아래 단계별 가이드를 보면서 하나씩 따라해 보세요. 각 단계마다 필요한 명령어나 코드를 복사해서 Jupyter Notebook 또는 터미널에 입력하면 됩니다.
1. 작업환경 준비하기
1-1. Python 설치 확인
- 터미널(또는 명령 프롬프트)을 열어 아래 명령어로 Python이 설치되어 있는지 확인하세요.
python3 --version- 만약 설치되어 있지 않다면 python.org에서 설치하세요.
1-2. 작업 디렉터리 만들기
- 터미널에서 다음 명령어를 입력하여 머신러닝 관련 파일들을 저장할 디렉터리를 만듭니다.
(예: 홈 디렉터리 아래ml폴더)
export ML_PATH="$HOME/ml" # 원하는 경로로 변경 가능
mkdir -p $ML_PATH- 명령 프롬프트(cmd)에서 환경 변수 설정 및 디렉터리 생성
set ML_PATH=%USERPROFILE%\ml
mkdir %ML_PATH%
- PowerShell에서 환경 변수 설정 및 디렉터리 생성
$env:ML_PATH = "$env:USERPROFILE\ml"
New-Item -ItemType Directory -Force -Path $env:ML_PATH2. 필수 패키지 설치하기
2-1. pip 업그레이드
- pip가 최신 버전인지 확인하고, 필요하면 업그레이드합니다.
pip3 install --upgrade pip2-2. virtualenv 설치 (선택 사항 – 독립된 환경을 원할 때)
- 다른 프로젝트와 라이브러리 충돌을 피하기 위해 virtualenv를 사용합니다.
pip3 install --user --upgrade virtualenv2-3. 가상환경 생성 및 활성화
- 작업 디렉터리로 이동한 후, 가상환경을 생성하고 활성화하세요.
cd $ML_PATH
virtualenv env
source env/bin/activate- 명령 프롬프트(cmd)
cd $ML_PATH
python -m venv env
.\my_env\Scripts\activate 2-4. 필요한 패키지 설치
- Jupyter Notebook, matplotlib, numpy, pandas, scipy, scikit-learn 등을 설치합니다.
pip3 install --upgrade jupyter matplotlib numpy pandas scipy scikit-learn3. Jupyter Notebook 실행하기
- 터미널에서 아래 명령어를 입력하여 Jupyter Notebook을 실행합니다.
jupyter notebook
-
웹 브라우저가 자동으로 열리면서 Notebook 대시보드가 나타납니다.
-
New 버튼을 클릭하고 Python 버전을 선택해 새 Notebook을 생성하세요.
-
새 Notebook의 이름을 상단의 “Untitled”를 클릭해서 Housing으로 변경하세요.
4. 데이터 다운로드 및 준비하기
4-1. 데이터 다운로드 코드 작성
- Notebook의 첫 번째 셀에 아래 코드를 입력하고 실행하여 데이터를 다운로드하고 압축을 풉니다.
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = os.path.join("datasets", "housing")
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path, filter=lambda tarinfo: tarinfo)
housing_tgz.close()
fetch_housing_data()- 이 코드를 실행하면
datasets/housing디렉터리가 생성되고, 그 안에housing.tgz파일을 다운로드한 후 압축을 풀어housing.csv파일이 생성됩니다.
4-2. 데이터를 판다스로 불러오기
- 다음 셀에 데이터를 읽어오는 함수를 작성하고, 데이터를 DataFrame에 저장합니다.
import pandas as pd
import os
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
housing = load_housing_data()
5. 데이터 탐색하기
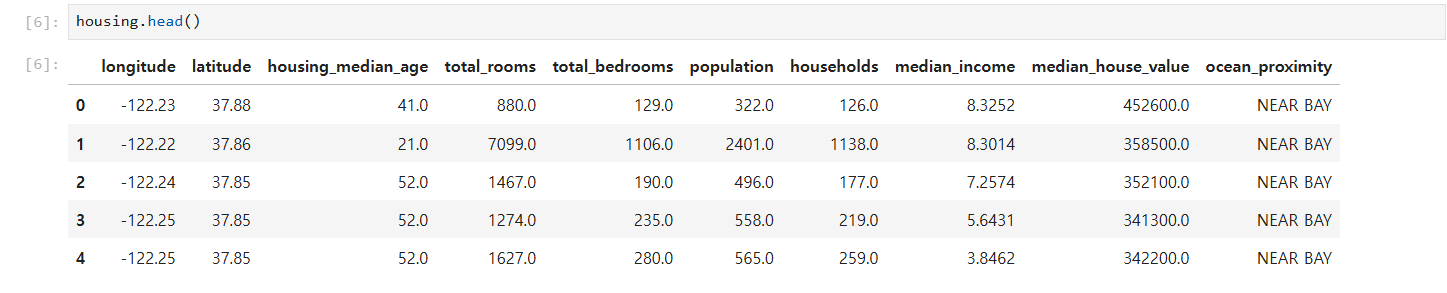
5-1. 데이터의 처음 5행 보기
housing.head()- 각 행이 한 구역을 나타내며, 열(특성)에는 예를 들어
longitude,latitude,housing_median_age,total_rooms,median_income등이 있습니다.
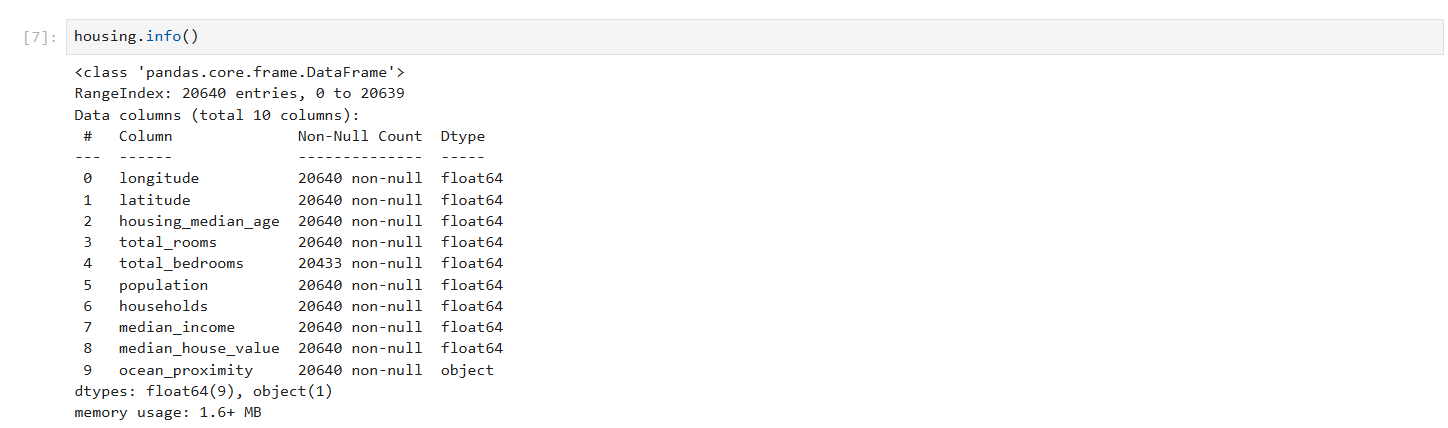
5-2. 데이터의 구조와 결측치 확인
housing.info()- 이 명령어를 통해 각 특성의 데이터 타입과 결측치 여부를 확인할 수 있습니다.
5-3. 수치형 특성 요약 통계 확인
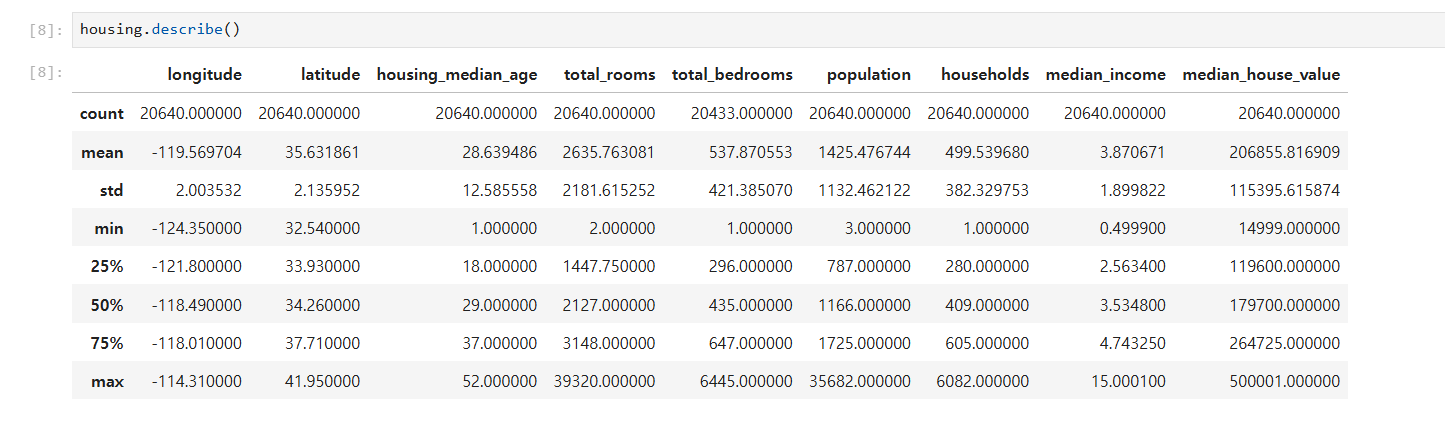
housing.describe()- 평균, 표준편차, 최소/최대값, 백분위수 등 데이터를 요약해서 보여줍니다.
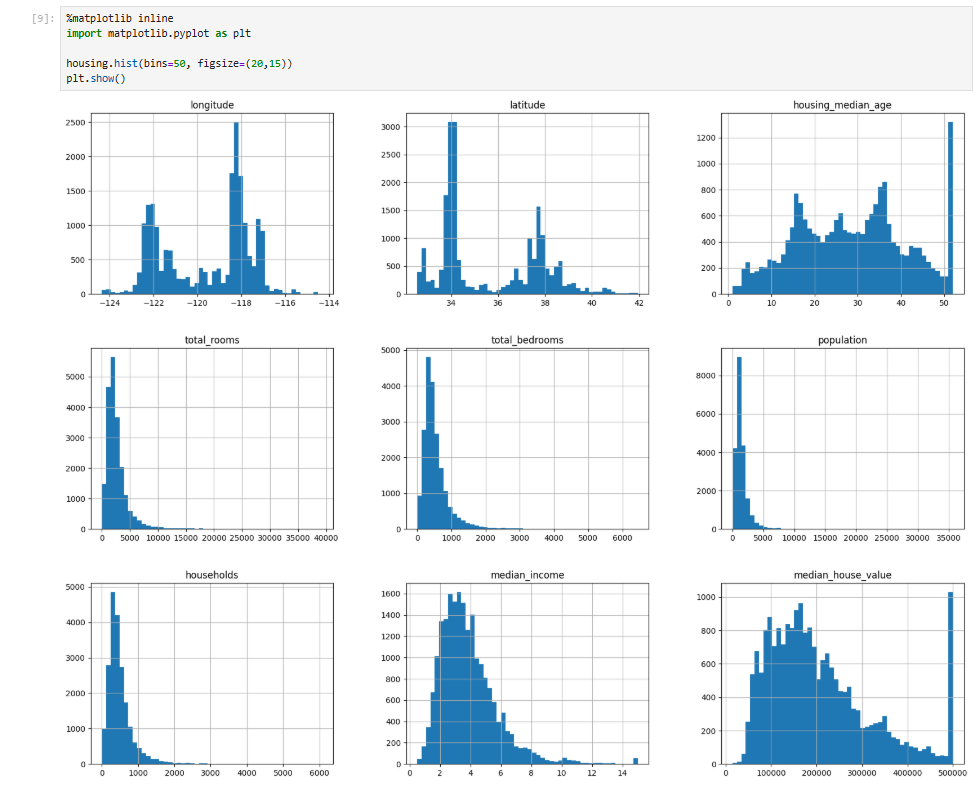
5-4. 히스토그램으로 데이터 분포 시각화
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
plt.show()-
이 코드를 실행하면 각 수치형 특성에 대한 히스토그램이 표시되어 데이터 분포를 한눈에 볼 수 있습니다.
%matplotlib inline:
Jupyter Notebook에서 matplotlib가 그린 그래프를 Notebook 내에 바로 표시하도록 설정하는 매직 명령어입니다.
6. (선택) 데이터셋 분할하기
6-1. 무작위로 테스트 셋 만들기
-
아래 코드를 사용하면 전체 데이터의 20%를 테스트 셋으로 분리할 수 있습니다.
-
훈련셋은 모델이 패턴을 학습하는 데 사용되고,
-
테스트셋은 학습된 모델의 성능을 평가하기 위해 사용됩니다.
-
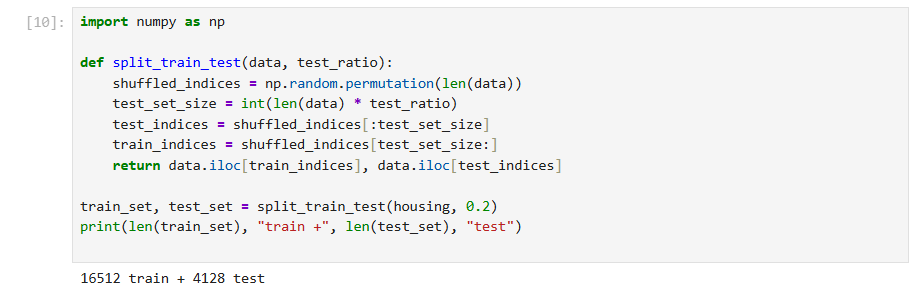
import numpy as np
def split_train_test(data, test_ratio):
# 전체 데이터 개수만큼의 인덱스를 무작위 순서로 섞습니다.
shuffled_indices = np.random.permutation(len(data))
# 테스트 셋의 크기를 계산합니다.
test_set_size = int(len(data) * test_ratio)
# 섞인 인덱스 중 앞부분은 테스트 셋, 뒷부분은 훈련 셋의 인덱스로 사용합니다.
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
train_set, test_set = split_train_test(housing, 0.2)
print(len(train_set), "train +", len(test_set), "test")
6-2. 계층적 샘플링(중간 소득 기반)
- 중간 소득(
median_income)을 바탕으로 카테고리(income_cat)를 만들어 계층 샘플링을 할 수 있습니다.
# 중간 소득을 1.5로 나누고 올림한 후, 5보다 큰 값은 5로 변경합니다.
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
# 계층 샘플링 후에는 임시로 생성한 income_cat 특성을 삭제합니다.
for set_ in (strat_train_set, strat_test_set):
set_.drop("income_cat", axis=1, inplace=True)- 이렇게 하면 데이터셋의 중간 소득 분포를 고려한 테스트 셋을 만들 수 있습니다.
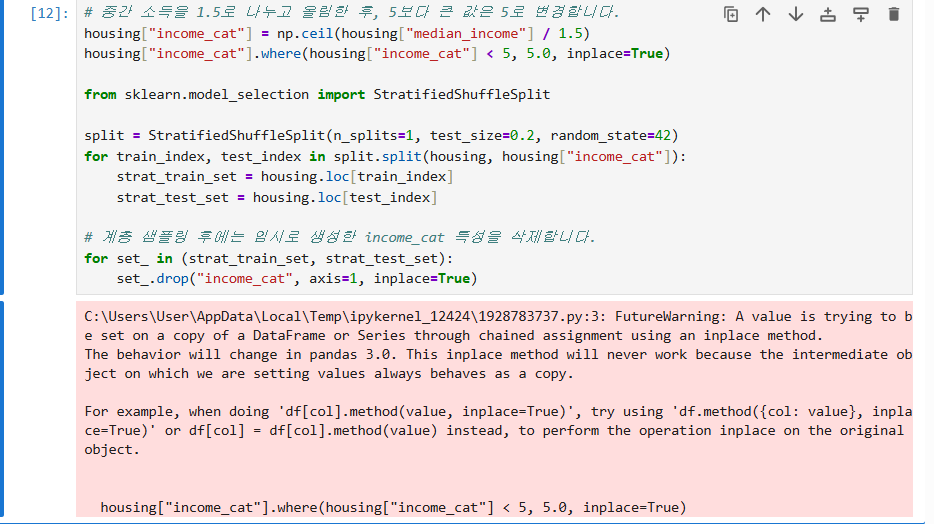
-
이 경고는 DataFrame의 일부 값을 직접 수정할 때 원본에 제대로 반영되지 않을 수 있어 발생합니다. 해결 방법은 수정 결과를 재할당하는 것입니다.
inplace=True로 설정하면 수정된 결과를 새 객체로 반환하지 않고, 기존의 객체 자체를 변경합니다.
housing["income_cat"] = housing["income_cat"].where(housing["income_cat"] < 5, 5.0)
7. 추가 학습
-
이 후 단계에서는 데이터를 분석하고, 전처리하며, 머신러닝 모델을 적용해 볼 수 있습니다.
-
Notebook 상에서 각 코드 셀을 실행하면서 결과를 확인해보고, 필요에 따라 각 명령어의 의미를 찾아보세요.
이 가이드를 따라 하면서 궁금한 점이나 문제가 생기면 언제든 질문해 주세요. 이제 한 단계씩 진행해 보세요!

All views expressed here are solely my own and do not represent those of any affiliated organization.