특정 값을 예측하기 위한 수단의 머신러닝: 수치 예측(Numerical Prediction), 범주 예측(Categorical Prediction)
Artificial Intelligence
- Machine Learning 은 주어진 X와 Y데이터를 이용하여 모델 F(x)를 추론하는 과정이라고 배웠다.
- 그렇게 모델 F(x)를 추론하고 나면 새로운 데이터 X가 주어졌을 때, 모델에 입력 X를 넣어서 출력 Y값을 예측 할 수 있다.
- 결국 Machine Learning은 특정 값을 예측하기 위한 수단으로 사용할 수 있다는 뜻이다.
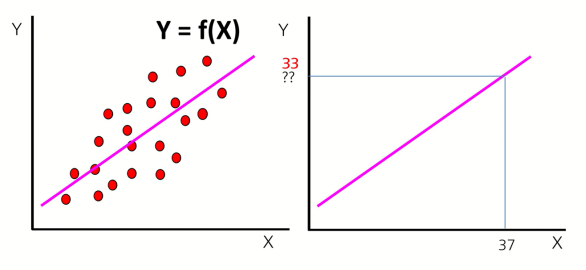
1. 수치 예측 (Numerical Prediction)
-
수치 예측은 연속적인 값(숫자)을 예측하는 문제로, 회귀(Regression) 분야와 크게 관련되어 있습니다.
-
"회귀(Regression)"는 수치 예측 문제에서 데이터를 기반으로 연속적인 값(숫자)을 예측하거나 모델링하는 방법을 의미합니다.
- 이 용어는 통계학에서 처음 사용되었으며, 머신러닝이나 데이터 분석에서도 같은 맥락으로 사용됩니다.
-
-
예측 결과는 주로 실수(float) 또는 정수(int) 데이터 타입으로 표현됩니다.
특징
-
출력 값이 연속형(Continuous)
-
예측 값이 연속된 숫자 범위 안에 있을 수 있습니다.
-
예를 들면: 3.52, 100.78, 2500 등.
-
-
대표적 모델/기법
-
선형회귀(Linear Regression)
-
다항회귀(Polynomial Regression)
-
결정트리 회귀(Decision Tree Regressor)
-
랜덤 포레스트 회귀(Random Forest Regressor)
-
XGBoost, LightGBM
-
신경망 (Neural Networks, 특히 회귀용 구조)
-
-
평가 지표
-
수치 예측 모델의 성능은 오차 기반 지표로 평가합니다. 대표적인 지표는 다음과 같습니다.
-
평균 제곱 오차(MSE, Mean Squared Error)
-
평균 절대 오차(MAE, Mean Absolute Error)
-
평균 제곱근 오차(RMSE, Root Mean Squared Error)
-
결정 계수(R²)
-
-
예제
-
주택 가격 예측: 특정 지역에서 집값을 예측 (연속적인 금액 예측)
-
날씨 예측: 내일의 기온, 강수량, 습도를 예측
-
판매량 예측: 특정 제품의 일간/월간 판매량
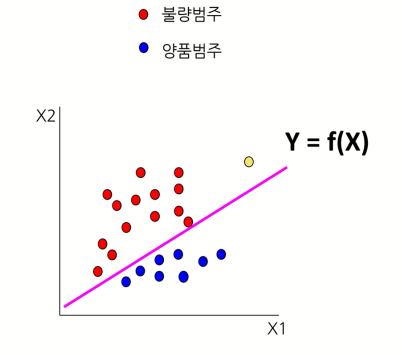
2. 범주 예측 (Categorical Prediction)
-
범주 예측은 데이터가 속할 특정 카테고리(범주)를 예측하는 문제로, 분류(Classification)에 해당됩니다.
-
출력 값은 이산형(Discrete)으로 제한된 범주(클래스) 중 하나를 선택해야 합니다.
특징
-
출력 값이 이산형(Discrete)
-
예측 값이 사전 정의된 클래스(범주) 중 하나로 나타납니다.
-
예를 들면: "고양이", "개", "새" 또는 "정상", "이상".
-
-
범주의 종류
-
이진 분류(Binary Classification): 출력 값이 두 가지인 경우 (예: 스팸/정상 이메일).
-
다중 분류(Multi-class Classification): 클래스가 셋 이상인 경우 (예: 개/고양이/새).
-
-
대표적 모델/기법
-
로지스틱 회귀(Logistic Regression)
-
의사결정나무(Decision Tree)
-
랜덤 포레스트(Random Forest Classifier)
-
서포트 벡터 머신(SVM)
-
k-최근접 이웃 알고리즘(k-NN)
-
신경망(Neural Networks)
-
딥러닝 CNN/RNN
-
-
평가 지표
-
범주 예측의 성능은 다음 주요 지표로 평가합니다.
-
정확도(Accuracy): 전체 정답 예측 비율.
-
정밀도(Precision): 양성으로 예측한 값의 정확성.
-
재현율(Recall): 실제 양성 값을 얼마나 잘 예측했는지.
-
F1 점수(F1-Score): 정밀도와 재현율의 조화 평균.
-
ROC-AUC: 모델의 분류 성능을 시각적으로 나타냄.
-
-
예제
-
스팸 이메일 분류: 이메일이 스팸인지 아닌지 분류
-
이미지 분류: 개/고양이/새 이미지 분류
-
질병 진단: 환자가 질병에 걸렸는지 여부를 예측
-
고객 이탈 분석: 고객이 이탈할지, 남을지를 예측
3. 수치 예측과 범주 예측의 차이점
| 특징 | 수치 예측 (Numerical Prediction) | 범주 예측 (Categorical Prediction) |
|---|---|---|
| 출력 값 | 연속적인 값 (숫자) | 특정 범주 (예: 클래스) |
| 유형 | 회귀 문제 (Regression) | 분류 문제 (Classification) |
| 모델/기법 | 선형 회귀, 랜덤 포레스트 회귀 등 | 로지스틱 회귀, 의사결정나무, SVM 등 |
| 평가 지표 | MSE, MAE, R² | 정확도, 정밀도, 재현율, F1 점수 등 |
| 적용 예 | 주택 가격 예측, 날씨 예측, 판매량 예측 | 이메일 스팸 필터, 이미지 분류, 질병 진단 |
4. 통합 예제: 수치 예측과 범주 예측
-
예시 데이터셋
- 같은 데이터셋도 문제 설정에 따라 달라질 수 있습니다.
수치 예측 문제
-
데이터
-
특징(Feature): 면적 (m²), 방 개수, 위치
-
타겟(Target): 주택 가격($) (연속형 값)
-
-
목표
- 집값을 숫자로 예측 (예: $350,000).
-
모델
- 선형 회귀, 랜덤 포레스트 회귀 등
범주 예측 문제
-
데이터
-
특징(Feature): 면적 (m²), 방 개수, 위치
-
타겟(Target): 주택의 가격 등급 (카테고리: "저가", "중가", "고가")
-
-
목표
- 집이 "저가/중가/고가" 중 어디에 속하는지 분류.
-
모델
- 로지스틱 회귀, SVM, 랜덤 포레스트 분류 등
5. 요약
-
수치 예측: 연속적인 값을 예측하는 회귀 문제.
- 예: 주택 가격, 날씨(기온, 강수량) 예측
-
범주 예측: 데이터를 특정 클래스로 분류하는 문제.
- 예: 스팸 이메일 분류, 이미지 분류
- 두 유형의 문제는 서로 다른 목적과 데이터 출력 형태를 가진다는 점에서 차이가 있으며, 적용 모델과 평가 지표 또한 다릅니다.
