
✍🏻 15일 공부 이야기.
👀 오늘 공부한 내용의 자세한 코드는 아래 깃허브에 올라와있습니다!
https://github.com/nabi4442/ZeroBaseDataSchool/blob/main/07.%20Population.ipynb
인구 분석
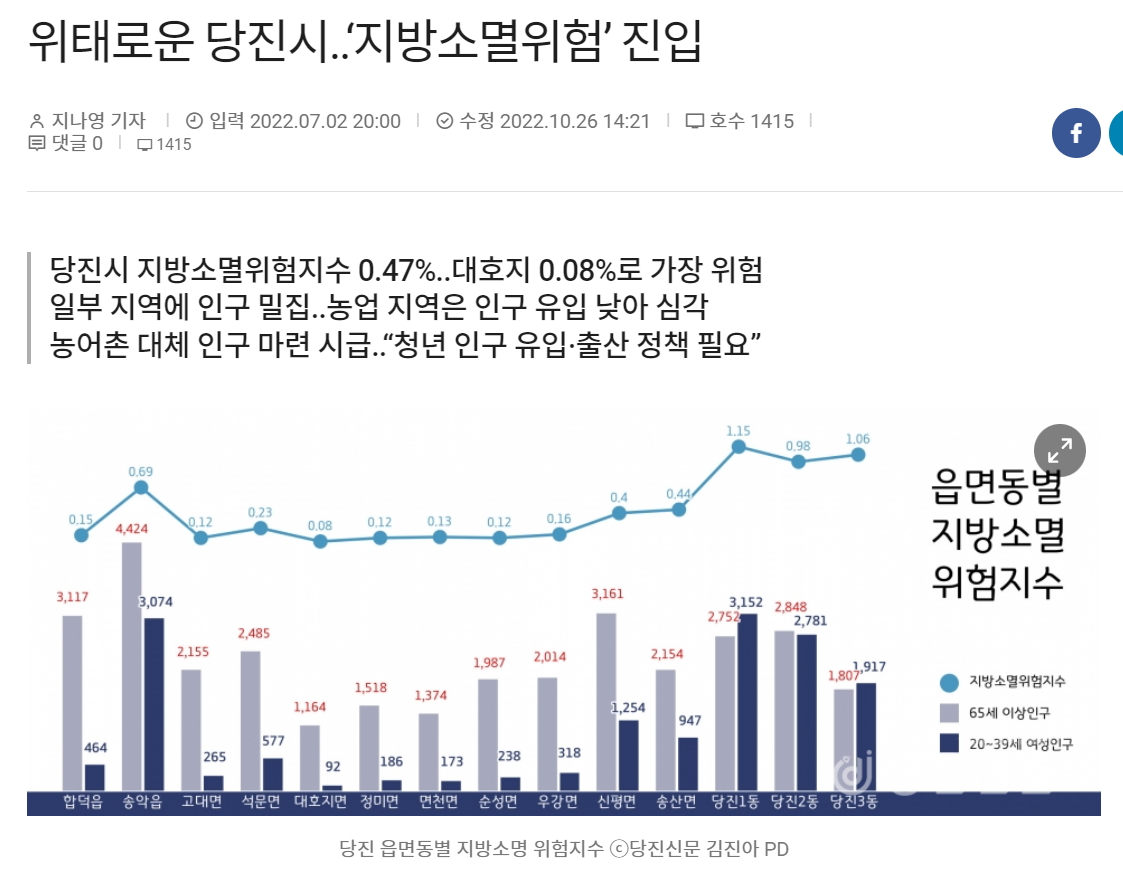
강의에서는 19년도 기사를 인용했지만, 찾아보니 22년도 기사도 있어서 캡쳐해왔다.

인구 소멸 위기 지역은
65세 이상 노인 인구와 20-39세 여성 인구를 비교해 젊은 여성 인구가 노인 인구의 절반에 미달할 경우 "소멸 위험 지역"으로 분류하는 것을 의미한다.
오늘은 인구 소멸 위기 지역을 지도에 시각화해보려 한다.
folium 말고도 카르토그램(카토그램)으로도 시각화해보려 하는데 카르토그램이란 뭘까?
카르토그램
지리적인 위치는 유지하되, 지역의 크기를 인구수에 비례하게 그려놓은 지도이다.
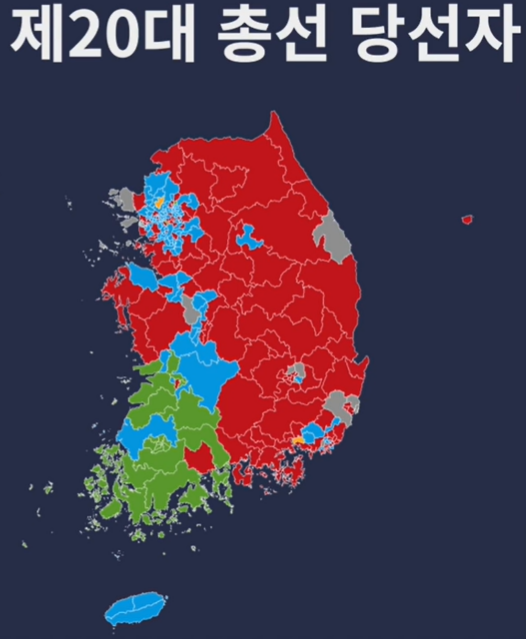 | 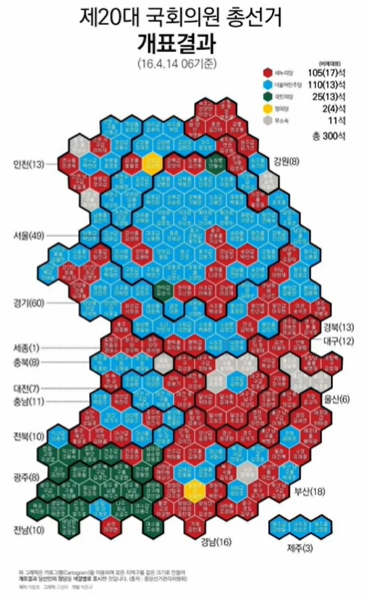 |
|---|
왼쪽 지도만 보면, 빨간색이 우세해보이지만, 실제 각 구별 당선된 당을 보면 오른쪽 그림과 같이 보여진다.
이렇듯 지역 크기에 "인구수"가 영향을 끼치는 경우 사용되는 것이 카르토그램이다.
인구 소멸 위험 지역을 카르토그램으로 표시해볼까?
📌 오늘의 목표
1. 인구 소멸 위기 지역 파악
2. 인구 소멸 위기 지역의 지도 표현
3. 지도 표현에 대한 카르토그램 표현
📄 데이터
- 인구 현황 데이터 : KOSIS 국가 통계 포털
데이터 읽기 및 정리
최근 데이터를 사용해보면 좋았겠지만, 이해하기 힘든 강의 내용이기도 하고 옵션을 어떻게 설정하냐에 따라 어떤 데이터를 다운받는지가 달라진다고 하여 이번에는 강의에서 주어진 데이터로 실습해보기로 했다.
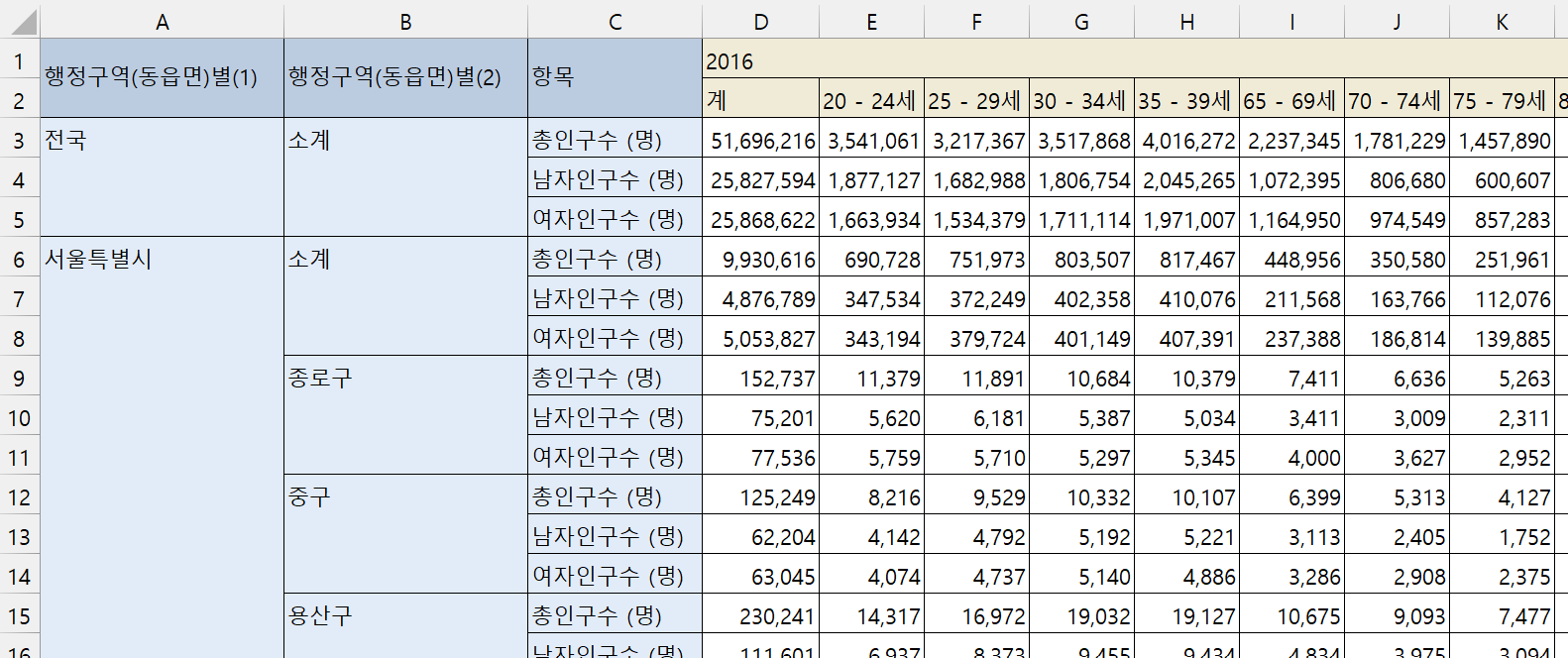
원본 데이터는 위 파일과 같다.
👀 데이터를 읽어보자.
필요없는 1행 컬럼은 날려주고,
A4, A5, B4, B5 칸을 보면 A3의 '전국' 데이터가 A4, A5에, B3의 '소계' 데이터가 B4, B5에 들어가는 것인데 읽어들인 데이터프레임에선 Nan 표시가 되어 나타난다.
그래서 이 Nan값들을 열을 기준으로 이전 값에 있는 데이터로 채워줘야하는 작업이 필요했다.
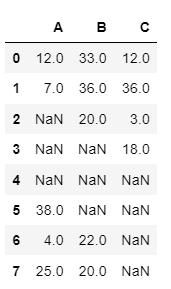 |  |
|---|
이럴 때 사용하는 것이 fillna(method = "pad")이다.
이것을 이용해 데이터프레임을 불러들이면 아래와 같다.
population = pd.read_excel("../data/07_population_raw_data.xlsx", header = 1)
population.fillna(method = "pad", inplace = True) # 행정구역 컬럼들에 nan값을 이전값으로 채워줌
population fillna 하기 전 fillna 하기 전 |  fillna 한 후 fillna 한 후 |
|---|
👀 컬럼명과 데이터명을 알아보기 쉽게 바꿔보자.
컬럼명을 알아보기 쉽게 바꿔줬다.
또한, <시도> 컬럼에 있는 '소계' 데이터는 총합 데이터이므로 구별 데이터가 필요한 우리의 목적과는 상관없는 데이터다. 삭제해주자.
마지막으로 긴 데이터명은 간단하게 바꿔주었다.
# 컬럼 이름 변경
population.rename(
columns = {
"행정구역(동읍면)별(1)" : "광역시도",
"행정구역(동읍면)별(2)" : "시도",
"계" : "인구수"
}, inplace = True
)
# 소계 제거
population = population[population["시도"] != "소계"]
# 항목 컬럼명 변경
population.is_copy = False
population.rename(
columns = {"항목" : "구분"}, inplace = True
)
# 구분 컬럼 내 데이터 명을 쉽게 정리
# 총인구수 (명) -> 합계
# 남자인구수 (명) -> 남자
# 여자인구수 (명) -> 여자
# 행 , 열
population.loc[population["구분"] == "총인구수 (명)", "구분"] = "합계"
population.loc[population["구분"] == "남자인구수 (명)", "구분"] = "남자"
population.loc[population["구분"] == "여자인구수 (명)", "구분"] = "여자"
👀 인구 소멸 지역을 계산하기 위한 컬럼을 생성하고 계산하기 쉽게 데이터프레임을 변형시켜보자.
인구 소멸 지역을 계산하기 위해선, 20-39세 여성 인구수와 65세 이상 노인 인구수가 필요하다.
데이터프레임에서 해당 조건에 맞는 열을 <20-39세>, <65세이상> 컬럼으로 새로 만들어주었다.
그리고 <광역시도>, <시도>를 행으로 하고 <구분>을 열로 하여 <인구수>, <20-39세>, <65세이상> 데이터를 값으로 하는 데이터프레임을 만들어주었다.
# 소멸 지역을 조사하기 위한 데이터 열 생성
# 20-39세 여성 인구, 65세 이상 노인 인구
population["20-39세"] = (
population["20 - 24세"] + population["25 - 29세"] + population["30 - 34세"] + population["35 - 39세"]
)
population["65세이상"] = (
population["65 - 69세"] + population["70 - 74세"] + population["75 - 79세"] + population["80 - 84세"] +
population["85 - 89세"] + population["90 - 94세"] + population["100+"]
)
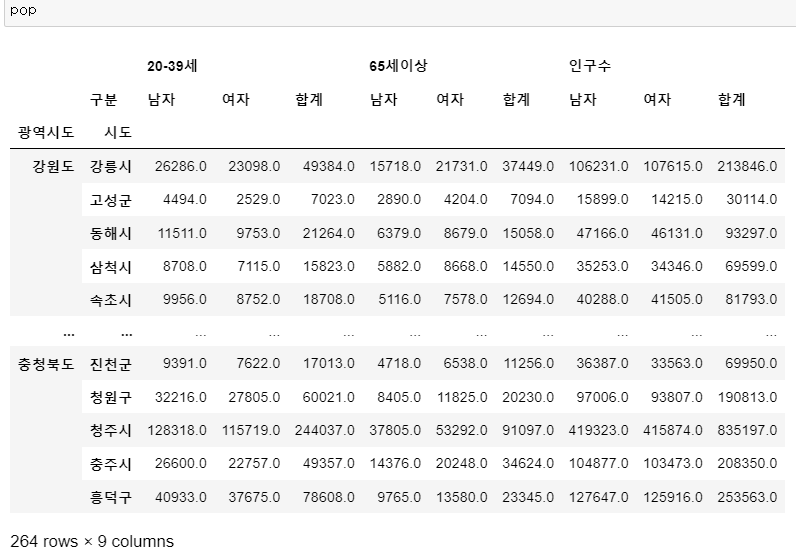
# pivot_table
pop = pd.pivot_table(
data = population,
index = ["광역시도", '시도'],
columns = ["구분"],
values = ["인구수", "20-39세", "65세이상"]
) |  |
|---|
👀 새로 만든 열로 소멸 비율을 계산하고 그 값이 1.0 미만인 경우 <소멸위기지역>으로 분류하는 컬럼을 생성해보자.
# 소멸 비율 계산
# 65세 이상 노인 인구와 20-39세 여성 인구를 비교해
# 젊은 여성 인구가 노인 인구의 절반에 미달할 경우 "소멸 위험 지역"으로 분류
pop["소멸비율"] = pop["20-39세", "여자"] / (pop["65세이상", "합계"] / 2)
# 소멸비율이 1 미만인 경우 소멸위기지역으로 분류
pop["소멸위기지역"] = pop["소멸비율"] < 1.0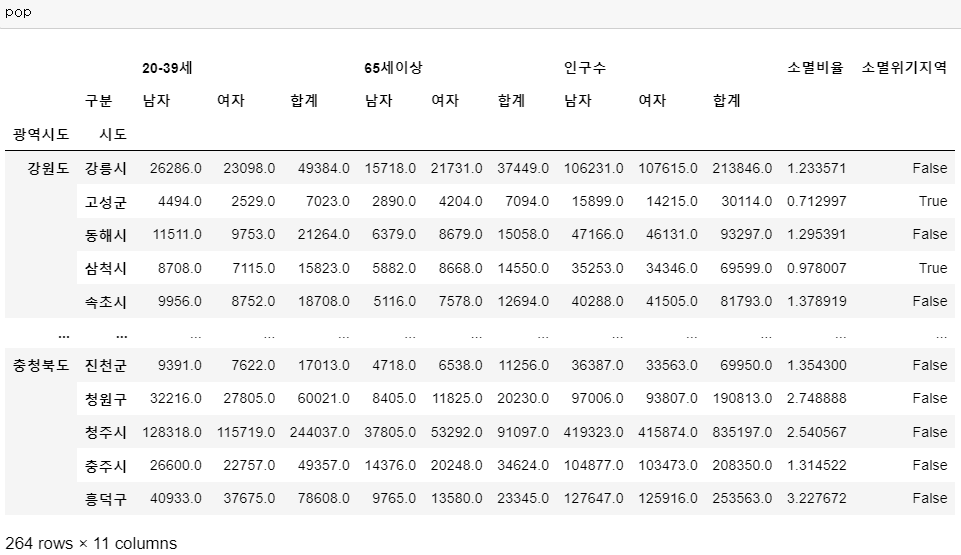
pop.reset_index(inplace = True)
# 멀티 컬럼 정리
tmp_columns = [
pop.columns.get_level_values(0)[n] + pop.columns.get_level_values(1)[n]
for n in range(0, len(pop.columns.get_level_values(0)))
]
pop.columns = tmp_columns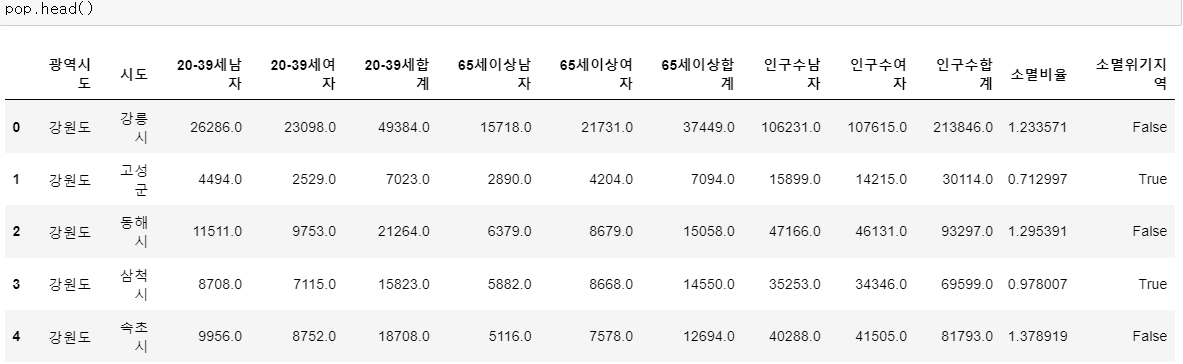
지도 시각화를 위한 지역별 ID 만들기
지도에 시각화하기 위해선 행정구역 경계선 json파일에도 기준점으로 사용할 ID가 필요하고 데이터 파일에도 ID가 필요.
<시도> 컬럼에 있는 값들은 전국의 '구/군/시' 이름이 들어가있다. 이름이 고유하다면, ID로 사용할 수 있겠지만 일부 다른 지역인데 이름이 같은 경우가 있어 원본 데이터를 ID로 사용하기엔 어렵다.
따라서 지역별 ID를 생성해줘야한다.
<광역시도> 컬럼에는 '광역시'와 '도' 이름이 있는데,
'광역시'는 광역시 이름을 넣어준 후 "시도" 컬럼의 '구'이름을 덧붙여줄 것이고
'도'는 도 이름이 아닌 아래 사이트에서 추출한 '시'이름을 붙인 후, '구/군' 이름을 덧붙여주고자 한다.
예시
- 만들고자 하는 ID의 형태
- 서울 중구
- 서울 서초
- 통영
- 남양주
- 포항 북구
- 인천 남동
- 안양 만안
- 안양 동안
- 안산 단원
...
<대한민국 구 목록> 자료를 기준으로 '구'를 가지고 있는 '시' 이름을 추출했다.
👀 지역별 ID를 넣을 변수를 만들자.
# 지역별 ID를 넣을 값
si_name = [None] * len(pop)👀 먼저, 일반 시 이름과 세종시, 광역시도 일반 구를 정리해보자.
예시
광역시도 시도 ID 경기도 의정부 의정부 세종특별자치시 세종특별자치시 세종 서울특별시 중구 서울 중구 서울특별시 용산구 서울 용산
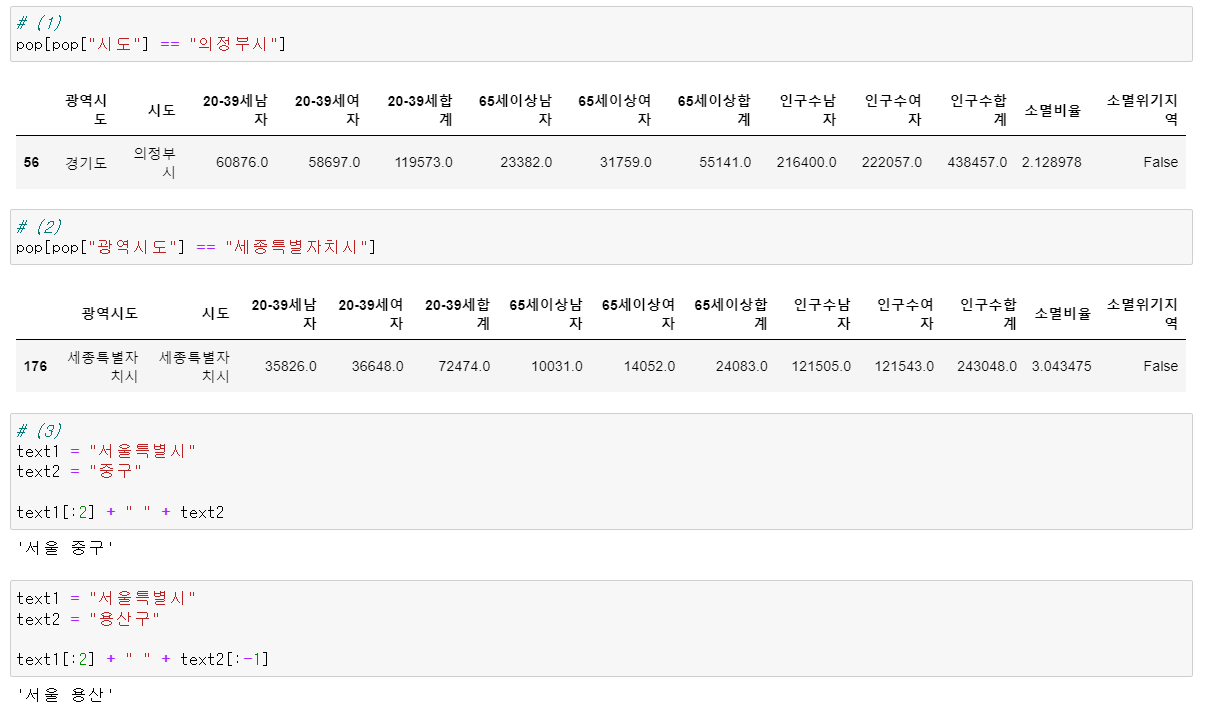
위의 테스트 코드를 아래와 같이 모든 데이터에 적용될 수 있도록 변환해주었다.
for idx, row in pop.iterrows():
# (1) 광역시도 데이터의 마지막 세글자가 "광역시", "특별시", "자치시" 가 아닌 경우
if row["광역시도"][-3:] not in ["광역시", "특별시", "자치시"]:
# 시도 컬럼의 마지막 글자만 빼고 넣어줘라
# 의정부
si_name[idx] = row["시도"][:-1]
# (2) "세종특별자치시" -> "세종"
elif row["광역시도"] == "세종특별자치시":
si_name[idx] = "세종"
# (3) 광역시도 데이터의 마지막 세글자가 "광역시", "특별시", "자치시"인 경우
else:
# 중구
if len(row["시도"]) == 2:
# 서울 중구
si_name[idx] = row["광역시도"][:2] + " " + row["시도"]
# 용산구
else:
# 서울 용산
si_name[idx] = row["광역시도"][:2] + " " + row["시도"][:-1]
👀 두번째로, <대한민국 구 목록> 자료를 기준으로 정리한 '구'를 가지고 있는 '시'를 정리해보자.
tmp_gu_dict = {
"수원": ["장안구", "권선구", "팔달구", "영통구"],
"성남": ["수정구", "중원구", "분당구"],
"안양": ["만안구", "동안구"],
"안산": ["상록구", "단원구"],
"고양": ["덕양구", "일산동구", "일산서구"],
"용인": ["처인구", "기흥구", "수지구"],
"청주": ["상당구", "서원구", "흥덕구", "청원구"],
"천안": ["동남구", "서북구"],
"전주": ["완산구", "덕진구"],
"포항": ["남구", "북구"],
"창원": ["의창구", "성산구", "진해구", "마산합포구", "마산회원구"],
"부천": ["오정구", "원미구", "소사구"],
}예시
광역시도 시도 ID 경상북도 남구 포항 남구 경상남도 마산합포구 창원 합포 경기도 장안구 수원 장안
for idx, row in pop.iterrows():
# 광역시도 데이터의 마지막 세글자가 "광역시", "특별시", "자치시" 가 아닌 경우
if row["광역시도"][-3:] not in ["광역시", "특별시", "자치시"]:
for keys, values in tmp_gu_dict.items():
# row["시도"] 가 tmp_gu_dict 의 value 값에 있다면
if row["시도"] in values: # 예) (1)남구 , (2)마산합포구 , (3)장안구
# (1) row["시도"] 의 길이가 2인 경우는
# 남구 -> 포항 남구
if len(row["시도"]) == 2:
# 시 이름 + 시도 이름을 붙여줘라.
si_name[idx] = keys + " " + row["시도"]
# (2) row["시도"]가 "마산합포구", "마산회원구"인 경우는
# 마산합포구 -> 창원 합포
elif row["시도"] in ["마산합포구", "마산회원구"]:
# 시 이름 + ('합포', '회원')을 붙여줘라.
si_name[idx] = keys + " " + row["시도"][2:-1]
# (3) 나머지 경우는
# 장안구 -> 수원 장안
else:
# 시 이름 + '구'를 뺀 시도 이름을 붙여줘라.
si_name[idx] = keys + " " + row["시도"][:-1]👀 '고성군' 데이터는 고성(강원), 고성(경남) 으로 정리해보자.
# 고성군에 대하여 한번 더 정리
for idx, row in pop.iterrows():
if row["광역시도"][-3:] not in ["광역시", "특별시", "자치시"]:
# row["시도"]의 끝자리가 '고성' 이며 row["광역시도"] 가 '강원도'인 경우
if row["시도"][:-1] == "고성" and row["광역시도"] == "강원도":
si_name[idx] = "고성(강원)"
# row["시도"]의 끝자리가 '고성' 이며 row["광역시도"] 가 '경상남도'인 경우
elif row["시도"][:-1] == "고성" and row["광역시도"] == "경상남도":
si_name[idx] = "고성(경남)"👀 si_name을 데이터프레임에 붙여주고 필요한 데이터만 남겨보자.
# ID를 데이터프레임에 넣어주기
pop["ID"] = si_name
# 필요한 데이터만 남기기
del pop["20-39세남자"]
del pop["65세이상남자"]
del pop["65세이상여자"]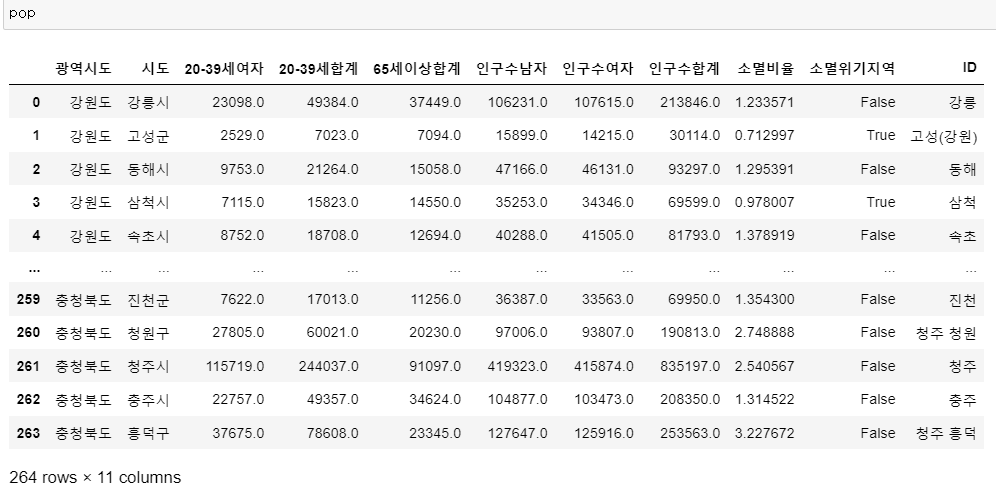
카르토그램 그리기
먼저, 지도가 되어줄 밑바탕이 필요하다.
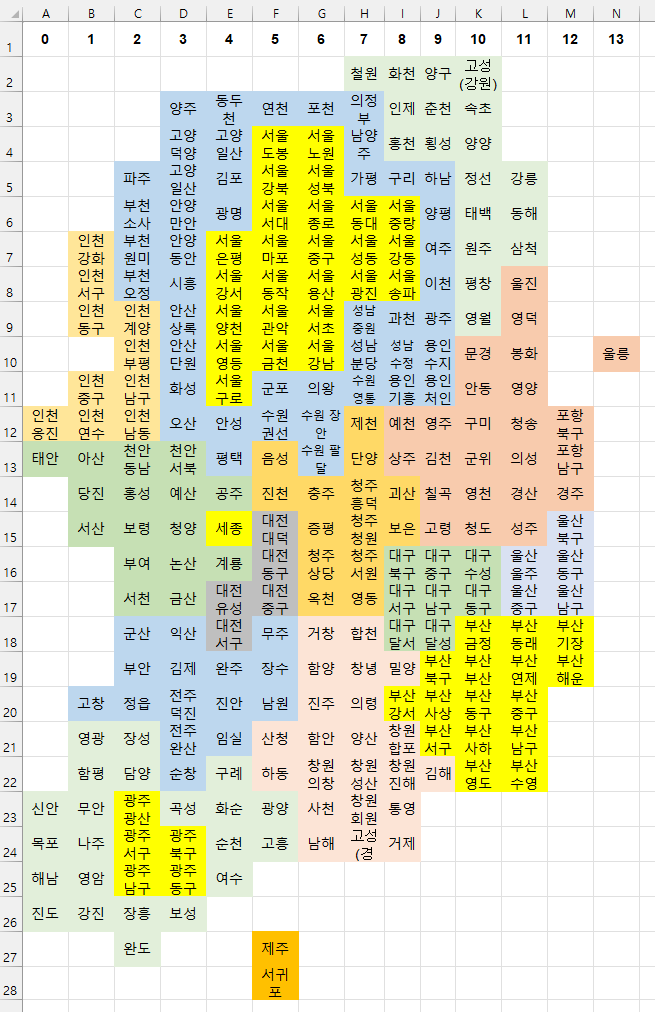
💡 엑셀로 그린 지도를 파이썬에서 불러와 밑바탕으로 쓰려고 한다!
👀 지도가 그려진 엑셀 파일을 불러와보자.
# 대한민국 지도를 그린 엑셀 파일
draw_korea_raw = pd.read_excel("../data/07_draw_korea_raw.xlsx")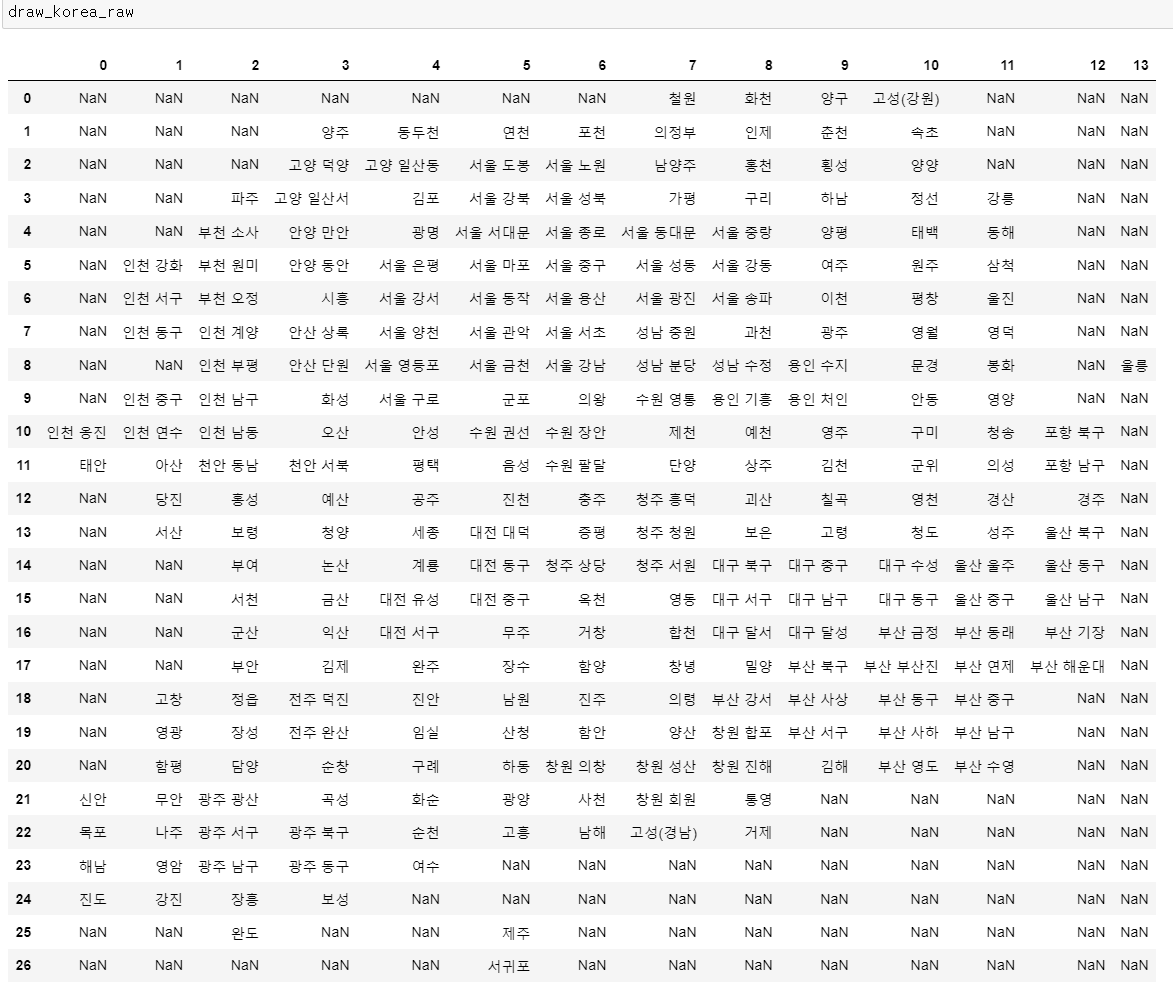
👀 각 지역 이름의 좌표값을 추출해보고, 각 행정구의 경계선을 추출해보자.
draw_korea_raw_stacked = pd.DataFrame(draw_korea_raw.stack())
# stack() : 각 데이터의 좌표를 구할 수 있음
draw_korea_raw_stacked.reset_index(inplace = True)
# 컬럼명 변경
draw_korea_raw_stacked.rename(
columns = {
"level_0" : "y",
"level_1" : "x",
0 : "ID"
}, inplace = True
)
draw_korea = draw_korea_raw_stacked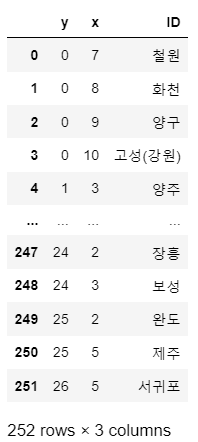
# 각 행정구의 경계선 추출
BORDER_LINES = [
[(5, 1), (5, 2), (7, 2), (7, 3), (11, 3), (11, 0)], # 인천
[(5, 4), (5, 5), (2, 5), (2, 7), (4, 7), (4, 9), (7, 9), (7, 7), (9, 7), (9, 5), (10, 5), (10, 4), (5, 4)], # 서울
[(1, 7), (1, 8), (3, 8), (3, 10), (10, 10), (10, 7), (12, 7), (12, 6), (11, 6), (11, 5), (12, 5), (12, 4), (11, 4), (11, 3)], # 경기도
[(8, 10), (8, 11), (6, 11), (6, 12)], # 강원도
[(12, 5), (13, 5), (13, 4), (14, 4), (14, 5), (15, 5), (15, 4), (16, 4), (16, 2)], # 충청북도
[(16, 4), (17, 4), (17, 5), (16, 5), (16, 6), (19, 6), (19, 5), (20, 5), (20, 4), (21, 4), (21, 3), (19, 3), (19, 1)], # 전라북도
[(13, 5), (13, 6), (16, 6)],
[(13, 5), (14, 5)], # 대전시 # 세종시
[(21, 2), (21, 3), (22, 3), (22, 4), (24, 4), (24, 2), (21, 2)], # 광주
[(20, 5), (21, 5), (21, 6), (23, 6)], # 전라남도
[(10, 8), (12, 8), (12, 9), (14, 9), (14, 8), (16, 8), (16, 6)], # 충청북도
[(14, 9), (14, 11), (14, 12), (13, 12), (13, 13)], # 경상북도
[(15, 8), (17, 8), (17, 10), (16, 10), (16, 11), (14, 11)], # 대구
[(17, 9), (18, 9), (18, 8), (19, 8), (19, 9), (20, 9), (20, 10), (21, 10)], # 부산
[(16, 11), (16, 13)],
[(27, 5), (27, 6), (25, 6)]
]
처음부터 모든 내용을 짜기엔 어렵다. 먼저 테스트로 엑셀로 그린 내용과 그 안의 지역 이름을 matplotlib으로도 그려지는지 확인해보자.
👀 원본 엑셀 파일 지도 이름 형태로 데이터프레임 지도 이름 형태를 맞춰주는 함수를 만들어보고 이를 그리는 함수를 만들어보자.
예시
->


위 테스트 코드를 참고하여 아래와 같이 함수를 만들어주었다.
# 원본 엑셀 파일 지도 이름 형태와 데이터프레임 지도 이름 형태를 맞춰주는 함수
"""
현재 데이터프레임을 보면 "고양 덕양"와 같이 원본 엑셀 파일에서는
고양
덕양
과 같이 긴 문자열들은 한 줄 내려간 형태로 이름이 표시되었다.
"""
def plot_text_simple(draw_korea):
# dispname : 지도에 표시할 내용
for idx, row in draw_korea.iterrows():
'''
Step1. 들어갈 내용 정리
'''
# 공백을 기준으로 나누었을 때 문자열이 2개라면
if len(row["ID"].split()) == 2:
# 고양
# 덕양
# 과 같이 한 줄 내려줘라. # (1) 참고
dispname = "{}\n{}".format(row["ID"].split()[0], row["ID"].split()[1])
# 고성(강원), 고성(경남)은 "고성"으로 표시
# 왜냐하면 지도로 보는 고성은 강원인지 경남인지 구분 가능하니깐!
elif row["ID"][:2] == "고성":
dispname = "고성"
# 나머지 지역 이름은 그대로 표시
else:
dispname = row["ID"]
'''
Step2. 폰트 크기 및 간격 조절
'''
# (2) 참고
if len(dispname.splitlines()[-1]) >= 3: # 길이가 3 이상(서귀포)이라면
fontsize, linespacing = 9.5, 1.5 # 폰트를 작게
else:
fontsize, linespacing = 11, 1.2
'''
Step3. 지도에 직접 표시
Signature:
plt.annotate(
text,
xy,
)
Docstring:
Annotate the point *xy* with text *text*.
matplotlib에서 주석을 이용하면 글씨를 쓸 수 있음!
'''
plt.annotate(
dispname,
(row["x"] + 0.5 , row["y"] + 0.5),
weight = "bold",
fontsize = fontsize,
linespacing = linespacing,
ha = "center", # 수평 정렬
va = "center" # 수직 정렬
)각 행정구역별 경계선(BORDER_LINES)을 그리고 그 위에 지역 이름을 적어주는 함수는 아래와 같다.
def simpleDraw(draw_korea):
plt.figure(figsize = (8,11))
plot_text_simple(draw_korea)
for path in BORDER_LINES:
ys, xs = zip(*path) # 리스트 안에 리스트를 기준으로 y좌표를 한 곳에, x좌표를 한 곳에 모아둠
plt.plot(xs , ys, c = "black", lw = 1.5)
# y좌표를 위에서 아래로 내려가게 해줌
'''
보통 그래프는 아래에서 위로 올라간다.
하지만 좌표를 그릴 때 위에서 아래로 내려가는 형태로 그렸으므로
y축을 뒤집어주는 해당 작업을 해줘야한다.
안 해주면.. 서귀포가 북쪽에 있는 형태가 나옴
'''
plt.gca().invert_yaxis()
plt.axis("off") # 모든 축과 라벨을 제거하는 기능
plt.tight_layout() # 그래프 요소들 간에 겹치지 않게끔 간격을 주는 기능
plt.show()
👀 이제 인구현황 데이터(pop)와 지도 데이터(draw_korea)를 합쳐주기 전, 각 ID가 정확하게 일치한지 검증해보자.
# 지도에서 이미 pop 데이터프레임의 ID 이름에 맞게 지역명을 작성해뒀으므로
# 차집합이 없어야 정상!
set(draw_korea["ID"].unique()) - set(pop["ID"].unique())💻 출력
set()
# 반대로도 해보자.
set(pop["ID"].unique()) - set(draw_korea["ID"].unique())💻 출력
{'고양', '부천', '성남', '수원', '안산', '안양', '용인', '전주', '창원', '천안', '청주', '포항'}
살펴보니 pop 데이터프레임에는 아래와 같이 전체 데이터가 포함된 데이터들이 남아있었다. 생각해보니 🖱️ 앞서 tmp_gu_dict로 고쳐주었던 '시'들이 남아있었다. 원본 데이터를 살펴보니 다른 지역은 '소계'를 지워서 없었던 데이터였는데 tmp_gu_dict의 '시'들은 아래와 같이 데이터 자체에 'ㅇㅇ시'로 전체 데이터가 있었다.
 | 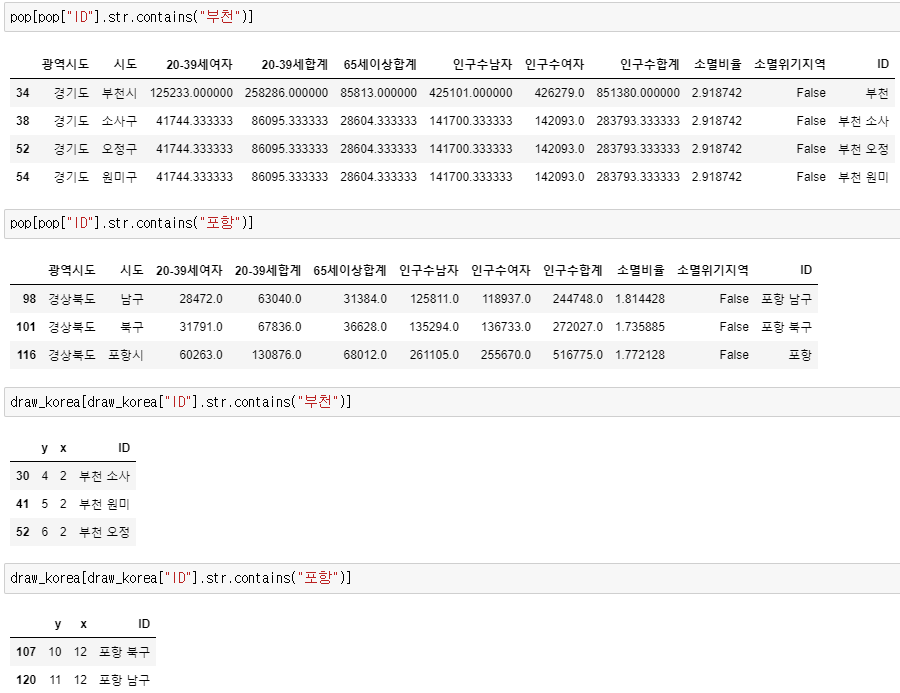 |
|---|
우리가 필요한건 각 구별 데이터이기 때문에 전체 데이터는 없어도 되므로 삭제해주자!
tmp_list = list(set(pop["ID"].unique()) - set(draw_korea["ID"].unique()))
for tmp in tmp_list:
pop = pop.drop(pop[pop["ID"] == tmp].index)
print(set(pop["ID"].unique()) - set(draw_korea["ID"].unique())) #깔끔하게 지워졌다!💻 출력
set()
👀 지도를 이제 그려보자! 인구 현황 데이터프레임과 지도 데이터프레임을 ID 기준으로 합쳐주자.
pop = pd.merge(pop, draw_korea, how = "left", on = "ID") # 왼쪽 데이터프레임(pop)을 기준으로 ID를 통해 합쳐주자.
pop.head() # x좌표와 y좌표가 잘 붙었다:)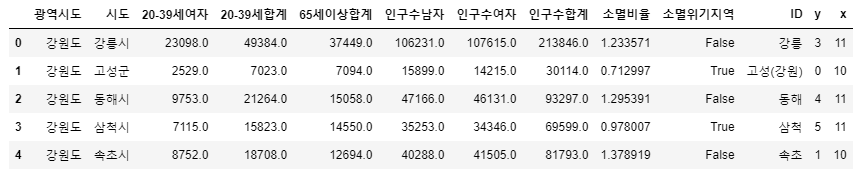
지금부터는 그림을 그리기 위한 데이터를 계산하는 함수를 만들고자 한다. 코드만 보고 이해하기엔 벅찬(?) 감이 있어서 결과물을 몇가지 보고 보면서 설명하도록 하겠다.
- 색상을 만들 때, 최소값은 흰색으로 함.
- blockedMap : 인구 현황(pop)
- targetData : 그리고 싶은 컬럼
👀 각 배경에 맞춰 글씨 색상을 바꿔주는 함수를 만들어보자.
예시
위 사진과 같이 배경이 어두워지는 지역들은 흰색 글씨로, 배경이 밝은 지역들은 검은색 글씨로 출력되게 하는 함수를 만들어보자.

# 계산된 데이터에 따라 배경 색상이 달라지는데
# 각 배경 맞춰 글씨 색상을 바꿔줌
def get_data_info(targetData, blockedMap):
# 글씨를 흰색으로 바꿔서 표시할 경계값
# 색깔이 진한 배경에는 흰색 글씨를, 색깔이 연한 배경에는 검은색 글씨를 넣어줌
whitelabelmin = (
max(blockedMap[targetData]) - min(blockedMap[targetData])
) * 0.25 + min(blockedMap[targetData])
vmin = min(blockedMap[targetData])
vmax = max(blockedMap[targetData])
# 지역 이름이 그려진 지도에 지역 이름 대신, 각 데이터(숫자)가 들어가게 함
mapdata = blockedMap.pivot_table(index="y", columns="x", values=targetData)
return mapdata, vmax, vmin, whitelabelmin👀 그리고 싶은 데이터의 범위가 <음수 ~ 양수> 값 사이인 경우 0을 중앙값으로 맞춰주는 함수를 만들어주자.
예시
그리고 싶은 데이터의 절댓값 중 최대값을 +/- 부호를 씌워서 컬러바의 최소값, 최대값으로 만들어주자.
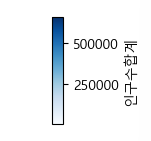
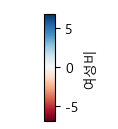
# 계산된 데이터가 <음수 ~ 0 ~ 양수> 값 사이로 나온 경우
# 계산된 값 중 0을 센터로 맞춰주는 함수
def get_data_info_for_zero_center(targetData, blockedMap):
whitelabelmin = 5
tmp_max = max(
[np.abs(min(blockedMap[targetData])), np.abs(max(blockedMap[targetData]))]
)
vmin, vmax = -tmp_max, tmp_max
mapdata = blockedMap.pivot_table(index="y", columns="x", values=targetData)
return mapdata, vmax, vmin, whitelabelmin👀 앞서 만든 plot_text_simple 함수의 실제 버전을 만들어보자.
def plot_text(targetData, blockedMap, whitelabelmin):
for idx, row in blockedMap.iterrows():
if len(row["ID"].split()) == 2:
dispname = "{}\n{}".format(row["ID"].split()[0], row["ID"].split()[1])
elif row["ID"][:2] == "고성":
dispname = "고성"
else:
dispname = row["ID"]
if len(dispname.splitlines()[-1]) >= 3:
fontsize, linespacing = 9.5, 1.5
else:
fontsize, linespacing = 11, 1.2
# 색깔 지정
# whitelabelmin보다 크면 흰색 글씨, 작으면 검정색 글씨
annocolor = "white" if np.abs(row[targetData]) > whitelabelmin else "black"
plt.annotate(
dispname,
(row["x"] + 0.5, row["y"] + 0.5),
weight="bold",
color=annocolor,# 색깔 지정
fontsize=fontsize,
linespacing=linespacing,
ha="center",
va="center",
)추가된 것은 폰트 색상 밖에 없다!
👀 앞서 만든 simpleDraw 함수의 실제 버전을 만들어보자.
def drawKorea(targetData, blockedMap, cmapname, zeroCenter=False):
# 0을 중앙값으로 맞출건지에 따른 함수 적용
if zeroCenter:
masked_mapdata, vmax, vmin, whitelabelmin = get_data_info_for_zero_center(targetData, blockedMap)
if not zeroCenter:
masked_mapdata, vmax, vmin, whitelabelmin = get_data_info(targetData, blockedMap)
plt.figure(figsize=(8, 11))
# 지도에 배경 색상 그려주기 가장자리 색상(회색)
plt.pcolor(masked_mapdata, vmin=vmin, vmax=vmax, cmap=cmapname, edgecolor="#aaaaaa", linewidth=0.5)
# 지도에 지역 이름 써주기
plot_text(targetData, blockedMap, whitelabelmin)
for path in BORDER_LINES:
ys, xs = zip(*path)
plt.plot(xs, ys, c="black", lw=1.5)
plt.gca().invert_yaxis()
plt.axis("off")
plt.tight_layout()
cb = plt.colorbar(shrink=0.1, aspect=10) # 컬러바 추가
cb.set_label(targetData) # 컬러바 추가
plt.show()그리고 싶은 데이터의 중앙값을 0으로 설정할 것인지 아닌지에 따른 데이터, 최소값, 최대값, 흰색 글씨가 될 기준값을 정해주고
지도에 배경 색상 그려주기, 지역 이름 써주기를 추가했다!
👀 '인구수합계'에 따른 지도 시각화
drawKorea("인구수합계", pop, "Blues")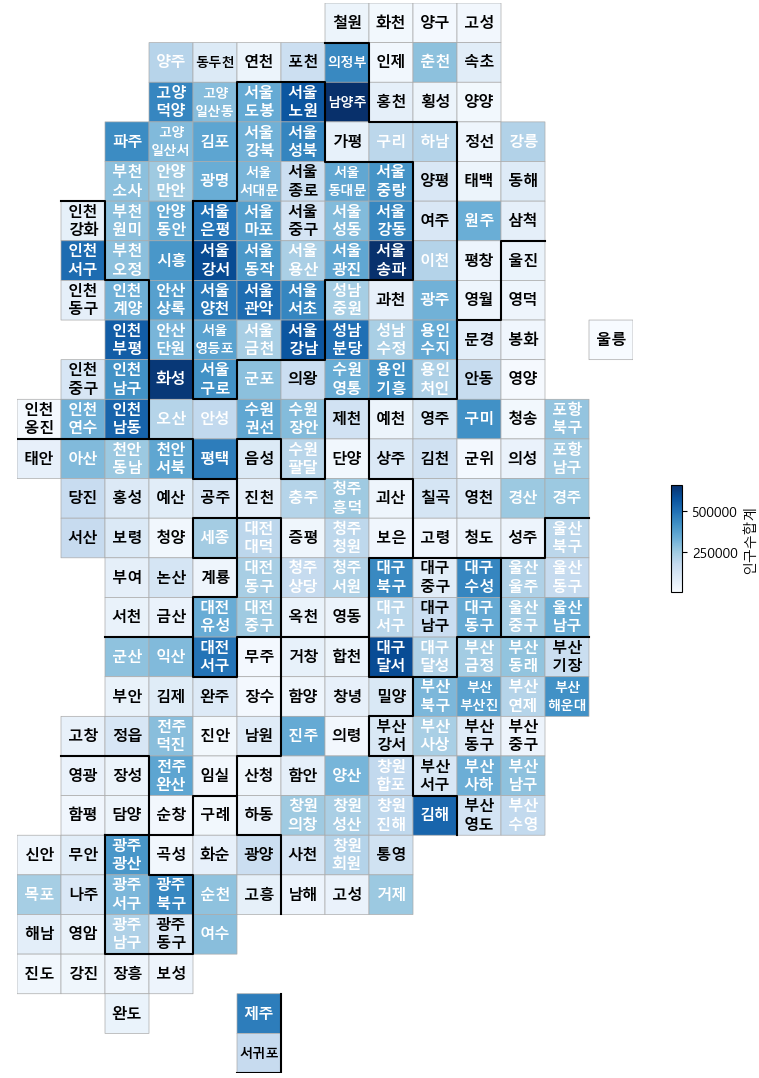
: 수도권에 인구수가 몰려있는 것을 확인할 수 있었다.
👀 '소멸위기지역'에 따른 지도 시각화
pop["소멸위기지역"] = [1 if con else 0 for con in pop["소멸위기지역"]] #True : 1 , False : 0으로 바꿔줌
drawKorea("소멸위기지역", pop, "Reds")
: 소멸위기 지역이 꽤 있어보인다..!
👀 '여성비'에 따른 지도 시각화
pop["여성비"] = (pop["인구수여자"] / pop["인구수합계"] - 0.5) * 100
drawKorea("여성비" , pop, "RdBu", zeroCenter = True)
: 붉은 부분은 여성이 적고, 푸른 부분이 여성이 많은 것인데 진한 파란색이 없는 것으로 보아 전국적으로 여성이 많은 지역은 별로 없어보인다!
👀 '2030여성비'에 따른 지도 시각화
pop["2030여성비"] = (pop["20-39세여자"] / pop["20-39세합계"] - 0.5) * 100
drawKorea("2030여성비" , pop, "RdBu", zeroCenter = True)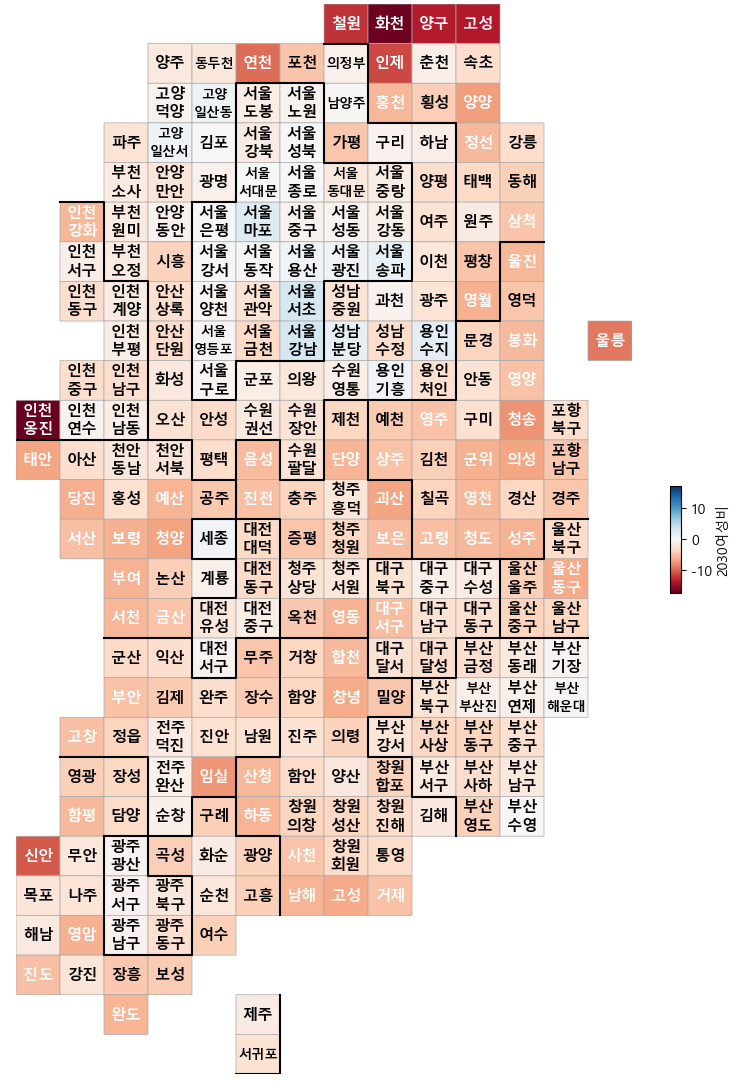
: 대부분 붉은색이다...! 2030의 여성들이 별로 없는 것 같다.
folium
import folium
import json
geo_path = "../data/07_skorea_municipalities_geo_simple.json"
geo_str = json.load(open(geo_path, encoding = "utf-8"))
pop_folium = pop.set_index("ID")
pop_folium.head()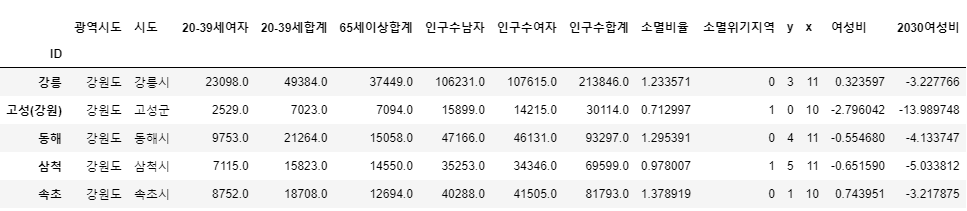
👀 '인구수합계'에 따른 지도 시각화
# 인구수 합계 시각화
mymap = folium.Map(location = [36.2002,127.054], zoom_start = 7)
mymap.choropleth(
geo_data = geo_str,
data = pop_folium["인구수합계"],
key_on = "feature.id",
columns = [pop_folium.index, pop_folium["인구수합계"]],
fill_color = "YlGnBu"
)
mymap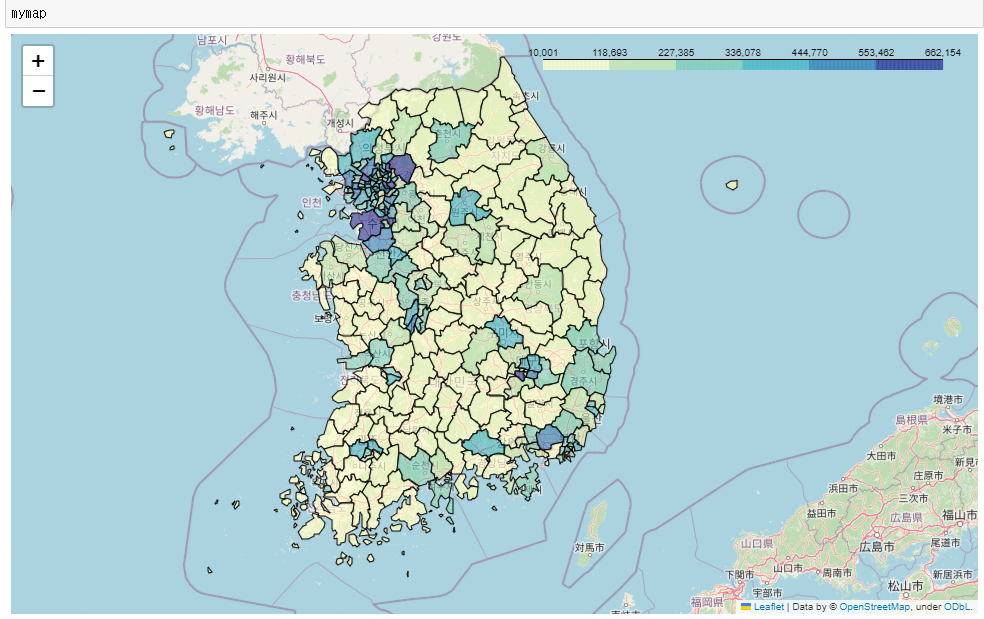
👀 '소멸 위기 지역'에 따른 지도 시각화
# 소멸 위기 지역 시각화
mymap = folium.Map(location = [36.2002,127.054], zoom_start = 7)
mymap.choropleth(
geo_data = geo_str,
data = pop_folium["소멸위기지역"],
key_on = "feature.id",
columns = [pop_folium.index, pop_folium["소멸위기지역"]],
fill_color = "PuRd"
)
mymap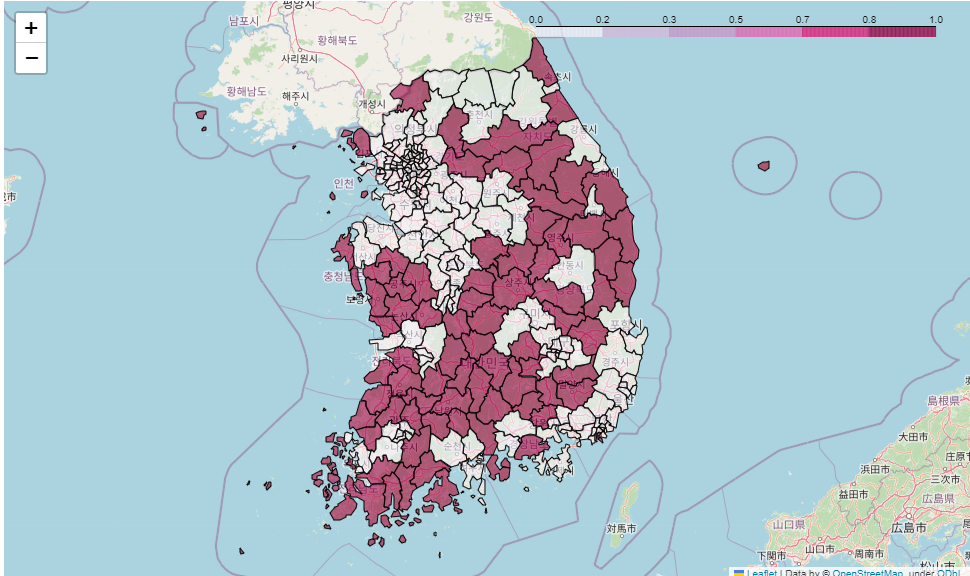
: 확실히 카르토그램으로 봤을 때 보다 소멸위기지역의 크기가 넓어보인다.
