Redis 자료구조 : Set Collection
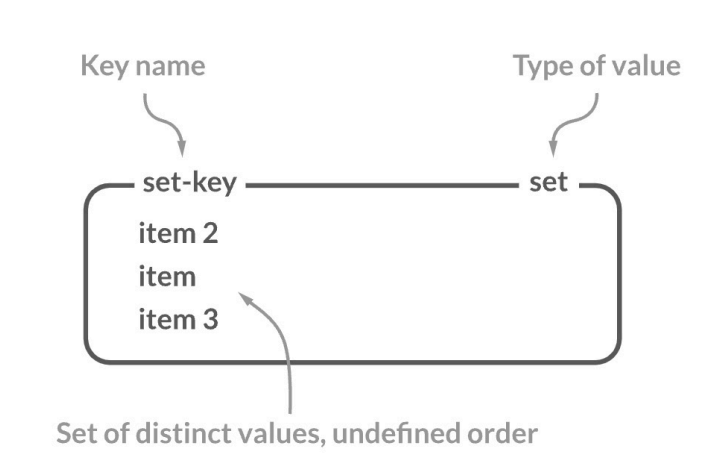
1. Set이란?
Redis의 Set 자료구조는 중복 없이, 정렬되지 않은 문자열의 모음이다. 하나의 Key에 대해 여러 개의 Value를 저장할 수 있으며, 중복 데이터는 허용되지 않는다. 또한, Redis에는 Sorted Set도 제공하며, 이는 Set에 정렬 기능이 추가된 형태다.
두 타입은 기본적으로 데이터가 기존에 존재했는지 아닌지에 대한 중복 체크나, 관계를 표현할 떄 많이 사용된다. 가장 단순한 명령어로는 SADD, SREM 등이 있다.
1-2. Set의 특징
-
중복 불허: Set 내에 동일한 값이 저장되지 않는다.
-
정렬 없음: 값들이 정렬되지 않은 상태로 저장된다.
-
빠른 연산: Set의 데이터 추가, 삭제, 확인 등이 O(1)의 시간 복잡도로 매우 빠르다.
-
활용: 중복 체크, 관계 표현, 집합 연산 등에 주로 사용된다.
1-3. Set의 주요 명렁어
1. 데이터 추가 및 삭제
- SADD: Set에 새로운 데이터를 추가한다.
> SADD myset "Alice" "Bob" "Charlie"
(integer) 3- SREM: Set에서 특정 데이터를 제거한다.
> SREM myset "Alice"
(integer) 12. 데이터 조회
- SMEMBERS: Set 내 모든 값을 반환한다.
> SMEMBERS myset
1) "Bob"
2) "Charlie"- SPOP: Set에서 임의의 값을 반환하고 삭제한다.
> SPOP myset
"Charlie"- SCAN: 대량의 데이터를 페이지 단위로 가져온다.
> SCAN 0 MATCH myset:* COUNT 103. 데이터 포함 여부 확인
- SMISMEMBER: 특정 값이 Set에 포함되어 있는지 확인한다. 값을 가져오지 않아 네트워크 I/O 비용을 줄인다.
> SADD myset "Alice" "Bob"
(integer) 2
> SMISMEMBER myset "Alice"
(integer) 14. 집합 연산
-
SUNION: 두 Set의 합집합을 반환한다.
-
SINTER : 두 Set의 교집합을 반환한다.
-
SDIFF : 두 Set의 차집합을 반환한다.
> SADD set1 "Alice" "Bob"
> SADD set2 "Bob" "Charlie"
> SUNION set1 set2
1) "Alice"
2) "Bob"
3) "Charlie"
> SINTER set1 set2
1) "Bob"2. Sorted Set이란?
기존 Set과 다르게 Sorted Set은 Set에 정렬 기능을 추가한 자료구조이다. 저장된 값(Value)과 함께 Score라는 숫자 값을 유지하며, 이 Score를 기준으로 값이 정렬된다
2-1. Sorted Set의 주요 명렁어
1. 데이터 추가 및 삭제
- ZADD: Sorted Set에 데이터를 추가하며 Score 값을 함께 지정한다.
> ZADD leaderboard 100 "Alice" 200 "Bob"
(integer) 2- ZREM: 특정 데이터를 제거한다.
> ZREM leaderboard "Alice"
(integer) 12. 데이터 조회
- ZRANGE: 특정 범위 내의 데이터를 오름차순으로 반환한다.
> ZADD leaderboard 100 "Alice" 200 "Bob" 150 "Charlie"
> ZRANGE leaderboard 0 -1 WITHSCORES
1) "Alice"
2) "100"
3) "Charlie"
4) "150"
5) "Bob"
6) "200"- ZREVRANGE: 특정 범위 내의 데이터를 내림차순으로 데이터를 반환한다.
> ZADD leaderboard 100 "Alice" 200 "Bob" 150 "Charlie"
> ZREVRANGE leaderboard 0 -1 WITHSCORES
1) "Bob"
2) "200"
3) "Charlie"
4) "150"
5) "Alice"
6) "100"3. 순위 계산
- ZRANK: 특정 데이터의 순위를 반환한다.
> ZRANK leaderboard "Bob"
(integer) 1- ZCOUNT: 특정 범위 내의 데이터 수를 반환한다.
# Sorted Set 데이터 추가
>ZADD leaderboard 100 "Player1" 200 "Player2" 150 "Player3"
# 내림차순으로 정렬된 데이터를 조회 (상위 3명)
>ZREVRANGE leaderboard 0 2 WITHSCORES
1) "Player2"
2) "200"
3) "Player3"
4) "150"
5) "Player1"
6) "100"3. Set, Sorted Set의 활용 예시
1. 중복 데이터 관리
- 사용자 세션 관리
현재 로그인한 사용자들의 세션 ID를 저장
중복 로그인 방지를 위한 사용자 ID 관리
로그아웃 시 세션 삭제
# 세션 ID 저장
SADD active_sessions "session1" "session2"
# 특정 세션 ID 확인
SMISMEMBER active_sessions "session1"
# (integer) 1 (존재)
# 세션 로그아웃 시 삭제
SREM active_sessions "session1"# 사용자 ID 저장
SETNX user:login:user1 "session1"
# 다른 세션 ID로 중복 로그인 시도 시 실패
SETNX user:login:user1 "session2"
# (integer) 0 (이미 존재)
# 로그아웃 시 키 삭제
DEL user:login:user12. 우선순위 큐
- 작업의 우선순위를 Score로 지정하여 높은 순위부터 처리
# 작업 추가 (score는 우선순위)
ZADD task_queue 10 "Task1" 5 "Task2" 20 "Task3"
# 가장 높은 우선순위의 작업 조회
ZRANGE task_queue 0 0 WITHSCORES
# "Task3", 20
# 작업 처리 후 삭제
ZREM task_queue "Task3"
3. 랭킹 시스템
- 사용자 점수에 따른 리더보드 구현
# 사용자 점수 추가/업데이트
>ZADD leaderboard 1500 "Player1" 2000 "Player2" 1200 "Player3"
# 상위 3명의 순위와 점수 조회
>ZREVRANGE leaderboard 0 2 WITHSCORES
1) "Player2" 2) "2000"
3) "Player1" 4) "1500"
5) "Player3" 6) "1200"
# 특정 사용자의 순위 조회
>ZRANK leaderboard "Player1"
(integer) 1
# 특정 사용자의 점수 조회
>ZSCORE leaderboard "Player1"
"1500"
4. 실시간 검색어 순위
# 검색어의 Score를 실시간 업데이트
>ZINCRBY trending_keywords 1 "Redis"
>ZINCRBY trending_keywords 1 "Python"
>ZINCRBY trending_keywords 1 "Redis"
# 상위 5개의 인기 검색어 조회
>ZREVRANGE trending_keywords 0 4 WITHSCORES
1) "Redis" 2) "2"
3) "Python" 4) "1"
정리
1. Set
- 중복 없이 값을 저장하고, 집합 연산과 관계 표현에 유용하다
예: 중복 데이터 확인, 관계 데이터 저장, 집합 연산.
2. Sorted Set
-
Score를 기반으로 정렬된 데이터를 저장하며, 순위 관리 및 우선순위 기반 작업에 적합하다.
예: 리더보드, 우선순위 큐, 시간 기반 데이터 관리. -
Redis의 Set과 Sorted Set은 다양한 데이터 관리와 처리 작업에서 중요한 역할을 하며, 필요에 따라 적절히 활용하면 높은 효율을 얻을 수 있다.

안녕하세요!! 백엔드 개발자를 희망하는 취준생입니다 !!