Frozen Lake 환경 개요
-
FrozenLake는 OpenAIGym에서 제공하는 강화학습 환경 중 하나로, 간단한 그리드 기반 게임입니다. -
에이전트가 얼어붙은 호수에서 미끄럽지 않은 곳을 지나 목표 지점(Goal)에 도달하는 것을 목표로 합니다.
- 에이전트는 장애물(구멍, Hole)을 피해야 하며, 잘못된 경로를 선택하면 게임이 종료됩니다.
Frozen Lake의 주요 개념
-
격자판(Grid World)
-
기본적으로
4x4또는8x8격자판으로 구성.-
S(Start): 에이전트가 시작하는 위치. -
F(Frozen): 안전한 얼음 길, 에이전트가 자유롭게 이동 가능. -
H(Hole): 구멍, 에이전트가 떨어지면 실패. -
G(Goal): 목표 지점, 도착하면 보상을 받으며 에피소드 종료.
-
-
-
목표
- 에이전트가 환경을 탐험하여 최적의 경로를 학습하고, 시작 지점(S)에서 목표(G)까지 안전한 경로를 학습합니다.
-
행동(Actions)
-
에이전트는 4가지 동작 중 하나를 선택
-
0: 좌로 이동(Left) -
1: 아래로 이동(Down) -
2: 우로 이동(Right) -
3: 위로 이동(Up)
-
-
-
보상 구조
-
목표 지점(G)에 도달하면 1점을 받습니다.
-
다른 모든 상황에서는 보상이 0입니다.
-
-
is_slippery옵션-
True: 행동 결과가 미끄러질 수 있음(확률적으로 엉뚱한 방향으로 이동). -
False: 행동이 정확히 명령한 대로 이동.
-
Frozen Lake 코드
Q-Learning 학습 코드
- 다음 코드는
4x4 Frozen Lake에서 Q-Learning 알고리즘을 사용해 최적의 정책을 학습하는 예제입니다.
import numpy as np
import gym
import warnings
# DeprecationWarning 무시
warnings.filterwarnings("ignore", category=DeprecationWarning)
# FrozenLake 환경 생성
env = gym.make("FrozenLake-v1", is_slippery=False)
# Q-테이블 초기화 (상태 x 행동)
Q_table = np.zeros([env.observation_space.n, env.action_space.n])
# 하이퍼파라미터
learning_rate = 0.8 # 학습률: 기존 값과 새로운 값 간 균형
discount_factor = 0.95 # 감가율(Gamma): 미래 보상 중요도
epsilon = 0.1 # 탐험/탐사 비율(Epsilon-Greedy)
num_episodes = 2000 # 학습 에피소드 수
max_steps_per_episode = 100 # 한 에피소드 내 최대 이동 수
# Q-Learning 알고리즘 학습
for episode in range(num_episodes):
state, _ = env.reset() # 환경 초기화
done = False
step = 0
while not done and step < max_steps_per_episode:
# Epsilon-Greedy 정책
if np.random.uniform(0, 1) < epsilon:
action = env.action_space.sample() # 무작위 행동
else:
action = np.argmax(Q_table[state, :]) # Q-테이블 기반 행동
# 행동 실행 & 다음 상태, 보상, 종료 여부 받기
new_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
# Q-값 업데이트 (Bellman Equation)
Q_table[state, action] = Q_table[state, action] + \
learning_rate * (reward + discount_factor * np.max(Q_table[new_state, :]) - Q_table[state, action])
# 상태 업데이트
state = new_state
step += 1
# 훈련된 Q-테이블 출력
print("훈련된 Q-테이블:")
print(Q_table)
# 학습된 정책 테스트 및 시각화
state, _ = env.reset()
done = False
step = 0
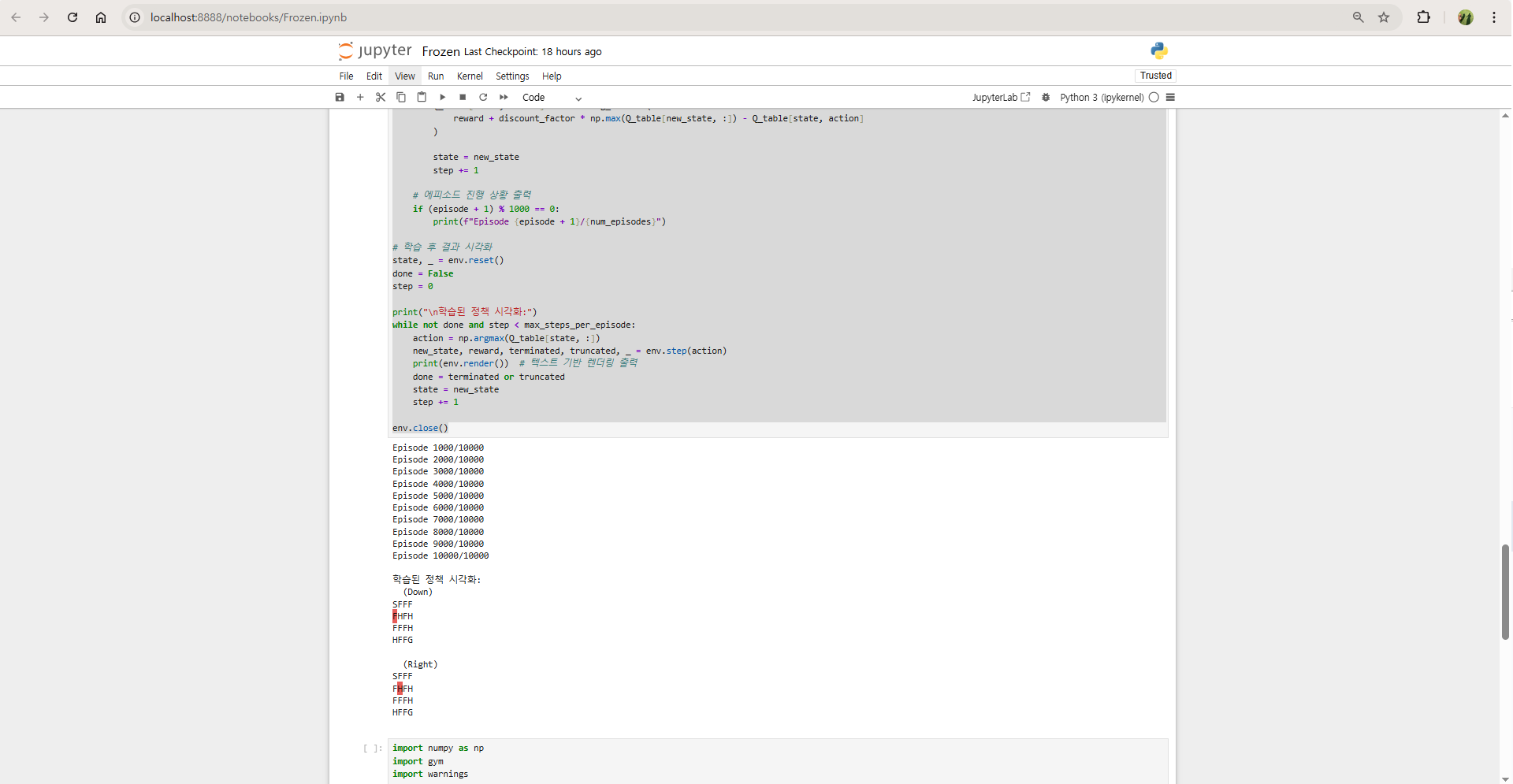
print("\n학습된 정책 시각화:")
while not done and step < max_steps_per_episode:
action = np.argmax(Q_table[state, :]) # 최적 행동 선택
state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
env.render() # 환경 렌더링
step += 1
env.close()
코드 설명
1. 라이브러리와 환경 설정
env = gym.make("FrozenLake-v1", is_slippery=False)-
Frozen Lake 환경 생성.
-
is_slippery=False는 미끄럼을 방지하여 행동 결과가 정확히 명령대로 수행되도록 설정.
2. Q-테이블 초기화
Q_table = np.zeros([env.observation_space.n, env.action_space.n])-
env.observation_space.n: 상태(State)의 총 개수. -
env.action_space.n: 가능한 행동(Action)의 총 개수. -
모든 Q-값을 0으로 초기화.
3. Q-Learning 알고리즘
Epsilon-Greedy 정책
if np.random.uniform(0, 1) < epsilon:
action = env.action_space.sample() # 탐험: 무작위 행동
else:
action = np.argmax(Q_table[state, :]) # 탐사: Q-테이블 기반 최적 행동 선택-
탐험(Exploration): 임의로 다른 상태를 살펴봄.
-
탐사(Exploitation): 학습된 Q-테이블을 참고하여 최적의 행동을 선택.
Q-값 업데이트
Q_table[state, action] = Q_table[state, action] + \
learning_rate * (reward + discount_factor * np.max(Q_table[new_state, :]) - Q_table[state, action])- Bellman Equation을 기반으로, 에이전트는 다음 상태에서의 최대 가치와 현재 보상을 바탕으로 Q-값을 갱신.
4. 학습 종료 후 테스트
while not done and step < max_steps_per_episode:
action = np.argmax(Q_table[state, :]) # 학습된 정책에서 최적 행동 루프
...
env.render() # 현재 상태를 출력- 학습이 완료된 후, 에이전트가 학습한 정책을 따라가는 과정을 시각적으로 출력.
Q-Learning의 한계
-
상태 공간이 커지거나 복잡하면 Q-테이블 학습 방식은 한계가 있음.
-
FrozenLake는 환경이 비교적 단순하므로 잘 작동하지만, 복잡한 환경에는 Deep Q-Learning(DQN) 등의 확장 방법이 필요.
실행 결과
-
훈련된 Q-테이블
-
학습이 진행되며, 에이전트는 목표(Goal)에 빠르게 도달하는 경로를 배움.
-
최종 Q-테이블의 값은 각 상태-행동 쌍에서의 가치를 나타냄.
-
값이 클수록 해당 행동이 더 나은 정책이라는 것을 의미.
-
-
Frozen Lake 시각화
-
학습된 정책을 따라 에이전트가 시작 지점(S)에서 목표 지점(G)으로 이동.
-
이동 경로와 상태가 콘솔 화면에 출력됨.
-
위 코드를 실행하면 에이전트는 학습 과정을 통해 최적의 이동 정책을 학습하고 목표 지점(G)으로 안전하게 도달합니다. Frozen Lake와 Q-Learning을 통해 강화학습의 핵심 원리를 직접 경험할 수 있습니다!
수정 버전 - Frozen Lake: KeyboardInterrupt 문제 해결
KeyboardInterrupt는 사용자가 실행 도중 프로그램을 강제로 중단하거나, 코드가 렌더링 과정에서 응답이 없어 무한정 대기하게 될 때 발생할 수 있습니다.
원인 1: Render 모드로 인한 대기
-
render_mode="human"설정 시, 기본 프레임 속도가 매우 느려(약 4 FPS), 학습 과정 전체가 지연될 수 있습니다. -
느려진 속도로 인해 사용자가 진행을 중단해서 발생한 문제입니다.
원인 2: 무한 루프
-
학습 단계에서 종료 조건(
done)이 충족되지 못한 채 루프가 계속될 수 있음. -
학습 에피소드 중 에이전트가 반복적으로 잘못된 경로를 탐험하면서 중단되지 않음.
해결 방법
방법 1: 렌더링 모드 변경
- 텍스트 기반 출력으로 바꾸거나 GUI 출력 속도를 최적화합니다.
텍스트 기반 렌더링 사용
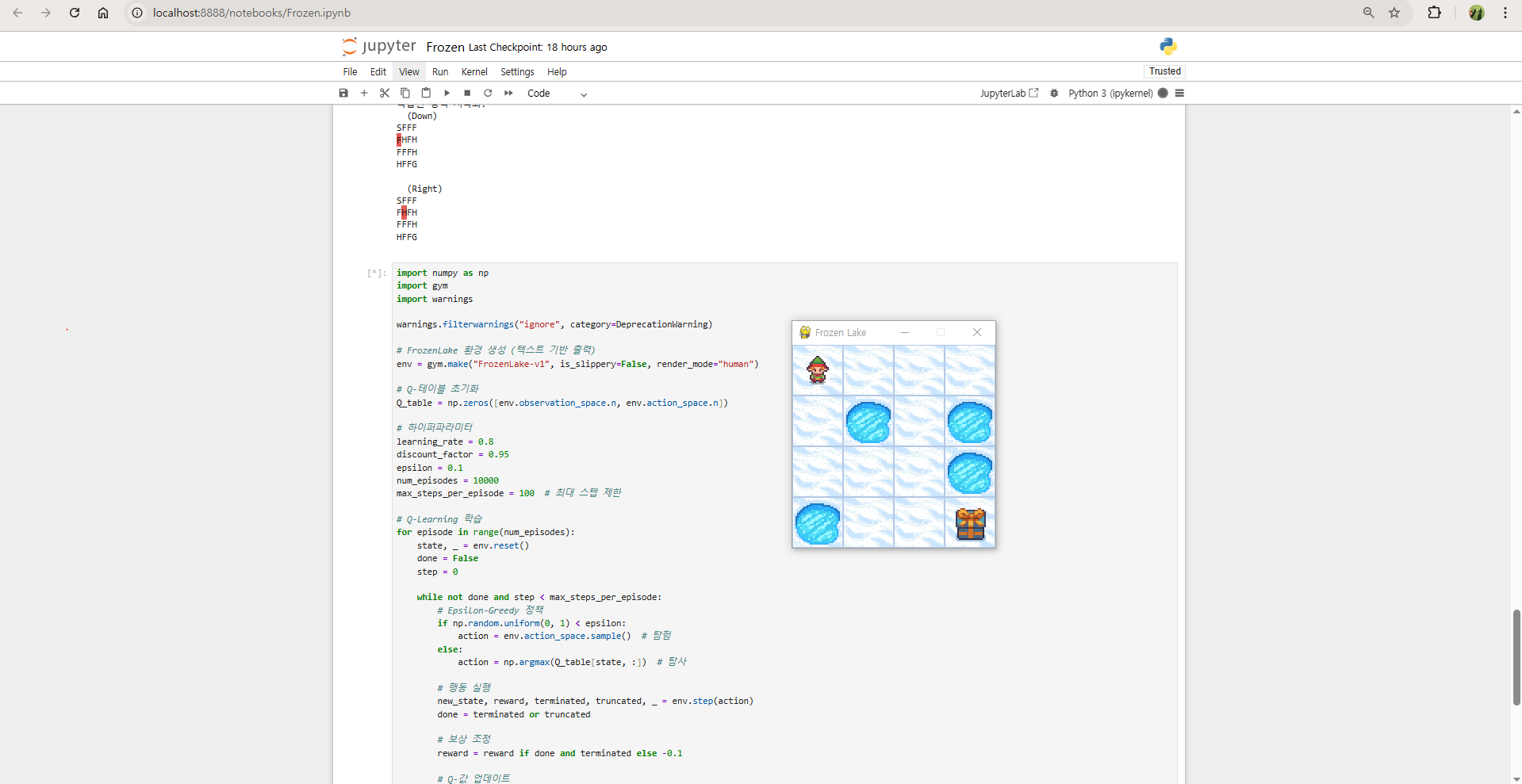
render_mode="ansi"를 설정하면 텍스트 기반 출력으로 실행됩니다. 이 설정은pygame설치 없이 실행 가능하며 출력 속도가 빠릅니다.
env = gym.make("FrozenLake-v1", is_slippery=False, render_mode="ansi")GUI 렌더링 속도 조정
render_mode="human"을 사용할 경우, 렌더링 속도를 증가시키기 위해 FPS 설정을 조정합니다.
env.metadata["render_fps"] = 60 # 기본값(4 FPS)에서 60 FPS로 조정방법 2: 렌더링 생략
- 학습 중에는 렌더링을 생략하고, 학습이 끝난 후에만 시각화할 수도 있습니다.
학습 중 렌더링 생략
# 학습 중에는 env.render()를 호출하지 않음
# 학습 후 정책을 시각화하며 확인방법 3: 학습 루프 종료 조건 설정
-
에피소드가 너무 길어지지 않도록 최대 스텝 제한을 추가합니다.
-
max_steps_per_episode를 설정해 무한 루프를 방지
max_steps_per_episode = 100- 지난 코드에서 종료 조건 추가
while not done and step < max_steps_per_episode:
# 행동 수행, Q-테이블 업데이트 코드
step += 1최종 수정된 코드
import numpy as np
import gym
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
# FrozenLake 환경 생성 (텍스트 기반 출력)
env = gym.make("FrozenLake-v1", is_slippery=False, render_mode="ansi")
# Q-테이블 초기화
Q_table = np.zeros([env.observation_space.n, env.action_space.n])
# 하이퍼파라미터
learning_rate = 0.8
discount_factor = 0.95
epsilon = 0.1
num_episodes = 10000
max_steps_per_episode = 100 # 최대 스텝 제한
# Q-Learning 학습
for episode in range(num_episodes):
state, _ = env.reset()
done = False
step = 0
while not done and step < max_steps_per_episode:
# Epsilon-Greedy 정책
if np.random.uniform(0, 1) < epsilon:
action = env.action_space.sample() # 탐험
else:
action = np.argmax(Q_table[state, :]) # 탐사
# 행동 실행
new_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
# 보상 조정
reward = reward if done and terminated else -0.1
# Q-값 업데이트
Q_table[state, action] += learning_rate * (
reward + discount_factor * np.max(Q_table[new_state, :]) - Q_table[state, action]
)
state = new_state
step += 1
# 에피소드 진행 상황 출력
if (episode + 1) % 1000 == 0:
print(f"Episode {episode + 1}/{num_episodes}")
# 학습 후 결과 시각화
state, _ = env.reset()
done = False
step = 0
print("\n학습된 정책 시각화:")
while not done and step < max_steps_per_episode:
action = np.argmax(Q_table[state, :])
new_state, reward, terminated, truncated, _ = env.step(action)
print(env.render()) # 텍스트 기반 렌더링 출력
done = terminated or truncated
state = new_state
step += 1
env.close()수정 사항 요약
-
render_mode="ansi"추가-
텍스트 기반 렌더링 사용 (GUI 렌더링 없이 실행 가능).
-
GPU 리소스 문제 없는 환경에서 실행 속도가 빠름.
-
-
FPS 속도 조정
- GUI 렌더링 시 실행 속도를 변경:
env.metadata["render_fps"] = 60.
- GUI 렌더링 시 실행 속도를 변경:
-
최대 스텝 제한
- 에피소드가 너무 길어지지 않도록
max_steps_per_episode로 제한.
- 에피소드가 너무 길어지지 않도록
-
학습 생략
- 학습 중 렌더링을 끄고, 학습 후 시각화만 수행.
결과
-
FrozenLake학습이 빨라지고 무한 루프 또는 중단되는 문제가 해결됩니다. -
GUI 렌더링 또는 텍스트 출력이 사용자 정의 속도로 실행됩니다.
훈련된 Q-테이블:
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
...
[0. 0. 0. 0.]]
학습된 정책 시각화:
SFFF
FHFH
FFFH
HFFG