Redis 자료구조 : List Collection
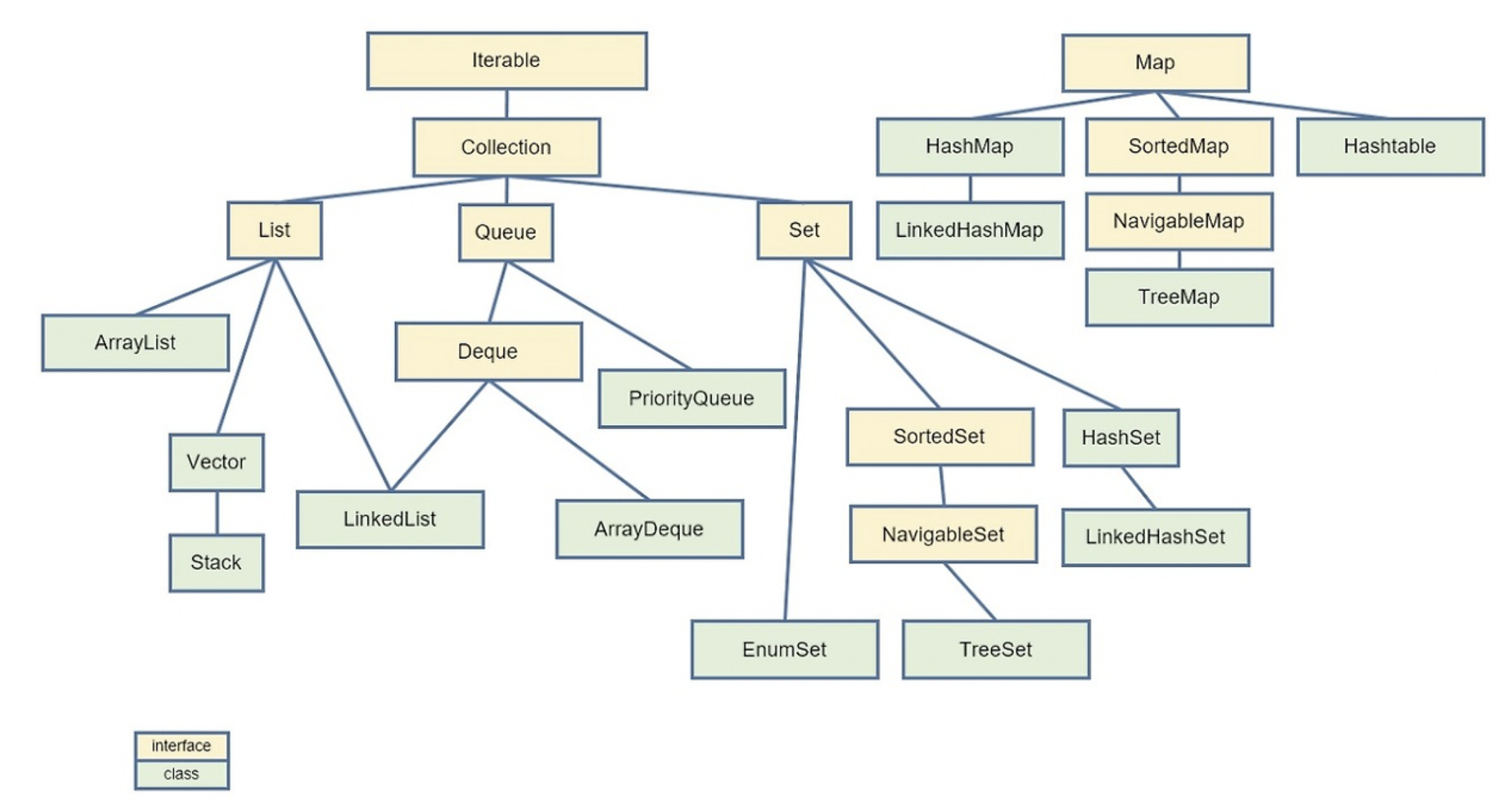
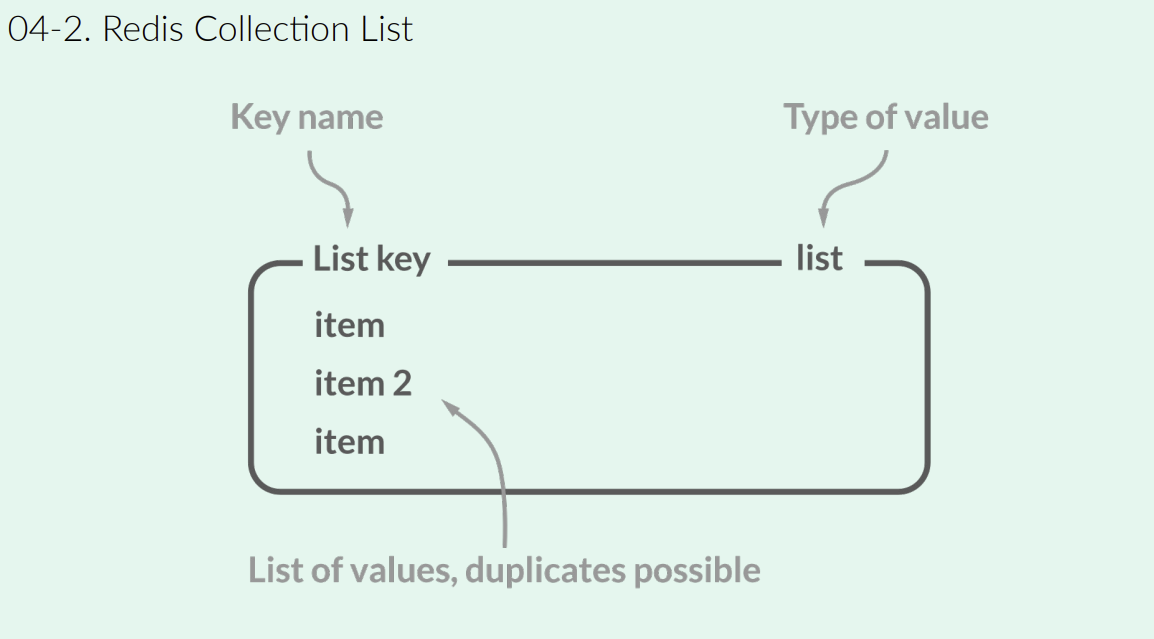
Redis의 List는 Linked-List 형태로 구현된 자료구조이다. 이는 양방향으로 데이터를 빠르게 추가/제거할 수 있는 특성을 가지고 있어, 특정 경우에 매우 효율적인 성능을 기대할 수 있다..
List에 대한 자세한 설명은 정리가 잘 된 블로그가 있어 대체하도록 하겠다. List 포스팅 바로가기
1. Linked-List란?
Linked-List는 각 요소가 노드(Node)로 구성되어 있고, 각 노드는 데이터와 다음 노드를 가리키는 포인터를 가지고 있는 자료구조이다. Redis의 List는 이러한 Linked-List와 유사하게, 각 요소가 연결되어 있는 구조를 가진다.
-
Linked-List의 특성 상, Head와 Tail에 데이터를 추가하는 데 동일한 시간이 소요된다.
-
특정 위치에 데이터를 삽입하거나 조회하는 데 시간이 더 걸릴 수 있지만, ( O(n)의 시간 복잡도), Head와 Tail에서의 삽입/삭제가 매우 빠르다. ( O(1)의 시간 복잡도 )
2. Redis List 명령어
Redis List는 여러 가지 명령어를 제공하여 데이터를 쉽게 처리할 수 있다
Push POP ( L와 R이 붙음으로서 Head 나 Tail중 어느 곳에 데이터를 Push POP을 할 것인지 결정한다. )
1. LPUSH / RPUSH: Head / Tail에 데이터 추가
- LPUSH: 리스트의 head(앞쪽)에 데이터를 추가한다.
- RPUSH: 리스트의 tail(뒤쪽)에 데이터를 추가한다.
> LPUSH mylist "A" # Head에 A 추가
> RPUSH mylist "B" # Tail에 B 추가2. LPOP / RPOP: Head / Tail에서 데이터 제거
-
LPOP: 리스트의 head에서 데이터를 제거하고 반환한다.
-
RPOP: 리스트의 tail에서 데이터를 제거하고 반환한다.
> LPOP mylist # Head에서 데이터 제거
"A"
> RPOP mylist # Tail에서 데이터 제거
"B"3. LLEN: 리스트 길이 조회
- LLEN: 리스트의 길이(총 요소 개수)를 반환한다.
> LLEN mylist # 리스트 길이 조회
(integer) 0그러나 Head나 Tail이 아닌 Head와 Tail사이 그 어딘가 데이터를 수정할 필요가 있는 경우가 있다. ( 특정 값의 인덱스의 위치를 찾아야 하는 경우 or 어떤 값을 갖고 있는지 조회해야 할 경우 )
-> LPOS, Line Index 사용
Push Pop과는 다르게 O(1)의 시간복잡도가 아닌 O(n)의 시간복잡도를 갖는다고 한다. ( 상대적으로 비효율적 )
4. LPOS ( List Position ): 특정 값의 인덱스 조회
- LPOS: 리스트에서 주어진 값이 위치한 인덱스를 반환한다.
>LPUSH mylist "apple" "banana" "apple" "cherry"
>LPOS mylist "apple" // 결과: 2 (첫 번째 "apple"의 위치)
"2"
>LPOS mylist "apple" COUNT 2 // 결과: [2, 0] (모든 "apple"의 위치)
"[2, 0]"5. Line Index: 특정 인덱스 값 조회
- Redis에서는 Line Index를 사용하여 특정 인덱스에 위치한 값을 조회할 수 있다.
# 리스트 생성
RPUSH mylist "A" "B" "C" "D" "E"
# 양수 인덱스 접근
LINDEX mylist 0 // "A" 반환 (첫 번째 요소)
LINDEX mylist 2 // "C" 반환 (세 번째 요소)
# 음수 인덱스 접근
LINDEX mylist -1 // "E" 반환 (마지막 요소)
LINDEX mylist -2 // "D" 반환 (뒤에서 두 번째 요소)
# 범위를 벗어난 인덱스
LINDEX mylist 10 // (nil) 반환- List 와 Rinked-List의 시간 복잡도 차이
Array: [A][B][C][D][E] // 메모리 연속 할당
→ 인덱스 3에 직접 접근 가능 O(1)
Linked List: [A]→[B]→[C]→[D]→[E] // 메모리 분산 할당
→ 인덱스 3에 접근하려면 A→B→C→D 순서로 이동 O(N)6. Plus : 시간 복잡도 정리
- 이러한 시간 복잡도 특성 때문에 Redis List는 주로 큐(Queue) 처럼, 양끝에서의 작업이 주를 이루는 용도로 사용하는 것이 효율적이다.
LPUSH/RPUSH : O(1) // 양끝 삽입
LPOP/RPOP : O(1) // 양끝 삭제
LINDEX : O(N) // 중간 요소 접근
LINSERT : O(N) // 중간 삽입
LSET : O(N) // 중간 수정3. Redis List 활용 사례
List 형태를 사용하게 된다면 사용 가능한 모델링이 있다.
많이 사용되지는 않지만, Job Queue, Pub/Sub 모델 구현 등에 사용되며, BRPOP, BLPOP과 함께 사용이 되기도 한다.
1. Job Queue
- Redis List는 작업 큐(Job Queue)로 활용될 수 있다. 예를 들어, 여러 인스턴스가 하나의 큐에서 작업을 꺼내 처리하는 구조라면, 각 인스턴스는 큐에서 작업을 하나씩 꺼내서 처리하며, 모든 작업이 처리되면 큐가 비게 된다. 이때 BRPOP이나 BLPOP 명령어를 사용하여 큐에서 데이터를 가져오고, 큐가 비면 대기하는 방식으로 구현할 수 있다
> BRPOP myqueue 0 # 큐에서 대기하며 작업을 처리 (큐에 데이터가 들어올 때까지 대기)
2. Pub/Sub 모델 구현
- Redis는 자체적으로 Pub/Sub 모델을 제공하지만, List 자료구조와 BRPOP / BLPOP을 함께 사용하면 데이터를 지속적으로 풀링하면서 이벤트를 대기하는 방식으로 사용할 수 있다. 이를 통해 이벤트 기반 시스템을 구축할 수 있다.
Pub/Sub 구조에 대한 강사님의 말
특정 인스턴스는 리스트에 들어있는 데이터를 기반으로 어떤 데이터를 가공하고 처리하고 있다. 해당 인스턴스는 지속적으로 리스트에 있는 데이터를 가져와서 처리를 해야 하는 상태.
그런 경우에 대해서 BRPOP, BLPOP을 사용한다면, 데이터가 들어올 떄까지 계속해서 풀링을 하게된다.
"그래서 일종의 이벤트를 계속해서 풀링한다" 처럼 동작할 수 있기 떄문에 이러한 부분도 활용 가능
( Pub/Sub 을 만들고 싶다고 이런 리스트를 사용하지 않아도 된다. 어차피 Redis에서 Pub/Sub 모델도 제공을 한다고 하기 떄문. )
-> 말이 너무 어렵다면 RabbitMQ 처럼 메세지 큐 방식을 떠올려보자. 생각해보면 그냥 똑같은 말이다..
4. Redis 사용 시 장점
1. 빠른 삽입/삭제:
- LPUSH, RPUSH, LPOP, RPOP 명령어는 모두 O(1) 시간 복잡도를 가진다. 떄문에 데이터를 Head와 Tail에서 추가하거나 제거할 때 매우 빠르다.
2. 특정 위치 접근:
- LPOS, LINDEX 등을 통해 리스트 내에서 특정 값을 찾거나 특정 인덱스를 조회할 수 있다. 하지만 중간에 데이터를 수정하거나 조회하는 것은 O(n) 시간이 소요되므로, Head와 Tail에서의 작업이 가장 효율적이다.
3. 이벤트 기반 시스템:
- BRPOP, BLPOP을 이용하여 큐에서 데이터를 대기하고, 데이터가 들어올 때까지 기다릴 수 있어 이벤트 기반 처리에 유용하다.
5. Redis List 활용 시 주의점
1. 메모리 관리:
- 리스트가 커질 경우 메모리 사용량이 증가하므로, 적절한 크기의 리스트 관리와 메모리 최적화가 필요하다.
2. 인덱스 조회 성능:
- 리스트 중간에 있는 데이터를 조회하는 경우 성능이 떨어질 수 있으므로, 필요한 경우 head나 tail을 주로 활용하는 것이 좋다.
3. 동시성 처리:
- 여러 클라이언트가 동시에 데이터를 삽입하거나 제거하는 경우, 적절한 동기화나 락 처리가 필요할 수 있다.
정리
Redis List는 Linked-List를 기반으로 하여 빠른 삽입/삭제와 특정 인덱스 접근을 지원하는 자료구조다. 이를 활용하면 Job Queue, Pub/Sub 모델 등 다양한 실시간 시스템을 구축할 수 있으며, Redis의 고성능 특성을 그대로 활용할 수 있다. 하지만 리스트 중간에 있는 데이터를 조회하는 데는 성능상의 한계가 있으므로 Head와 Tail에서의 작업을 주로 사용하는 것이 좋다.
