1. Vector와 Embedding

Vector란?
-
여러 개의 수치 데이터를 특정 순서로 나열한 것.
-
데이터 관점: 하나의 데이터 레코드(예: 문서, 이미지 특징)를 수치화한 배열.
-
Matrix(행렬): 벡터들의 집합.
Embedding이란?
-
텍스트·이미지·오디오 등 비정형 데이터를 기계가 이해할 수 있는 고차원 벡터로 변환하는 과정.
-
목적: 의미적 유사성을 수치로 표현하여 검색·추천·분류 등에 활용.
-
예시
-
"고양이" →
[0.2, -0.4, 0.7] -
"개" →
[0.6, 0.1, 0.5]
→ 두 벡터가 가까우면 의미적으로 유사.
-
mnist(숫자손글씨 이미지세트)

One-Hot Encoding
-
방법: 단어를 고유 인덱스로 매핑 후, 해당 위치만 1로 표시.
-
장점: 구현 간단, 단어 존재 여부 확인 용이.
-
단점
-
차원 폭발: 단어 수가 많아질수록 벡터 차원 커짐.
-
의미 관계 없음: "book"과 "books"는 완전히 다른 벡터.
-
-
실무 팁: 의미 기반 검색에는 부적합, 현재는 거의 사용 안 함.
-
예시
-
예를 들어
I like rabbit and I hate coriander라는 문장을 벡터화 -
먼저 단어단위로 분해하고
I,like,rabbit,and,I,hate,coriander
-
정수 인코딩(Integer Encoding)
{ ‘I’ : 1, ’like’ : 2, ‘rabbit’: 3, ‘hate’:4, ‘coriander’:5 }
-
one-hot vector
I : [1,0,0,0,0]
like : [0,1,0,0,0]
rabbit : [0,0,1,0,0]
hate : [0,0,0,1,0]
coriander : [0,0,0,0,1]
-
이런식으로 간단하게 벡터화를 할 수 있지만, 단어의 개수가 늘어날수록 벡터를 저장하기 위한 공간이 계속 늘어나게 됩니다.
-
예를 들어 단어가 10000개라면, 각각의 단어는 10000개의 차원을 가진 벡터
- 공간의 활용에 있어서 비효율적이라는 단점이 있습니다.
Word Embedding
-
단어의 의미를 다차원 공간에 벡터로 표현.
-
원리: Distributional Hypothesis — 비슷한 문맥에서 등장하는 단어는 비슷한 의미를 가진다.
-
장점
-
단어 간 유사도 계산 가능.
-
의미를 여러 차원에 분산 표현.
-
-
모델 예시
-
Word2Vec, GloVe, FastText (고전)
-
BERT, Sentence-BERT, OpenAI Embeddings (최신)
-
-
실무 팁
-
도메인 특화 모델 사용 시 정확도 향상 (예: 의료 → BioBERT, 법률 → LegalBERT)
-
텍스트뿐 아니라 이미지(CLIP), 오디오(Wav2Vec)도 임베딩 가능.
-
-
예시
- 고양이와 개는 의미론적 관계를 반영해 서로 가깝지만 행복과 슬픔은 반대방향이므로 대조되는 의미임을 알 수 있습니다.
고양이 [0.2, -0.4, 0.7]
개 [0.6, 0.1, 0.5]
사과 [0.8, -0.2, -0.3]
오렌지 [0.7, -0.1, -0.6]
행복 [-0.5, 0.9, 0.2]
슬픔 [0.4, -0.7, -0.5]2. VectorDB란?
-
VectorDB: 임베딩을 통해 생성된 고차원 벡터 데이터를 효율적으로 저장·검색하는 데이터베이스.
-
차이점 (vs RDBMS)
-
RDBMS: 정확히 일치하는 행 검색 (Exact Match)
-
VectorDB: 벡터 간 거리/유사도를 기반으로 가장 가까운 결과 검색 (Similarity Search)
-
필요성
-
수천~수억 개의 벡터를 비교하는 것은 계산량이 매우 큼.
-
VectorDB는 Indexing + Querying + Filtering을 통해 속도와 정확도의 균형을 맞춤.
3. VectorDB 핵심 기능

Indexing (벡터 탐색 최적화)
| 알고리즘 | 특징 | 장점 | 단점 | 실무 적용 |
|---|---|---|---|---|
| Flat Index | 모든 벡터와 직접 비교 | 정확도 100% | 대규모 데이터에서 느림 | 소규모 데이터(≤50K) |
| Random Projection | 차원 축소 후 검색 | 속도↑ | 근사값, 정확도↓ | 차원 축소 필요 시 |
| PQ (Product Quantization) | 벡터를 서브벡터로 나눠 양자화 | 메모리 절감, 속도↑ | 약간의 정확도 손실 | 대규모 데이터 |
| LSH | 유사 벡터를 같은 버킷에 저장 | 매우 빠름 | 메모리↑, 해시 튜닝 필요 | 초고속 검색 |
| HNSW | 계층 그래프 탐색 | 속도·정확도 우수 | 메모리↑ | 대규모 실시간 검색 |
| IVF | 클러스터링 후 검색 | 속도↑ | 클러스터 경계 문제 | nprobe로 보완 |
Querying (유사도 계산)
-
Cosine Similarity: 각도 기반, -1~1 범위, 1에 가까울수록 유사.
-
Euclidean Distance (L2): 직선 거리, 0에 가까울수록 유사.
-
Dot Product: 방향성 기반, 양수 → 같은 방향, 음수 → 반대 방향.
Filtering (결과 후처리)
-
Pre-filtering: 검색 전 메타데이터로 필터링 → 탐색 공간 축소, 속도↑, 하지만 일부 결과 누락 가능.
-
Post-filtering: 검색 후 필터링 → 정확도↑, 하지만 오버헤드↑.
4. VectorDB Indexing 기법 정리
Flat Index (No Optimization)
-
별도의 인덱싱 없이 모든 벡터를 그대로 저장하고, 검색 시 모든 벡터와 유사도를 계산.
-
장점
-
정확도 100% (정확한 Nearest Neighbor Search)
-
구현이 단순
-
-
단점
- 데이터가 많아질수록 검색 속도 급격히 저하 (O(N) 연산)
-
적용 범위
-
벡터 개수가 10,000~50,000개 이하인 경우
-
정확도가 매우 중요한 경우
-
-
실무 예시
-
소규모 FAQ 검색
-
프로토타입/PoC 단계
-
Random Projection
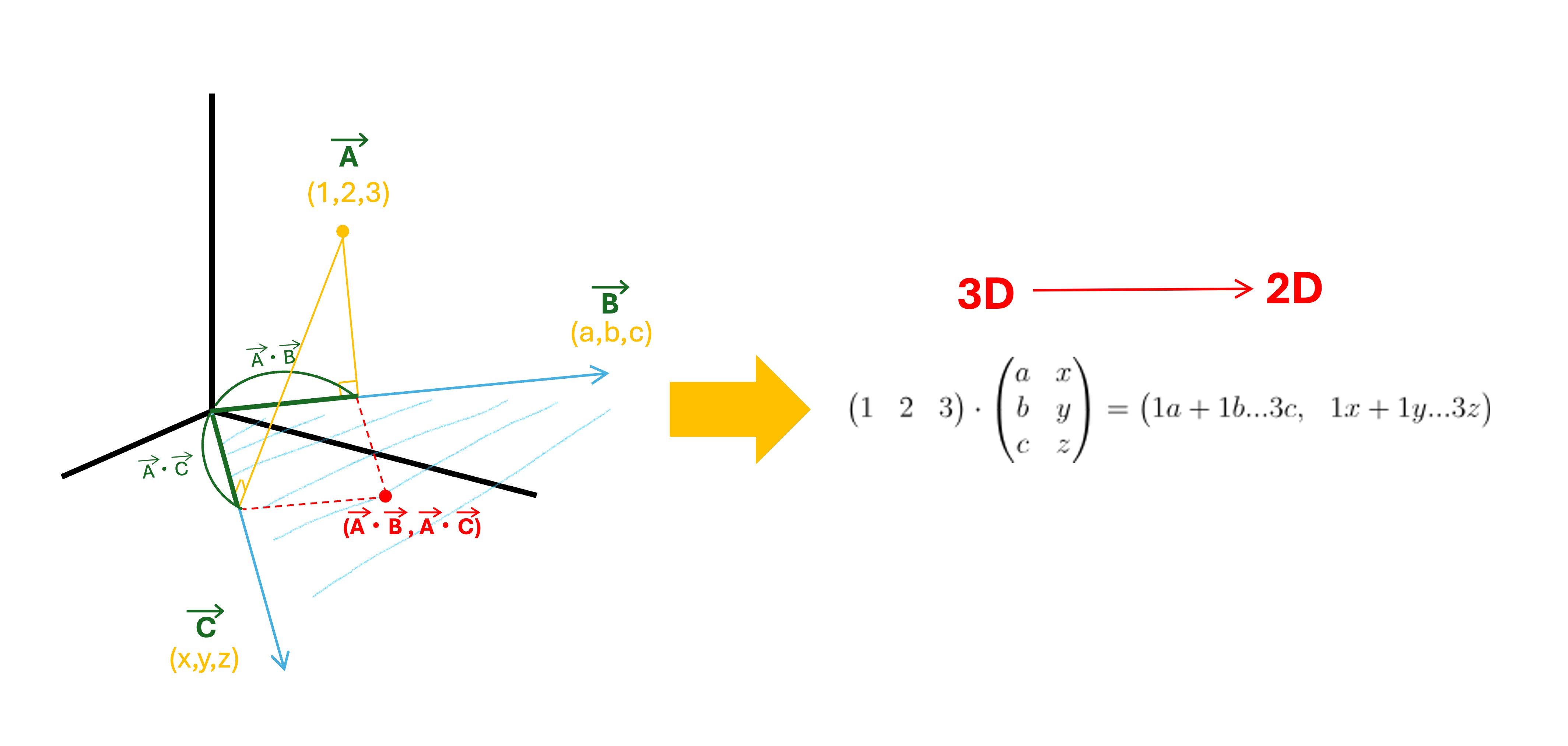
-
랜덤하게 생성한 벡터(투영 행렬)에 원래 벡터를 내적하여 차원을 축소.
-
원리
-
고차원 벡터를 저차원 공간에 사영(Projection)하되, 유사성(거리 구조)은 최대한 유지.
-
예: 3차원 점 (1,2,3)을 2차원 평면에 정사영.
-
-
장점
-
차원 축소로 검색 속도 향상
-
메모리 사용량 절감
-
-
단점
- 근사값(Approximation) → 정확도 일부 손실
-
실무 예시
- 차원이 매우 높은 이미지/텍스트 임베딩(>1,000차원)에서 사전 차원 축소 후 검색
PQ (Product Quantization)
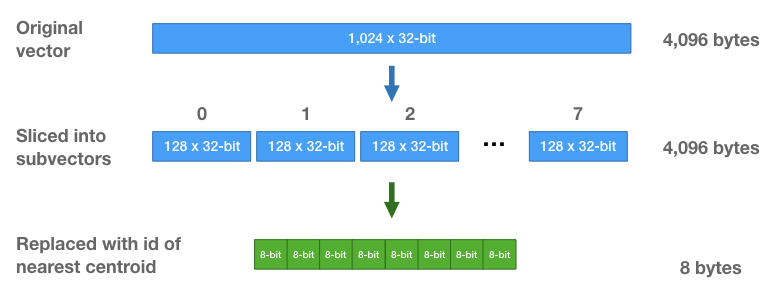
-
벡터를 여러 개의 서브벡터로 나누고, 각 서브벡터를 양자화(Quantization)하여 압축 저장.
-
Quantization(양자화)
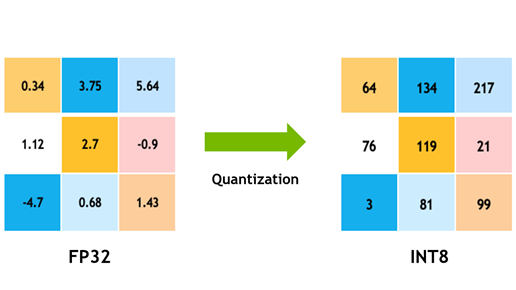
-
일반적으로 Quantization이란 lower preciision bits로 매핑하는 것을 의미합니다.
-
예: Float32(32bit) → Int8(8bit)로 변환
-
소숫점을 표현할때에는 Float32의 경우, 총 32bit를 사용하고 이를 정수형인 Int8, 총 8bit로 표현한다면 그 경향은 비슷하겠지만 표현할 수 있는 숫자의 범위가 상대적으로 제한될 것
-
-
메모리 절감, 연산 속도 향상
-
-
장점
-
대규모 데이터셋에서 빠른 검색 가능
-
메모리 사용량 대폭 절감
-
-
단점
- 양자화로 인한 미세한 정확도 손실
-
실무 예시
-
수억 개 이상의 벡터를 저장하는 추천 시스템
-
이미지 검색 서비스
-
LSH (Locality-Sensitive Hashing)
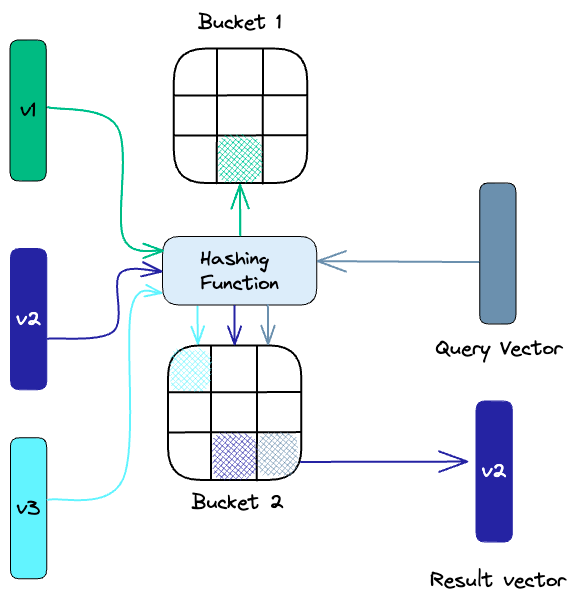
-
유사한 벡터를 동일한 해시 버킷(Bucket)에 매핑하는 기법.
-
원리
-
해시 함수 설계 시, 유사한 벡터일수록 같은 해시값을 가질 확률이 높도록 함.
-
검색 시 동일 버킷 내에서만 비교 → 속도 향상
-
-
장점
-
매우 빠른 검색
-
대규모 데이터 처리 가능
-
-
단점
-
메모리 사용량 증가
-
해시 파라미터 튜닝 필요
-
-
실무 예시
-
실시간 근사 최근접 검색(ANN)
-
대규모 로그 데이터 이상 탐지
-
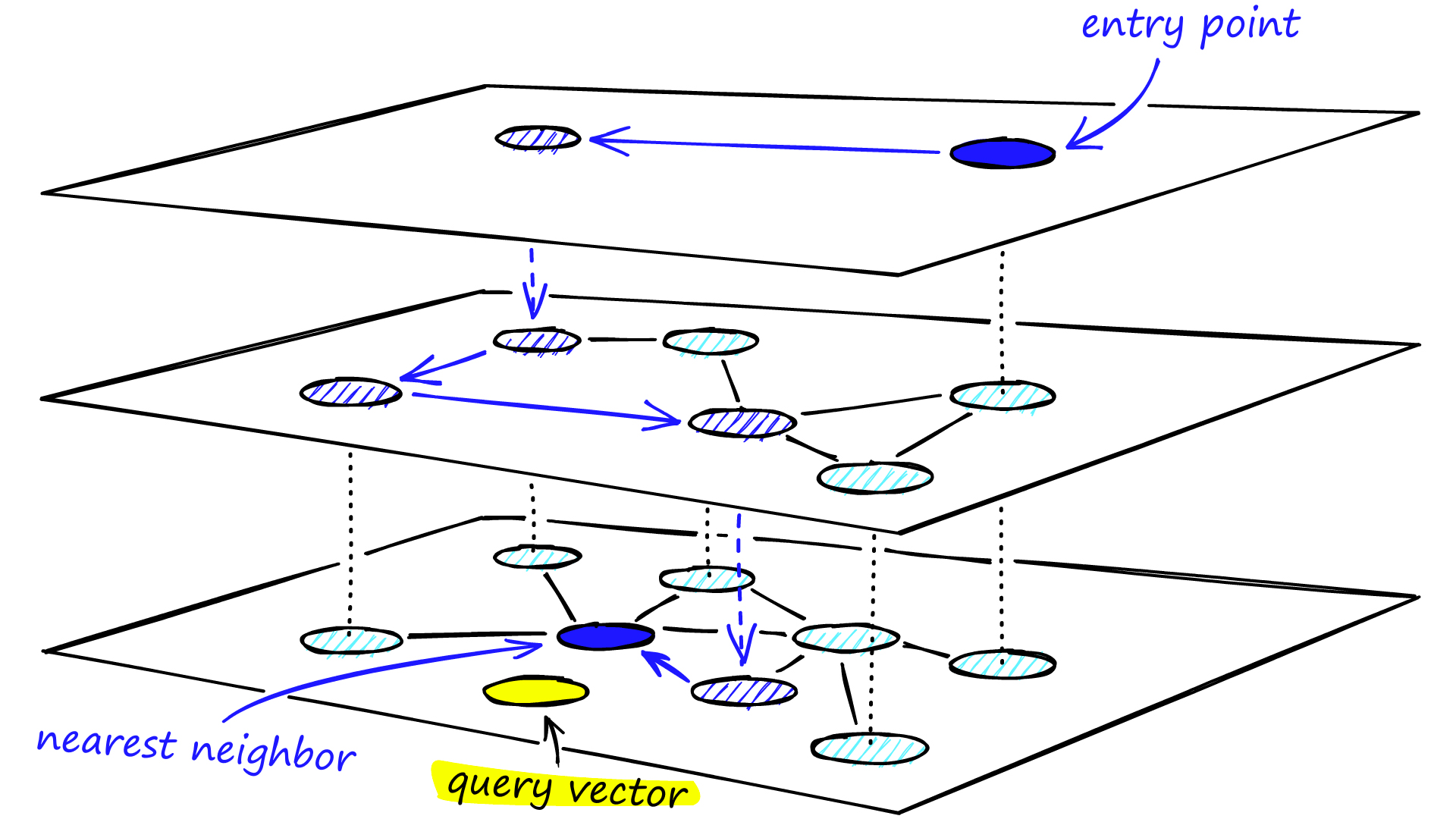
HNSW (Hierarchical Navigable Small World Graph)
-
벡터를 그래프 형태로 구성하고, 여러 계층(layer)로 나누어 탐색.
-
탐색 과정
-
최상위 레이어에서 임의 노드 시작
-
가장 가까운 노드로 이동
-
더 이상 가까워질 수 없으면 하위 레이어로 이동
-
최하위 레이어에서 최종 최근접 벡터 탐색
-
-
장점
-
속도와 정확도 모두 우수
-
대규모 데이터에 적합
-
-
단점
- 메모리 사용량 큼
-
실무 예시
-
실시간 추천 시스템
-
대규모 전자상거래 상품 검색
-
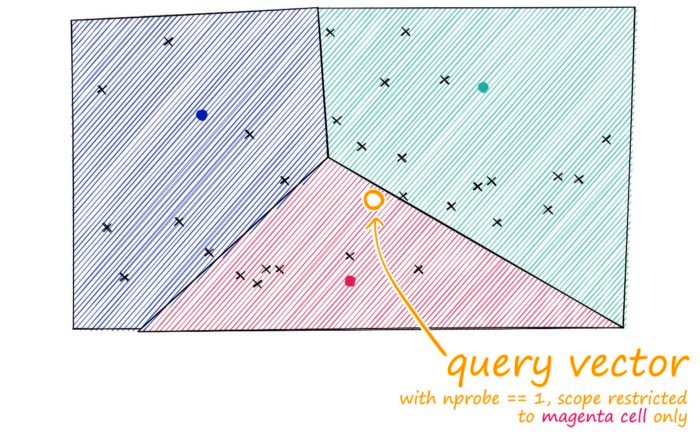
IVF (Inverted File Index)
-
클러스터링(K-means 등)으로 벡터를 N개의 클러스터로 나누고, 각 클러스터에 속한 벡터 목록(Inverted List)을 저장.
-
검색 과정
-
쿼리 벡터가 속할 클러스터 찾기
-
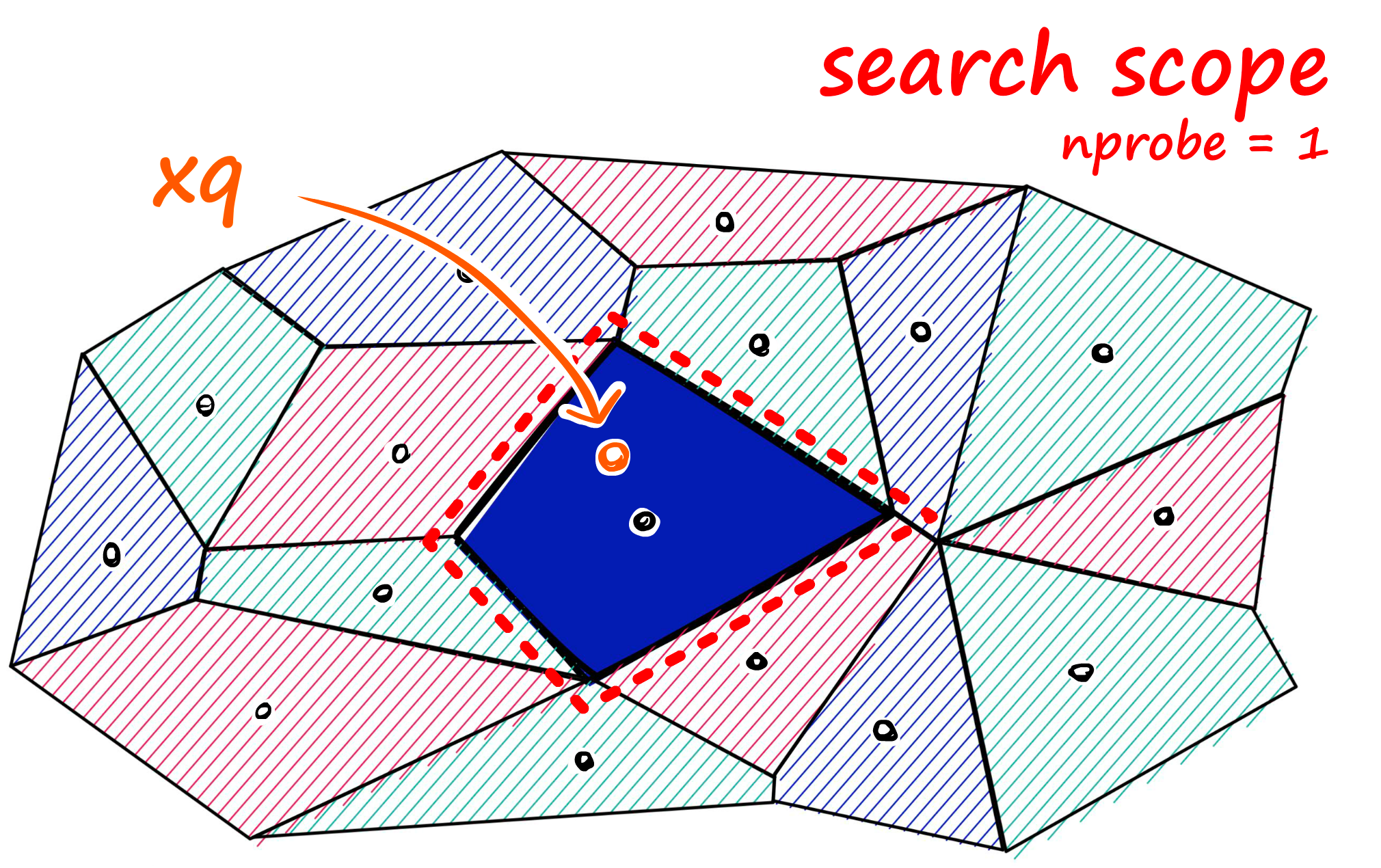
해당 클러스터 내에서만 검색
-
nprobe파라미터로 여러 클러스터 검색 가능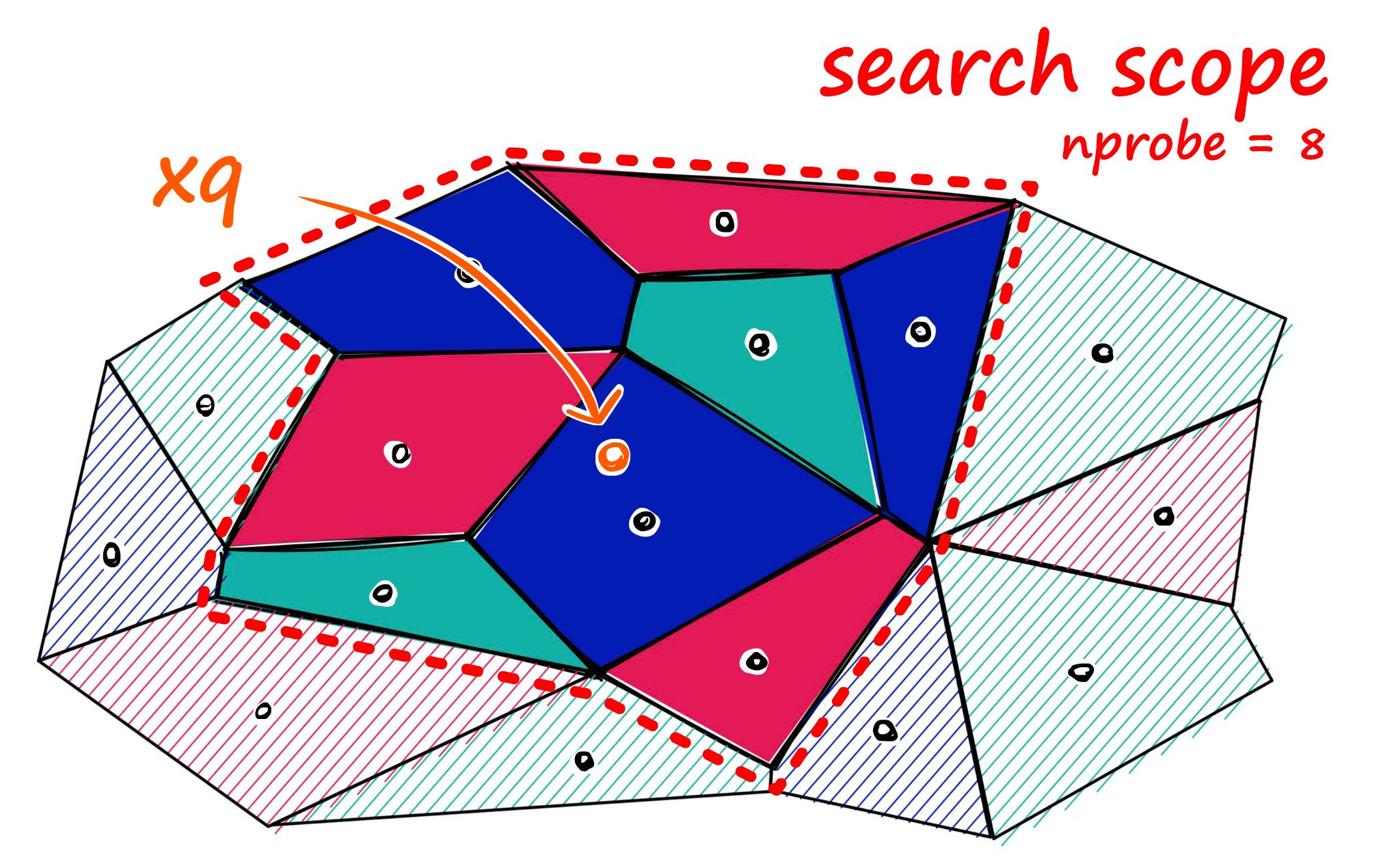
-
-
장점
-
검색 속도 향상
-
대규모 데이터 처리 가능
-
-
단점
- 클러스터 경계 문제 (경계에 있는 벡터는 놓칠 수 있음)
-
실무 예시
-
이미지/동영상 검색
-
대규모 문서 검색
-
Tip: 실무 선택 가이드
- HNSW는 실시간 검색에 강하고,
- IVF+PQ는 대규모 배치 검색에 강합니다.
- LSH는 초고속 근사 검색이 필요할 때 유용합니다.
데이터 규모 추천 알고리즘 비고 ≤ 50K Flat Index 정확도 100% 50K ~ 5M HNSW, IVF 속도·정확도 균형 ≥ 5M IVF+PQ, LSH 메모리 절감, 초고속 검색
5. VectorDB 종류
| 유형 | 특징 | 장점 | 단점 | 예시 |
|---|---|---|---|---|
| Vector 라이브러리 | 유사도 검색·Indexing 기능 제공 | 가볍고 빠름 | CRUD, 백업 제한 | FAISS, Annoy |
| Vector 전용 DB | 벡터 저장·검색 최적화 | 대규모 처리, 다양한 Index 지원 | SQL 제한, 파라미터 튜닝 필요 | Pinecone, Milvus, Weaviate |
| Enterprise DB with Vectors | 기존 DB에 벡터 기능 추가 | SQL 지원, 엔터프라이즈 기능 | 벡터 검색 최적화 부족 | PostgreSQL+pgvector, ElasticSearch |
6. 실무 활용 예시
| 분야 | Raw Data | Embedding Model | VectorDB 활용 |
|---|---|---|---|
| 검색 | 고객 문의 텍스트 | Sentence-BERT | 의미 기반 FAQ 검색 |
| 추천 | 상품 이미지 | CLIP | 유사 상품 추천 |
| 보안 | 네트워크 로그 | Custom Embedding | 이상 패턴 탐지 |
| 법률 | 판례 문서 | OpenAI Embeddings | 유사 판례 검색 |
7. 실무 주의사항
-
모델 선택: 도메인 특화 모델 사용 시 정확도 향상.
-
Index 파라미터 튜닝: nprobe, efSearch 등 속도·정확도 균형 조정.
-
메타데이터 관리: 벡터+원본+메타데이터 함께 저장.
-
정확도 vs 속도: ANN 기법은 근사값이므로 품질 검증 필요.
-
백업·복구 전략: VectorDB는 대규모 데이터이므로 장애 대비 필수.
추천 실무 접근
1. PoC 단계: FAISS/HNSW로 소규모 테스트.
2. 확장 단계: Milvus/Pinecone로 대규모 운영.
3. 엔터프라이즈 통합: pgvector, ElasticSearch로 기존 시스템에 벡터 검색 추가.
