
논문에서 제시하는 기존 RAG의 한계점은 다음과 같다.
- 엔티티 간의 복잡한 관계를 기반으로 정보를 이해하고 검색하는 능력이 제한됨
- 엔티티와 상호 관계 전반에 걸쳐 일관성을 유지하지 못하고, 사용자 쿼리를 완전히 처리하지 못하는 응답을 생성할 수 있음 (복수의 내용들을 종합, 연결하여 종속적이고 상호적인 답변을 생성해야 하는 경우의 처리가 어려움. e.g. '전기자동차의 증가가 도시의 대기질과 대중교통 인프라에 어떤 영향을 미치나요?'라는 질문에 대하여 각각의 정보는 잘 찾을 수 있지만, 그 영향관계에 대한 답변을 생성하지 못함)
이를 해결 하기 위해 텍스트 인덱싱과 검색 프로세스에 그래프 구조를 적용하는 방식을 제안한다. 그래프 구조는 다양한 엔티티 간의 상호 관계와 의존성을 효과적으로 표현할 수 있는 만큼 여러가지 정보를 종합하여 상황에 맞고 일관된 응답으로 통합하는데 적용할 수 있다.
그래프를 빠르게 구축하고 쿼리해서 RAG에 적용하기 위해서 다음 세 가지의 주요 과제를 해결하고자 했다.
- 포괄적인 정보 검색
모든 문서에서 상호 의존적인(inter-dependent) 엔티티의 전체 맥락을 포착하는 포괄적인 정보 검색을 보장한다. - 검색 효율성 증대
그래프 기반 디식 구조에 비해 검색 효율성을 향상시켜 응답 시간을 단축시킨다. - 새로운 데이터에 대한 신속한 적용
새로운 데이터 업데이트트를 빠르게 적용하여 동적 환경의 시스템에서도 적용할 수 있도록 한다.
Architecture
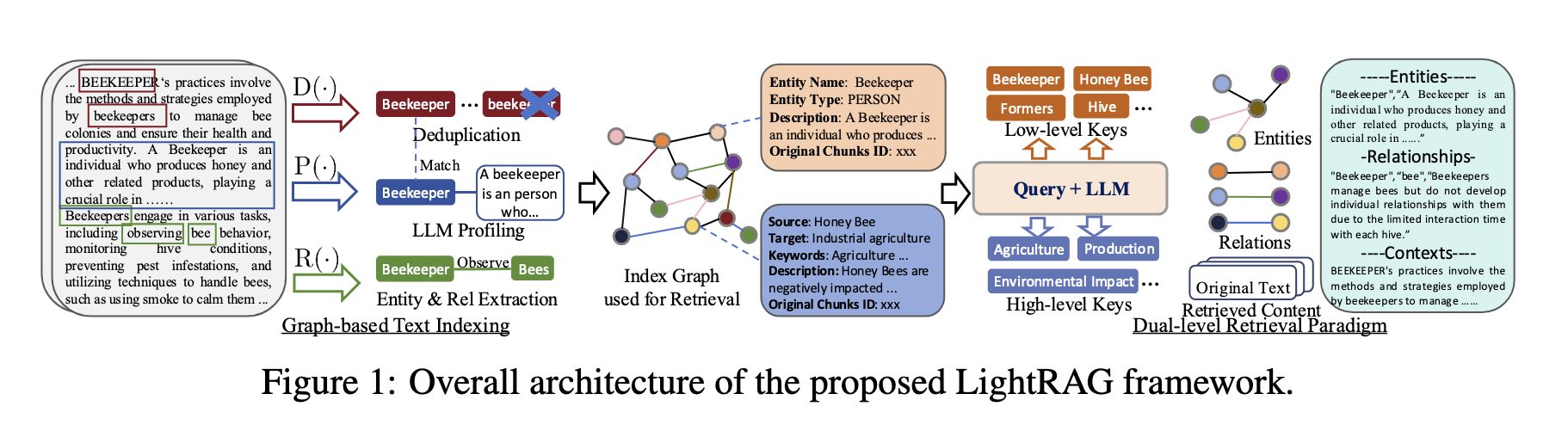
LightRAG는 그래프 기반의 data indexing과 두 단계 검색(retrieval) 구조를 갖는다. 이 때 두 단계는 특정 정보에 대한 정확한 정보에 초점을 맞춘 개념검색(low-level retrieval)과 더 넓은 주제를 포괄하는 세부검색(high-level retrieval)로 구분된다. 또한 그래프 구조를 벡터 표현과 통합함으로써 관련 엔티티와 관계의 효율적인 검색과 함께 지식그래프를 통한 포괄성을 향상할 수 있다고 한다.
각 구조를 하나씩 자세히 살펴보겠다.
(1) Graph-Based Data(Text) Indexing

우선 LightRAG는 문서를 더 작고 관리하기 쉬운 피스로 분할(segmenting)한다고 한다. 이후 LLM을 활용하여(위와 같이 prompting을 통해서) 각 문장에서 엔티티와 관계를 식별하고 추출하여 KG를 생성한다. 이 데이터를 생성하기 위한 세 가지 처리 단계는 다음과 같다.
1. Extracting Entities and Relationships
문서D에서 엔티티(V)와 관계(E)를 추출하는 과정이다. 이는 LLM에서 prompting을 통해서 진행된다(Neo4j나 기타 LPG를 구축하는 방식과 동일함).
2. LLM Profiling for Key-Value Pair Generation
엔티티(V)와 관계(E)에 대해서 Key-Value쌍을 생성하기 위해 LLM 기반 프로파일링(P) 기능을 사용한다. 이때의 key는 단어나 짧은 문구를 사용해서 효율적인 검색을 할 수 있도록 하고 value는 관련 내용을 요약한 텍스트 단락이다. (V가 Key가 되고 E가 Value가 될 때, Key는 여러개의 Value를 가질 수 있음)
3. Deduplication to Optimize Graph Operations
조각 별로 나누어서 엔티티와 관계를 추출했으므로, 서로 다른 조각에서 동일한 엔티티와 관계를 식별하고 중복을 제거한다. 중복을 제거함으로써 오버헤드를 줄일 수 있다고 한다.
❓ 중복은 어떤 방식으로 제거하는가?
데이터 reconcile이나 기타 통합 작업을 할 때 항상 문제가 되는 부분이 통합의 key, 즉 두 엔티티가 정확히 같은 것이라는 걸 어떻게 인식하냐는 것이다. 여기서도 엔티티의 이름은 같을 수 있지만, 다른 의미를 가질 수 있을텐데 이를 어떻게 구분하는지 궁금했다.
새로운 데이터가 발생하는 경우, 추가분만 기존과 동일한 방식으로 엔티티와 관계를 추출하여 그래프를 만들고 합칩합을 취하여 원본 그래프와 결합해준다.
기존 연결의 무결성(Integrity)는 보장할 수 있지만, 중복되는 값을 제거하는 단계는 없는 걸까?
(2) Dual-Level Data Retrieval
검색의 수준/단계
사용자의 질문은 세부적일수도 있고, 포괄적인 내용을 다뤄야 할 수도 있다. 쿼리의 수준을 두 가지로 분리하면 다음과 같다.
- Specific Queries
상세한 수준의 쿼리로, 특정 엔티티와 관계를 정확하게 검색해야 한다. (e.g. '오만과 편견'을 쓴 사람은 누구인가?) - Abstract Queries
특정 엔티티에 직접적으로 연결되지 않은 넓고 포괄적인 주제의 검색을 의미한다. (e.g. 인공지능이 현태 교육에 어떤 영향을 미치는가?)

이러한 두 수준의 쿼리를 모두 수용하기 위해 LightRAG는 두 단계의 검색 전략을 사용한다고 한다. low와 high는 prompt에서 제시한 개념과 예시에 의해서 분류된다.
1. Low-level Retrieval
관련 속성 또는 관계와 함께 특정 엔티티를 검색하는데 중점을 둔다. 세부적이며 정확한 엔티티, 관계를 추출하는 것을 목표로 한다.
2. High-level Retrieval
광범위하고 포괄적인 주제에 대해서 검색하는데 중점을 둔다. 더 높은 수준의 개념 및 요약에 대한 인사이트 제공을 목표로 한다.
Vector + Graph Retrieval
벡터 표현과 그래프 구조를 결합한 검색방식인데, 논문의 설명만 보면 이해하기 다소 어려운 부분이 있다. 이 글에서 코드와 함께 설명한 부분을 참고했다.
1. Query Keyword Extraction
주어진 쿼리에 대해서 local query keyword k(l)와 global query keyword k(g)를 모두 추출한다. (low-level이 local, high-level이 global)
이때 local과 global은 위에서 low와 high를 구분하는 것과 동일한 기준으로 구분되어야 할 것 같다.
(+) appendix의 figure3를 보면 키워드를 추출한다는 의미가 단순히 쿼리에 있는 단어들을 추출하는 것이 아닌, 명사형으로 만든다거나 high-level의 경우 쿼리를 기반으로 관련된 키워드들을 새로 생성하기도 하는 것 같다.
2. Keyword Matching & 3. Incorporating High-Order Relatedness
2, 3 부분은 논문의 글만 봐서는 잘 모르겠다. 위 블로그의 글과 코드(lightrag/operator.py)를 참고해서 정리해보겠다.
우선, Keyword Matching은 효율적인 vector DB를 사용해서 k(l)를 후보(candidate) 엔티티와 일치시키고, k(g)를 global key에 연결된 관계와 일치시킨다고 설명하고 있다.
다시 정리하면, 쿼리에서 뽑은 키워드 중에서 local-keyword로 분류된 것은 이전에 데이터셋에서 key를 뽑아서 인덱싱 해둔 것과 vector 기반의 similarity를 통해서 유사한 것 top-k(min k=10)를 뽑고(get_vector_context() 함수에서 진행), global-keyword로 분류된 것은 객체 간의 관계까지 포함해서 Multi-hop(subgraph)구조까지 고려해서 검색한다는 것이다.
retrieved data들을 rerank하는 부분은 prompt에 명시되어 있다.
When handling information with timestamps:
1. Each piece of information (both relationships and content) has a "created_at" timestamp indicating when we acquired this knowledge
2. When encountering conflicting information, consider both the content/relationship and the timestamp
3. Don't automatically prefer the most recent information - use judgment based on the context
4. For time-specific queries, prioritize temporal information in the content before considering creation timestamps
❓ 단순히 키워드를 벡터화 시켜서 similarity를 시키는 게 맞는가..? 혹은 단어가 아닌 chunk 단위로 가져오는 것인지..?
❓ Subgraph의 기준은 어디까지 인가? Depth를 어디까지 주는지는 코드 상에서 결정하는지?
Retrieval-Augmented Answer Generation

Appendix에는 위와 같은 예시를 제시한다.
[Query part] '영화 추천 시스템을 평가하는 가장 유용한 측정항목은 무엇인가?'라는 쿼리가 들어왔을 때, [Keywords part] high-level keyword와 low-level keyword를 각각 추출(생성) 한다. [Retrieval Context part]이후 각 level에서 retrieve해온 정보들을 다시 Entities, Relationships, Sources로 분류하고 [LLM Response part] 최종 응답 LLM에 augmented data로 넣어줘서 답변을 출력한다.
Graph RAG와의 차이
local과 global을 구분하고, text를 LPG 그래프로 만들 때 거의 전적으로 prompt에 의존해서 진행한다는 점 등 MS의 Graph RAG와 상당 부분 유사하다고 생각했지만, 논문에서는 LightRAG가 커뮤니키 기반 traversal 기반보다 오버 해드가 현저히 적다고 설명한다. Graph RAG는 쿼리의 커뮤니티를 찾기 위해 모든 커뮤니티와 유사도를 계산하고, 해당 커뮤니티 하위로 들어가는 방식이라면 LightRAG는 엔티티와 관계를 중심으로 검색하기 때문에 더 효율적이라는 것이다.
Subgraph를 어느 범위로 정의하냐에 따라서 성능 차이가 있을 것 같다고 생각한다.
(+) 이런 방식으로 했을 때 high-level에서 뽑은 그래프 부분과 row-level에서 뽑은 그래프 부분이 멀리 떨어져 있을 가능성은 없을까? 이런 경우 그래프 자체를 잘 만들지 못했다고 봐야 할까?
참고자료
