Ollama 란?
-
Ollama(올라마)는 로컬 PC(윈도우, 맥, 리눅스 등)에서 직접 대형 언어 모델(LLM)들을 손쉽게 다운로드하고 실행할 수 있게 해주는 도구입니다.
-
Ollama의 특징
-
모델 다운로드와 실행이 매우 간편: 터미널 한 줄 명령으로 유명한 오픈소스 LLM(예: Llama2, Mistral, Gemma 등)을 바로 받아 실행할 수 있습니다.
-
로컬 실행: 인터넷에 연결하지 않아도 개인 PC에서 LLM의 생성 AI 기능을 사용할 수 있어 개인정보 유출 걱정이 적습니다.
-
API 지원: Ollama에서 실행 중인 모델에 OpenAI 스타일 API로 접근할 수 있어, 기존 앱에 쉽게 연동 가능합니다.
-
경량화된 모델 최적화: PC 환경에서 효율적으로 작동하도록 모델 최적화가 되어 있습니다.
즉, Ollama는 개별 PC에서도 강력한 LLM의 생성형 AI 기능을 쉽고 빠르게 이용할 수 있게 해주는 플랫폼입니다.
-
1. Ollama의 작동 순서 (일반적인 예시)
-
Ollama 설치
- 사용자가 로컬 환경(Windows, Mac, Linux)에 Ollama를 설치합니다. 보통 설치 방법에는 공식 사이트(GUI) 또는 터미널(커맨드라인) 설치가 있습니다.
-
모델 내려받기(Pull)
- 원하는 LLM(예: llama2, mistral 등)을
ollama pull 모델이름명령으로 다운로드합니다.
- 원하는 LLM(예: llama2, mistral 등)을
-
Ollama 서버 실행
- Ollama가 백그라운드(서버 프로세스)로 실행됩니다. 이때 API 서버(REST API)도 함께 켜집니다.
-
LLM 모델 실행 및 관리
-
Ollama 프로세스는 여러 LLM 모델(다운로드된)을 관리할 수 있습니다.
-
단일 또는 여러 개의 모델을 동시에 로드/언로드 가능합니다.
-
-
API 요청 처리
-
사용자는
curl, Postman, 또는 애플리케이션(예: Langchain)에서 Ollama가 제공하는 OpenAI 호환 REST API 엔드포인트로 대화/프롬프트 요청을 보냅니다. -
Ollama가 요청을 받아 모델에 입력을 전달하고, 결과(생성 텍스트 등)를 다시 반환합니다.
-
-
응용
- Langchain, 로컬 커스텀 챗봇, 개발 중인 앱 등에서 Ollama API를 호출해서 자연어 처리 기능을 사용합니다.
2. Ollama와 Docker의 관계
-
Ollama는 내부적으로 Docker 컨테이너 방식을 지원합니다.
-
Ollama를 Docker 컨테이너로 실행할 수도 있고, Ollama가 여러 LLM 모델(특히 가상 머신 격리가 필요한 경우)을 각각 Docker 컨테이너로 관리하여 학습·생성 작업을 처리할 수도 있습니다
. -
이렇게 하면, 여러 모델 또는 다양한 환경에서 충돌 없이 효율적으로 LLM을 실행할 수 있습니다.
3. Ollama 내부 동작 관계도 & 전체 구조
-
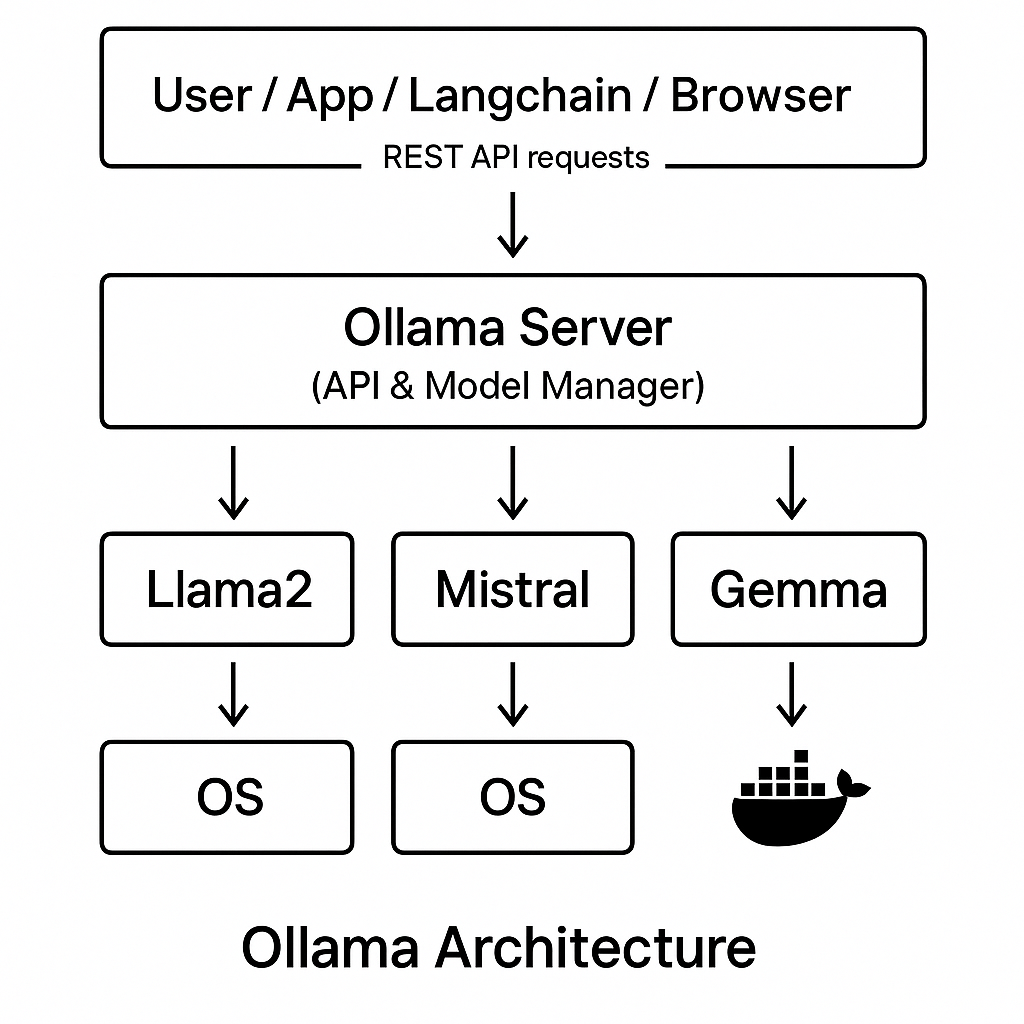
아래는 Ollama의 기본 구조(관계도) 예시입니다.
- Ollama 서버가 로컬 환경(혹은 Docker)에 설치되어 있고, API를 통해 클라이언트 및 외부 응용프로그램과 통신하는 구조입니다.
┌─────────────────────────────┐
│ 사용자/앱/ │
│ (브라우저, Postman, Langchain)│
└────────────┬────────────────┘
│ (REST API 요청)
▼
┌─────────────────┐
│ Ollama 서버 │
│ ----------------│
│ REST API │
│ LLM 매니저 │
└────────┬────────┘
│ (모델 관리, 실행)
┌─────────────┼─────────────────────┐
│ │ │
▼ ▼ ▼
┌──────┐ ┌──────────┐ ┌──────────┐
│Llama2│ │Mistral │ ... │Gemma │
│모델 │ │모델 │ │모델 │
└─┬────┘ └─────┬────┘ └─────┬────┘
│ │ │
█████████████████████████████████████████████████
(직접 실행 or Docker 컨테이너)
█████████████████████████████████████████████████-
Ollama 서버(데몬)이 REST API를 열어둡니다.
-
사용자는 API를 통해 요청(프롬프트 등)을 보냅니다.
-
Ollama가 요청에 따라 내부적으로 로드된 모델에 작업을 위임합니다.
-
모델은 Docker 컨테이너 내 실행일 수도 있고, 그냥 OS 프로세스일 수도 있습니다.
참고: Docker로 Ollama 실행 예시
docker run -d -p 11434:11434 --name ollama ollama/ollama- 위와 같이 Docker에서 Ollama 이미지를 실행하면, 외부 애플리케이션이
localhost:11434포트에서 Ollama OpenAI API와 통신할 수 있습니다.
요약
-
Ollama는 강력한 LLM을 설치/실행/API화하는 도구
-
원할 경우 Docker로 실행해 격리와 유연성을 높일 수 있음
-
Ollama REST API를 통해 다양한 외부 앱(브라우저, Langchain 등)에서 활용 가능
-
내부적으로
모델 선택 → 프롬프트 전달 → 결과 반환의 구조 -
여러 LLM 모델을 손쉽게 관리하고, 로컬에서 개인정보 안전하게 처리 가능
[사용자/앱/브라우저/Langchain]
|
(API 요청)
v
[Ollama API 서버]
|
┌─────Model Pool─────┐
│ Llama2 │
│ Mistral │
│ Gemma ... │
└────────────────────┘
(Docker or Direct)