- 논문링크: https://arxiv.org/abs/2406.11160
- 참고자료: https://medium.com/modelmind/what-are-context-graphs-building-the-ai-that-trulyunderstands-e7e5db39138d
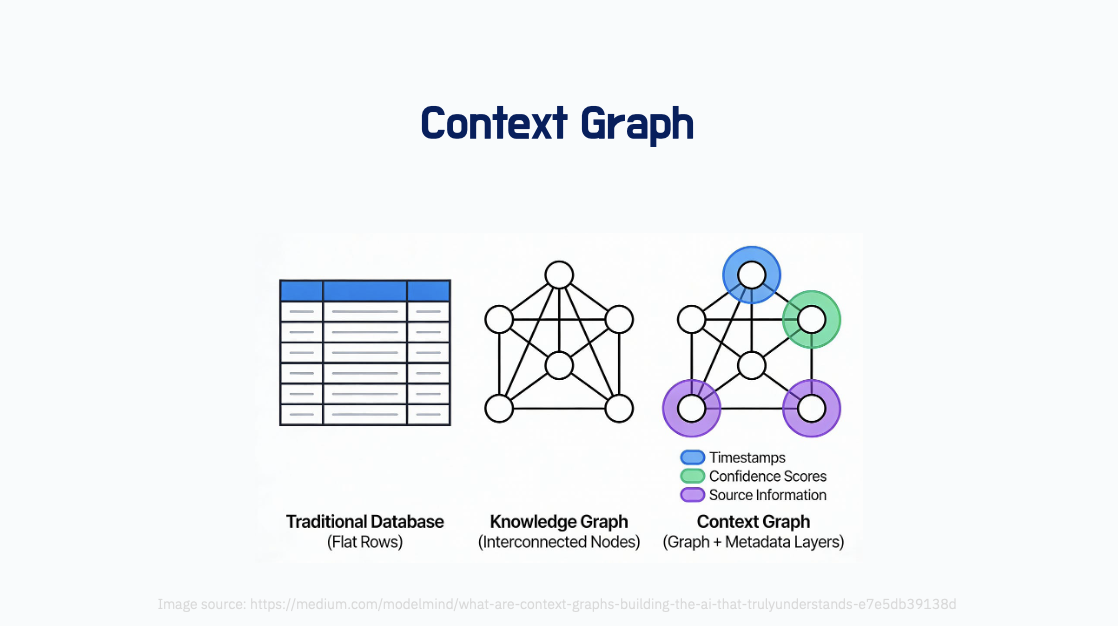
기존의 triple 기반의 지식그래프는 enitty 간의 관계는 충분히 표현할 수 있지만, 시간/위치/출처 등 맥락적(context)인 정보를 표현하는데는 한계가 있다. 이에 따라 제안된 개념인 Context Graph(CGs)는 트리플 구조의 표현을 확장함으로써 기존의 지식그래프 대비 정교하고 풍부한 정보를 표현할 수 있다는 특징이 있다.
첨부한 참고자료에서 이렇게 표현한다: Knowledge graphs answer “what” and “how are things related?” Context graphs answer “what, when, where, why, and how confident?”
현재 Context Graph가 더 주목받게 된 데에는 AI와 지식그래프의 결합적 활용 측면에서 비롯된다. 지식그래프의 구조적인 표현이 기계가 이해하기 쉬운 형태임에 따라 LLM의 hallucination을 보완할 수 있는 방안으로 제안되고 있는데, 이때 맥락적인 정보, 즉 더 풍부한 정보를 줄 수 있는 Context Graph가 주목받게 된 것이다.
참고자료에서는 Context Graphs는 다음과 같은 이점들을 가진다고 설명한다.
1. Solving the LLM Hallucination Problem
2. Enabling Multi-Hop Reasoning
3. Explainability and Auditability
4. Real-Time, Context-Aware Decision-Making
본 논문에서는 기존 트리플 기반의 지식그래프의 한계와 Context Graphs의 차별점, 정의를 설명하고, CGs의 유용성을 LLM의 추론을 활용한 Context Graph Reasoning을 통해 입증한다. 현재 작업 중인 내용과 맞닿아 있는 내용이 많아서 논문과 함께 기타 참고자료도 찾아보고, 고민하고 있는 개인적인 생각을 포함해서 정리했다.
✅ Limitations of Triple-based KGs
head entity, relations, tail entity(S-P-O)로 구성되는 트리플 형식의 지식그래프는 맥락적 정보를 배제한다. 예를 들어, 'Apple Computer went public in 1980. Jobs became chairman while Markkula took on the role of president', 'In August 2011, Jobs resigned, and was appointed Chairman of Apple'라는 두 문장이 있을 때, 이를 통해 생성해낼 수 있는 트리플은 'Steve Jobs-Chairman of->Apple Inc'로 동일하지만, 두 문장은 시간적, 상황적 차이를 갖는다. 만약 위 문장을 Context Graphs로 표현했다면 시간적 정보인 '1980', 'August 2011'등을 포함하여 구분이 가능해진다.
또한 문맥을 제거한 경우, 정보의 conflict이 발생했을 때 검증하기 어렵다는 문제도 있다. 예를 들어, '거주하다', '산다', '머무른다' 등 비슷한 맥락의 속성을 하나의 'lives in'으로 표현하면 정보의 왜곡이 발생할 수 있지만, 앞뒤 문맥을 다 제거한 상태에서는 어느 정보가 정확한지 판단할 수 없게 된다.
즉, 구조화하고 개념화하여 추상화한 그래프는 이해와 활용 측면에서 장점을 갖지만, 상세한 맥락 정보 상실이라는 단점을 유발한다는 것이다. 이러한 특징은 고차원 추론을 시도하는 현재의 AI 환경에서 한계점으로 작용할 수 밖에 없다.
✅ Context Graphs
Context Graphs는 기존의 triple-based KGs에 'additional information layers'가 추가된다고 이해할 수 있다. 이 레이어는 entity의 attributes, types, description, aliases, reference links, images, speeches, videos 등이 포함될 수 있으며, 시간/장소/기타맥락에 따라 차이가 발생할 수 있다.
Context Graphs의 풍부한 문맥 정보를 활용하면 고차원의 지식 추론을 수행할 수 있다. CGs는 직접적인 관계로 연결되어 있지 않아도 유사한 문맥 혹은 공통된 상황, 조건, 배경 정보 등으로 정보가 연결될 수 있으며, 이를 통해 연관 추론이 가능하다. 따라서 단순 관계 정보를 통한 지식 보다 복잡한 추론 질문(e.g. 글로벌 스마트폰 시장에서 현재 Apple의 가장 큰 경쟁사는?' --> 특정 시점, 시장 점유율 같은 정량적 정보를 조건으로 정보 추론)을 수행할 수 있게 된다.
정량적 정보를 활용한 복합 추론이 가능하다는 점이 인상적인데, 기존의 데이터를 serialize된 RDF 기반의 그래프로 모두 변환할 때는 property의 range값을 맞추기 위해서 수치 데이터의 형태를 정제해야 한다는 어려움이 있었다. 예를 들어 'height'라는 속성에 instance 값이 '170cm', '170'이 들어 있는 경우, height라는 속성의 range가 float일 경우 170cm는 에러가 된다는 것이다. 물론, 속성값의 range를 넓혀주거나 property graph인 경우, 표준어휘를 사용하지 않는 경우는 전혀 문제가 없고, Context Graph가 이런 문제만을 해결하진 않지만, 정량적 정보를 metadata에 보다 유연한 형태로 저장할 수 있다는 점은 분명 장점이 된다고 생각했다.
✅ CGR(Context Graphs Reasoning)
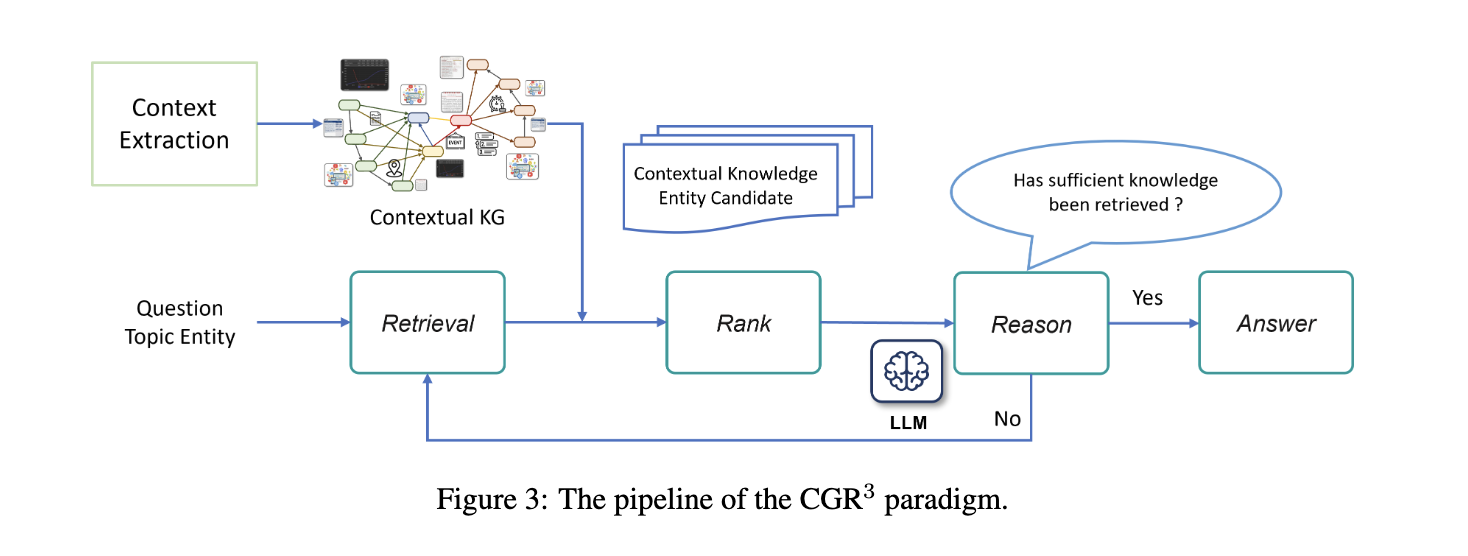
논문에서는 Context Graph를 구축을 위한 Extraction 작업을 우선 진행하는데, 이는 기존의 triple-based KGs에 context를 부여하기 위한 과정이다. FB15k237, YAGO3-10, Wikidata5M 등과 같은 이미 구축된 triple-based KGs가 있을 때, entity에 해당하는 wikipedia pages를 수집한 뒤(Wikidata ID를 URI를 사용해서 수행할 수 있음), Sentence-BERT를 사용해서 해당 트리플을 설명할 수 있는 top-r개의 문장을 추출해내는 방식을 사용한다. 이후 트리플의 형태를 context-aware quadruple (h, r, t, rc) 형태로 만든다고 한다.
이후 Context Graph가 KG reasoning model의 성능 향상에 기여하는지 검증하기 위해 Context Graphs Reasoning로써 KG Competion과 KG question answering을 수행한다. KGC는 single-hop reasoning으로 수행되므로 reasoning step을 뺐다고 한다.
KGC(Knowledge Graph Completion)
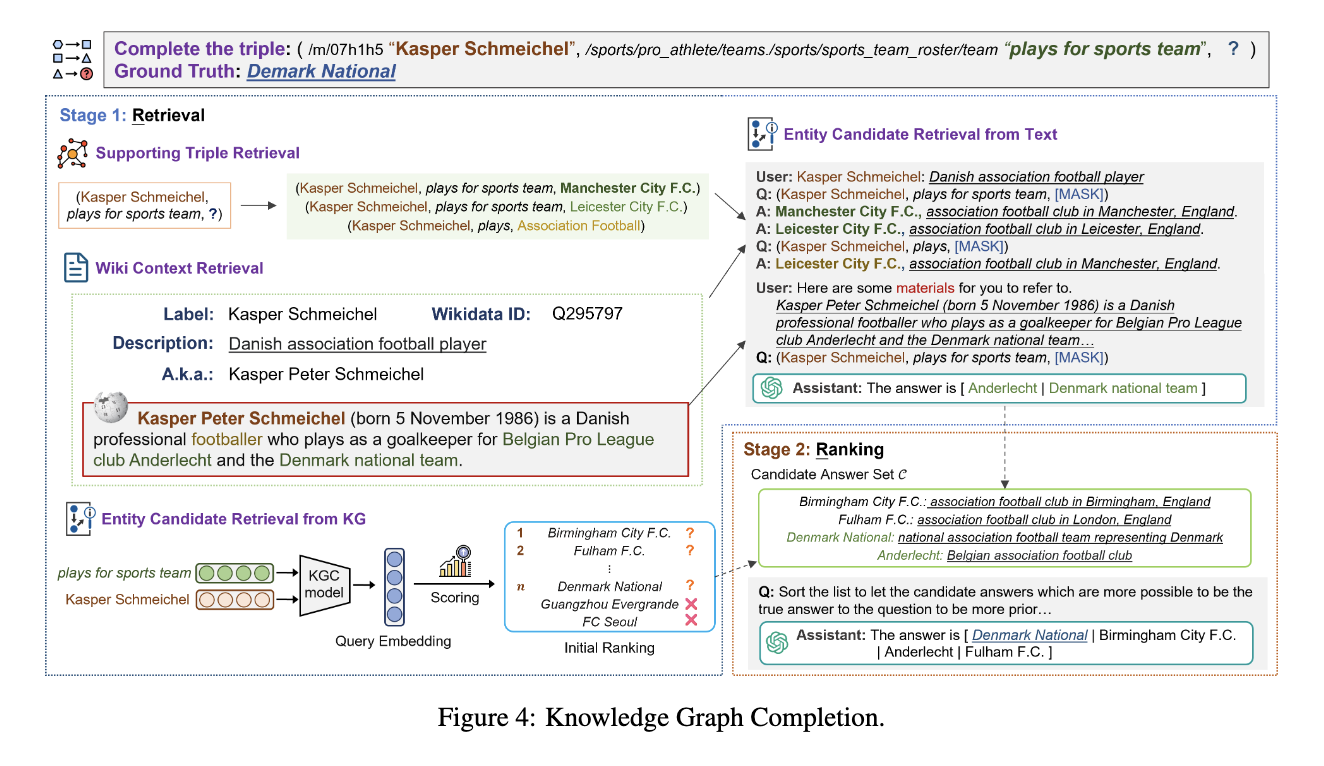
(1) Retrieval
Retrieval 단계의 목적은 불완전한 트리플을 완성하는 데 도움이 될 수 있는 모든 구조적, 의미적 정보를 수집하는 것이다. Supporting Triple Retrieval은 우선 (h, r, ?)와 같은 input이 있을 때, h, r을 공유하는 트리플을 검색하고, k개 이하로 검색될 경우 ?s r ?o 형태를 검색한 뒤, ?s가 h와 가장 유사한 트리플을 선정한다고 한다. 이를 통해 의미적으로 가장 유사한 정보를 수집할 수 있게 된다. Textual Context Retrieval의 경우, 트리플을 구성하는 ID나 속성값들을 보다 문맥 기반으로 풀어서 설명해서(트리플 자체는 구조적으로 형성되어 있으므로) LLM이 이해하기 쉽도록 만드는 과정이다. 이를 위해 Wikidata를 중심으로 엔티티의 텍스트 문맥(label, 문서의 텍스트 설명 등)을 수집해서 자연어 기반의 의미 표현을 보강한다. Candidate Answer Retrieval from KG 단계에서는 사전에 학습된 embedding model을 기반으로 ? 자리에 들어갈 가능성 점수가 가장 높은 엔티티 랭킹 리스트 사전에 필터링한다. 마지막으로 Candidate Answer Retrieval from Text에서는 KG구조(트리플)과 임베딩이 놓칠 수 있는 후보를 문맥 이해 기반으로 보완하는 단계로, 트리플을 자연어로 변환한 질문을 기반으로 LLM이 가능한 답변 엔티티 후보 목록을 생성하고, 정확성을 위해 KG에 존재하지 않는 엔티티 제거, 정규화 등의 후처리를 진행한다고 한다.
정확히 이 네가지 방식을 어떻게 수행하는지 설명만으로는 명확히 이해하기 어려웠는데, 네 단계의 관계는 아래와 같이 정리될 것 같다 (by ChatGPT)
┌───────────────┐ │ Query Triple │ └──────┬────────┘ │ ┌─────────────┴─────────────┐ │ │ 1) Supporting Triples 3) Embedding-based (KG 구조) Candidate Ranking │ │ 2) Text Context │ (Wikidata/Wiki) │ │ │ └─────────────┬─────────────┘ │ 4) LLM-based Candidate Generation │ 교집합 + 후처리
(2) Ranking
이렇게 수집한 정보들 중, input 질문을 처리하기 위해 가장 유용한 정보를 찾기 위한 순위화 과정이다. 논문에서는 LLM as Judge 방식(프롬프트 기반의 방식은 아님)을 사용하기 위해 SFT, LoRA 기반으로 모델을 학습시킨다. SFT 학습은 '질문+후보'가 있을 때, 그럴듯한(plausible)답의 순위를 매기는 식으로 학습 데이터를 구성한다. 이렇게 학습한 모델로 retrieval된 목록의 부분집합 C를 재정렬하고, 기존의 랭킹과 합성해서 정밀도를 높이는 방식으로 순서를 수정한다.
KGQA(Knowledge Base Question Answering)
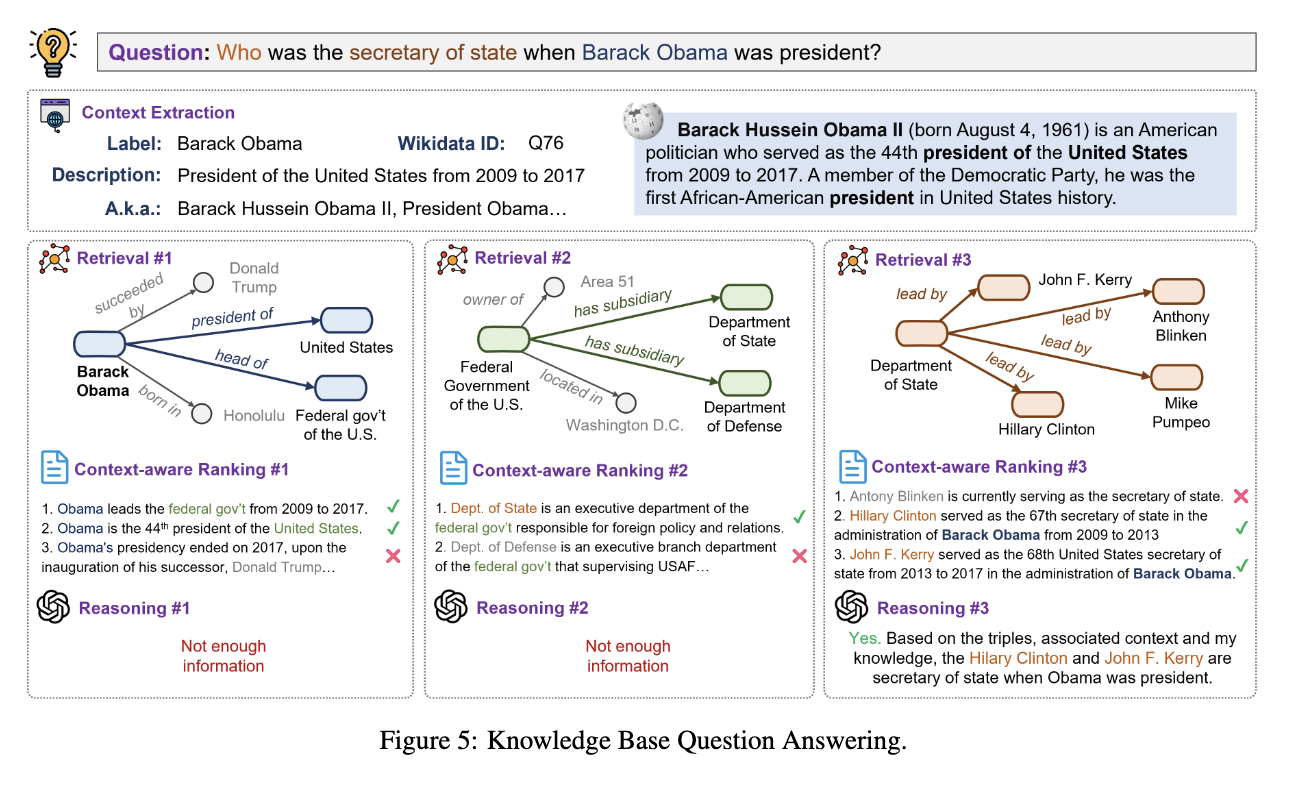
두번째 검증은 지식베이스 기반 QA이다. 위 예시를 보면 '버락 오바마가 대통령이던 당시 국무장관이 누구인가?'라는 질문이 들어왔을 때, 우선 topic 엔티티를 중심으로 context를 추출하고 이 엔티티에 연결된 모든 relation을 수집한다.
(1) Context-aware Triple Retrieval
이 단계에서는 위에서 선별된 relation의 object들을 가져와서 후보 triple 집합을 생성한다. 다만, 과도한 후보군이 생길 가능성을 대비하여 생성된 query triple들에 대해 LLM을 활용하여 질문과 관련성이 높은 상위 M개의 확장 후보만 선택한다. 이를 통해 reasoning paths, 즉 추론 경로 확장이 유도된다.
(2) Candidate Entity Ranking
이 단계에서는 (1) 단계에서 생성된 후보 triple 각각에 대해, 해당 relation이 지니는 의미적 맥락을 보완하기 위해 relation context 문장을 결합한다. 이러한 context 문장은 동일하거나 유사한 관계가 실제 텍스트 환경에서 어떻게 사용되는지를 반영하며, triple 단위의 구조적 정보가 갖는 의미적 모호성을 완화하는 역할을 한다.
이후, LLM은 질문, 후보 triple, 그리고 이에 대응하는 relation context를 함께 고려하여, 답변 도출에 기여할 가능성이 높은 triple들을 선택한다. 이를 통해 질문과 무관하거나 의미적으로 부적합한 이웃 엔티티를 효과적으로 제거할 수 있다. 또한, LLM 입력 길이 제약을 고려하여, 1차 선별 이후에도 추가적인 정합성 평가를 수행함으로써 최종적으로 상위 M개의 triple만을 유지한다. 이 과정은 reasoning path의 품질을 유지하면서도, 이후 단계에서의 추론 부담을 줄이는 역할을 한다.
(3) Context-aware Reasoning
이 단계에서는 (1), (2) 단계를 통해 확장, 정제된 reasoning paths와 이에 대응하는 relation context 문장들을 질문과 함께 LLM의 입력으로 통합한다. LLM은 단순히 트리플 구조만을 사용하는 것이 아니라, 각 reasoning path가 담고 있는 관계의 의미적 맥락과 질문 간의 정합성을 종합적으로 고려하여(충분한지 아닌지 LLM이 판단후 불 충분할 경우 (1)로 다시 돌아가서 반복) 추론한다고 한다.
이러한 반복적 추론 과정은 컨텍스트 정보를 활용하여 추론 경로의 방향성을 지속적으로 조정하여 불필요한 탐색을 줄이고 질문에 가장 적합한 reasoning paths를 점진적으로 확장하도록 유도한다.
.
.
.
KGC와 KGQA 테스트 결과를 종합하면, contextual information을 추가해주는 것이 추론 성능을 상당히 높였다고 한다.
LLM의 등장 덕분에 개인적인 느낌으로는 unstructured data를 Context Graphs로 변환하는 과정이 오히려 table data와 같은 structured data를 변환하는 것보다 수월하다는 생각이 들기도 한다. 시간, 주소, 좌표 정보가 텍스트 안에 설명되어 있다면 어떤 entity와 관련된 메타 정보인지 LLM이 판단할 수 있으나(이것도 쉽지 않지만 가능하다고 판단), row 형태라면, 이 row의 entity가 과연 1개인지 2개인지, 그리고 다른 데이터에서 발견된 entity의 정보와 conflict가 있는 경우 이를 비교, 판단하기 오히려 더 어렵다는 것이다. 이 부분에 대한 여러 접근법을 고민중이다...
