[논문리뷰] From human experts to machines: An LLM supported approach to ontology and knowledge graph construction
Paper Review

한 줄 요약:
LLM을 활용하여 (semi-)automatic하게 KG를 구축하는 방법
기존의 온톨로지와 KG는 각 엔티티와 관계를 정의하고, 계층관계를 구축하며, ABox(인스턴스 간의 관계), TBox(개념적인 관계)를 채우는 과정 등 상당히 노동 집약적인 과정을 통해 구축된다. 이 연구에서는 이러한 작업들을 LLM을 활용한 반-자동화 프로세스를 구축하여 human resource를 줄이고자 하는 시도를 진행했다.
참고로 이 논문은 Apache의 jena를 활용하고, 모든 소스코드를 깃헙에 공개하고 있다.
📌 Introduction
서론에서 언급되는 온톨로지와 지식그래프의 특징은 다음과 같다.
- 온톨로지
- 도메인 분야의 정보를 조직하고 표현함에 있어서의 기본 프레임워크
- 지식그래프를 구축하기 위한 기초 역할을 함
- 지식그래프
- 다양한 정보를 상호 연결하는 강력한 메커니즘
- 정교한 데이터 분석과 추론을 촉진할 수있음
즉, 온톨로지 내에서 '캡슐화'된 도메인 지식은 다양한 지식 집약적 응용 프로그램에서 중요한 자산이 된다고 한다.
캡슐화(encapsulated)는 특정 분야의 지식에 대하여 관련 개념과 관계를 명확하게 정의하여 컴퓨터가 복잡한 정보 체계를 구조적으로 관리할 수 있도록 하는 방식을 의미한다.
그러나 이때의 온톨로지와 지식그래프는 학제간 협력을 통해서 구축해야 하는만큼, 많은 시간과 자원이 소요된다. 특히 온톨로지의 표현력을 높일수록(구체적) 정확성, 확장성, 지식의 깊이 등 복잡한 설계 과정이 필요하다. 일반적으로 KG를 구축할 때는 도메인 전문가로부터 모은 CQs(Competency Questions)를 통해 도메인 요구사항을 수집하고, CS분야의 과학자들이 협력하여 온톨로지를 개발하며 구조화되지 않은 데이터를 구조화된 형식으로 변환하여 KG를 구축하는 과정으로 진행된다. 즉, 온톨로지 설계를 하고 데이터를 전처리, 그래프로 변환한다는 의미이다.
논문에서는 다음과 같은 질문을 한다.
'온톨로지 구축의 자원(노동) 집약적 특성과 도메인 지식을 효과적으로 활용해야 하는 필요성 사이에서 어떻게 균형을 맞출 수 있을까?'
논문에서는 이에 대한 방안으로 LLM을 활용한 KG 구축을 제안하며, 이를 통해 인간의 노력을 최소화하고자 한다. 최근 LLM은 자연어 처리와 지식 표현 부분에서 뛰어난 성능을 보이고 있고, 다양한 언어와 분야에서 인간과 같은 텍스트를 생성할 수 있다. 따라서 온톨로지를 구축하기 위한 CQs 구축 부터 온톨로지 생성, 데이터 채우는 작업까지 LLM을 활용한 반-자동 구성을 진행한다. 또한 이 평가는 생물 다양성 분야의 학술 출판문에서 추출한 딥러닝 방법론에 대한 온톨로지와 지식그래프 생성을 통해 진행한다.
📌 Related work
LLM은 지식 엔지니어링과 자연어 처리(NLP) 분야에 혁명을 가져왔으며, 다양한 언어 작업에서 인간 수준의 성능을 보여주고 있다. KG Completion, Ontology refinement, question answering 등 다양한 응용을 탐색하는 방향으로 빠르게 확장되고 있다.
최근에는 지식 그래프 엔지니어링에서 LLM을 사용하는 방법에 대한 연구들이 수행되고 있다. LLM을 활용하여 지식그래프 스키마와 온톨로지를 강화하는 등의 지식그래프 엔지니어링의 응용 영역 목록을 제시하거나(Meyer et al.), LLM을 강화하기 위한 KG 혹은 그 반대의 경우에서의 가능성에 대해서 언급한 논문들이 있다(Pan et al.). 또한 온톨로지의 생성, 확장, 완성과 학습을 LLM을 활용하는 방식도 제안되었는데, Cohen 등은 'subject-relation-object' 문장 형식을 사용하여 LLM에서 지식 그래프를 추출하는 크롤링 접근법을 제시했으며, Funk 등은 시드(기초)개념에서부터 주어진 도메인에 대한 개념 계층을 구축하는데 중점을 두었다. 그러나 이 연구들은 subconcept/is-a 관계만 고려하고 다른 관계는 고려하지 않았다는 한계가 있다.
해당 연구에서는 모든 개념(concepts)과 관계(relations)를 기존에 있는 온톨로지를 재사용하는데 중점을 둔다고 한다. 한편, LLM을 사용한 지식 그래프나 온톨로지 구축에 관한 연구는 제한점이 있으며, LLM을 활용하여도 여전히 전문가 협업과 커뮤니티 내의 합의 등의 과정을 거치는 근본적인 프로세스는 유지되어야 하지만, 이 과정에서 LLM을 통한 온톨로지스트의 생산성 향상과 개발의 단순화에 도움을 줄 수 있다고 설명한다. 또한 이 연구는 오픈소스 LLM을 사용한다는 점에서 의의가 있다.
📌 Methods
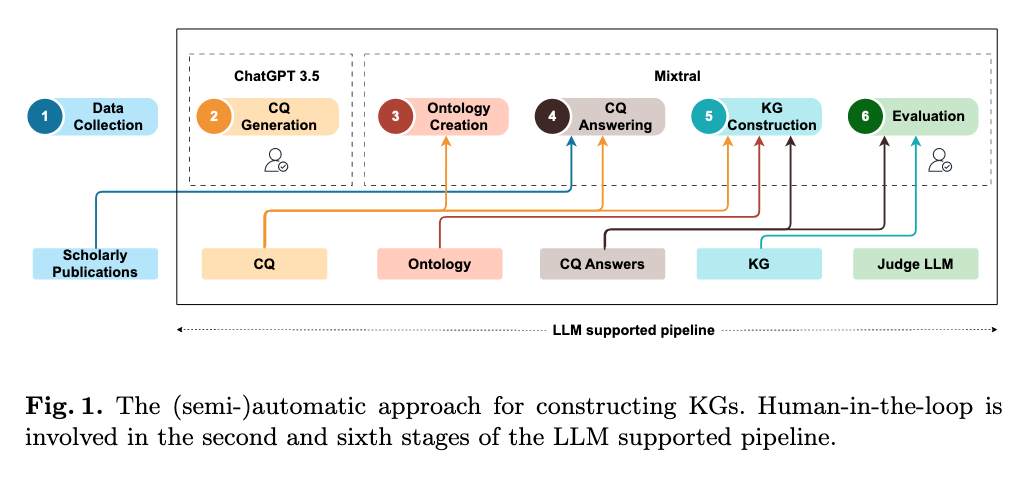
KG를 반-자동적으로 구축하는 과정은 다음 6단계로 진행된다. (다 읽고 위 fig를 다시 봤을 때, 각 부분의 input에 대해서 명확하게 보여준다는 점에서 효과적인 표현법인 것 같다는 생각을 했다)
(1) Data Collection
데이터셋은 이전 연구에서 사용한 것을 재사용했다고 한다. 데이터 구축 과정은 다음과 같다.
- Google Scholar에서 생물다양성 전문가가 제시한 키워드(생물다양성 연구에 딥러닝 기술 관련)를 검색 활용한 출판물 검색
- 전문가의 관련 출판물 데이터셋 큐레이션을 통해 61개 선정
- 두 명의 도메인 전문가가 61개 출판물 중 5개에 대해 재현성(reproducibility) 관련 변수를 수동으로 추출
(2) CQs generation
Competency Questions를 한국어로 해석하면 '역량 질문' 혹은 '적격성 질문' 정도 되는데, 이는 온톨로지가 답할 수 있어야 하는 질문들의 집합을 의미한다고 한다. 즉, 온톨로지를 구축하는 과정에서 어떤 지식을 표현해야 하는지 정의하고(요구사항 명세), 이에 대해 개발자가 이해하는 지침을 제공하며(설계 지침), 완성된 온톨로지의 성능을 파악할 수 있는 기준(평가 기준)이 될 수 있는 질문들을 의미하는 것이다.
아마도 특정 도메인의 정보를 담고 있는 텍스트 문서(이 논문의 경우 5개 출판물에서 출판한 딥러닝 방법론에 대한 문서)를 ChatGPT-3.5에 넣어서 프롬프팅을 통해서 질문을 생성하는 방식으로 진행했을 것 같다.
이 논문에서는 ChatGPT-3.5를 사용하여 CQs를 생성한 뒤, 두 명의 인간 도메인 전문가가 검토하고 개선하는 방식으로 진행한다. 이 질문들은 나중에 온톨로지 구조를 설계하고, RAG를 통해 학술 논문에서 관련 정보를 추출하는 데 사용되었다고 한다.
CQs를 생성한 뒤, 3개의 오픈 소스 모델(Llama 2-70B, Mixtral 8x7B, Falcon-40B)을 비교하는 작업을 진행했는데, 각 모델의 출력값을 수동으로 비교한 결과, Mixtral 8x7B 출력이 상대적으로 우수하여 이후 단계의 활용 모델로 채택했다고 한다. 모델은 따로 파인튜닝을 하진 않고 제로샷으로 진행되며, temperature는 10^(-5), 최대 출력 토큰은 25000로 설정한다. 또한 RAG 파이프라인에서는 chunk size는 2500, overlap size는 100으로 설정한다.
(3) Ontology creation
CQ를 기반으로 온톨로지를 구축하는 과정은 두 단계로 진행된다.
- CQs로부터 모든 엔티티와 관계를 추출
: 지시사항 세트와 예상 출력이 포함된 예제 CQ를 프롬프트에 포함하여 진행한다. (few-shot) - 딥러닝 파이프라인 정보 설명을 위한 온톨로지 구성
: 온톨로지 구성을 하기 위해서 in-context 예제를 제공하는데, 이때의 예제는 PROV-O(W3C에서 권장하는 출처(provenance) 기술을 위한 표준 온톨로지)를 기반으로 사용한다. 즉, 이미 잘 설계된 표준 온톨로지를 재사용함으로써 표준 용어와 호환성을 확보하고 CQ에서 추출한 개념과 관계를 통합한다는 것이다.
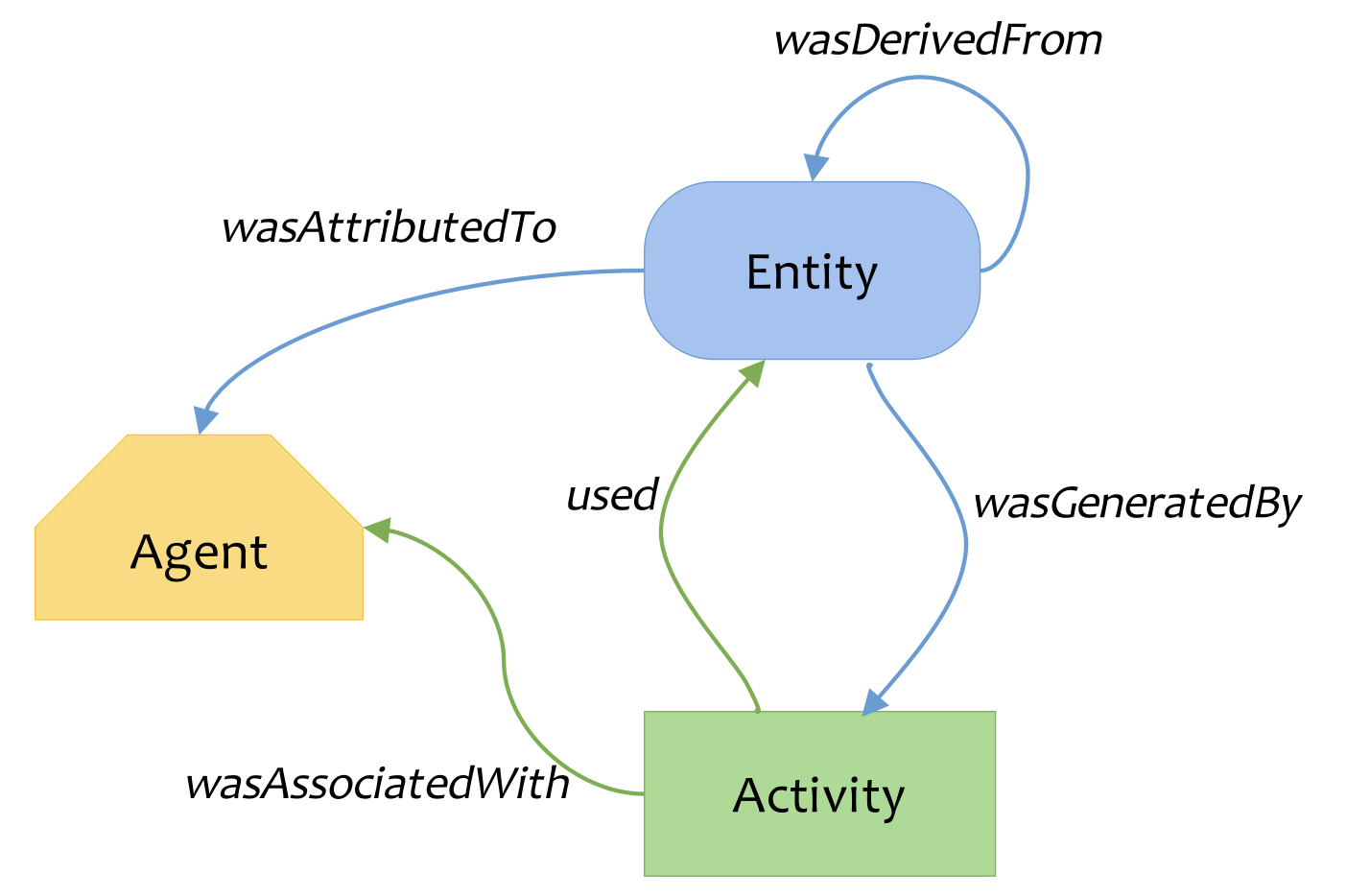
PROV-O란?
- 이미지 출처: 위키피디아
PROV-O(온톨로지)는 W3C에서 권장하는 프로비넌스(provenance) 정보를 표현하기 위한 것으로, 데이터나 문서의 출처, 생성 과정, 변경 이력 등을 기술하기 위한 표준화된 방법을 제공한다.
기본 구성 요소: PROV-O의 기본 구성 요소는 다음과 같다.
- 엔티티(Entity): 데이터, 문서, 시스템과 같은 물리적, 디지털 또는 개념적 객체
- 활동(Activity): 엔티티를 생성, 처리 또는 변환하는 프로세스
- 행위자(Agent): 활동에 책임이 있는 사람, 조직 또는 소프트웨어
기본 구성 요소들 간에는 다음과 같은 다양한 관계가 정의된다.
- wasGeneratedBy: 엔티티가 특정 활동에 의해 생성됨
- wasAttributedTo: 엔티티가 특정 행위자에 귀속됨
- wasAssociatedWith: 활동이 특정 행위자와 연관됨
- used: 활동이 특정 엔티티를 사용함
(4) CQ Answering
이 단계는 파이프라인, 특히 KG 구축의 중심 구성 요소이다. 모든 CQs에 대해서 앞서 선택한 5개의 생물다양성 학술 출판물을 사용하여 RAG 기반 답변을 생성한다. 이후, 기본 텍스트 처리 기술(?)을 적용하여 중복되거나 반복된 콘텐츠를 제거한다.
(5) KG construction
KG를 구축하기 위해 CQ와 답변, LLM이 생성한 온톨로지를 LLM에 입력값으로 제공한다. 프롬프트를 통해 LLM에게 CQs의 답변에서 주요 엔티티, 관계, 개념을 추출하고 온톨로지에 매핑하여 KG를 생성하도록 지시한다.
(6) Evaluation
지금까지 단계를 거치면, CQs의 답변과 추출된 KG 개념들이 출력되고 이를 각각 평가한다. 평가 방법은 기본적으로 LLM judge를 활용한다.
우선 4번 단계에서 진행한 CQs 답변의 경우, 인간이 만든 ground truth와 LLM judge를 기반으로 평가한 내용을 비교한다. 인간 평가자는 전체 논문 중 5개의 학술 논문에 대해서만(전체 평가를 인간이 진행하면 너무 오랜 시간이 걸리기 때문) CQ의 답변을 '정답', '부분 정답', '오답' 세 개로 라벨링 진행한다. LLM judge는 연구자가 생성한 ground truth를 기반으로 0~10사이로 답변을 다시 평가하고, 그 결과는 6점 이상일 경우 정답, 3-5점은 부분 정답, 3점 미만은 오답으로 분류된다.
5번 단계의 결과인 KG 구축 결과도 LLM judge로 평가되는데, 개별 KG의 개념이 각각의 생성된 CQs의 답변에 등장했는지를 확인한다. 확인 방법은 온톨로지 개념을 사용하여 KG의 개별 개념과 생성된 CQ의 답변 사이의 링크를 설정한다고 한다.
예시 (Claude를 활용하여 생성)
- CQ: "이 연구에서 사용된 신경망 아키텍처는 무엇인가?"
- CQ Answer: "이 연구에서는 이미지 분류를 위해 CNN(Convolutional Neural Network) 아키텍처를 사용했으며, 구체적으로는 ResNet-50 모델을 적용했습니다. 이 모델은 50개 층으로 구성되어 있으며..."
- KG:
dlprov:Architecture_1 rdf:type dlprov:DeepLearningArchitecture ; rdfs:label "CNN" ; dlprov:hasModelName "ResNet-50" .- 평가 과정
- "CNN"과 "ResNet-50"이 CQ 답변에 나타나는지 검사
- 온톨로지 개념(DeepLearningArchitecture, hasModelName)을 사용하여 KG individual concept(Architecture_1)과 CQ 답변 간의 연결을 확립
- DeepLearningArchitecture 클래스의 인스턴스가 CQ 답변에 언급된 아키텍처와 일치하는지 확인
- hasModelName 관계가 CQ 답변에 언급된 모델 이름과 일치하는지 확인
.
.
정리하면, 문서를 기반으로 CQ(질문)를 생성하고(2단계), CQ(질문)을 기반으로 모든 개념과 관계를 추출하여 PROV-O기반의 온톨로지(스키마)를 구축하고(3단계), CQ의 답변을 RAG 기반으로 생성한 뒤(4단계), 2~3단계의 결과를 기반으로 KG를 구축한다(5단계). 이후 4단계와 5단계의 결과를 각각 인간 연구자와 LLM judge가 평가를 진행한다.
📌 Results
이제 위의 연구 방법을 기반으로 실제로 수행한 연구의 결과이다. 각 단계별로 결과를 정리하면 다음과 같다.
✅ Step2
위 과정을 통해 생성한 CQs는 총 40개이다. 이 질문들은 딥러닝 파이프라인의 모든 단계(원시 데이터 소스, 전처리 기법, 모델 아키텍처, 하이퍼파라미터 설정, 소프트웨어/하드웨어 선택, 후처리 단계, 민감한 데이터 처리를 위한 보안 조치, 데이터 편향 및 윤리적 고려사항)의 내용을 포함한다.
✅ Step3
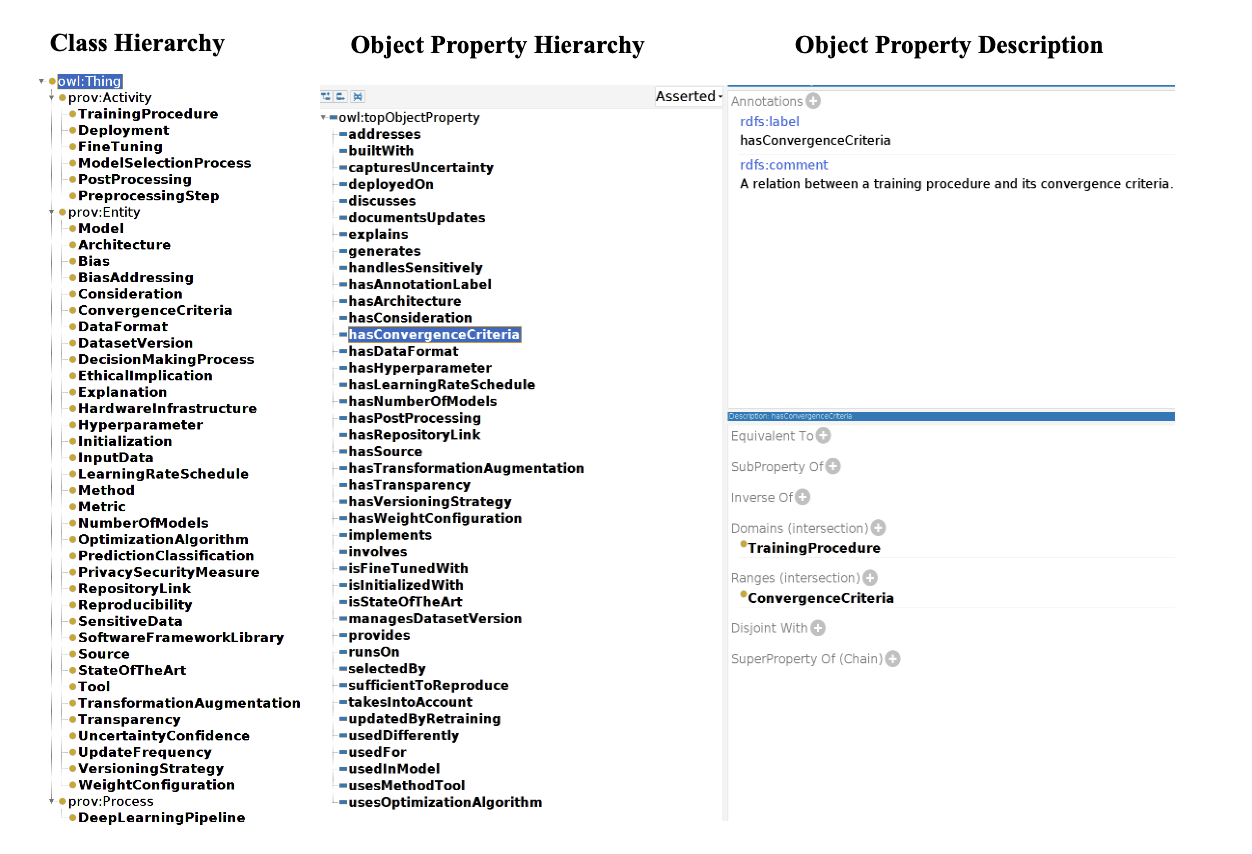
CQs와 PROV-O를 재활용하여 만든 DLProv 온톨로지는 45개의 클래스와 41개의 관계, 그리고 365개의 공리(axioms)로 구성된다.
axioms는 개념들 사이의 관계와 제약 조건을 명시적으로 정의하는 논리적 표현으로, 온톨로지가 표현하는 지식 도메인의 '규칙'이나 '사실'로 볼 수 있다. axioms는 온톨로지의 표현력과 추론 능력을 결정하는 중요한 요소이다.
그러나 PROV-O를 재사용한 정도는 제한적인데, 세 개의 PROV-O 클래스에만 하위 클래스로 개념이 추가되었고, 객체 속성은 재사용하지 않았다고 한다. MLSchema 온톨로지를 재사용하려는 다른 실험에서는 하나의 클래스만 재사용되고 객체 속성은 재사용되지 않았다.
figure2를 보면, Class의 계층적 구조는 최상위에 owl:Thing을 두고 하위로 prov:Activity, prov:Entity, prov:Process가 있고 각각의 클래스의 하위에 sub-class들이 명시되어 있다.
Property의 경우, PROV-O의 속성을 재사용한 경우는 없었다. 즉, 모두 DLProv에서 새로 정의했다는 것이다.
✅ Step4
RAG기반으로 생성된 CQs의 답변 평가 결과를 보면, 200개의 질문에 대하여 인간 연구자와 LLM judge의 답변을 비교해보면 42개가 의견 불일치가 있었다고 한다. 대부분의 경우, 인간 평가자는 '부분적 정답'이라고 평가했지만, LLM judge는 '오답'이라고 평가했으며 이를 통해 LLM judge가 더 엄격한 기준으로 평가했음을 알 수 있다.
✅ Setp5
CQs의 답변들과 온톨로지(스키마)를 기반으로 생성된 트리플 형식의 KG는 다음과 같은 형태로 구축되었다.
dlprov:DeepLearningPipeline1 rdf:type dlprov:DeepLearningPipeline ;
dlprov:hasDataFormat dlprov:DataFormat1 ;
dlprov:hasDataFormat dlprov:DataFormat2 .
dlprov:DataFormat1 rdf:type dlprov:DataFormat ;
rdfs:label 'Audio Spectrogram' .
dlprov:DataFormat2 rdf:type dlprov:DataFormat ;
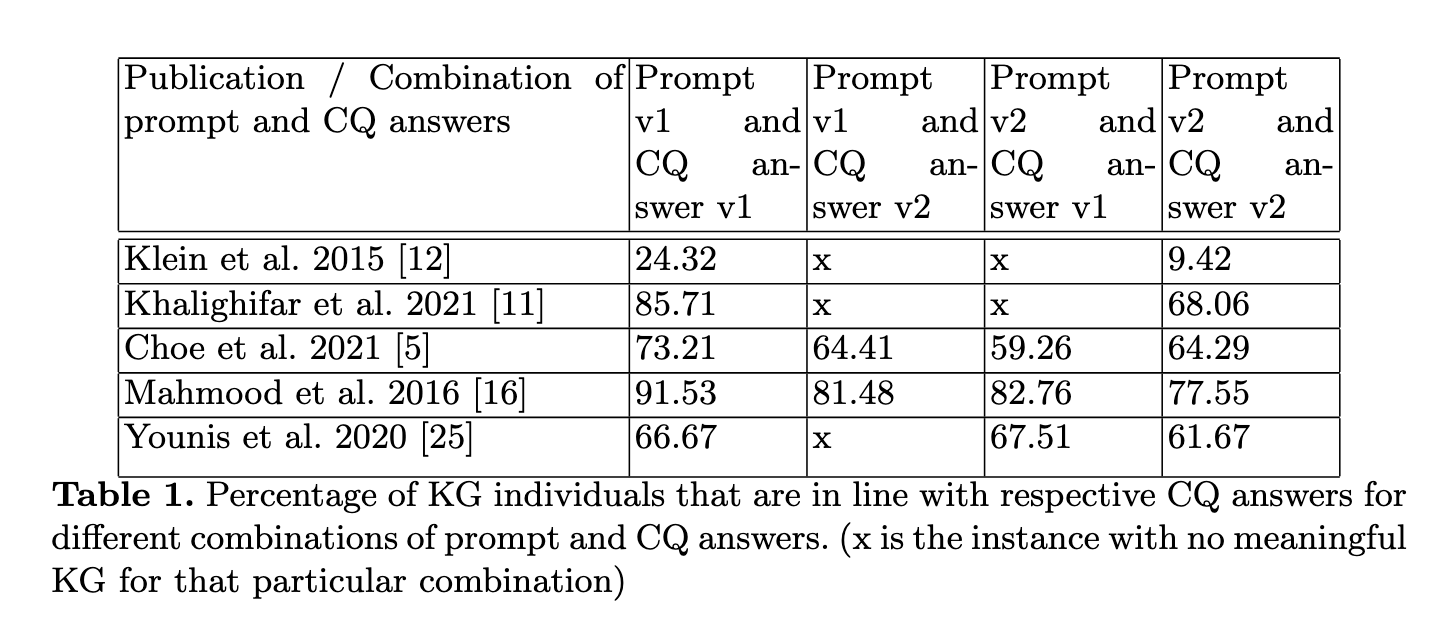
rdfs:label 'Image data' .연구팀을 여러방식으로 다양한 버전의 KG를 구축했는데, 두 가지 다른 프롬프트와 두가지의 다른 RAG기반으로 생성한 CQ의 답변을 조합했다고 한다. 이 중 가장 좋은 성능을 보인 지식 그래프는 5개의 학술 출판물에서 추출한 총 203개의 개체 중 142개, 즉 약 70%의 KG 개체를 CQ 답변과 성공적으로 연관시켰다. 아래 테이블에 따르면, 방법에 따라서도 결과가 다르지만, 출판문에 따라서도 상이한 결과가 도출될 수 있음을 알 수 있다.
📌 Discussion
초기 단계에서는 전체 학술 출판물 내용을 한 번에 제공하여 딥러닝 파이프라인의 방법 정보를 표현하는 지식 그래프를 바로 생성하려고 했는데, 이 방식은 KG와 관련된 내용을 거의 제공하지 않았다고 한다. 따라서 지금과 같이 약 6단계로 분리하여 진행했다.
LLM을 기반으로 CQs의 답변을 생성하는 과정에서는 모델이 답변에 불필요한 정보까지 너무 과도하게 포함하여 도출하는 경향이 있었다고 한다. 따라서 '자동 텍스트 처리 기술'을 사용하여 중복되고 반복적인 내용을 제거했다고 한다.
자동 텍스트 처리 기술이란? 아마도 룰베이스로 중복되는 내용을 삭제하는 로직을 만들었을 것으로 추측한다.
또한 생성된 지식 그래프(KG)의 형식이 실제 사용 환경과 완벽하게 호환되지 않는 경우가 있었는데, 특히 라이브러리나 SPARQL 엔진과의 호환성을 확보하기 위해서는 추가적인 조정이 필요했다고 한다.
프롬프트 엔지니어링의 중요성에 대해서도 언급하는데, KG 구축 중에는 CQ의 답변과 온톨로지의 프롬프트 입력 순서를 바꾸는 것도 결과에 영향을 미쳤다고 한다. 따라서 연구자들은 필요한 부분에 in-context examples를 포함하여 최대한 변동성과 환각을 줄이고자 했다고 설명한다.
평가 과정에서는 RAGAS나 Tonic ai를 활용하여 RAG의 생성 결과를 평가하려고 했는데, 이때 OpenAI의 API 키를 제공할 때만 완전히 작동했기 때문에 프롬프팅을 통한 LLM judge로 평가를 진행했다고 한다.
이 부분에 대해서 정말 그런가?에 대한 의문이 있었는데, 아마 RAGAS에서 평가 모델을 로컬 모델로 수정하면 가능하지 않을까 싶다.
📌 Conclusion
이 연구는 온톨로지와 지식 그래프 생성에 오픈소스 LLM을 활용하는 가능성을 탐색하며 잠재적으로 LLM이 인간 전문가의 보조적 혹은 공동 작업자 역할을 할 수 있음을 보여줬다. 향후 연구로는 이 파이프라인을 지속적으로 개선하며, 다양한 오픈소스 LLM과 프롬프트 개선을 통한 결과 변화를 평가할 것이라고 한다. 또한 생성한 온톨로지를 다른 ML, DL 온톨로지와 매핑하는 방법을 탐색할 예정이라고 언급하며 논문을 마무리한다.
