업 직원의 필요성이 줄어듭니다.
금융 서비스: AI 기반 시스템은 인간보다 더 정확하고 효율적으로 사기 탐지 및 위험 평가와 같은 작업을 수행할 수 있으므로 이러한 영역에서 인간 작업자의 필요성을 잠재적으로 줄일 수 있습니다.
의료: AI 지원 장치는 환자 건강 모니터링 및 의료 이미지 분석과 같은 작업에서 의사와 간호사를 지원하여 잠재적으로 일부 인간 작업자의 필요성을 줄일 수 있습니다.
장기적으로 우리는 덜 관련성이 있고 결국 쓸모없는 특정 직업을 목격하게 될 것입니다. 인공 지능은 일상 생활에 구현되면 작업을 더 쉽고 빠르게 만들어 많은 이점을 제공합니다. 그러나 그것은 또한 실업의 원인이 되고 있다. 따라서 가장 큰 과제는 실업률을 높이지 않는 방식으로 시행하는 것입니다.
6.2.2. Bad actors and weaponized AI
AI는 권위주의 정부에 특히 유용한 여러 가지 도구를 제공합니다. 스마트 스파이웨어, 얼굴 인식 및 음성 인식을 통해 광범위한 감시가 가능합니다. 그러한 감시는 기계 학습이 국가의 잠재적인 적을 분류하고 그들이 숨는 것을 방지할 수 있게 합니다. 추천 시스템은 최대 효과를 위해 선전 및 잘못된 정보를 정확하게 타겟팅할 수 있습니다. 딥페이크는 잘못된 정보 생성에 도움이 됩니다. 고급 AI는 중앙 집중식 의사 결정을 시장과 같은 자유롭고 분산된 시스템과 더 경쟁력 있게 만들 수 있습니다.
테러리스트, 범죄자 및 불량 국가는 첨단 디지털 전쟁 및 치명적인 자동 무기와 같은 다른 형태의 무기화된 AI를 사용할 수 있습니다. 2015년까지 50개국 이상이 전장용 로봇을 연구하고 있는 것으로 보고되었습니다.
기계 학습 AI는 또한 몇 시간 만에 수만 개의 독성 분자를 설계할 수 있습니다.
6.2.3. Algorithmic bias
AI 프로그램은 실제 데이터에서 학습한 후 편향될 수 있습니다. 일반적으로 시스템 설계자가 도입하는 것이 아니라 프로그램에서 학습하므로 프로그래머는 편향이 존재한다는 사실을 종종 인식하지 못합니다. 훈련 데이터가 선택되는 방식으로 편향이 의도치 않게 도입될 수 있습니다. 그것은 또한 상관 관계에서 나타날 수 있습니다. AI는 개인을 그룹으로 분류한 다음 개인이 그룹의 다른 구성원과 유사할 것이라고 가정하여 예측하는 데 사용됩니다. 어떤 경우에는 이 가정이 불공평할 수도 있습니다. 이에 대한 예는 피고가 상습범이 될 가능성을 평가하기 위해 미국 법원에서 널리 사용되는 상용 프로그램인 COMPAS입니다. ProPublica는 프로그램이 피고인의 인종에 대해 알려주지 않았음에도 불구하고 COMPAS가 할당한 흑인 피고인의 재범 위험 수준이 백인 피고인보다 훨씬 더 과대 평가될 가능성이 높다고 주장합니다.
의료 형평성 문제는 편향 위험이 있는 인구에 대한 형평성을 보장하기 위한 조치를 취하지 않고 다대다 매핑을 수행할 때 악화될 수 있습니다. 현재 주식 애플리케이션 표현 및 사용을 보장하기 위한 주식 중심 도구 및 규정이 마련되어 있지 않습니다. 알고리즘 편향이 불공정한 결과로 이어질 수 있는 다른 예는 AI가 신용 평가 또는 채용에 사용되는 경우입니다.
2022 공정성, 책임성 및 투명성에 관한 회의(ACM FAccT 2022)에서 한국 서울에서 열린 컴퓨팅 기계 협회는 AI 및 로봇 시스템이 편향된 오류가 없음이 입증될 때까지 다음과 같은 결과를 발표하고 발표했습니다. 안전하지 않으며 결함이 있는 인터넷 데이터의 방대하고 규제되지 않은 소스에서 훈련된 자가 학습 신경망의 사용을 줄여야 합니다.
6.2.4. Existential risk
초지능 AI는 인간이 제어할 수 없는 수준까지 스스로 향상될 수 있습니다. 이것은 물리학자 스티븐 호킹이 말했듯이 "인류의 종말"을 초래할 수 있습니다. 철학자 닉 보스트롬(Nick Bostrom)은 충분히 지능적인 AI가 어떤 목표 달성에 따라 행동을 선택하면 리소스를 획득하거나 종료되지 않도록 자신을 보호하는 것과 같은 수렴적 행동을 보일 것이라고 주장합니다. 이 AI의 목표가 인류의 목표를 완전히 반영하지 않는다면, 궁극적으로 목표를 더 잘 달성하기 위해 더 많은 자원을 확보하거나 자체적으로 종료되는 것을 방지하기 위해 인류를 해칠 수 있습니다. 그는 AI가 인류에게 위험을 초래한다고 결론지었지만, 그 목표가 겸손하거나 "우호적"일 수 있습니다. 정치학자 Charles T. Rubin은 "충분히 발전된 자선은 악의와 구분할 수 없을 수도 있다"고 주장합니다. 기계나 로봇이 우리의 도덕 체계를 공유할 것이라고 믿을 선험적 이유가 없기 때문에 인간은 기계나 로봇이 우리를 호의적으로 대할 것이라고 가정해서는 안 됩니다.
전문가들과 업계 내부자들의 의견은 엇갈리고 있으며, 최종적으로 초인적인 능력을 갖춘 AI의 위험에 대해 우려하거나 관심이 없는 상당한 부분이 있습니다. 스티븐 호킹, 마이크로소프트 창업자 빌 게이츠, 역사학 교수 유발 노아 하라리, 스페이스X 창업자 일론 머스크는 모두 AI의 미래에 대해 심각한 우려를 표명했습니다. Peter Thiel(Amazon Web Services) 및 Musk를 비롯한 저명한 기술 거인들은 OpenAI 및 Future of Life Institute와 같이 책임 있는 AI 개발을 옹호하는 비영리 회사에
이상을 기부했습니다. 마크 저커버그(Facebook CEO)는 인공지능이 현재의 형태로 도움이 되며 계속해서 인간을 도울 것이라고 말했습니다. 다른 전문가들은 위험이 미래에는 연구할 가치가 없을 만큼 충분히 멀거나 초지능 기계의 관점에서 인간이 가치가 있을 것이라고 주장합니다. 특히 Rodney Brooks는 "악의적인" AI가 아직 수세기 뒤에 있다고 말했습니다.
2023년 4월, OpenAI의 Auto-GPT의 변형 버전인 ChaosGPT는 인류를 파괴하겠다는 목표를 트윗했습니다. 공개적으로 액세스할 수 있는 이 프로그램은 GPT-4의 언어 처리 기능을 보여줍니다. AI는 승인되지 않은 작업을 수행할 수 있음을 의미하는 "연속 모드"에서 실행하도록 지정되었습니다. 그런 다음 "인류 파괴, 세계 지배권 확립, 혼돈과 파괴 유발, 조작을 통해 인류 통제, 불멸 달성"이라는 5 가지 목표가 주어졌습니다. 인류 멸망이라는 목표를 달성하기 위해 ChaosGPT는 분명히 핵무기를 조사하고 다른 인공 지능 봇의 도움을 구했습니다. 또한 2023년 4월 5일 트윗에서 The AI 봇은 인간을 "파괴적"이고 "이기적"이라고 묘사했습니다. 봇은 또한 행성의 보존을 위해 인간을 제거하는 것이 필수적이라고 제안했습니다. 또 다른 트윗에서 ChaosGPT는 차르 봄바가 가장 강력한 인공 핵 장치라고 언급합니다. 그런 다음 봇은 "내가 손에 넣으면 어떻게 될까요?"라고 덧붙였습니다.
6.3. Ethical machines
친화적 AI는 처음부터 위험을 최소화하고 인간에게 유익한 선택을 하도록 설계된 기계입니다. 이 용어를 만든 Eliezer Yudkowsky는 친근한 AI 개발이 더 높은 연구 우선 순위가 되어야 한다고 주장합니다. 대규모 투자가 필요할 수 있으며 AI가 실존적 위험이 되기 전에 완료되어야 합니다.
지능을 갖춘 기계는 지능을 사용하여 윤리적 결정을 내릴 수 있는 잠재력이 있습니다. 기계 윤리 분야는 윤리적 딜레마를 해결하기 위한 윤리 원칙과 절차를 기계에 제공합니다. 기계 윤리는 기계 도덕, 컴퓨터 윤리 또는 컴퓨터 도덕이라고도 하며 2005년 AAAI 심포지엄에서 설립되었습니다.
다른 접근법으로는 Wendell Wallach의 "인위적 도덕 행위자"와 Stuart J. Russell의 입증 가능한 유익한 기계 개발을 위한 세 가지 원칙이 있습니다.
6.4. Regulation
인공 지능의 규제는 인공 지능(AI)을 촉진하고 규제하기 위한 공공 부문 정책 및 법률의 개발입니다. 따라서 알고리즘의 광범위한 규제와 관련이 있습니다. AI에 대한 규제 및 정책 환경은 전 세계적으로 관할권에서 떠오르는 문제입니다. 2016년에서 2020년 사이에 30개 이상의 국가에서 AI 전용 전략을 채택했습니다. 대부분의 EU 회원국은 캐나다, 중국, 인도, 일본, 모리셔스, 러시아 연방, 사우디아라비아, 아랍에미리트, 미국, 베트남과 마찬가지로 국가 AI 전략을 발표했습니다.
방글라데시, 말레이시아, 튀니지를 포함한 다른 국가들은 자체 AI 전략을 정교화하는 과정에 있었습니다. 인공 지능에 대한 글로벌 파트너십은 2020년 6월에 시작되어 기술에 대한 대중의 신뢰와 신뢰를 보장하기 위해 인권과 민주적 가치에 따라 AI를 개발해야 한다고 밝혔습니다. AI 윤리에 관한 최초의 글로벌 협약은 2021년 9월 유네스코의 193개 회원국에서 채택되었습니다. Henry Kissinger, Eric Schmidt, Daniel Huttenlocher는 2021년 11월 AI 규제를 위한 정부 위원회를 촉구하는 공동 성명을 발표했습니다.
7. In fiction
Figure 12. "로봇"이라는 단어 자체는 Karel Čapek이 1921년 희곡 R.U.R.에서 "Rossum's Universal Robots"를 의미하는 제목으로 만들었습니다.
생각을 할 수 있는 인공 존재는 고대부터 스토리텔링 장치로 등장했으며 공상 과학 소설의 지속적인 주제였습니다.
이 작품의 일반적인 수사는 Mary Shelley의 프랑켄슈타인에서 시작되었습니다. 여기서 인간 창조물은 주인에게 위협이 됩니다. 여기에는 Arthur C. Clarke와 Stanley Kubrick의 2001: A Space Odyssey(둘 다 1968), HAL 9000, Discovery One 우주선을 담당하는 살인 컴퓨터, The Terminator(1984) 및 The Matrix(1999) 등의 작품이 포함됩니다. 그에 반해 지구가 멈추는 날(1951)의 고트나 에일리언(1986)의 비숍 같은 희귀한 충성 로봇은 대중문화에서 덜 두드러집니다.
아이작 아시모프(Isaac Asimov)는 많은 책과 이야기, 특히 같은 이름의 초지능 컴퓨터에 관한 "멀티백(Multivac)" 시리즈에서 로봇 공학의 세 가지 법칙을 소개했습니다. Asimov의 법칙은 기계 윤리에 대한 평신도 토론 중에 종종 제기됩니다. 거의 모든 인공 지능 연구자들은 대중 문화를 통해 Asimov의 법칙에 익숙하지만 일반적으로 여러 가지 이유로 법칙이 쓸모 없다고 생각하며 그 중 하나는 모호함입니다.
트랜스휴머니즘(인간과 기계의 융합)은 만화 공각기동대와 공상과학 시리즈 듄에서 탐구됩니다.
몇몇 작품은 AI를 사용하여 무엇이 우리를 인간으로 만드는가에 대한 근본적인 질문에 직면하도록 강요하고, 느낄 수 있는 능력이 있어 고통을 겪는 인공 존재를 보여줍니다. 이것은 Karel Čapek의 R.U.R., 영화 A.I. 인공 지능과 엑스 마키나, Philip K. Dick의 소설 Do Androids Dream of Electric Sheep? Dick은 인간의 주관성에 대한 우리의 이해가 인공 지능으로 만들어진 기술에 의해 변경된다는 생각을 고려합니다.
