'AI계 인형 눈 붙이기' 데이터 라벨링 뭐길래… 메타도 13조 투자 추진: https://www.chosun.com/economy/tech_it/2025/06/10/NVCMHFALCNHHHHKWPN6Q6227SA/
https://www.comworld.co.kr/news/articleView.html?idxno=49895
데이터 라벨링(Data Labeling)
-
데이터 라벨링이란 원시 데이터(raw data)에 의미 있는 정답 정보(ground truth)를 부여하는 과정
-
모델 관점
- 입력 X에 대응하는 정답 y를 명시하는 행위
-
학습 관점
- 지도학습(Supervised Learning)의 전제 조건
-
시스템 관점
- 모델 성능의 상한선을 결정하는 핵심 요소
-
일반적으로 성립하는 관계
- 모델 성능 = 데이터 품질 × 모델 구조 × 학습 전략
-
실무적으로 가장 큰 영향을 미치는 요소
-
데이터 품질
-
그중에서도 라벨 품질
-
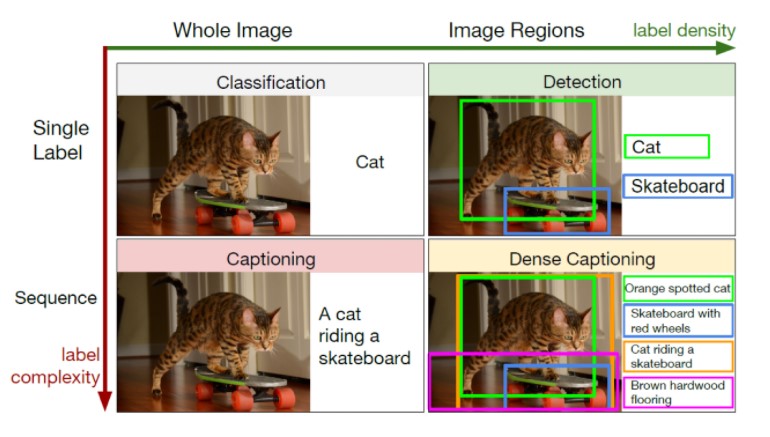
2. 데이터 라벨링의 주요 종류
1) 컴퓨터 비전 (Computer Vision)
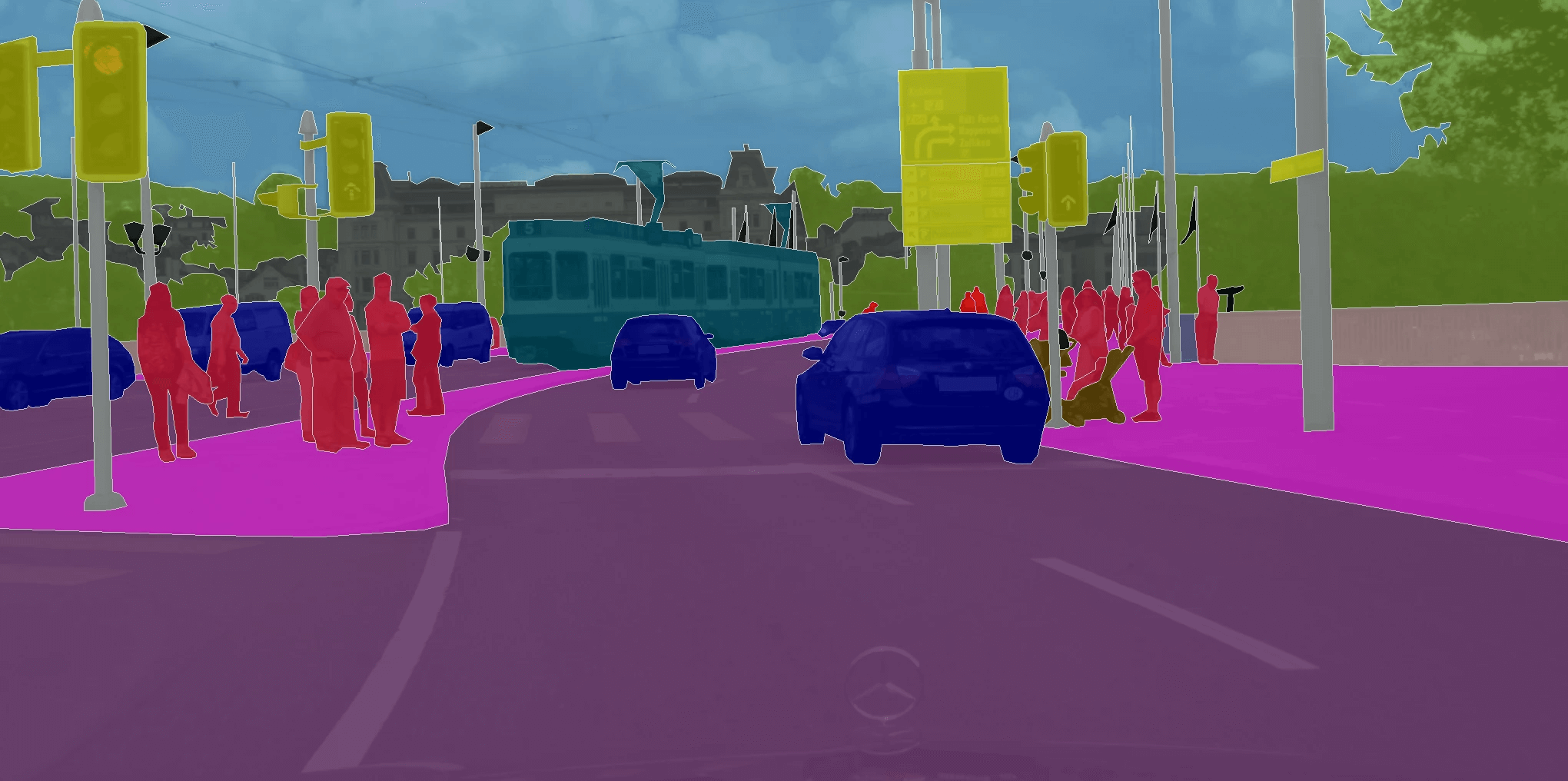

-
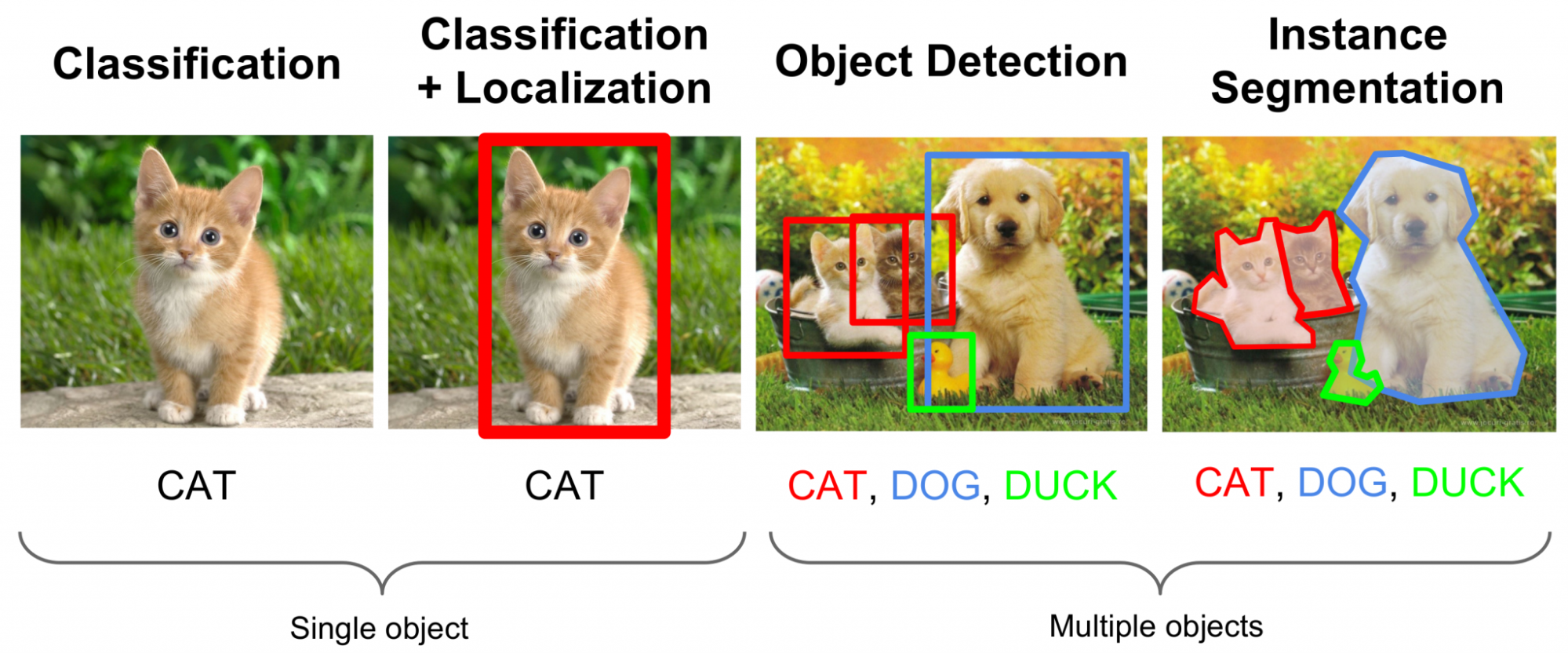
Image Classification
-
이미지 전체에 하나 또는 복수의 클래스 부여
-
예: 고양이, 개
-
-
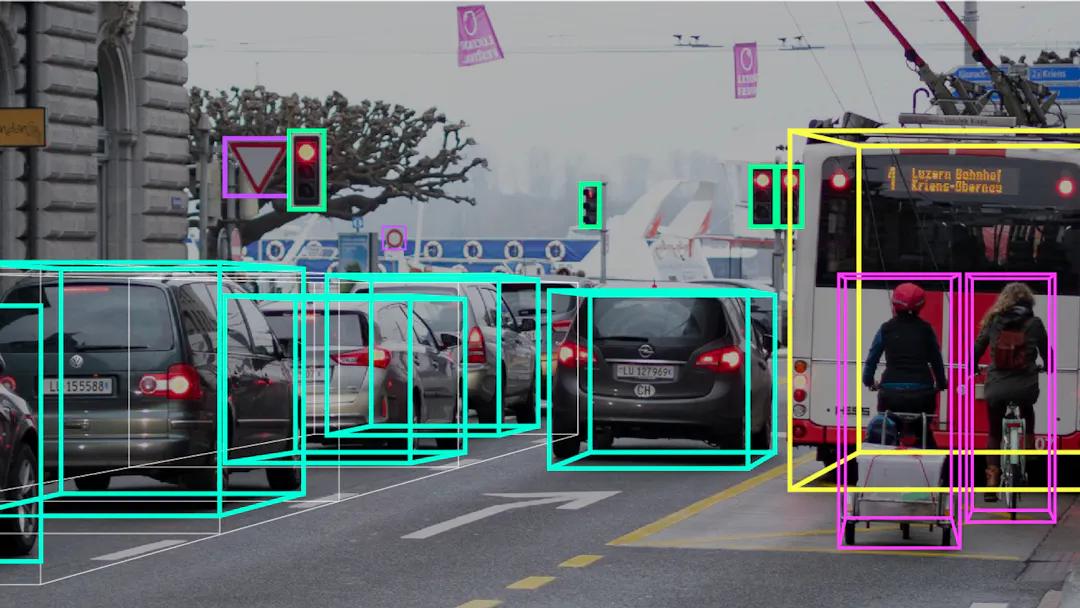
Object Detection
-
객체 위치와 클래스 동시 지정
-
예: Bounding Box
-
-
Semantic Segmentation
-
픽셀 단위로 클래스 라벨 부여
-
예: 도로, 하늘
-
-
Instance Segmentation
-
객체별 픽셀 분리
-
예: 사람1, 사람2
-
-
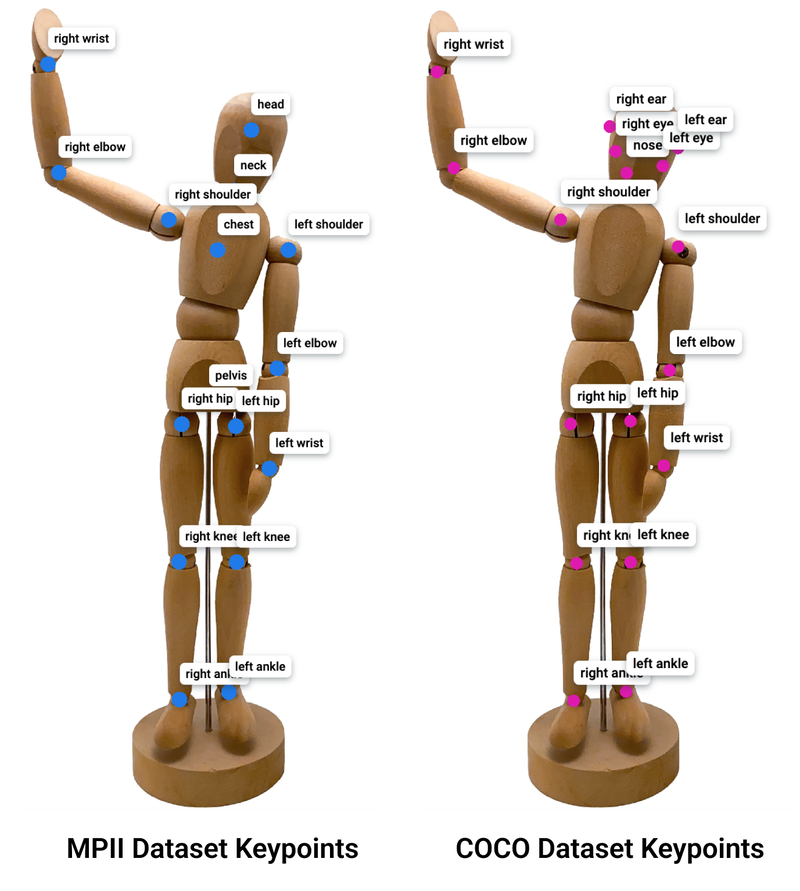
Keypoint / Pose
-
관절 또는 특징점 좌표 라벨링
-
예: 얼굴 랜드마크, 인체 관절
-
2) 자연어 처리 (NLP)




-
Text Classification
- 문서 또는 문장을 특정 범주로 분류
-
Named Entity Recognition (NER)
- 사람, 조직, 장소 등 개체명 인식
-
Sentiment Analysis
- 감정 상태 분류
-
Question Answering / Summarization
- 질문-답변 쌍 또는 요약 결과를 정답으로 제공
3) 음성 및 시계열 데이터
-
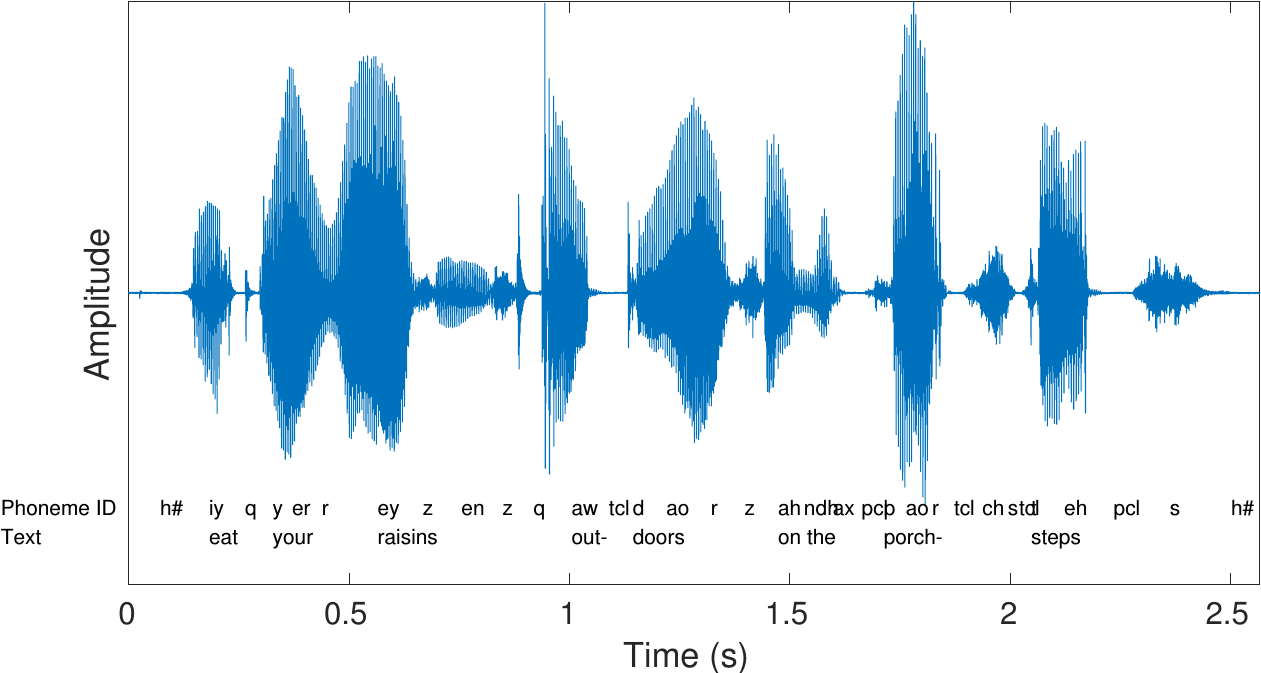
ASR (Automatic Speech Recognition)
- 음성을 텍스트로 변환
-
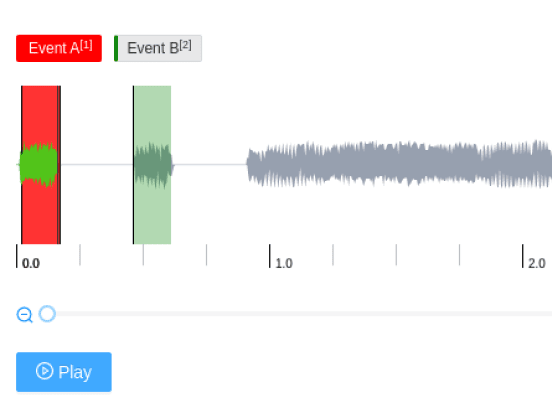
Audio Event Detection
- 특정 소리 이벤트 구간 라벨링
-
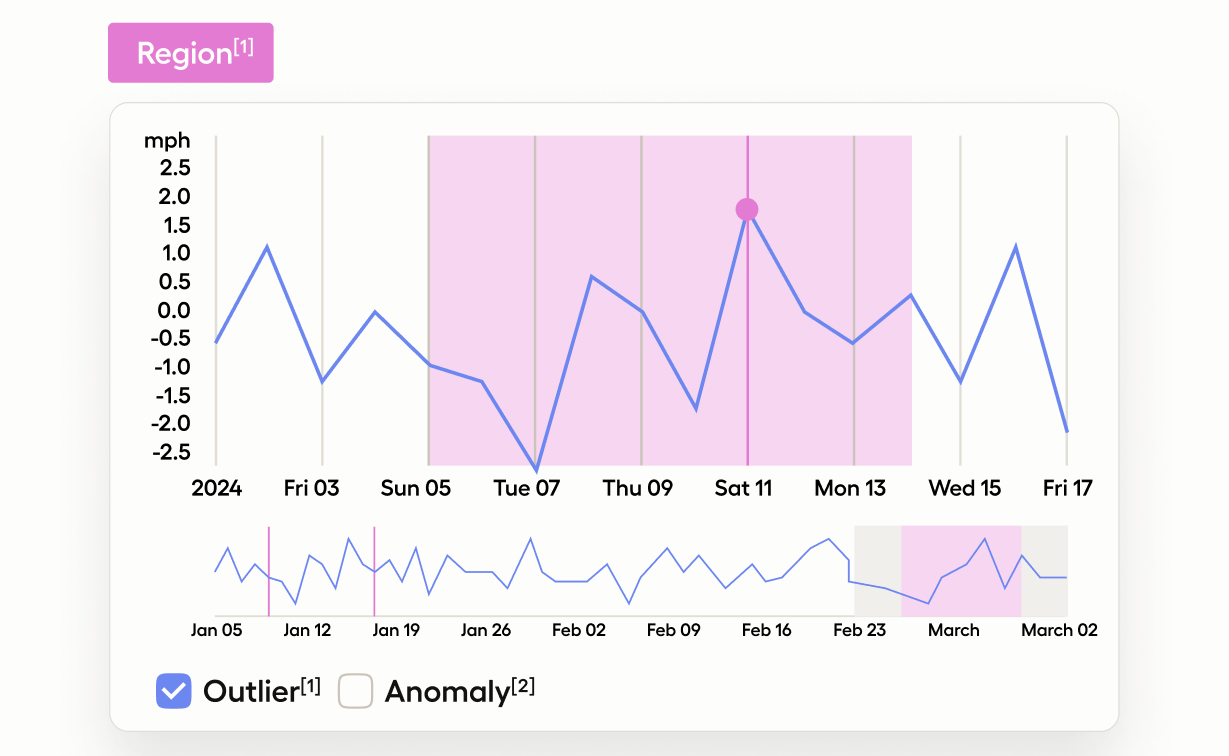
Time-series Labeling
-
이상 탐지
-
이벤트 발생 시점 정의
-
3. 데이터 라벨링 전체 과정 (End-to-End)
1) 전체 파이프라인
-
문제 정의
-
데이터 수집
-
라벨 스펙 정의
-
라벨링 가이드 작성
-
라벨링 수행
-
검수(QA)
-
데이터셋 버저닝
-
모델 학습 및 피드백 반영
2) 핵심 단계별 설명
-
문제 정의(Task Definition)
-
무엇을 예측할 것인가
-
클래스 수는 얼마인가
-
단일 라벨인지 멀티 라벨인지
-
이 단계가 불명확할 경우 라벨 불일치가 필연적으로 발생
-
-
라벨 스펙 정의(Label Specification)
-
클래스 정의
-
포함 기준과 제외 기준
-
애매한 케이스 처리 규칙 명시
-
예시
-
Person 클래스
- 사람 전체가 50% 이상 보일 때만 라벨링
- 거울 속 반사는 제외
-
-
-
라벨링 가이드 작성
-
예시 이미지 또는 문장 포함
-
“이럴 때는 이렇게 한다”는 규칙 명문화
-
라벨러 간 해석 차이 최소화
-
-
라벨링 수행
-
수작업
-
반자동
-
자동
-
CVAT, Label Studio 등 툴 활용
-
-
검수(Quality Assurance)
-
다중 라벨러 교차 검증
-
샘플링 검사
-
disagreement 사례 분석
-
4. 데이터 라벨링 품질(Quality)
1) 라벨 품질이 중요한 이유
-
노이즈 라벨은 모델을 직접적으로 훼손
-
잘못된 라벨은 모델에 잘못된 지식을 학습시키는 것과 동일
-
경험적으로 관측되는 현상
-
약 10%의 라벨 오류
-
모델 성능 20~40% 하락 사례 다수 존재
-
2) 주요 품질 지표
-
Accuracy: 정답 비율
-
Consistency: 라벨 간 일관성
-
Inter-Annotator Agreement: 라벨러 간 합의도
-
Coverage: 데이터 분포 커버 여부
-
대표적 합의도 지표
-
Cohen’s Kappa
-
Fleiss’ Kappa
-
5. 데이터 라벨링 기법(Methodology)
1) 수작업 라벨링(Manual)
-
장점: 정확도 최고 수준
-
단점: 비용과 시간 소요 큼
-
주로 사용되는 분야
-
의료
-
법률
-
안전-critical 시스템
-
2) 반자동 라벨링(Semi-Automatic)
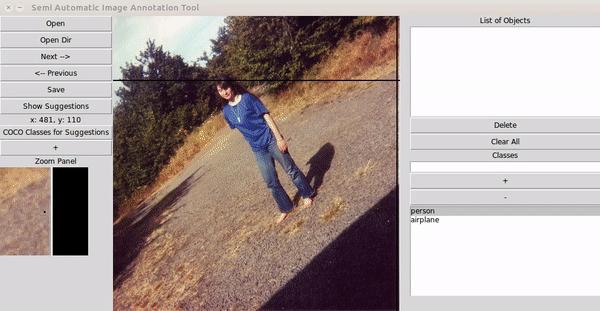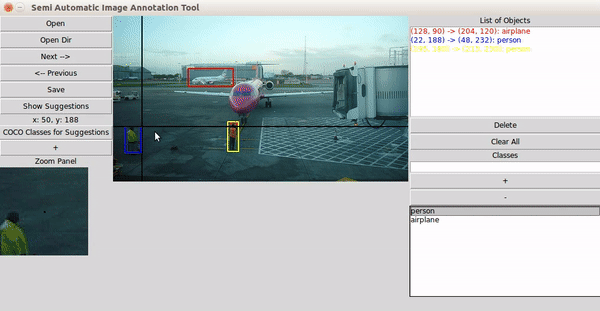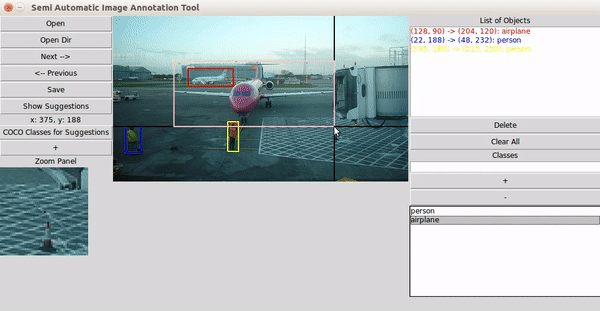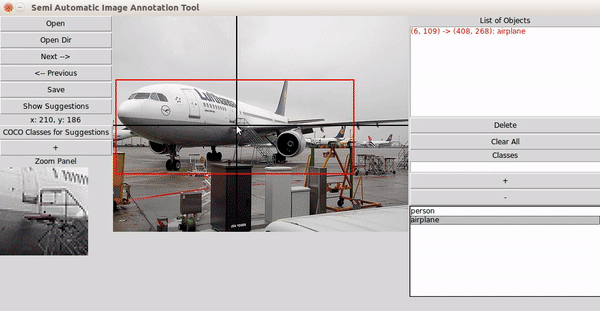
-
초기 모델이 라벨 예측
-
인간이 예측 결과를 수정
-
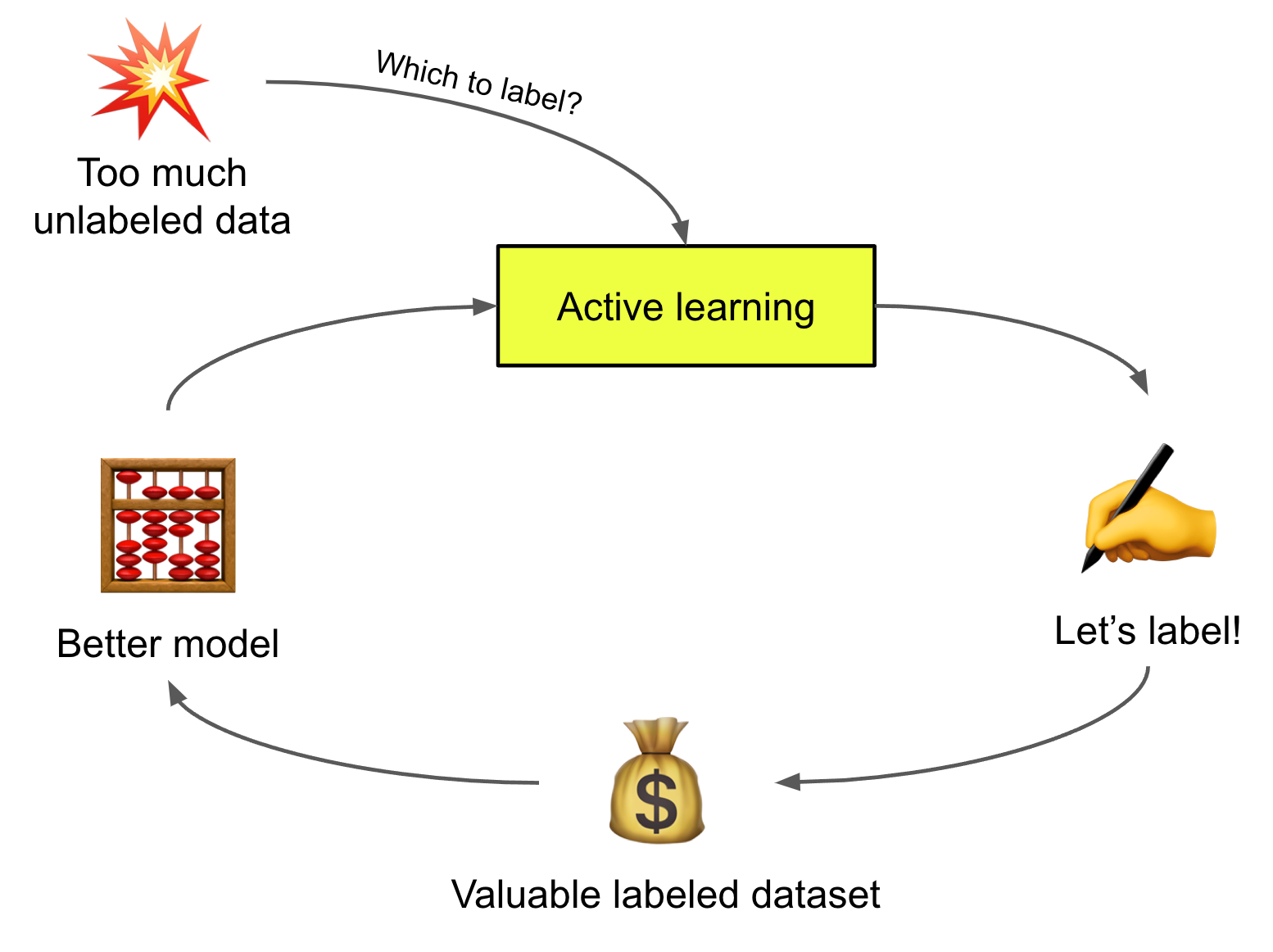
Active Learning 기반 반복 구조
-
장점
- 비용 감소
- 점진적 품질 향상
3) 자동 라벨링(Automatic)
-
규칙 기반 라벨링
-
기존 모델을 활용한 pseudo-label
-
리스크
-
오류 증폭 가능
-
검수 없이 사용 시 장기적 품질 붕괴
-
4) Weak / Noisy Labeling
-
휴리스틱 기반
-
로그 기반
-
Distant supervision
-
대규모 데이터에서 속도와 정확도의 절충 전략으로 사용
6. 실무에서 자주 발생하는 실패 패턴
-
클래스 정의가 모호함
-
라벨링 가이드 없이 작업 시작
-
QA 없는 대량 라벨링
-
모델 학습 결과가 라벨 기준에 반영되지 않음
-
라벨을 소모품으로 인식하는 조직 문화
7. 데이터 라벨링 운영 전략
- 데이터 라벨링은 단순 작업이 아니라 설계 행위
- 라벨 품질은 모델 성능의 상한선을 결정
- 좋은 라벨링의 조건
- 명확한 정의
- 일관성
- 검수
- 피드백 루프
- 자동화보다 우선되는 것은 기준 정립
1) 좋은 전략의 특징
-
작게 시작하고 빠르게 검증
-
모델 결과를 통해 라벨 기준을 지속적으로 보정
-
데이터셋 버전 관리 수행
-
v1
-
v2
-
v3
-
3) 권장 운영 구조
-
문제 정의 담당(ML Engineer)
-
라벨링 가이드 작성
-
QA 기준 설정
-
모델 결과 피드백
-
-
라벨러
-
라벨링 작업 수행
-
애매한 케이스 보고
-
기준 개선을 위한 피드백 제공
-
