Database에서 중요한 것!
Database란??
정의
어떤 조직의 응용 시스템들이 공용(shared)할 수 있도록 통합(integrated), 저장(stored)된 운영 데이터의 집합
특징
실시간 접근성 (real-time accessibility)
질의에 대한 실시간 처리가 가능
응답시간이 납득할만한 수준이어야 함
계속적인 변화 (continuous evolution)
갱신, 삽입, 삭제가 지속적으로 발생함
계속적인 변화 속에서도 현재의 정확한 상태를 유지해야 함
동시 공용 (concurrent sharing)
여러 사용자가 동시에 사용할 수 있어야 함
내용에 의한 참조(content reference)
데이터가 저장된 위치나 주소에 의해 참조되는 것이 아님
데이터의 값에 따라 참조할 수 있어야 함
구조
DBMS란?
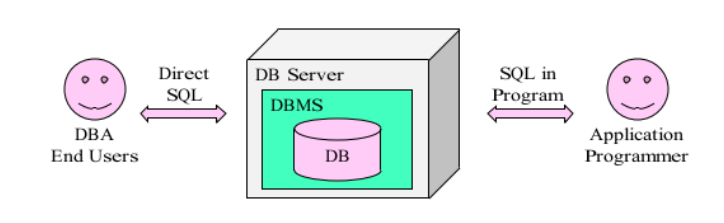
응용프로그램과 데이터의 중재자
(DBMS 를 통해서만 DB 를 사용할 수 있음)
모든 응용프로그램들이 데이터베이스를 공유할 수 있도록 관리해 주는 소프트웨어 시스템
DB의 구성, 접근 방법, 유지 관리에 대한 모든 책임을 담당
DB에 대한 모든 접근 요청(SQL request)을 처리
사용자와 DB 사이에 위치하여 DB를 관리하고, 사용자의 요구에 따라 필요한 정보를 제공하는 소프트웨어
⇒ DB를 사용하기 위해서는 무조건 사용해야하는 프로그램!
DBMS의 역할
- Data Definition: DB
의 구조를 정의하는 기능 - Data Manipulation:
데이터의 검색, 삽입, 삭제, 갱신 기능 - Optimization & Execution:
연산의 최적화 및 실행 - Performance:
최상의 성능을 보장 - Data Protection: 데이터 보안
- System Catalog(Data Dictionary or Metadata) : 데이터 분류 및 카테고리화
DBMS가 필요한 이유
⇒ 데이터 독립성 (Data independency)!!!
데이터의 논리적/물리적 구조가 변경되더라도 응용프로그램에 영향을 주지 않도록 하는 것
Logical data independency: DB의 논리적 구조를 변경해도 응용 프로그램이 영향을 받지 않음
Physical data independency: DB의 물리적 구조를 변경해도 응용 프로그램이 영향을 받지 않음
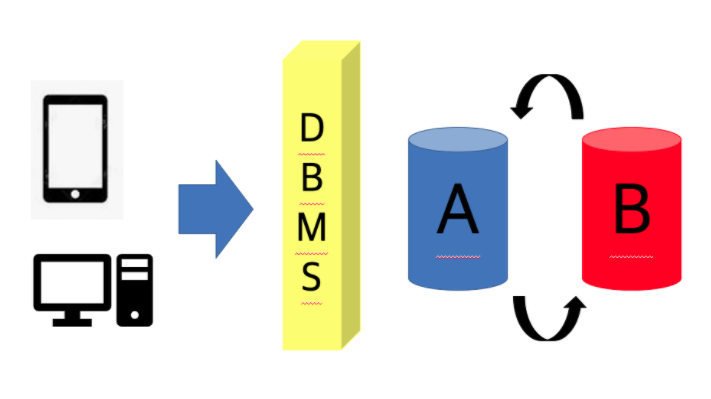
⇒ 어플리케이션은 DBMS만 확인하면 되기 때문에 데이터베이스가 바뀌어도 상관이 없다!!!
[참고] 데이터베이스 논리적/물리적 구조
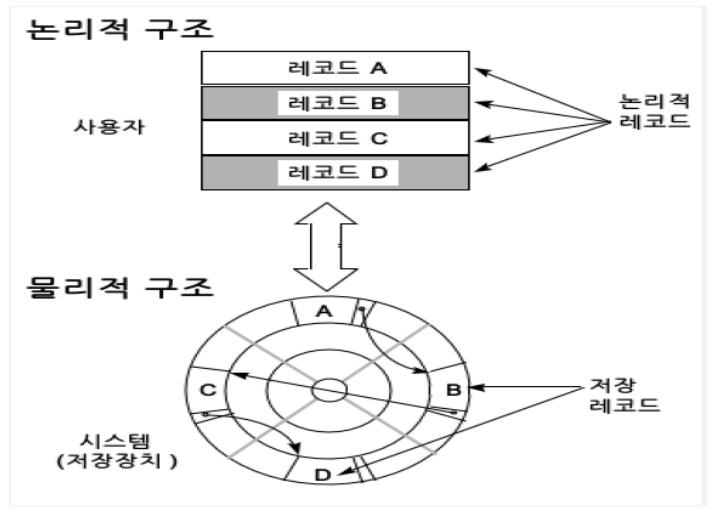
이 논리적 구조와 물리적 구조는 자주 바뀐다!(프로그래머가 관리하기엔 너무 복잡하고 효용성이 낮음)
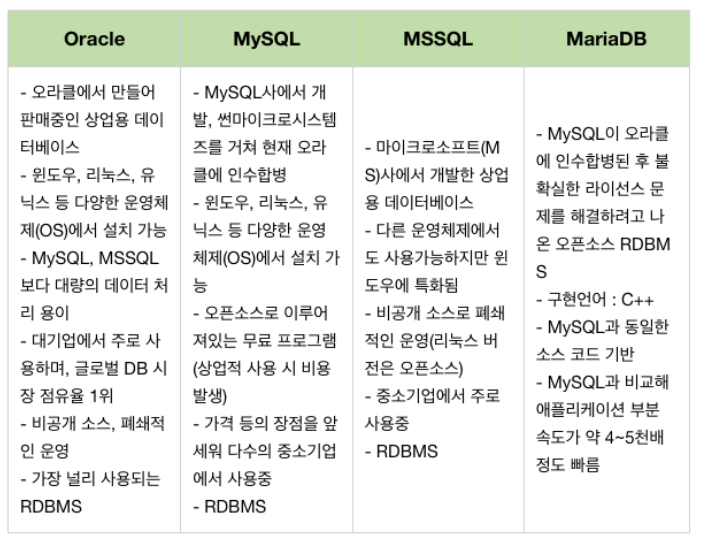
MySQL
- 전세계적으로 가장 널리 사용되고 있는 오픈 소스 데이터베이스
- 표준 데이터베이스 질의 언어 SQL(Structured Query Language)을 사용하는 개방 소스의 관계형 데이터베이스 관리시스템(RDBMS)
- 매우 빠르고, 유연하며, 사용하기 쉬운 특징
- 다양한 개발 환경 지원(Java, C, C++),(Linux, Window)
Mysql Workbench
Mysql에서 제공하는 공식 GUI 어플리케이션!
[참고] GUI vs CLI
CLI : 터미널과 명령어 기반으로 컴퓨터와 소통하는 방식!!, 자원 소모가 적기 때문에 서버용 컴퓨터들이 많이 사용한다.
GUL : 그래픽을 이용해 사용자와 소통하는 방식으로 그림이나 아이콘을 주로 사용한다.
데이터베이스 스키마
데이터베이스 구조
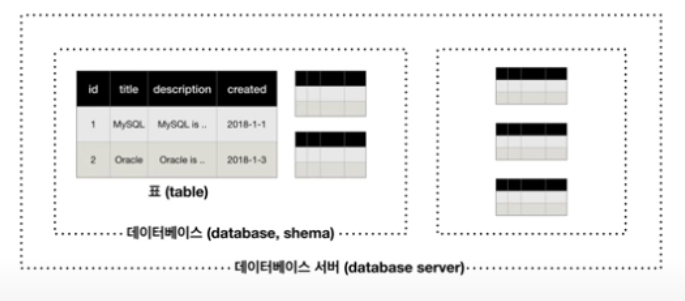
스키마 : 데이터베이스 내의 단위로 테이블을 분리하여 관리할 수 있도록 해준다.
스키마 생성 명령어 : create schema 스키마 이름; 또는 create database 스키마 이름
스키마 조회 명령어 : show databases
스키마 삭제 명령어 : drop databas 스키마 명
스키마 선택 명령어 : use 스키마 명
- Mysql에서는 스키마와 데이터베이스라는 용어를 혼용해서 쓴다.
데이터베이스 테이블

테이블 : 실질적인 데이터가 들어가는 장소
행 : 실질적인 데이터 단위 묶음
열 : 데이터의 속성값
테이블 생성 명령어 :
create table 테이블명(
컬럼 명 데이터 타입(길이) NULL 유무 자동증가);
EX)
create table subject(
id INT(11) NOT NULL AUTO_INCREMENT,
title VARCHAR(30) NOT NULL,
description TEXT NULL,
PRIMARY KEY(id)
);
[참고] PRIMARY KEY → 중복 방지를 위해 설정한 유니크한 값
[참고] SQL data type
블로그 참고 : https://blog.martinwork.co.kr/mysql/2020/01/17/mysql-data-type.html
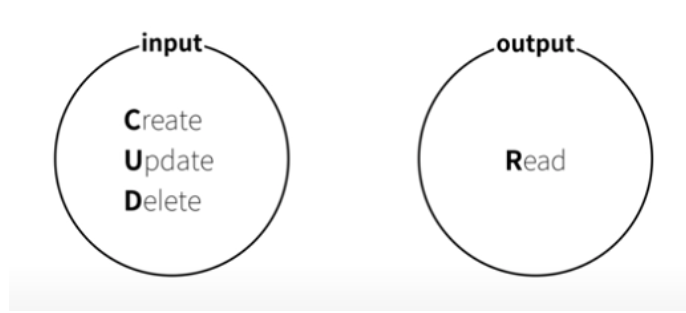
Create - 생성
테이블에 데이터를 저장하는 방법 입니다.
명령어 :
insert into 테이블 (컬럼명,) values(컬럼값);
EX)
insert into subject (title, desciption) values("수학", "제일 싫어하는 함수");
Read - 읽기
테이블에서 데이터를 읽습니다.
명령어 :
select 컬럼명 from 테이블명 where 조건 order by 컬럼명 조건 limit 개수;
EX)
select title from subject where title = '수학';
[참고]
select from table 하게 되면 모든 컬럼이 조회됩니다. 즉 은 모든 것 이라고 알면 됩니다.
where 문이랑 order by문, limit문은 생략 가능합니다.
Update - 수정
테이블에 담겨있는 데이터를 수정합니다.
명령어 :
update 테이블 명 set 컬럼명 = 수정값 where 조건
EX)
update subject set description = "이제는 좀 좋아진 과목" where title = "수학";
Delete - 삭제
테이블에 담겨있는 데이터를 삭제합니다.
명령어 :
delete from 테이블 이름 where 조건;
EX) delete from subject where title = "수학";
