
- 논문링크: https://ieeexplore.ieee.org/document/8509057
- 참고글: https://medium.com/@gouri.benni/an-overview-on-a-hybrid-database-approach-using-graph-and-relational-database-fb216e0a24f1
한 줄 요약: RDB, GraphDB의 장단점을 분석하고 이 둘을 hybrid로 사용하기 위한 개념적 수준의 접근법 제안
'정보의 연결성'이라는 목적 하에 테이블 데이터를 그래프로 변환하는 작업들을 꽤 오래 진행하고 있다. 그러나 데이터 사이즈가 커지면서, 메타데이터나 컬럼 수준의 관계 정보를 그래프로 표현하는 것은 충분히 가능하고 효과적이지만, 인스턴스 수준까지 모두 그래프로 표현해서 몇 억 트리플의 그래프를 만드는게 과연 효율/효과적이며 필요한가?라는 질문을 계속 하게 된다. 물론 쿼리를 수행하기 위한 리소스가 무한대라면 아무 문제 없겠지만, 현실적이지 않으니 제외하고 다음으로 생각한 방식이 'RDB+SchemalessDB+GraphDB'의 구축 가능성이다. 관련 논문들을 하나씩 읽어보고 정리해보고자 한다.
.
.
.
✅ Backgrounds
RDB(Relational DataBase; 관계형 데이터베이스)는 1970년대 이후 오랜 기간 산업 표준으로 자리잡았다. 안정적이고 직관적인 SQL 쿼리 언어를 통해 구조화된 데이터를 다루는데 최적화되어 있고, 사전에 정의한 스키마 기반 구조로 구성되어 명확하고 데이터 일관성이 보장된다는 장점이 있다. 반면, 데이터 간 관계를 직접 저장하지 않음에 따라 연결성을 파악하려면 JOIN연산이 필요하고, 사이즈가 커질수록 연산속도가 기하급수적으로 느려진다는 문제가 있다. 따라서 현대의 연결성이 강하고 구조적 특성이 약한 데이터 특성을 다루는데 한계가 있다고 논문에서 설명하고 있다.
그래프DB는 복잡한 연결관계를 표현하는데 적합하다. 유현한 스키마, 복잡한 관계 탐색 등은 모두 데이터 간 관계를 중심으로 모델링함에 따라 수행 가능하다. 그럼에도 재규모 분석 처리의 한계와 같은 기능 제약과 벤치마킹 기준 부재 등의 문제가 있어 실무 적용시 구조적 한계를 갖고 있다.
RDB와 GDB는 모두 각각의 장단점과 특징이 뚜렷하기 때문에, RDB를 그래프로 마이그레이션 하려는 연구(RDB스키마를 트리플로 변환하는 매핑 스키마로 변환하고 구조적 규칙 제시. 변환 복잡성에 의해 쉽지 않음)를 지나 이 둘을 하이브리드 방식으로 활용하고자 하는 연구들이 다수 존재한다.
- NoSQL + SQL 하이브리드 분산 DB. Google의 광고 시스템을 위한 설계된 방식으로 대규모 엔터프라이즈 환경에서 하이브리드 모델의 성공사례임 (Jeff Shute et al, ; F1: A Distributed SQL Database That Scales)
- SQL(MySQL), NoSQL(MongoDB), hybrid DB 세가지 모드에 데이터를 전부 두고 비교한 연구. hybrid 모두가 대용량 데이터 저장, 관리 성능이 좋았음 (Blessing E. James and P.O.Asagba., 2020; Hybrid database system for big data storage and management )
- 전통적인 RDBMS와 in-memory graph store 사이의 쿼리 프로세스 중간 레이어를 통해 쿼리가 들어오면 RDB기반의 행 중심 서브 쿼리와 그래프 중심 서브 쿼리로 분리해서 실행하는 방식. gSQL이라는 하이브리드 질의 언어 제안 (Christopher J. O. Little, 2016; Grapht: A Hybrid Database System for Flexible Retrieval of Graph-structured Data)
- 두 개의 데이터베이스를 개별적으로 관리하지 않고, 단일 데이터베이스처럼 작동하는 두 DB에 모두 추상화 계층(abstraction layer)을 만드는 방식으로, RDB에 가상의 관계를 생성하고 사전에 triple 형식으로 변환된 NoSQL 데이터를 로드하는 방식 (John Roijacker, 2012; Bridging sql and nosql)
- NoSQL 시스템 위에서 SQL 쿼리를 실행하는 방법. 성능저하를 감수하고 택한 방식(?)(Luis Ferreira, 2011; Bridging the gap between SQL and NoSQL)
- RDB(FishBase: 관계형 생물학 DB)를 그래프로 전환하고 동기화하는 방식. Regraph 아키텍쳐로 관계형와 그래프 DB를 동기화할 수 있음(Patricia Raia Nogueira Cavotol, 2016; ReGraph: Bridging Relational and Graph Databases)
- PostgraSQL과 Neo4J를 연결하는 미들웨어 기반 Bridge-DB를 자체 질의언어 BQL을 통해 사용하는 방식. 이기종 DB 간 질의 최적화를 시도한 연구(Rune Ettrup and Lisbeth Nielsen, 2015; Bridge-DB- Query Optimization in a Multi-Database System)
- 관계형, 그래프, 시멘틱 데이터를 단일 인메모리 엔진에 통합해서 단일 실행 엔진에서 한번에 질의 처리하는 방식(Martin Grund, Philippe Cudre-Mauroux, Jens Krueger and Hasso Plattner, 2013; Hybrid graph and relational query processing in main memory)
사실 논문의 설명만으로는 정확히 어떤 방식으로 작동하는지 이해되지 않는다. 세부적으로 살펴봐야 할듯
✅ Proposed System
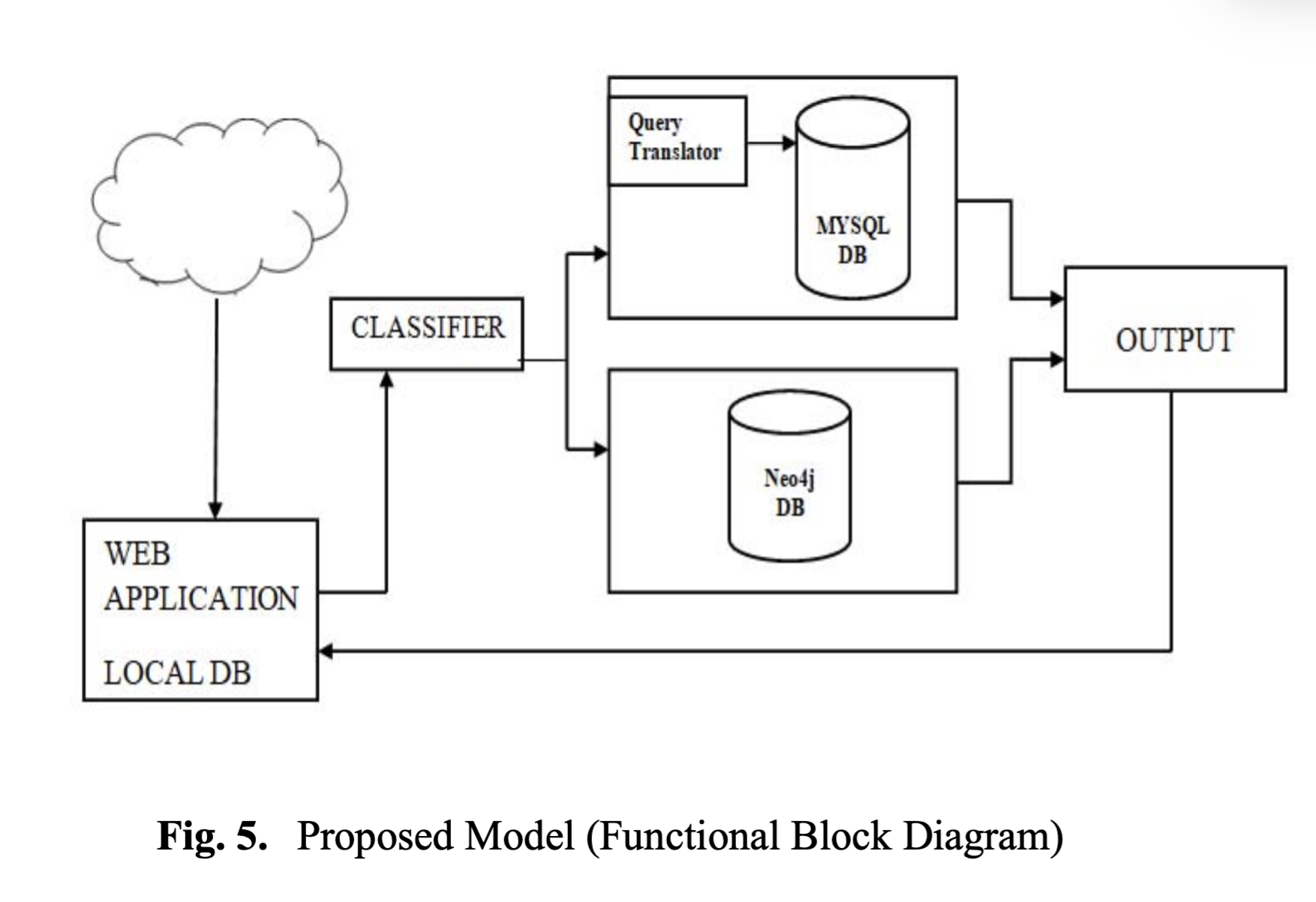
구조는 간단하다. 데이터가 입력된 순간 데이터의 특성, 구조적인지 아닌지를 판단해서 전자인 경우 MySQL에 저장하고 후자인 경우 Neo4j에 저장하는 것이다. 마이그레이션을 하지 않고 통합 인터페이스를 통해서 두 형태의 DB를 하나처럼 보이도록 추상화한다는 전략이다.
구현 논문이 아니라서 다소 싱겁게 끝난다.. 더 알아야 할 점은 (1) 어떻게 구조적/비구조적 데이터를 구분하는지? (2) 저장한 뒤 두 퀴리를 할때는 어떤 형태의 DB에 해당 데이터가 들어 있는지 알고 쿼리를 할지? (3) 통합 질의어가 있는지? 등등..
.
.
.
이 논문과 동일 연도에 나온 'Integration of Relational and Graph Databases Functionally'(Pokorny, 2018) 에서도 RDB와 property graph를 통합하는 방법론이 아주 간단하게 소개하는데, 이때의 통합은 단일한 추상 질의(LT query)를 사용해서 두 형태의 DB에 동시에 질의할 수 있는 변환 방식 정도를 의미한다고 이해했다.
일반적으로 두 DB를 통합할 때는 다음 세 가지 방법을 적용할 수 있다: (1) native(그 시스템 고유 모델을 그대로 유지하는 방법) (2) hybrid(두 특성을 혼합하는 방법) (3) reducing to one option(둘 줄 하나로 통합하는 방법). 해당 논문에서는 multilevel modelling 기반으로, 기본적으로 두 DB의 개념적 표현이 완전히 일치할 수 없고 교집합을 가지는 형태라고 본다.
제안한 모델을 간단하게 보면, 'Spielberg가 감독한 영화의 제목 t'을 LT queries로 λ t (∃ m, r Movie(m)(t,'Spielberg',r))와 같이 표현한다고 했을때, Movies의 타입을 Movies / (Bool : Title, Released, Director, Genre)로 확인하고, 논리식을 'Movies 테이블에 Director=‘Spielberg’이고 Title=t인 행이 존재'하여 각각 SQL과 Cypher 쿼리로 변환할 수 있다는 것이다.
이 논문의 전제는 동일한 현실 세계의 데이터가 RDB와 GDB에 각각 표현되어 있다는 것일 것 같은데, 앞서 본 논문에서 언급했듯 이 둘을 어떻게 동기화할 지도 주요 쟁점이 된다. 현 시점에서는 LLM을 활용해서 쿼리간 변환은 매우 쉬워진 것도 같고..

아키텍처가 너무 허무하네요..