https://www.kaggle.com/code/samuelcortinhas/mish-a-self-regularized-activation-function-tf
활성화 함수의 기울기(Gradient)와 학습 안정성
1) 기울기가 부드럽다는 것의 의미
-
신경망은 역전파(Backpropagation) 를 통해 손실함수의 기울기를 계산하고, 그 기울기를 사용해 가중치를 업데이트한다.
- 따라서 활성화 함수의 기울기(미분값) 가 안정적으로 잘 전달되는지는 학습 가능성 자체를 좌우한다.
-
역전파에서 가중치 업데이트는 다음과 같이 계산된다.
-
여기서 항은 활성화 함수의 미분값이다.
-
즉, 활성화 함수가 어떤 형태냐에 따라 기울기가 끝까지 잘 전달될 수도 있고, 중간에 거의 0이 되어 끊겨버릴 수도 있다.
-
기울기가 0이 되면 그 뉴런은 더 이상 학습하지 않는다.
-
기울기가 갑자기 튀거나 불연속이면 학습이 불안정해진다.
-
-
- 따라서 “기울기가 부드럽다”는 말은, 활성화 함수의 기울기가 모든 구간에서 존재하고, 급격히 튀지 않으며, 점진적으로 변화한다는 뜻이다.
2) 경사 하강법(Gradient Descent)의 원리
-
신경망의 학습은 결국 손실 함수(Loss Function) 를 최소화하는 가중치()를 찾는 과정이다.
- 손실 함수는 모델의 예측값과 실제값의 차이를 수치로 나타내며, 이 값을 최소화하면 모델이 더 정확해진다.
-
경사 하강법은 손실 함수의 기울기(gradient) 를 따라 내려가면서 손실을 줄이는 방법이다.
- 손실 함수의 기울기는 다음과 같이 정의된다.
-
기울기는 함수의 증가 방향을 가리키므로, 그 반대 방향으로 이동하면 손실을 줄일 수 있다.
- 따라서 가중치의 갱신은 다음 식으로 표현된다.
- 여기서 는 학습률(learning rate) 로, 한 번에 얼마나 이동할지를 조절하는 상수다.
-
경사 하강법은 직관적으로 공을 언덕 아래로 굴리는 과정으로 생각할 수 있다.
-
손실 함수의 값(Loss)은 “높이(height)”
-
가중치(weight)는 “공의 위치(x, y)”
-
기울기(gradient)는 “언덕의 경사도”
-
학습률(η)은 “공이 한 번에 굴러가는 거리”
-
-
학습이란 결국 공이 손실 함수의 곡면을 따라 내려가며 최저점(최적의 가중치) 에 도달하는 과정이다.
3) ReLU와 Mish의 비교
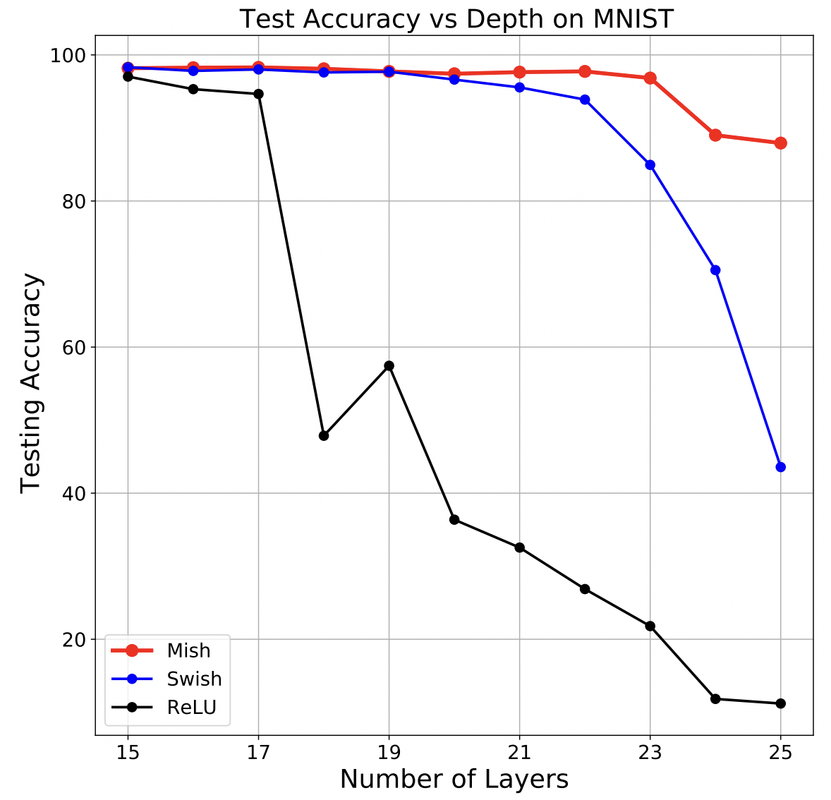
(1) ReLU
-
ReLU(Rectified Linear Unit)는 다음과 같이 정의된다.
-
일 때는 그대로 를 내보낸다.
-
일 때는 0을 출력한다.
-
-
ReLU의 미분(기울기)은 다음과 같다.
-
이 특성은 다음과 같은 결과를 만든다.
-
음수 입력 구간에서는 기울기가 0이므로, 뉴런이 더 이상 갱신되지 않는다.
→ 이를 죽은 뉴런(Dying ReLU) 문제라고 한다.
-
근처에서 기울기가 갑자기 바뀌므로(0 → 1로 점프),
미분이 불연속적이며 학습이 거칠어질 수 있다.
-
-
ReLU의 장점은 계산이 매우 빠르고, 깊은 신경망에서도 일정 수준의 기울기가 유지된다는 점이다.
- 따라서 여전히 가장 널리 사용되는 활성화 함수이다.
(2) Mish
-
Mish는 다음과 같이 정의된다.
-
여기서 항은 softplus 함수이다.
-
softplus를 에 통과시킨 후 최종적으로 와 곱한다.
-
-
Mish의 미분 과정을 전개하면 다음과 같다.
-
곱의 미분법 적용
-
의 미분은 이므로,
-
의 미분은 시그모이드이다.
-
위 결과를 모두 합치면,
-
-
Mish의 중요한 특성은 다음과 같다.
-
모든 구간에서 기울기가 존재한다.
-
기울기가 0으로 고정되어 죽는 뉴런이 없다.
-
기울기가 끊기거나 급격히 튀지 않고, 연속적으로 변화한다.
-
-
결과적으로 Mish는 학습 과정에서 gradient의 흐름이 자연스럽게 유지되도록 도와준다.
- 이 점이 ReLU와의 가장 큰 차이이다.
4) 손실 함수의 지형(loss surface)과 학습 안정성
-
손실 함수의 값은 “지형의 높이(height)”, 가중치들은 “지형의 좌표(x, y)”라고 볼 수 있다.
- 즉, 신경망의 학습은 언덕 위에서 공을 굴려 최저점을 찾는 과정이다.
-
이때 활성화 함수의 형태는 이 “지형의 모양”에 직접적인 영향을 준다.
-
ReLU는 0에서 꺾이기 때문에 손실 곡면이 각지고 불연속적이다.
-
Mish는 완만한 곡선이므로 손실 곡면이 부드럽고 연속적이다.
-
-
손실 곡면이 불연속적이면, 기울기가 갑자기 사라지거나 튀어 공(모델)이 제대로 굴러가지 못한다.
-
반면 손실 곡면이 매끄럽다면, 공은 부드럽게 내려가며 안정적으로 최소점에 도달한다.
구분 손실 곡면 형태 학습 특성 ReLU 각지고 불연속적 공이 멈추거나 튐 (불안정) Mish 곡면형, 연속적 공이 부드럽게 수렴 (안정적)
-
- 따라서 활성화 함수의 부드러움은 곧 손실 함수의 매끄러움과 연결되며, 이는 경사 하강법이 안정적으로 작동하기 위한 전제 조건이다.
5) 부드러운 기울기의 학습 효과
-
기울기가 부드럽게 유지된다는 것은 다음을 의미한다.
-
역전파 시 기울기가 0으로 사라지거나 폭발적으로 커지지 않는다.
-
손실 함수의 지형(loss surface)이 매끄러운 곡면처럼 동작하므로,
경사 하강법이 안정적으로 최소점을 탐색할 수 있다. -
입력의 작은 변화가 출력의 급격한 변화를 유발하지 않아, 모델의 일반화 능력(새로운 데이터 대응력)이 향상된다.
-
깊은 층까지 gradient가 전달되어 심층 신경망에서도 학습이 지속된다.
-
→ 기울기가 부드러운 활성화 함수는 학습의 안정성과 지속성을 보장한다.
6) ReLU 계열과 Mish의 선택 기준
-
ReLU 계열 (ReLU, Leaky ReLU, PReLU 등)
-
계산이 빠르고 단순하며 대규모 네트워크에 적합하다.
-
GPU 효율이 중요하거나, 빠른 수렴이 필요한 경우 유리하다.
-
-
Mish 및 Swish 계열
-
계산량은 약간 많지만 기울기가 연속적이고 부드럽다.
-
학습이 보다 정교하고 안정적이며, 고정밀 시각 인식·객체 탐지(YOLOv4 등) 모델에서 높은 성능을 보인다.
-
-
정리하면 다음과 같다.
-
ReLU류: 속도와 단순성 중심
-
Mish류: 안정성, 표현력, 일반화 중심
-
7) 핵심 요약
-
활성화 함수의 기울기가 부드럽다는 것은, 역전파 중 신호가 약해지거나 끊어지지 않고 신경망 전체로 고르게 퍼진다는 의미이다.
- 이는 신경망이 끝까지 학습을 지속할 수 있도록 보장하는 핵심 요인이다.
결론적으로, 활성화 함수는 단순히 출력을 조정하는 수학식이 아니라
신경망이 얼마나 안정적이고, 깊게, 정확하게 배울 수 있는지를 결정하는 핵심 설계 요소이다.
