
몇 달 전쯤, 커뮤니티에서 나름 핫했던 논문이었던 것 같다. 룰 기반의 하드코딩된 추론 방식이나 fine-tuning 없이 인간의 메모리 기능과 유사한 방식으로 일반 목적의 모델의 성능을 향상시키는 'AgentFly'를 제안한 논문이다. 즉, 에피소드식으로 'Case Bank'에 저장한 과거의 memory를 기반으로 유사한 상황의 의사결정을 할 수 있도록 하는 방식을 의미한다.
프레임워크를 보고 난 느낌은 Fine-Tuning을 하지 않고, 넓게 보면 prompt engineering이지만, 이때 강화학습의 매커니즘도 적용한다는 점에서 흥미로웠다. 하지만 Q-함수를 써도 여전히 벡터 기반의 유사도로 situation을 찾아야 하지 않을까 라는 의문이 들었고, 실제 적용 측면에서 subtask를 나누는 프롬프팅과 MCP 서버를 통한 tool orchestration 부분을 깃헙 코드를 검토해봐야겠다는 생각을 했다. 또한 GAIA 등 범용적인 분야의 복합 추론 성능을 평가하는 방식 부분에서도 참고할 수 있을 것 같다.
한편, CBT나 MDP 등 들어는 봤지만 정확히는 모르겠는 개념들이 많이 등장하고, 기본적인 기법들을 수식적으로 설명하는 논문이다. 간단하게 개념들을 알아보면서 프레임워크 위주로 이해했다.
1️⃣ Introduction
(1) fixed workflows and hard coded reasoning (2) updating the LLM itself through parameter tuning via fine-tuning or reinforcement learning 이 두 방식을 사용하지 않으면서 어떻게 효율적으로 LLM의 성능을 향상시킬 수 있을까?
논문에서는 CBR(case-based reasoning) 원칙을 기반으로 메모리에 저장해 둔 과거에 풀었던 문제를 기반으로 해결하는 방식을 제안한다. AgentFly는 'A planner', 'a tool-enabled executor', 'a growing Case Bank(과거의 사건, 에피소드를 저장하는 곳)'으로 구성된다.
2️⃣ Related Work
Continual-learning in LLM Agent Systems
LLM agents를 위한 continual-learning은 크게 (1) Parametric approaches 와 (2) Non-parametric approaches로 구분된다. 전자는 강화학습이나 fine-tuning과 같은 post-training을 통해서 LLM의 파라미터를 업데이트 하는 방식으로, 상당한 컴퓨팅 자원과 연산이 필요하며 정보의 손실(학습을 한다고 해서 100%반영된다고 볼 수 없으므로)이 발생할 수 있다. 또한 장기적으로 학습을 위한 데이터를 준비하고 지속적으로 업데이트하기에는 한계가 존재한다.
이와 달리, LLM의 파라미터는 고정한 채, 외부 정보를 프롬프트 기반으로 반영하는 방법이 있다. 인간의 인지 시스템 역시 메모리 기반으로 작동하는데, 기억은 분할되고 선택적으로 재생되는 방식으로, 초기 AI 패러다임의 CBR에 영향을 주었다. 최근 언급되는 RAG 시스템 역시 CBR을 기반으로 작동하지만, 일반적으로 정적 문서 코퍼스를 쿼리하고 지속적인 적용을 위한 매커니즘이 부족하다는 한계가 있다.
Tool-augmented LLM
Agents는 컨텍스트 한계와 연산의 제한점 등을 극복하기 위해 웹 검색과 같은 외부 도구를 사용한다. 복잡한 질의를 처리하기 위해서는 다중 홉 도구 호출이 필요한 경우가 많으며, 이를 위해 최근 AutoGEN, OWL, DeerFlow와 같은 다중 에이전트 파이프라인이 제안되고 있다고 한다. 또한 정적인 문제 해결이 아닌 동적으로 에이전트 환경을 추론을 학습하는 Agentic Reinforcement Learning나 Toolformer를 포함한 지도학습 등의 방식도 시도되고 있다. 그러나 여전히 명확한 계획 없이 호출할 도구와 호출 시기를 결정하는 것은 한계가 있으며, 사례 기반 추론의 필요성을 언급한다.
Agent Memory Mechanism
최근 연구는 Agent에 명시적인 메모리 구조를 부여하는데 중점을 두고 있는데, 고정된 방식의 디자인은 유동성이 적으며, human feedback을 받는 방식 역시 사전에 정의된 방식에 한정적이라는 특징을 갖는다. LLM Agents는 시간이 지남에 따라 장기 기억을 더 많이 갖추고 지식을 축적, 확장하며 성장해야 한다. 이를 위해 오래되고 유용성이 낮은 정보는 약화되고 중요한 정보를 강화하거나, 로그 혹은 typological network를 통해 기억을 유지하는 방법 등이 제안되고 있다. 본 논문에서는 메모리 증강(memory-augmented) MDP(Markov Decision Process)로 planning 과정을 공식화하고, online soft Q-learning을 통해 에피소드 별로 선택적 학습을 통해 파라미터를 fine-tuning 하지 않고 지속적인 적용이 가능한 방법을 제시한다.
✅ Markov Decision Process란?
MDP는 쉽게 '지금 어떤 행동을 했을 때 앞으로 어떤 결과가 생길지를 고려해서 가장 좋은 선택을 하는 방법'을 의미한다. MDP는 일반적으로 State(현재 상태), Action(가능한 행동), Trasition Probability(행동에 따라 바뀔 수 있는 상태의 확률), Reward(행동 후 얻는 보상)로 구성된다. 즉, 현재 상태를 알면 미래를 예측할 수 있다는 의미로, 지금 상태(S)에서 가능한 행동(A) 중에서 앞으로 받을 보상(R)의 합이 가장 커지게 하려면 어떤 행동을 해야 할 지 결정하고, 이를 Policy로 규정한다.
3️⃣ Methology: Memory-Based MDP with Case-based Reasoning Policy
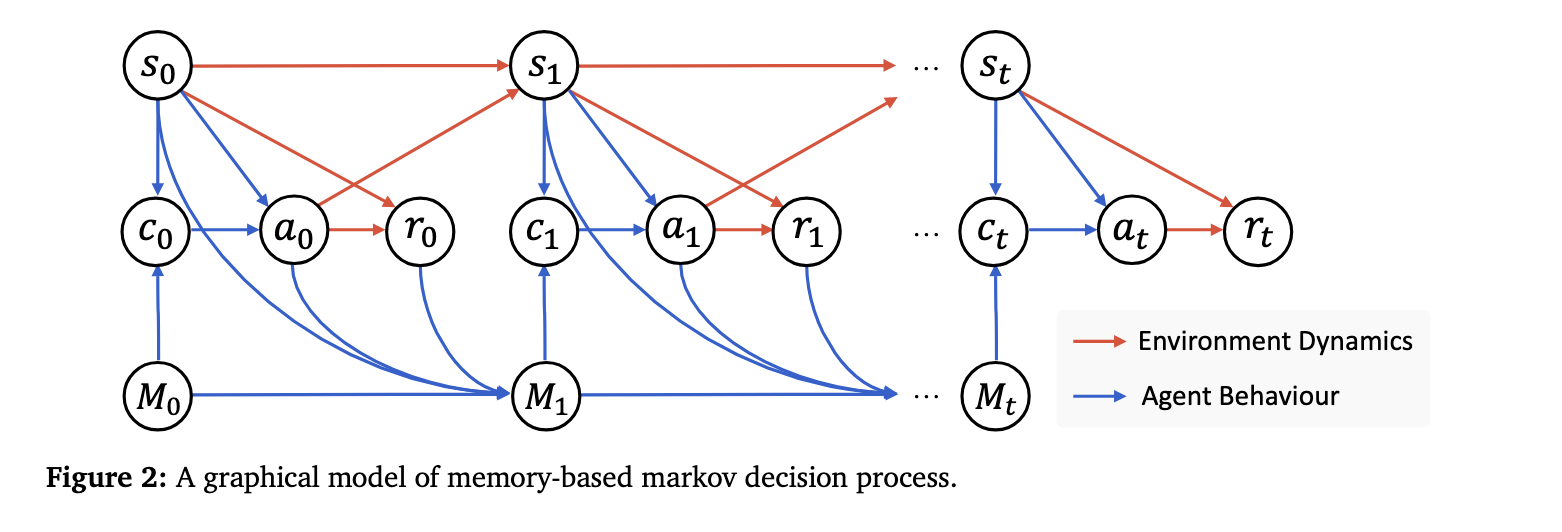
M-MDP는 위와 같은 구조로 구성된다. 기본 MDP와의 주요 차이점은 과거 경험의 집합으로 메모리 공간(M)을 도입한다는 점이다. 각 요소는 아래와 같은 의미를 갖는다.

S: State spaceA: Action spaceP: transition dynamicsR: reward functionM: memory space
CBR 기반 Agent는 현재 상태와 과거 경험에 대한 유한한 기억을 기반으로 결정을 내린다. 수식적 설명은 패스하고 최종적인 확률 계산 부분을 보면, 시간 t=0 부터 T-1까지 에이전트가 환경과 상호작용하면서 경로 τ를 따라갈 확률을 계산한다. 이때 (1) Retrieve 부분은 현재 상태에서 메모리속 케이스 중 어떤걸 참고할 지 선택하고, (2) Reuse&Revise 부분에서는 LLM이 참고한 사례를 기반으로 행동을 생성한다. (3) Evaluation에서는 행동의 결과로 보상을 계산하고, 이 결과를 (4) Retain에서 메모리에 추가한다. 이후 (5) Transition은 다음 상태로 이동하는 부분으로 구성된다. 즉, 이 모든 과정이 T번 반복하면서 Agent는 새로운 경험을 축적하고 지식을 확장하게 된다.
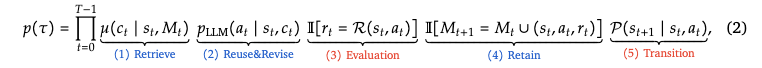
Soft Q-Learning은 과거 메모리 기반으로 최적의 참조 케이스를 가져오기 위해 policy를 학습하는 것을 의미한다. 현재 상태와 메모리가 주어졌을 때, 에이전트는 메모리의 한 케이스를 선택하고 이를 참고해서 수행할 행동을 생성한다. 이를 기반으로 보상이 생기고 그 결과 메모리가 갱신되며 그 다음 상태로 이동하는데, 이 과정에서 어떤 케이스가 큰 보상을 주는지 학습하게 된다. Soft Q-learning은 Maximum Entropy RL 방식을 통해 최적의 케이스 뿐만 아니라 다양한 경험을 통해 더 안정적인 학습을 할 수 있도록 한다.
Enhanced Q-Learning은 Soft Q-learning이 자연어로 표현된 비슷한 문장, 맥락의 상태의 유사도를 처리하기 어려우며, Q(기대 보상)을 직접 학습해야 한다는 한계를 보완하기 위한 방법이다. 즉, 완전히 새 상태가 들어와도 기존의 상태, 케이스와 유사도를 계산해서 유사한 과거 경험들의 Q값을 가중평균으로 계산한다. 따라서 Q함수를 직접 학습할 필요 없이 사례 기반으로 추정하는 방식을 적용한다.
[generated by ChatGPT]
4️⃣ Implementation: Deep Research Agent
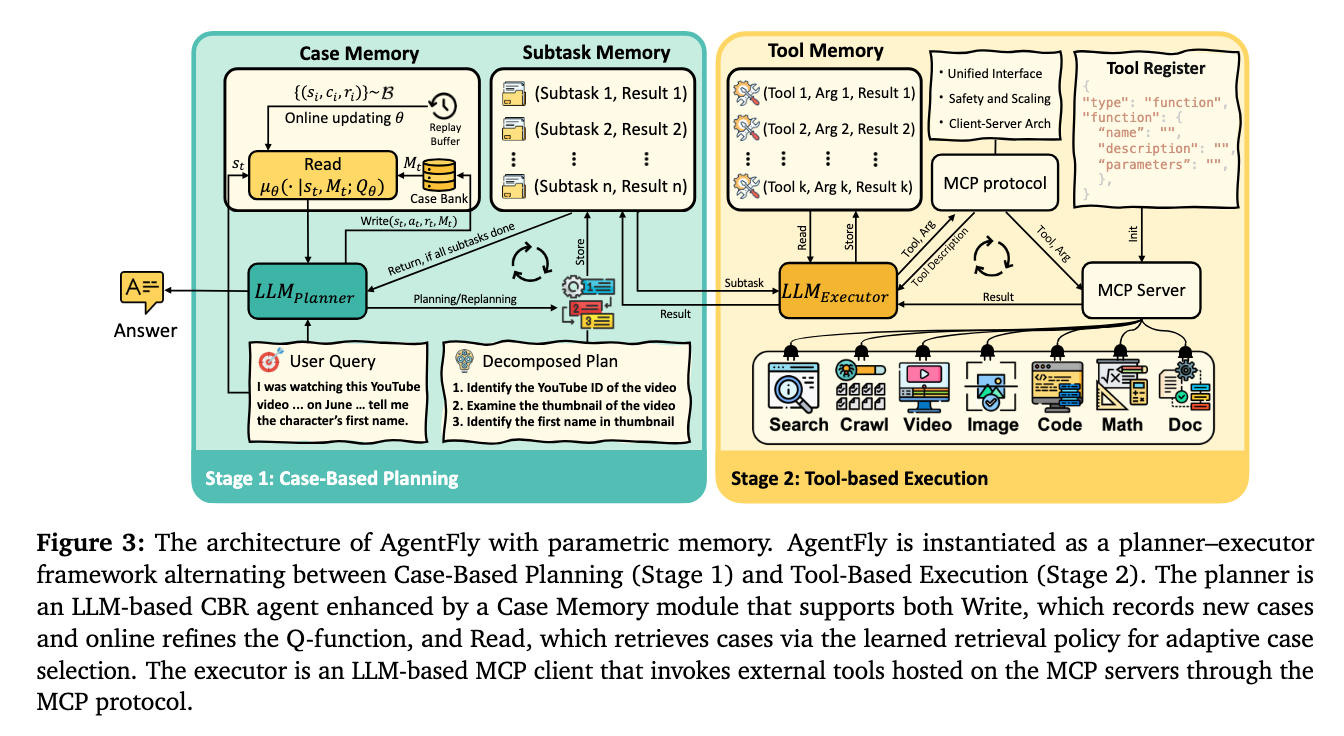
다양한 도구를 사용해서 복합 추론을 통해 답변을 도출하는 긴 호흡의 프로세스가 필요한 복잡한 질의를 처리하기 위해 AgentFly는 Planner와 Executor를 분리해서 진행한다. 이때 다음 세 종류의 메모리가 사용된다.
- Case Memory
: high-level planning을 위한 사전적인 케이스들을 벡터로 저장하는 메모리. 성공/실패 여부를 함께 기록하고 새로운 케이스가 생길때마다 바로바로 업데이트 된다는 특징이 있음. non-parametric memory retrieval - Subtask Memory
: active 서브 태스크들과 그 결과를 텍스트 기반으로 저장하는 메모리 - Tool Memory
: 각 서브태스크에서 상호작용하는 도구들의 로그를 텍스트 기반으로 저장하는 메모리. 외부 도구는 검색 엔지, 크롤러, 멀티모달 작업 처리기(e.g. 이미지는 VLM을 사용해서 캡션을 추가하고 오디오는 자동음성인식을 통해 텍스트로 변환), 연산 수행자, 코드 작업기 등이 포함됨.
Stage1: Case-based Mangement
Planner는 LLM기반 CBR 에이전트로 동작한다. 사용자의 지시사항이 입력되면, Case Memory에서 관련된 사례 triplets(si:과거의 작업, ai:그 작업에 대한 계획, ri:계획의 성공여부)을 검색한다. 검색 방법으로는 유사도 기반의 검색기와 온라인 업데이트 되는 Q-함수를 사용하는데, 이를 통해 parametric 기억과 non-parametric 기억을 모두 활용할 수 있다고 한다.
✅ 온라인 업데이트 되는 Q-함수란 새로운 경험이 발생할 때마다 Q 값을 갱신하는 방식(=online)의 강화학습 원리를 적용한 검색 함수를 의미한다. 강화학습은 상태 s에서 행동 a를 취했을 때 얻는 기대보상을 기반으로 점진적으로 유용한 사례를 더 잘 선택하도록 학습하는 방식이다. 따라서 단순히 유사도 기반으로 과거와 유사한 사례만을 찾는게 아닌, 가장 성공적인 사례를 찾을 수 있다는 점에서 장점을 갖는다.
포인트는 Q-함수를 어떻게 구성하냐는 건데, 생각하기론, 강화학습을 위한 데이터셋 형태를 만들어주고(triplet 형식) 궁극적인 '유사한 상황'을 찾기 위해선 벡터 기반의 계산을 해줘야 할 것 같다. 즉, 유사한 상황들을 쭉 찾은 뒤, 성공률인 Q값을 정렬해서 가장 성공적이었던 action을 찾아낸다는 것이다.
이후 검색된 사례들을 기반으로 하위 작업들을 구성하고 Subtask Memory가 각 하위 작업과 실행과 execution을 통한 결과를 관리하고(이 부분에서 각 하위 작업이 executor와 연결됨), Planner는 이 결과들을 종합해서 작업 완료 여부를 평가한다. 작업이 완료되지 않았다고 판단한 경우 새로운 계획을 다시 수립해서 이 과정을 반복하고, 완료된 경우 최종 결과를 반환하고 Case Memory를 업데이트한다.
Stage2: Tool-based Execution
분리된 개별 하위 작업들은 실제 실행을 위해서 Stage2의 Executor와 연결되는데, 이때의 Executor는 범용 LLM으로 구성되고 MCP 프로토콜을 통해 작업을 수행한다. 즉, 개별 하위 작업들은 독립된 에피소드 형식으로, Tool Memory를 통해서 적절한 외부 도구를 호출하여 사용하는 등 복합적이고 유연한 도구 조합을 사용할 수 있는 것이다. 그리고 이 모든 실행 기록은 SubTask Memory에 저장되고, Planner는 향후 이 기록들을 기반으로 후속 판단(replan 혹은 완료 판정)을 내리게 된다.
5️⃣ Experiments
Datasets
AgentFly의 복합 추론과 multi-step 작업의 성능을 평가하기 위해선 그만큼 복잡한 질의로 구성된 평가 데이터세트가 필요하다. 평가 데이터셋의 선정 기준에 따라 네 가지 세트를 선정했다. 세부적인 데이터 구성과 규모를 알고 싶다면 '5.1 Datasets'부분을 읽어보면 된다.
(1) long-horizon tool use and planning: GAIA
(2) real-time web-based research: DeepReseacher
(3) concise fatual accuracy: SimpleQA
(4) exploration at the frontier of human knowledge: HLE
평가는 질문 단이도 순으로 level1(5단계 정도의 단이 도구 사용이 필요한 질문), level2(5~10개 정도의 복합 도구를 요구하는 질문), level3(50개 이상의 단계와 도구를 자유롭게 사용해야 하는 질문)로 구분한다.
Model Configurations
- Planner: GPT-4.1
- Executor: o3, o4-mini
- Image processing: GPT-4o
- Video Agent: Gemini 2.5 Pro
- Audio Agent: Assembly AI
- Encode model: SimCSE
Experimental Results
성능 평가 결과, Deep Researcher 벤치마크는 기존은 COT+RAG 조합보다 AgentFly(MCP 포함) 도구의 F1 score가 약 30% 정도 높았다. 이는 실시간 온라인 검색 도구가 정적인 DB보다 높은 성능을 낼 수 있다는 것을 의미한다. 장기 추론과 도구 조합도를 평가할 수 있는 GAIA의 경우, Manus, Aworld, OWL 등과 같은 기존 오픈소스 에이전트 프레임워크보다 성능이 높았으나 여전히 고급 추론과 복잡한 도구 협업은 어려워했다. HLE(Humanity Last Exam)은 전문적이고 흔하지 않은 도메인의 복잡 추론 능력을 평가하는데, 25.32%의 GPT-5 다음으로 가장 높은 성능을 보였다(24.4%). 또한 단일 홉의 사실 기반 QA 질문을 통해 신뢰성과 환각 정도를 측정했을 때, 정확도가 95%로 평가 모델 중 가장 뛰어났다.
종합적으로, AgentFl는 실시간 검색과 장기적인 계획 수립과 수행, 단순 QA 등 전반적은 영역에서 안정적인 성능을 보인다는 것을 논문에서 보여주고 있다.
Ablation Studies
AgentFly의 성능에 가장 큰 영향을 주는 요소를 파악하는 단계이다. 하이퍼파라미터로는 Executor를 offline으로 두는지 online으로 두는지와 CBR의 포함여부로 둔다. offline Executor의 의미는 planner, case memory와 모든 외부 도구를 제외하고 단순히 LLM 자체의 지식만 사용하는 방법이다. CBR의 경우, 앞선 테스트(Table3)에서 검색된 사례의 수(K)를 늘리면 계산 비용 증가와 노이즈가 발생할 수 있으므로 K를 0부터 32까지 2의 배수로 측정했고,그 결과 K=4일때 성능이 가장 뛰어났다. 또한 4개 이상일 때 성능이 일부 감소하는 것을 통해 일반적인 few-shot prompting과 달리, 고품질의 적은 사례가 성능에 영향을 준다는 것을 확인했다.
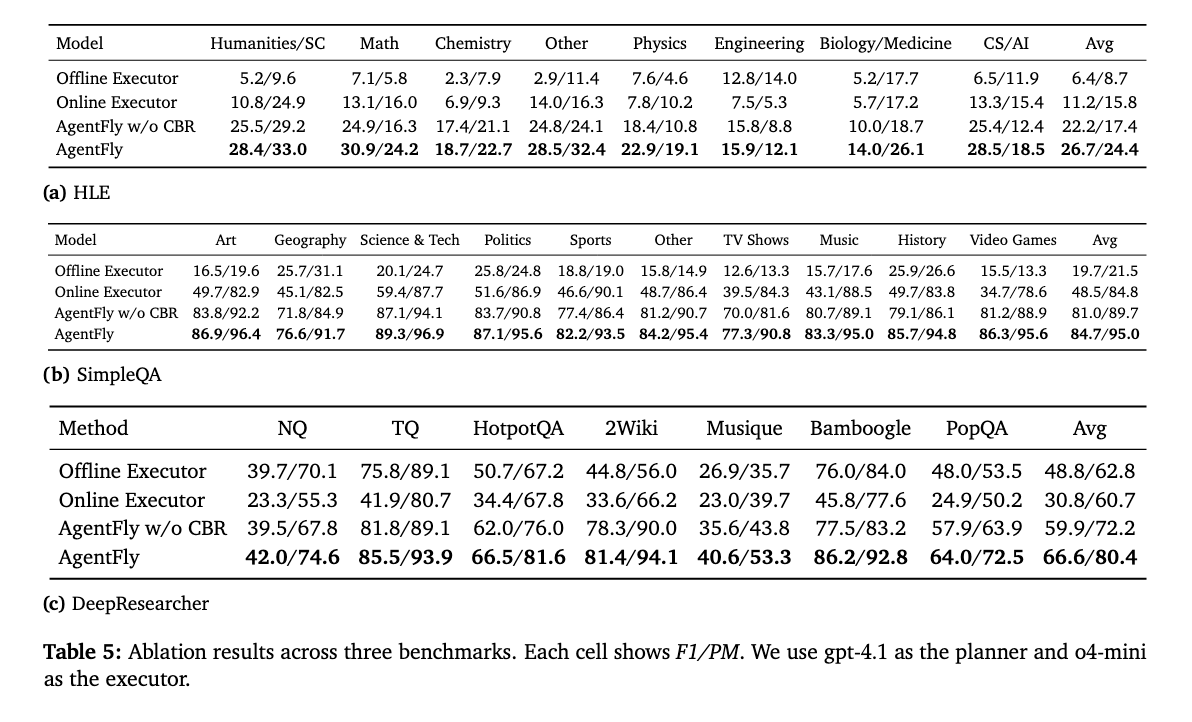
평가 결과, 모든 벤치마크 데이터셋에서 offline 대비 online executor가 환각 현상을 줄어들고 F1 score와 PM(Partial Match) 점수가 높아졌다. 한편 HLE의 경우, CBR이나 online executor의 영향이 가장 적었는데, 아무래도 특정 도메인 데이터를 포함하거나 특화된 프로세스를 갖고 있지 않기 때문인 것 같다.
token size와 비용의 경우, 예상한대로 level3, 즉 심층 질문의 경우에 가장 input/output token 길이가 길고 비용이 높았다.
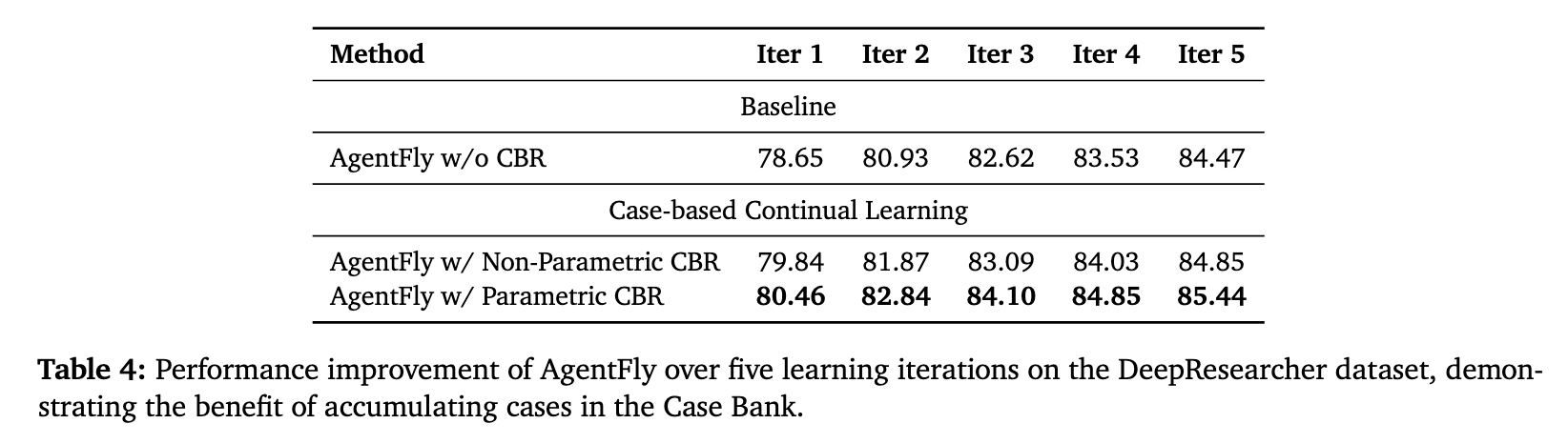
한편, parameter CBR의 여부에 따른 성능도 비교하는데, CBR이 없을 때보다 있을 때 성능이 훨씬 향상됐다. 또한 iteration을 늘릴 수록 정확도가 점진적으로 향상된다는 점에서 파라미터 업데이트 없이 메모리 기반 접근법으로도 성능 향상을 낼 수 있다는 것을 확인했는데, Case Bank가 포화되면 될 수록 성과 개선의 폭은 미미했다. 즉, 과도한 반복이 모델의 성능에 큰 도움을 주진 않는다는 것이다.
Case Bank가 3천개 이상이 되면 참조해야 하는 정보가 너무 커져서 필요한 정보를 가져오기 힘들다는 의미인지, 테스트 케이스에 한정해서는 3천개의 케이스가 거의 모든 상황을 다 포함해서 성능이 고정되는건지 궁금하다. 이해하기론 후자인데, 그렇다면 Case Bank의 한계(?)가 어디까지 일지, 연산량의 문제는 없는지 등의 의문점이 있다.
6️⃣ Discussion and Analysis
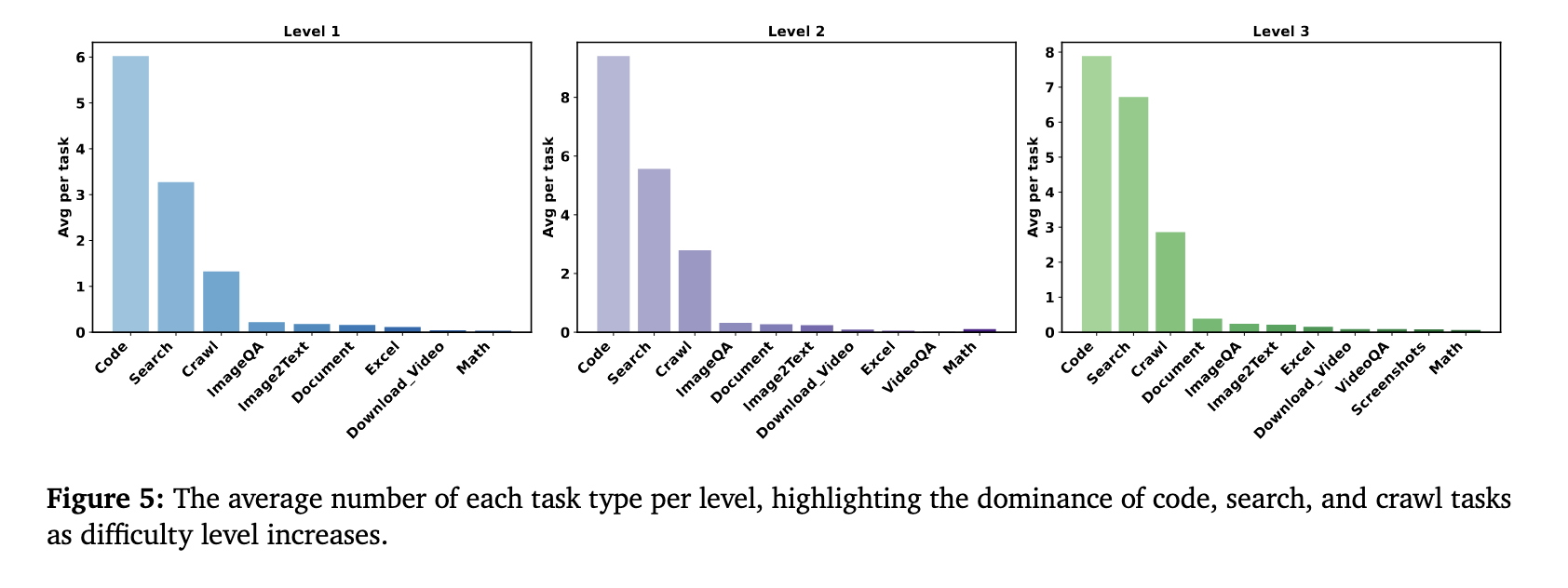
외부 도구 사용 정도를 보면 Code, Search, Crawl 순으로 많이 사용되는데, 한가지 특이한 점은 어려운 질문일수록(Level3) 단순히 MCP를 사용해서 더 많은 도구를 호출하는 형태가 아닌 모델 내부 추론에 더 의존한다는 점이다. 즉, 복잡한 문제를 풀기 위해 시도할 수 있는 방법으로 더 많은, 고성능의 도구를 연결하는 것과 함께, 모델이 계획하고 메모리를 수집하며 이를 기반으로 종합적인 판단을 할 수 있도록하는 방법에 대한 연구도 중요하다는 점이다.
이 부분이 중요한 포인트라고 생각하는데, 수행하는 작업의 특성에 따라 다르겠지만, 현재 수준에서 인간이 Agent를 활용하는 범위가 한정적인 만큼 MCP를 통해서 호출하는 도구도 한정적이다. 따라서 일정 수준의 도구 연결은 필요하지만, 고도의 작업을 수행하기 위해서는 새로운 단일 도구가 필요한 것이 아닌, 기존 도구들을 복합적으로 활용하는 방법과 도구 사용 결과를 종합하는 모델 내부의 추론 과정이 최종적인 결과를 좌우하게 되는 것이다.
한편, Planner 모델을 설계할때 Fast Planner(빠르고 직관적인 계획)와 Slow Planner(신중하고 깊이 생각한 계획)로 구분한 뒤 성능을 측정했을 때, Fast Planner가 보다 문제를 효과적으로 세부 태스크로 나누고 간결한 계획을 세워서 성능이 좋았다. Slow Planner의 경우 불필요한 문맥과 중복된 정보를 생산하여 오히려 혼동을 주었다.
