
한줄 요약
LLM을 활용하여 Tabular data를 전처리하는 방법 (prompting 기법을 위주로)
1️⃣ Introduction
LLM은 급속도로 발전했고, 학계와 산업 분야 등에서 다양하게 활용되고 있다. data management와 mining 분야에서는 SQL 쿼리 생성이나 데이터베이스 진단(diagnosis), data wrangling과 분석 등에서 활용되고 있다.
본 연구는 데이터 마이닝이나 분석의 가장 기본이 되는 '전처리' 과정에서 LLM을 활용하는 방법에 대해서 다루고 있다. LLM은 데이터 전처리 과정에서 에러를 탐지하거나 빈 셀 채우기(data imputation), 스키마나 엔티티 매칭을 할 수 있다. 이처럼 LLM을 어떤 부분에서 어떻게 활용할 수 있는지 판단하기 위해서는 LLM의 특성과 한계에 대해서 파악하고 있어야 한다. 따라서 논문은 다음과 같은 전개로 진행된다.
- LLM의 내재된 지식과 추론 능력을 zero, few-shot 프롬프팅을 통해 향상하는 방법에 대해서 탐구한다. 연산 비용과 비효율성이라는 한계점을 함께 검토한다.
- LLM 기반의 데이터 전처리 프레임워크를 제안한다. 프레임워크는 프롬프팅과 함께 전통적인 방법인 contextualization과 feature selection을 포함한다.
- 4개의 데이터 전처리 작업에 대한 12개의 데이터세트를 통해 프레임워크를 평가한다. 이때 GPT3.5, 4, 4o 등의 모델을 각각 평가에 활용한다.
2️⃣ Preliminaries
2.1 Data Preprocessing
본 논문에서 다루는 data는 Tabular에 한정하고 다음 테스크들을 고려한다.
- Error Detection; ED
- Data Imputation; DI
- Schema Matching; SM
- Entity Matching; EM
data fusion과 data wrangling은 향후 과제로 두고, input data는 'data instance'라고 표현한다.
2.2 Large Language Models
✅ 장점
- LLM은 언어의 의미와 구조에 대한 포괄적인 이해와 방대한 양의 텍스트 데이터를 통해 학습한 지식을 통해 데이터의 오류와 변칙(anomalies) 등을 파악해낼 수 있다.
별도의 fine-tuning이나 인간의 enfineered rules(?)없이도 전처리가 가능하다는 설명도 있는데, 이 부분은 일부은 100% 동의하기는 어려운 것 같다.
- 대부분의 LLM은 프롬프트 인터페이스를 제공하여 별도의 컴퓨터 프로그래밍이나 도구가 필요 없다.
이 부분을 보고 실험을 할 때 API를 쓰진 않은건가? 싶었지만 일단 넘어갔다
- LLM은 우수한 추론 능력을 기반으로 데이터 전처리의 결과와 함께 그 이유를 제공할 수 있다. 따라서 다른 DL의 접근법보다 더 해석 가능한 방법이다.
이 부분 역시... 애매할 수 있다. 환각에 대한 부분을 고려한다면 LLM은 매우 큰 black-box라고 볼 수 있으므로.
- LLM은 few-shot 프롬프팅으로 조절될 수 있으므로 전처리 작업의 기준을 조정할 수 있다.
✅ 한계점
- LLM을 활용한 데이터 전처리의 가장 큰 한계는 도메인에 특화된 처리가 어렵다는 점이다.
- LLM은 가끔 환각을 일으키는 부정확하거나 무의미한 텍스트를 생성한다.
- 대규모 데이터를 전처리하는데 있어 비용 발생과 효율성, 확장성이 떨어질 수 있다.
3️⃣ Method
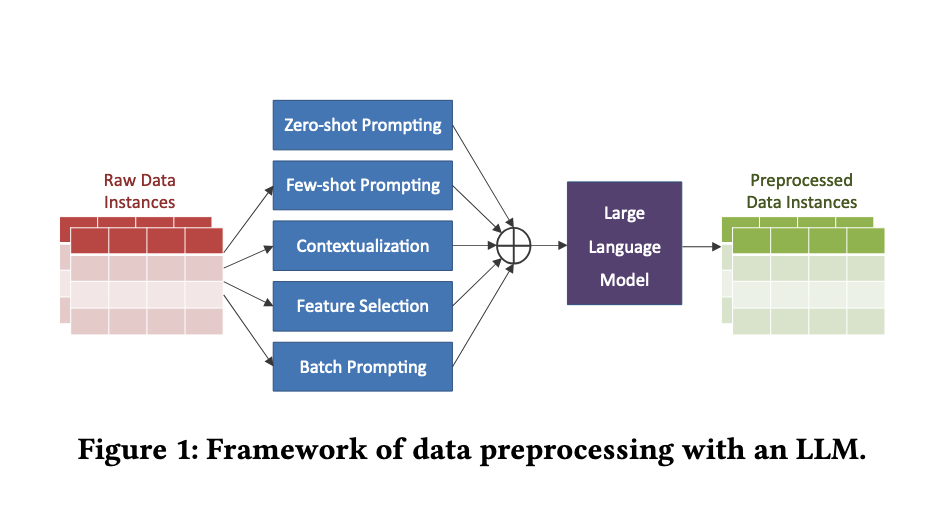
연구에서는 LLM에 대한 입력으로 프롬프트를 구성하는 여러 모듈을 구성한다. LLM의 프롬프트에는 'You are a database engineer'라고 페르소나를 부여하고 시작한다고 한다.
3.1 Zero-shot Prompting

Zero-shot 프롬프팅을 예제는 주지 않고, 원하는 출력을 생성하도록 하는 가이드만을 제시해서 추론 능력을 향상시키는 방식이다. 위 예제는 Error Detection, Data Imputation을 위한 프롬프트이다. ED의 경우 전체 레코드 r을 제공하면서 LLM에서 특정 속성 ri에서 오류를 감지하도록 요청하는데, 이때 LLM이 실수로 다른 속성 rj(j와 i는 같지 않음)에서 오류를 잘못 식별할 수 있다. 따라서 프롬프트에서 'Please confirm the target attribute in your reason for inference.'와 같이 이유를 명시할 것을 제시하고 있다.
이것만으로 충분할지 궁금하다. 이유마저 잘못 생성한다면?
DI의 경우, 입력할 속성의 데이터 유형에 대한 힌트를 제공하는데, 예를 들어, "'hoursperweek' 속성은 정수 범위가 될 수 있다"라는 힌트를 제공하면, LLM은 단일 숫자가 아닌 범위로 응답하게 된다.
이때의 Data Imputation은 데이터에서 누락된 값을 채워넣는 것을 의미하는 것 같다. 다만, 주어진 정보 내에서 null 값을 채울 수 있다면 효과적이지만, 오류를 생산하지 않도록 어떤 제약 조건을 줘야할 것 같다.
3.2 Few-shot Prompting

Few-shot 프롬프팅은 몇 가지 예시들을 넣어주는 방식이다. 예를 들어, [name: "carey’s corner", addr: "1215 powers ferry rd.", phone: "770-933-0909", type: "hamburgers", city: ???] as [Data Instance 1], [Reason 1] 와 같은 예시가 주어졌을 때, 전화번호에서 '770'은 Atlanta나 Georgia의 Marietta의 지역번호이므로 city 열의 빈 행은 'Marietta'가 될 수 있다.
이처럼 데이터를 채워주기 위한 추론 과정에 대한 예시를 프롬프트에 넣어준다는 것이다.
이 예시의 경우 Data Imputation이 효과적일 듯!
3.3 Contextualization
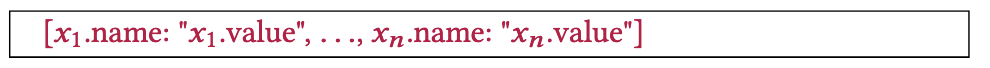
테이블 형식의 데이터는 위와 같이 key-value 형태로 입력된다. xi는 i번째(행)의 데이터 인스턴스를 의미하고 name은 속성값(컬럼), value는 해당 속성의 실제 인스턴스를 의미한다. 또한 null인 경우 ???가 입력되도록 한다.
3.4 Feature Selection
메타데이터를 사용할 수 있는 경우, 성능 향상을 위해 이 정보를 활용할 수 있다. 예를 들어, '식당의 주소'속성 값을 채울때, '전화번호', '거리 이름' 등의 속성은 참조할 수 있는 속성에 해당하지만, '식당의 이름'은 관련이 없다. 따라서 사용자들은 프롬프트에서 이에 대한 정보를 제공하는 방식을 선택할 수 있다.
데이터가 굉장히 많은 경우, 이 작업이 어려워서 이를 자동화하면 좋을텐데...라는 생각이 들면서도 결국 스키마를 만들어주는 작업은 인간이 해야 하는 영역인 것 같다는 생각도 든다.
3.5 Batch Prompting
LLM의 토큰 사용량과 시간을 고려했을 때, 하나씩 처리하는 것보다 batch로 실행하는 것이 효율적이다. 이를 위해 여러 데이터 인스턴스가 단일 프롬프트로 표현되며, LLM에는 모든 데이터에 답변하도록 지시할 수 있다.
실제로 해보면 데이터를 누락하는 경우가 종종 있다. 프롬프트를 더 엄격하게 주거나, 적절한 batch 크기를 찾는게 중요할 것 같다.
논문에서는 배치의 두 가지 모드를 제안하는데, 첫번째는 random batching으로 데이터 인스턴스를 무작위로 할당하는 방법이고, 두번째는 cluster batching으로, 데이터 세트에서 클러스터링을 수행한 뒤 각 클러스터 내에서 임의로 배치가 수행되는 것이다.
정확한 방법은 잘 모르겠다.
4️⃣ Experiments
실험에서는 GPT-3.5-turbo, GPT-4, GPT-4o를 사용했고 temperature는 0.35로 설정했다. Schema Matching 작업에서는 3-shot으로 예제를 넣어줬고, 다른 테스크는 모두 10-shot으로 진행했다. batch size는 각 모델마다 다르게 설정했으며, 네 가지 작업(ED, DI, SM, EM)에서 GPT-3를 사용해서 각 작업에 특화된 베이스라인 모델들을 사용했다고 한다. 본 논문은 오픈소스 모델을 고려하지 않았다고 한다.
실험 결과, GPT-4의 성능이 가장 뛰어났고, HCI(Human-Computer Interaction)에 초점을 맞춘 GPT-4o는 이런 작업에 적합하지 않았다고 언급한다. 또한 테이블 형식 입력 처리를 위해 fine-tuning된 Table-GPT(GPT-3.5 기반)는 GPT-3.5보다 다소 낮은 평가 점수가 보였다. 그러나 논문에서는 모델을 상황에 맞게 fine-tuning하는 것의 중요성을 강조하고 있다.
이 이유로는, fine-tuning이 문제라기 보다는 Table-GPT가 EM이라는 테스트에 최적화된 모델이 아니므로 이 테스크에 최적화된 학습을 하면 성능이 향상될 수 있다는 의미인 것 같다.
비용/시간 대비 효과는 GPT-3.5가 뛰어났다고 한다.
zero-shot과 few-shot의 성능을 비교해보면, 모든 태스크에서 few-shot일 때 성능이 향상되었다고 한다. 또한 batch prompting은 약간의 품질 저하를 일으키지만, 비용과 시간 대비 적용할 만한 방식이라고 한다.
.
.
.
논문의 결론을 종합해보면, 결국 task specific하게 최적의 모델과 batch size, 제공 예제의 개수 등을 찾아야 하는 것 같고, 이 과정에서 fine-tuning을 하면 성능이 좋아질 수도 있다(? 논문에서 실제로 하진 않았으므로..) 정도가 될 것 같다.
한 가지 희망은, 테이블 데이터를 전처리 하는 태스크의 벤치마크 데이터셋이 있다는 점인데, 여전히 multi-lingual 문제를 고려해야 할 것 같긴 하다. 또한 위에서 나온 예시 처럼, 전화번호의 지역번호는 국가별로 상이하므로 이에 대한 정보도 추가로 줘야 원하는 성능을 얻을 수 있을 것이다.
결국 수작업은 피할 수 없는 것...
