[논문리뷰] Large Language Models, Knowledge Graphs and Search Engines: A Crossroads for Answering Users’ Questions
Paper Review

LLM, KG와 검색엔진의 장점과 단점을 파악하여 가능한 시너지 효과를 연구한 논문이다. 개인적으로 논문을 읽으면서 참 깔끔한 정리라고 생각했는데(역시 대가의 논문..) 세 개념의 정의와 비교 분석, 그리고 앞으로의 발전 방향 제시까지 모든 부분을 굉장히 이해하기 쉽게 정리해서 설명하고 있다(직관적인 테이블 정리와 적절한 그래프까지).
📌 Introduction
몇 년 사이에 활발히 사용되고 언급되는 생성형 AI는 대부분 Transformer 아키텍쳐 기반의 다음 토큰을 예측하는 generation 모델이다. 흔히 LLM이라고 불리는 이 모델들은 다양한 범위의 답변을 유연하게 한다는 특징이 있지만, 논문 앞부분에 제시한 예시와 같이 여전히 잘못된 정보를 사실인 것 처럼 답변하는 hallucination과 같은 문제들이 존재한다. 저자가 정리한 LLM의 한계점은 다음과 같다.
- Hallucination: 실제 데이터를 기반으로 하지 않는 상황과 사실들을 '창조'하는 능력이 떨어짐
- Opaqueness: 답변의 출처가 불투명함
- Staleness: 계속 재학습을 시키지 못해서 최신 정보를 반영하지 못함
- Incompleteness: 확률적인 계산에 의해 가장 그럴듯한 답변을 하지만, 실제로 이를 검증할 순 없음(전체 목록을 열거 할 수 없다는 불완전성)
이러한 한계점들을 보완할 수 있는 방법으로 Search Engine을 붙여서 더 많은 정보를 Augmented 한 답변을 하는 RAG 기법이 제안되었으나, 여전히 long-tail 주제(희소하고 드물게 발생하는 현상이나 정보)에 대해서는 한계점이 있다고 한다.
KG는 정형화된 구조의 데이터와 지식을 기반으로 한다는 점에서 LLM의 한계점을 보완할 수 있는 가능성을 가진다. 이 논문은 이에 대한 증명을 해나가는 식으로 진행된다.
📌 SE vs. KG vs. LLM
논문에서는 세 기법을 (무려) 15가지 측면에서 비교하고 있다. 이 모든걸 다 정리할 순 없어서 논문에서 제시한 테이블로 대체하고, 인상깊었던 부분만 추가 설명을 해보겠다. 참고로, 최근에는 LLM에 Search Engine을 붙여서 답변을 하는 기능이 많이 사용되고 있지만, 논문에서 비교하는 LLM은 다른 기능을 붙이지 않은 그 자체만을 기준으로 한다고 설명한다.

Completness
'완전성'의 의미는 base corpus에서 관련있는 모든 정보를 반환할 수 있는 능력을 의미한다. KG는 관련있는 완전한 정보들을 모두 반환할 수 있으며, SE 역시 인덱싱한 모든 정보를 반환할 수는 있지만 이때의 정보가 반드시 쿼리와 관련된 정보는 아닐 수 있다고 한다. LLM의 경우 종종 불완전한 답변을 생성하는데, 예를들어 LLM으로는 '밥 딜런의 노래를 커버한 모든 가수의 모든 목록'을 생성함에 있어 수천명의 뮤지션을 나열하는 것은 거의 불가능하다. 다만, KG와 SE 역시 '완전함'의 범위를 불분명하긴 하다.
한편, 답변의 완전성은 답변의 투명성 혹은 출처 제공 가능성과도 연관이 되는 부분이라고 생각했다. KG, SE는 일반적으로 정보의 출처를 추적할 수 있는 메타데이터를 포함하므로, 정보의 출처가 상대적으로 명확하다. 반면, LLM은 학습된 데이터 전체를 출처로 삼지만, 다양한 출처의 정보가 모델 가중치에 통합되어 있어, 특정 답변이 어떤 출처에서 왔는지 명시하기 어렵다.
Generation
LLM의 Generation은 쉽게 이해가 되는데, KG의 Generation은 잘 상상되지 않았다. 이때의 '생성'이란 기존의 코퍼스에서 새로운 콘텐츠를 도출하는 것을 의미한다. KG는 그 자체로는 생성적이지 않지만, 온톨로지와 규칙은 연역적 추론을 통해 새로운 지식을 생성할 수 있으며, 지식 그래프 임베딩과 그래프 신경망은 귀납적 추론을 통해 새로운 지식을 생성할 수 있다. 검색 엔진(SE)은 그 자체로는 생성적이지 않고 일반적으로 기본 정보를 있는 그대로 사용자에게 반환할 수 있을 뿐이다 .
Coherency
'일관성'은 동일한 질문에 대해서 항상 논리적으로 일정한 답변을 할 수 있는지를 의미한다. KG는 결정론적(deterministic)으로 설계되어 있어 항상 일관성이 유지되며, SE는 rank 알고리즘에 따라서 일부 변화가 있을 수 있다. 반면 LLM은 같은 질문에 대해 높은 확률로 매번 다른 형식으로 답변을 한다. 이에 따라 KG나 SE에서는 가능한 쿼리 동등성(query equivalence)를 LLM에서는 가능하지 않다는 것이다(e.g. A와 C쿼리는 반드시 모두 B라는 동일한 답변을 도출하는 쿼리이다)
Refineability
'정제(개선) 가능성'은 미래에 반환되는 정보의 품질을 향상시키기 위해 수정할 수 있는 능력을 의미한다. KG와 SE에서 불완전하거나 부정확한 결과는 대개 누락되거나 잘못된 입력 때문이므로 관리자가 수정하면 된다. 반면, LLM은 이러한 수정이 불가능할 수도 있는데, 이 오류가 발생하는 시점과 부분, 즉 원인을 알 수 없기 때문이다. 학습 데이터를 다시 잘 정제한다고 해도 반드시 문제가 해결된다는 보장은 없기 때문이다.
Expressivity
'표현력'은 잠재적인 복잡한 질문에 답변하고 표현할 수 있는 능력을 의미한다고 설명하는데, 사용자가 궁금한 문제에 대해서 질문하기 위한 쿼리의 표현력을 의미한다고 이해했다.
KG는 관계 간에 데이터를 연결하고, 지리적 지역과 같은 카테고리별로 엔티티를 그룹화하고, 그룹에 대한 집계를 계산하는 등 다양한 기능을 지원하는 표현력 있는 쿼리 언어를 제공한다. LLM과 SE는 자연어로 요청을 할 수 있으며, SE는 키워드 형태와 함께 최근에는 간결한 문장형으로도 요청할 수 있다. LLM은 긴 텍스트 요청을 받을 수 있으며 문서 형태(spreadsheet)도 가능한다. 그러나 텍스트 형태의 표현은 장단점이 있다. LLM은 KG에서 모델링하기 어려운 미묘한 표현을 포착할 수 있지만, KG는 텍스트에서는 불가능한 명확한 해석이 가능한 형식적 타입과 논리 연산자를 기반으로 명시적이고 명확한 쿼리를 생성할 수 있다.
Efficiency
'효율성'측면에서 SE와 KG는 모두 retrieval, 즉 query에 대한 답변을 반환하는 구조를 가지므로 inference(추론)을 거쳐야 하는 LLM 대비 효율적이다. 또한 SE는 KG에 대한 간단한 쿼리를 다룬다는 점에서 효율성 측면은 더 높다고 볼 수 있다. LLM은 추론 과정에서 막대한 컴퓨팅 리소스(CPU, GPU 등)이 필요하다는 점에서 비용적, 환경적 비용이 크다.
📌 The Perspective of Information-seeking users
KG, LLM, SE는 각각의 장단점이 있으며, 사용자가 어떤 목적을 가졌는지에 따라서 적합한 기법이 다를 수 있다. 본 논문에서는 사실적인 대답 뿐만 아니라 보다 광범위하고 포괄적인 사용자의 니즈 상황을 고려하고 있다.
결론부터 말하자면, KG는 정밀하고 효율적이며 투명한 방식으로 선별된 지식을 통해서 정확성있는 답변에 적합하지만, 다소 창의적인 요구(설명, 계획, 조언 등)에는 활용하기 어렵다. SE는 모든 종류의 질문에 답변할 수 있으나, 해당 질문에 대한 관련 문서가 있다는 전제하에만 가능하고, 복합적인 질문에 대해서는 사용자가 직접 여러 문서의 정보를 종합해서 이해하고 인사이트를 얻어야 한다. LLM 창의적이거나 여러 정보를 종합해서 답변할 수 있으나, hallucination을 유발할 수 있으며 어느 부분이 틀렸는지조차 파악하기 어려울 수 있다는 한계가 있다.
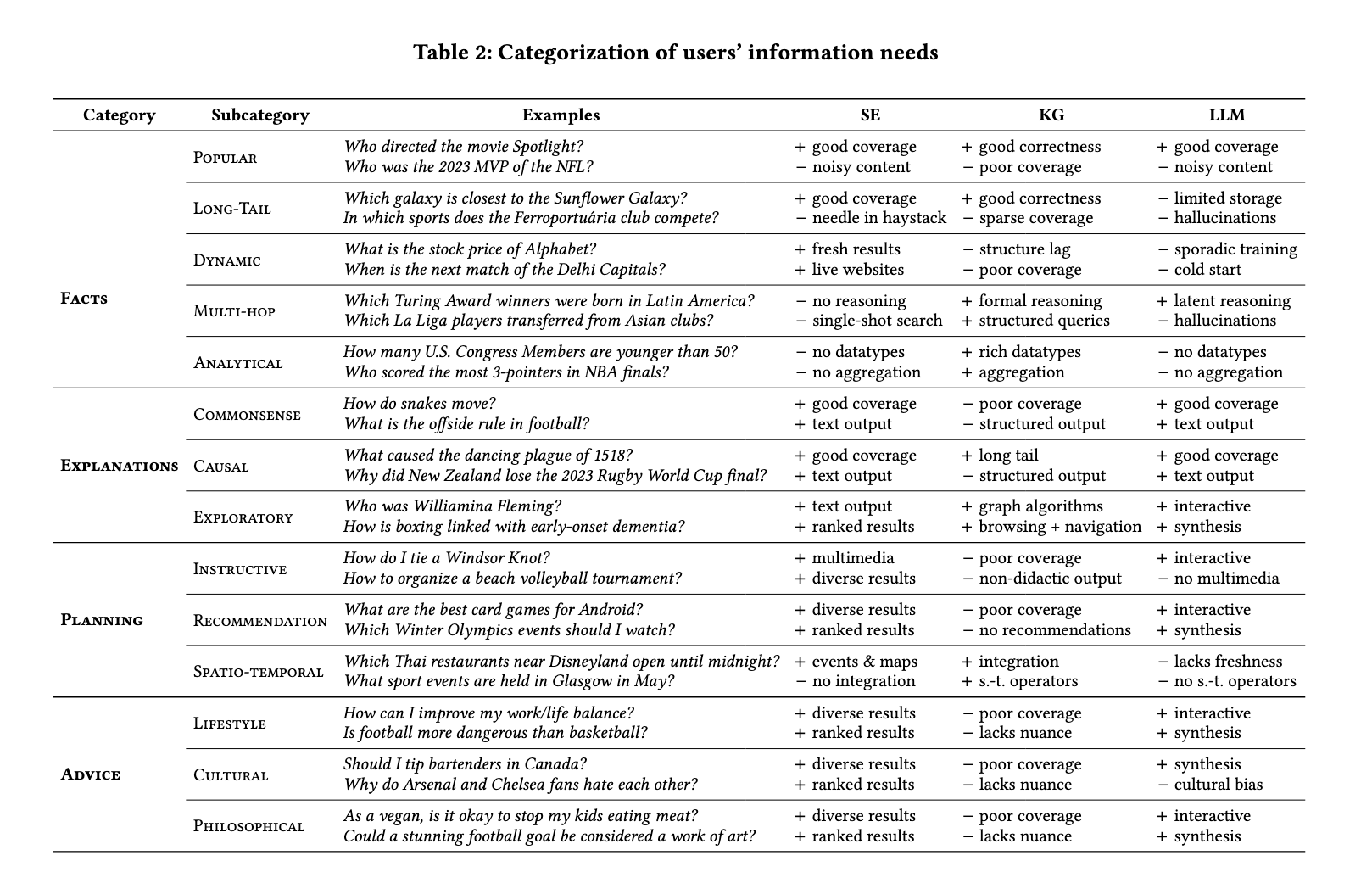
(1) Facts
Multi-hop query는 여러가지 다중 관계들을 파악하고 결합하여 답변해야 하는 질문을 의미한다. SE와 LLM은 연역적 추론에 약하기 때문에 이러한 유형의 질문에는 답변을 어려워하지만, KG는 구조적이고 경로 표현으로 추론을 통한 답변을 할 수 있다는 특징이 있다.
정확성, 사실적인 정보를 추론을 기반으로 답변하는 측면에서는 KG가 강점을 보임
(2) Explanations
Causal query는 사건이나 사실의 원인에 대한 설명을 포함한다. SE나 LLM의 경우 잘 알려진 사실에 대해서는 괜찮은 성능을 보이지만, 인과 관계가 복잡하고 자연어로 표현되기 어려운 사실에 대해서는 부족함이 있을 수 있다. 반면, KG는 이러한 복잡성에는 잘 대응하지만, 일반적으로 '원인'에는 미묘한 뉘앙스가 있으며 뉘앙스는 구조화된 형태로 잘 표현되지 않는다는 특징이 있다.
일반적인 사실의 원인은 복합적이기 때문에 설명하기 어려운 미묘한 뉘앙스 수준은 KG의 구조화된 형태로 표현되기 어렵다는 의미로 이해했다.
(3) Planning
Instructive query의 경우, SE와 LLM은 모두 지시 사항들을 도출해낼 수 있으나, 텍스트 형식보다는 이미지나 비디오 등의 형식이 더 적합할 수 있다는 점에서 SE가 가장 강점을 갖는다. KG의 경우 procedural knowledge, 즉 순서나 시퀀셜한 정보는 일반적으로 많이 포함하지 않는다는 점에서 활용도가 낮다. Recommandation query도 이와 유사한 특성을 갖는다.
Spatio-temporal query는 특정 지리적 또는 시간적 배경에서 정보를 찾는 것으로, SE는 최신 정보 제공에는 유리하지만 이 정보들을 종합하는데는 도움이 되지 않는다. LLM은 이를 종합하여 제공할 수 있다는 특징을 갖지만, 잘 알려지지 않은 장소나 real-time 정보는 제공하기 어렵다. KG는 지리공간 연산자를 사용하여 쿼리할 수 있는 풍부한 지리 정보를 포함하고 있지만, 이 역시 완전히 최신 상태가 아닐 수 있으며, 주관적 기준을 평가하는 데는 간접적으로만 도움이 될 수 있다.
(4) Advice
Lifestyle, cultural, philosophical 질문들은 모두 다양한 내용들을 복합적으로 반영한 답변이 필요하며, 미묘한 뉘앙스들을 반영해야 한다. 이에 따라 구조적인 쿼리로 표현이 어려워 KG는 다소 활용도가 낮다.
📌 Research Directions
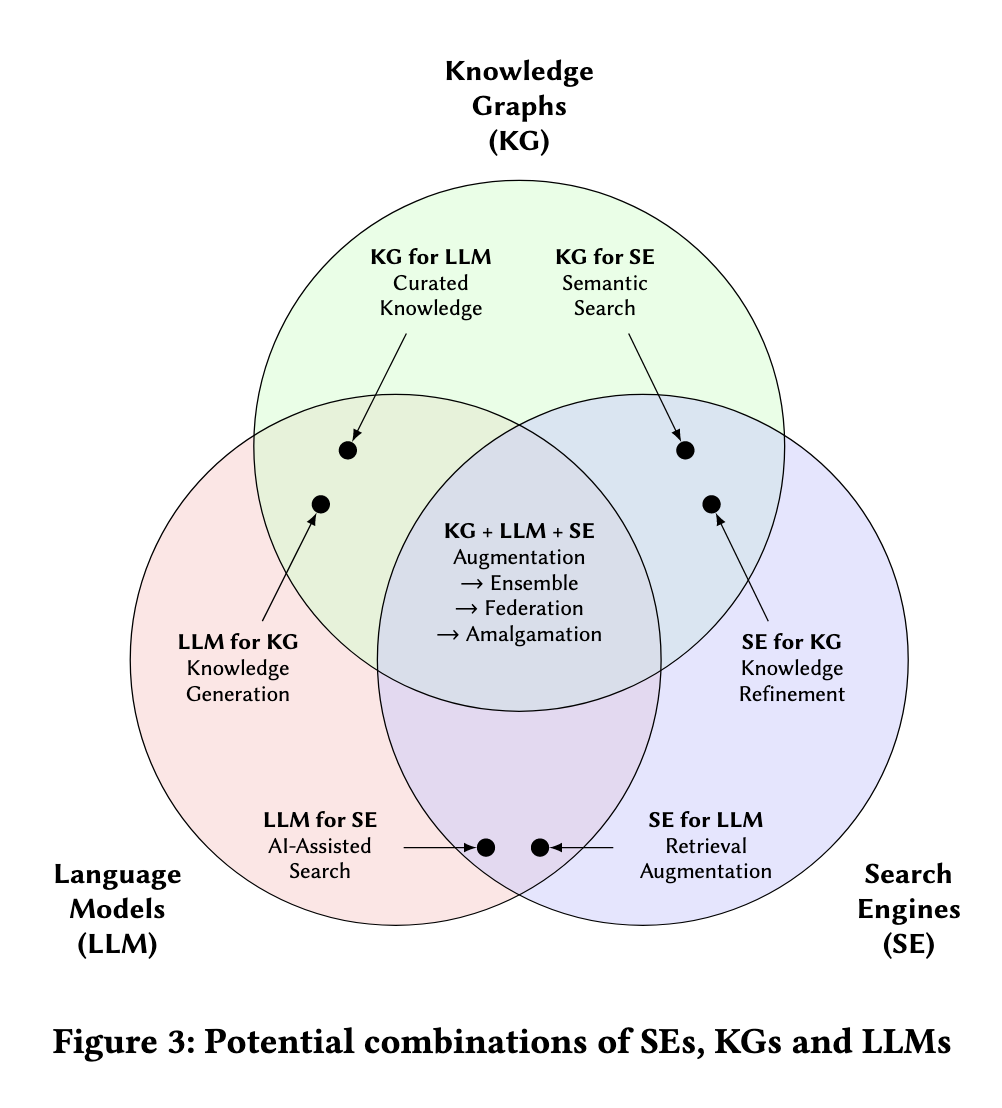
✅ Augmenting LLM
(1) KG for LLM
KG는 다음 두 가지 측면에서 LLM을 향상시킬 수 있다.
- 복잡한 문제를 다룰 수 있음(Multi-hop과 같은 다중 추론 문제)
- 답변의 정확성을 높일 수 있음
또한 LLM의 Training과정 부터 Inference 단계까지 모두 KG를 적용할 수 있는 가능성을 설명한다. Training 단계에서는 학습 데이터셋 구축 단계에서 KG를 활용한 factual info를 적용하는 방식과(entity markup in text documents, injecting entity types 등) LLM의 파라미터와 KG 임베딩을 동시에 학습하는 방법이 있다. Inference 단계에서는 RAG 방식으로 KG의 정보를 답변 생성에 넣어주는 방법이 있고 Post-processing 단계에서 생성된 답변을 검증하는 방식으로도 활용할 수 있다.
이 방식들은 모두 LLM의 hallucination과 bias를 줄이는데 도움을 줄 수 있으며, long-tail과 multi-hop 질문의 답변 가능성을 확장한다.
이때 여전히 텍스트 기반으로 KG에서 적합한 정보를 추출하는 방법의 연구 필요성이 존재한다.
(2) SE for LLM
RAG 방식으로 현재 많은 LLM이 검색엔진을 붙여서 검색 결과를 답변 생성에 활용하는 방식을 채택하고 있다.
✅ Augmenting SE
LLM for SE
SE에 LLM을 활용하면, 사용자의 input값을 정제해서 더 적합한 결과가 쿼리되도록 할 수 있다. 검색된 결과를 다시 사용자에게 보여줄 때에도 해당 내용들을 종합해서 요약한 값을 제공함으로써 사용자에게 보다 친숙한(human-friendly)형태로 리턴하는 등으로 활용할 수 있다. 그러나 이 방식은 computational resources를 고려해야 한다.
KG for SE
Google과 같은 대부분의 주요 검색 엔진들은 이미 백엔드 부분에서 KG를 활용하고 있으며, Google의 knowledge panels(cards)가 그 예시이다. KG를 검색엔진에서 사용할 경우, multi-hop과 같이 더욱 복잡한 쿼리를 다룰 수 있으며 모호함을 줄일 수 있다는 장점이 있다.
✅ Augmenting KG
LLM for KG
LLM을 Knowledge Base로 활용한다는 생각은 다소 어려움이 있음을 설명하는데, LLM을 기반으로 생성한 지식은 Wikidata와 같은 KG보다 사이즈가 세 배 이상 작으며, 출력의 정확성 역시 상당히 낮기 때문이다. 또한 KG가 생성하는 불확실한 정보들은 오히려 KG의 정확성을 떨어트릴 수 있다는 위험성이 존재한다. 따라서 저자는 LLM을 활용하여 KG를 생성(re-create)하기 보다는 누락된 객체나 사실과 같은 'gaps'을 찾아서 KG를 통해 전략적으로 메우는 방법을 주장한다. 특히 LLM은 long tail(드물에 언급되는) 객체에 대해서 성능이 급격히 저하되기 때문에 이러한 경우도 똑같이 정보를 저장하고 접근할 수 있는 KG가 보완적 역할을 할 수 있다.
다만, KG는 뉘앙스를 파악하는데 어려움이 있는데 이 부분을 LLM으로 보완하여 KG의 범위와 표현력을 넓혀 답변할 수 있는 범위를 확장할 수 있다.
KG의 정확성을 유지하되, 뉘앙스를 파악하는데 LLM을 보완적으로 활용할 수 있음. (이때의 뉘앙스란 단순한 주어-술어-목적어 구조만으로는 완전히 표현하기 어려운 지식의 미묘한 측면이나 맥락적 특성을 의미함)
SE for KG
SE는 KG의 업데이트, 검증, 출처표기 등에 활용될 수 있다. 예를 들어, '현재 대통령은?'과 같은 질문에 대해 KG로 검색된 결과를 다시 검색 엔진의 최신 뉴스와 소셜미디어의 결과와 비교해서 검증 후 수정한 값을 도출해낼 수 있다. 또한 KG의 statements를 뒷받침하는 증거나 모순되는 내용을 찾아서 검증을 시킬 수 있으며, 단순히 KG에 없는 내용이라 나오지 않는 건지 실제로 틀린 내용인지를 SE를 통해 검토할 수 있다. 이를 통해 KG의 정확성을 높일 수 있으나, 한 가지 주의해야 할 점은 웹 상의 노이즈가 많은 데이터에서 정확한 정보를 추출하는 기술이 필요하다는 것이다(발전해야 한다).
✅ 세 기법을 종합해서 활용한다면?
Augmentation -> Ensemble -> Federation -> Amalganation
Augmentation(증강)은 주요 기술로 다른 두 기술을 보완하는 단계로, LLM이 SE가 검색한 소스에서 지식을 추출해 KG를 확장, 개선하거나 나아가 이를 LLM의 응답에 참조할 수 있는 RAG 시스템에 활용하는 것을 의미한다. 이는 지식 획득과 생성이라는 더 넓은 주제로 통합될 수 있다.
Ensemble(조화)은 사용자의 쿼리에 대해 KG, LLM, SE를 동등한 위치에 두고 가장 적합한 기술을 선택하는 방법이다. 사용자의 자연어 쿼리를 처리하는 부분은 LLM이 담당하고, 그 아래에서는 KG, LLM 또는 SE를 적절한 상황에 따라 호출하여 사용할 수 있다. 예를 들어, 다중 홉 쿼리는 KG에, 상식 쿼리는 LLM에, 뉴스 이벤트 쿼리는 SE가 수행하는 방식이다. 이 방식은 자동화될 수 있으며, 저비용 방식이라고 설명한다.
여기서 세 기법 중에서 어떤 방식이 적합한지를 판단하는 과정이 Rule-base의 Router일지, LLM일지?
Federation(연합)은 앙상블 방법과 같이 사용자의 쿼리에 가장 적합한 기법에 라우팅되지만, 필요에 따라서 다른 컴포넌트에 하위 작업이 전달될 수 있다. 예를 들어, 라우터를 통해 적합한 기법이 선택되고 수행한 뒤, 추가적인 작업은 다시 새로운 API들(캘린더, 계산기 등)을 호출해서 활용하는 방법이다. 이 방법은 최근 Agent가 Tool을 선택하는 방식과도 유사하다고 생각했다. KG와 SE도 이러한 하위 작업에서 호출될 수 있는 도구의 일부가 될 수 있다.
위에서 있었던 질문을 이 논문에서도 언급하는데, 언제 어떤 API 호출을 해야 하는지, 호출의 입력 매개변수를 어떻게 추론하는지, 출력 매개변수를 어떻게 처리하여 호출 기술에 적합한 형식으로 변환하는지에 대한 이슈가 있다고 한다. 이 과정에서 실행 계획을 최적화하거나 연산 비용 혹은 병렬 처리를 고려할 수 있다. Wikifunctions과 같은 함수 라이브러리는 질문에 대한 답변을 계산하거나, 복잡한 답변을 조립하는 데 사용될 수 있는 답변의 일부를 계산하는 데 사용될 수 있다고 한다.
Amalgamation(융합)은 세 기술을 근본적인 수준에서 결합하는 단계이다. 이 단계의 핵심 특징은 다음과 같은 예시로 설명할 수 있다. (1) 자연어와 사실적으로 구조화된 지식의 통합된 신경망 표현을 만들기 (2) 검색을 위해서 역색인을 하기 (3) 지식을 위한 데이터베이스 색인과 의미론 (4) 복잡한 사실적 요청을 위한 구조화된 쿼리 언어로 보완. 이 모든 요소가 상호보완적으로 작용할 수 있다는 것이다.
핵심은, 일관되고 모호하지 않은(명확한) 토큰을 사용하는 것이다. 이는 같은 개념이 다른 시스템에서도 동일하게 표현되게 하는 것을 의미한다. 예를 들어,
LLM이 '튜링 상'이라는 텍스트를 생성하고, KG가 특정 지역에서 태어난 튜링상 수상자를 쿼리하고, SE가 그 수상자를 언급하는 소스를 검색하는 과정에서 각 엔티티의 Concept는 일관되어야 한다. 이러한 토큰은 데이터 타입과 연결하거나 구조화된 의미론적 설명을 포함하고 토큰 간의 상호 관계 정보를 통합하는 방법 등으로 더욱 강화(enriched)될 수 있다. 또 다른 아이디어로는 '이중 신경 지식'(Dual Neural Knowledge) 이 있는데, 자주 언급되거나 유명한, 즉 인기 있는 엔티티(popular entities)는 LLM과 KG의 조합으로 인코딩하고 비교적 덜 언급되는 롱테일 정보(long-tail information)는 KG와 SE의 조합으로 처리하는 방식이다. 이러한 접근 방식은 각 유형의 정보에 가장 적합한 기술 조합을 적용하여 전체 시스템의 효율성과 정확성을 극대화할 수 있다.
이 네 방법들의 궁극적인 목표는 개별 기술들의 장점은 최대한 살리면서 단점을 최소화하는 것이다. 이를 통해 앞서 사용자의 다양한 요구들에 대해 더 나은 성능을 제공하는 통합 시스템을 만들 수 있다.
이제 이론적으로는 세 기법의 상호보완적인 관계를 잘 알겠다. 이제 나아가야 할 방향은 실제로 구현 단계에서 발생하는 bottle-neck들을 어떻게 효과적으로 해결할 수 있는지에 대한 내용인 것 같다.
