[논문리뷰] SM3-Text-to-Query: Synthetic Multi-Model Medical Text-to-Query Benchmark
Paper Review

- 논문링크
- Medium post: Are LLMs Better at Generating SQL, SPARQL, Cypher, or MongoDB Queries?
- GitHub-SM3-Text-to-Query
이 논문은 의료분야 데이터의 합성 멀티모달 Text-to-Query 벤치마크를 소개한다. EHR(Electrobnic health records, 진료기록지 정도로 이해하면 됨)은 RDB, document store, graph DB 등 다양한 형태의 데이터베이스에 저장되며 이를 위해 다양한 언어로 쿼리하는데 어려움이 있다. 따라서 비구조적인 자연어 텍스트를 쿼리로 변환해주는 Text-to-Query 시스템이 등장했으며, 이 논문에서는 여러 쿼리 언어를 복합적으로 다루고자 한다.
이번 논문 리뷰는 최대한 도메인과 관련된 설명은 제외하고, 벤치마크 데이터셋을 생성하는 과정에 초점을 맞췄다. 특히 필자는 text-2-spraql에 관심이 있기 때문에 해당 분야를 중심으로 봤는데, 결과부터 말하자면 기존의 LLM은 여러 쿼리 중 SPARQL을 생성하는데 가장 어려움을 겪는 것 같다. 이는 SPARQL과 관련된 정보가 학습데이터셋에 많이 없었기 때문이며 그만큼 범용적이지 않다는 것을 의미한다. 본 논문에서는 모델의 fine-tuning까지 다루진 않지만, 평가 데이터셋을 생성하는 과정은 곧 학습 데이터를 생성하는 과정과도 유사하므로 추후 프로젝트에서 참고할 수 있을 것 같다. 전체 요약된 글은 위에 링크로 걸어둔 Medium 글을 읽어도 좋을 것 같다.
🧩 Introduction
일반적으로 EHR은 RDB 형태로 저장되고 사용되지만, 구조적 유연성과 데이터 소스를 상호 연결하는 특성 등을 활용하기 위해 document, graph 형식의 저장소의 사용도도 증가하는 추세이다. 특히 RDF 기반의 그래프 형식은 생명과학이나 약학 분야에서 활발하게 사용되고 있다고 한다.
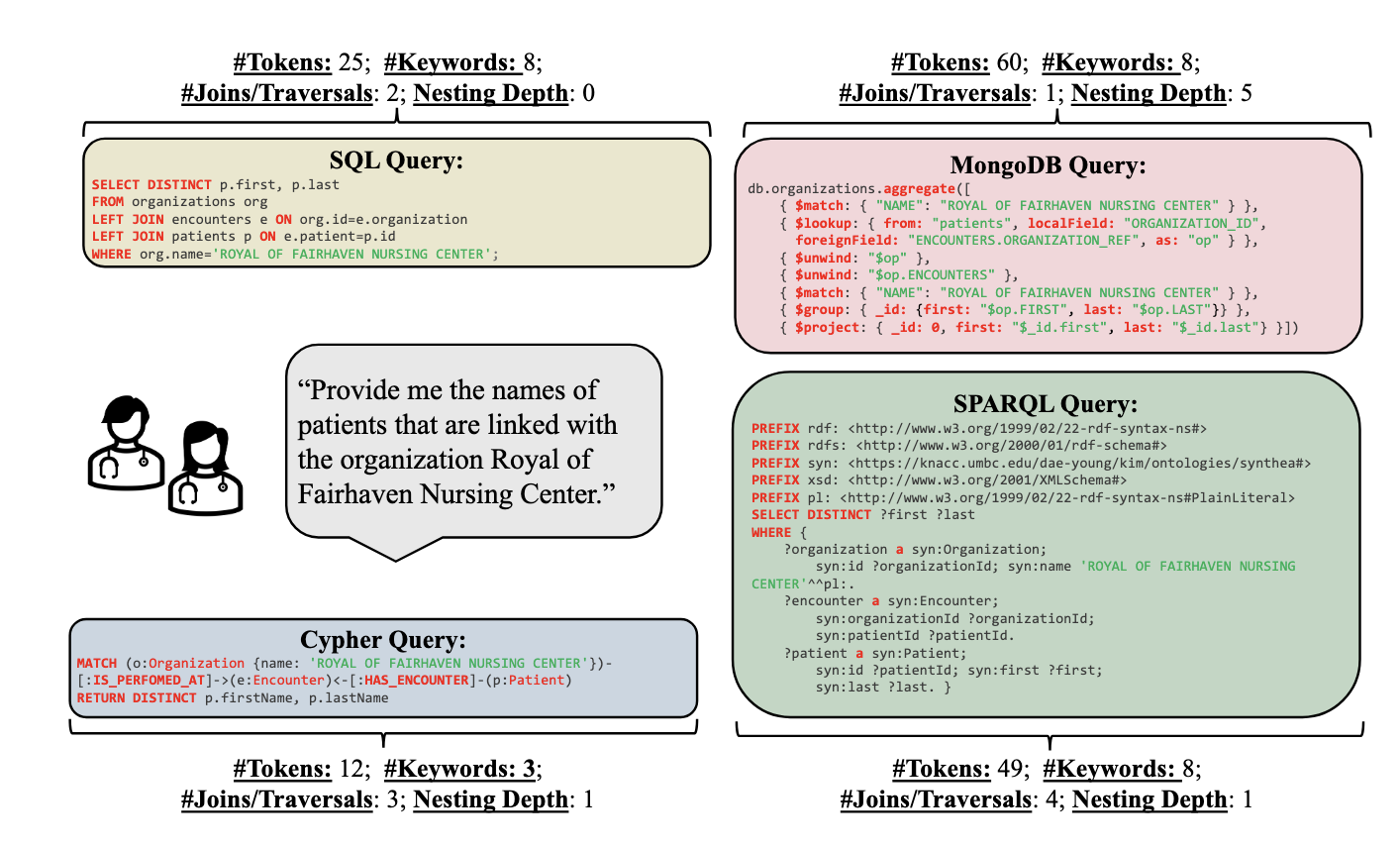
데이터베이스의 형태에 따른 쿼리 방식은 굉장히 달라지는데, 위 figure를 보면, 동일한 질문에 대해서 SQL, MQL, Cyper, SPARQL이 각각 얼마나 다른 탐색을 위한 접근 방식과 쿼리를 갖는지 알 수 있다. 일반적인 Text-to-Query 데이터셋과 벤치마크의 경우 단일 데이터베이스 모델과 쿼리에 중점을 두고 있으며, 이 논문에서 최초로 복합 데이터베이스 기반의 Text-to-Query를 다룬다고 한다.
🧩 SM3-Text-to-Query Benchmark Construction
SM3 T2Q 벤치마크는 다음 두 단계로 구성된다: (1) 네가지 데이터 모델에서 합성 의료 데이터를 기반으로 DB를 구축 (2) 템플릿 기반으로 텍스트-쿼리 쌍의 구조 생성. 데이터는 의료계 종사자들과 함께 1년 이상 시간 동안 구축했으며, 질문 템플릿은 SNOMED CT(Clinical Terms, 의료관련 multi-lingual 용어집)의 모든 엔티티를 포함한다.
Database Construction
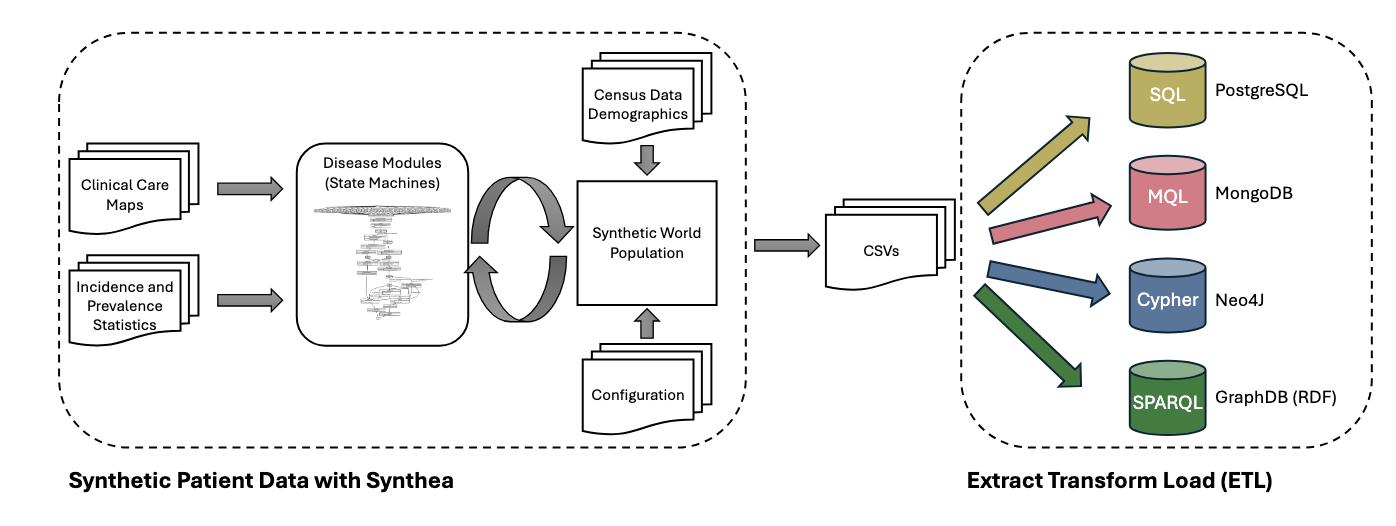
구축한 벤치마크 데이터셋은 SNOMED CT의 표준 용어를 사용하여 실제 EHR에 기반한 합성 의료 데이터셋으로 구성된다. 성된 데이터는 알레르기, 진료 계획, 약물 등 의료의 다양한 측면을 나타내는 18개 클래스가 포함되며, CSV, FHIR, C-CDA, CPCDS 형식으로 제공된다
합성데이터를 기반으로 RDB(PostgresSQL), Document DB(MongoDB), Graph DB(Neo4j, GraphDB) 형식에 저장하기 위한 ETL 파이프라인을 구축한다. Postgres에 저장하기 위해선 적절한 데이터타입과 PK, FK를 설정하고, MongoDB의 경우 엄격한 스키마가 필요하지 않고 트리 구조의 JSON 스키마로 표현하며, ID 참조를 통해 문서를 연결한다. Neo4J의 경우 자체 솔루션을 사용하고, RDF로 표현할 때는 Synthea-RDF를 확장하여 CSV를 TTL 형식으로 자동으로 변환한다고 설명한다.
데이터베이스별로 구축한 스키마 시각화 예시는 Appendix6에서 확인할 수 있다.
Text/Query-Paris Construction
텍스트-쿼리 쌍을 만들기 위해서 특정한 형식의 템플릿을 두고 확장해서 사용하는 방식을 적용한다. 이를 통해 수동으로 체계적인 408개의 템플릿을 생성했고, 템플릿의 유형으로는 WH 질문, 비WH, 사실 질문, 연결 질문, 요약질문, 원인-결과 질문 등이 포함된다. 이후 SQL, MQL, Cyper, SPARQL 언어를 사용한 쿼리를 생성하며 ID, 질병 설명, 환자 이름 등 DB에서 추출한 값을 자동 삽입함으로써 규모를 확장할 수 있었다. 최종 언어별로 10K 쌍의 데이터를 생성해서 총 40K의 데이터셋을 구축할 수 있었다.
템플릿을 통해서 데이터를 생성하는 것의 장점은 합성 데이터셋의 불안정성이나 편향을 감소시킬 수 있다는 점이다. 즉, 구조는 일정하되 주요 정보만 조합을 통해서 끼워넣어주기 때문에 특정 패턴이 과적합될 가능성도 적어지고, 잘못된 정보를 생성할 가능성도 없기 때문이다.
🧩 Dataset Analysis and Comparison
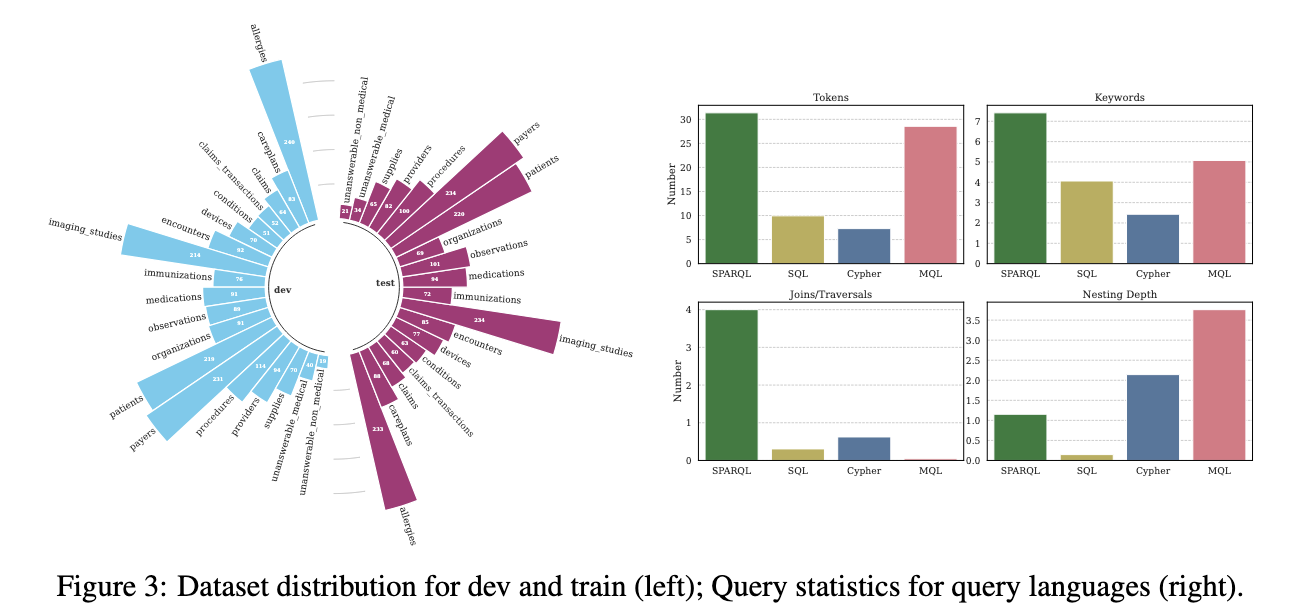
구축한 데이터셋은 6:2:2의 비율로 train, test, valid로 구분하며, 질문의 유형 비율은 차이가 있음을 위에 좌측 그래프를 통해 확인할 수 있다. 또한 동일한 자연어 질의에 대해서 쿼리 언어별로 형태와 특성도 차이가 있는데, SPARQL의 경우 토큰과 키워드 수가 가장 많으며, Join/Traversal 개수도 많아서 복잡도가 높다는 것을 알 수 있다. MQL의 경우 Join의 수는 가장 적지만, 중첩 컬렉션 구조가 많아서 중첩 깊이는 가장 높게 나타났다.
🧩 Baseline Experimental Evaluation
Experimental Setup
이 벤치마크의 목표는 LLM이 얼마나 자연어를 쿼리로 잘 변환하는지 확인하는 것이다. 우선 open, closed-source LLM 중에서 아래 4개의 평가 모델을 선정한다. 오픈소스 모델의 경우 NVIDIA A100 GPU와 Groq의 클라우드 서비스를 활용한다.
- [open-source] Meta - Llama3-8b, Llama3-70b
- [closed-source] Google - Gemini 1.0 Pro, OpenAI - GPT-3.5-turbo-0125
평가 모델은 모두 같은 구조의 프롬프트를 사용하는데, 프롬프트는 작업 지시문과 스키마/온톨로지, 그리고 few-shot 예시를 포함한다. 이때 SPARQL 온톨로지의 경우, 사이즈가 커서 클래스, 객체, 속성 정보를 JSON으로 요약한 버전을 넣어주고, MQL, Cyper도 각각 문서와 그래프 스키마를 넣어준다. few-shot으로 넣어줄 샘플은 계층화(stratified)된 랜덤 샘플링을 통해 선정한다.
- w/schema 0-shot
- w/schema 1-shot
- w/schema 5-shot
- w/o schema 1-shot
- w/o schema 5-shot
평가를 위한 메인 매트릭 EA(Execution Accuracy)는 '전체 쿼리 중에서 예측 쿼리와 정답 쿼리를 실행했을 때 결과가 완전히 동일한 비율'로 측정한다.
Text-to-Query Accuracy
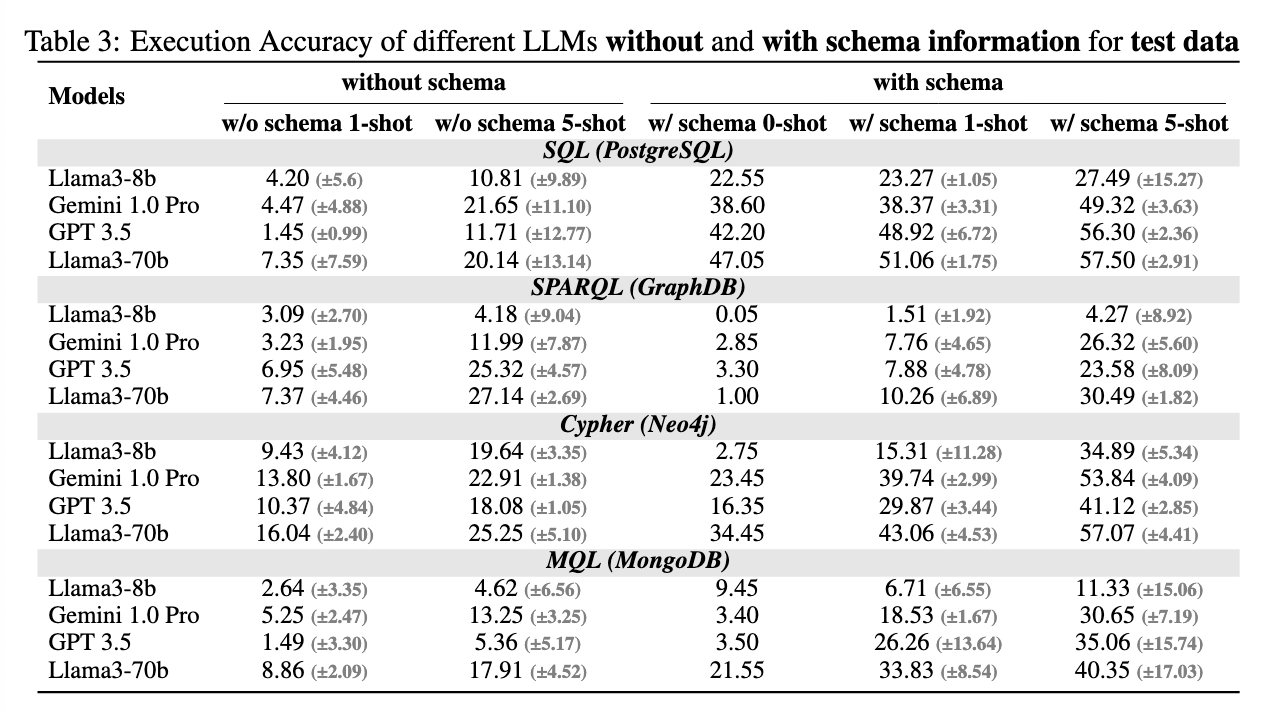
위 테이블에서 5개의 프롬프트 방식 조합에 따른 평가 결과를 확인할 수 있는데, 전체적으로 schema 정보를 넣어줬을 때와 1-shot일때보다 5-shot일 때 성능이 더 향상된 것을 알 수 있다. 다만 스키마의 유무가 모든 언어에서 동일하게 도움이 되는건 아니었는데, SPARQL의 경우 스키마 정보가 성능 향상에 큰 영향을 주지 않았기 때문이다. 이는 LLM이 사전 학습 과정에서 SNOMED-CT 온톨로지 용어를 이미 접했을 가능성이 크기 때문에 SPARQL에서는 스키마 정보가 큰 효과가 없었고 SQL, Cyper, MQL의 구체적인 스키마 정보는 새로운 정보(데이터셋에 따라 차이가 있으므로 학습할 때 봤던 스키마와는 다를 것)이므로 중요성이 더 컸을 것이라고 해석할 수 있다.
예제를 넣어주는 것도 성능 향상에 영향을 주지만, 이 역시 언어에 따른 차이가 있었다. SQL과 같이 일반적으로 사용되는 언어는 예제의 개수에 따른 성능 차이가 크지 않지만 SPARQL, Cyper, MQL과 같은 경우 프롬프트의 예제 개수에 성능 차이가 두드러지게 나타났다. 또한 샘플로 넣어준 예제의 종류에 따라서도 성능 차이가 발생했는데, 이는 아래에서 더 자세히 다른다.
한편, 모델에 따른 성능 차이는 언어별로 크게 나타나지 않았다. 즉, 언어에 관계 없이 Llama3-70b, GPT-3.5 등의 성능이 뛰어났고, 가장 작은 사이즈의 Llama3-8b의 성능은 항상 낮았다.
Simliarity-based few-shot sample selection
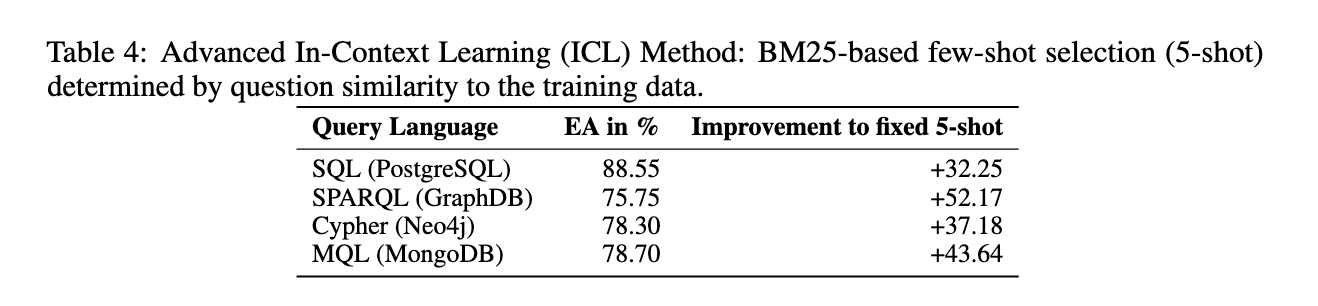
이번에는 few-shot 예제를 넣어줄 때 유사도 기반의 샘플링 기법을 사용한다. BM25를 사용해서 각 질문에 대해 훈련 데이터에서 가장 유사한 5개의 질문-쿼리를 검색하고, 검색된 결과를 프롬프트에 넣어주는 것이다. 평가는 GPT-3.5를 사용하고 스키마를 포함한 프롬프트에 적용했다. 결과는 성능이 최대 88.55%까지 크게 향상되었고, 이를 통해 최적의 ICL기법과 스키마 인코딩 방법 탐색의 필요성을 확인할 수 있었다.
유사한 방법으로, 이전에 읽었던 논문에서 프롬프트의 few-shot 예제를 넣어줄 때 샘플데이터를 넣지 않고 해당 작업을 위한 가장 최적의 예제를 의미적, 구조적 유사도 기반으로 계산해서 넣어줬던 방법이 있다. 물론 이때는 ER을 위한 프롬프트였지만, 예제를 넣어주는 방식에 있어서 보다 정교한 설계를 했던 것 같다.
🧩 Discussion and Limitations
한계점으로는 영어 기반으로만 구성되었다는 점과 일부 언어에 있어서는 너무 간단한 쿼리로만 구성했다는 점이 있다. 또한 모델에 따라서 동일한 프롬프트를 사용해도 출력값의 차이가 크게 나타나며, 이 차이는 쿼리 언어에 따라서도 발생한다고 한다. 예를 들어, GPT3.5는 동일한 프롬프트 구조를 사용했음에도 SQL생성은 잘했지만, MQL은 잘못했다. 이는 LLM을 학습한 데이터셋의 차이가 있기 때문에 발생할 가능성이 있으며, 향후 fine-tuning을 통한 최적화가 필요함을 시사한다.
