
✍🏻5일 공부 이야기.

오늘 공부한 실습 코드는 위 깃허브에 올려두었습니다 :) 사진 클릭시 해당 링크로 이동해요 !
Modeling 하는 방법 2가지
방법 1. nn.Sequential
import torch
from torch import nn
import torch.nn.functional as F
import torchsummary
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = nn.Sequential(
nn.Linear(784, 15),
nn.Sigmoid(),
nn.Linear(15, 10),
nn.Sigmoid(),
).to(device)
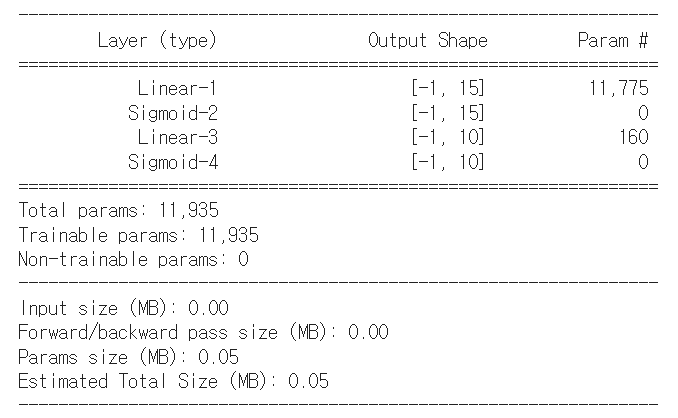
# model의 정보를 좀 더 자세하고 이쁘게 출력 가능
torchsummary.summary(model, (784, ))💻 출력
방법 2. nn.Module sub class
# (1, 28, 28) input size 가정
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# input 수를 지정해주어야함
self.conv1 = nn.Conv2d(1, 20, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(20, 50, kernel_size=3, padding=1)
self.fc1 = nn.Linear(4900, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) #(28, 28)
x = F.max_pool2d(x, 2, 2) #(14, 14)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2) #(7, 7)
x = x.view(-1, 4900)
x = F.relu(self.fc1(x))
x = F.log_softmax(self.fc2(x), dim=1)
return x
model = Net()
torchsummary.summary(model, (1, 28, 28))💻 출력

ResNet 구현
# ResidualBlock
class ResidualBlock(nn.Module):
def __init__(self, in_channel, out_channel):
super(ResidualBlock, self).__init__()
self.in_channel, self.out_channel = in_channel, out_channel
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=1, padding=0)
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(out_channel, out_channel, kernel_size=1, padding=0)
if in_channel != out_channel:
# in_channel과 out_channel이 맞지 않을 시
# 더해주기 전 한 번 더 channel을 맞춰주는 작업 실시
self.shortcut = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=1, padding=0)
)
else:
self.shortcut = nn.Sequential()
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.relu(self.conv2(out))
out = F.relu(self.conv3(out))
out += self.shortcut(x)
return out
class ResNet(nn.Module):
def __init__(self, color='gray'):
super(ResNet, self).__init__()
# 컬러에 따라 맨 첫번째 레이어을 다르게 작업
if color == "gray":
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
elif color == "rgb":
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.resblock1 = ResidualBlock(32, 64)
self.resblock2 = ResidualBlock(64, 64)
self.avgpool = nn.AdaptiveAvgPool2d((1,1)) # averagepool
self.fc1 = nn.Linear(64, 64)
self.fc2 = nn.Linear(64, 10) # output에 맞게
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = self.resblock1(x)
x = self.resblock2(x)
x = self.avgpool(x)
x = torch.flatten(x,1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
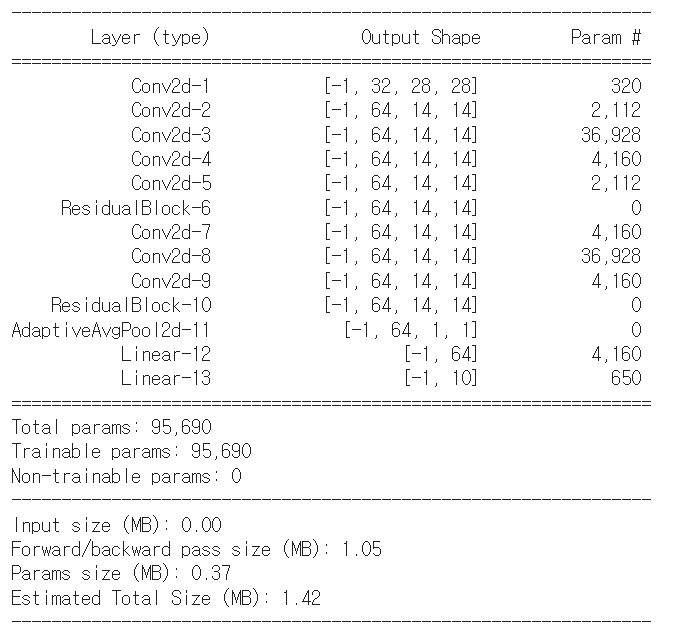
model = ResNet()
torchsummary.summary(model, (1, 28, 28))💻 출력
최적화
Training
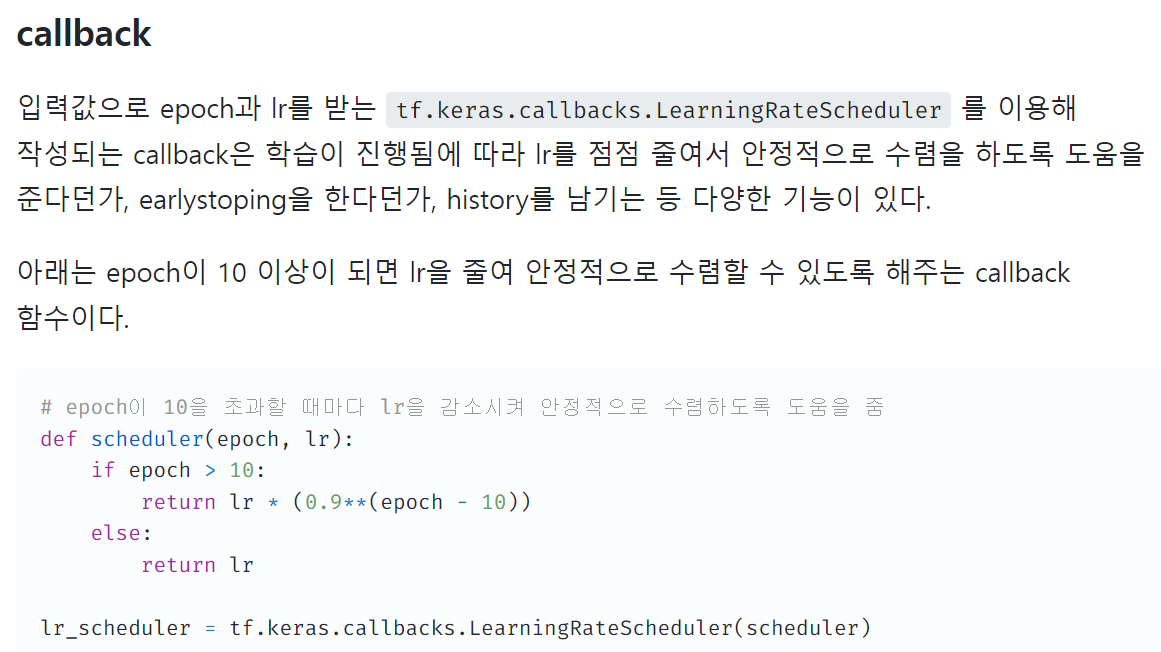
tensorflow에 위와 같은 기능을 하는 것이 pytorch에도 있다.
Learning Rate Scheduler
model = ResNet().to(device)
opt = optim.Adam(model.parameters(), lr = 0.03)
from torch.optim.lr_scheduler import ReduceLROnPlateau
scheduler = ReduceLROnPlateau(opt, mode = 'min', verbose = True)
# epoch이 진행됨에 따라 학습률을 줄여 안정적으로 수렴하도록 도움을 줌
# training loop
def train_loop(dataloader, model, loss_fn, optimizer, scheduler, epoch):
model.train()
size = len(dataloader)
for batch, (x, y) in enumerate (dataloader):
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
print(f"Epoch {epoch} : [{batch} / {size}] loss : {loss.item()}")
scheduler.step(loss)
return loss.item()
# 학습
for epoch in range(10):
loss = train_loop(train_loader, model, F.nll_loss, opt, scheduler, epoch)
print(f"Epoch : {epoch} loss : {loss}")Model save
Weight만 저장
# 저장
torch.save(model.state_dict(), 'model_weights.pth')
# 불러오기
model.load_state_dict(torch.load('model_weights.pth'))구조도 함께 저장
# 저장
torch.save(model, 'model.pth')
# 불러오기
model = torch.load('model.pth')어떻게 사용? -> checkpoint
# 저장 경로
checkpoint_path = 'checkpoint.pth'
# 저장
torch.save({
'epoch' : epoch,
'model_state_dict' : model.state_dict(),
'optimizer_state_dict' : opt.state_dict(),
'loss' : loss
}, checkpoint_path)
# 불러오기
checkpoint = torch.load(checkpoint_path)
# 학습시킬 모델 선언
model = ResNet().to(device)
optimizer = optim.SGD(model.parameters(), lr = 0.03)
# 다음에 학습할 때 위 정보를 이어서 학습할 수 있게 됨!
model.load_state_dict(checkpoint['model_state_dict'])
epoch = checkpoint['epoch']
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
loss = checkpoint['loss']데이터 다루기
PyTorch에서 Dataloader 만들기
torch.utils.data.DataLoader를 사용하면 된다!
batch_size = 32
# 기존에 우리가 했던 방법
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('dataset/',
train=True, download=True, # 로컬 환경에 데이터가 없다면 다운로드하라
transform=transforms.Compose([ # 가져올 때 미리 아래와 같이 전처리해서 가져오겠다
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,)) # mean이 0.5이고 std가 0.5가 되는 분포가 되도록 정규화시켜라.
# 튜플 형태로 넣어주어야함
])),
batch_size=batch_size,
shuffle=True)로컬 데이터를 torch.utils.data.Dataset으로 만들기
ImageFolder를 이용하면 되는데 tf의 flow_from_directory와 같은 제약 조건이 있다.
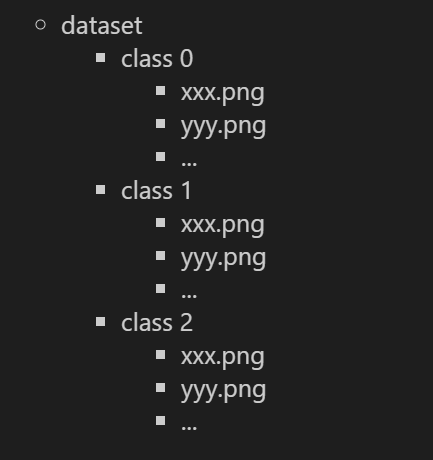
해당 조건이 만족한다면 아래와 같은 방법으로 데이터셋을 만들 수 있다.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_dir = '../../datasets/mnist_png/training/'
test_dir = '../../datasets/mnist_png/testing'
train_dataset = datasets.ImageFolder(
root = train_dir,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0.5, 0.5)
])
)
test_dataset = datasets.ImageFolder(
root = test_dir,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0.5, 0.5)
])
)
# x, y = next(iter(train_dataset))
# x.shape, y # (torch.Size([3, 28, 28]), 0)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size = 32,
shuffle = True
)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size = 32,
shuffle = True
)
x, y = next(iter(train_loader))
x.shape, y.shape # 배치 사이즈만큼 뽑힘 # (torch.Size([32, 3, 28, 28]), torch.Size([32]))Custom dataset 다루기
ImageFolder는 제약사항이 많으므로 직접 torch.utils.data.dataset.Dataset 상속받아 데이터셋을 구현해보자.
지금 현재 파일 이름에 클래스의 이름이 있고 이를 label.txt의 인덱스와 매치시켜 원핫인코딩된 타겟 데이터를 얻어낼 수 있는 구조이다.
# custom
class Dataset(torch.utils.data.Dataset):
def __init__(self,data_paths, transform = None):
super(Dataset).__init__()
self.data_paths = data_paths
self.transform = transform
def __len__(self):
return len(self.data_paths)
def __getitem__(self, idx):
# 이미지, 레이블 추출
path = self.data_paths[idx] # 파일 경로
image = Image.open(path) # return 할 이미지
label_name = path.split('.png')[0].split('_')[-1].strip() # 클래스 라벨 이름
label = label_list.index(label_name) # 원핫인코딩역할을 하는 타겟 데이터
if self.transform:
image = self.transform(image)
return image, label
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
batch_size = 32
train_loader = torch.utils.data.DataLoader(
Dataset(train_paths, transform=transforms.ToTensor()),
batch_size = batch_size, shuffle = True
)
test_loader = torch.utils.data.DataLoader(
Dataset(test_paths, transform=transforms.ToTensor()),
batch_size = batch_size
)
x, y = next(iter(train_loader))
x.shape, y.shape # (torch.Size([32, 3, 32, 32]), torch.Size([32]))Transform
from torchvision import transforms
image = Image.open('/content/drive/MyDrive/제로베이스스쿨 공부/Deep Learning/data/sample.png')transforms.Resize([512, 512])(image): 해당 픽셀로 resizetransforms.RandomCrop(size = (512, 512))(image): 해당 픽셀만큼 랜덤으로 croptransforms.ColorJitter(brightness = 1)(image): 랜덤으로 밝기 조절transforms.Grayscale()(image): grayscale 적용transforms.Pad(padding = (20 , 10))(image): padding 적용transforms.RandomAffine(degrees = 90)(image): 랜덤하게 회전transforms.RandomHorizontalFlip(p = 1.)(image): 반전
위 과정을 한 번에 모두 수행하고 싶다면
# 한 번에
transform_list = [
transforms.RandomAffine(degrees = 90),
transforms.Pad((20,20))
]확률에 의해 적용시키고 싶다면
# 확률에 의해 적용
transforms.RandomApply(transform_list, p = 0.5)(image)랜덤하게 한 가지만 적용시키고 싶다면
# transform_list 중 랜덤하게 한 개만 적용
transforms.RandomChoice(transform_list)(image)
데이터 분석가(가 되고픈) 황성미입니다!