Thread pool
스레드를 비롯한 모든 객체의 생성은 자원 소모가 크다. 그렇기 때문에 미리 만들어놓고 필요에 따라 가져오는 방식을 사용할 수 있다. 이를 Thread pool이라고 한다.
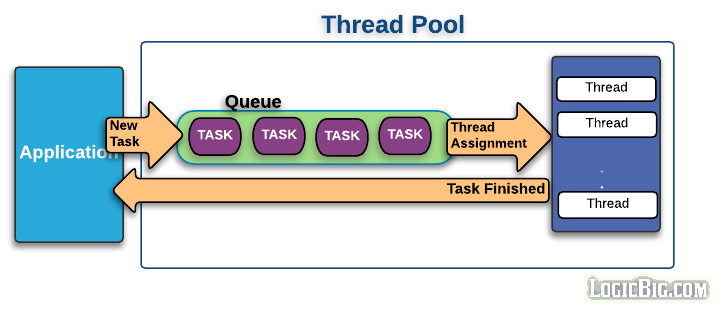
스레드 풀의 장점은 객체의 생성과 제거에 드는 자원 소모를 줄여주기 때문에 성능이 향상되고 다수의 요청을 누락없이 처리할 수 있다.
반대로 너무 많은 스레드를 만들어 놓으면 메모리 낭비와 유휴 스레드가 생겨서 비효율적이다.
사용 라이브러리
import logging
from concurrent.futures import ThreadPoolExecutor
import time스레드 풀 생성을 위한 ThreadPoolExecutor를 import한다.
메인 스레드와 서브 스레드
서브 스레드
1 ~ 10000까지 수를 세는 작업을 한다.
def task(name):
logging.info("Sub-Thread %s: starting", name)
result = 0
for i in range(10001):
result = result + i
logging.info("Sub-Thread %s: finishing result: %d", name, result)메인 스레드
ThreadPoolExecutor의 map을 활용해서 다수의 서브 스레드를 구현한다.
def main():
# Logging format 설정
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO, datefmt="%H:%M:%S")
logging.info("Main-Thread : before creating and running thread")
# with context 구문 사용
with ThreadPoolExecutor(max_workers=3) as executor:
tasks = executor.map(task, ['First', 'Second'])
# 결과 확인
# print(list(tasks))
logging.info("Main-Thread : all done")
if __name__ == '__main__':
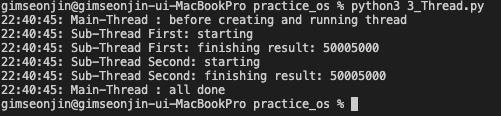
main()실행 결과

백엔드 개발자