
한 줄 요약:
AI 데이터 거버넌스에 지식그래프를 활용하는 KG.GOV 프레임워크를 제안한 논문
번역, 요약 과정에서 Gemini를 활용했습니다.
Introduction
GenAI 시장이 커짐과 동시에, 데이터에 대한 챌린지는 여전히 존재한다. 모델을 학습하는데 사용되는 데이터가 어떻게 수집되었는지(정확도, 안전성, 윤리적 문제 등이 없는지), 어떻게 사용되었는지 등에 대한 거버넌스 모델을 수립하는 것은 믿을만한 AI 시스템을 구축하는데 중요한 요소가 된다.
온톨로지와 KG(Knowledge Graph)는 일반적으로 데이터 관리(표현, 조직, 공유, 재사용 등)과 상호운용에 효과적인 도구로 알려져있다. 예를 들어, DCAT 같은 표준 어휘의 경우 데이터세트의 메타데이터를 표준 형식에 맞게 관리하여 상호운용이 가능하도록 한다. 이처럼 KG는 도메인의 지식 모델링에 도움이 될 뿐만 아니라, 다양한 동적인 메타데이터(lineage, security, ethical management 등)를 표현하여 AI 거버넌스를 잠재적으로 운영, 자동화할 수 있는 도구가 될 수 있다.
The KG.GOV framework
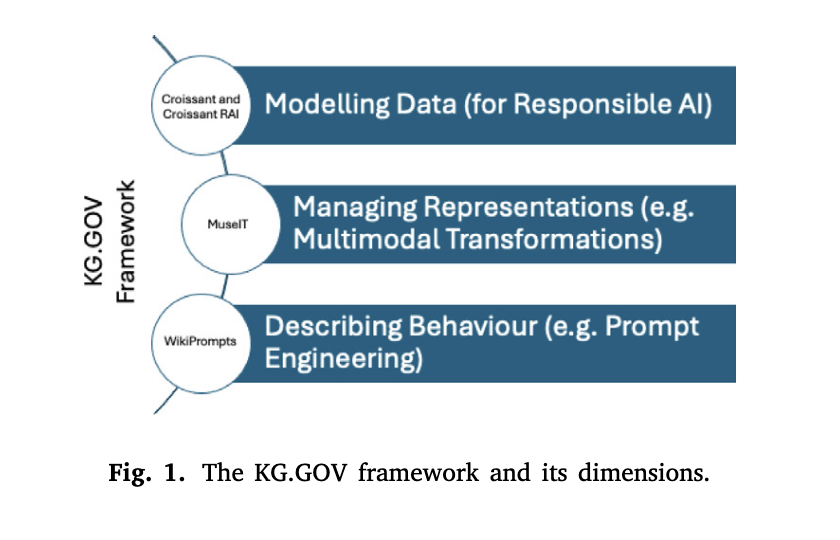
논문에서는 KG.GOV 프레임워크를 세가지 단계(측면)으로 설명하고 있다.
1. Modeling Data
기계와 인간이 상호작용할 수 있는 형식으로 데이터를 모델링하는 것은 효과적인 데이터 거버넌스에 필수적이다. KG는 동적이고 복잡한 컨텍스트를 쉽게 표현할 수 있도록 하여 데이터의 상호 운용성을 지원할 수 있는데, 이를 효과적으로 수행하기 위해서는 다음과 같은 사항을 고려해야한다.
- lifecycle을 통해 각 단계(tranining, refinement, deployment, maintenance 등)에서 AI의 의사결정을 개선해야하는 데이터 유형에 대한 확실한 지식이 필요함
- 시스템의 법적 감사와 같은 목적으로 기록해야 하는 데이터가 무엇인지
- 데이터 엑세스 권한과 지적 재산을 보호하는 특별 라이선스가 무엇인지
2. Managing Representations
AI 시스템과 관련된 메타데이터를 관리하는 것 외에도, AI governing의 기본 부분은 실제 AI 데이터 객체와 지식을 인식하는 것과 관리해야 하는 지식의 가능한 표현성이다. 전통적인 지식 기반의 표현은 'Symbols', 즉 기호 기반이었지만 기계학습의 출현으로 벡터 뿐만 아니라 텍스트와 이미지 기반으로도 확장되었다. 실제로 GenAI는 이미지, 사운드, 3D 등과 같은 다중 모드 데이터 처리와 이해에 점점 더 능숙해지고 있다.
3. Describing Behaviour
Agentic AI는 복잡하고 다양한 상황에서 AI가 능동적으로 결정하고 목표를 달성하는 것을 의미한다. 단순히 인간-AI의 대화하는 것을 넘어서, 스스로 프롬프트를 생성하고 각 AI 에이전트들이 상호작용을 하면서 프롬프트 엔지니어링을 하는 등 복잡한 상호작용의 워크 플로우로 이해할 수 있다.
Applications
Modeling data: Croissant
AI Act나 GDPR과 같은 기존의 AI 규제 프레임워크들은 책임있는 AI에 대하여 강조하고 있으며, 데이터 중심의 접근 방식의 필요성에 대해 초점을 맞추고 있음. 예를 들어, ML에서 data nutrition labels(데이터의 출처, 수집 방법, 목적 등을 포함하는 정보)과 같은 도구를 사용하여 데이터의수명주기의 다양한 측면에 대한 구조화된 요약은 AI 데이터에 대한 투명성을 높일 수 있는 한가지 방법이다.
ML Commons 커뮤니티는 산업계와 학계 전문가들이 협력하여 AI 데이터셋의 lineage(계보?)와 출처를 표준화하고 문서화하기 위한 표준을 개발하고 있다. 이때의 표준은 어떤 유형의 데이터를 모델링해야 하는지, 어떤 세부수준까지 모델링을 할 것인지, 어떻게 AI 시스템 내에서 책임있는 사용과 재사용을 효과적으로 홍보할 것인지 등은 여전히 중요한 과제이다.
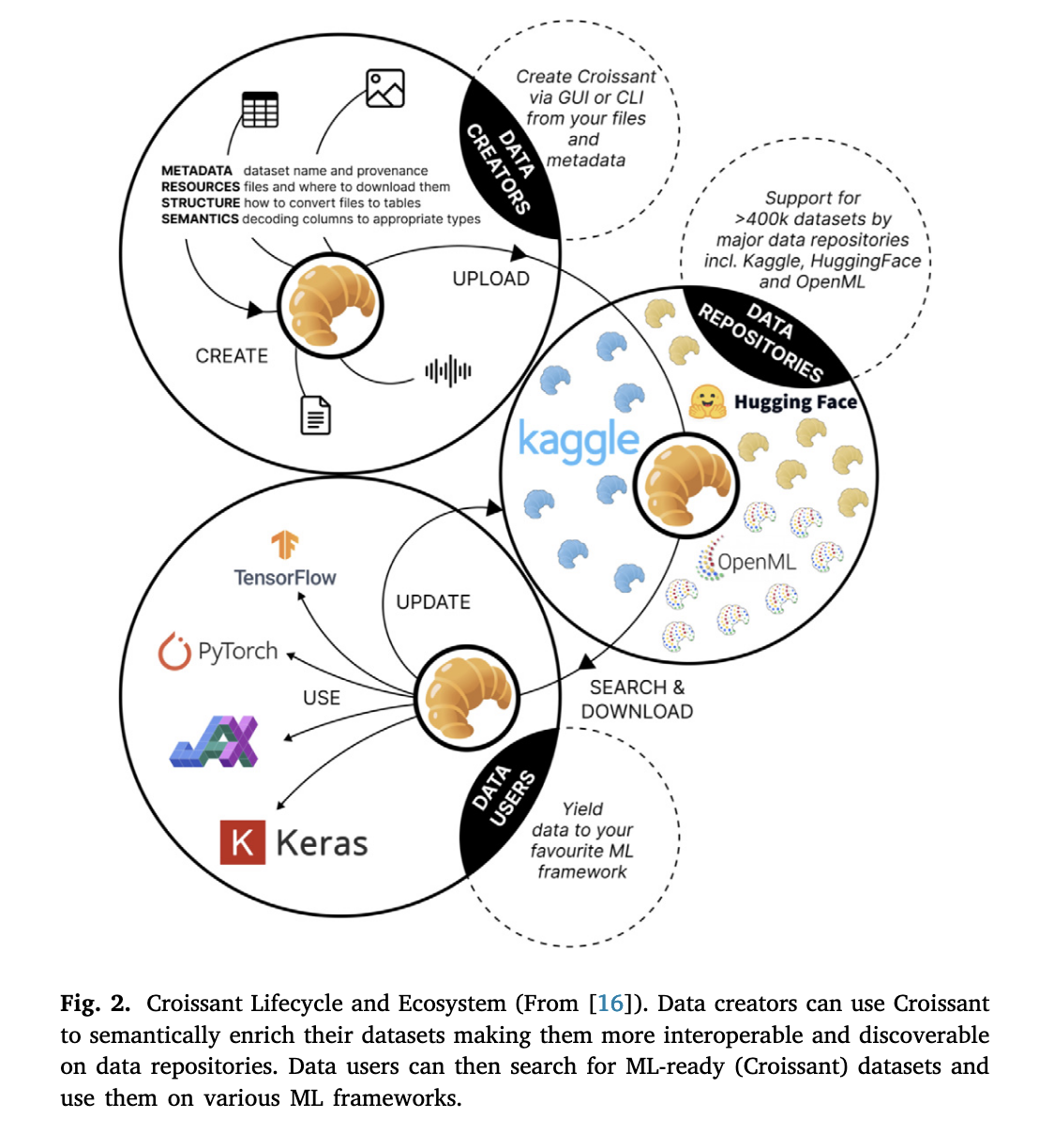
ML Commons의 working-group인 Croissant는 Schema.org 데이터셋 어휘를 이반으로 하는 Croissant라는 통합 메타데이터 형식을 개발하고 있다. Croissant은 ML 데이터셋의 검색 가능성, 이동성, 재현성, 그리고 상호운용성을 가능하게 하는 것을 목표로 하며 다음 네 가지 계층으로 구성되어 있다.
Croissant는 기계가 읽을 수 있는 데이터셋의 표준 메타데이터를 의미하며, 이를 통해 데이터의 검색 가능성, 상호운용성, 재현성, 투명성을 높일 수 있음
- Dataset Metadata Layer
데이터셋의 제목, 설명, 라이선스와 같은 일반적인 메타데이터를 설명함 - Resources Layer
데이터셋을 구성하는 파일이나 포맷 등과 같은 내용적인 메타데이터를 설명함 - Structure Layer
데이터셋의 다양한 출처의 설명과 구성을 지원함 - Semantic Layer
다양한 도메인 별 어플리케이션에서 데이터셋의 맥락적 무결성의 보존을 지원함
이때 포함되는 layer에 기존에 중점이 되던 메타데이터 뿐만 아니라 resources와 semantic layer가 포함된다는 점이 인상적이다. Croissant은 Hugginface나 GitHub, Kaggle과 같은 데이터 레포지토리에서 통합되어 사용될 수 있으며 현재 40만개 이상의 데이터셋이 Croissant 형식으로 검색할 수 있다고 한다.
실제로 huggingface의 Croissant-editor에서 데이터를 넣고 메타데이터나 관련 데이터, record sets 등을 확인할 수 있고, 이에 맞게 변환한 json-ld 파일을 다운받을 수 있다.
샘플로 있는 Titanic 데이터의 경우 메타데이터가 28개로 풍부하게 표기되어 있음을 확인할 수 있었다.
Croissant RAI(Responsible AI)는 책임있는 AI 원칙을 데이터셋 문서화에 적용하여 상세한 메타데이터 구축과 이를 통해 AI 시스템의 투명성, 책임성, 안전성을 높이는 것을 목표로 한다. 실제로 지리공간 분야나 의료 도메인에서는 Data Use Vocabulary (DUO), Data Privacy Vocabulary (DPV), Data Catalogue Vocabulary (DCAT), AIRO (AI 위험 표현), Open Digital Rights Language (ODRL)과 같은 널리 사용되는 관련 어휘와의 재사용, 통합 및 정렬이 연구되고 있다. 이처럼 다양한 어휘화의 통합은 Croissant의 상호 운용성을 높이고, 특정 도메인의 요구 사항을 충족하는데 도움을 준다.
Croissant과 같이 표준 모델링과 문서화는 데이터의 투명성과 상호운용성, 재사용성을 높일 뿐만 아니라 데이터를 처리하는 다양한 주체의 책임성을 확립하는데 도움을 준다(데이터 및 소프트웨어의 생산자, 관리자 등 개인과 단체의 책임을 의미함). 이는 데이터 거버넌스 구현과 AI 시스템 구축 방법과 관련하여 법적 준수를 확인하는데에도 도움을 준다.
한편, Croissant RAI는 기술적, 법적, 사회적 측면 등 다양한 특면을 다루기 때문에 어떤 구체적인 데이터를 어떤 수준에서 모델링해야 하는지에 대한 과제가 있다. KG의 상호운용성은 다양한 도메인에서 여러 기존 어휘들이 경쟁하고 있기 때문에 상호 운용성은 본질적인 제한 사항이다. 또한 KG는 일반적으로 symbolic/text 기준을 다루며, 트리플 스토어 및 쿼리 엔진에서 멀티모달을 다루는 것이 부족하다는 한계가 있다. 새로운 표준은 이러한 문제를 해결하는데 도움이 될 수 있다(?)
?? 어떤 도움이 되는걸까? 아래 내용을 더 읽어 보자...
Alternative representations: Multimodal transformations
text-only 모델 뿐만 아니라, 현재의 GenAI는 이미지, 비디오, 오디오 뿐만 아니라 depth, IMU sensor(모션 센서) 등 다양한 형식의 Input과 Output을 다룰 수 있으며, 이는 multi-sensor 환경의 실제 세상을 다룰 수 있도록 한다 (논문 작성 당시 기준으로 GPT-4 Vision, Gemini, ImageBind 등을 예시로 설명함). 이 기술은 Transformer와 Diffusion 기술을 기반으로 하는데, Transformer는 처음에는 NLP를 위해 디자인되었지만 현재는 멀티 모달 환경에서도 적용되고, Diffusion은 점차적으로 노이즈를 일관된 데이터로 변환하는 모델로 text2image를 가능하게 한다. 이 두 모델은 함께 다양한 양식에 걸쳐 이해하고 생성하는 AI의 능력의 획기적 도약에 큰 영향을 미쳤다.
Multi-modal AI는 단순히 기술적 도구를 넘어 사회적 불평등을 해소하고 모든 사람이 지식에 접근할 수 있도록 한다는 점에서 중요한 역할을 갖는다.
또한 Multi-modal KG의 구축, 활용, 확장에 중요한 역할을 할 수도 있다고 설명하며, 추론, 분류, 생성, 검색 등과 같은 downstream task의 성능을 높이는데 사용할 수 있다고 설명하며 MuseIT 프로젝트와 CUBE-MT 벤치마크의 예시를 제시한다. MuseIT 프로젝트는 생성형 AI를 활용하여 사용자의 감각 능력에 따라 다양한 사용자 요구를 충족하는 데이터 표현을 자동을 제공하는 방법을 연구한다. 이를 위해 Text-to-Image 모델에 대한 벤치마크인 CUBE-MT를 제안하는데, CUBE는 텍스트-이미지 모델의 문화적 인식(8개국)을 평가하는 벤치마크이며 CUBE-MT는 텍스트, 점자, 음성, 음악, 비디오 및 3D의 6가지 추가 양식을 확장한 벤치마크 데이터셋이다. 해당 데이터셋은 Wikidata KG에서 추출한 속성을 기반으로 생성되므로 데이터의 신뢰성과 객관성을 확보할 수 있다고 한다.
KG 기반으로 구성된 Wikidata의 속성을 기반으로 멀티모달 모델을 평가/학습할 수 있는 벤치마크 데이터셋을 생성한다... 개념적으로 이해했지만, 정확히 어떻게 구현되는 건지는 잘 이해가 가지 않았다. Gemini에게 물어보니 다음과 같은 답변을 했다:
Wikidata는 다양한 객체와 그 속성에 대한 구조화된 정보를 제공하는 지식 그래프입니다. 예를 들어, "고진야마 요새"라는 객체에는 "위치", "건축 시기", "역사적 중요성" 등의 속성이 연결되어 있습니다.이러한 속성은 객체에 대한 정보를 체계적으로 정리하고, 다양한 데이터 간의 관계를 명확하게 정의하는 데 도움을 줍니다.
CUBE-MT 벤치마크에서는 Wikidata의 이러한 속성 정보를 활용하여 멀티모달 생성 모델을 위한 프롬프트를 생성합니다.
즉, "고진야마 요새"의 "위치" 속성을 사용하여 "일본의 고진야마 요새의 전경"이라는 이미지 생성 프롬프트를 만들거나, "역사적 중요성" 속성을 사용하여 "고진야마 요새에 대한 역사적 설명을 담은 텍스트"를 생성하는 식입니다.즉, Text-to-Image 혹은 Text-to-Voice 등의 벤치마크 데이터셋을 만들때, 해당 객체의 속성들을 기반으로 조합하여 여러 유형의 프롬프트를 생성했다는 의미이며, 이때 Wikidata는 여러 문화의 아티팩트를 포함하므로 해당 특성을 담은 프롬프트를 생성할 수 있어서 모델이 문화적 맥락을 잘 학습할 수 있게 되었다는 의미로 이해할 수 있다.
Describing behaviour: WikiPrompts
Agent AI의 등장으로 인해 AI 시스템의 작동 방식을 문서화하고 모델링하는데 새로운 접근 방식이 필요하게 되었다. 이때의 agenticness란 'direct supervision(?)이 제한되는 복잡한 환경에서 복잡한 목표(goal)를 달성하는 것'을 의미하는데, 이는 AI 시스템이 단순히 도구를 넘어 행위자로 작동할 수 있음을 의미한다. 복잡한 상황은 멀티모달 환경에서 다국어를 처리하며, 사용자의 다양한 요구사항이 존재할 때를 의미하며, 이를 해결하기 위해서는 인간과 AI의 소통 뿐만 아니라 AI간의 자율적인 상호작용도 포함된다. 이런 복잡한 상호작용을 관리하고 이해하기 위해서는 orchestration과 모델링이 필요한데, 이는 AI 시스템 간의 상호작용을 명확하게 정의하고 관리하는 것으로 Semantic Web Services와 유사하다.
따라서 주요 질문은 다음과 같다.
- AI는 어떤 복잡한 워크 플로우를 생성하고 어떻게 문서화할 수 있는가?
- 입력과 출력을 특정 프로세스 및 모델에 어떻게 맵핑할 수 있는가?
이때의 '문서화'의 의미가 무엇인지 생각해보았는데, 오케스트레이션 해서 최종 목표에 달성하는 그 모든 과정을 재현가능하도록 기록하고, 작동 과정에서 오류 발생 시 원인을 분석하여 유지, 관리할 수 있도록 하는 것을 의미한다고 이해했다.
이러한 상호작용을 위해서 AI모델은 자연어로 구조화되어 AI가 해석할 수 있는 prompts를 사용하며, 이 최적인 output을 얻기 위한 prompt engineering과 같은 튜닝은 중요한 요소로 작용된다. 이에 따라 프롬프트도 GitHub나 Huggingface 등에서 공유되곤 하는데, 프롬프트를 적절하게 문서화 하며, 업데이트하고, 출처를 명시하며, 확장가능한 방식으로 프롬프트 공유를 하는 방법 등과 같이 다양한 논의 사항이 존재한다.
이러한 질문들을 해결하기 위해 프롬프트와 프롬프트 워크 플로우의 공동 지식그래프인 WikiPrompts 라는 것을 제시한다. WikiPrompt는 Wikidata와 유사하게 구조화된 형태로, FAIR 원칙을 기반으로 프롬프트 재사용을 위해 KG 기반으로 문서화한 사이트이다.
WikiPrompts 사이트를 검색해서 들어가보니, 15$를 내면 평생 사용할 수 있고, 구매한 사람에 한해서 웹사이트 링크를 공유한다고 한다(https://wikiprompts.net/). 이름만 보고 당연히 Wikidata와 같이 Open-Source를 지향할 것이라 생각해서 다소 당황했다. 이와 관련해서 논문에서도 한계점을 언급하긴 한다.
Discussion and vision
Data Modeling은 Croissant 뿐 아니라 WikiPrompts와 Multimodal Transformation에서도 과제로 나타난다. KG.GOV는 high-level(높은 수준의 추상 메타데이터. 데이터세트의 출판, 저자, 버전, 라이선스 등을 설명하는 메타데이터-Croissant)부터 low-level(행동제어와 모니터링, 데이터 생성 방식에 대한 세부적인 출처 명시-WikiPrompts)까지 포괄적으로 지원하며 KG를 사용하여 상호운용성 및 통합과 자동화를 이룰 수 있다.
사회적 측면에서는 KG를 통한 AI 거버넌스에 시민 사회의 참여와 요구사항을 적절하게 수집하는 것이 중요하다(Wikidata나 Wikipedia도 누구나 수정할 수 있는 형태로 공동의 knowledge를 구축하였다). 또한 Multimodal Transformation에서는 AI 생성 콘텐츠 평가에 시민들이 주요 평가자로 참여하고 윤리적, 도덕적 문제를 찾아내는 역할을 해야 한다.
마지막으로, KG 데이터 모델 혹은 KG 기반의 AI 행동 플랫폼 및 생성 콘텐츠가 장기적이고 안정적인 AI 거버넌스에 얼마나 효과적인지 평가하는 것은 매우 어려운 일이라고 설명한다. 예를 들어, 'AI생성 멀티모달 KG 콘텐츠에 대해 윤리 및 편향과 관련된 지표에서 어떤 데이터세트, 프롬프트 및 모델 조합이 낮은 점수를 받는가?'와 같은 질문에 KG를 사용해서 만들었을 때를 기준으로 답할 수 있어야 한다는 것이다(종합적인 평가를 해야 한다는 의미). 또한 최종 답변이 생성되기까지 어떤 워크 플로우와 데이터를 활용했는지 완전한 추적이 가능한 아키텍쳐 역시 요구된다. 이를 위해서는 Croissant에서는 더 많은 메타데이터가 필요하며, 더 많은 프롬프트 예제들이 필요하다.
결론적으로, 논문에서 제시하는 KG.GOV는 KG가 AI 거버넌스의 중추적 역할을 할 수 있다는 것을 제시하며, 새로운 과제와 연구 질문을 제시한다.
- 데이터 및 시스템 측면에서 표현된 메타데이터 어휘에 대한 요구 사항을 계속 높여야 함 (KG의 확장과 결합)
- 거버넌스를 위한 KG의 확장성은 멀티모달 데이터, 풍부한 텍스트와 복잡한 워크 플로우의 표현과 쿼리를 지원하는데 어려움을 겪음
- 커뮤니티 수용과 AI 시스템과의 인터페이스에 대한 인간의 수용이 필요함
- KG 데이터 모델 개발, AI 시스템 및 KG가 AI 시스템에 미치는 영향을 평가하는 것은 AI 거버넌스 및 AI 전반에서 가장 큰 과제임
Croissant 라이선스 메타데이터를 적절히 사용하면 훈련 데이터 출처를 추적하고 모델 속성과 연결하며, 모델 출력을 문서화하고 규정 준수 여부를 평가하는 데 활용할 수 있으며, AI를 활용하여 다양한 표현을 생성하고 변환함으로써 생성된 미디어를 보호하고 관리하는 새로운 태스크를 고려할 수 있다. AI 워크플로우 및 프롬프트의 지식 기반 관리는 지식 관리 프로세스의 자동화를 지원하며, AI 거버넌스의 미래는 KG 데이터 및 워크플로우 기반의 부분적인 자동화로부터 비롯될 것이다.
.
.
.
읽기 쉽진 않은 논문이었다
