
요약
- 대규모 오픈 도메인(Wikipedia 등 공개된 인터넷 출처를 기반으로 만든) KGs를 지속적으로 업데이트 하기 위한 파이프라인 구축
- LLM-based knowledgr exetractor를 중점으로 설명하고 있음
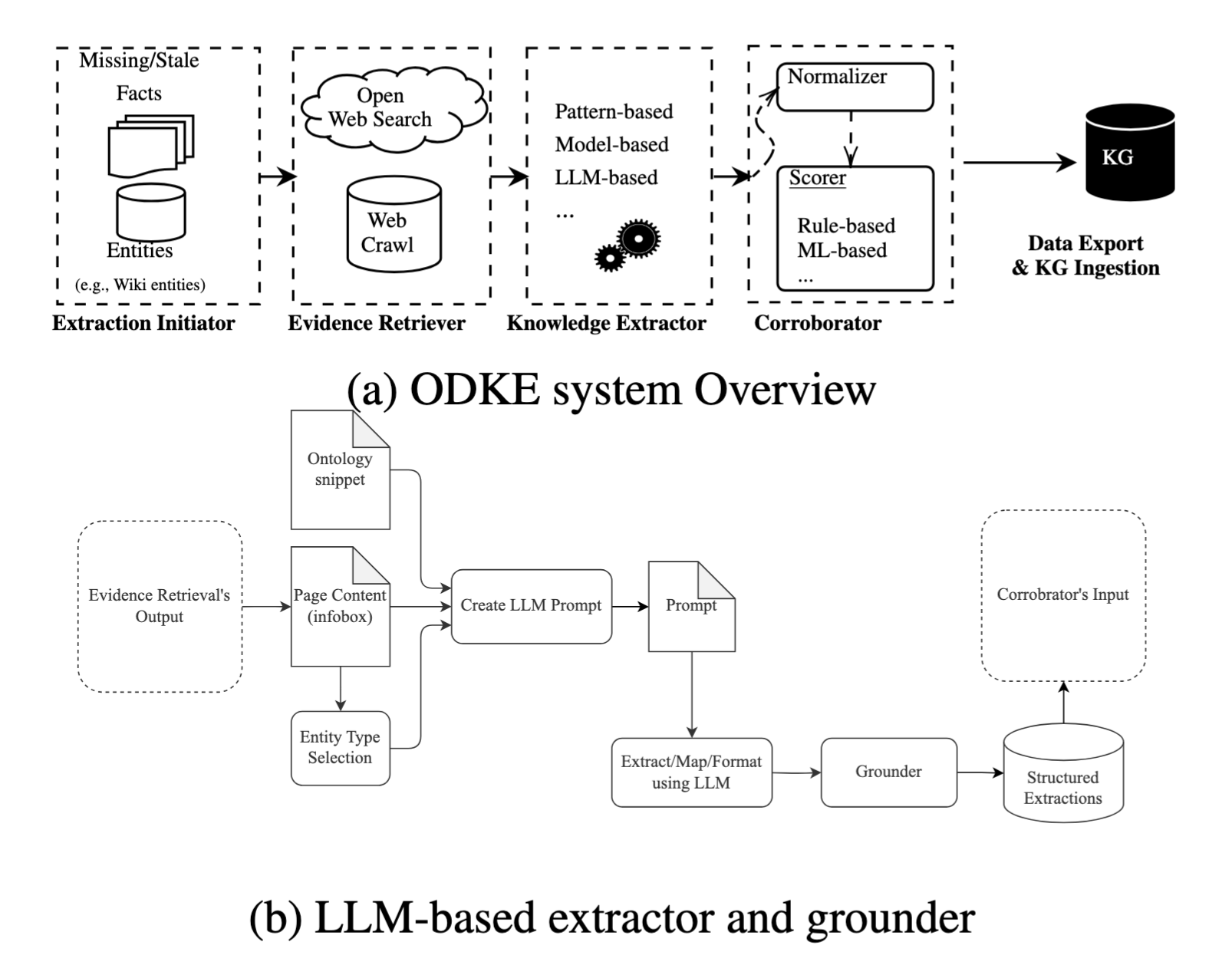
1. Extraction Initiator
지식그래프 내에서 누락되었거나 오래된 사실을 탐지하고, 업데이트가 필요한 엔티티와 웹 소스를 식별하는 모듈. 위키피디아의 경우 최근 문서 수정 이력을 트래킹해서 해당 문서와 연결된 엔티티에 업데이트 사실이 있음을 탐지함
위키피디아가 아닌 경우에는 변경 상태를 어떻게 파악할까? 웹페이지 개편으로 인해 구조가 바뀐 경우에는?
2. Evidence Retriever
선택된 엔티티에 대해 신뢰 가능한 웹 문서(주로 Wikipedia)를 수집하여 이후 추출 단계의 입력으로 제공하는 모듈
3. Knowledge Extractor
수집된 문서로부터 사실(triple)을 추출하며, 규칙 기반 방식과 LLM 기반 방식을 병렬적으로 활용하는 모듈. 두 가지 방식의 추출기를 병행함
(1) Pattern-based Extractor
정규표현식 등을 활용한 미리 정의된 규칙을 이용해서 트리플을 추출함. 확장성은 낮지만, 위키피디아 인포박스와 같은 반정형 데이터에서는 높은 정확성을 보이는 방식
(2) LLM-based Extractor
비정형 또는 다양한 형식의 문서에 활용할 수 있는 추출기
- Prompt Generator: 엔티티 타입에 맞는 ontology sippets(허용 가능한 predicate 목록, 각 predicate의 의미설명, quilifier, 허용 단위, 정규화 필요 여부 등)을 생성함. 전체 온톨로지를 넣지 않고 엔티티 타입별로 축약된 스키마 부분만 넣는 방식
이때 ontology snippets는 (1) 엔티티 타입별 중요 predicate 순위화하고 (2) Wikidata 및 KG 메타데이터를 결합하여 predicate을 확장하며(Predicate 360) (3) 단위, 포맷, 정규화 규칙을 포함한 normalization 설정을 생성하는 내용을 포함한다.이전에 추출하고자 하는 엔티티와 관련된 스키마 정보만 요약해서 프롬프트에 넣어줌으로써 토큰/시간 효율을 높이는 방식을 시도한 적이 있는데, 랜덤 샘플링 아닌 랭킹화 하는 방식에 대해서 구체적으로 알고 싶다.
- Extraction: 프롬프트를 기반으로 JSON 형식으로 출력. 추론이나 생성을 엄격히 금지해서 hallucination을 억제
- Schema Mapping: 추출된 값이 ontology snippet의 predicate 중에서 대응되는지 검토, 연결
- Schema Translation: KG ingestion이 가능한 구조화된 포맷으로 serialize
4. Grounder
LLM이 추출한 사실이 실제 문서 근거에 의해 명시적으로 뒷받침되는지 검증하여 hallucination을 방지하기 위한 모듈. 추출된 사실에서 자연어 형태의 statement를 생성한뒤, 사실인지 판단하는 LLM(프롬프트 기반)으로 T/F를 결정
5. Corroborator
여러 추출 결과를 정규화, 통합하고 신뢰도를 평가하여 최종적으로 KG에 반영할 후보 사실을 결정하는 모듈
최종 선택된 사실은 KG ingestion 파이프라인으로 전달되어 스키마 검증을 거친 뒤 적재된다. 또한 Human Validators로 구성된 KG Quality Team이 매주 랜덤으로 2000개 샘플링된 트리플을 검토하고, 사용자의 선호도를 annotation으로 수집하는 방식으로 지속적인 모니터링을 실시하는 파이프라인을 갖는다.
.
.
.
정형 데이터도 업데이트가 될 때 value의 형태나 단위에 의해서 기존의 predicate, 특히 표준 어휘일 경우 range나 표현이 맞지 않게 될 가능성이 있다. 이 부분을 프롬프트 기반으로 judge process를 구축한다면 자동화에 도움이 될 수 있지 않을까 라는 생각을 했다.
