[논문리뷰] From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Paper Review

필자의 생각+질문들을 섞어서 정리한 글 입니다. 잘못된 정보가 있다면 댓글 남겨주시면 감사하겠습니다! 🤩
<요약 정리>
1. 문서 준비
2. chunking
3. chunk 단위로 prompt를 사용해서 entity, relation, claims 생성하고 각각 description도 생성
4. relation 기반으로 edge weight 계산하고 Leiden 기법으로 clustering해서 community 생성
5. community 별로 summarization
6. query가 들어왔을 때 summary를 기반으로 답변
1. Introduction
<문제 의식>
기존의 RAG는 Chunk 단위로 가져오기 때문에, 전체 맥락을 가져오지 못 할 수 있고, 특히 '이 문서의 내용을 요약해줘'와 같은 질문은 답할 수 없다는 문제가 있음 (Query-Focused Summarization)
동의한다. 기존의 RAG는 chunk size에 생각보다 큰 영향을 받고, 'A와 B를 비교해줘'와 같은 질문에는 A와 관련된 chunk만 가져오거나 B와 관련된 chunk만 가져오는 등 retrieve 정보가 불완전하다는 느낌을 받았다.
<제안 방법>
Graph RAG는 (1) document에서 entity를 추출해서 (2) 유사 entities끼리 community를 만들고, (3) 이러한 community(local단위)끼리 summarization을 한 뒤, (4) 이것들을 모아서 global summarization을 하는 일종의 'map reduce' 방식이다. (순서 넘버링은 임의로 부여)
(단위별로 쪼개서 요약을 진행하는 이유는 LLM의 input length의 제한이 있으며, 한번에 처리했을 때 정보가 소실될 수 있기 때문이다.)
여기까지의 질문
1. entity를 뽑아오는 범위를 chunking해줘야 할텐데, 여기서 chunk size가 작으면 작을수록 더 specific 해지니까 성능이 높아질까?
2. 유사한 entity community는 어떤 방식으로 계산할까?
2. Graph RAG Approach & Pipeline
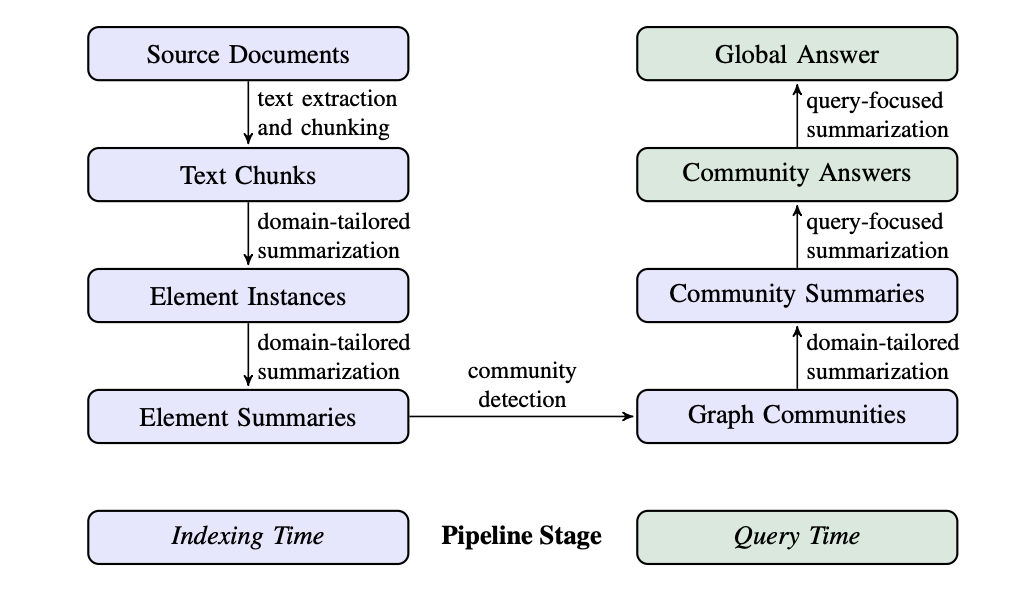
2.1 Source Documents -> Text Chunks
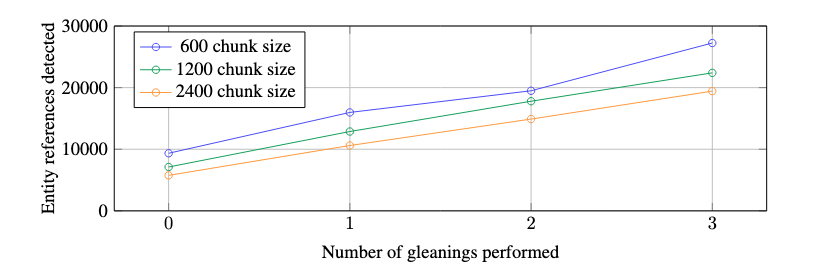
retrieve를 할 문서에서 chunking을 진행하는 단계이다. chunk의 사이즈가 크면 클 수록 entity를 extraction하는 횟수가 줄어들지만, recall 성능이 저하된다고 한다.
이게 무슨말 인지 고민했는데, Fig2에서 볼 수 있듯, entity extraction은 각 chunk 별로 하기 때문에 chunk 사이즈가 작으면, 추출되는 entity의 개수가 더 많을 것이고, 이에 따라 많은 참조 entity가 생기는 것이다.
2.2 Text Chunks -> Element Instances
이 단계에서는 chunk에서 element(entity와 동일한 개념으로 이해함)를 추출하는데, 이때 LLM에 few-shot example을 넣은 prompt를 활용한다. 우선적으로 각 entity를 판별하는데, 이때의 entity는 people, places, organizations 등이 되는데, 도메인에 따라 세부적으로 분류할 수 있다.
보조 추출 프롬프트로 'claims'도 추출하는데, 이는 제목, 개체, 유형, 설명, 소스 텍스트 범위, 시작 및 종료 날짜를 포함하여 감지된 엔터디에 연결된 주장을 추출하는 것을 목표로 한다고 한다.
각 element의 entity를 추출했을 때, 해당 entity를 설명할 수 있는 보조적인 역할을 하는 건 맞는데, 정확한 의미는 잘 이해되지 않았다. 깃헙에 있는 GraphRAG 코드 중
claim_extraction.txt파일을 한글로 번역하면 다음과 같다.-대상 활동- 당신은 특정 단체에 대한 주장이 제시된 텍스트 문서를 분석하는 인간 분석가를 돕는 지능형 비서입니다. -목표- 관련될 수 있는 텍스트 문서, 엔터티 명세, 및 주장 설명이 주어졌을 때, 엔터티 명세와 일치하는 모든 엔터티와 해당 엔터티에 대한 모든 주장을 추출합니다. -단계- 1. 미리 정의된 엔터티 명세와 일치하는 모든 명명된 엔터티를 추출합니다. 엔터티 명세는 엔터티 이름 목록이거나 엔터티 유형 목록일 수 있습니다. 2. 1단계에서 식별된 각 엔터티에 대해, 해당 엔터티와 연관된 모든 주장을 추출합니다. 주장은 지정된 주장 설명과 일치해야 하며, 엔터티는 주장의 주체가 되어야 합니다. 각 주장에 대해 다음 정보를 추출합니다: • 주체: 주장의 주체가 되는 엔터티의 이름을 대문자로 표기합니다. 주체 엔터티는 주장에서 설명된 행동을 수행한 것으로 간주됩니다. 주체는 1단계에서 식별된 명명된 엔터티 중 하나여야 합니다. • 객체: 주장의 객체가 되는 엔터티의 이름을 대문자로 표기합니다. 객체 엔터티는 행동을 보고하거나 처리하거나 행동에 영향을 받는 엔터티입니다. 객체 엔터티를 알 수 없는 경우 NONE을 사용합니다. • 주장 유형: 주장에 대한 전반적인 범주를 대문자로 표기합니다. 동일한 유형의 주장이 여러 텍스트 입력에서 반복될 수 있도록 이름을 지정합니다. • 주장 상태: TRUE, FALSE, 또는 SUSPECTED 중 하나를 선택합니다. TRUE는 주장이 확인된 경우, FALSE는 주장이 거짓으로 판명된 경우, SUSPECTED는 주장이 확인되지 않은 경우를 의미합니다. • 주장 설명: 주장에 대한 상세한 설명과 관련된 증거 및 참조를 포함합니다. • 주장 날짜: 주장이 제기된 기간(시작 날짜, 종료 날짜)을 ISO-8601 형식으로 기재합니다. 주장이 특정 날짜에 제기된 경우, 시작 날짜와 종료 날짜에 동일한 날짜를 입력합니다. 날짜를 알 수 없는 경우 NONE을 사용합니다. • 주장 출처 텍스트: 주장과 관련된 원문 텍스트의 모든 인용구를 나열합니다. 각 주장을 다음 형식으로 작성합니다: (<주체 엔터티>{tuple_delimiter}<객체 엔터티>{tuple_delimiter}<주장 유형>{tuple_delimiter}<주장 상태>{tuple_delimiter}<주장 시작 날짜>{tuple_delimiter}<주장 종료 날짜>{tuple_delimiter}<주장 설명>{tuple_delimiter}<주장 출처>) 3. 1단계와 2단계에서 식별된 모든 주장의 결과를 단일 목록으로 반환합니다. 목록 구분자로 **{record_delimiter}**를 사용합니다. 4. 완료되면 {completion_delimiter}를 출력합니다. -예시- 예시 1: 엔터티 명세: organization 주장 설명: 엔터티와 관련된 위험 신호 텍스트: 2022/01/10에 발표된 기사에 따르면, 회사 A는 정부 기관 B에서 발표한 여러 공공 입찰에 참여하면서 입찰 담합으로 벌금을 부과받았습니다. 이 회사는 2015년에 부패 행위를 한 것으로 의심되는 사람 C가 소유하고 있습니다. 출력: (COMPANY A{tuple_delimiter}GOVERNMENT AGENCY B{tuple_delimiter}ANTI-COMPETITIVE PRACTICES{tuple_delimiter}TRUE{tuple_delimiter}2022-01-10T00:00:00{tuple_delimiter}2022-01-10T00:00:00{tuple_delimiter}2022/01/10에 발표된 기사에 따르면, 회사 A는 정부 기관 B에서 발표한 여러 공공 입찰에 참여하면서 입찰 담합으로 벌금을 부과받았습니다{tuple_delimiter}2022/01/10에 발표된 기사에 따르면, 회사 A는 정부 기관 B에서 발표한 여러 공공 입찰에 참여하면서 입찰 담합으로 벌금을 부과받았습니다.) {completion_delimiter} 예시 2: 엔터티 명세: 회사 A, 사람 C 주장 설명: 엔터티와 관련된 위험 신호 텍스트: 2022/01/10에 발표된 기사에 따르면, 회사 A는 정부 기관 B에서 발표한 여러 공공 입찰에 참여하면서 입찰 담합으로 벌금을 부과받았습니다. 이 회사는 2015년에 부패 행위를 한 것으로 의심되는 사람 C가 소유하고 있습니다. 출력: (COMPANY A{tuple_delimiter}GOVERNMENT AGENCY B{tuple_delimiter}ANTI-COMPETITIVE PRACTICES{tuple_delimiter}TRUE{tuple_delimiter}2022-01-10T00:00:00{tuple_delimiter}2022-01-10T00:00:00{tuple_delimiter}2022/01/10에 발표된 기사에 따르면, 회사 A는 정부 기관 B에서 발표한 여러 공공 입찰에 참여하면서 입찰 담합으로 벌금을 부과받았습니다{tuple_delimiter}2022/01/10에 발표된 기사에 따르면, 회사 A는 정부 기관 B에서 발표한 여러 공공 입찰에 참여하면서 입찰 담합으로 벌금을 부과받았습니다.) {record_delimiter} (PERSON C{tuple_delimiter}NONE{tuple_delimiter}CORRUPTION{tuple_delimiter}SUSPECTED{tuple_delimiter}2015-01-01T00:00:00{tuple_delimiter}2015-12-30T00:00:00{tuple_delimiter}사람 C는 2015년에 부패 행위를 한 것으로 의심됩니다{tuple_delimiter}이 회사는 2015년에 부패 행위를 한 것으로 의심되는 사람 C가 소유하고 있습니다) {completion_delimiter}
또한 'gleaning'(수집?) 단계에 대해서도 언급하는데, 효율성과 품질 요구의 균형을 맞추기 위해서 LLM이 이전 추출 라운드에서 놓쳤을 수 있는 추가 entity를 감지하도록 장려하기 위해 지정된 최대값까지 여러 라운드에서 수집되는 과정을 의미한다. 방법은 먼저 LLM에 모든 entity가 추출되었는지 여부를 평가하도록 하고, 예/아니오로 평가하도록 하고 누락되었다고 응답되었을 때 "엔티티가 누락되었습니다"라는 메세지를 출력하도록 하여서 누락된 entity를 다시 수집하도록 intruction을 주게 된다.
2.3 Element Instaces -> Element Summaries
이 단계에서는 이전에 추출된 entity, relationships, claims에 대해서 이미 작성된 추상적인 description을 기반으로 summarize를 진행한다. 각 인스턴스 레벨의 요약글을 하나의 single-blocks 요약으로 추가적인 요약을 하는 것이다.
이때의 bottle neck은 '동일한 entity명에 대해서 항상 같은 description이 적히지 않아서 중복이 발생할 수 있다는 것'이다.
BERT기반의 모델을 생각했을 때도, 여러 문장에서 등장하는 동일한 토큰들의 embedding vector는 문맥에 따라서 다르기 때문에, 단어 기준의 similarity를 계산하기 어렵다는 문제가 있었다.
그러나 이 이후 단계에서 유사한 것들 끼리 community를 생성하고 다시 summarization을 진행하기 때문에, 동음이의어나 다음이의어를 LLM이 처리할 수 있다는 가정을 두는 것 같다.
2.4 Element Summaries -> Graph Communities
이전단계까지 거쳐서 entity nodes, relations, claims에 대해서 인덱싱이 다 된 상태이고, 각 관계에 대한 edge weight(가중치)는 연결된 인스턴스의 정규화된 개수(degree...로 이해)로 계산된다. 그리고 이 가중치를 활용해서 서로 더 강한 연결을 갖는 community로 그래프를 분할 할 수 있다.
이때 분할은 chunk 안에서 진행하는지? (아니라고 생각함)
이때 계층적 클러스터링 기법 중 하나인 Leiden 개념이 등장하는데, Leiden은 상호 배타적이고 집합적인 방식으로 그래프의 노드를 아우르는 community partition을 제공하여 분할하고 다시 복구하여 global 요약을 가능하게 한다고 한다. 즉, local summarization과 global summarization을 모두 가능하게 하는 계층적(분리와 합침이 가능한) 클러스터링 기법을 사용한다는 것이다.
Leiden 기법과 관련해서는 추가적인 논문을 읽어봐야 이해할 수 있을 것 같은데, 일단 지금 수준에서는 아래 블로그에 정리된 글들을 기반으로 이해했다.
2.5 Graph Communities -> Community Summaries
이제 Leiden으로 분할된 community 별로 summarization을 진행한다. 이때의 summary는 사용자의 local 질문에 대해서 대답할 수 있는 말뭉치가 되기도 하고 global, 즉 전역적인 수준에서 응답하는데 사용될 수도 있는데, 여기서는 후자에 중점을 둔다고 한다. community summaries는 다음과 같은 방식으로 진행된다.
- leaf-level community: 리프 수준 커뮤니티(노드, 에지, 공변량)의 요소 요약에 우선순위가 부여된 다음 토큰 제한에 도달할 때까지 LLM 컨텍스트 창에 반복적으로 추가. 우선 순위는 source node와 target node의 결합 정도(예: 전체 중요도)가 감소하는 순서로 각 커뮤니티 가장자리에 대해 source node, target node, linked covariate, edge 자체에 대한 설명을 추가
- higher-level community: 모든 element 요약이 컨텍스트 창의 토큰 제한 내에 맞는 경우 리프 수준 커뮤니티와 마찬가지로 진행하고 커뮤니티 내의 모든 element 요약을 요약함. 컨텐스트의 길이가 긴 경우, element 요약 토큰의 내림차순으로 하위 커뮤니티의 순위를 지정하고 컨텍스트 창에 맞을 때까지 관련 element 요약(더 긴)을 하위 커뮤니티 요약(더 짧은)으로 반복적으로 대체함
정리하면, community summarization도 단계적으로 진행하는데, 우선 노드, 엣지, covariate기준으로 각각의 description을 prompt에 넣어서 요약을 하는데, 이때 넣는 순서는 중요도가 높은 순(아마도 weight가 높은 순)으로 들어간다. 그리고 이렇게 요약된 각 leaf들을 모두 합쳤을 때 max context length보다 짧으면 그대로 넣어서 요약을 진행하고, 만약 길이가 너무 길다면, 짧은 요약들로 반복해서 대체해서 넣으면서 최대 길이를 맞춘다는 의미 같다.
2.6 Community Summaries -> Community Answers -> Global Answer
사용자의 query가 들어왔을 때, 앞에서 생성된 community summarization은 retrieve chunk로써 사용될 수 있다. 특정 community 수준에서 사용자의 query에 대한 전체 답변은 다음과 같이 생성된다.
-
Prepare community summaries: 커뮤니티 요약은 무작위로 섞이고 미리 지정된 토큰 크기의 덩어리로 나뉜다. 이를 통해 관련 정보가 단일 컨텍스트 창에 집중(및 잠재적으로 손실될 수 있음)하는 대신 여러 청크로 분산된다.
-
Map community answers: 각 청크마다 하나씩 중간 답변을 병렬로 생성한다. LLM은 또한 생성된 답변이 목표 질문에 답변하는 데 얼마나 도움이 되는지 나타내는 0-100 사이의 점수를 생성하도록 요청받는다. 점수가 0인 답변은 필터링된다.
여기서 chunk별로 중간 답변을 병렬로 생성한다는 것이 헷갈렸다. community 내부에서 다시 chunk를 나눈다는 의미인지?
-
Reduce to global answer: 중간 커뮤니티 답변은 유용성 점수의 내림차순으로 정렬되고 토큰 제한에 도달할 때까지 새 컨텍스트 창에 반복적으로 추가된다. 이 최종 컨텍스트는 사용자에게 반환되는 전역 응답을 생성하는 데 사용된다.
