[논문리뷰] Knowledge Graphs, Large Language Models, and Hallucinations: An NLP Perspective
Paper Review

한 줄 요약
: LLM의 본질적 한계인 Hallucination을 보완할 수 있는 방법으로 KG를 어떻게 적용할 수 있을 것인지에 대한 open challenges를 논의함
읽으면서 계속 느끼지만, 이 논문은 그래서 어떻게 해야 한다! 혹은 이렇게 해봤더니 됐다! 를 말하는 논문은 아니다. 여러 문제들을 제기하고 그래서 어떻게 하면 좋을까? KG를 적용하면 되지 않을까? 뭐 이런 흐름으로 진행돼서 명확한 솔루션을 제시하지는 않는다는 점을 유의하길 바란다.
1. Introduction
LLM은 QA, 요약 등의 자연어 태스크에 강점을 보여 다양한 분야에 적용가능하지만, 근본적으로 factual inconsistencies, 즉 Hallucination 문제를 가지고 있다. 최근 연구에서는 entity와 relation으로 구성된 구조적인 그래프 형식인 Knowledge Graphs가 LLM 답변의 사실성을 부여할 수 있다는 것을 제시하고 있으며, KG는 추론 과정과 post-generation 부분에서 적용될 수 있다(-> KG-based hallucination mitfation models)
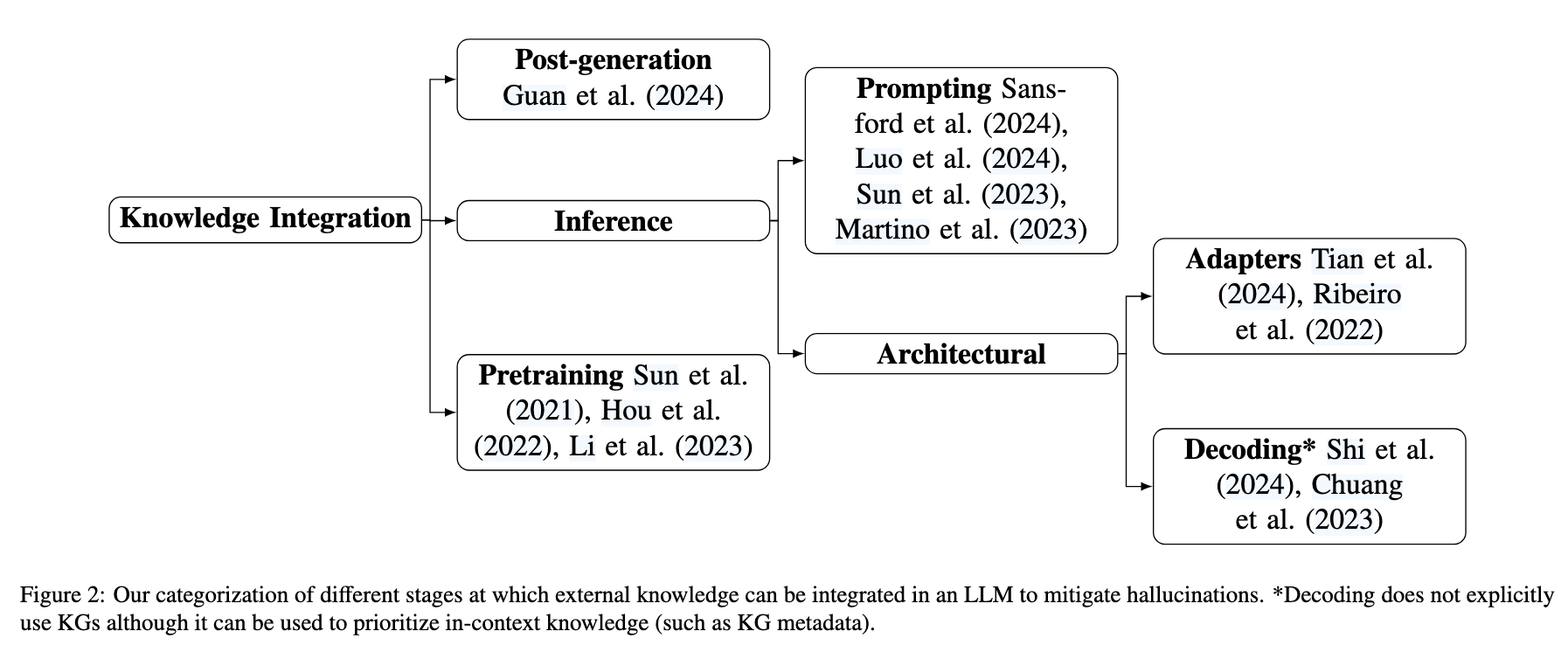
위 그림은 KGs를 LLM의 어떤 단계에서 적용할 수 있는 지를 카테고리로 분류해서 설명한다.
논문에서 제안하는 세 가지 연구 방향은 다음과 같다.
- 환각 현상이 일어나는 특정 부분에 대한 세밀한 탐지
LLM의 답변에서 환각이 일어날 수 있는 부분은 subtle하기 때문에, 전체적인 답변의 정확도도 중요하지만, 부분부분 오류가 존재하는지 세밀한 위치와 범위를 식별할 필요가 있음 - 텍스트 프롬프트에서 벗어나 LLM에 지식을 통합하는 효과적인 방법 탐구
LLM에 외부 지식을 부여할 때, 텍스트 프롬프트 외에 다른 방식을 활용할 수 있는 방법 (?) - 모델 성능에 대한 심층적 분석을 위한 다중 프롬프트, 다국어, 다중 작업 공간에서의 사실성 평가
1번과 연결되는 내용으로, 모델 성능을 보다 심층적으로 평가하기 위해서는 다중 프롬프트나 multilingual, multitask 테스트가 필요함을 의미함
2. Available Resources for Evaluating Hallucinations
LLM의 hallucination을 평가할 수 있는 벤치마크 데이터셋은 중요하며, 실용적인 활용을 위해 다양한 도메인과 태스크를 포괄하는 종합적인 평가가 필요하다.
Table1에는 법률, 정치, 의학 등 도메인의 벤치마크 데이터셋이 있는데, 주로 문장, 응답, 범위 수준에서 환각 여부를 판단할 수 있는 test-size의 데이터이다(knowledge subgraph를 활용하는 모델을 평가하거나 학습하는데 필요한 형식의 train-data의 부재 언급). 또한 대부분 영어로 제공되어 다국어 평가가 부족하고, 비정형 텍스트를 이용한 RAG기반 모델 평가에 초점을 맞추고 있으며, Multiprompt 평가의 필요성에 대해서도 설명한다.
즉, KG를 활용하여 환각 현상을 탐지하거나 완화하기 이전에, 고품질의 평가 방법이 다소 부족한 상황을 설명하는 것이다.
3. Feasibility of Hallucination Mitigation
이전 연구들은 수식적으로 LLM이 hallucination에서 자유로울 수 없다는 것을 설명한다(Transformer 기반 모델의 한계). 이런한 배경에서 외부 지식에 접근하는 방법, 즉 RAG와 같은 방법이 제안된 것이다.
외부 지식에 접근하는 것은 확장성은 불분명하지만, hallucination을 줄일 수 있는 효과적인 방법일 수 있다고 설명한다. LLM의 신뢰성을 향상시키기 위한 두 가지 요구 사항은 다음과 같다.
- 출력값을 해석 가능하게 하여 최종 유저가 환각의 가능성을 명확히 판단할 수 있도록 함 -> 어떤 과정을 거쳐서, 어떤 근거에 기반하여 답변이 도출되었는지를 사용자에게 설명하는 것을 의미함
- 신뢰할 수 있는 외부 지식 소스를 기반으로 하는 것
이때 2번의 신뢰할 수 있는 외부 지식 소스는 KG가 될 수 있다. LLM이 KG의 트리플을 효과적으로 사용하면, 출력값을 보고 다시 그래프로 돌아와서 출처를 확인할 수 있기 때문이다.
4. Detection of Hallucination
LLM의 답변에서 Hallucination을 찾는 것은 여러 측면을 고려해야 하기 때문에 쉽지 않다. 이와 관련된 선행 연구들을 하나씩 설명하는데, 특징별로 요약하면 다음과 같다.
- LLM의 출력에서 atomic claims(더이상 분해할 수 없는 가장 작은 단위)혹은 NE(Named Entities)를 추출하고, gt(ground-truth) 혹은 질의, 외부 참조 데이터들에서도 똑같이 추출해서 각각을 triple 형식의 sub-graph를 만든 뒤 alignment 정도를 비교함
- LLM의 출력에서 triple을 추출하고(위와 같음) 이를 기반으로 다시 LLM 질문을 생성하여 KG 혹은 웹 서치 엔진에서 검색하여 나온 결과를 비교함
그러나 이러한 방식들을 적용했을 때 문제가 완전히 해결되지 않았고, 아직 성공 사례도 많이 없는 것 같다. 논문에서는 프롬프팅에 전적으로 의존하는 환각 탐지 기법은 확장성과 robutness에 문제가 있을 수 있다고 설명한다. 실제로 프롬프팅 기반으로 평가를 진행해보면, 일관성이 없으며 평가의 기준의 모호하다고 생각될 때가 있다.
따라서 제안하는 연구 방향은 LLM 프롬프팅에 대한 의존도를 추고, KG 기반의 환각 탐지 방법을 연구하는 것을 제안한다.
5. Methods for Integrating Knowledge from KGs in LLMs
앞서 Figure2에서 어느 단계에서 KG를 적용할 수 있을 지에 대해서 각 카테고리 별로 자세히 설명하고 있다.
Knowledge in Pretraining
KG를 모델의 사전학습 단계에서 학습에 사용되는 raw-text에 그래프의 triple을 융합하는 방법에 대한 연구가 진행되고 있다. 트리플의 일부를 마스킹하고 이를 예측하는 MLM 방식에서 사용하거나, LLM 아키텍쳐에 adapter로 add-ons 하는 방식들이 제안되었다.
Knowledge During Inference
추론 단계에서 KG를 활용하는 방법은 RAG 방식으로 볼 수 있다. 다만, 이 방식에는 context length가 제한적이고 기존의 모델이 가지고 있는 내부 지식과 충돌될 가능성이 있다는 등의 한계점이 있다. 따라서 context-aware decoding(프롬프트 내 지식의 우선순위를 학습한 매개변수를 사용하는 것?)이나 KG-Based-S-Expression Generation(사용자 질의에서 추출된 엔티티로 S-표현식을 생성함), 그리고 Adapter Networks(잠재된(latent)공간에 KG의 정보를 동적으로 주입함?) 등의 방식들이 제안되고 있다. 이때의 전제는 KG가 안정적이고 완전하게 구축되었다는 것을 두고 있다.
Post-Generation
Post-Generation은 일단 LLM이 답변을 출력한 뒤에 KG를 기반으로 답변을 수정하는 방식이다. 이는 평가의 방법과 유사하게 진행될 수 있을것 같은데, 답변의 정확성(hallucination 정도 등)을 판단하고, 비교하여 수정하면 된다. Google의 Data Gemma의 RIG 방식을 예로 들 수 있을 것 같다.
Multilinguality
LLM이 개발된 초기에 비해서 최근에는 비교적 다양한 언어들이 지원되고 있지만, 여전히 언어에 따른 성능 불균형이 존재한다. 따라서 다국어 KGs를 통해 이를 뒷받침 할 수 있는 방법도 제시되는데, 어뎁터 세트를 통해서 다국어 KG에 대한 지식을 정적으로 인코딩하여 개선하는 방식이 있다. 이는 여러 언어로 표현된 동일한 엔티티 혹은 개념들을 align하여 서로 연결하는 방식으로 LLM의 구조를 크게 변경하지 않으면서 외부 지식을 활용할 수 있는 방법이다.
Limitations
pre-training 단계에서 KG를 사용하는 방법은 지식이 정적으로 인코딩 되어서 빠른 지식 업데이트를 하지 못한다(이건 학습방식의 공통적인 한계임)는 한계가 있고, 프롬프팅에 의존도가 높은 부분은 오류 발생 가능성이 더욱 증가할 수 있다.
6. On Hallucination Evaluation
LLM의 사실성 평가는 작업 방식에 따라 매우 복잡하며, 단순 선택형 질문 답변 방식은 모델의 내부 지식 수준을 정확히 평가하기 어렵다. 따라서 각 부분을 분해하여 더 세밀하게 비교할 필요가 있으며 다국어 지원과 인간의 평가가 필요하다. 이때 프롬프팅의 의존도는 낮추고 KG의 활용을 강화한 방법의 연구가 필요하다.
7. Conclusions and Future Work
결론적으로, LLM의 hallucination 완화는 중요한 문제이고, 이때 KG가 활용될 수 있으며 다양한 분야의 협력을 통해서 효과적인 방안을 찾는 연구가 필요하다~
