[논문 리뷰] ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer - 1
PaperReview
목록 보기
2/4
Yuanmeng Yan et al, ACL 2021.
논문 링크

- BERT와 같은 Large-scale 모델을 통해 semantic similarity 비교 뿐만 아니라 광범위한 다양한 태스크들에서 좋은 문장 벡터 표현을 통해 좋은 성능을 보였다.
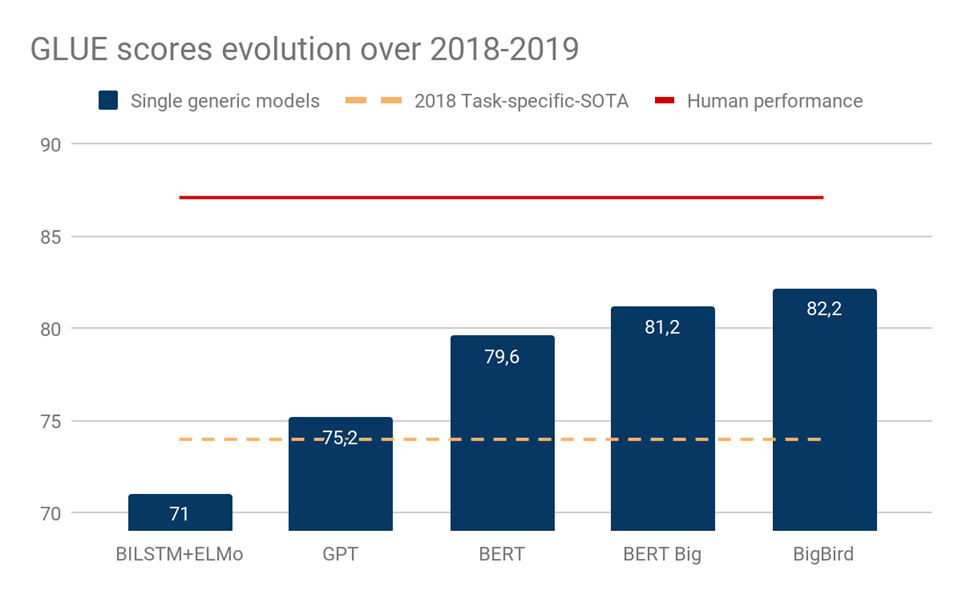
- BERT를 베이스로한 사전학습 모델들은 마찬가지로 규모를 키워가며 supervised task에서도 높은 성능을 보여주고 있다.
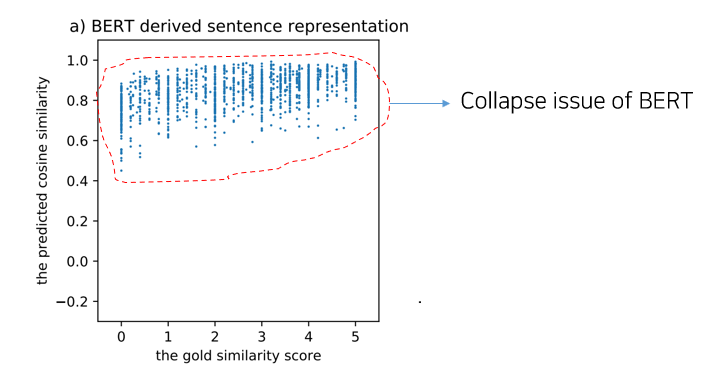
- 하지만, Reimers and Gurevych 의 2019년에 연구 그리고 Li 등의 연구에 따르면 BERT에서 얻어진 naive한 문장 표현들은 그 퀄리티가 낮다고 주장한다.
- 위 그림을 보면, 정답 similarity 분포는 0~5 사이로 분포되어있다고 했을 때, 모델이 예측한 cosine similarity 의 분포는 대체로 0.6 ~ 1.0 사이에 거의 몰려있는 것을 확인할 수 있다.
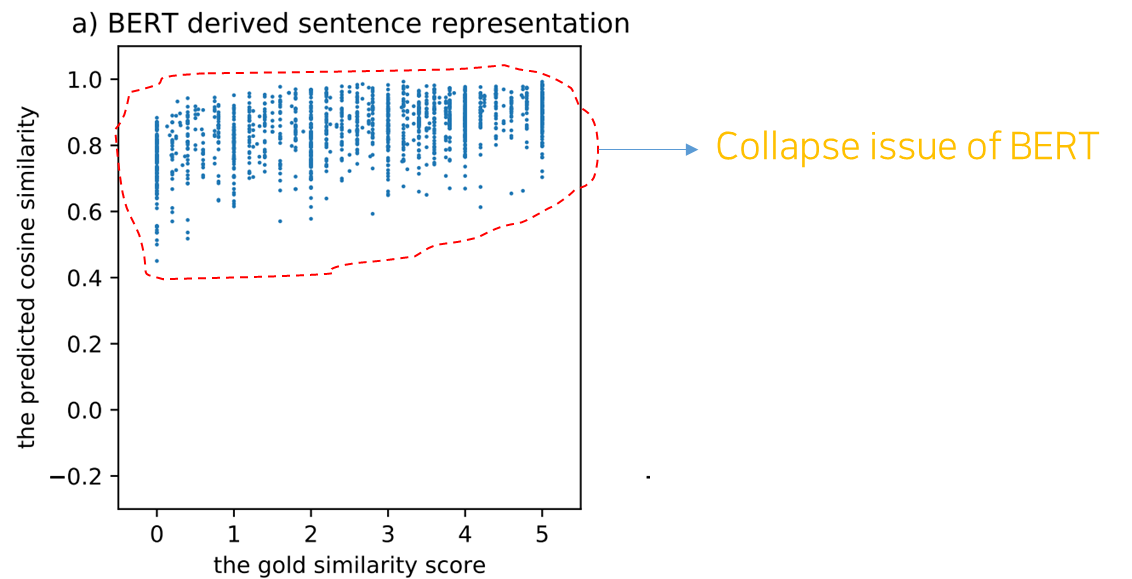
- 즉, 대부분의 문장들이 작은 공간 안에 높은 유사도로 매핑되어 있는 것이다. 위와 같은 현상들은 이전의 여러 연구들에서도 관찰되는데, 따라서 이 때문에 버트의 naive한 문장 표현들이 바로 사용되기 적합하지 않다는 것이다. 그리고 이런 것을 BERT 표현의 collapse issue라고 부른다.

- 이런 현상들은 이전 연구들에서 발견한 “anisotropic” 문제와 연관되어 있다고 저자들은 이야기하고 있는데, 이 문제에 대해서 간략하게 정리해보면 “On the Sentence Embeddings from Pre-trained Language Models” 라는 EMNLP 2020년에 실린 논문은 BERT word representation 의 특성을 분석하면서 아래와 같이 이야기한다.
We find that BERT always induces a non-smooth anisotropic semantic space of sentences, which harms its performance of semantic similarity.
- 여기서 문제가 되는 anisotropic embedding space 는 단어 벡터들이 얇은 콘 모양으로 분포되어있기 때문에, 관계 없는 단어들 사이에서도 높은 코사인 유사도가 나타나는 현상을 좀 더 집중적으로 이야기한다. 이런 현상이 일어나는 까닭에 대해서 이전 연구 에서는 이런 원인을 단어 빈도수에 의해 생기는 편향(빈도수 높은 단어들은 origin에 모여있고 그렇지 않은 경우 최적화가 되어도 origin에서 멈) 을 이야기하고 있다.
아래 내용은 조금 더 성질에 가까운 이야기기 때문에 anisotropic 에 관심이 없으신 분들은 내려도 좋다.
- a non-smooth anisotropic semantic space of sentences 라는 문장의 뜻을 좀 더 이해하기 위해서 다음 그림과 개념을익명의 블로그(https://beoks.tistory.com/29)에서 가져와봤다.
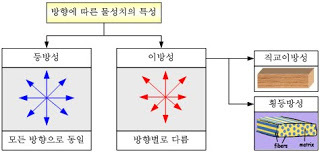
- 등방성은 어느 방향에서 보아도 똑같은 성질을 가지는 것을 의미한다. 이에 비해 비등방성은 특정 방향에서는 다른 성질을 가지게 되는 것을 의미한다.
- 비등방성 함수의 경우 특정 좌표에서 기울기의 성질이 변하는 경우가 존재하는 형태의 무언가라고 이해할 수 있다. 아래 그림과 같이, 기울기가 가르키는 지점이 여러가지일 때, 이를 비등방성 함수라고 부른다.
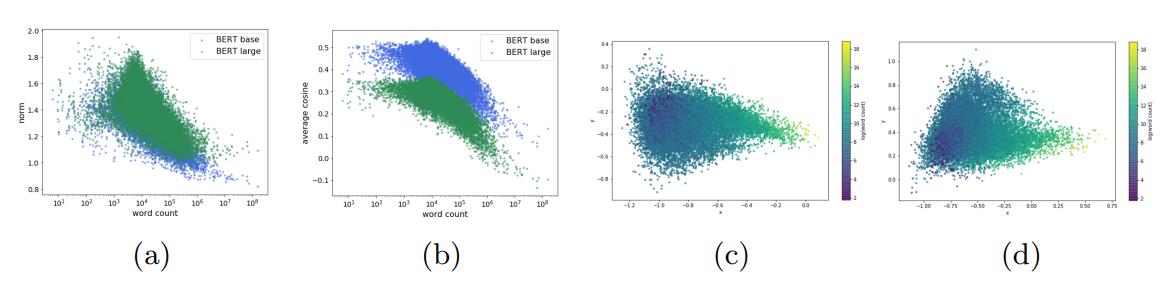
- 이 그림은 설명을 돕기 위해 BERT의 임베딩을 PCA로 차원축소하여 시각화 한 그림을 이 논문에서 가져와봤다. c와 d는 각각 BERT-base 그리고 BERT-large 모델에서 나온 word embedding이다. (이 논문도 제목이 Learning to Remove: Towards Isotropic Pre-trained BERT Embedding 으로 찾아보면 BERT에서 나온 embedding의 Isotropic, anisotropic 형태에 관한 문제는 BERT 이후로 꾸준하게 다뤄졌음을 알 수 있다. 그리고 이런 문제들을 다룸으로써, word similarity, word analogy, semantic texutal simiarity 와 같은 태스크의 성능향상에 연관관계가 있는 것으로 보인다.)
- 본 포스트는 저자들의 문제 해결 접근방법과 self-supervised 기술인 contrastive learning을 어떻게 활용하였는지에 관심이 있으므로, anistropic한 성질에 대해서는 이정도로 다루고 넘어가려고 한다.
- 따라서 논문의 저자들은 BERT에서 얻어진 문장 표현에 대해 위에서 다음 성질과 관련하여 발생하는 collapse issue를 어떻게 해결할 것인지 고민한다.
최종적으로 저자들이 제시하는 방법은 ConSERT 라는 문장 표현 transfer를 제시하는데, 이것은 contrastive learning 방법론을 이용하고 있다. 저자들은 이 방법론을 이용해서 기존 문제를 완화하고 적은 레이블에서도 좋은 성능을 냈음을 강조한다.
또한, contrastive learning 방법론을 구체화하는 과정에서 다양한 augmentation 전략들을 실험한 것을 같이 이야기하고 있는데, 예를 들어 adversarial attack, token shuffling, cutoff, dropout 과 같은 것들이다.
저자들은 자신의 논문의 기여를 다음과 같이 정리하였다.
- simple 하지만 effective한 문장 레벨에서의 학습 목적함수를 제공하고, 이를 통해 BERT에서 얻어진 collapse issue를 해결한다.
- 다양한 text augmentation 전략을 통해 효과적인 문장 표현을 위한 unsupervised transfer에 대해 탐구한다.
- supervised NLI 에서는 state-of-the-art 그리고 적은 NLI 샘플로 fine-tuning 시, STS tasks에서 성능 향상을 하였음을 보여준다.
- 이런 실험이 data scarcity 문제에 대해서 방법론을 적용하였을 때, robustness함의 강점이 있다고 한다.
그럼 방법론에 대해서는 다음 포스트를 통해 자세히 설명하고 구현해보도록 할 예정이다.

Seize the day!