들어가며
분산 시스템에서 가장 중요한 것은 바로 데이터의 병렬 및 동시 처리다. 이를 병렬성과 동시성이라고 하는데 가장 쉽게 공부할 수 있는 방법이 바로 Thread와 Process에 대해 공부하고 다뤄보는 것이다.
따라서 이번 포스팅에서는 Thread와 Process의 개념에 대해 간략히 정리하고 다음 포스트부터는 간단한 실습을 진행해볼 계획이다. 언어는 Python을 사용할 것이다. GIL(Global interpreter Lock) 때문에 멀티 쓰레드 환경 구축이 쉽진 않지만 Java와 다르게 Multi Processing이 가능하므로(Java도 가능할 수 있지만 찾기가 어렵다) 파이썬을 통해 공부하고자 한다.
프로세스 (Process)
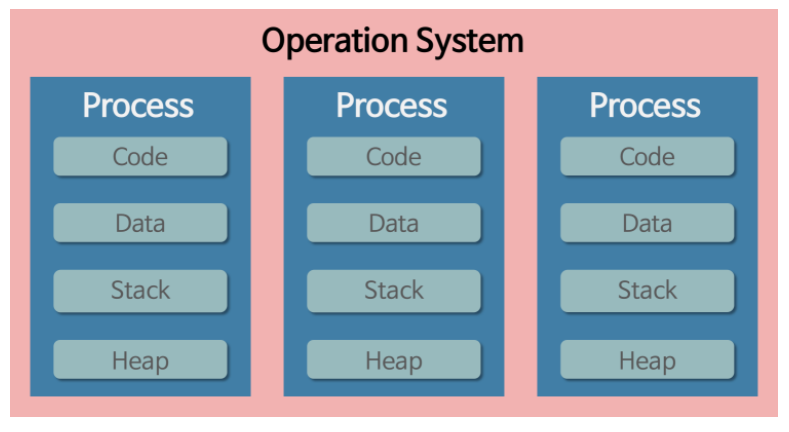
프로세스는 저장장치에 저장된 프로그램(소스코드)가 실행되어 운영체제에 의해 자원을 할당 받는 자원이다.
CPU를 사용함에 있어서, 시간, 주소공간이 독립적이다. 즉 여러 프로세스가 실행되어도 각각이 독립적으로 구분되어 서로에게 영향을 끼치지 않는다.
Code, Data, Stack, Heap 또한 독립적이다. 위에서 얘기했든 주소공간, 즉 메모리 공간이 독립되어 있기 때문에 각각의 프로세스는 개인적인 Code, Data, Stack, Heap을 가지고 있다.
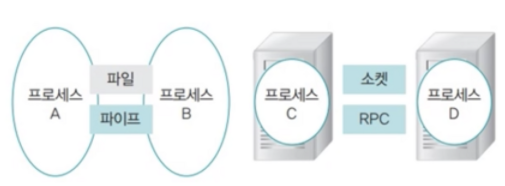
프로세스 간에 데이터를 주고 받기 위해선 파이프, 파일, 소켓 등을 사용해야 한다. 이 방법들은 Cost(자원 소모율)이 높다. 그 이유는 바로 Context Switching 때문이다.
Context Switching는 단일 CPU에서 여러 개의 프로세스를 동시에 처리하기 위해 사용된다. 단일 CPU는 시분할을 통해서 프로세스를 동치에 실행하는데 (1번 실행, 2번 대기 -> 1번 저장, 2번 실행 -> 1번 불러오기, 2번 저장 -> 1번 저장, 2번 불러오기 -> 1번 불러오기, 2번 끝 -> 1번 끝, 2번 끝) 다음과 같이 실행된다.

기존에 작업하던 내용을 임시 저장하고, 새로운 작업을 진행한다. 새로운 작업을 하다가 CPU 할당 시간이 끝나면 임시 저장하고 또 다른 작업의 내용을 불러온다. 이때 프로세스 간의 통신을 진행하면 별도의 저장 공간(메모리-파이프, 저장 장치-파일)를 사용하거나 네트워크(소켓)을 활용해야 하기 때문에 자원 소모율이 높다.
스레드 (Thread)
스레드는 프로세스 내에서 실행되는 흐름의 단위를 나타낸다. 개인적으로 메소드와 유사하다고 생각한다.
스레드는 프로세스와 다르게 자원이 독립적이지 않고 프로세스 내의 바원을 함께 사용한다. 이때 동적 데이터 선언 및 참조값 저장에 필요한 Stack만 별도로 할당 받는다.
여기서 Stack만 별도로 할당 받는 이유는 Stack에 저장되는 데이터 성격과 관련이 있다. Stack에는 데이터들의 참조값이 들어간다. 이 참조값은 쉽게 말해서 (int a)와 같은 변수 명이라고 볼 수 있다. 만약 이 Stack이 공유가 된다면 모든 스레드 별로 다른 변수 명을 정해줘야 한다. 즉 스레드가 100개면 int a1 ~ int a100 까지 각각 지정해줘야한다. 따라서 Stack을 별도로 지정해주면 int a라는 이름의 변수 명을 모든 스레드가 사용가능하다. 다만 Heap 공동으로 사용하기 때문에 A tread의 int a의 참조값과 B thread의 int a의 참조값은 다르다!
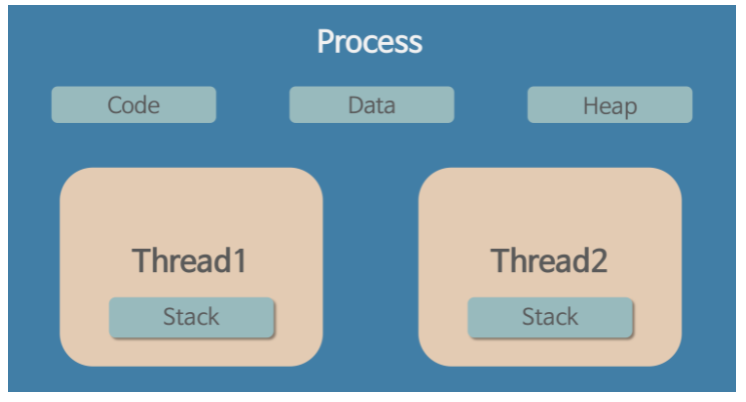
스레드에서 Stack을 제외한 부분은 모두 공유된다. 따라서 Data, Heap 부분의 값을 변경할 경우, 다른 스레드에 영향을 끼친다. 따라서 Data의 값을 변경할 수 없도록 한다던지(Static 선언), 스레드가 사용할 경우, 다른 스레드가 사용할 수 없게 한다던지(Lock), 데이터를 관리하는 객체를 하나만 사용한다던지(Singleton 패턴) 다양하게 데이터 변경을 보호한다. 이를 동기화 문제라고 하며 디버깅에 많은 어려움이 있다.
멀티 스레드와 멀티 프로세스
멀티 스레드는 여러 개의 스레드로 구성되어 작업을 처리하는 것이다. 이 방법을 사용하면 시스템 자원 소모가 감소되고 처리량이 증가한다. 왜냐하면 메모리를 공유하기 때문에 스레드간 데이터 통신이 쉽고 메모리 낭비가 줄어들기 때문이다. 다만 디버깅이 어렵고 자원 공유 문제(교착 상태) 등 문제가 발생하면 프로세스 전체에 영향을 줘 다른 스레드에도 문제가 생긴다.
멀티 프로세스는 여러 개의 프로세스를 실행하여 작업을 진행한다. 멀티 코어, 쿼드 코어 등 여러 개의 CPU가 집적된 보드를 사용하면서 진정한 의미의 멀티 프로세싱이 가능해지면서 잘만 사용하면 매우 빠르게 작업을 처리할 수 있다. 하지만 캐시 체인지나 오버헤드, 프로세스 간 데이터 통신이 어렵기 때문에 사용하기 쉽지 않다. 프로세스 간에 영향을 주지 않기 때문에 문제가 생겨도 다른 프로세스에는 문제가 생기지 않는다.
