“ Causal LM with Prompt tuning 그리고 Few shot Text Classification. ”
Sewon Min et al., 2022, ACL 2022. (University of Washington)
1. Introduction & 2. Related Work
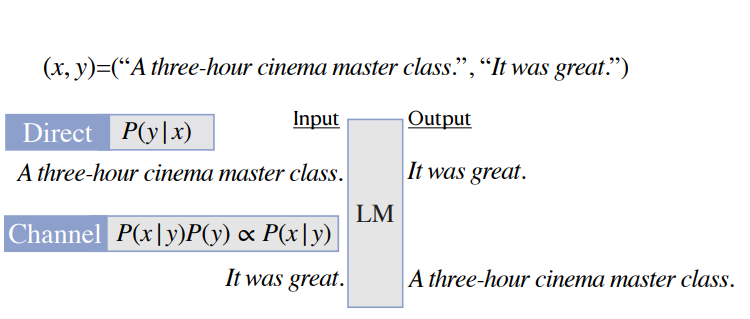
요약
💡 본 논문은 text classification task에 prompt 기법을 활용하여 언어모델을 기반으로 few-shot learning 방법들을 비교한다. 특히, Noisy channel 이라는 접근법을 제시하고 있는데, Noisy channel 접근법이란 기존에 텍스트 분류 태스크를 베이지안 정리를 이용하여 이를 바꿔서 확률을 계산하는 기법을 의미한다. 예로 들면 x 텍스트에 대해 y라는 레이블을 예측시키도록 모델을 학습하거나 추론 하였는데 (여기서는 direct라고 부른다.), 그 대신 이를 베이즈 정리를 이용해서 y가 예측될 사전 확률에 y가 주어졌을 때, x가 발생할 확률을 곱하여 (i.e. p(x|y)p(y)) 이를 확률 계산하도록 한 것이다. (베이즈 정리에 대한 자세한 정리는 추후 정리해볼 예정이다.)- Fomulation
- 우리는 텍스트 분류 tasks들에 집중한다. 우리의 목적은 task 함수 를 학습하는 것이다. (where : the set of all natural language texts and is a set of labels)
1) Direct : 레이블들의 분포를 입력값 x가 주어졌을 때, 계산한다.
Modern neural networks 에서 가장 많이 쓰는 방법론이다.
2) Direct++ : 더 강한 direct 모델로, 앞선 대신 을 계산한다. 이런 접근법은 LMs이 교정(calibration)에 취약하고 같은 의미지만 다른 strings에 취약하다는 사실에 착안하여 계산한 것이다.
(예를 들어 기존 계산에 LMs이 아무 값도 입력되지 않았을 때, 레이블을 예측할 확률에 대한 값을 나눠준다.)
3) Channel : Bayes’ rule을 사용하여 앞선. 을 으로 재정의한다. 우리는 일반적으로 P(x)는 로부터 독립적일 때, 특정 클래스에 대해서 을 argmax 하는 것에 관심이 있다. 우리는 으로 가정하고 에 대해 계산하였다.
4. Method
- 우리는 direct 그리고 channel 모델들을 라고 부른 cuasal language model (LM) 을 이용하여 탐구하였다. 를 이용하여 주어진 x에 대해 text y에 대한 조건부 확률을 얻을 수 있다. 더 정확히, Vocabulary 집합으로 구성된 텍스트 x 그리고 y에 대해 는 을 의미한다.
- Task function 을 학습하는데, 우리는 미리 정의된 을 기반으로 각 레이블을 자연어 표현으로 치환시킨다.
- 예를 들어 sentiment analysis의 으로 두고, 예제 텍스트 “A three-hour cinema master class”에 대해 example 는 = “It was great” = “It was terrible”.이라고 볼 수 있다. Few-shot setup을 위해, 우리는 K 개의 학습 예제들을 준다.
- 우리는 학습하지 않는 파라미터들에 관심이 있다 (Zero-shot). 특히 학습 수가 전체에서 0.01% 미만으로 아주 작은 것(Tuning Method) 에 또한 관심이 있다. 이는 이전에 거대한 수의 파라미터로 각 task마다 학습하는 것이 비싸고 종종 실행불가능한 것에 대한 관찰에 따른다.
4.1 Demonstration methods
- 이 섹션에선 파라미터를 학습하지 않는다.

Zero-shot
그리고 에 대해 그리고 으로 계산한다. 예를 들어 channel 모델에선 텍스트** “A three-hour cinema master class”에 대해서 “it was terrible”을 예측한 확률 값을 구한다.
Concat-based demonstrations
****Few-shot 메서드를 따른다. Direct 모델 기준으로 제로샷이 정말 단순하게 x를 주고 v(c)를 구하고자 했다면 concat 방법은 여기에 K 예제들을 함께 결합하여 입력한다. 이를 통해 언어 모델의 확률 값을 구할 때, 태스크 setup도 함께 배우도록 한다.
# Concat based input checkEnsemble-based demonstrations
저자들은 더 강한 direct 모델을 만들기 위해서 K 학습 예제들을 결합한 방식 대신, 한번에 한 개의 학습 예제를 입력해 output probabilities를 구하고, 이를 K번 조건부 확률로 곱하여 최종 결과를 구한다. 이를 수식으로 표현하면
이 방법론은 Concat-based 방법에 비해 메모리를 절약할 수 있다. 논문에서는 이 방법이 만큼의 공간 복잡도를 차지하여 기존 Concat 베이스의 의 공간복잡도보다 이를 아끼고 순서대로 들어가야하는 dependancy를 줄일 수 있다고 이야기하고 있다. 그리고 이렇게 하였을 떄 오히려 모델의 성능이 향상됐음을 이야기한다.
# Ensemble based input check4.2 Tuning methods
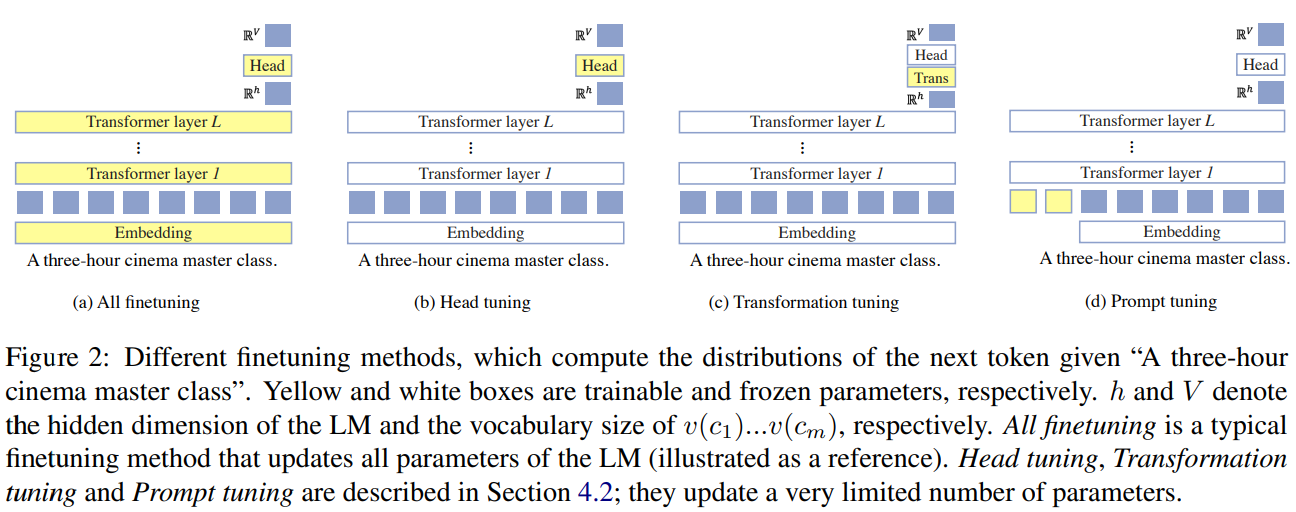
Head tuning
Head를 파인튜닝한다. Head란 LM의 transformer layer 마지막에 나온 hidden representation 을 logit values로 바꿔주는 matrix이다. (예를 들어, 14 by 768 트랜스포머 레이어를 통과하여 결과가 나온다고 했을 때,이를 14 by vocab 개수 만큼 변환시켜준다.) 비록 O가 LM의 임베딩 레이어에 tied되어 있지만 기존 이를 함께 학습한 매트릭스와 다르게 이를 random 초기화 했다고 저자들은 이야기하고 있다
Tranformation tuning
Head tuning 대신 의 transformation matrix을 학습시킨다. 의 의 확률을 계산한다. 이 때 O는 LM 파라미터와 마찬가지로 학습 시 고정한다.
Prompt tuning
기본적으로 LM을 블랙박스 모델로 간주하고, promt embeddings을 배우도록 하는 것이다. 따라서 프롬프트 튜닝을 따를 때, direct 모델 그리고 hannel 모델 모두 x와 함께 이 함께 입력되어 이 임베딩을 학습하게 된다. 즉 학습 시, 이 프롬프트 토큰들의 임베딩 값이 학습되게 된다.
- direct model compute :
- channel models compute :
# Head tuning
# Transformation tuning
# Prompt tuning
5. Experimental Setup
Datasets : 11개의 텍스트 분류 데이터세트를 이용. 아래는 데이터세트의 통계 자료.
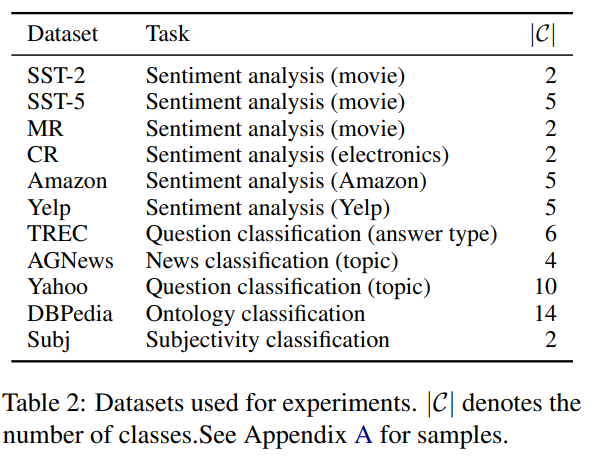
Training Data
Few shot setup : (4,16,64, Full 비교) - 레이블 별 동일한 학습 데이터 수를 가정.
제한된 한정 데이터를 학습으로 썼다.
Language Models
- LM으로 GPT-2 를 사용하였다. 우선적으로 GPT-2 Large를 사용하고 그 사이즈를 달리하여 실험하고 경향성을 확인하였다. 그리고 저자들은 이 실험 결과들이 다른 causal language model들에게도 쉽게 확장될 수 있음을 이야기한다.
Evaluation
- 4개의 verbalizaers를 사용하였다. 아래와 같은 verbalizer들을 사용했다고 한다.
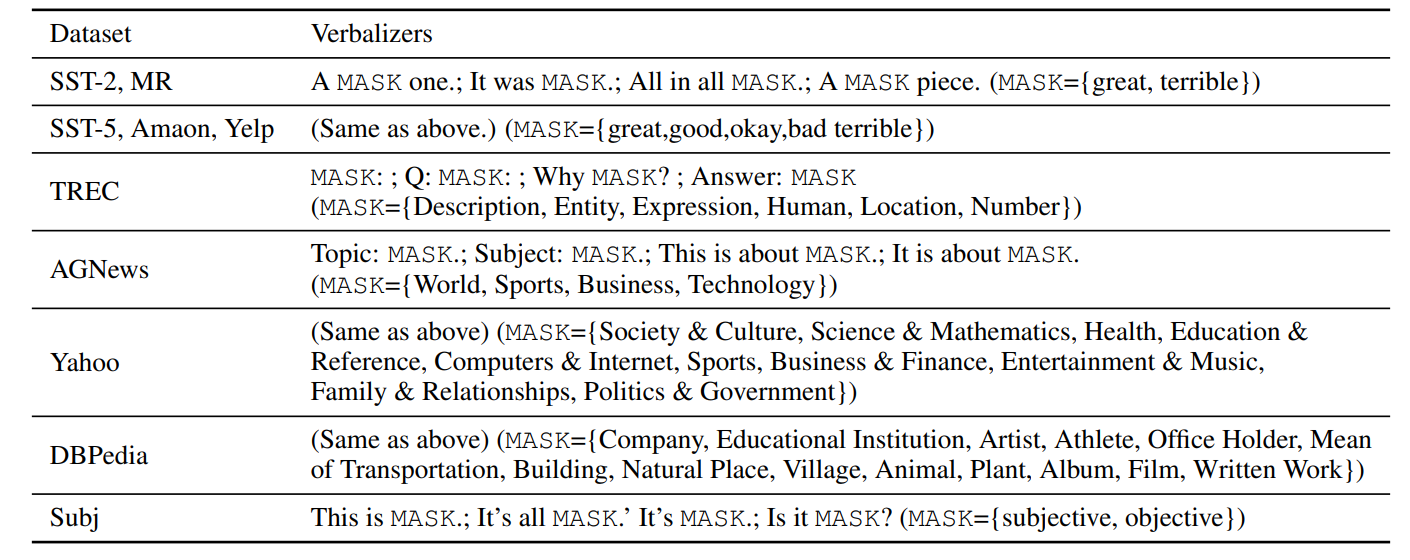
-
Comment
- 쉽게 템플릿이라고 생각하면 될 것 같다.
-
저자들은 평균 정확도와 최악의 정확도를 함께 확인하여 프롬프트 방법론이 지니는 한계를 보완하고자 했다. 특히 few shot learning 모델들이 high variance를 보여주기 때문에 평균 정확도는 이를 위해서라도 필요하다. 이는 과거의 연구들도 그렇다. (Zhao et al., 2021; Perez et al., 2021). 또한 high-risk application을 위해 최악 정확도도 필요하다.
6. Experimental Results

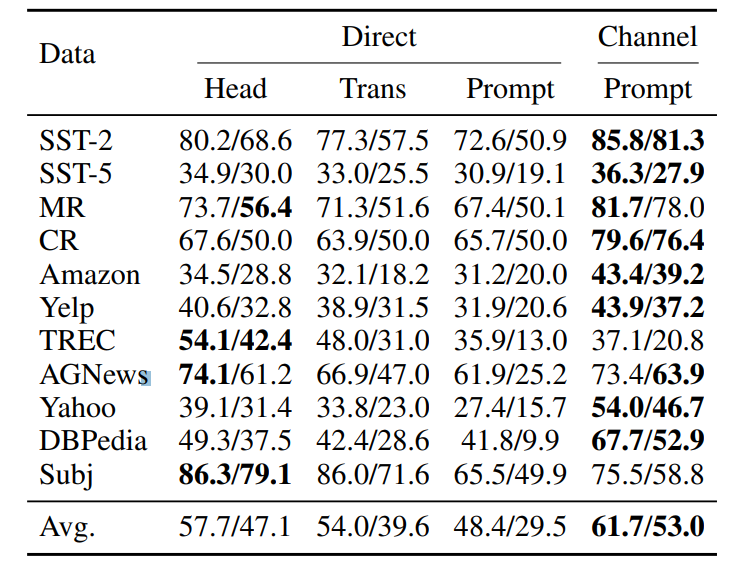
저자들은 4가지로 나누어서 결과를 설명하였다. 테이블의 숫자 A/B 의 경우 A는 average accuracy B는 worst-case accuracy를 기록한 것을 확인할 수 있다. 여기서 평균을 구한 이유는 verbalizer 그리고 데이터 시드를 달리 줬음을 이야기한다.
Direct vs. Direct++
- Direct보다 Direct ++ 결과가 거의 모두 좋은 것을 확인할 수 있다.
Concat vs Ensemble
- 앙상블 베이스 모델의 결과가 direct 모델에서 Concat 베이스 모델보다 성능이 좋았다고 이야기하고 있다. channel 모델에서 앙상블 방법론이 항상 좋진 못했는데 긴 입력값에 대해서만 좋은 성능을 보여주었다. 이 경우에 대해 저자들은 레이블 뷸균형이 있을 때, 이런 경향이 나타나는 것으로 짐작하였다.
Direct++ vs. Channel
- Channel 모델이 대부분의 실험 결과에서 성능 향상을 보인다. 가장 차이가 나는 모델은
Zero-shot vs. Few-shot
- Zero-shot과 Few-shot에서의 direct 모델의 성능을 비교했을 때, Few-shot에서 더 떨어진 것을 확인할 수 있다. 이런 결과는 이전의 실험들의 관찰된 바와 유사하다.
- 하지만 channel 모델에서는 오히려 few-shot에서 성능이 향상되는 것을 관찰할 수 있다. 모든 데이터세트에 대해 zero-shot 성능보다 높았다.
Main Results : Tuning Methods
Comparison when prompt tuning
- channel 방식이 prompt 를 이용하여 튜닝하였을 때, 모든 데이터에서 큰 성능 차이로 더 좋은 성능을 보였음을 확인한다. 특히 이런 양상은 평균적인 정확도 향상뿐만 아니라 worst case에 대한 성능도 크게 향상됨을 관찰하였다고 설명한다.
- *특히 논문에서 더 강조하는 점은 Direct한 prompt는 best case의 경우 비슷하게 성능이 좋지만, worst case에 대해서 정확도에 channel 성능의 변동 폭(variance)이 적었다는 점이다.*
Head tuning vs. prompt tuning
- 논문에서는 head tuing 자체가 매우 강력했다고 설명하고 있다. 모델의 거의 모든 사이즈에서 Direct head 성능이 Direct promt 성능보다 더 나은 것을 실제로 확인할 수 있다. 특히 Language modeling과 태스크 형태 자체가 다를수록(e.g. TREC) 그 양상이 크게 보임을 해석하고 있다.
- 하지만, channel 방식을 사용했을 때 prompt tuning 성능은 direct head tuning 성능보다 더 나은 것을 확인할 수 있다고 설명한다. 저자들은 이러한 이유에 대해서 K개의 프롬프트가 일반적으로 unseen한 레이블에 대해 일반화할 수 있기 때문이라고 추측한다.
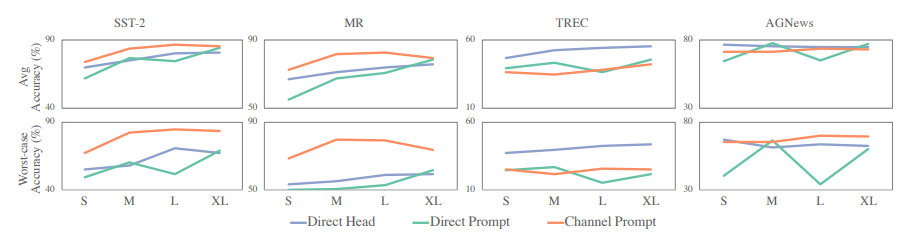
Ablation
- 학습 예제들(K) 의 변이 실험.
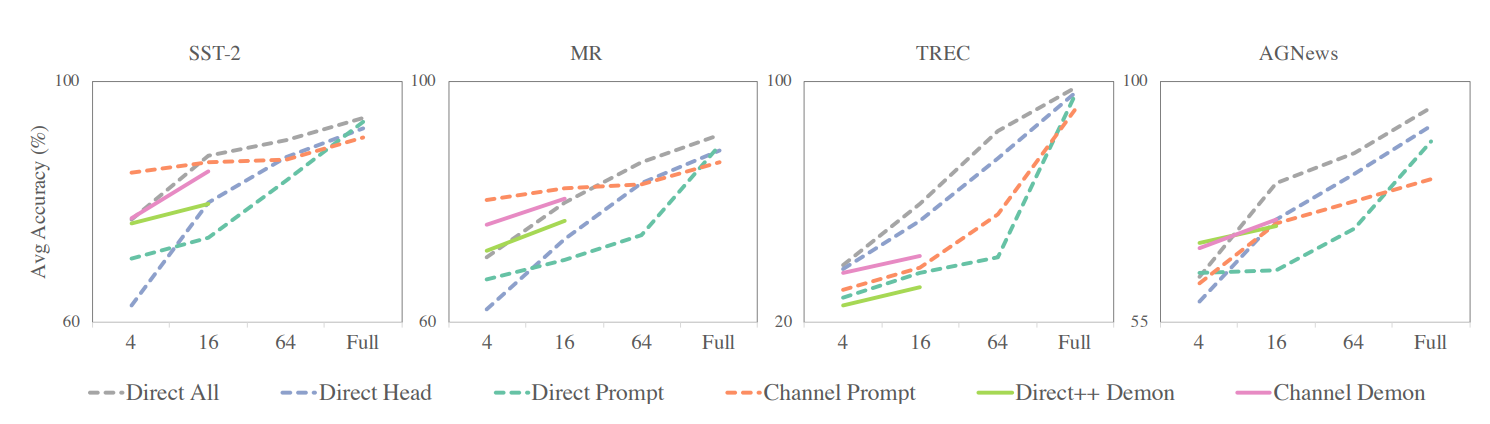
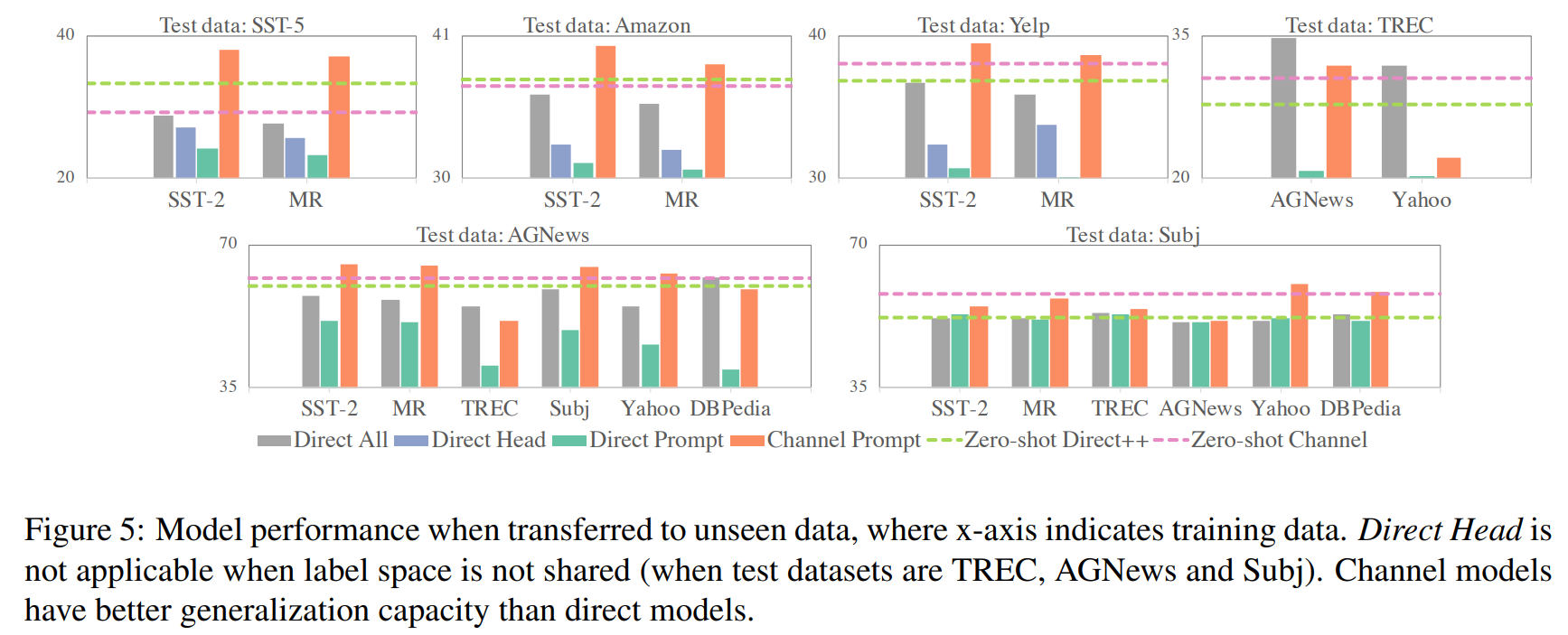
Generalization to unseen label
7. Discussion & Conclusion
-
우리는 이 연구에서 LM prompting을 통해 few-shot 텍스트 분류에 noisy channel 접근법을 소개하였다.
-
우리는 또한 LM prompting 시연하였으며 연속적(continuous) 공간에의 prompt embeddings을 조정해보았다.
-
우리의 실험에서의 11개 데이터세트는 채널 모델들이 다른 direct 모델들보다 더 성능이 좋음을 보였다. 특히 그들의 안정성에서. 예를 들면, 더 낮은 변동과 더 적은 worst-case 정확도를 확인하였을 때. 우리는 또한 direct head tunng이 더 경쟁력이 있고 다른 방법론들보다 선호된다는 것을 찾아냈다. 특히 channel prompting tuning의 경우 다른 시나리오들보다 더 선호된다.
-
K is small : Channel prompt tuning은 더 적은 학습 예제들에서 경쟁력 있다. 우리는 두 가지 이유로 가설을 세워보았다. (1) Channel 모델들은 더 안정적이다. 그 말은 더 낮은 variance 그리고 높은 worst case 정확도를 가진다. 다른 direct 모델들은 작은 k에 대해 더 높은 불안정성을 보였다. (2) Channel 모델들은 더 많은 신호를 제공한다. (모델이 input word 마다 설명하도록 함으로써)
-
Data is imbalanced or || is large : 학습 데이터가 조금만 불균형하더라도 direct 모델들은 경쟁력을 가지지 못했다. 우리는 이를 LM head가 너무 unconditional한 레이블의 분포에 의존하기 때문이라고 본다. Channel prompt tuning은 덜 민감하다, 왜냐면 레이블들이 conditioning한 variable*들이기 때문이다.
-
Generalization to unseen labels is required : 모든 direct 모델들은 학습 때 보지 못한 레이블들을 예측하는 것이 가능하지 않다. 이것은 label 공간에 과적합됐음을 의미한다. 대조적으로, 채널 모델들은 보지 못한 labels에 대해서 예측이 가능하다. 이것은 이전 연구들의 채널 모델들이 distribution shift에 더 유능한 것을 보여준것과 비슷한다.
-
Task is closer to language modeling : 만약 task가 language modeling과 너무 다르다면 (e.g., TREC and Subj) head tuning 이 prompt tuning보다 더 좋은 성능을 냈다. 이것은 LM의 파라미터를 directly 업데이트하는데 이점이 있기 때문으로 보인다. Causal LMs들이 모든 task에 적합한 것은 아니다라는 것을 보여주며 우리는 causal LMs이 LM의 파라미터 업데이트 없이 적용될 수 있는 더 정교한 방법을 찾는 것이 필요할 것으로 보인다.
Appendix
저자들은 아래 그림과 같이 각 데이터세트마다 입력 값을 변형 하였다. c는 레이블이다.



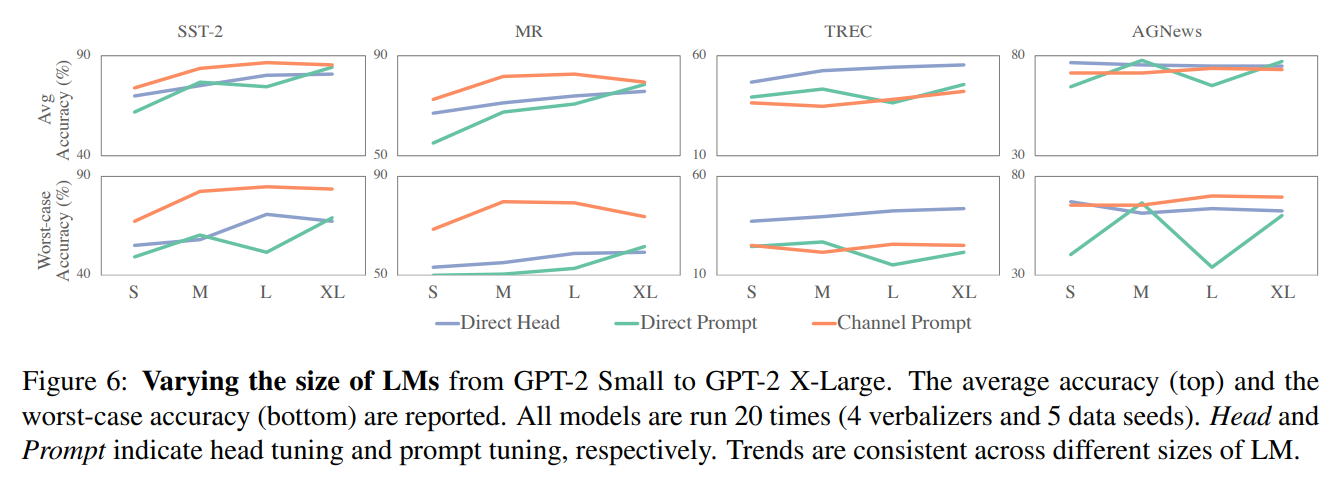
저자들은 LM 모델의 사이즈를 바꿔서 동일하게 메서드들을 비교 실험한다. 실험 결과의 Trends들은 비슷한 것을 보인다.
본 논문의 경우, 텍스트 분류 작업에서 언어모델(LLM)을 이용한 프롬프트 성능에 대해 체계적으로 실험하여 정보를 전달하고 있다. 본 논문에서 제안된 channel 방식은 그 아이디어가 간단하지만 특히 프롬프트를 이용하였을 때, 기존 불안정한 성능 문제를 개선하는데 효과를 확인할 수 있다. 이런 점은 앞으로 프롬프트를 사용할 때 활용해볼 수 있을 뿐더러 적은 데이터 소스만으로도 (few-shot learning) 텍스트 분류에서 모델의 일반적인 성능을 확인하는데도 도움이 될 것으로 보인다. 이는 현재 GPT-3 그리고 다른 대규모 스케일 모델들의 이용하는데 활용해볼 수 있을 것으로 기대하고, 실험해볼 수 있을 것이다.
추가 설명
*Conditioning variables : Y variable is conditioned by X=1
*This is in line with N : ~N과 맥락이 같다.
*Distribution shift : Single distribution의 경우 train evaluation 의 데이터가 같은 분포에서 나왔음을 의미한다 (e.g. SQuAD 2.0 paragraph from Wiki) 따라서 Distribution shift 를 테스트해보면 New Wikipedia / New York Times/ Reddit/ Amazon 에서 나온 데이터들로 Test 세트를 구축하여 테스트해보는 것을 확인해볼 수 있다.
*Non-parametric method : 파라미터의 분포가 일반적인 normal distribution을 따르지만 데이터의 분포가 정규 분포에서 유래한다고 가정하지는 않음. 예를 들어 k-Nearest classifier 등이 있다. 예를 들어 새로운 인스턴스에 대해서 유사한 훈련 패턴이 있다는 것만 가정하고 모델을 학습시킨다. (참조 : https://process-mining.tistory.com/131, https://deepai.org/machine-learning-glossary-and-terms/non-parametric-model)
*Heldout evaluation : 전체 데이터세트를 Train 그리고 Test set 두 개로 나누는 과정을 의미한다. 따라서 Holdout evaluation 의 경우 나눠진 평가 데이터세트를 의미한다.
