Gemini Embedding 2: Our first natively multimodal embedding model
Artificial Intelligence
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/
New modalities and flexible output dimensions
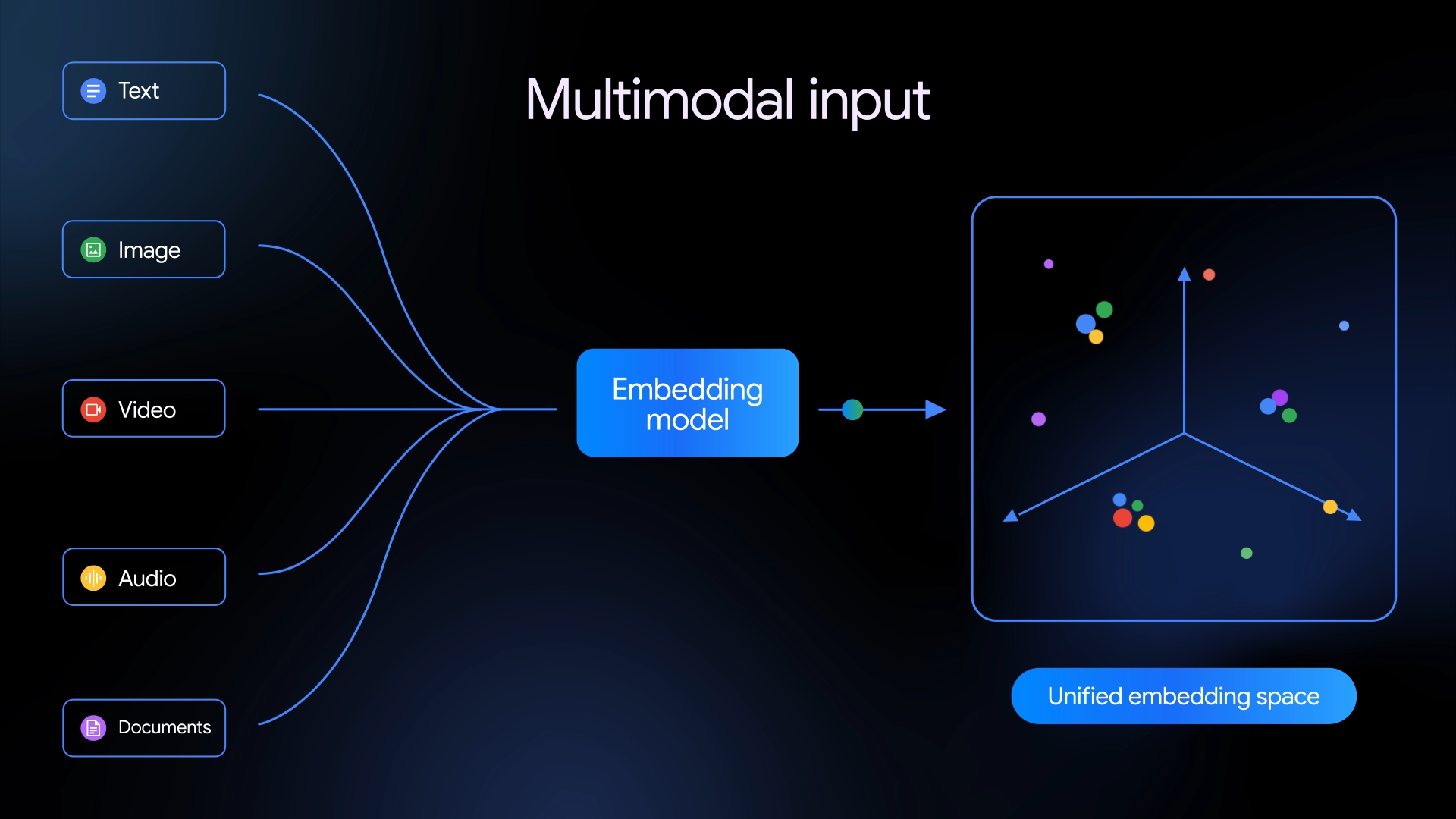
The model is based on Gemini and leverages its best-in-class multimodal understanding capabilities to create high-quality embeddings across:
Text: supports an expansive context of up to 8192 input tokens
Images: capable of processing up to 6 images per request, supporting PNG and JPEG formats
Videos: supports up to 120 seconds of video input in MP4 and MOV formats
Audio: natively ingests and embeds audio data without needing intermediate text transcriptions
Documents: directly embed PDFs up to 6 pages long
Beyond processing one modality at a time, this model natively understands interleaved input so you can pass multiple modalities of input (e.g., image + text) in a single request. This allows the model to capture the complex, nuanced relationships between different media types, unlocking more accurate understanding of complex, real-world data.
https://ai.google.dev/gemini-api/docs/models/gemini-embedding-2-preview?hl=ko
