
✍🏻 9일 공부 이야기.
👀 오늘 공부한 자세한 내용의 코드는 아래 깃허브에 올라와 있습니다!
검색어 입력
from selenium import webdriver
from selenium.webdriver.common.by import By네이버 홈페이지에서 검색어를 입력해 검색창으로 이동해보자.
driver = webdriver.Chrome()
driver.get('https://www.naver.com')
# 검색창에 검색어 입력
keyword = driver.find_element(By.CSS_SELECTOR , '#query')
keyword.send_keys('파이썬')
# 검색 버튼 클릭
search_btn = driver.find_element(By.CSS_SELECTOR, '#search-btn')
search_btn.click()
# 이어서 계속 검색하려면
# keyword.clear() 를 통해 검색창을 지워주고 다시 실행해줘야함https://pinkwink.kr/ 홈페이지에서 검색해보자.

driver = webdriver.Chrome()
driver.get('https://pinkwink.kr/')위 홈페이지는
1. 돋보기 버튼 클릭
2. 검색어 입력
3. 돋보기 버튼 클릭
하면 검색을 할 수 있다.
그래서 해당 돋보기 버튼의 CSS_SELECTOR를 클릭하고 아래와 같이 버튼을 클릭한다는 코드를 입력하면 에러가 뜬다.
search_btn = driver.find_element(By.CSS_SELECTOR, '#header > div.search > button')
search_btn.click()다시 한 번 홈페이지를 잘 살펴보자.
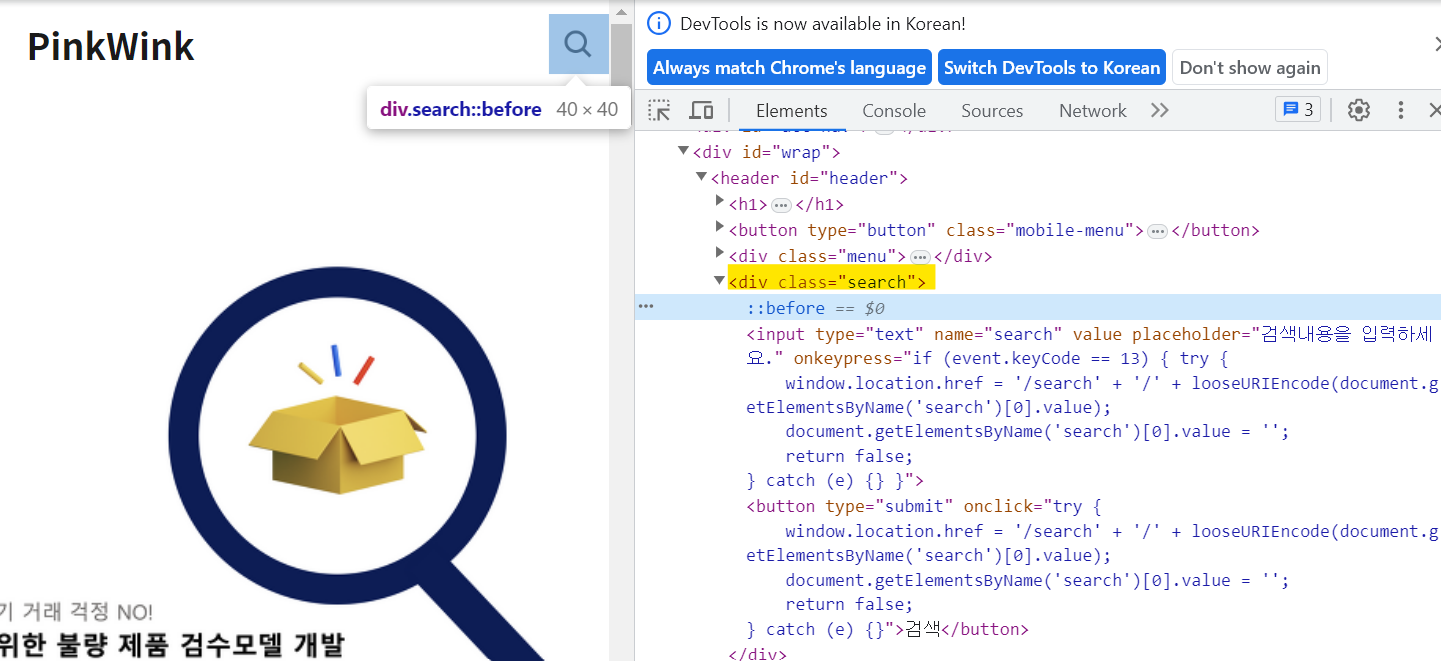 돋보기 버튼 클릭 전 돋보기 버튼 클릭 전 | 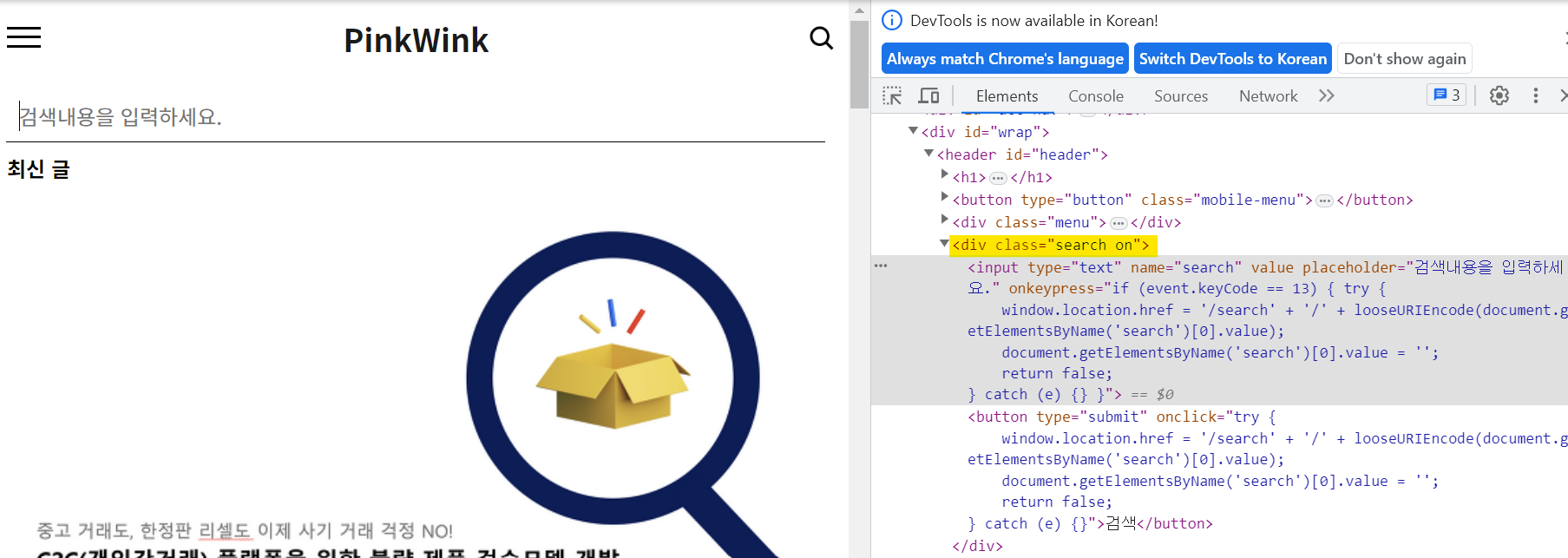 돋보기 버튼 클릭 후 돋보기 버튼 클릭 후 |
|---|
돋보기 버튼을 클릭하면 class가 search -> search on 으로 바뀐 것을 볼 수 있다. 이것이 바로 동적 홈페이지의 특징 중 하나이다.
# 1. 돋보기 버튼을 클릭
from selenium.webdriver import ActionChains
search_tag = driver.find_element(By.CSS_SELECTOR, '.search')
# 이전 시간에는 #header > div.search 와 같이 css_selector를 복사해서 넣어줬는데
# .클래스명 도 가능한가보다! (공식 문서를 좀 더 찾아봐야할듯)
# 그런데, 버튼에 대한 css_selector는 작동되지 않는다.
# 혹시 위 코드도 그냥 상위 클래스 코드의 css_selector는 되지 않을까 했는데 똑같이 오류가 뜬다.
action = ActionChains(driver)
action.click(search_tag)
action.perform()# 2. 검색어를 입력
keyword = driver.find_element(By.CSS_SELECTOR , '#header > div.search.on > input[type=text]')
keyword.send_keys('머신러닝')# 3. 검색 버튼 클릭
search_btn = driver.find_element(By.CSS_SELECTOR ,'#header > div.search.on > button')
search_btn.click()위와 같이 ActionChains를 활용하면 잘 동작되는 것을 볼 수 있다.
🤔 왜 돋보기 버튼의 코드가 아닌 상위 클래스 코드의 css_selector나 .search만 가능한지는 좀 더 찾아볼 필요가 있어보인다.
Selenium + BeautifulSoup
Selenium을 이용해 우리가 원하는 부분까지 이동한 후, BeautifulSoup을 통해 데이터를 추출해보자.
from bs4 import BeautifulSoup
req = driver.page_source #현재 html 코드
soup = BeautifulSoup(req, "html.parser")
contents = soup.select('.title')
contents[1]
셀프 주유소가 정말 저렴할까?
https://www.opinet.co.kr/user/main/mainView.do
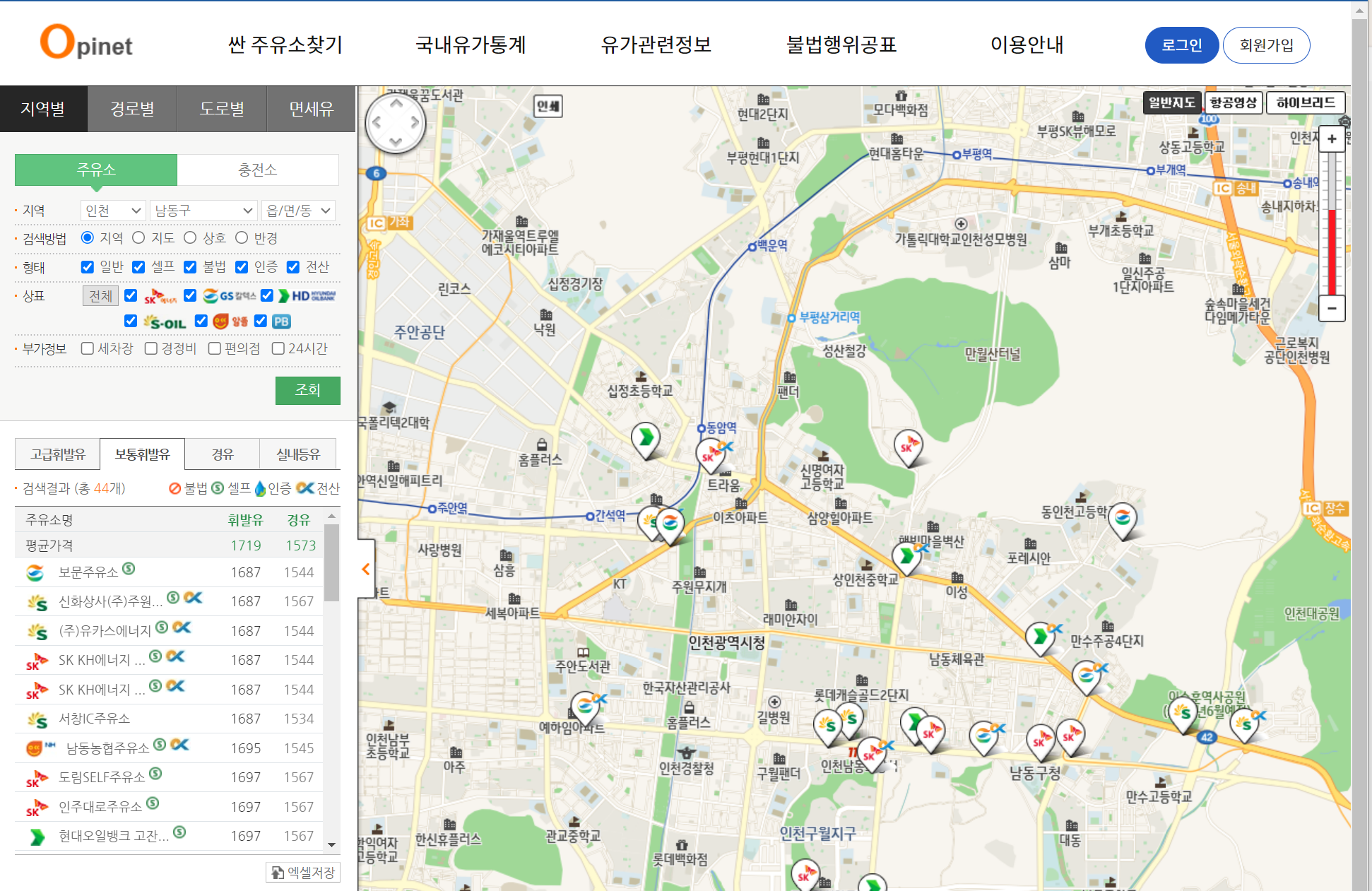
[🖱️ 해당 사이트 - 싼 주유소 찾기 - 지역별]
driver = webdriver.Chrome()
driver.get('https://www.opinet.co.kr/searRgSelect.do')데이터 추출
우리가 분석할 사이트를 탐색하고 데이터를 추출해보자.
- 브랜드
- 가격
- 셀프 주유 여부
- 위치
💡 Idea
- 지역 정보를 선택하고 조회 버튼을 눌러야 조회 가능
- 엑셀 저장 버튼을 클릭하여 데이터를 추출할 수 있음
- 주유 가격을 확인하는 사이트에 접근하기
driver = webdriver.Chrome()
driver.get('https://www.opinet.co.kr/searRgSelect.do')- 지역 검색어 집어넣기
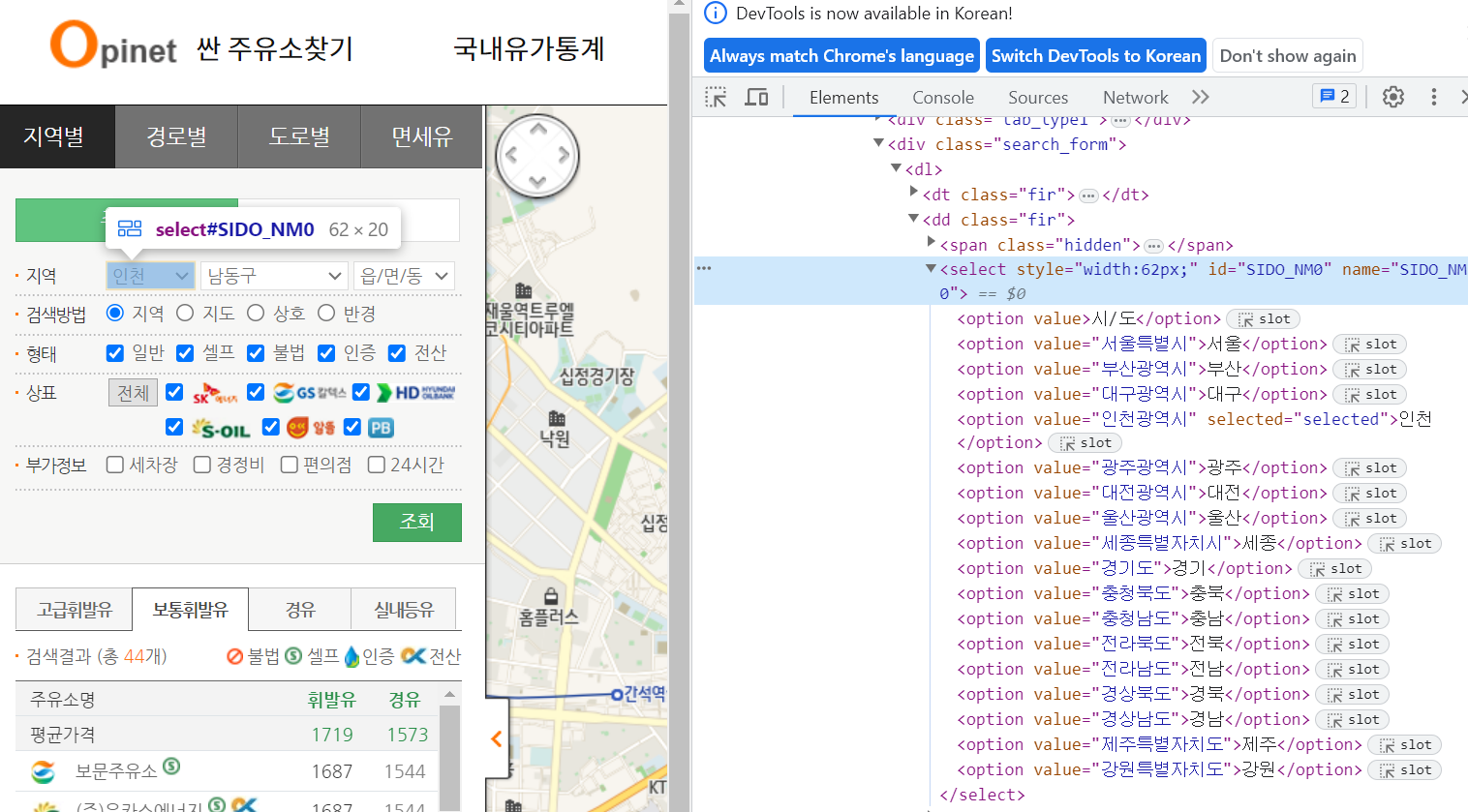
- 시 출력하기
sido_list_raw = driver.find_element(By.ID, "SIDO_NM0")
sido_list = sido_list_raw.find_elements(By.TAG_NAME, "option")
sido_names = [option.get_attribute('value') for option in sido_list]
sido_names = sido_names[1:]
- 구/군 출력하기(인천광역시 기준)
gu_list_raw = driver.find_element(By.ID, "SIGUNGU_NM0") # 부모 태그
# 구/군은 여러개가 있으므로 elements
gu_list = gu_list_raw.find_elements(By.TAG_NAME, "option") #자식 태그
gu_names = [option.get_attribute("value") for option in gu_list]
gu_names = gu_names[1:] #공백 하나 삭제
- 엑셀 저장 버튼을 클릭하기
# 구를 입력하여 작동이 되는지 확인
gu_list_raw.send_keys(gu_names[4]) # 미추홀구
# 엑셀 저장
driver.find_element(By.CSS_SELECTOR, "#glopopd_excel").click()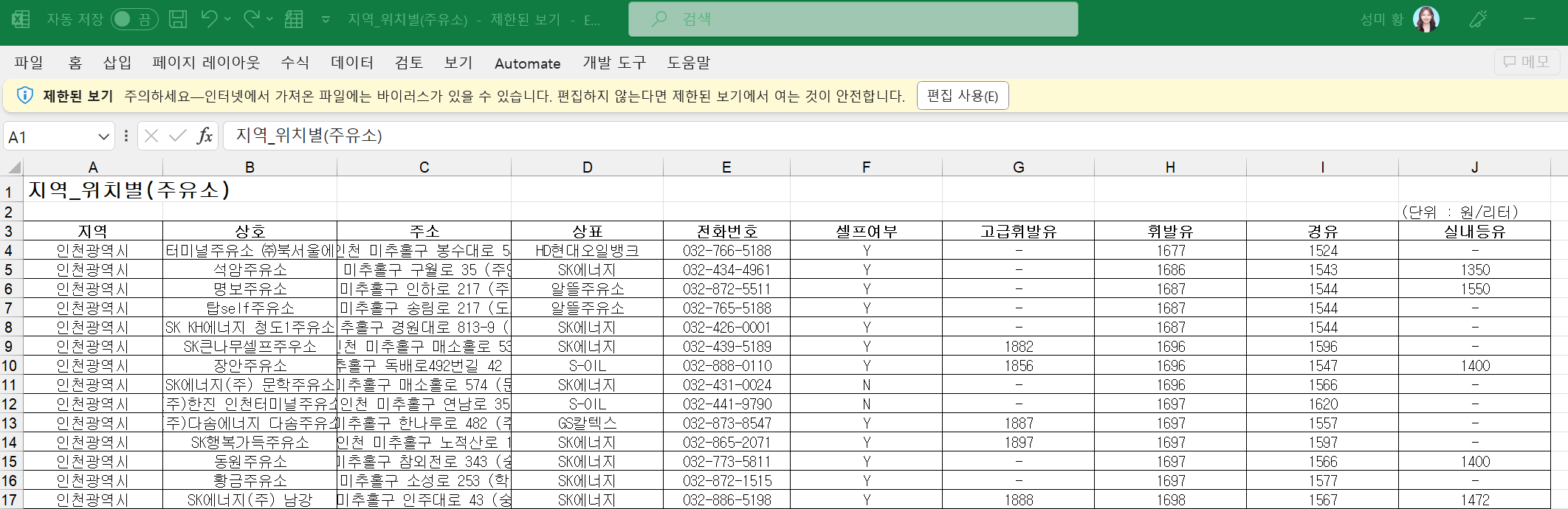
- 반복문으로 모든 구의 데이터를 엑셀 파일로 저장
# 반복문으로 모든 내용 저장하기
import time
from tqdm import tqdm_notebook
for gu in tqdm_notebook(gu_names):
element = driver.find_element(By.ID, "SIGUNGU_NM0")
element.send_keys(gu)
time.sleep(3)
element_get_excel = driver.find_element(By.CSS_SELECTOR, "#glopopd_excel").click()
time.sleep(3)
driver.close()
# 인천광역시 구/군 10개 데이터가 잘 받아졌다.
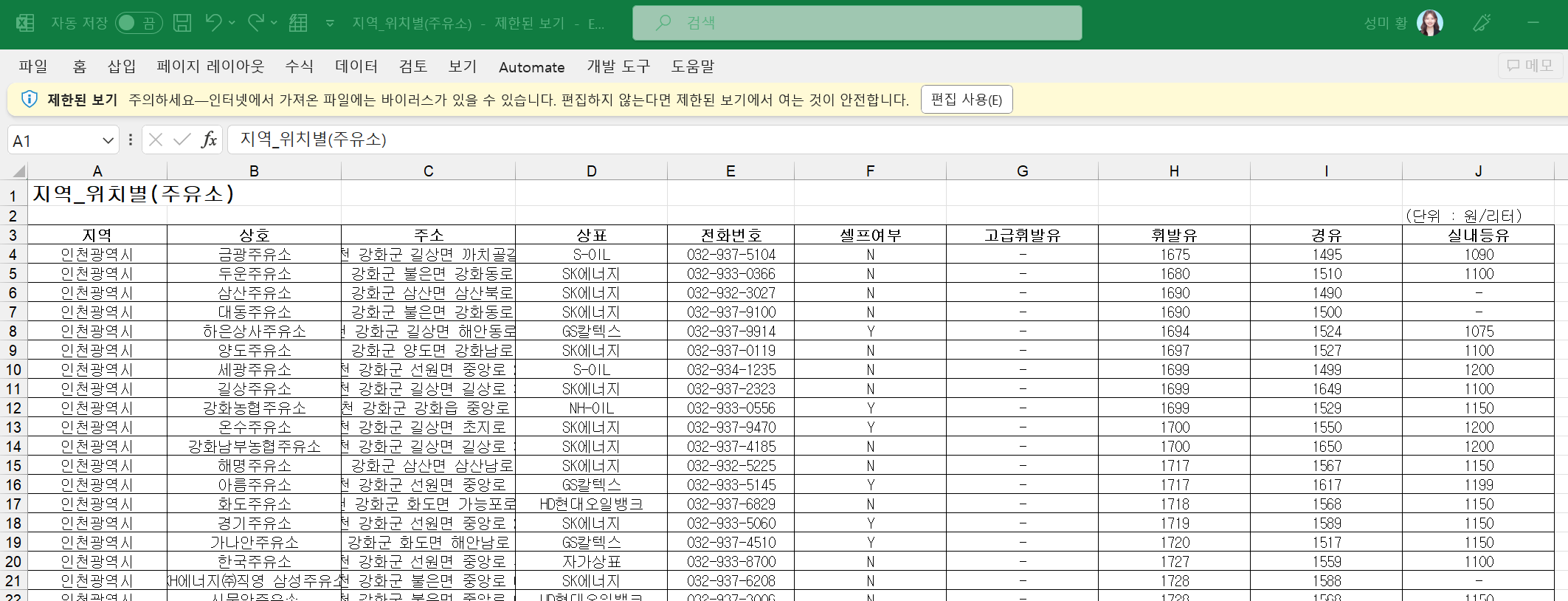
위에서 저장한 데이터를 이제 분석해보자.
데이터 정리하기
import pandas as pd
from glob import glob- 특정 파일명을 가진 모든 파일들 읽어오기
# 파일명 저장
station_files = glob("../data/Self Oil Station/지역_*.xls")
# '지역_' 로 되어있는 파일을 모두 가져와라
# 모든 파일을 데이터 프레임으로 읽어들이기
tmp_raw = []
for file_name in station_files:
tmp = pd.read_excel(file_name, header = 2)
tmp_raw.append(tmp)
- 구조가 동일한 데이터 프레임 여러개를 합치기(
concat)
# 형식이 동일하고 연달아 붙이기만 하면 되는 데이터 프레임 합치기
# 행 숫자와 인덱스가 일치하지 않는 것 체크
station_raw = pd.concat(tmp_raw)
station_raw
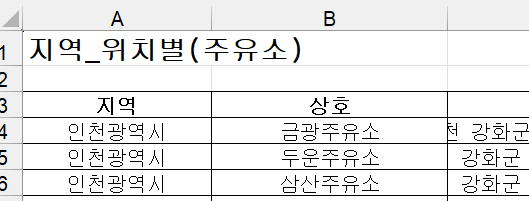
- 원하는 컬럼들만 추출하고 '주소'컬럼을 이용해 '구' 컬럼 추가하기
stations = pd.DataFrame({
"상호" : station_raw["상호"],
"주소" : station_raw["주소"],
"가격" : station_raw["휘발유"],
"셀프" : station_raw["셀프여부"],
"상표" : station_raw["상표"],
})
stations.head()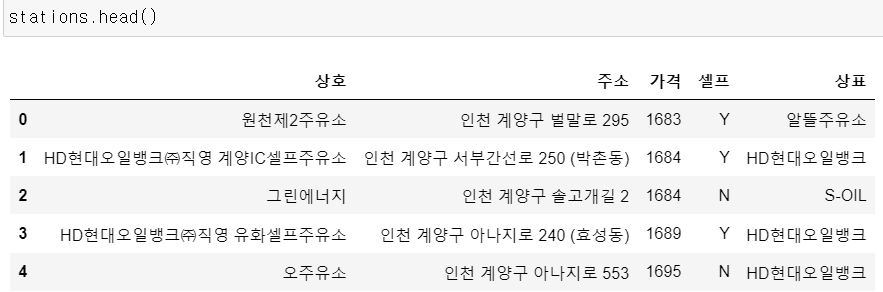
# 구/군 데이터 추가
stations["구"] = [eachAddress.split()[1] for eachAddress in stations["주소"]]
# 미추홀구 데이터가 남구로 바뀌어져있는 것을 확인
stations["구"][stations["구"] == "남구"] = "미추홀구"
len(stations["구"].unique()), stations["구"].unique()
: 미추홀구 데이터 사이에 남구라고 되어있어 실제 인천광역시 구/군 10개의 개수보다 많은 11개의 개수가 찍혀서 나온 것을 고쳐주었음!
- 가격 데이터를 숫자형 데이터로 변환하기
stations["가격"] = stations["가격"].astype("float")
'''
간혹, 가격 정보가 없어서 '-' 라고 표시된 문자열 때문에
float형으로 변환이 안 되는 경우가 있다면 아래와 같이 해결할 것.
강의에서는 가격 정보가 있는 주유소 데이터만 사용했다.
stations = stations[stations["가격"] != "-"]
'''
- 마무리 데이터 정리
# 인덱스 재정렬
stations.reset_index(inplace = True)
# index 컬럼 삭제
del stations["index"]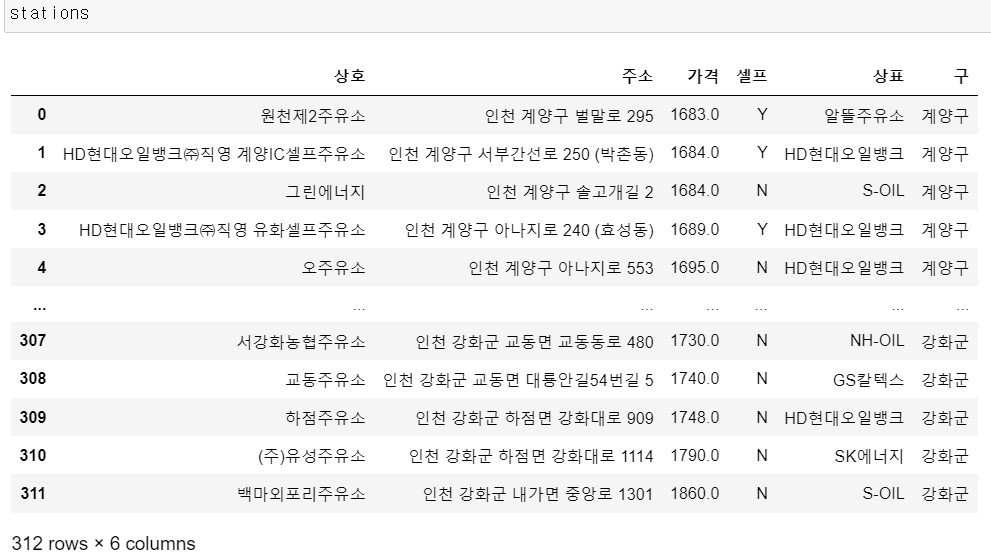
위에서 정리한 데이터를 이제 시각화해보자.
데이터 시각화
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
rc("font", family = "Malgun Gothic")
get_ipython().run_line_magic("matplotlib", "inline")- 셀프 주유소인 곳과 아닌 곳의 가격 차이
# boxplot (feat.seaborn)
plt.figure(figsize = (12,8))
sns.boxplot(x = "셀프", y = "가격", data = stations, palette = "Set3")
plt.grid(True)
plt.show()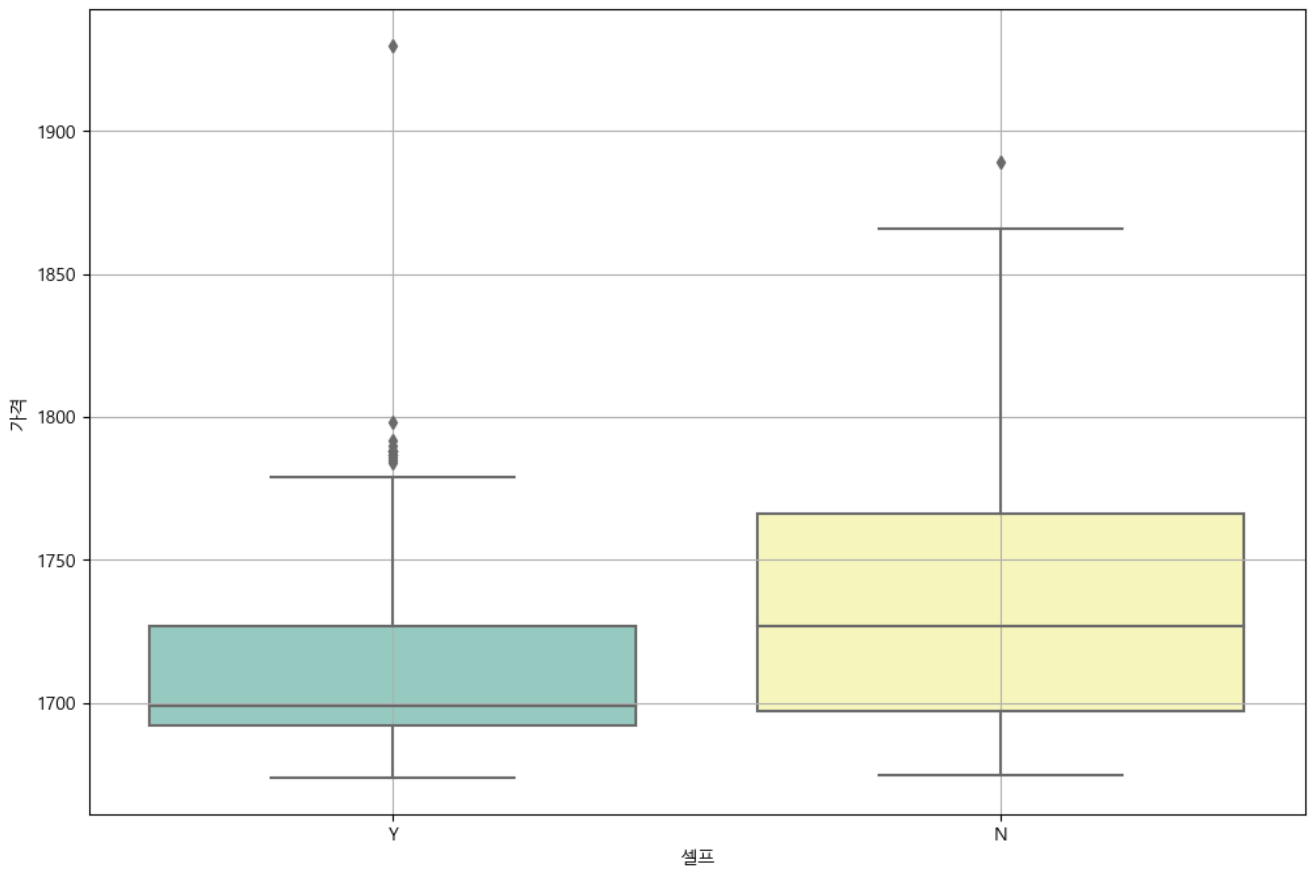
: 대체적으로 셀프 주유소의 휘발유 가격이 더 싼 것을 확인할 수 있다.
- 각 상표 별 셀프 주유 여부 및 가격 분포 차이
# boxplot(feat.seaborn)
plt.figure(figsize = (12,8))
sns.boxplot(x = "상표", y = "가격", hue = "셀프", data = stations, palette = "Set3")
plt.grid(True)
plt.show()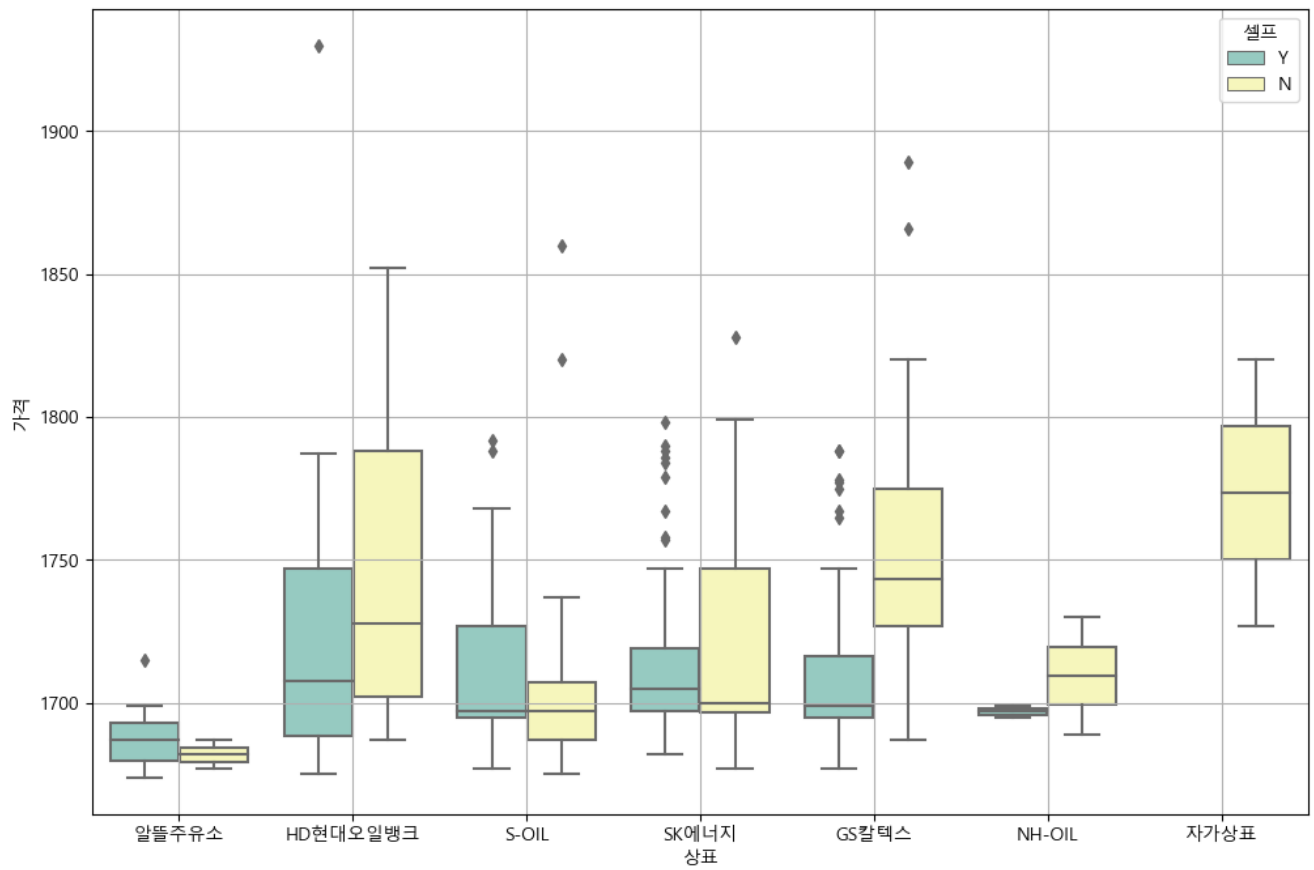
: 현대오일뱅크는 지점별로 가격의 차이가 큰 것을 볼 수 있었고, 반대로 알뜰주유소는 가격이 제일 저렴하면서 지점별로도 큰 차이가 없어보인다.
- 구/군 데이터를 지도에 시각화해보자
# 지도 시각화
import json
import folium
import warnings
warnings.simplefilter(action = "ignore", category = FutureWarning) # 경고 문구 나오지 마라
import numpy as np
gu_data = pd.pivot_table(data = stations, index = "구", values = "가격", aggfunc = np.mean)
지도에 시각화하기 위해선, 행정구역별 경계값 데이터인 json파일이 필요하다. 앞서 공부했을 때에 사용했던 json파일은 서울시의 데이터만 있어서 지금 하고 있는 인천시의 데이터를 시각화할 수 없었다.
인천광역시 데이터를 찾아보던중,
최신 행정구역(SHP)를 다운받아 geojson 파일로 변환하는 사이트를 발견해서 시군구 데이터를 다운받아 작업해보았는데.. 인코딩이 자꾸 깨져서 사용할 수가 없었다. (대부분 구글링하면 위와 비슷한 순서로 작업한다!)
그래서 인천광역시 데이터를 얻고자.. 3시간 넘게 작업해보다가.. 이 사이트에서 제공한 TL_SCCO_SIG.json 파일로 작업해보니깐 얼추 시각화를 할 수 있긴 했다.
# https://neurowhai.tistory.com/350 에서 제공하는 json파일 이용
geo_path = "../data/TL_SCCO_SIG.json"
geo_str = json.load(open(geo_path, encoding = "utf-8"))
my_map = folium.Map(location = [37.4647,126.6934], zoom_start = 10, tiles = "Stamen Toner")
my_map.choropleth(
geo_data = geo_str,
data = gu_data,
columns = [gu_data.index, "가격"],
key_on='feature.properties.SIG_KOR_NM',
fill_color = "PuRd",
legend_name = "Price",
)
my_map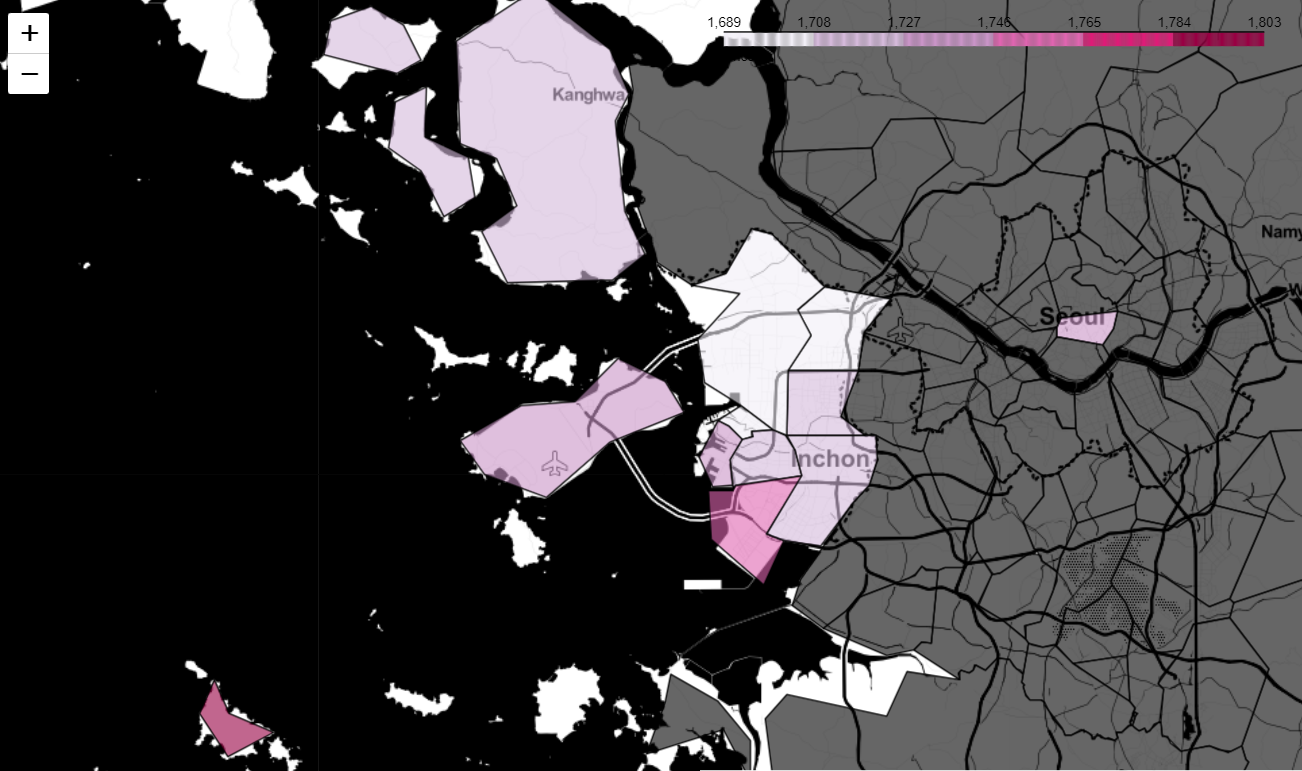
이번 작업을 하면서 choropleth의 key_on 옵션에 대해 더 알아보게 되었는데, 무작정 'feature.id', 'feature.~'를 사용하는게 아니였다.
해당 json파일을 들어가보면 아래와 같이 나오는데
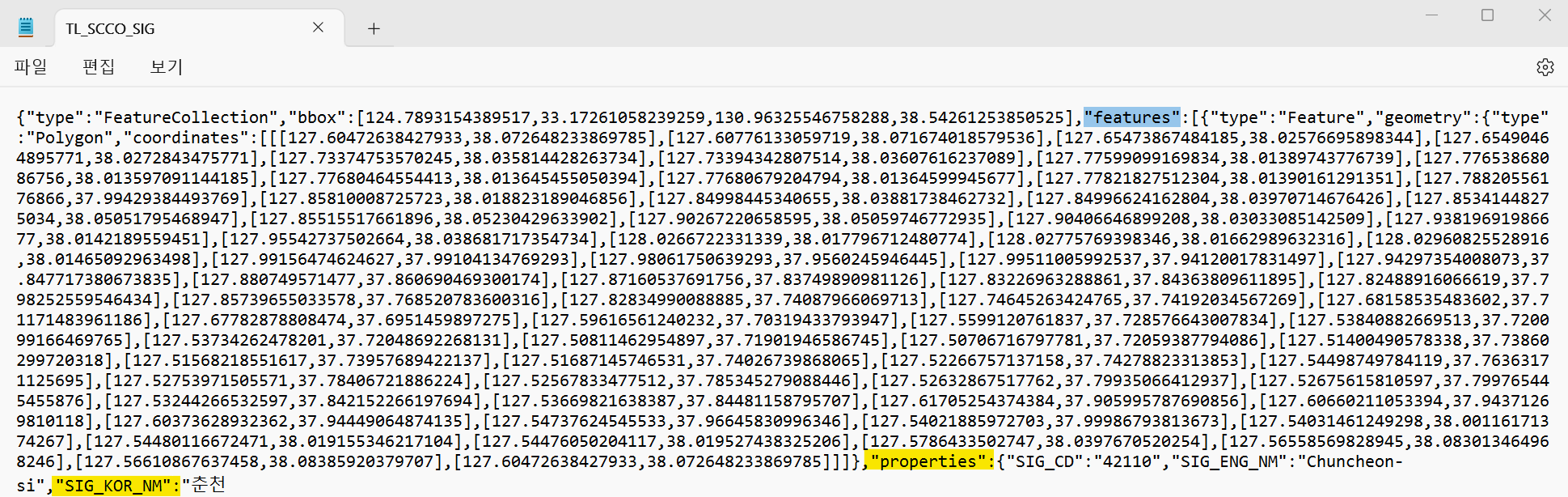
여기에서 key값으로 쓸 아이를 지정해주는 것이다. 따라서
key_on = "feature.properties.SIG_KOR_NM"이 되는 것!
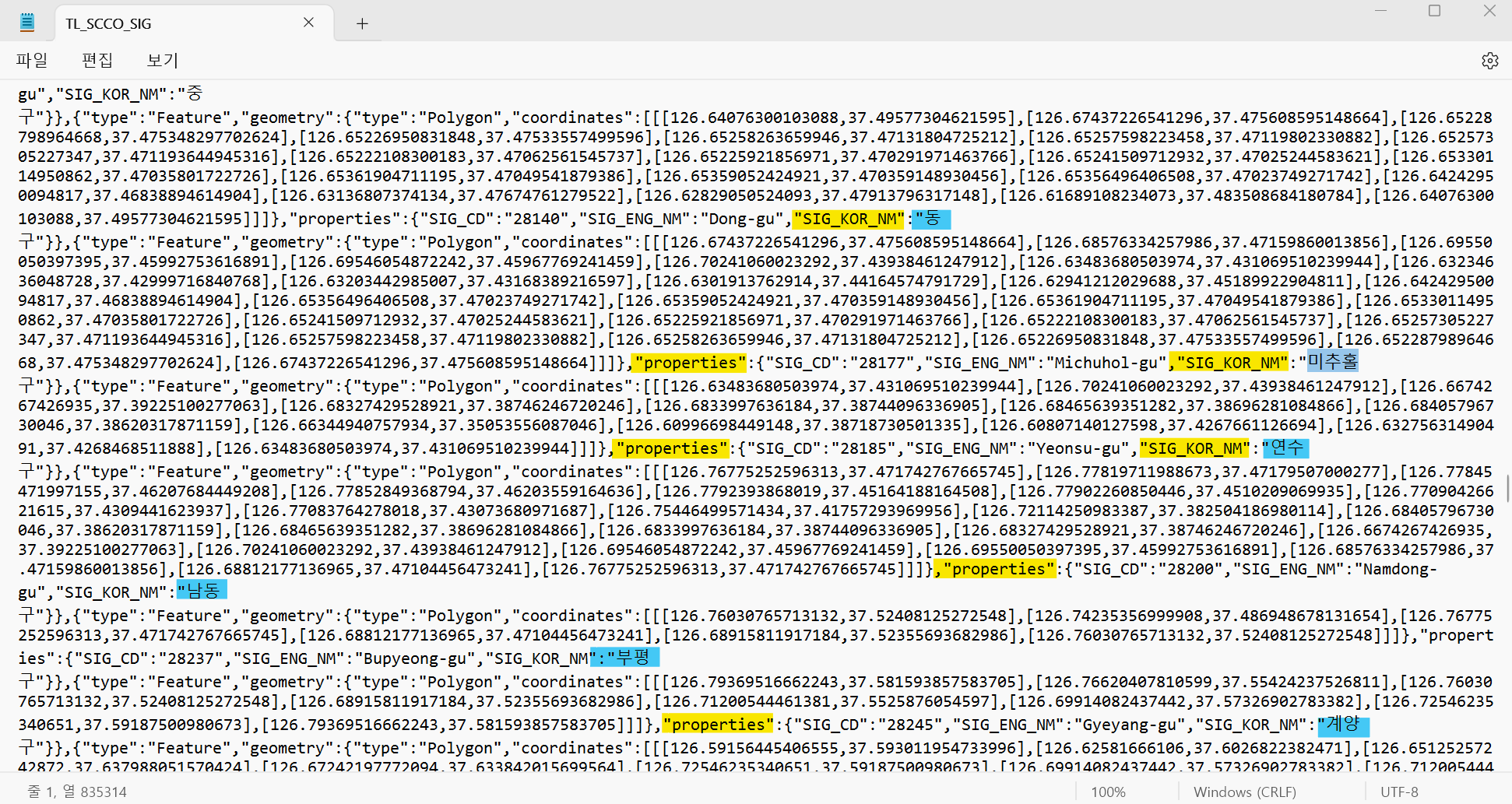
위 사진처럼 인천시에 대한 구/군 데이터도 들어가있다 :)
