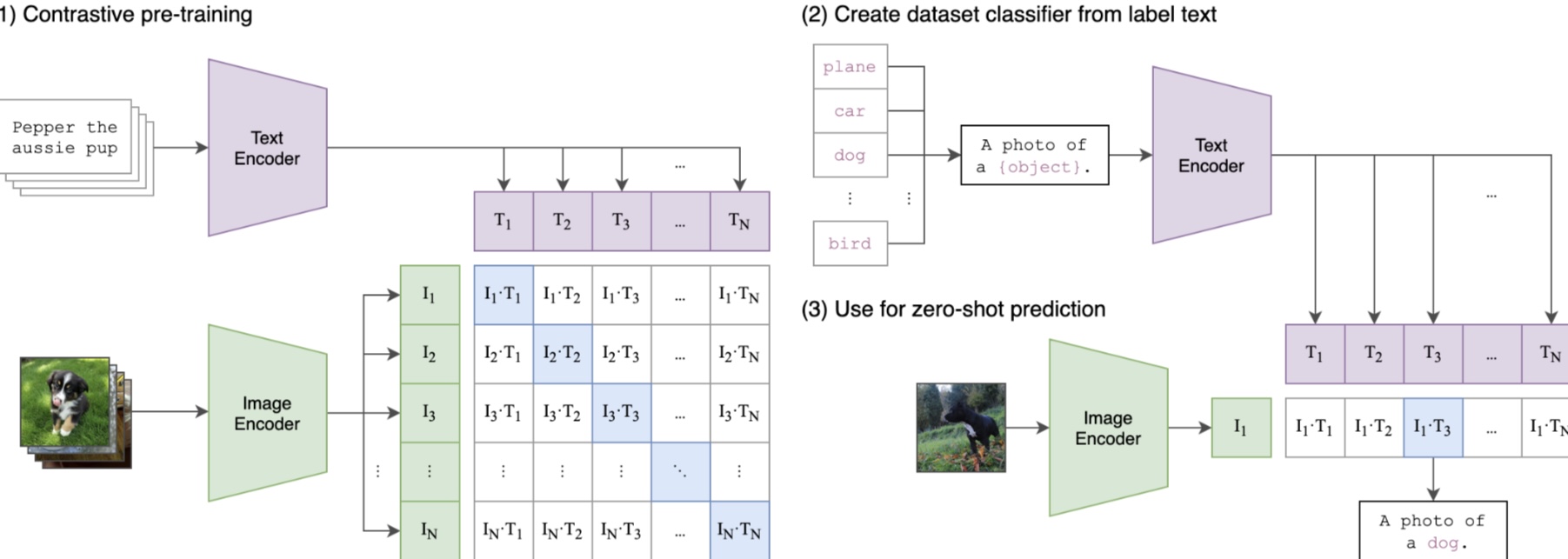
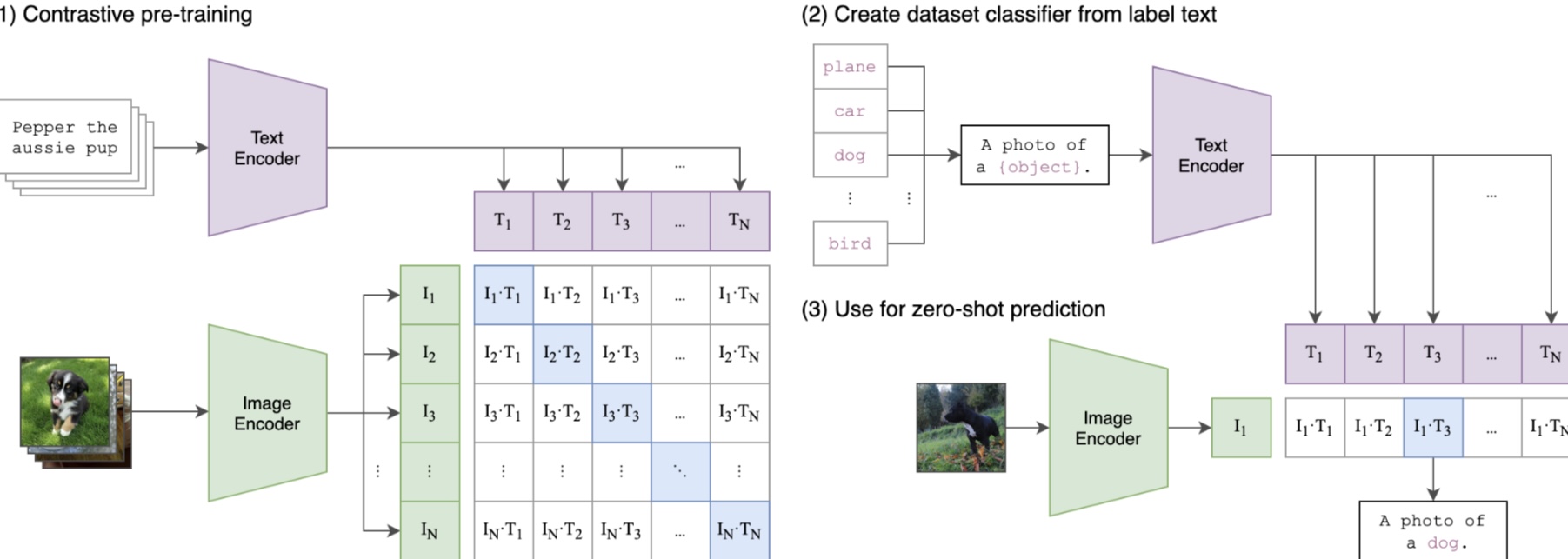
"바나나를 그려줘" 요청이 들어왔을 때, 이미지 벡터 DB에서 바나나를 찾는 전체 과정이야.
전체 흐름 요약
사용자 입력 → 텍스트 임베딩 → 벡터 유사도 검색 → 이미지 반환
단계별 상세 과정
1. 입력 처리 (Query Encoding)
"바나나를 그려줘" 입력이 들어오면 텍스트 전처리로 "banana" 또는 "바나나" 키워드를 추출하고, CLIP text encoder를 사용해 텍스트를 임베딩 벡터로 변환한다.
query_vec = [0.23, -0.11, 0.87, ..., 0.45] // 512~1536차원핵심은 텍스트와 이미지를 같은 임베딩 공간에 매핑하는 모델이 필요하다는 점이다. CLIP이 대표적이다.
2. Vector DB에서 유사도 검색 (ANN Search)
Vector DB에는 이미 이미지들이 아래처럼 저장되어 있다.
image_id | embedding | metadata
img_001 | [0.21, -0.09, 0.85, ..., 0.43] | tag: "banana"
img_002 | [0.10, 0.55, 0.03, ..., 0.77] | tag: "apple"
img_003 | [0.19, -0.12, 0.89, ..., 0.41] | tag: "banana"검색 쿼리:
results = vector_db.search(
query_vector=query_vec,
top_k=5,
metric="cosine_similarity"
)코사인 유사도 계산:
similarity = (query_vec · stored_vec) / (|query_vec| x |stored_vec|)
img_001: similarity = 0.97 (바나나)
img_002: similarity = 0.31 (사과)
img_003: similarity = 0.95 (바나나)3. 인덱싱 알고리즘
전체 벡터를 브루트포스로 비교하면 느리기 때문에 ANN(Approximate Nearest Neighbor) 알고리즘을 사용한다.
HNSW (Hierarchical Navigable Small World) - Pinecone, Weaviate 기본값
FAISS IVF - Facebook 오픈소스
ScaNN - GoogleHNSW는 계층 구조로 탐색 범위를 좁혀가며 최근접 벡터를 근사 탐색한다.
Layer 2 (희소): [img_050] - [img_001]
Layer 1 (중간): [img_022] - [img_001] - [img_089]
Layer 0 (밀집): [img_003] - [img_001] - [img_047] - ...
최종 후보군4. 결과 반환 및 활용
[
{ "id": "img_001", "score": 0.97, "url": "s3://bucket/banana1.png" },
{ "id": "img_003", "score": 0.95, "url": "s3://bucket/banana2.png" },
{ "id": "img_007", "score": 0.91, "url": "s3://bucket/banana3.png" },
]이후 선택지는 두 가지다. 검색 기반 시스템은 가장 유사한 이미지를 그대로 반환하고, 생성 기반 시스템은 검색 결과를 레퍼런스로 이미지 생성 모델(Stable Diffusion 등)에 넘긴다.
CLIP이 핵심인 이유
텍스트: "banana" -> [Text Encoder] -> vec_t
이미지: (banana) -> [Image Encoder] -> vec_i
-> 같은 공간에서 vec_t ≈ vec_i (유사도 높음)
-> 텍스트로 이미지를 검색 가능CLIP은 4억 쌍의 (텍스트, 이미지) 데이터로 학습되어, "바나나"라는 텍스트 벡터가 바나나 이미지 벡터와 가까운 공간에 위치하게 된다.
전체 아키텍처 요약
"바나나를 그려줘"
|
[CLIP Text Encoder] -> query_vec (512d)
|
[Vector DB: HNSW 인덱스 탐색]
|
[Top-K 유사 이미지 후보]
|
반환(RAG) / 생성 모델 레퍼런스로 활용Vector DB는 이미지 자체가 아니라 이미지의 의미를 압축한 벡터를 저장한다. 텍스트 쿼리도 같은 방식으로 벡터화되기 때문에, 언어 경계를 넘어서 의미 기반 검색이 가능하다.

Hi!