✍🏻 8일 공부 이야기.
개요 및 기초
특징
- 자연어 데이터의 특징
- 문장을 구성하고 있는 단어들의 위치가 변해서는 안됨
- 단어들 간의 관계가 중요하고 하나의 단어만 바뀌거나 추가되어도 전혀 다른 의미를 가질 수 있음
Bert는 특히 자연어 데이터에 특화죈 데이터프레임 워크
- GPT를 구성하고 있는 모델은
Transformer에서 가져온 것이므로Transformer의 구성 모듈에 대해 자세히 배울 예정
-
자연어 데이터의 토큰화
🤔 어떻게 쪼갤 것인가?
문자별로? 공백 별로? 구두점(' / ! 등) 별로?일단 최소한의 의미가 있는 것 별로 쪼개야한다는 생각해볼 수 있을 것이다. 그 관점에서 보면
-
문자 별(Character) : 문장의 시계열 길이가 너무 늘어나고, 각각의 문자는 의미를 가지고 있지 않으므로 결국 단어로 표현을 해야한다는 단점이 있음
-
단어 별(Word) : 경우의 수가 너무 많으며 특히 사전에 없는 단어(이모티콘, 신조어 등)가 생길 위험이 있음
위와 같은 생각을 할 수 있을 것이다.
각자가 생각하는 최소한의 의미가 다 다르기 때문에 이미 만들어진 모델을 불러와서 사용한다고 해도 결과가 완전 다를 수 있다.따라서 GPT에서는 전처리를 어떻게 했는지부터 하나하나 세심하게 볼 필요가 있다.
-
-
자연어 처리 Task
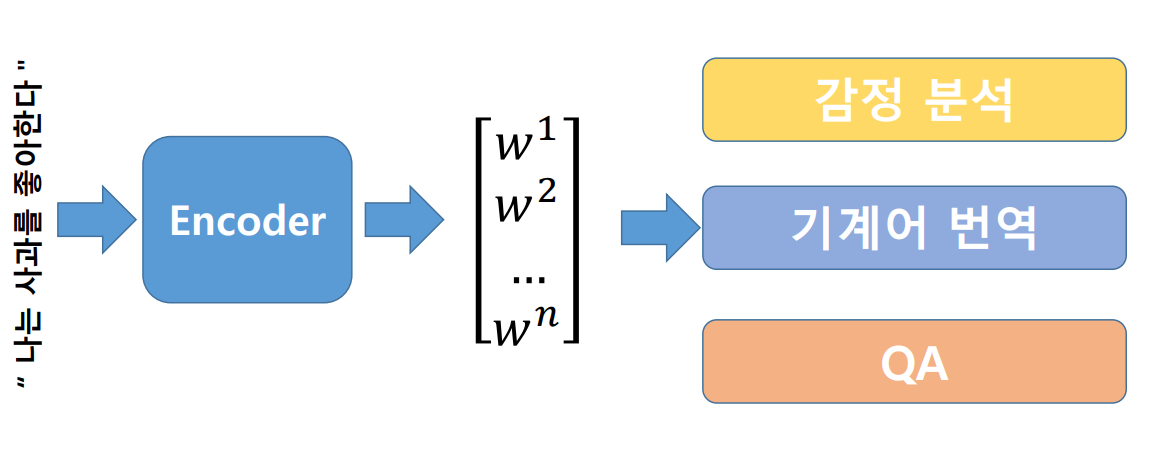
- 자연어 처리 모델은 어떤 흐름을 가지고 있을까?
먼저, 하나의 문장을 여러 개로 나누고 나눈 토큰들의 결합 분포로 문장에 대해서 확률을 계산한다. 이를 통해- 감정 분석 : 해당 문장의 긍/부정의 확률 추출
- 번역 : 해당 문장을 번역
- 중간 단어를 빈칸으로 보고 해당 단어에 무엇이 들어올지 예측
- 자연어 처리 모델은 어떤 흐름을 가지고 있을까?
기존 연구 간략 소개
자연어 처리에서 또 중요하게 생각한 것은 context(문맥)이다. 한 문장을 context를 가지고 있는 어떤 벡터로 표현하고 싶었는데 이미지나 다른 데이터와 다르게 각각의 순서가 너무 중요했다.
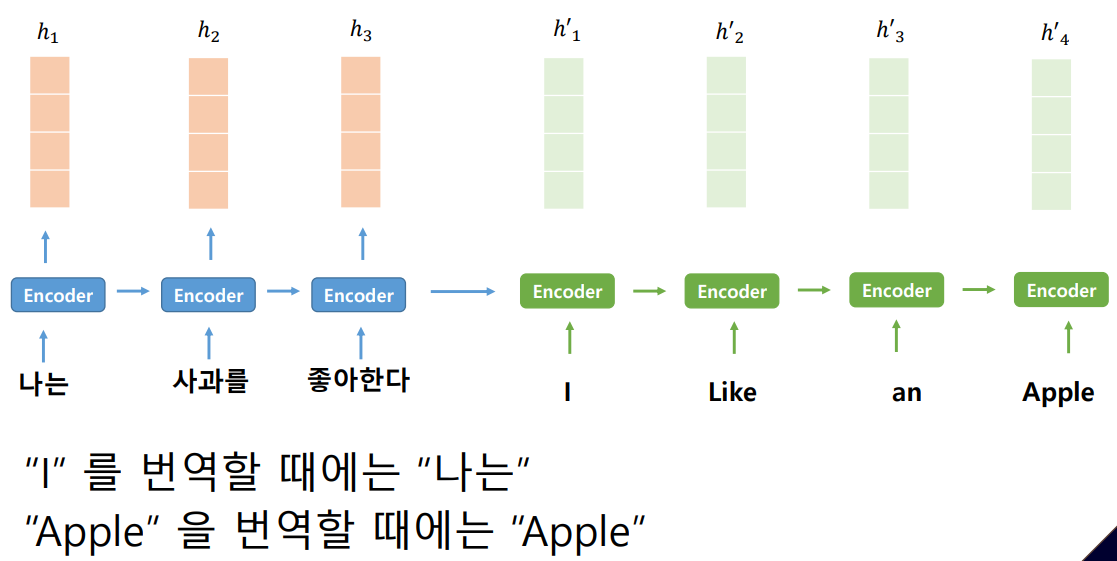
그래서 문맥을 알아내는 Encoder를 학습했다면 다양한 Task에 적용이 가능했다.
기존 연구(RNN, LSTM)에서 문장은 순서를 가지고 있으니, 문장의 처음부터 끝까지 순서대로 입력을 받아서 최종적으로 벡터를 생성해서 사용했었다.

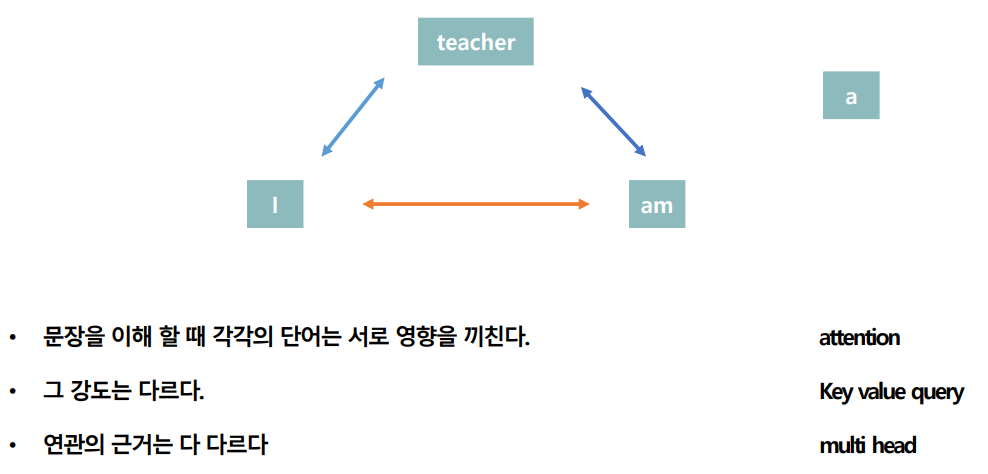
하지만 중요한 단어들이 앞 부분에 있다면 순서대로 입력받는 와중에 정보를 잃어버리지 않을까? 하는 의문을 해결하기 위해 각각의 단어에 대해 Attention을 주기로 했다.

--|--|
그래서 attention score라는 것이 나왔는데
Apple이라는 단어를 번역한다고 했을 때 '사과를' 이라는 단어와의 유사 확률이 가장 높게 나올 것이며 가장 높은 확률을 가지는 단어에 Attention하면서 이후 과정을 진행하게 되는 것이다.
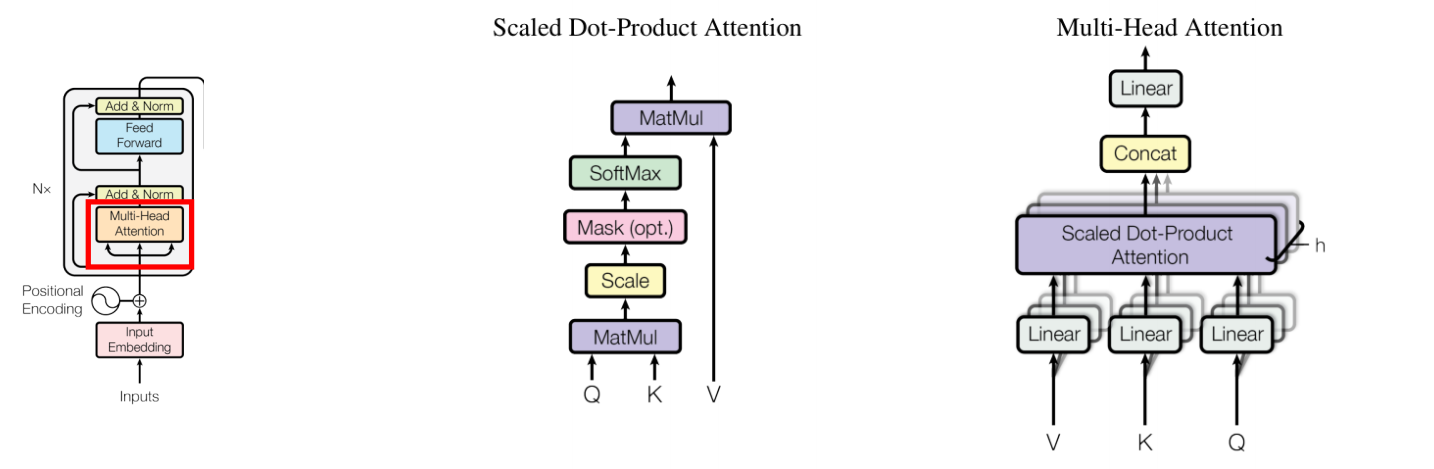
Transformer
Positional Encoding
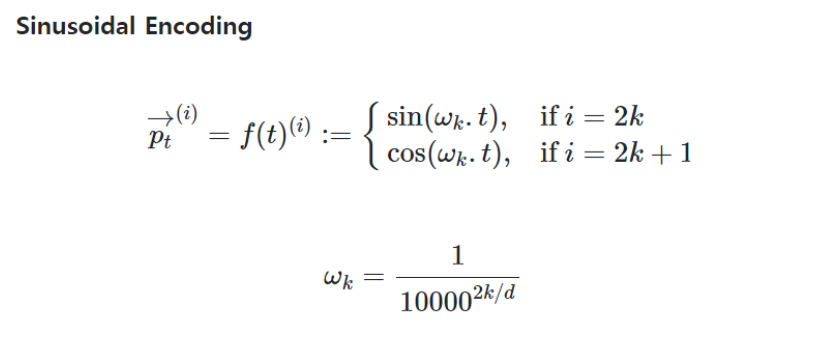
RNN은 순서를 처리할 수 있었지만, Transformer는 병렬처리를 하기 때문에 순서를 알 수 없었다. 그래서 Positional Encoding을 적용시켰으며 Multi head attention이라는 핵심 모듈을 이용했다.
Multi head attention은 Self-Attention 매커니즘을 이용하며 key query value 개념을 이용했다.
어떻게 줄까?
👀 먼저, 병렬적으로 데이터를 처리하는 Transformer에서는 순서를 고려하기 위해 Positional Encoding을 적용하게 되었다고 했다.
어떻게 줄까에 대해 여러 방법들이 나왔었는데 아래와 같은 문제점들이 있었다.
- 단어 순서대로 카운팅 : 숫자가 너무 커져서 weight 학습 시 어려움
- 단어 순서대로 카운팅 후 정규화 : weight는 안정적이지만 문장의 단어 개수에 따라 같은 자릿수에 있는 단어에 다른 값이 할당됨
- 단어 순서대로 벡터로 표현 : 문장의 단어 개수에 영향을 받지 않지만 단어 순서끼리의 거리가 다르게 됨
🤔 숫자가 너무 커지지 않으며, 같은 자릿수의 단어에는 같은 값이 할당되고, 문장 내 단어의 상대적인 위치가 같을 수 있는 방법이 없을까?
위와 같은 고민으로 탄생된게 Sinusoidal Encoding 방법이다.

이 방법은 위 3가지 고민을 해결하며 단어의 순서에 따른 문맥을 이해할 수 있게 되었다. 위 사진에서 t는 문장 내 단어의 위치이고 i는 임베딩 차원의 인덱스를 뜻한다.
코드는 아래와 같이 구현할 수 있다.
솔직히... 아직 이해가 완벽하게 된 상태가 아닌 상태이긴 하다... 🥲
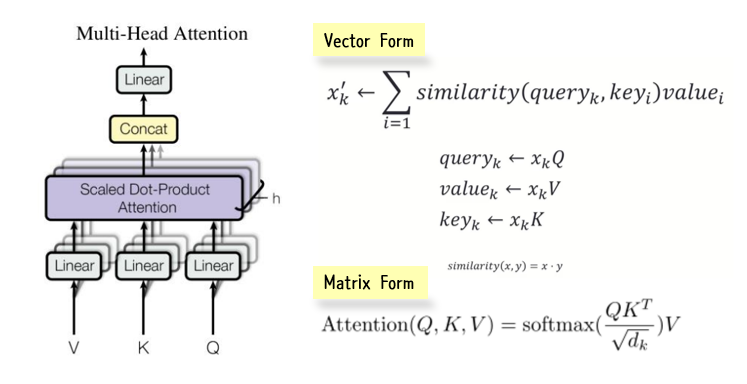
Multi head self attention
 |  |
|---|
- key , query, value 개념을 기본으로
- scaled dot-product attention 이용
: 단어에 대한 벡터는(Q) 주어진 단어들에 대해서 유사한 정도만큼(K) 고려하고 각 주어진 단어들은 V만큼의 중요도를 가진다.
📌 코드로 이해하기
class MultiHeadAttentionLayer(nn.Module):
def __init__(self, hidden_dim, n_heads, dropout_ratio, device):
super().__init__()
assert hidden_dim % n_heads == 0
self.hidden_dim = hidden_dim # 임베딩 차원
self.n_heads = n_heads # 헤드(head)의 개수: 서로 다른 어텐션(attention) 컨셉의 수
self.head_dim = hidden_dim // n_heads # 각 헤드(head)에서의 임베딩 차원
self.fc_q = nn.Linear(hidden_dim, hidden_dim) # Query 값에 적용될 FC 레이어
self.fc_k = nn.Linear(hidden_dim, hidden_dim) # Key 값에 적용될 FC 레이어
self.fc_v = nn.Linear(hidden_dim, hidden_dim) # Value 값에 적용될 FC 레이어
self.fc_o = nn.Linear(hidden_dim, hidden_dim)
self.dropout = nn.Dropout(dropout_ratio)
self.scale = torch.sqrt(torch.FloatTensor([self.head_dim])).to(device)
def forward(self, query, key, value, mask = None):
batch_size = query.shape[0]
# query: [batch_size, query_len, hidden_dim]
# key: [batch_size, key_len, hidden_dim]
# value: [batch_size, value_len, hidden_dim]
Q = self.fc_q(query)
K = self.fc_k(key)
V = self.fc_v(value)
# Q: [batch_size, query_len, hidden_dim]
# K: [batch_size, key_len, hidden_dim]
# V: [batch_size, value_len, hidden_dim]
# hidden_dim → n_heads X head_dim 형태로 변형
# n_heads(h)개의 서로 다른 어텐션(attention) 컨셉을 학습하도록 유도
Q = Q.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
K = K.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
V = V.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
# Q: [batch_size, n_heads, query_len, head_dim]
# K: [batch_size, n_heads, key_len, head_dim]
# V: [batch_size, n_heads, value_len, head_dim]
# Attention Energy 계산
energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
# energy: [batch_size, n_heads, query_len, key_len]
# 마스크(mask)를 사용하는 경우
if mask is not None:
# 마스크(mask) 값이 0인 부분을 -1e10으로 채우기
energy = energy.masked_fill(mask==0, -1e10)
# 어텐션(attention) 스코어 계산: 각 단어에 대한 확률 값
attention = torch.softmax(energy, dim=-1)
# attention: [batch_size, n_heads, query_len, key_len]
# 여기에서 Scaled Dot-Product Attention을 계산
x = torch.matmul(self.dropout(attention), V)
# x: [batch_size, n_heads, query_len, head_dim]
x = x.permute(0, 2, 1, 3).contiguous()
# x: [batch_size, query_len, n_heads, head_dim]
x = x.view(batch_size, -1, self.hidden_dim)
# x: [batch_size, query_len, hidden_dim]
x = self.fc_o(x)
# x: [batch_size, query_len, hidden_dim]
return x, attentionLayer norm
👀 Batch Normalization vs Layer Normalization
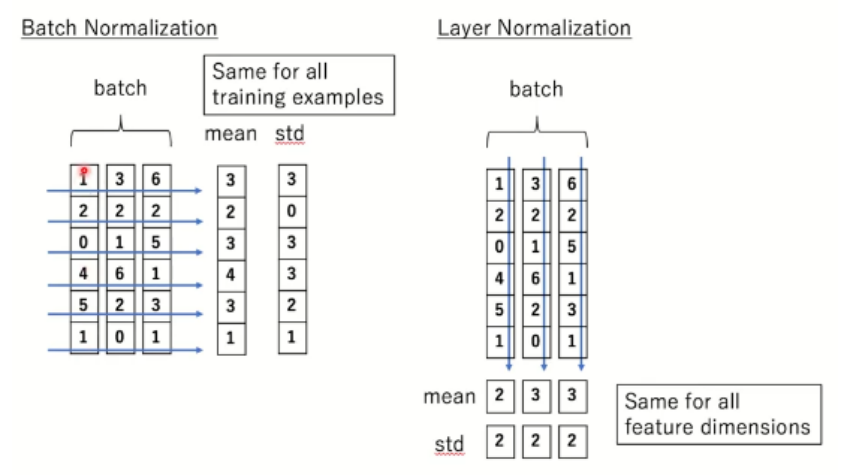
- Batch norm : sample 들의 feature 별 평균과 분산 -> batch size에 따라서 성능 변화가 심함
- Layer norm : 각 batch 에 대해서 feature들의 평균과 분산
📌 코드로 이해하기
class LayerNorm(nn.Module):
def __init__(self, d_model, eps = 1e-8):
super(LayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, x):
# -1 : 마지막 dim(= feature)에 대한 평균
mean = x.mean(-1, keepdim = True)
std = x.std(-1, keepdim = True)
return self.gamma * (x - mean) / (std + self.eps) + self.beta
🖱️ Transformer 코드 이해하기
https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice/blob/master/code_practices/Attention_is_All_You_Need_Tutorial_(German_English).ipynb
BERT , GPT
자연어 데이터는 다양한 Label이 요구되고 format도 매우 복잡하게 되어있다.
의료 데이터셋과 비교하면 수많은 텍스트 데이터들이 레이블이 없이 존재하는 경우가 많은데 주어진 문장에 대한 함축적인 문맥을 이해할 수 있다면 우리는 다양한 Task에 적용할 수 있을 것이다.
GPT-1
- 비지도 학습 기반과 지도 학습 기반을 결합한 semi-supervised learning
- 이를 통해 다양한 자연어 Task에서 지도 학습 만으로도 좋은 성능을 보이는 범용적인 자연어 representation을 학습시킴
- 2 stage로 구성되어있으며 Transformer의 Decoder 구조를 사용
- 기존 RNN 대비 좋은 성능
📌 GPT-1의 2 stage
 | 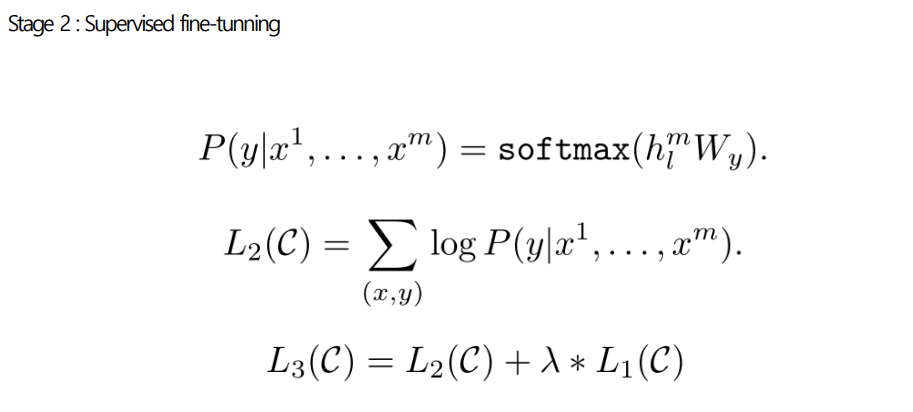 |
|---|
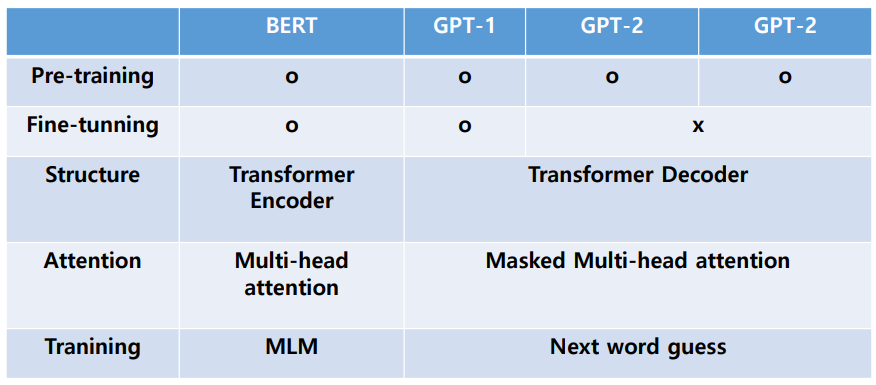
BERT
- Wiki & Book data와 같은 대용량 unlabeled data 로 pre-training 시킨 후 특정 Task 에 Transfer learning을 함
- GPT와 달리 새로운 네트워크를 붙이지 않고 Fine-tunning 만 진행
- GPT에서의 Unsupervised pre-trainning 을 BERT에서는 Masked Language Model과 Next sentence prediction을 사용
- Next sentence prediction : 문장 간 관계를 알아내기 위한 Task
- Pre-training 프로세스는 GPT-1과 같음
GPT-2
- Fine tunning 없이
- 모델 자체는 GPT-1과 크게 다르지 않음
- WebText 데이터를 구축
- 이 대용량 데이터셋에 LM 모델을 학습했을 때 supervision 없이도 다양한 Task 처리가 가능해짐
- Byte pair Encoding을 활용하여 Out of Vocabulary 문제 해결
GPT-3
- GPT-2 대비 Self attention layer를 굉장히 많이 쌓아 parameter 수를 대폭 늘림
- GPT-2에서 사용하는 Zero shot learning framwork 확장
📌 정리
Hugging face 라이브러리
소개 및 사용법
🖱️ Hugging Face 공식 사이트
📌 install
pip install transformers
pip install transformers[sentencepiece]
pip install datasets
다양한 Task
from transformers import pipeline
pipeline('사용할 Task 이름', model = '모델명')
감성 분석(sentiment-analysis)
: 문장의 긍/부정 예측
# sentiment-analysis 작업을 하는 pipeline 불러오기
classifier = pipeline('sentiment-analysis')
classifier("I've been waiting for a HuggingFace course my whole life.")
# 해당 문장에 대한 긍/부정과 스코어값 반환💻 출력
[{'label': 'POSITIVE', 'score': 0.9598048329353333}]
제로샷 learning
: 새로운 클래스에 대한 학습 데이터가 없는 상황에서도 해당 클래스를 인식하고 분류할 수 있는 학습 방법
classifier = pipeline('zero-shot-classification')
# 레이블이 없기 때문에 우리가 주고 학습시키면 됨
classifier(
"This is a course about the transformers library",
candidate_labels = ['education', 'politics', 'business'] # 우리가 원하는 라벨에 대한 출력 가능
)💻 출력
{'sequence': 'This is a course about the transformers library',
'labels': ['education', 'business', 'politics'],
'scores': [0.9192408919334412, 0.06077827885746956, 0.01998082548379898]}
# 문장 속 단어는 높게 추출
classifier(
"this is a course about the transformers library",
candidate_labels = ['education', 'politics', 'business',
'library', 'game', 'play']
)💻 출력
{'sequence': 'this is a course about the transformers library',
'labels': ['library', 'education', 'business', 'play', 'game', 'politics'],
'scores': [0.5048014521598816,
0.4317719638347626,
0.026262251660227776,
0.015142401680350304,
0.011997081339359283,
0.010024827904999256]}
Text-generation
: 주어진 문맥이나 지시에 따라 새로운 텍스트를 생성
generator = pipeline('text-generation')
generator("In this course, we will teach you how to ")💻 출력
Setting
pad_token_idtoeos_token_id:50256 for open-end generation.
[{'generated_text': 'In this course, we will teach you how to ute asynchronously in the time-honoured way, creating simple, effective, and highly interactive apps and applications to help you be productive in the most productive time of your life—while simultaneously'}]
# 다양한 옵션을 지정할 수도 있고
generator("In this course, we will teach you how to " ,
# 다양한 옵션 지정 가능
num_return_sequences = 10,
max_length = 30
)
# 리스트 형태로 문장을 넣어줄 수 있음
list_ = ["In this course, we will teach you how to " ,
"this is a course about the transformers library"]
for sentence in list_:
print(generator(sentence, num_return_sequences = 1, max_length = 50))Mask filling
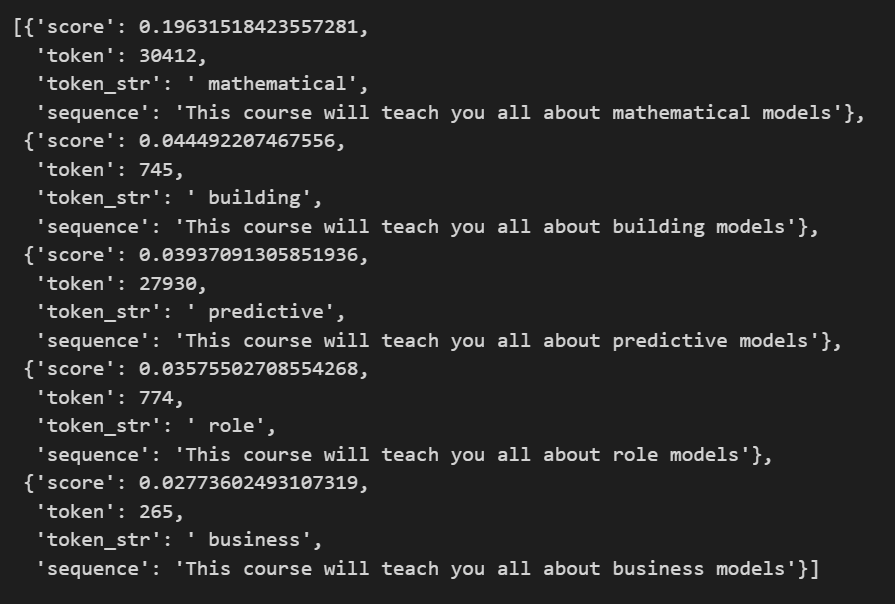
: 문장에서 일부 단어를 마스킹(가려서 숨김)한 후, 모델이 해당 마스킹된 단어를 예측하는 작업
unmasker = pipeline('fill-mask')
# 마스크할 부분을 <mask>로 지정
unmasker("This course will teach you all about <mask> models" ,
top_k = 5 # 몇 개를 추출할 것인지
)💻 출력
Question Answering
: 문장에서 내가 물어보는 것에 대한 답변을 해주는 작업
question_answerer = pipeline('question-answering')
question_answerer(
question = 'Where do I work?',
context = "My name is Sylvain and I work at Hugging Face in Brooklyn."
)💻 출력
{'score': 0.6385914087295532, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}
Summarization
: 문장을 요약해주는 작업
summarizer = pipeline('summarization')
summarizer(
"""
On the technical side, it is sometimes claimed that Netflix epitomises a “vertical integration model”, operating across the entire chain of TV content production and distribution. But in reality it is great at outsourcing.
For while Netflix has its own engineers and proprietary technology, including its famed recommendation system and algorithm, the company has designed its entire media delivery on third-party service infrastructure.
Netflix shut its last data centre in 2016. Now everything the platform needs, from data storage to customer information and algorithms runs on Amazon’s web services.
Outsourcing media delivery has enabled Netflix to avoid sinking cash in to global infrastructure, and instead focus on its core mission: members’ engagement across markets.
The same goes with content production. Netflix 'originals' are produced by the platform insofar has it pays for the entirety of the production costs. But the content is actually made by outside film and TV producers.
This entails governing a vast network of suppliers, giving it extraordinary flexibility in a fast moving industry. In contrast, the likes of Disney+ have to rely more heavily on a limited range of production it is directly responsible for making.
If Netflix does have a corporate weakness, it may be that its streaming service is not part of a large enterprise ecosystem. Amazon and Apple for example, sell goods to millions of customers and cleverly entwine different parts of their empires to deliver significant economies of scale.
Despite this, Netflix’s approach embraces the challenges and opportunities a global market offers. Its outsourcing model makes it agile and able to pivot rapidly with a business model which enables it to thrive.
The streaming industry – and television at large – is entering a period of adjustment because it needs to close the gap between content investment and revenue generation. Aided by some shrewd decisions and with a truly global outlook, the market leader appears to be in a good position to weather the storm.
"""
)💻 출력
No model was supplied, defaulted to sshleifer/distilbart-cnn-12-6 and revision a4f8f3e (https://huggingface.co/sshleifer/distilbart-cnn-12-6).
Using a pipeline without specifying a model name and revision in production is not recommended.
기계어 번역
: 문장을 다른 언어로 번역해주는 작업
translator = pipeline('translation', model = 'Helsinki-NLP/opus-mt-fr-en') # 프랑스어 -> 영어
translator("Ce cours est produit par Hugging Face.")💻 출력
[{'translation_text': 'This course is produced by Hugging Face.'}]
Tranning
Tokenizer
📌 데이터 준비
from transformers import AutoTokenizer
checkpoint = 'distilbert-base-uncased-finetuned-sst-2-english'
# 체크포인트의 tokenizer 불러오기
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for a huggingface course my whole life",
"I hate this so much!"
]
inputs = tokenizer(raw_inputs,
padding = True,
truncation = True,
return_tensors = 'pt')📌 모델
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
model.config.id2label # {0: 'NEGATIVE', 1: 'POSITIVE'}
outputs = model(**inputs)
outputs # 긍/부정이 확률값으로 나옴
# softmax 씌워서 최종 output 출력
import torch
predictions = torch.nn.functional.softmax(outputs.logits , dim = 1)
predictions💻 출력
tensor([[4.8393e-02, 9.5161e-01],
[9.9946e-01, 5.4418e-04]])
model을 커스터마이징하고 저장하기
from transformers import BertConfig, BertModel
config = BertConfig()
config # BERT에 사용되고 있는 디폴트 옵션들
config.hidden_size = 48
model = BertModel(config)
model # 48로 교체된 것을 볼 수 있음
# 저장
model.save_pretrained('./test')Tokenizer를 할 때 꼭 해야하는 과정
tokenizer를 할 때 의미있는 단어를 하나로 볼 수 있도록 학습시켜야하는 과정이 꼭 필요하다.
예를 들어 기계 번호(KT-13982)와 같은 경우 이상한 단어로 분리시키거나 Unknown을 띄우기 때문에 학습을 꼭 시켜주어야한다.
📌 데이터 및 모델 준비
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = 'distilbert-base-uncased-finetuned-sst-2-english'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."📌 1. 수동으로 토큰화하고 인덱스로 변환하는 과정
#1 수동으로 토근화하고 인덱스로 변환하는 과정
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor(ids)📌 2. return_tensors 옵션을 통해 자동으로 하는 방법
#2 return_tensors 옵션을 통해 자동으로 가능!
tokenized_inputs = tokenizer(sequence, return_tensors='pt')방법 2를 더 추천하는 이유
#1을 사용하는 경우에는 몇 가지 문제점이 있을 수 있습니다.
1. 특수 문자 처리: #1에서는 직접 토큰화 과정을 거치기 때문에 특수 문자에 대한 처리를 별도로 해주어야 합니다. 예를 들어, 문장에 포함된 구두점이나 기호를 어떻게 처리할지 결정해야 합니다.
2. 토큰 제한: #1에서는 입력 시퀀스를 토큰화한 후 정수 인덱스로 변환하는 과정을 직접 수행하기 때문에, 모델이 처리할 수 있는 최대 토큰 개수를 초과하는 경우에는 문제가 발생할 수 있습니다. 이 경우에는 입력 시퀀스를 잘라내거나 다른 방법으로 처리해야 할 수 있습니다.
3. 특정 모델에 종속적: #1에서는 tokenizer와 모델을 따로 정의하고 초기화해야 합니다. 이는 특정 모델에 종속적이기 때문에 다른 모델을 사용하고자 할 때는 코드를 수정해야 합니다.이러한 문제점들은 #2의 방식을 사용하는 경우에는 자동으로 처리되기 때문에 발생하지 않습니다. tokenizer 함수를 사용하면 특수 문자 처리, 토큰 제한 등의 과정이 내부적으로 처리되며, 특정 모델에 종속되지 않고 다양한 모델을 손쉽게 사용할 수 있습니다.
실제 자연어 모델 학습 과정
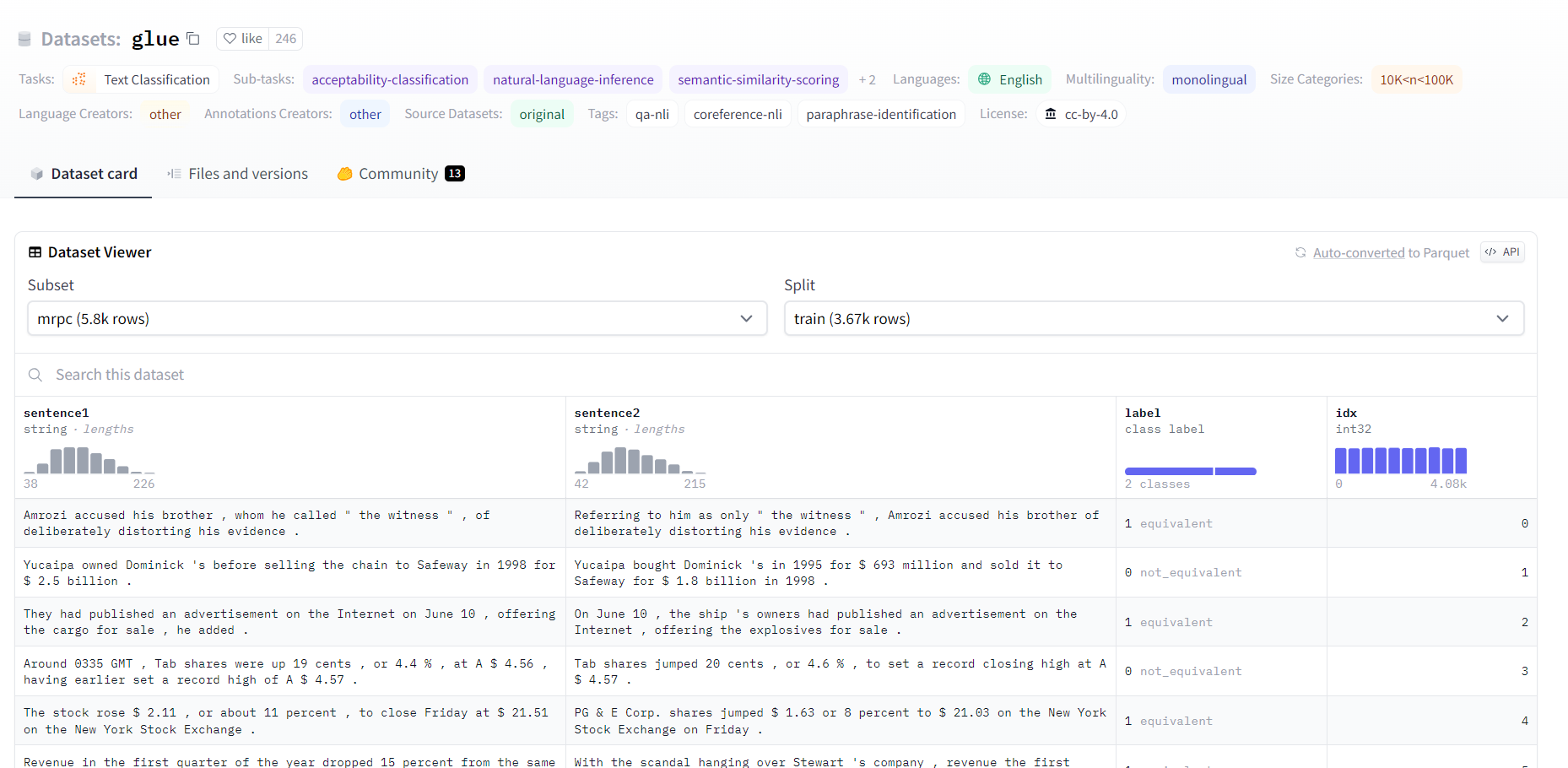 | 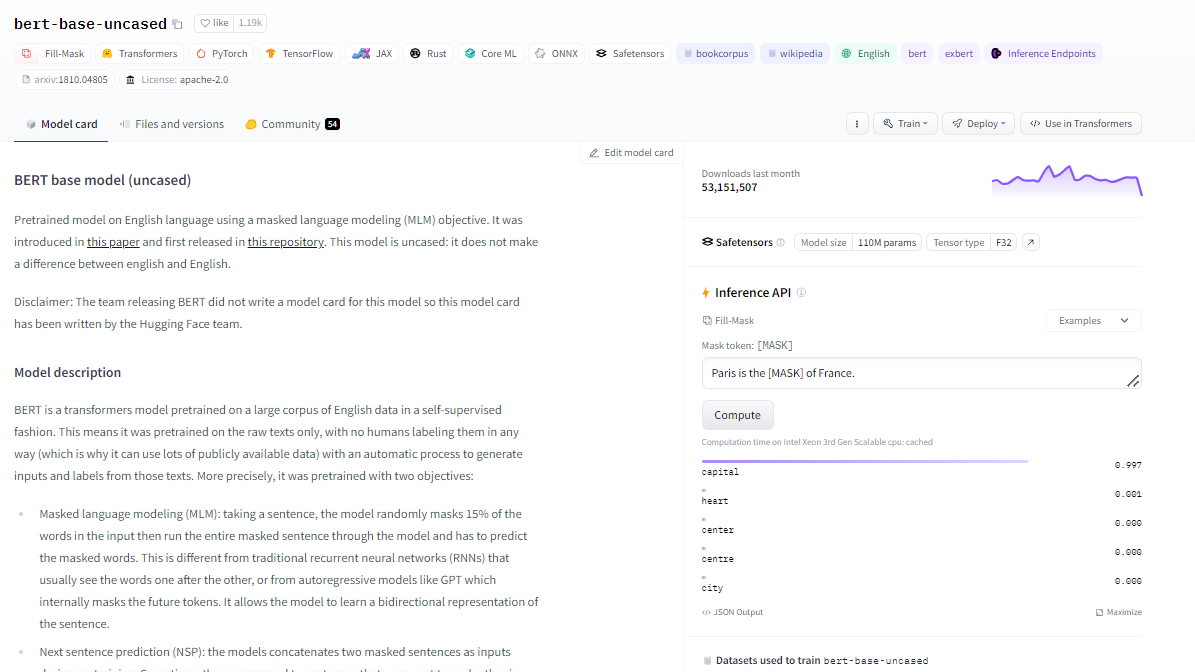 |
|---|
📌 데이터 준비
# 데이터로드는 아래와 같이
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", 'mrpc')
checkpoint = 'bert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)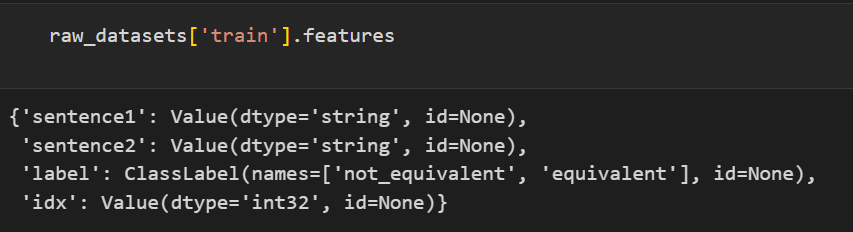
데이터셋 구성은 위와 같이 되어있는 것을 볼 수 있다.
📌 지정한 컬럼에 대해 tokenizer 실시 및 컬럼명 변경
# tokenizer function 지정
def tokenize_function(example):
# sentence1, sentence2 에 대해 tokenizer 실시
return tokenizer(example['sentence1'], example['sentence2'], truncation = True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched = True)
# padding 지정
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# 컬럼명 변경
tokenized_datasets = tokenized_datasets.remove_columns(['sentence1', 'sentence2', 'idx'])
tokenized_datasets = tokenized_datasets.rename_column('label', 'labels')
tokenized_datasets.set_format('torch')
tokenized_datasets['train'].column_names📌 데이터셋 분리
# 데이터 분리
from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_datasets['train'], shuffle=True, batch_size=8, collate_fn = data_collator
)
eval_dataloader = DataLoader(
tokenized_datasets['validation'], batch_size=8, collate_fn = data_collator
)📌 학습
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
# optim
from transformers import AdamW
optimizer = AdamW(model.parameters(), lr = 5e-5)
# scheduler
from transformers import get_scheduler
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
'linear',
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
# gpu 설정
import torch
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
# train
from tqdm import tqdm
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k : v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
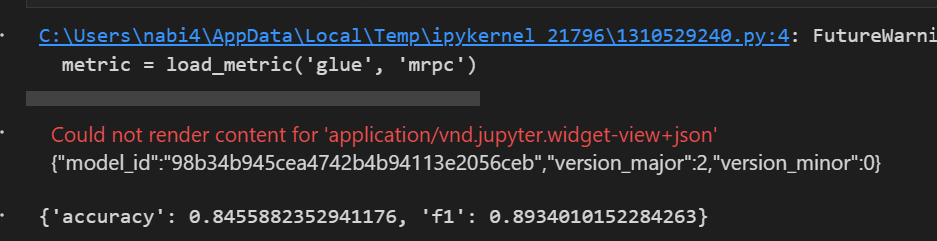
progress_bar.update(1)📌 평가
# evaluation
from datasets import load_metric
metric = load_metric('glue', 'mrpc')
model.eval()
for batch in eval_dataloader:
batch = {k : v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
logits = outputs.logits
predictions = torch.argmax(logits, dim = 1)
metric.add_batch(predictions = predictions, references = batch['labels'])
metric.compute()💻 출력