Rerank 란?
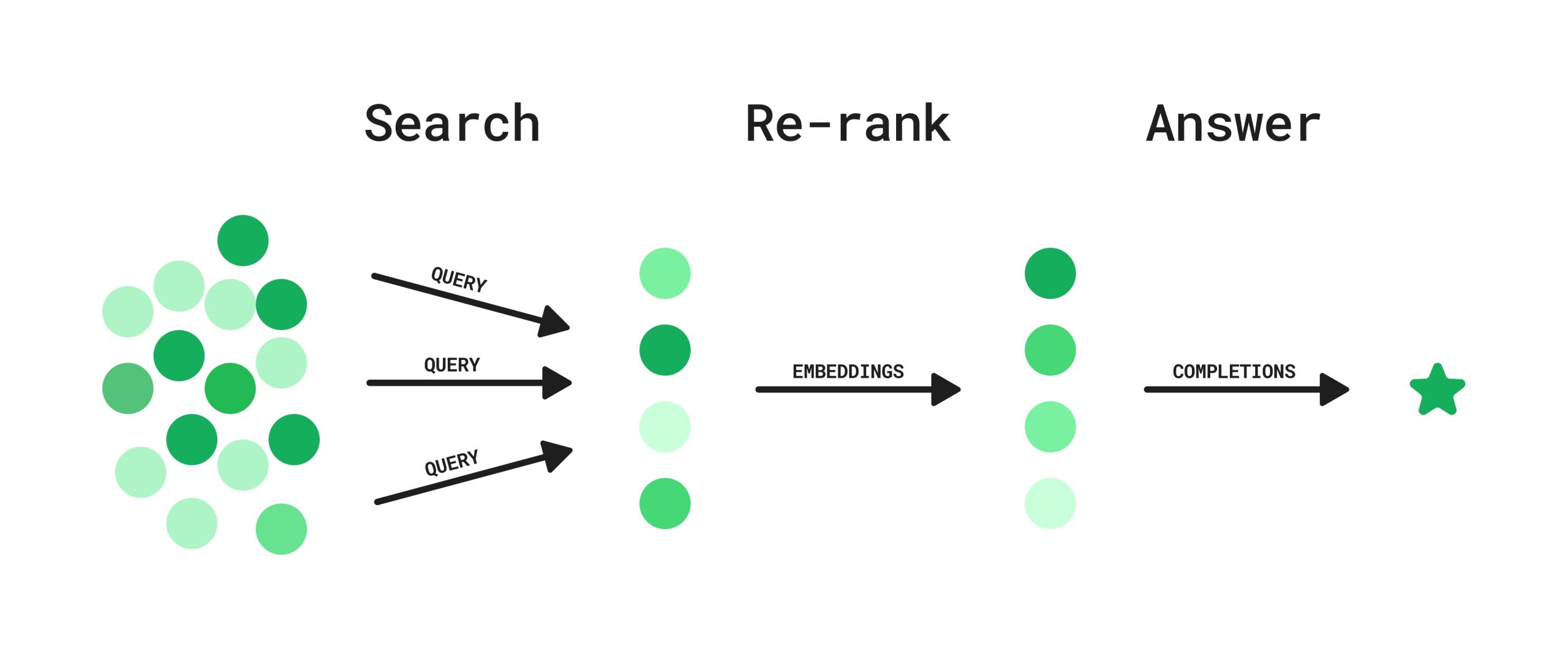
RAG(Retrieval Augmented Generation)은 너무 오래된 정보를 제공하지 않고 Hallucianation을 최소화하기 위해 최신 정보를 검색하고 이를 생성 단계에서 사용합니다. 문제는 생성 단계에서 검색된 결과를 제공하는 컨텍스트를 구성할 때 발생하는데요. "최근 논문에 따르면 RAG의 정확도는 관련 정보의 컨텍스트 내 존재 유무가 아니라 순서라는 것이 발견하였습니다. 즉, 관련 정보가 컨텍스트 내 상위권에 위치하고 있을 때 좋은 답변을 얻을 수 있다는 뜻입니다."(출처: AWS)
-
Rerank는 검색 결과의 순위를 재조정하는 과정을 말합니다.
-
RAG 시스템에서 Rerank는 초기 검색 결과에서 가져온 문서들의 순위를 다시 매기는 역할을 합니다.
-
이를 통해 사용자의 질문과 가장 관련성 높은 문서들을 상위에 배치하여 LLM이 더 정확한 답변을 생성할 수 있도록 돕습니다.
-
-
Rerank의 핵심은 Cross-encoder 구조를 활용한다는 점입니다.
-
일반적인 벡터 검색에서 사용하는 Bi-encoder와 달리, Cross-encoder는 질문과 문서를 동시에 입력으로 받아 더 정확한 관련성 점수를 계산할 수 있습니다.
-
이를 통해 단순한 벡터 유사도 비교보다 훨씬 정교한 순위 조정이 가능해집니다.
-
RAG 성능을 높이는 5가지 Rerank 방법
-
Rerank(순위 재조정)는 RAG(Retrieval-Augmented Generation) 시스템의 성능을 개선하는 핵심 기술입니다.
- 적절한 Rerank 전략을 도입하면 검색 정확도와 효율성을 높이고, 풍부한 컨텍스트를 통해 LLM의 답변 품질도 개선할 수 있습니다.
1. 한국어 특화 Reranker 활용
-
한국어 데이터에 특화된 모델을 사용하면 한국어 RAG 시스템의 성능을 극대화할 수 있습니다.
- 예시: BAAI/bge-reranker-large를 한국어로 파인튜닝한 'Dongjin-kr/ko-reranker'
-
장점: 한국어의 문맥과 특성을 정확히 반영하여 관련성 높은 검색 결과 제공.
# Rerank 코드 예제
def rerank(query, documents):
pairs = [[query, doc] for doc in documents]
inputs = tokenizer(pairs, return_tensors='pt', padding=True, truncation=True, max_length=512)
scores = model(**inputs).logits.view(-1).float()
return sorted(zip(documents, scores), key=lambda x: x[1], reverse=True)2. 다국어 지원 Reranker 적용
-
다국어 환경에서는 여러 언어를 지원하는 Reranker를 활용하여 일관된 성능 확보.
- 예시: BAAI/bge-reranker-v2-m3
-
장점: 다중 언어를 빠르고 정확하게 처리 가능.
# 다국어 Rerank 코드 예제
def rerank_multilingual(query, documents):
pairs = [[query, doc] for doc in documents]
inputs = tokenizer(pairs, return_tensors='pt', padding=True, truncation=True, max_length=512)
scores = model(**inputs).logits.view(-1).float()
return sorted(zip(documents, scores), key=lambda x: x[1], reverse=True)3. 두 단계 검색 전략 구현
-
1단계: 벡터 검색으로 빠르게 후보 문서 추출
-
2단계: Reranker를 활용해 정교하게 순위 재조정
-
장점: 검색 속도와 정확도 사이에서 최적의 균형 달성.
# 두 단계 검색 전략
def two_stage_search(query, corpus, top_k=10):
candidates = vector_search(query, top_k=100) # 1단계 벡터 검색
reranked = rerank(query, candidates) # 2단계 Rerank
return reranked[:top_k]4. 컨텍스트 최적화
-
Rerank 결과를 LLM에 전달할 때, 중요 정보를 컨텍스트의 앞부분에 배치하고 중복을 제거하여 최적화.
-
장점: LLM 성능 극대화 및 정확한 답변 생성.
# 컨텍스트 최적화 코드
def optimize_context(reranked_docs, max_tokens=2000):
context = ""
for doc, score in reranked_docs:
if len(context) + len(doc) > max_tokens:
break
context += doc + "\n\n"
return context.strip()5. 동적 Reranker 선택
-
질문의 복잡도나 특성에 따라 서로 다른 Reranker를 동적으로 선택.
-
단순한 질문 → 경량화된 Reranker
-
복잡한 질문 → 고성능 Reranker
-
-
장점: 리소스를 효율적으로 사용하며 성능 극대화.
# 동적 Rerank 선택 코드
def select_reranker(query):
if is_complex_query(query):
return complex_reranker
else:
return simple_reranker
def dynamic_rerank(query, documents):
reranker = select_reranker(query)
return reranker(query, documents)Rerank의 중요성과 효과
Rerank가 제공하는 이점
-
검색 결과의 순위를 정교하게 조정하여 RAG 시스템의 정확도와 신뢰성을 높임.
-
LLM이 최적의 컨텍스트를 기반으로 답변을 생성하도록 지원.
-
트레이드오프를 고려한 효율적이고 유연한 검색 구조 구축.
핵심 전략
-
한국어, 다국어 모델 등 언어 특화 모델 활용.
-
효율적인 두 단계 검색 전략 도입.
-
컨텍스트 최적화와 동적 모델 선택으로 성능 및 리소스 관리 최적화.
Rerank는 단순한 검색 개선이 아니라 AI 시스템 성능 향상의 중요한 역할을 합니다. 이를 적극 활용해 더욱 효율적이고 신뢰할 수 있는 RAG 시스템을 구축하세요! 🚀
