✍🏻 14일 공부 이야기.
👀 오늘 공부한 자세한 코드는 아래 깃허브에 올라가있습니다!
forecast(시계열 분석)
: 시간의 흐름에 대해 특정 패턴과 같은 정보를 가지고 있는 경우를 시계열 데이터라고 함.(실제로 머신러닝에서는 시간의 특성은 별로 없고 딥러닝의 RNN 분야에서 조금 쓰임)
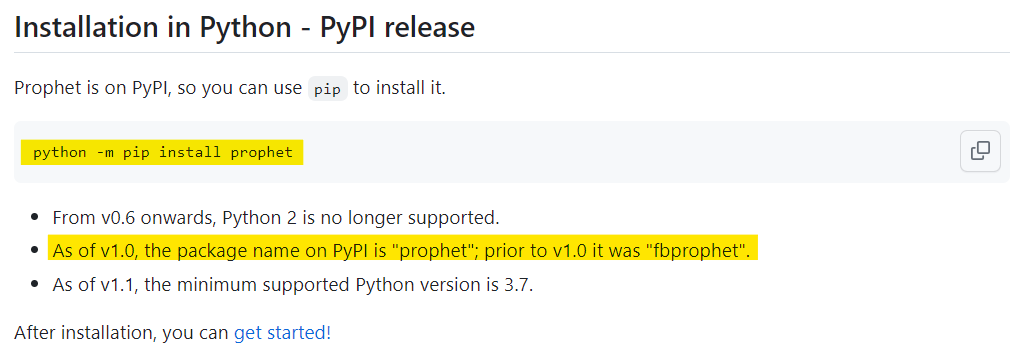
Prophet(fp-prophet에서 개명됨) 설치
💻 window.ver
- 비주얼 스튜디오 설치
conda install pandas-datareaderconda install -c conda-forge fbprophetfrom pandas_datareader import data from fbprophet import Prophet
※ 참고로 위의 과정을 따라했는데 아래와 같은 오류가 떴었다.
TypeError: This is a python-holidays entity loader class. For entity inheritance purposes please import a class you want to derive from directly: e.g., `from holidays.countries import Entity` or `from holidays.financial import Entity`.fprophet 설치 오류와 관련해서 구글링을 하던 중, 🖱️이 사이트를 발견했고
from pandas_datareader import data
from prophet import Prophet을 해줬는데
Importing plotly failed. Interactive plots will not work.경고 문구가 떴다.
pip install plotly까지 해주고 다시 실행해보니 아무 경고 문구 없이 깔끔하게 임포트 됨!
🖱️ Prophet 공식 문서에도 prophet이라 나와있다.
🖱️ Prophet 공식 깃허브에 가면 아래와 같이 개명되었다는 공지사항도 볼 수 있었다.
함수 기초
삼각함수의 기본형을 함수로 만들어 그래프를 만들어보자.
📌 파이썬 keyword argument를 이용해 사용자가 인자의 이름까지 전달하면서 함수를 호출하게끔 할 수 있음.
함수의 인자가 많은 경우, 함수를 각 인자들의 위치를 외우기가 쉽지 않으므로 호출할 때마다 선언 내용을 살펴봐야한다. 이런 경우에 keyword argument를 이용하여 사용자가 인자의 이름을 직접 설정해주면서 호출하기 편하게 하고 인자가 설정되지 않으면 기본값을 사용하게끔 할 수 있어 많이 사용한다!!
📌 쌍따옴표(") 혹은 홑따옴표(') 세 개를 이용해 주석을 달아주면 Docstring(함수명 끝에 커서를 두고 Shift + Tab)을 통해 볼 수 있다. 따라서 주석을 달아주는 습관을 들일 것!

## keyword argument : **변수명
## **변수명 을 이용해 사용자가 직접 옵션명과 같이 값을 설정해주면 그 값을 이용하고
## 아니면 기본값을 이용해 계산됨
def plotSinWave(**kwargs):
'''
plot sine wave
y = a sin(2 pi f t + t_0) + b
'''
# 옵션명 , 기본값
endTime = kwargs.get("endTime", 1)
sampleTime = kwargs.get("sampleTime", 0.01)
amp = kwargs.get("amp", 1)
freq = kwargs.get("freq", 1)
startTime =kwargs.get("startTime", 0)
bias = kwargs.get("bias", 0)
figsize = kwargs.get("figsize", (12,6))
time = np.arange(startTime, endTime, sampleTime)
result = amp * np.sin(2 * np.pi * freq * time + startTime) + bias
plt.figure(figsize = figsize)
plt.plot(time, result)
plt.grid(True)
plt.xlabel("time")
plt.ylabel("sin")
plt.title(str(amp) + "*sin(2*pi" + str(freq) + "*t+" + str(startTime) + ")+" + str(bias))
plt.show()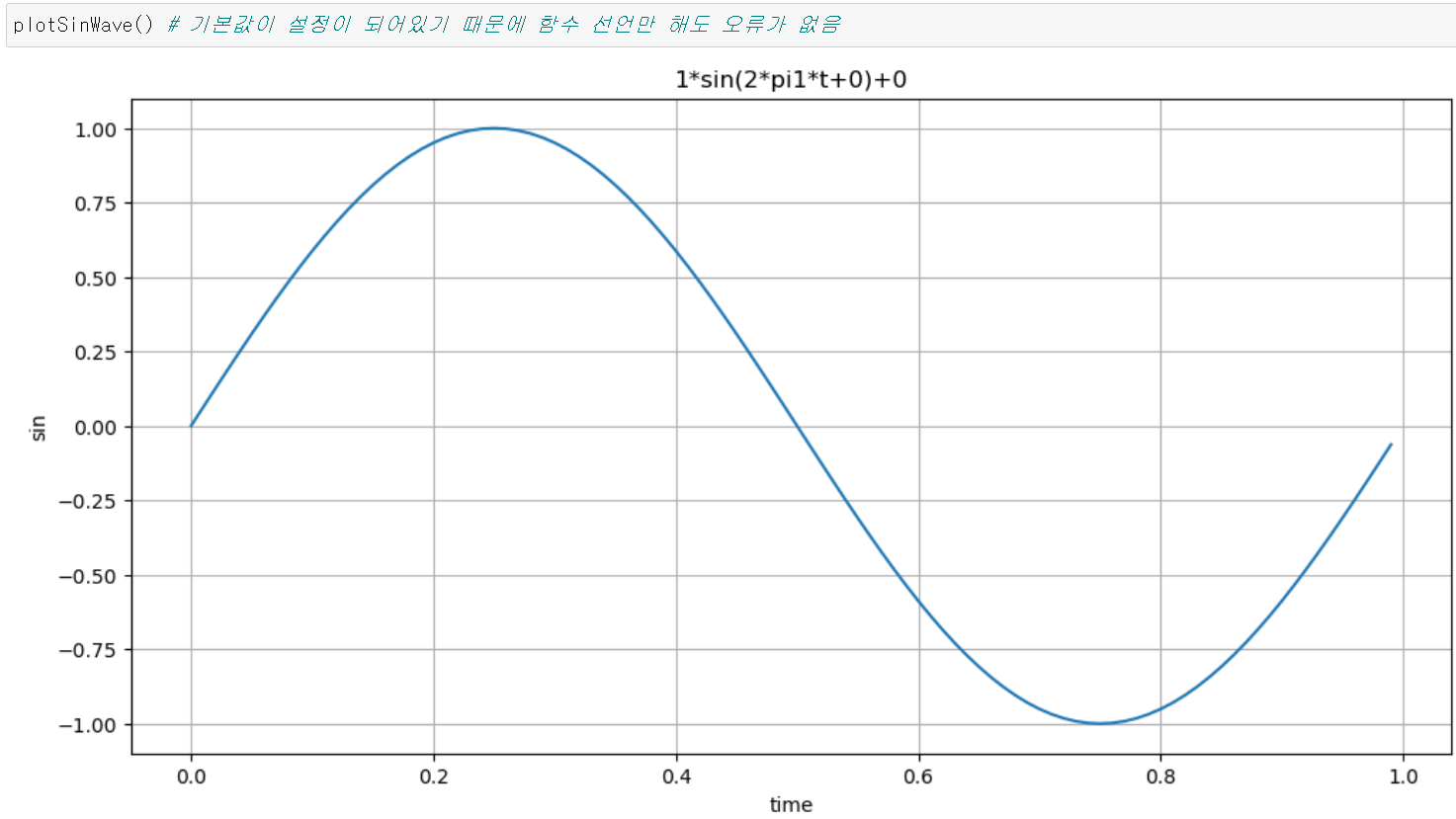 | 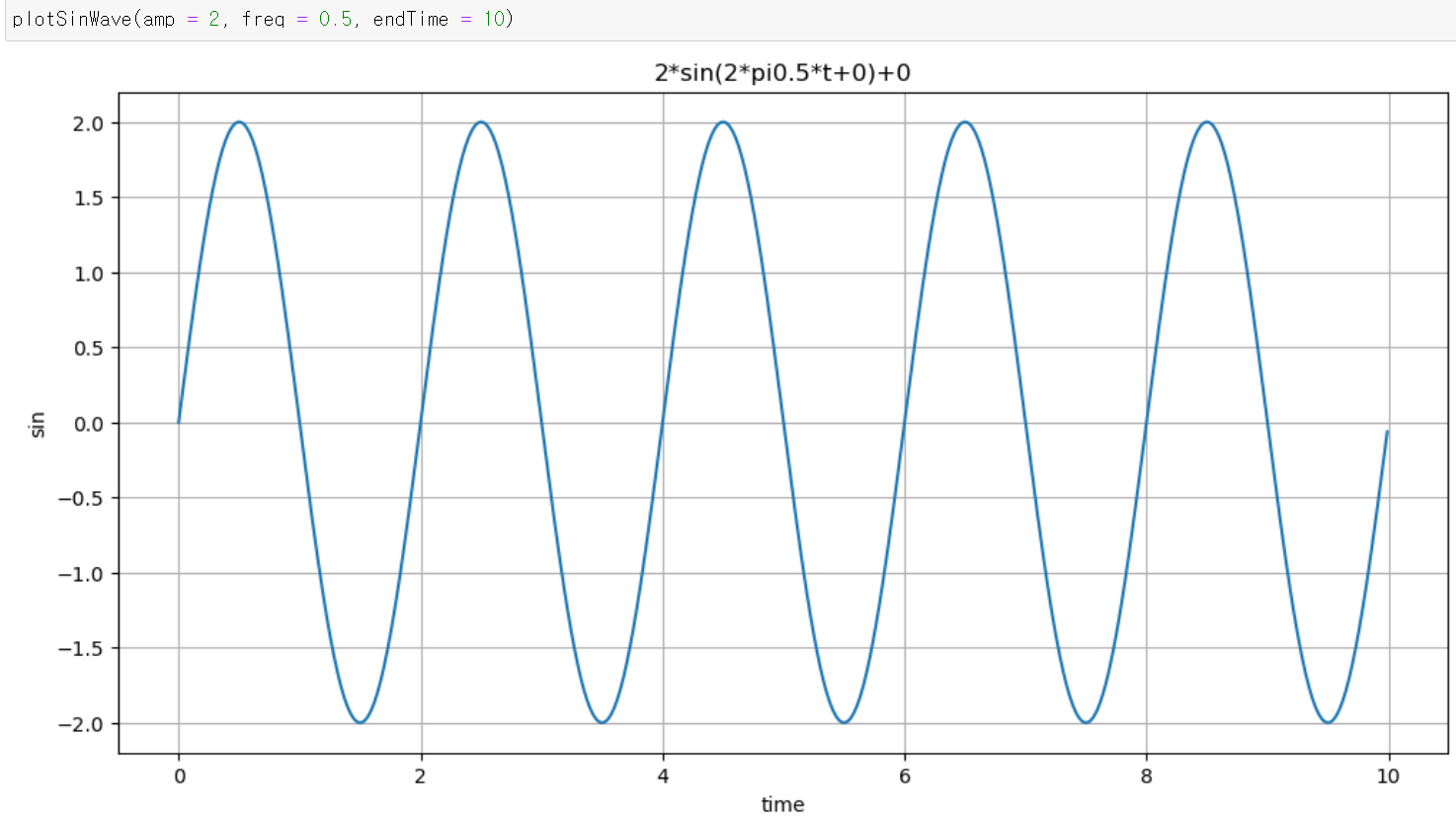 |
|---|
사용자 함수를 import하기
- 사용자 함수 코드가 들어간 파이썬 파일(.py) 생성
- 다른 파이썬 파일을 열어 import하기
import 사용자함수파일명 as 별명
별명.사용자함수명()💡 사용자함수가 들어가있는 파일을 직접 실행시키지 않아야 import의 의미(?)가 있다. 따라서 if __name__ == "__mian__: 코드를 통해 해당 파일이 직접 실행이 된 것인지 아닌지 확인할 수 있는 코드도 있으면 좋다 :)
이 기능을 이용해 그동안 matplotlib을 사용하면 항상 import 해주었던 코드를 파일로 만들어 다음부턴 파일명만 import 할 수 있도록 해보자.
VSCode에서 .py파일을 만들어 실행한다면 편할텐데, 주피터노트북에서는 아래와 같이 .py파일을 만들 수 있다.
1. New - Text File 클릭하기
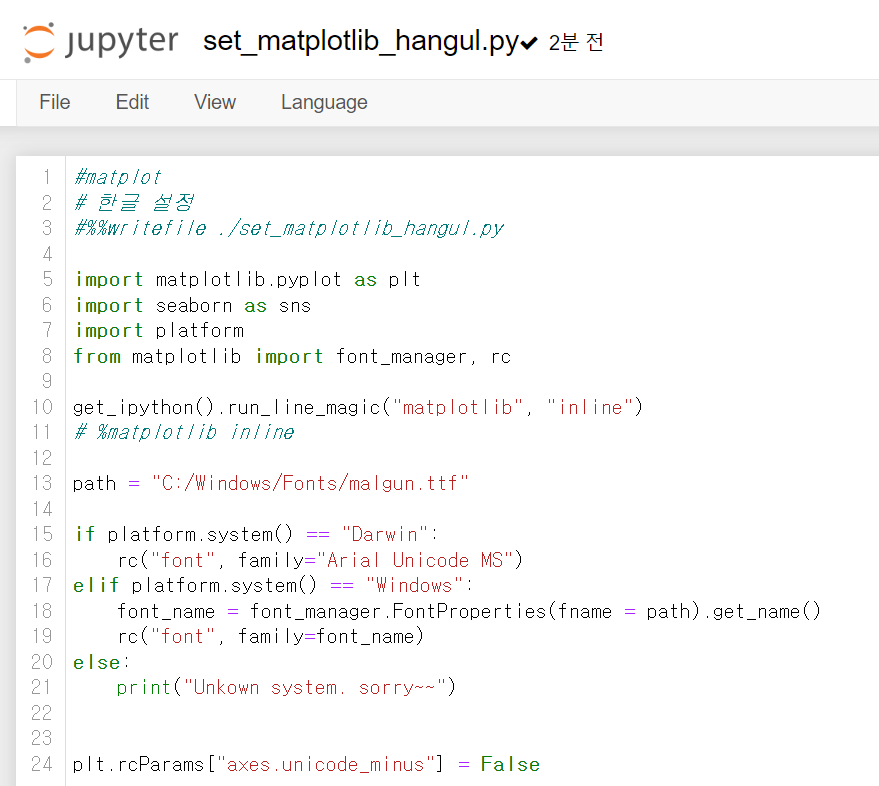
2. 코드를 적어준 후, 제목을 파일명.py로 지어주기
3. import해서 사용해주면 된다 !
prophet 기초
- 데이터 만들어주기
time = np.linspace(0,1,365*2)
result = np.sin(2*np.pi*12*time) + time + np.random.randn(365*2)/4 #sin그래프에 노이즈를 추가
ds = pd.date_range("2018-01-01", periods = 365*2, freq = "D") # 꼭 날짜형 데이터!
df = pd.DataFrame({"ds" : ds, "y" : result})
df["y"].plot(figsize = (10,6))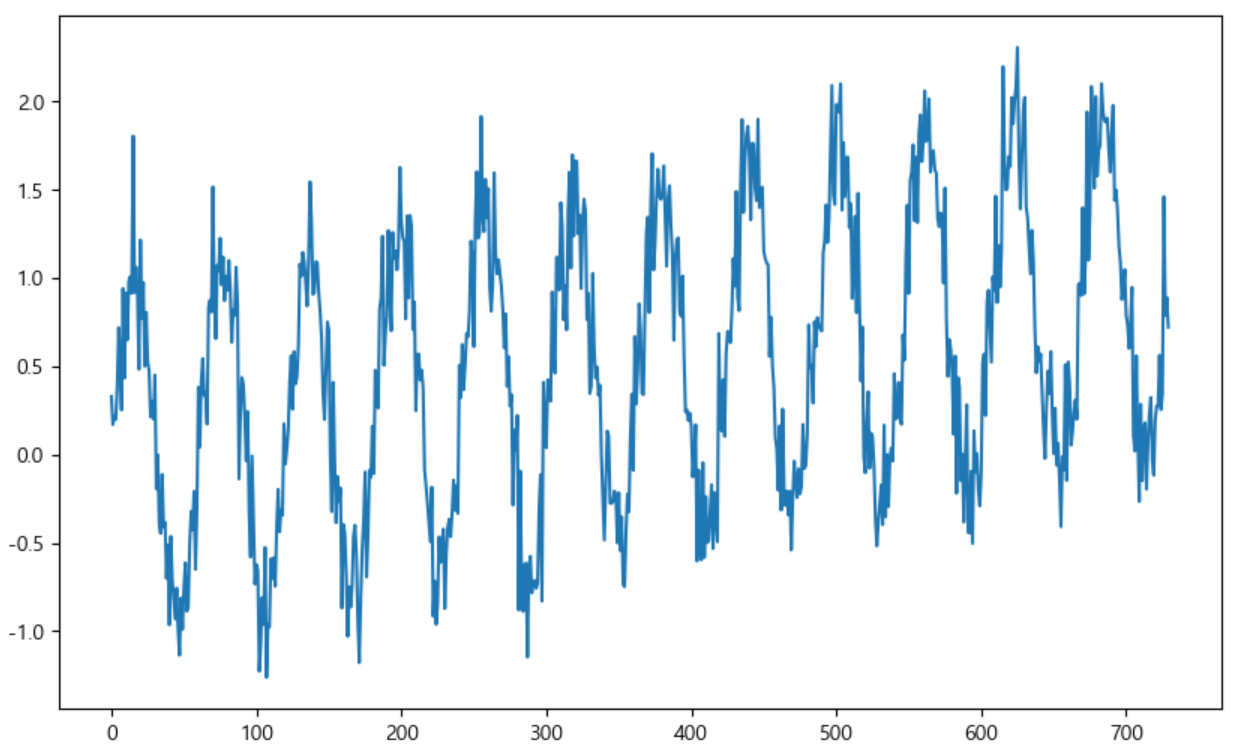
- prophet으로 학습시킨 후, 데이터를 예측시켜보기
변수명 = Prophet()
변수명.fit(데이터프레임명) # 학습
변수명2 = 변수명.make_future_dataframe(periods = 예측할 기간) # 설정한 기간만큼 데이터를 생성해줌
변수명3 = 변수명.predict(변수명2) # 예측값들이 저장됨m = Prophet(yearly_seasonality=True, daily_seasonality=True)
m.fit(df) # 우리가 만든 데이터를 집어넣어 학습시킴
future = m.make_future_dataframe(periods = 30) #30일 간의 데이터를 예측해봐라
forecast = m.predict(future) #예측값 저장
m.plot(forecast); #점이 찍혀있지 않은 그래프 부분이 학습에 의한 예측값 부분!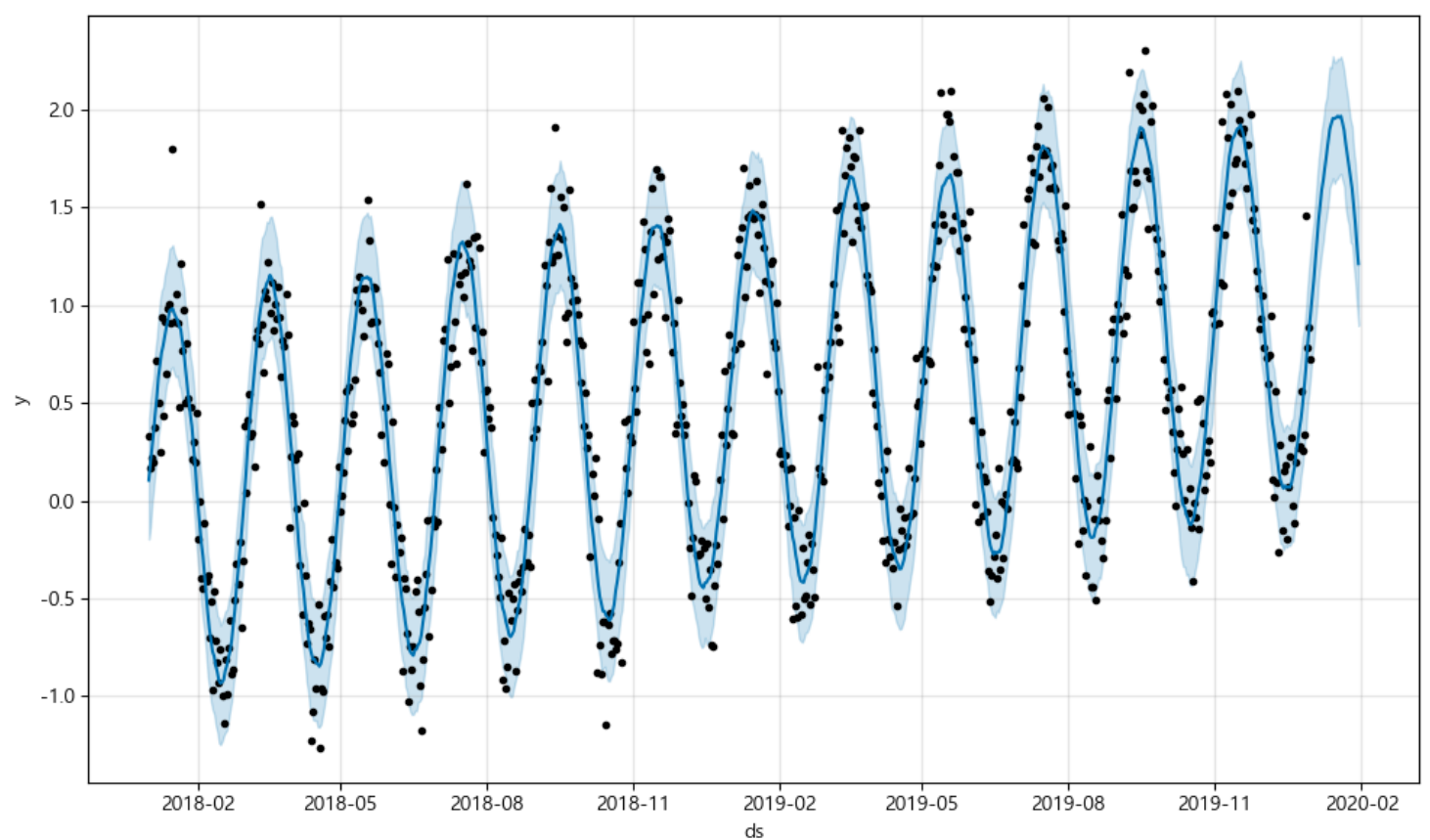
웹 유입량 데이터 분석
앞서 실습한 prophet을 이용해 https://pinkwink.kr/ 사이트의 웹 유입량 데이터를 분석해보자.
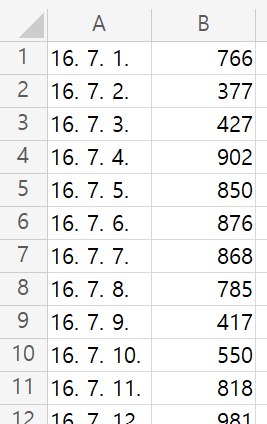
데이터는 위와 같이 날짜와 유입량 수로 이루어져있다.
pinkwink_web = pd.read_csv(
"../data/05_PinkWink_Web_Traffic.csv",
encoding = "utf-8",
thousands = ",",
names = ["date", "hit"],
index_col = 0
)데이터를 불러오고 정리하면 아래와 같은 데이터프레임이 만들어진다.

전체 데이터는 아래와 같은 형태를 띄고 있다는 것을 볼 수 있다.
# 전체 데이터 그려보기
pinkwink_web["hit"].plot(
figsize = (12,4),
grid = True
)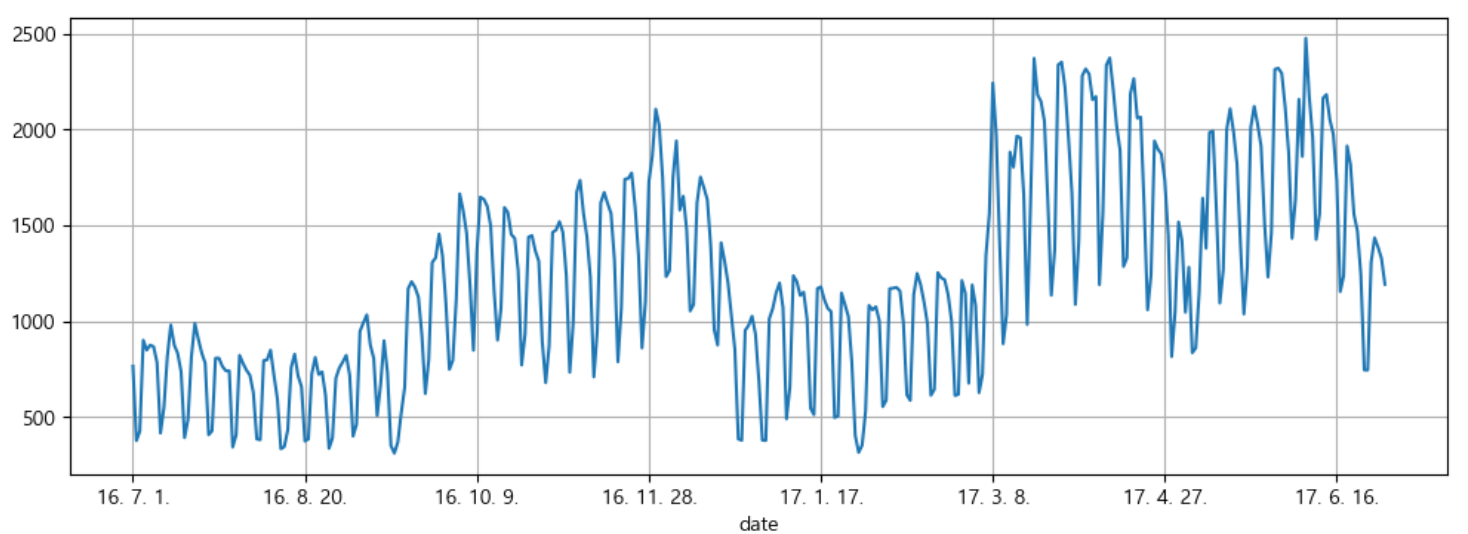
👀 전체 데이터를 그래프로 그려보니, 시간에 따른 패턴이 어느정도 있는 것 같아 시계열 분석을 해볼 수 있을 것 같다!
그래서 이전 시간에 배웠던 선형회귀와 오늘 배운 prophet 2가지로 데이터를 예측해볼 예정이다.
어떤 모델이 더 좋은지 확인하려면 에러를 계산해줄 지표가 필요한데, 오늘은 RMSE를 활용해보려 한다.
# 에러를 계산할 함수(RMSE)
def error(f, x, y):
return np.sqrt(np.mean((f(x) - y) ** 2))예측을 하기 위해 x축, y축 데이터를 뽑아주고
# trend 분석을 시각화하기 위한 x축 값 만들기
time = np.arange(0,len(pinkwink_web)) # 날짜 데이터 개수만큼의 x축 데이터 만들기
fx = np.linspace(0,time[-1], 1000) #0부터 x마지막 데이터 사이에서 1000개의 데이터 추출
traffic = pinkwink_web["hit"].values #y값회귀 직선을 통해 예측을 시켜보자.
# prophet을 사용하기 전, 이전 시간에 배웠던 회귀 직선을 이용해 추측해보자.
fp1 = np.polyfit(time, traffic, 1) # 1차식
f1 = np.poly1d(fp1) # 위에서 구한 값들로 다항식을 생성해줌
fp2 = np.polyfit(time, traffic, 2) # 2차식
f2 = np.poly1d(fp2)
fp3 = np.polyfit(time, traffic, 3) # 3차식
f3 = np.poly1d(fp3)
fp15 = np.polyfit(time, traffic, 15) # 15차식
f15 = np.poly1d(fp15)위에서 만든 회귀 직선들의 오차를 살펴보면
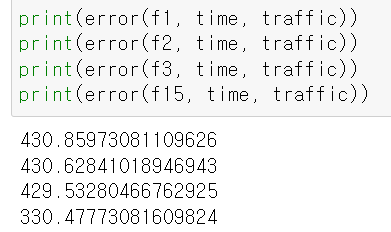
상당히 크다..!🤯
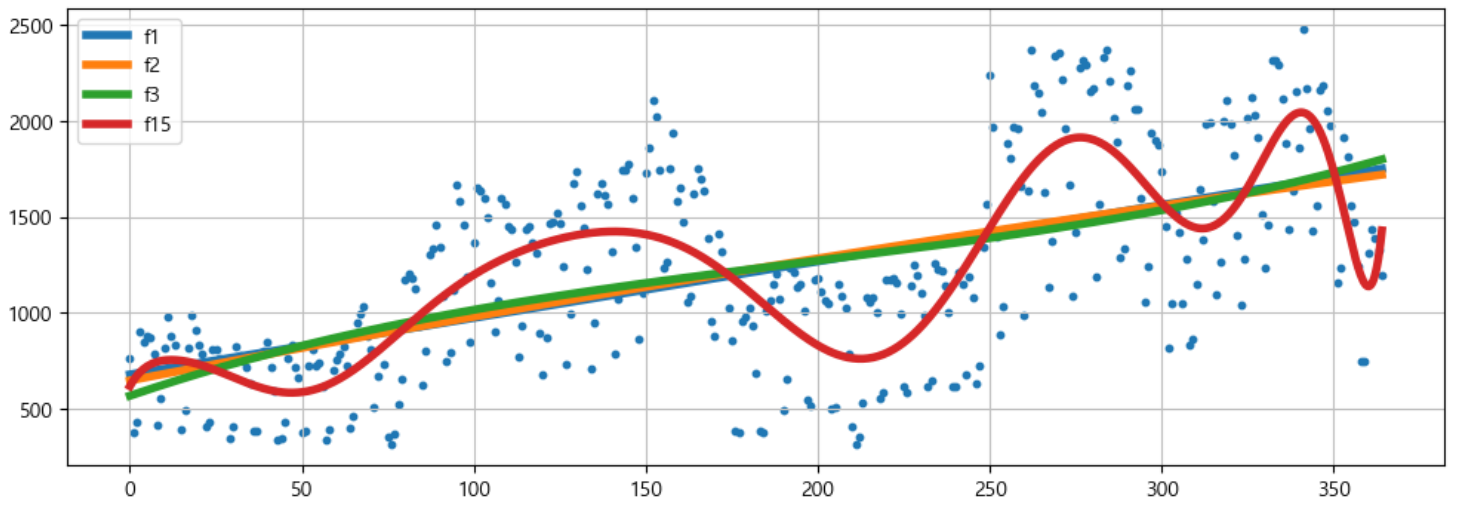
실제 데이터와 예측한 모델을 시각화해보면 위와 같다.
그렇다면 시간의 특성을 반영한 Prophet은 어떨까?
먼저 모델에 적용할 수 있게 데이터를 가공해준다.
df = pd.DataFrame({"ds" : pinkwink_web.index, "y" : pinkwink_web['hit']})
df.reset_index(inplace = True)
df["ds"] = pd.to_datetime(df["ds"], format = "%y. %m. %d.") # 날짜 형식 변환
del df['date']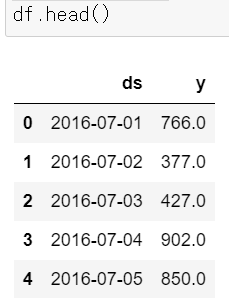
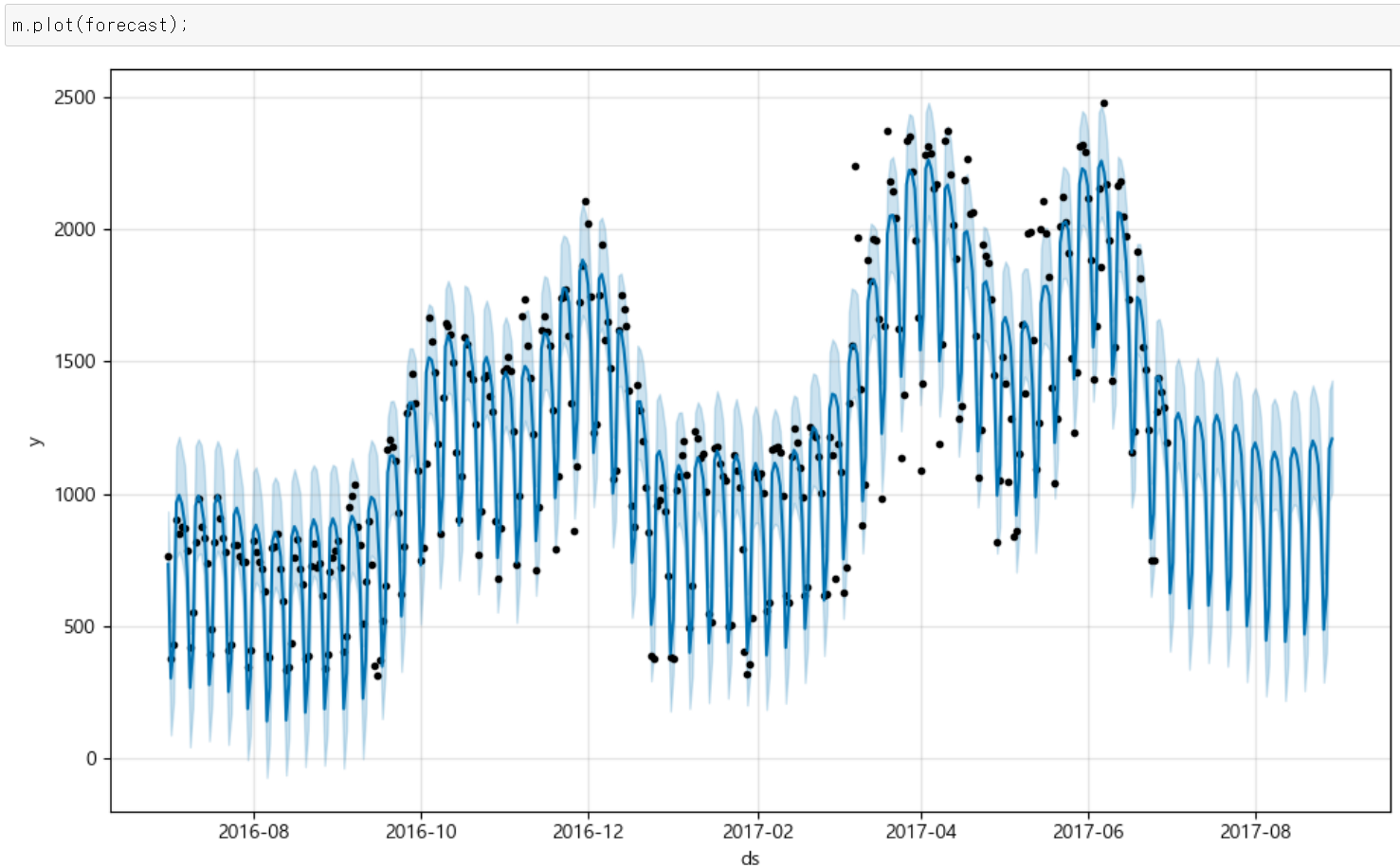
그 다음 Prophet으로 학습시킨 후, 예측시킨 결과는 아래와 같다.
m = Prophet(yearly_seasonality=True, daily_seasonality=True)
# 데이터 학습
m.fit(df)
# 60일에 해당하는 데이터 생성
future = m.make_future_dataframe(periods = 60)
# 예측 결과는 상한/하한의 범위를 포함해서 얻어짐
forecast = m.predict(future)
forecast #결과로 얻어지는 해당 열들에 대한 설명을 찾고 싶은데 못 찾겠다ㅠ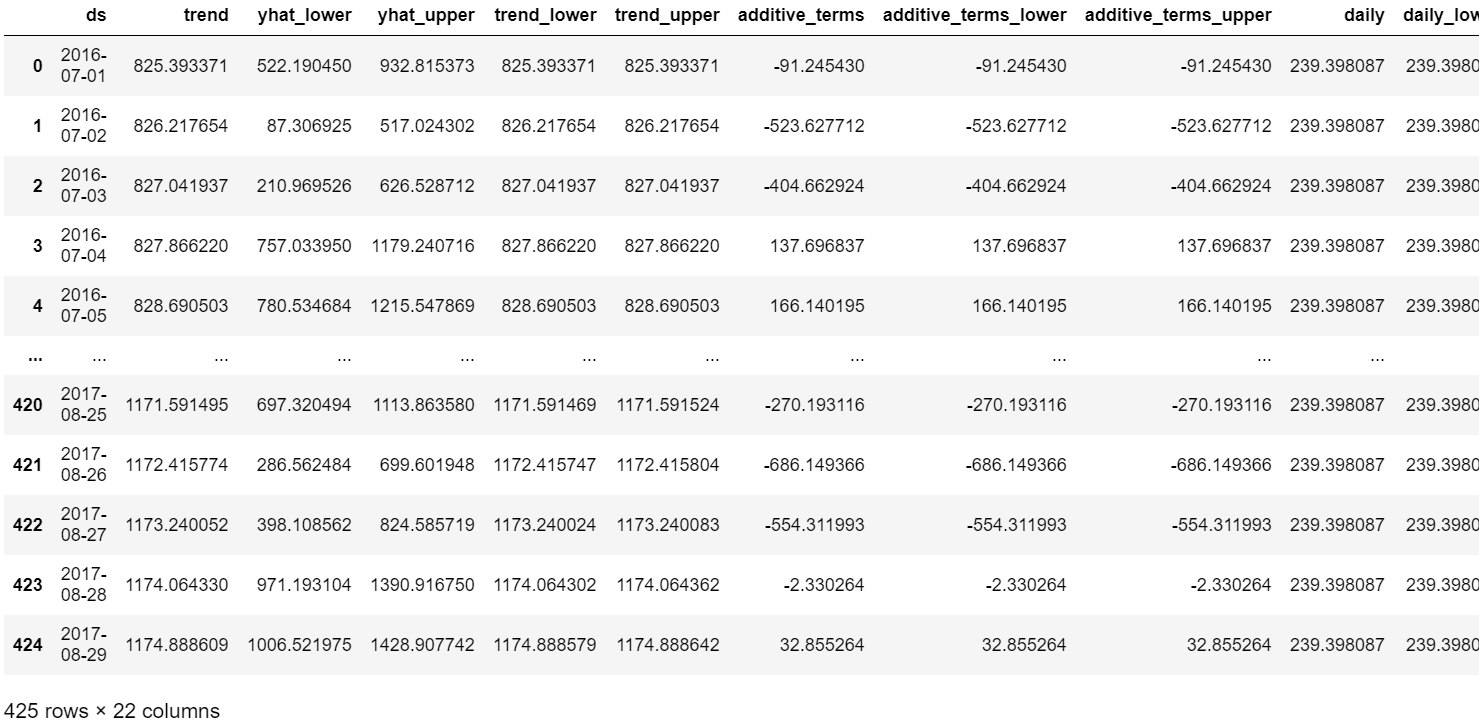
굉장히 열의 개수가 많은 데이터프레임이 만들어졌는데, 각 해당 열들이 무엇을 의미하는지 정확하게 알고 싶어 🖱️ Prophet 공식 문서에 들어가보았는데 찾질 못했다..🥺
어쩔 수 없이 ChatGPT에게라도 물어봤는데 아래와 같은 답변을 주었다 :)

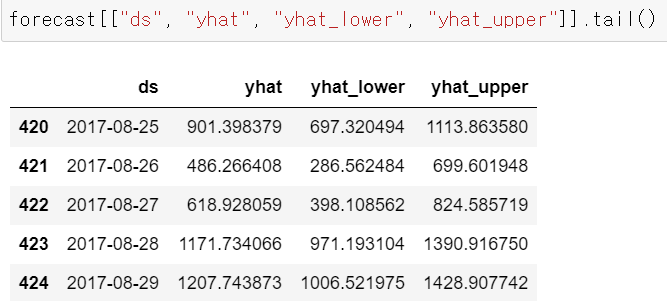
여기에서 나에게 필요한 컬럼들만 쏙! 뽑아 데이터프레임을 보면 아래와 같이 볼 수도 있다.
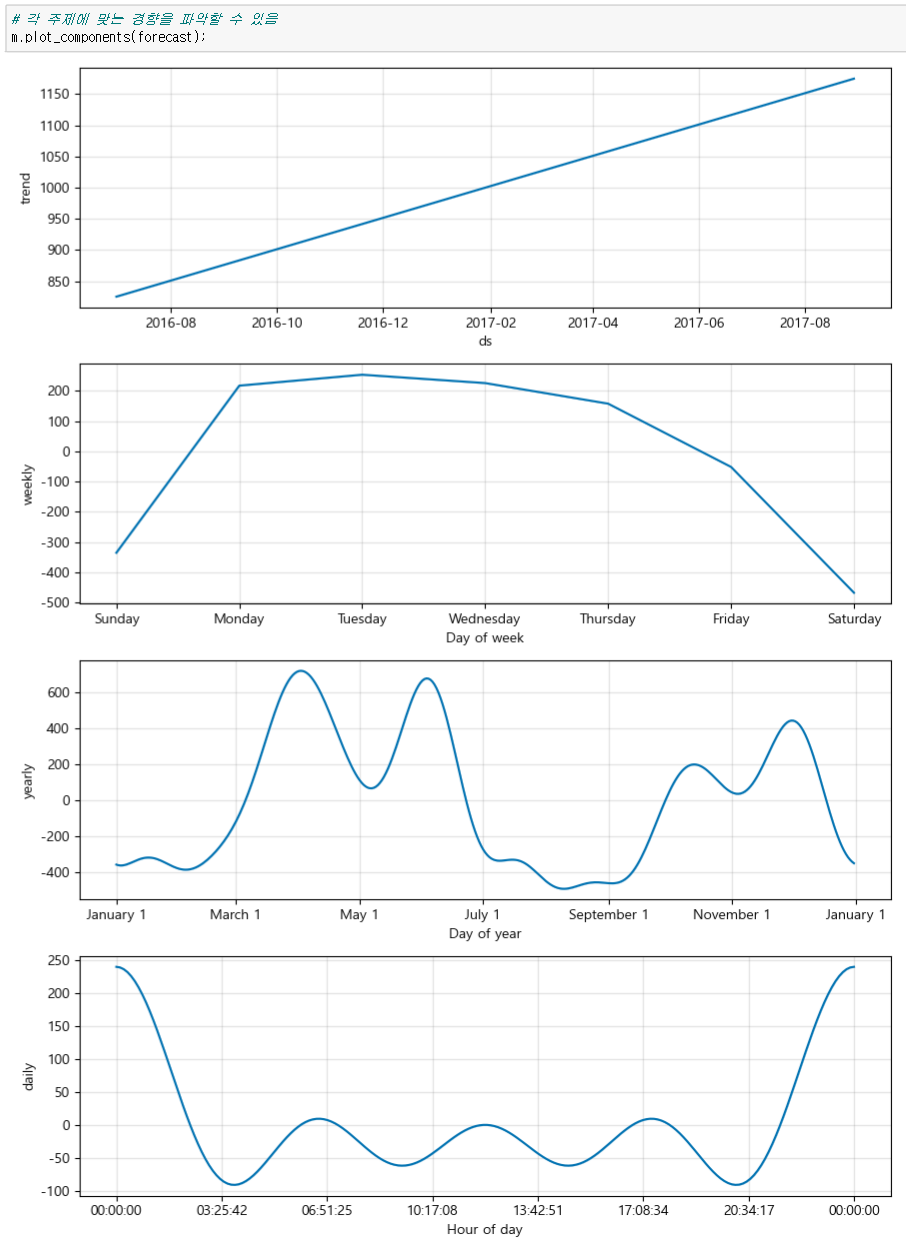
전체 경향과 plot_components 을 이용해 각 시간별, 주별, 월별, 년도별 등 시간에 따른 경향도 볼 수 있다.
 |  |
|---|
그렇다면 과연 오차는?

회귀로 예측한 오차들보다 훨씬 감소된 오차를 확인할 수 있었다 😆😆
Naver API
네이버 API를 사용하기 위해선 먼저 등록이 필요하다.
등록하기
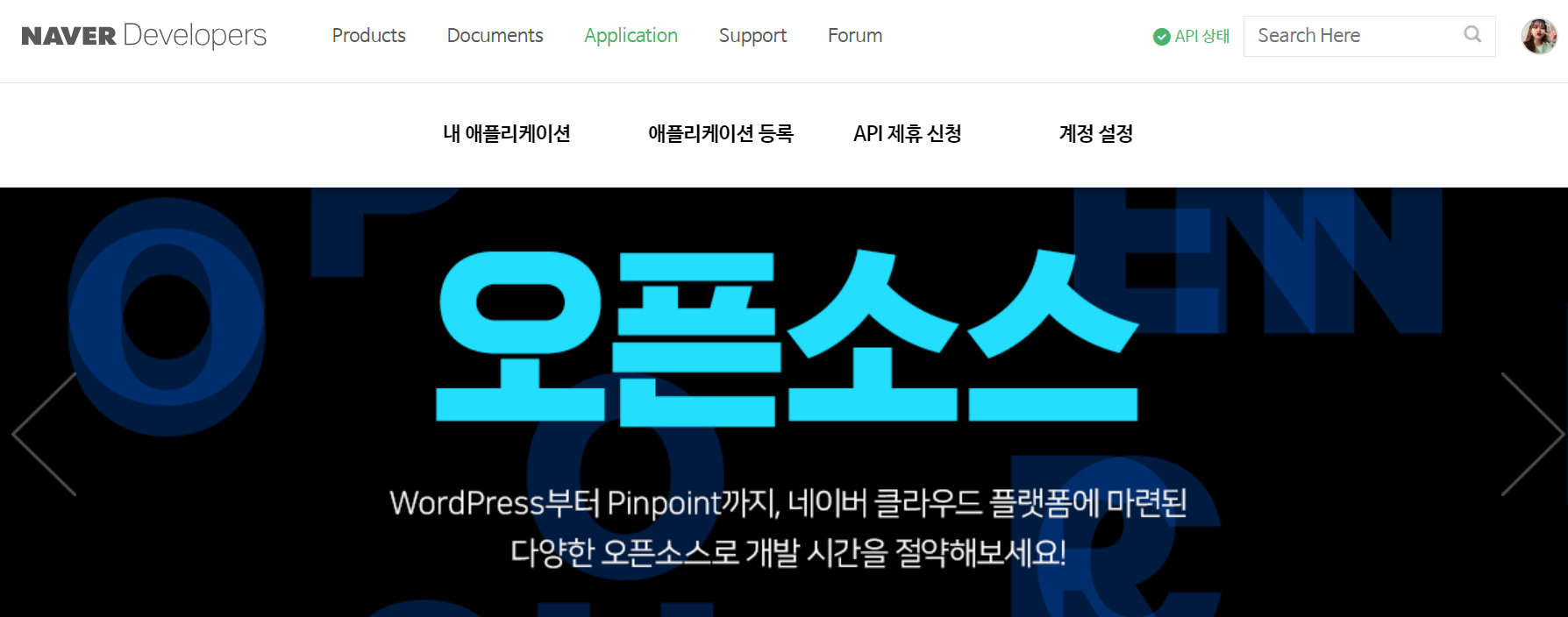
해당 링크에서 Application - 애플리케이션 등록에 들어가 등록해주면 된다.
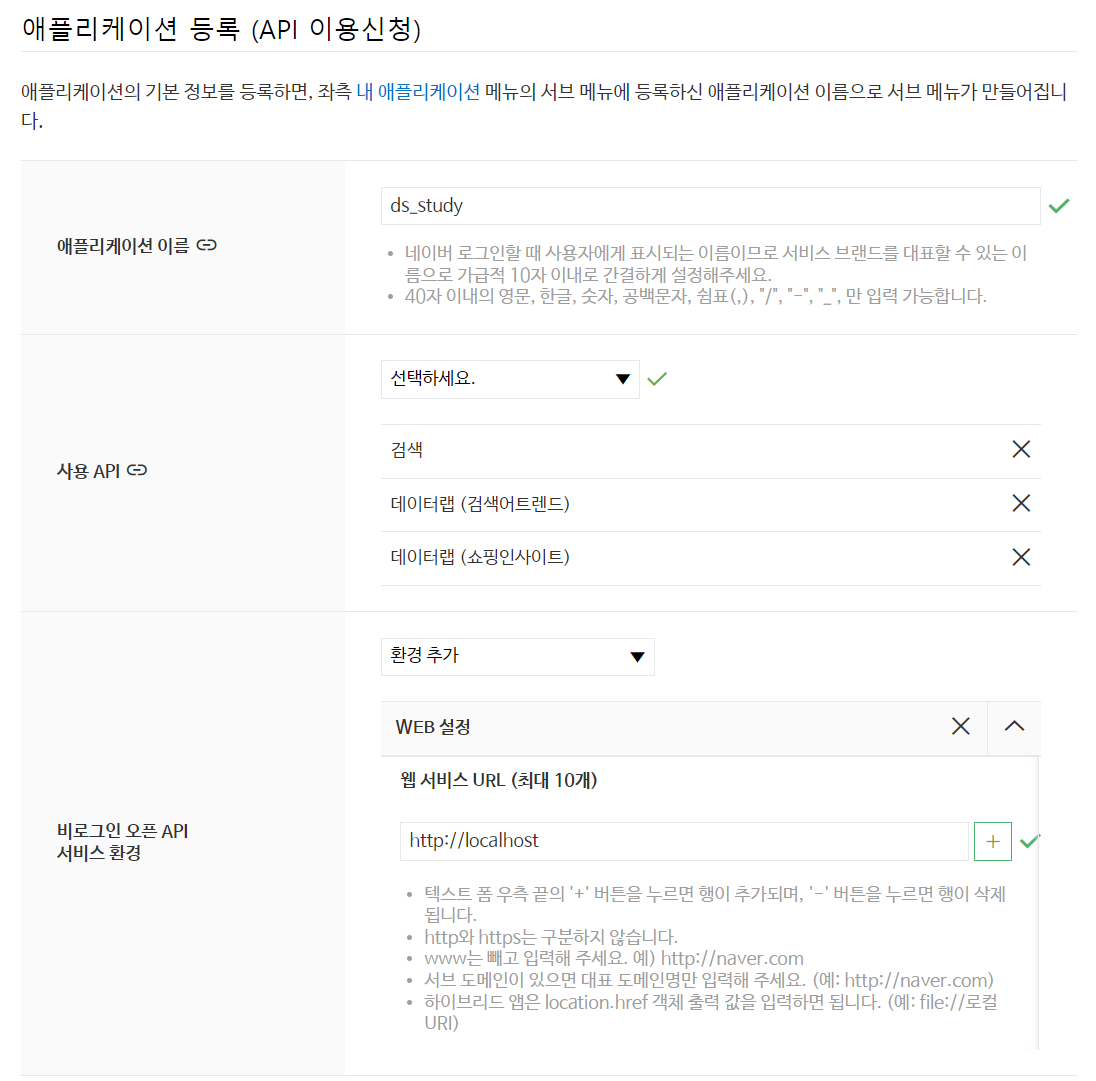
자신이 이용하고 싶은 API를 선택하고 환경을 설정해주면 끝!
💡 등록을 하면 Client ID 와 Secret이 나오는데 꼭 복사 붙여넣기해서 저장해두기
일일 검색량이 정해져있는 것도 확인할 수 있다.
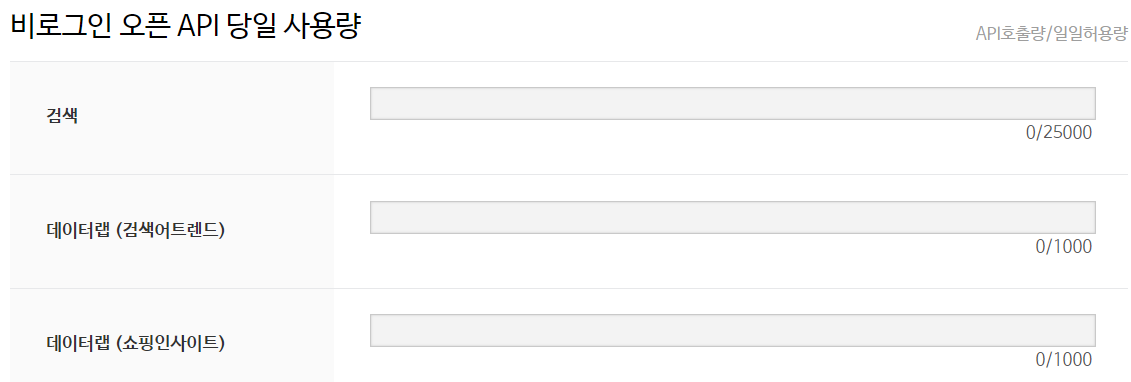
사용해보기
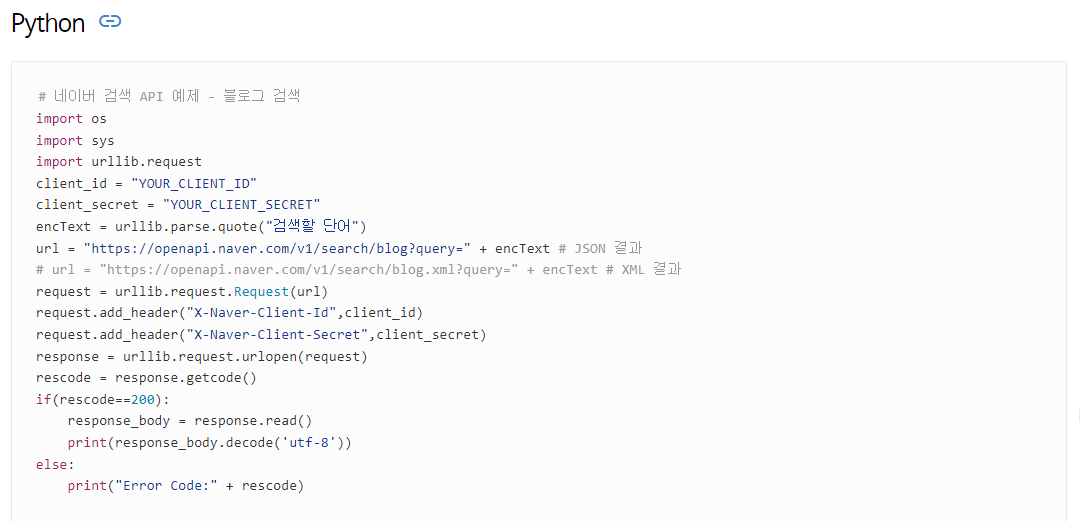
공식 문서에서 준 코드를 따라가보자.
💡 client_id 와 client_secret은 개인걸로 변경해주기
urllib: http 프로토콜에 따라 서버의 요청/응답을 처리하기 위한 모듈urllib.request: 클라이언트의 요청을 처리하는 모듈urllib.parse: url 주소에 대한 분석- 사용하는 서비스마다 오류 코드가 다르므로 공식 문서를 확인하기
위 사진에서 url부분만 살짝 원하는 API로 변경하면 된다.
검색 : 블로그(blog)
# 네이버 검색 API 예제 - 책 검색(url에서 blog -> book)
client_id = "fP155_fIbiINbREJMUiR"
client_secret = "hCFcz0YTay"
encText = urllib.parse.quote("파이썬")
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8')) # 한글로 읽기 위해 decode 설정
else:
print("Error Code:" + rescode) | 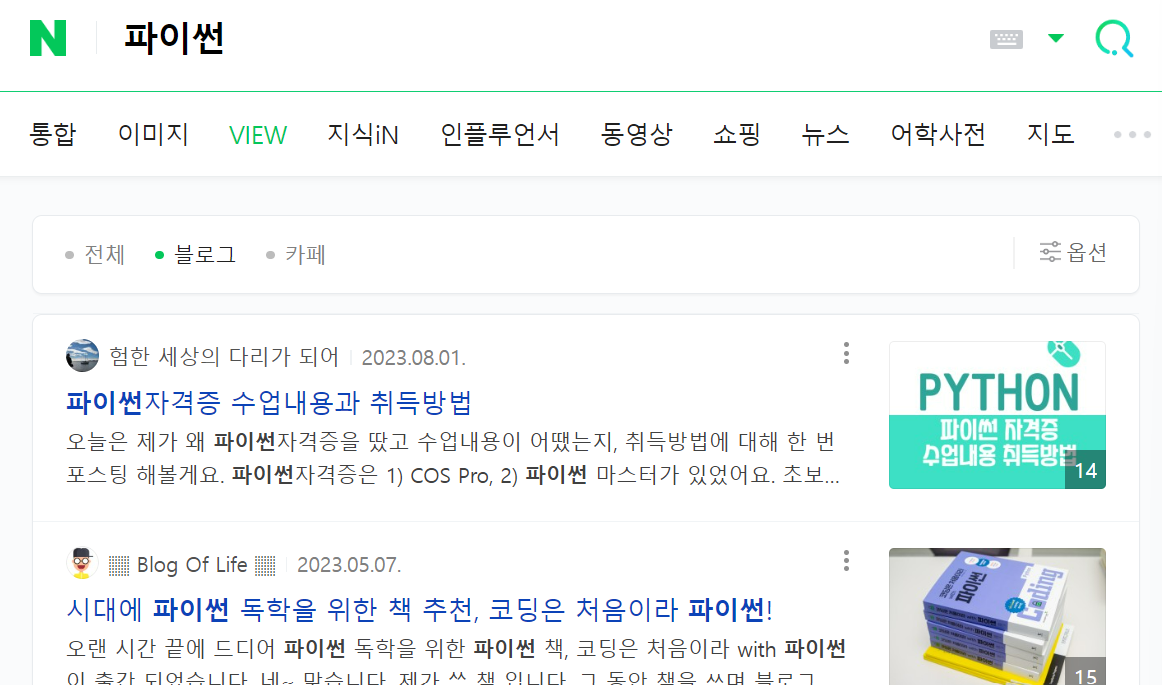 |
|---|
검색 : 책(book)
# 네이버 검색 API 예제 - 책 검색(url에서 blog -> book)
client_id = "fP155_fIbiINbREJMUiR"
client_secret = "hCFcz0YTay"
encText = urllib.parse.quote("파이썬")
url = "https://openapi.naver.com/v1/search/book?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8')) # 한글로 읽기 위해 decode 설정
else:
print("Error Code:" + rescode)
검색 : 카페(cafearticle)
# 네이버 검색 API 예제 - 카페 검색
client_id = "fP155_fIbiINbREJMUiR"
client_secret = "hCFcz0YTay"
encText = urllib.parse.quote("파이썬")
url = "https://openapi.naver.com/v1/search/cafearticle?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8')) # 한글로 읽기 위해 decode 설정
else:
print("Error Code:" + rescode) | 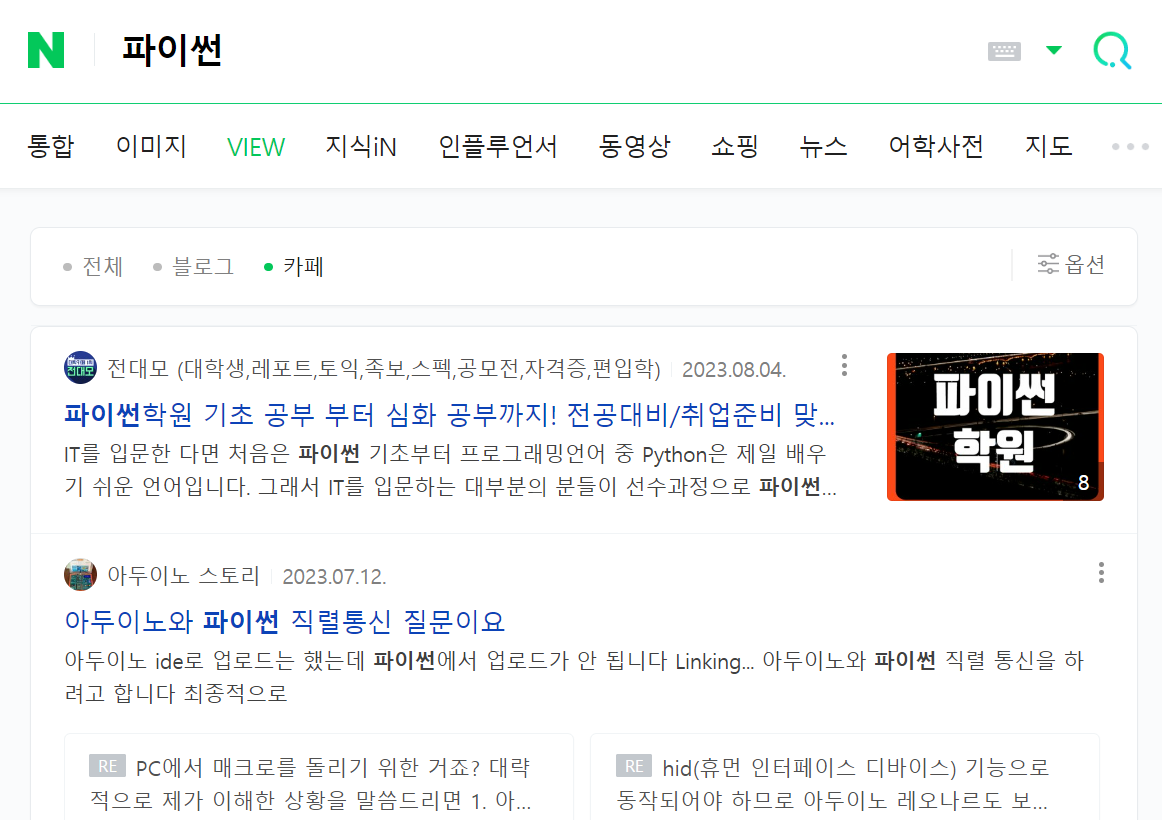 |
|---|
검색 : 쇼핑(shop)
 | 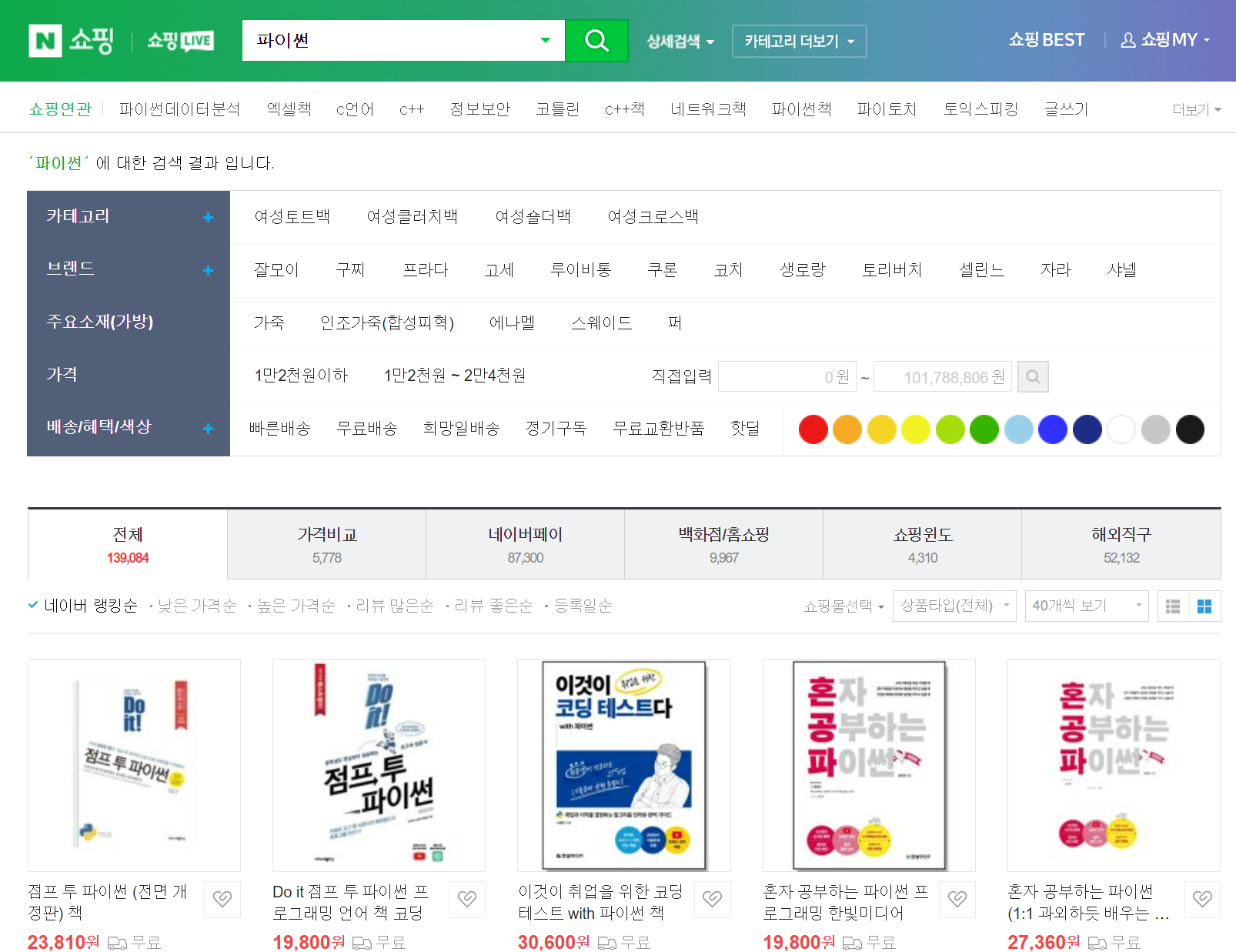 |
|---|
검색 : 백과사전(encyc)
| |
|---|
이외에도 아래와 같이

다양한 사이트에서의 검색 결과를 얻어낼 수 있다.
🤔 직접 네이버에 검색해보니 일치하는 부분이 나오기는 하는데 어떤 순서로 결과가 출력되는지는 모르겠다.
📌 위 사이트들 중 "영화"는 서비스를 종료했다고 한다. (영화 검색을 할시 404에러가 뜸!)
상품 검색하는 코드를 함수로 만들어보자
함수 개요 정리
get_search_url: 검색 url을 만드는 함수get_result_onpage: 페이지에 나타난 검색 결과를 저장해주는 함수get_fileds: 검색된 내용을 데이터프레임으로 저장해주는 함수actMain: 앞서 만든 함수들을 실제로 실행시켜 데이터를 수집해주는 함수toExcel: 최종적으로 엑셀 파일에 저장해주는 함수
Step1. get_search_url : 검색 url을 만드는 함수
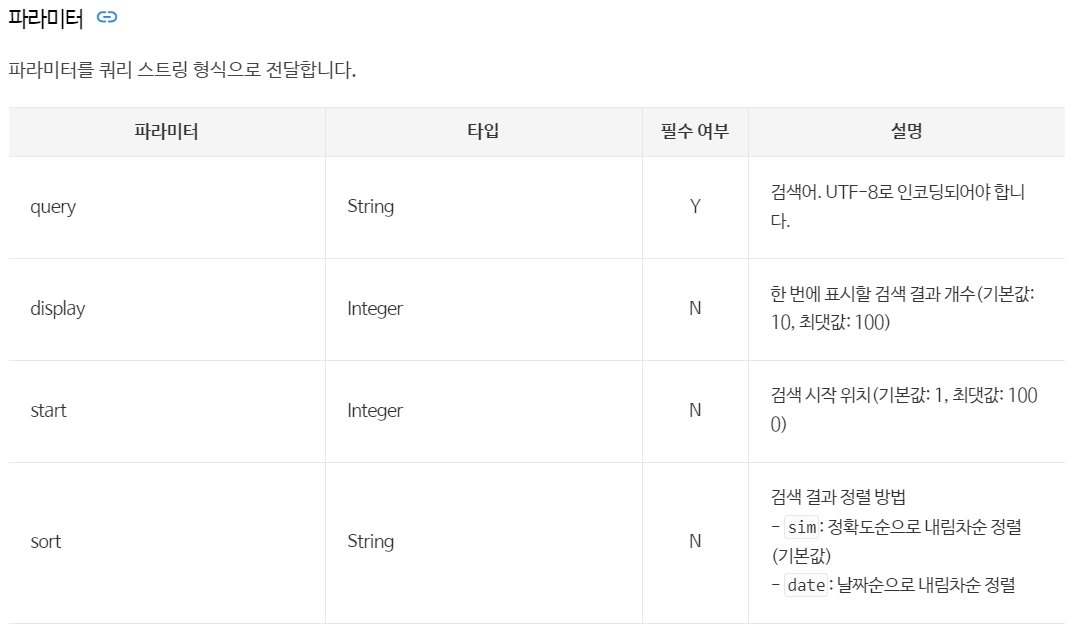

파라미터들을 살펴보면, 한 번에 표시될 수 있는 검색 결과(display) 최대 100개이다.
만약 우리가 1000개의 데이터를 얻고 싶다면, start 파라미터를 이용해줘야한다. 첫 번째 턴에서는 display = 100, start = 1, 두 번째 턴에서는 display = 100, start = 101 이런 형식으로.
"""
encText = urllib.parse.quote("몰스킨")
url = "https://openapi.naver.com/v1/search/shop?query=" + encText # JSON 결과
위 부분을 만들어주는 코드
"""
def get_search_url(api_node, search_text, start_num, disp_num):
"""
api_node : 쇼핑, 블로그, 카페 등 어디에서 검색할 것인지
search_text : 검색어
start_num : 검색 시작 위치
disp_num : 한 번에 표시할 검색 결과 개수
"""
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + ".json"
param_query = "?query=" + urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num)
param_disp = "&disp=" + str(disp_num)
return base + node + param_query + param_start + param_disp# 예시
get_search_url("shop", "TEST", 10,3)💻 출력
'https://openapi.naver.com/v1/search/shop.json?query=TEST&start=10&disp=3'
Step2. get_result_onpage : 페이지에 나타난 검색 결과를 저장해주는 함수
"""
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
위 부분을 만들어주는 코드
"""
import json
import datetime
client_id = "fP155_fIbiINbREJMUiR"
client_secret = "hCFcz0YTay"
def get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
print("[%s] Url Request Success" % datetime.datetime.now())
return json.loads(response.read().decode("utf-8"))지금까지 한 내용을 합쳐서 실행시키면 아래와 같이 출력된다.
※ Step1 + Step2
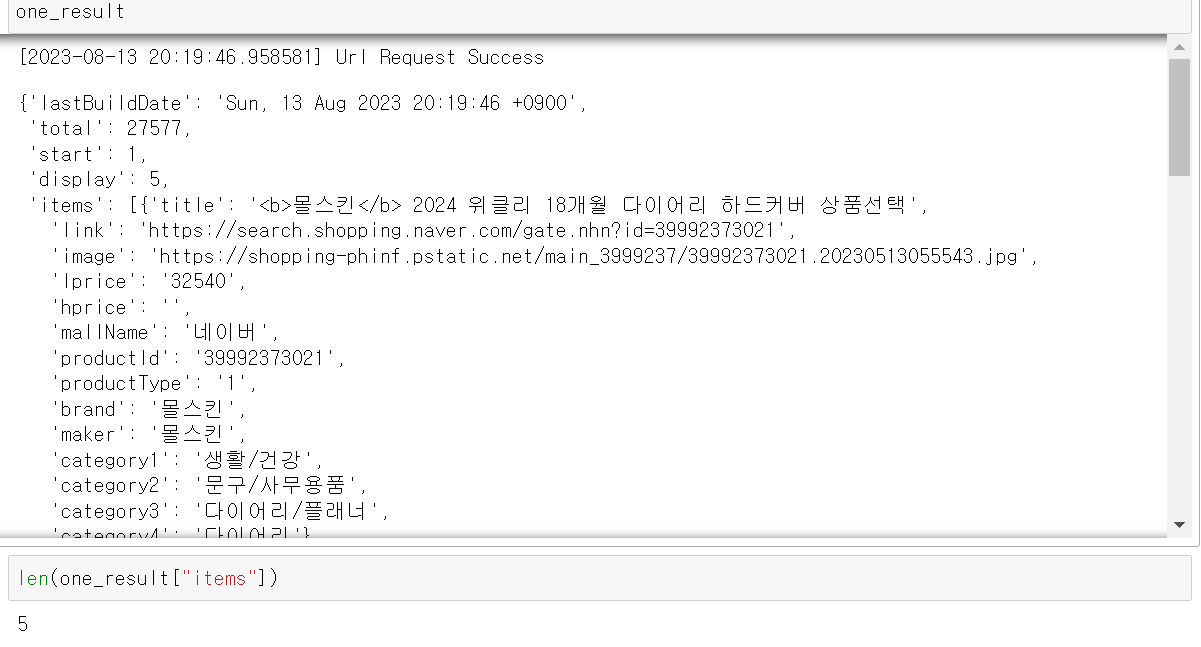
url = get_search_url("shop", "몰스킨", 1,5)
one_result = get_result_onpage(url)
one_result💻 출력
Step3. get_fileds : 검색된 내용을 데이터프레임으로 저장해주는 함수
"""
위 결과를 보고 원하는 정보만 추출하고 데이터프레임으로 저장해주는 작업
one_result["items"][0]["title"] # 제목 출력
one_result["items"][0]["link"] # 링크 출력
one_result["items"][0]["lprice"] # 가격 출력
one_result["items"][0]["mallName"] # 쇼핑몰 이름 출력
"""
import pandas as pd
# <b>태그가 포함되어있음
def delete_tag(input_str):
input_str = input_str.replace("<b>", "")
input_str = input_str.replace("</b>", "")
return input_str
import pandas as pd
def get_fields(json_data):
title = [delete_tag(each["title"]) for each in json_data["items"]]
link = [each["link"] for each in json_data["items"]]
lprice = [each["lprice"] for each in json_data["items"]]
mallName = [each["mallName"] for each in json_data["items"]]
result_pd = pd.DataFrame({
"title" : title,
"link" : link,
"lprice" : lprice,
"mallName" : mallName
}, columns = ["title", "lprice", "link", "mallName"])
return result_pdtitle, lprice, link, mallName결과 추출<b>태그 제거
get_fields(one_result)💻 출력
delete_tag 함수를 적용 안했을때
delete_tag 함수를 적용 했을때
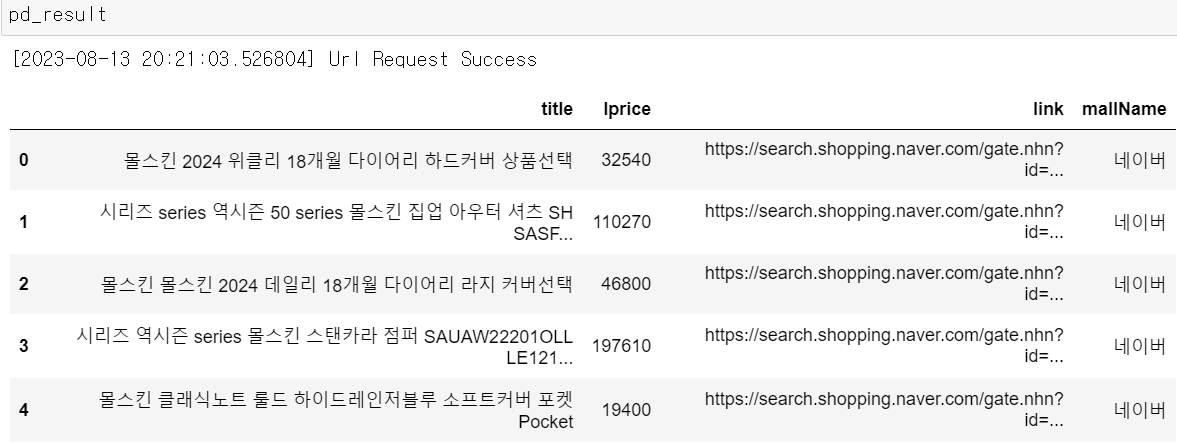
※ Step1 + Step2 + Step3
url = get_search_url("shop", "몰스킨", 1, 5)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)
pd_result💻 출력
Step4. actMain : 앞서 만든 함수들을 실제로 실행시켜 데이터를 수집해주는 함수
"""
"몰스킨"을 검색한 결과 1000개를 얻고자 한다.
검색 한 번당 최대로 수집할 수 있는 결과는 100개로 한정되어있다.(display 파라미터 참고)
그러므로
display = 100, start = 1
display = 100, start = 101
...
display = 100, start = 901
과 같이 진행된다면 1000개의 데이터를 수집할 수 있다.
"""
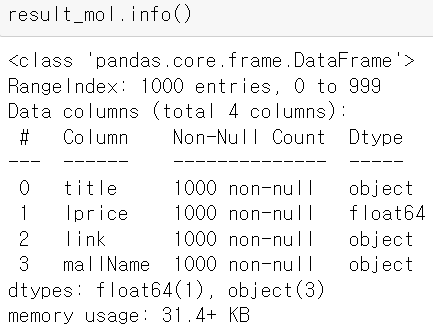
result_mol = []
for n in range(1, 1000, 100):
url = get_search_url("shop", "몰스킨", n, 100)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)
result_mol.append(pd_result)
result_mol = pd.concat(result_mol)
result_mol.reset_index(drop = True, inplace = True) # 인덱스 재설정
result_mol["lprice"] = result_mol["lprice"].astype("float") # 가격은 숫자형 데이터로 변환- 수집된 데이터의 index 번호만 다시 설정
- 가격은 숫자형 데이터로
💻 출력

Step5. toExcel : 최종적으로 엑셀 파일에 저장해주는 함수
- 엑셀 파일로 저장(xlsxwriter를 사용하면 보다 이쁘게(?) 파이썬으로 엑셀 파일을 만들 수 있다.)
# pip install xlsxwriter
변수명 = pd.ExcelWriter("파일 경로/파일명.xlsx", engine = "xlswriter")
데이터프레임명.to_excel(변수명, sheet_name = "시트명")# 엑셀 작업을 파이썬으로 하는 법
writer = pd.ExcelWriter("../data/06_molskin_diary_in_naver_shop.xlsx", engine="xlsxwriter")
result_mol.to_excel(writer, sheet_name="Sheet1")
workbook = writer.book
worksheet = writer.sheets["Sheet1"]
# 행:열 , 간격
worksheet.set_column("A:A", 4)
worksheet.set_column("B:B", 60)
worksheet.set_column("C:C", 10)
worksheet.set_column("D:D", 10)
worksheet.set_column("E:E", 50)
worksheet.set_column("F:F", 10)
worksheet.conditional_format("C2:C1001", {"type": "3_color_scale"})
writer.save()현재 내 컴퓨터에서는 아래와 같이 해당 파일이 있고 파이썬에서 불러와지기도 하는데 파일을 직접 열려고 하면 오른쪽 그림과 같이 팝업창이 뜨면서 해당 파일을 열 수가 없다😵💫
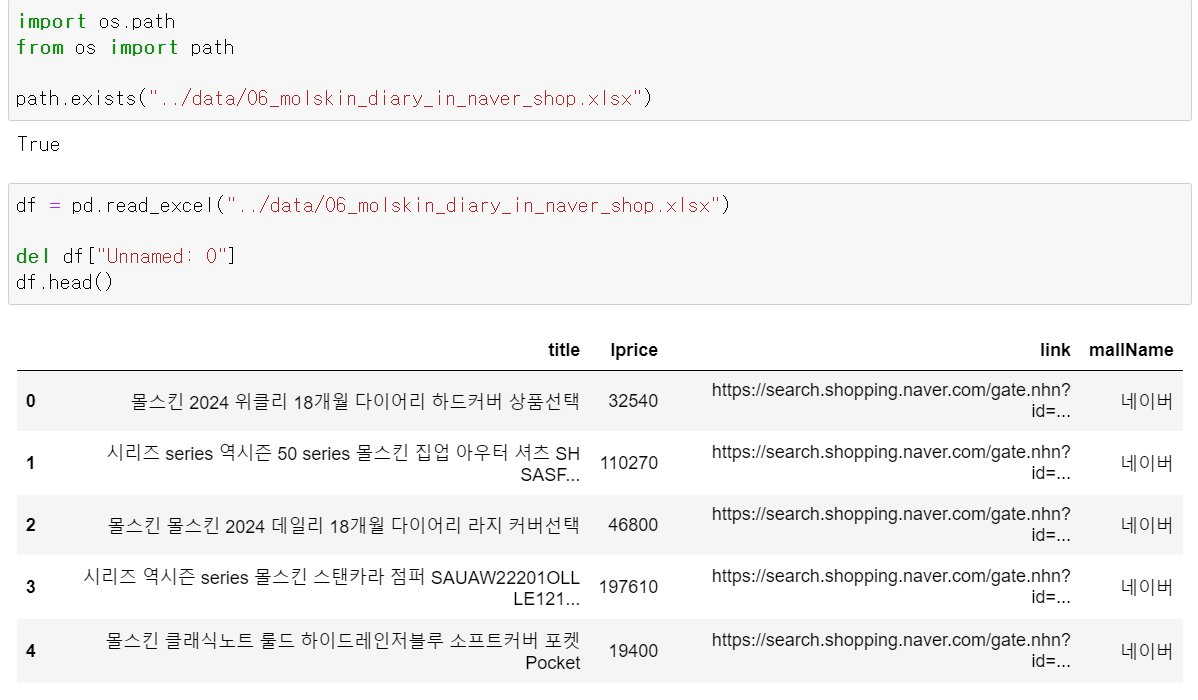 | 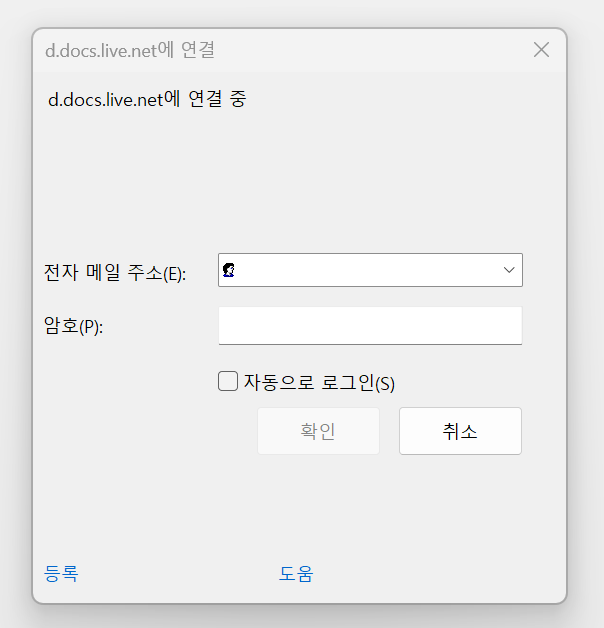 |
|---|
만약 파일이 제대로 열린다면 아래와 같이 가격에 컬러가 더해지고, 간격 값을 준 만큼 칸이 넓어지는 등 이쁜 파일이 만들어진다고 한다! (xlsxwriter는 깊게 파고들면 아주 다양한 파일을 만들어낼 수 있다고 한다)
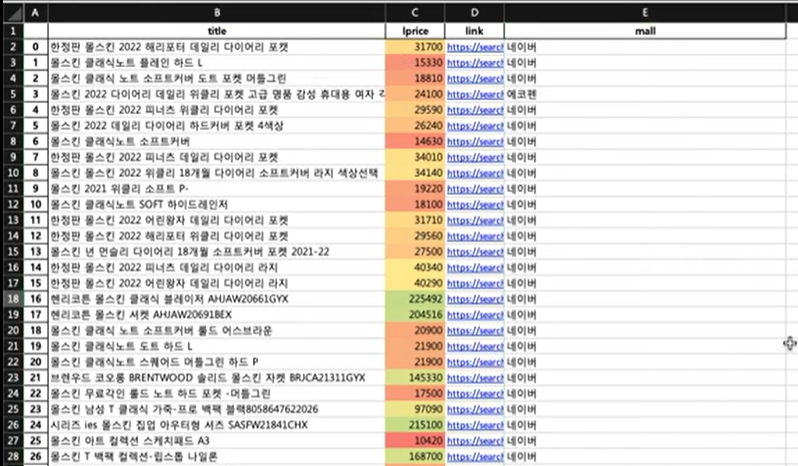
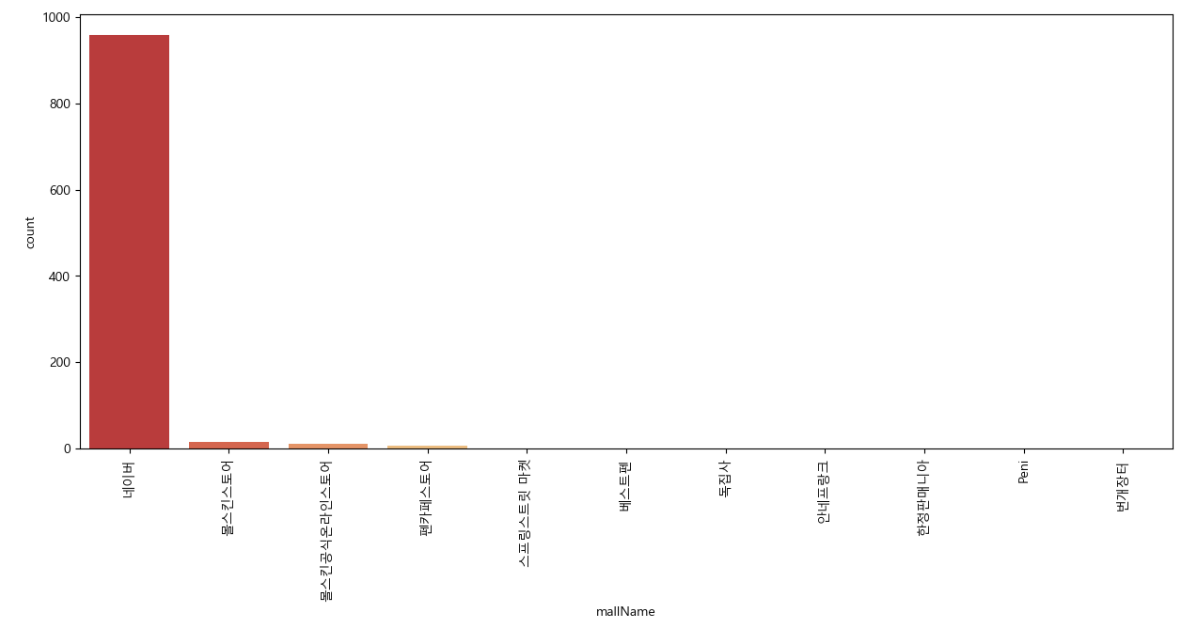
수집한 데이터로 각 쇼핑몰에서 "몰스킨"노트를 얼마나 판매하고 있는지 시각화해보자
plt.figure(figsize = (15,6))
sns.countplot(
x = "mallName",
data = result_mol,
palette = "RdYlGn",
order = result_mol["mallName"].value_counts().index
)
plt.xticks(rotation = 90) # x축의 각 값들을 90도 눕혀서 보여줌
plt.show()💻 출력