
이 논문은 text로 작성한 query를 SPARQL query로 변환할 때 LLM, 특히 ChatGPT를 활용한 실험을 수행하고 입력 토큰수를 줄이며 성능은 높이는 Auto-KGQAGPT라는 자체적인 프레임워크를 제시한다.
Experiments

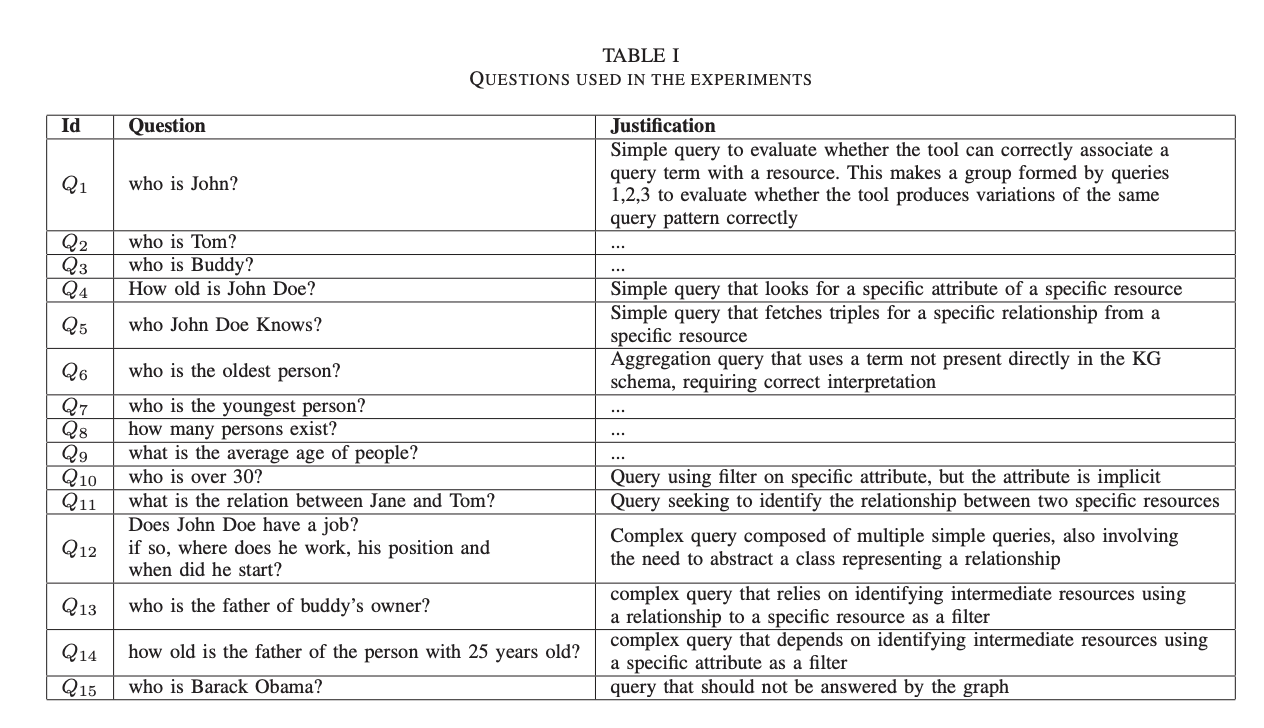
임의의 Toy KG를 만들고, 이 KG에게 할 수 있는 NL(Natural Language) 쿼리 세트를 생성한다. Toy KG는 Fig. 1과 같고, 원으로 표현된 건 class를 의미한다. NL 질문과 해당 질문을 생성한 이유에 대한 내용은 Table. 1에 정리되어 있다.
1. Direct Answering of NL Questions
외부 소스에 대한 쿼리를 수행하지 않고, 입력으로 직접 전달된 KG에 대한 NL 질문에 대답하는 ChatGPT의 능력을 평가하기 위한 방법이다. ChatGPT는 입력 KG를 해석하고, NL 질문을 이해하고, 그래프레서 직접 학습한 지식을 바탕으로 답변을 해야 함. KG는 한번만 입력되고, Taking into account the graph, {question}와 같은 형식을 만들어서 질문을 하게 된다.
KG의 사이즈가 커진다면, ChatGPT에 어떻게 다 넣을지?
2. Experiments with text-to-SPARQL using the A-Box and the T-Box
입력으로 전달된 특정 KG에 대해 NL 질문을 SPARQL 쿼리로 변환하는 ChatGPT의 기능을 테스트한다. 입력 KG는 turtle RDF에서 상호작용이 시작될 때, ChatGPT에 한번만 다시 전달됨. 각 NL 질문은 다른 대화와 격리된 단일 채팅 인스턴스 내에서 다시 전달되고, Write a SPARQL query for the question using only classes and properties defined in the graph, and remember to include the base URI declaration in the query and non-essential properties as opetional: {question}와 같은 프롬프트를 구성한다.
위 방법과 차이는 (1)은 KG와 NL을 기반으로 바로 답변을 생성하도록 하는 것이고, (2)는 KG와 NL을 기반으로 SPARQL query를 작성하도록 한다는 차이가 있다.
✨ T-Box와 A-Box
T-Box와 A-Box는 온톨로지에서 정보를 구조화하는 두 가지 주요 구성 요소이다.
T-Box(Terminological Box)는 온톨로지의 구조적 및 정의적 정보를 포함하며, 주로 클래스(개념)과 속성에 대한 정의를 제공한다. 또한 개체나 인스턴스에 대한 구체적인 정보보다는 개념적인 틀을 정의한다. 예를 들어, 사람(Person)이나 나이(Age)와 같은 개념이 T-Box에 해당한다.
A-Box(Assertional Box)는 온톨로지의 데이터적 정보를 포함하며, 주로 실제 인스턴스나 개체에 대한 정보와 이들 간의 관계를 다룬다. 또한 T-Box에서 정의된 클래스와 속성에 대한 구체적인 데이터나 사실을 나태나는 역할을 한다. 예를 들어, 'John'이라는 인스턴스가 '사람(Person)'이라는 클래스에 속하며 '나이는 30살'이라는 실제 정보가 A-Box에 해당한다.
3. Experiments text-to-SPARQL using only the T-Box or the A-Box
여기서는 각 대화를 시작하면 T-Box와 A-Box가 Turtle RDF 형식으로 ChatGPT에 별도로 전달되는 두 가지 실험을 설명한다. 각 NL 질문은 다른 대화와 격리된 단일 Chat 인스턴스 내에서 다시 전달되었으며 프롬프트로 구조되 된다.
Write a SPARQL query for the question using only classes and properties defined in the graph, and remeber to include the base URI declaration in the query and non-essential properties as optional if needed. Declare filters on strings as filter operations over regex function using the case insensitive flag. The question is following: {question}
(2)와 (3)의 차이는 입력 데이터의 방식과 응답 처리 방법에서 발생한다. (2)는 KG를 TurtleRDF 형식으로 한 번만 제공받으며, 이때는 T-Box와 A-Box가 모두 포함되어 있다. (3)에서는 KG의 T-Box와 A-Box 부분을 분리하여 각각 별도로 제공받게된다.
세 가지 방법을 테스트 해봤을 때, T-Box와 A-Box를 모두 통과하는 text-to-SPARQL 접근 방식이 가장 좋은결과를 생성한다는 것을 확인했다고 한다. ((2)번 방식으로 이해함) 그러나 이렇게 하기에는 KG가 클 경우 context length의 제한이 문제라는 한계가 있으며, 따라서 NL과 가장 관련성이 높은 subgraph를 선택하는 접근 방식인 Auto-KGQAGPT 방식을 소개한다.
Auto-KGQAGPT: An LLM-Based Framework For Text-To-SPARQL
이 프레임워크는 offline stage와 online stage 두 단계로 구분된다.
Offline Stage
offline stage에서는 SPARQL 엔드포인트를 통해 입력으로 KG(T-Box 및 A-Box)를 수신하고 online stage에서 사용되는 두 개의 인덱스를 생성한다. 첫 번째 인덱스는 클래스 및 속성 레이블에서 해당 URI로의 매핑을 생성하여 NL 용어를 T-Box 리소스에 매핑하는 역할을 한다. 두 번째 인덱스는 A-Box(인스턴스) 리소스 레이블에서 해당 URI로의 매핑을 생성하여 NL 용어를 A-Box 리소스로 매핑하는 역할을 한다.
이 인덱스들은 자연어 질문에서 특정용어가 지식 그래프의 어떤 요소를 참조하는지를 식별하는 데 사용된다.
GenerateIndexes, PopulateIndex는 T-Box와 A-Box를 각각 인덱싱하는 과정을 담당한다. 인덱스는 각 용어에 대해 URI, 레이블, 타입 그리고 그 용어가 참여하는 트리플 수 등의 속성 정보를 저장한다. 이 인덱스를 통해서 만약 query에서 '사람'이라는 단어가 언급되면 'Person'와 연결지을 수 있는 것이다.
유사도를 기반으로 연결되는걸까?
Online Stage
online stage에서는 사용자의 NL 질문 S를 입력으로 받고 LLM을 사용하여 S를 SPARQL 쿼리 Q로 변환한 다음 KG에서 Q를 실행하여 사용자에게 전송되는 응답을 생성하는 과정이 진행된다. 이 단계에서는 offline stage에서 생성된 인덱스를 사용하여 NL 질문에서 KG 용어에 대한 참조를 식별한다. LLM은 이러한 용어와 관련된 KG의 일부만 수신한다.
AnswerQuestion Algorithm 단계에서는 자연어 질문이 입력되면, 해당 질문을 정규화해서 중요한 토큰을 변환해서 지식그래프와 매칭될 수 있도록 한다.
이후 SelectResources Algorithm를 통해 추출된 핵심 용어들을 T-Box와 A-Box 인덱스와 비교해서 지식그래프 요소들인 class, property, instance를 식별한다.
SelectTriples Altorithm은 선택된 자원들을 바탕으로 지식그래프의 관련된 부분만 추출하는 과정이다. 전체 그래프를 LLM에 전달하면 토큰 수가 너무 커지기 때문에, 질문과 관련된 지식그래프 일부 조각만을 선택해서 전달하는 장식이다. 일부 조각은 Turtle 형식으로 직렬화하여 LLM이 이해할 수 있도록 한다. 그리고 Prompt Patterns을 통해서 앞서 만든 지식 조각, 즉 subgraph를 LLM에 넣어서 SPARQL query를 생성하고 여러 query 중 가장 적합한 쿼리를 선택한다.
정리하면, offline stage에서는 KG를 Indexing해서 저장하고, oneline stage에서는 prompt에 해당하는 값들만 찾아서 직렬화해서 LLM에 참조 정보로 넣어준다는 것이다.
결국, KG의 사이즈를 줄여서 넣어주지만, 전체 값을 다 넣는 것이 아니라 일부 필요한 부분만 retrieve하는 것을 의미하는데, 이때 해당하는 값을 찾는 방법이 뭔지 잘 모르겠다. 정규화해서 indexing한다는 것은 exact match되는 값을 찾는다는 의미 같기도 하고, 문자열 유사도를 통해서 볼 수도 있을 것 같은데, 어떤 방법을 사용한 건지? -> SelectResources Algorithm 부분을 보면, 추출된 용어와 인덱스에 저장된 레이블 간의 relevance scores를 계산한다고 한다. (레벤슈타인이나 코사인 유사도를 쓸 듯)
