https://devocean.sk.com/blog/techBoardDetail.do?ID=166910&boardType=techBlog
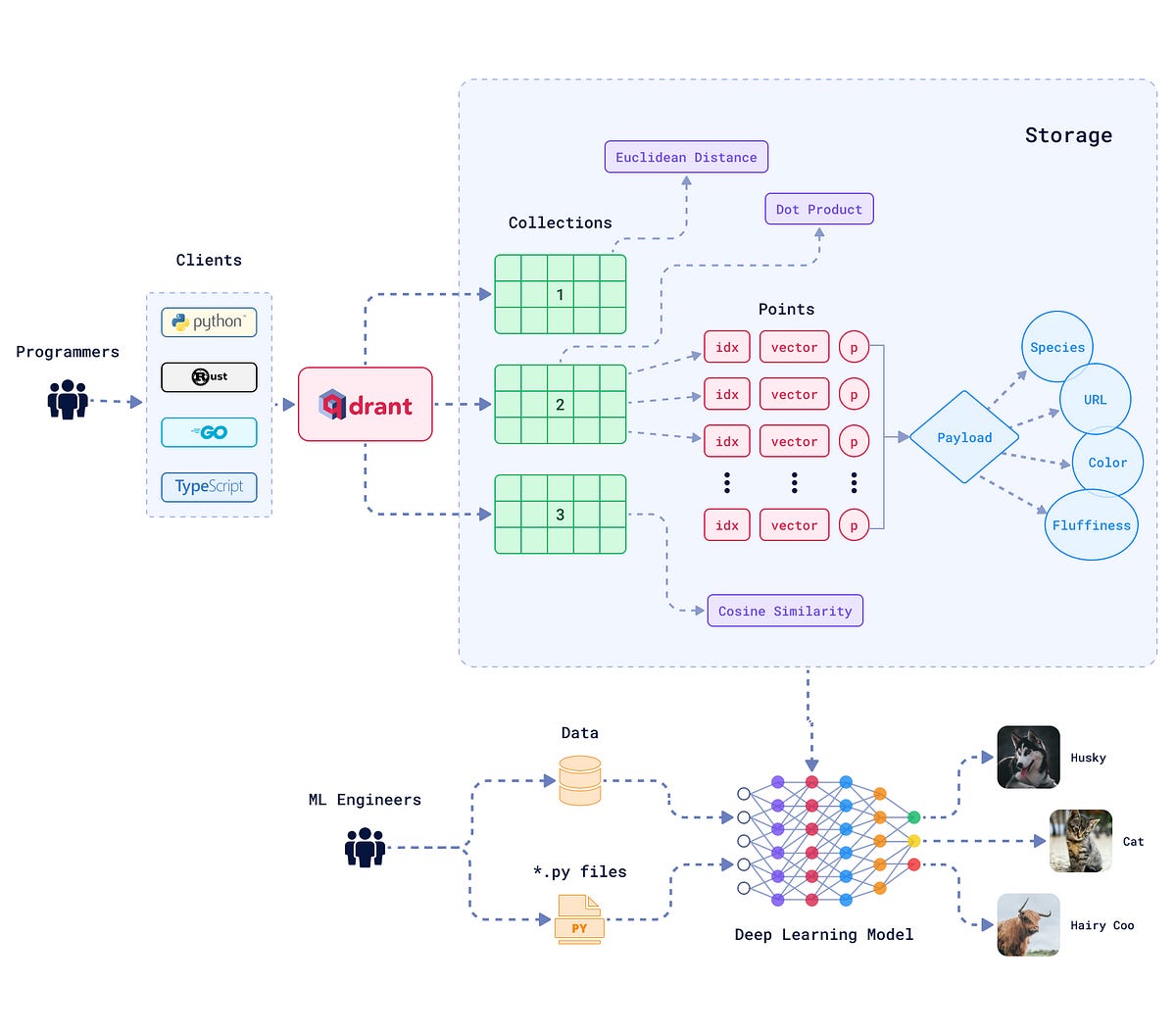
Qdrant Vector DB에서 사용하는 용어를 데이터의 생성부터 CRUD 측면으로 이해해 보는 것이 좋을 것 같습니다.
벡터로 다루는 것들
-
이미지·멀티모달: 임베딩으로 “비슷한 이미지 검색”, “이 사진과 유사한 상품/문서 찾기”
-
테이블/행 단위: DB 행을 메타데이터+텍스트로 묶어서 임베딩 → “이 조건이랑 비슷한 케이스/레코드 찾기”
-
대화·세션: 이전 대화를 청크/요약해서 벡터로 넣어두면 “비슷한 과거 대화/해결 사례” 검색
엔티티·관계: 사람, 프로젝트, 이슈 등을 벡터로 두고 “이 사람이 한 일과 비슷한 작업”, “이 이슈와 유사한 과거 이슈” 검색 -
코드/함수: 코드 조각 임베딩 → “이 로직이랑 비슷한 코드”, “이 에러와 비슷한 과거 패턴” 검색
- 즉, RAG = “문서 검색해서 LLM에 넣기”만 있는 게 아니라, “비슷한 것 찾기”가 필요한 곳이면 다 벡터(임베딩 + 벡터 DB)가 들어갈 수 있어요.
'영화 추천 시스템' 예시를 '기업용 인재 채용 관리 시스템(AI Recruitment System)'으로 전환하여 설명해 드리겠습니다.
MLOps 엔지니어로서 실무에서 RAG(Retrieval-Augmented Generation)를 구축할 때, 문서나 이력서 데이터를 다루는 경우가 많으므로 이 예시가 더 와닿으실 것입니다.
AI 인재 채용 시스템으로 이해하는 Qdrant
[가정]
- 당신은 수만 명의 지원자 중에서 공고에 가장 적합한 인재를 찾아주는 AI 채용 어시스턴트를 구축하게 되었습니다.
- 이 시스템은 지원자의 이력서 내용을 벡터로 변환하여 저장하고 검색합니다.
1. 인재 풀의 저장소: Collection과 Point
-
Qdrant에 데이터를 저장하려면 먼저 공간을 설계해야 합니다.
-
Collection (지원자 명단): 모든 지원자 데이터를 담는 큰 바구니입니다. (
candidates) -
Point (개별 지원자): 이력서 한 장 한 장이 하나의 Point가 됩니다.
-
Collection 생성하기 (API 예시)
POST /collections
{
"name": "candidates",
"vector_size": 768,
"distance": "Cosine"
}-
vector_size: BERT나 RoBERTa 같은 모델을 사용하여 이력서를 벡터화했을 때의 크기(768)입니다. -
distance: 'Cosine' 유사도를 사용하여 기술적 역량이 얼마나 유사한지 계산합니다.
2. 데이터를 다루는 방법: CRUD와 Payload 관리
Create (Upsert) - 지원자 등록
- 지원자의 이력서 텍스트를 벡터로 변환하여 정보를 추가합니다.
PUT /collections/candidates/points
{
"points": [
{
"id": 101,
"vector": [0.05, 0.12, -0.03, ...],
"payload": {
"name": "김철수",
"skills": ["Python", "PyTorch", "Docker"],
"experience_years": 5,
"current_role": "ML Engineer"
}
}
]
}Set Payload - 면접 결과 업데이트
- 기존 지원자 정보에 면접 점수나 새로운 스킬을 추가합니다.
POST /collections/candidates/points/101/payload
{
"payload": {
"interview_score": 9.5,
"status": "Passed"
}
}Delete Payload - 민감 정보 삭제
- 개인정보 보호를 위해 특정 필드(예: 전화번호)만 삭제해야 할 때 사용합니다.
DELETE /collections/candidates/points/101/payload
{
"keys": ["phone_number"]
}Delete - 지원자 정보 완전 삭제
- 지원자가 정보 삭제를 요청하거나 탈퇴했을 때 Point 자체를 제거합니다.
3. 스마트한 인재 탐색: Similarity 및 Hybrid Search
Similarity Search - "우리 회사 에이스와 닮은 사람 찾기"
- 현재 성과가 좋은 '에이스 엔지니어'의 이력서 벡터를 쿼리로 사용하여, 가장 유사한 역량을 가진 지원자 5명을 찾습니다.
POST /collections/candidates/points/search
{
"vector": [0.05, 0.12, -0.03, ...],
"top": 5
}
Hybrid Search - "특정 기술을 가진 경력직 찾기"
- 단순히 느낌이 비슷한 사람을 찾는 게 아니라, "Python을 할 줄 아는(Filter) + 3년 이상 경력(Filter) 중에서 + 역량이 유사한 사람"을 찾습니다.
POST /collections/candidates/points/search
{
"vector": [0.1, 0.3, ...],
"top": 3,
"filter": {
"must": [
{ "key": "skills", "match": { "value": "Python" } },
{ "key": "experience_years", "range": { "gte": 3 } }
]
}
}대규모 데이터 탐색: Scroll
-
우리 회사 인재 풀에 지원자가 10만 명이라면 한 번에 볼 수 없습니다.
- 이때 Scroll 기능을 사용하여 페이지를 넘기듯 확인합니다.
POST /collections/candidates/points/scroll
{
"limit": 20,
"with_payload": true
}- 한 번에 20명씩 끊어서 데이터를 가져오며, 다음 페이지를 호출할 때
offset을 사용하여 연결합니다.
용어 요약 (채용 시스템 버전)
-
Collection: 전체 인재 데이터베이스 (예:
tech_talent_pool) -
Point: 지원자 1명의 프로필 (ID + 벡터 + 이력 내용)
-
Vector: 이력서 텍스트를 AI 모델이 숫자로 압축한 결과물
-
Payload: 지원자 이름, 기술 스택, 경력 연수 등 검색에 필요한 '메타데이터'
-
Upsert: 새 지원자 등록 또는 기존 지원자 경력 업데이트
-
Hybrid Search: "기술 스택(필터) + 직무 적합도(벡터)"를 결합한 정교한 검색
MLOps 관점
영화 추천과 달리 채용이나 RAG 시스템에서는 Filter(Payload)의 역할이 매우 중요합니다. Qdrant는 인덱싱된 필드에 대해 매우 빠른 필터링을 지원하므로, 자주 검색 조건으로 쓰이는경력,기술스택,거주지등은 Payload에 넣고 인덱스를 생성해두는 것이 성능 최적화의 핵심입니다.
