[논문리뷰] A methodology for Evaluation RAG Systems: A Case Study On Configuration Dependency Validation
Paper Review

글 작성에 ChatGPT를 활용하였습니다.
한 줄 요약: RAG 시스템의 개발은 수많은 구성요소와 설계를 위한 결정 사항들이 있으며, 이를 평가할 수 있는 표준화된, 신뢰가능한 청사진을 제시하고자 한 논문
1️⃣ Introduction
- RAG is not a single technology, but an umbrella of different components, design decisions, and domain-specific adaptations.
- RAG 시스템의 구성
- Preprocess
- Embedded
- Store context documents in Vector DB
- Retrieval
- Final Results
- 구성 요소 별로 다양한 종류가 있으며, 어떤 조합을 했을 때 최적의 성능이 나오는지 하나씩 테스트하면서 확인해야 한다는 특징을 가짐. The final RAG system is, thus, a product of several design decisions and iterations based on empirical evidence about the RAG's effectiveness collected on the way.
- 이 논문에서 제시하는 두 가지 방법
(1) 소프트웨어 개발에서 RAG 시스템을 평가하기 위한 재사용 가능한 경험적 연구 설계의 검증된 청사진 제안
(2) 구성 종속성을 정확하게 검증하는 RAG 시스템
2️⃣ Scenario and Related work
Scenario: Configuation Dependency Validaion
- 현대 소프트웨어 개발에서는 여러 기술(코드 프레임워크, 빌드 도구, 데이터베이스 등)의 조합이 필요하며, 각각의 기술의 Dockerfile 등과 같은 구성 파일을 사용하여 구성하여 일관성 유지가 중요함
- 예를 들어, Spring Boot 애플리케이션의 application.yml 파일과 Dockerfile에서 같은 포트(8080)를 설정해야 애플리케이션이 정상 작동함
- 기존의 종속성 검출 방법(머신러닝, 휴리스틱 등)은 많은 오류를 발생시켜서 실용성이 떨어지는 문제가 있음
- RAG 시스템을 통해 보다 정확하고 기술에 의존하지 않는 종속성 검증 방법을 제공하는 것을 목표로 함
Related Work
RAG for Software Engineering
- 소프트웨어 엔지니어링에서 RAG는 코드 생성 뿐만 아니라 커밋 메세지를 생성하거나 테스트 케이스를 생성하는 등의 방법으로 활용될 수 있음
- 기존에도 비슷한 연구가 진행되었지만, 체계적인 연구 방법론을 사용하여 객관적으로 평가하진 않았음
Evaluation RAG
- RAG 시스템의 평가 기준은 아직 확립되지 않았으며, 다양한 연구에서 제안되고 있음
- e.g. RAGAS, eRAG, RGB 등
- 그러나 기존의 연구들은 대부분 RAG의 개별 구성 요소(Retrieval, Generation 등)의 평가에 초점을 맞추고 있으며, RAG 시스템 전체의 평가 방법론을 제공하지 않음
- 본 연구에서는 RAG 시스템을 연구 질문에 맞춰 체계적으로 평가할 수 있는 방법론을 제시하는 것이 핵심 목표임
Prompt Engineering
- 주요 프롬프트 기법은 다음과 같음
- Zero-shot prompting: 명확한 지침을 포함한 프롬프트를 제공하여 LLM이 작업을 수행하도록 유도
- Few-shot prompting: 몇 개의 입력-출력 예시를 포함하여 LLM이 과제를 학습하도록 도움
- Chain-of-thought prompting: LLM이 단계별 사고 과정을 거치며 더 정교한 응답을 생성하도록 유도.
- RAG 시스템에서 프롬프트 엔지니어링은 RAG 시스템을 효과적으로 활용하는데 중요하지만, 기존 연구들은 대부분 검색 성능을 개선하는데 집중했고, 프롬프트 엔지니어링에 대한 체계적 연구는 부족함
- 본 연구에서는 프롬프트의 영향을 포함하여 RAG 시스템을 평가하는 방법론을 제안함
3️⃣ A Reusable methodology for RAG evaluation
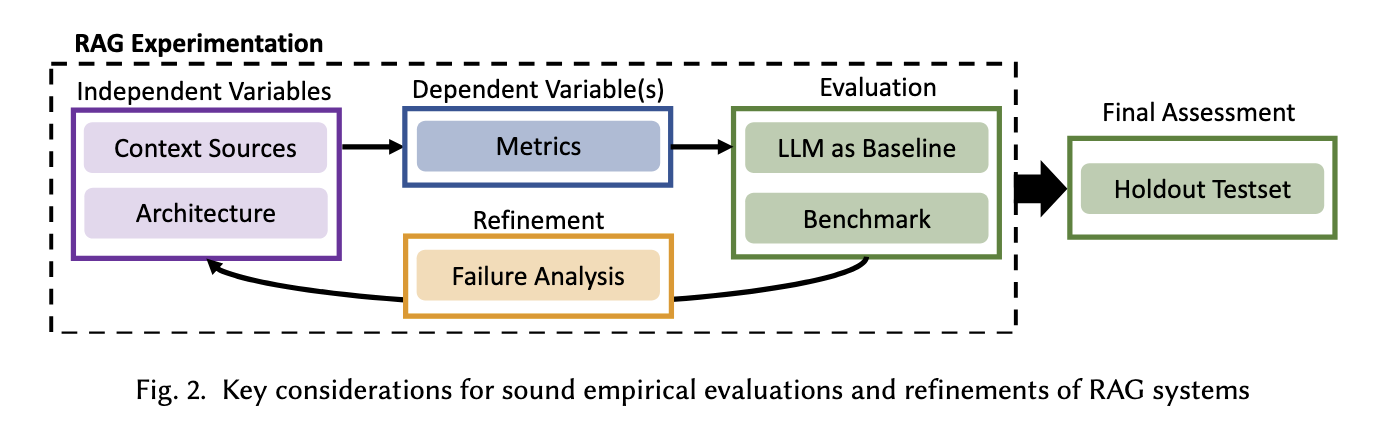
Independent Variables: What do we vary?
RAG 시스템의 성능을 평가할 때 고려해야 할 독립 변수(Independent Variables)는 다음과 같음
- Context resources
쿼리에 해당하는 문맥의 정보를 제공하는 것. 문맥 정보는 웹 검색, 데이터베이스, 사용자 피드백, 과거 데이터 등 다양한 형태가 있고 그들을 개별적으로 사용하거나 조합해서 제공할 수 있음. 이에 따라 성능이 어떻게 차이가 나는지 검토해볼 필요가 있음 - Architecture
RAG는 여러가지 구성 요소로 이뤄지기 때문에 어떤 선택지를 사용했을 때 성능이 어떻게 도출되는 지 검토해볼 필요가 있음
Dependent Variables: What and how to measure?
연구 질문을 실험적으로 평가할 수 있도록 적절한 지표를 선택해야 함. 평가하려는 대상의 작업 유형에 따라서 평가 지표를 구분하면 다음과 같음
- Classification: Precision, Recall, F1-score
- Generation: 정량적 평가가 어려움
문맥 관련성(context relevancy)과 같은 RAG 관련 측정 지표는 검색된 문서가 생성 작업과 얼마나 관련이 있는지를 평가함. 다만, RAG 시스템의 성능을 이해하는데는 유용하지만, 높은 문맥 관련성이 반드시 높은 성능을 보장하진 않으므로 실제 작업의 성능을 직접적으로 파악하기는 어려움. 따라서 Empirical Verify가 필수적임
Evaluation: How to evaluate the RAG system?
RAG 시스템을 효과적으로 평가하기 위한 방법은 다음과 같음
-
Baseline 설정
Baseline은 RAG를 적용한 base model이 될 수 있으며 RAG 시스템을 적용하기 전후의 성능을 비교할 수 있음 -
Benchmark 선정
일관된 평가 데이터셋이 필요하며, 기존의 벤치마크를 활용하거나 새로운 데이터셋을 구축할 필요가 있음. 실제 사용 환경과 유사한 데이터셋에서 테스트하는 것이 중요하며, 가능한 생성 과정과 데이터셋을 공개할 필요가 있음(transparency를 위해서)
Refinements: How to systematically refine the RAG system?
RAG 시스템을 반복적으로 평가하고, 수정하기 위해서는 우선 오류를 분석할 수 있음. 예를 들어, 성능이 낮은 경우 필터링 방식을 수정하거나 검색 엔진을 변경하거나 프롬프트 개선 등의 여러 요소의 개선 사항을 파악할 필요가 있음. 또한 이런 개선 사항을 반영할 때, 프롬프트의 수정 등은 Baseline 모델에도 동일하게 적용하여 동등한 비교가 가능하도록 맞춰야 함.
Final Accessment: How to ensure validity and soundness after refinement and re-evaluation?
최종적으로 RAG 시스템의 성능을 검증할 때는 Holdout Testset을 활용해야 함. 개선된 RAG 시스템이 특정 데이터셋에 과적합 되지 않도록 새로운 데이터셋을 사용하는 것을 의미함. 또한 개선 전후 성능을 비교하여 개선 사항이 실제로 의미가 있는지 확인해야 함. 평가 결과가 일관적이지 않다면, 추가적인 조정과 반복적인 실험이 필요함.
4️⃣ Demonstration of evaluating RAG for configuration dependency validation
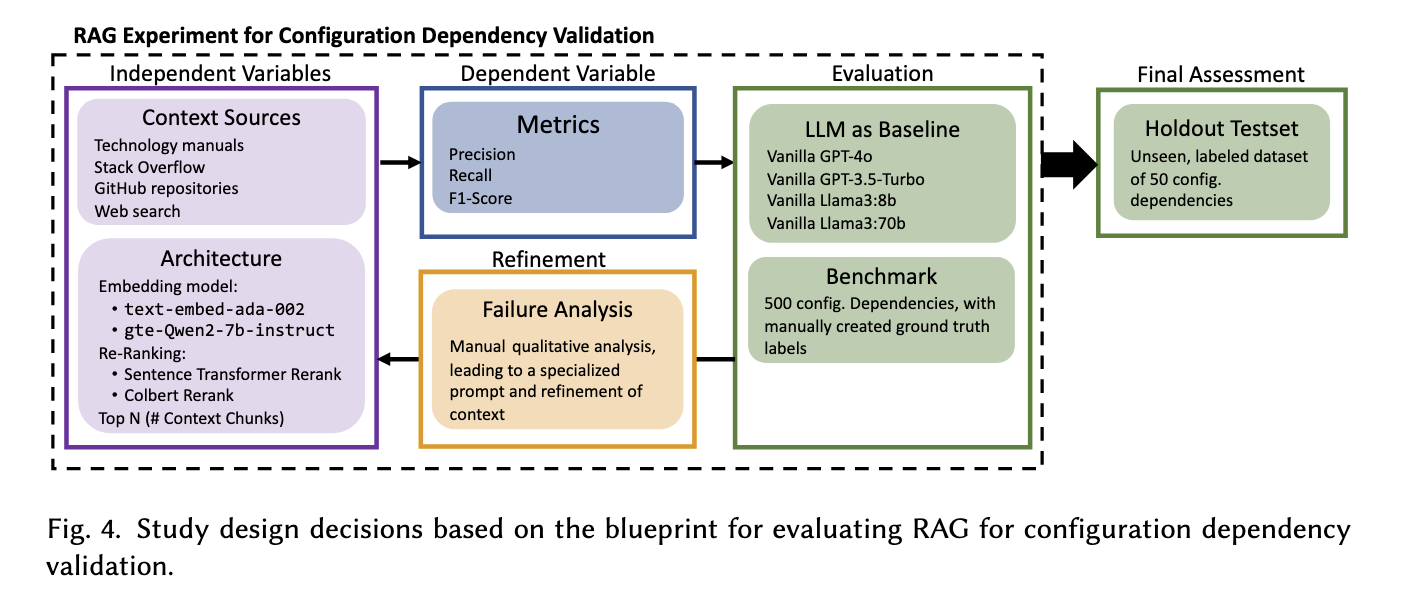
Resarch Question은 다음과 같음
- How effective are vanilla LLMs and unrefined RAG in validatin g configuration dependencies?
- What validation failures occur with vanilla LLMs and unrefined RAG and what refinements can be derived from that?
baseline은 GPT-4o, GPT-3.5-Turbo, Llama3 8B, Llama3 70B로 정함. 평가 데이터셋은 GitHub의 10개 오픈소스 프로젝트에서 500개의 종속성 검증 데이터셋 구축하고, 기존 연구에서 사용된 CfgNet 도구를 활용하여 종속성 후보를 자동으로 탐색함. 이후 연구진이 수동으로 검토하여 gt 라벨링을 진행함. 최종 평가 데이터셋은 새로운 50개의 데이터를 가져와서 평가를 진행
5️⃣ Results
vanilla LLM과 unrefined RAG를 비교했을 때, vanilla의 성능이 더 높게 나타남. 특히, 잘못된 문맥(noisy context)이 포함될 경우 LLM의 판단이 오히려 악화된다는 것을 알 수 있으며, 반드시 RAG를 적용했을 때 성능이 향상되는 건 아니라는 것을 알 수 있음.
주요 오류 유형은 다음과 같음
1. 구성 옵션 상속 및 재정의 오류 → 한 기술에서 다른 기술로 설정이 상속될 때 잘못 해석됨.
2. 구성 값 일관성 문제 → 서로 다른 파일에서 같은 값을 우연히 사용한 경우 오탐(false positive) 발생.
3. 정확한 문맥 정보 → 검색된 문서가 종속성 판단에 실질적으로 도움이 되지 않음.
따라서 다음과 같은 수정을 진행함
1. 프로젝트 별 세부 정보 추가 (모듈의 구조, 환경 설정 등)
2. 프롬프트 개선
3. Few-shot prompt 적용 (유사한 예제 제공)
위 사항들을 개선한 뒤, 개선된 RAG 시스템이 기본 LLM보다 전반적으로 더 높은 정확도를 기록함. 특히, 오픈소스 모델(Llama3 70B)과 RAG를 결합한 모델이 최고 성능(F1-score 0.89)을 달성. 즉, 고성능 LLM을 사용하지 않더라도 RAG 시스템을 최적화하면 더 나은 성능을 얻을 수 있다는 것을 나타냄.
