
한 줄 요약: 테이블의 메타데이터(컬럼명)을 활용하여 RAG와 LLM을 기반으로 Metadata를 KG의 개념에 맵핑하는 방법
테이블 데이터를 구조화하는 작업에서 컬럼명을 기준으로 맵핑하는 것의 한계가 있어서 인스턴스 단위를 고려해야 하지 않을까...에 대한 생각을 하던 차에 읽은 논문이다. 여전히 효율성 측면에서는 이점이 있을 수 있지만, 정확도 측면과 특히 도메인 특성이 강한 데이터 처리에는 이 방법의 어려움이 있을 것 같다는 생각이 있다. 그럼에도 CoT-SC와 RRF를 기반으로 한 Reranking 기법은 충분히 활용 가능한 방법인 것 같고, 추후 참고 가능하다.
1️⃣ Introduction
서로 다른 출처에서 생상된 두 개 이상의 데이터를 통합하는 것은 어느 분야에서나 쉽지 않은 작업이다. 이를 위한 한 가지 방법은 표준 어휘를 사용하거나 지식그래프를 활용하는 것으로, semantic table linking 혹은 table matching이라고 불린다. SemTab(Semantic Web Challenge on Tabular Data to Knowledge Graph Matching)은 ISWC(International Semantic Web Conference)에서 몇 년 동안 다뤄지고 있는 주제이며 자동 KG 구축을 목표로 한다. 세부 목표는 테이블 데이터에 DBpedia나 Wikidata의 엔티티를 자동으로 할당해 열 사이의 관계를 유추하거나 테이블 데이터 전체를 KG로 변환하는 것이다. 이때의 방법은 테이블 데이터의 메타데이터, 즉 컬럼 정보를 사용하는것이다.
그러나, 컬럼명만으로는 KG의 개념을 부여하기는 어렵다. 예를 들어, 컬럼명이 'ID'혹은 'Value'인 경우, 개념적 범위가 너무 넓어 추가적인 정보가 필요하고, 'Date'인 경우 출생일, 발생일 등 다양한 의미가 될 수 있다. 또한 테이블에 따라 고유한 명명 규칙이나 약어를 사용하여 동일한 개념도 다양한 단어로 표현될 수 있어
따라서 본 논문은 이러한 다양한 케이스들을 LLM을 기반으로 의미적 맵핑을 통해 해결하고자 한다. 또한 비용 효율성을 위해 KG 내에서 가장 관련성이 높은 정보만 검색하도록 RAG을 적용하고, CoT(Chain-of-Thought), SC(Self-COnsistency), RRF(Reciprocal Rank Fusion) 등을 활용한다고 한다.
2️⃣ Related Work
이전에 SemTab 챌린지에서 논의된 시스템(MTab, CSV2KG, DAGOBAH)는 다음 세 가지 테스크를 통해 KG 매칭을 시도했다.
- CEA(Creating cell Entity Annotations)
- CTA(Column Type Annotation)
- CPA(Column Property Annotation)
이 파이프라인은 일반적으로 개별 셀을 온톨로지의 엔티티에 연결한 뒤, 이 연결을 기반으로 가장 가능성 높은 컬럼 유형을 예측하는 과정으로 진행된다.
논문에서는 실제 인스턴스 단위의 데이터를 사용할 수 없는 상황(?)에서 이 방법을 사용할 수 없다고 말하는데, 이건 어떤 상황일지...? 실제 데이터에 어떤 값이 들어있는지 보지 않고 컬럼만 보고 맵핑을 하고 싶다는 걸까? 더 읽어봐야 할듯
전통적으로는 문자열 유사성부터 Wordnet과 같은 리소스를 기반으로 한 의미적 유사도의 방법으로 맵핑을 진행했는데, 이는 일반적/범용적 범위의 내용만 다루고 있어 도메인 특성을 반영한 작업은 어렵다는 한계가 있다. 이후 시멘틱 유사도를 Word2Vec과 같은 벡터를 기반으로 계산하는 기법이 시도되었고, 최근에는 LLM을 기반으로 한 entity matching, subject annotation가 진행되고 있다. 프롬프팅이나 Fine-tuning을 통한 시도가 있었는데, 전체 어휘를 컨텍스트로 제공하는 것은 비효율적일 수 있으며, 고급 프롬프트 최적화 전략은 아직 연구가 미흡한 상황이라고 한다.
3️⃣ Metadata Datasets
본 연구에서 사용하는 데이터는 다음과 같다.
(1) Dataset1
웹 상의 HTML 기반 테이블 중 일부 메타데이터로 구성된다. 이 테이블의 각 컬럼은 DBpedia 온톨로지의 하위 집합에 해당하는 속성에 매핑하는 것이 목표이다. DBPedia 온톨로지는 계층적으로 구조화되어 있지만, 여기서는 단순한 속성의 집합으로 간주되어 각 속성은 라벨과 간단한 설명만으로 정의되며, 속성 간의 관계는 고려되지 않는다. 총 77개의 웹 테이블 메타데이터가 제공되고, 141개의 컬럼을 매핑해야 한다. 사용된 어휘는 총 2881개의 속성으로 구성되어 있다.
(2) Dataset2
공개적으로 접근 가능한 데이터베이스에 존재하는 테이블로 구성된다. 이 테이블의 목표 역시 각 컬럼을 KG의 속성에 맵핑하는것인데, 이때의 속성은 기존의 KG에서 파생되지 않은, 자체 정의된 어휘를 의미한다고 한다. 이 데이터셋에는 75개의 테이블 메타데이터와 총 1181개의 컬럼이 존재하며, 어휘는 총 1181개의 항목으로 구성되어 있다.
정리하면, 두 데이터 모두 인스턴스 값은 없고 컬럼만으로 구조만 있는 데이터이다. 이 테스크의 목적은 '이 컬럼은 어떤 개념을 의미하는 것일까?'를 판단하는 것이고 Dataset1의 경우 DBPedia의 어휘를 사용하고 Dataset2는 이 연구에서 자체적으로 생산한 맞춤 어휘를 사용한다.
4️⃣ Methodology
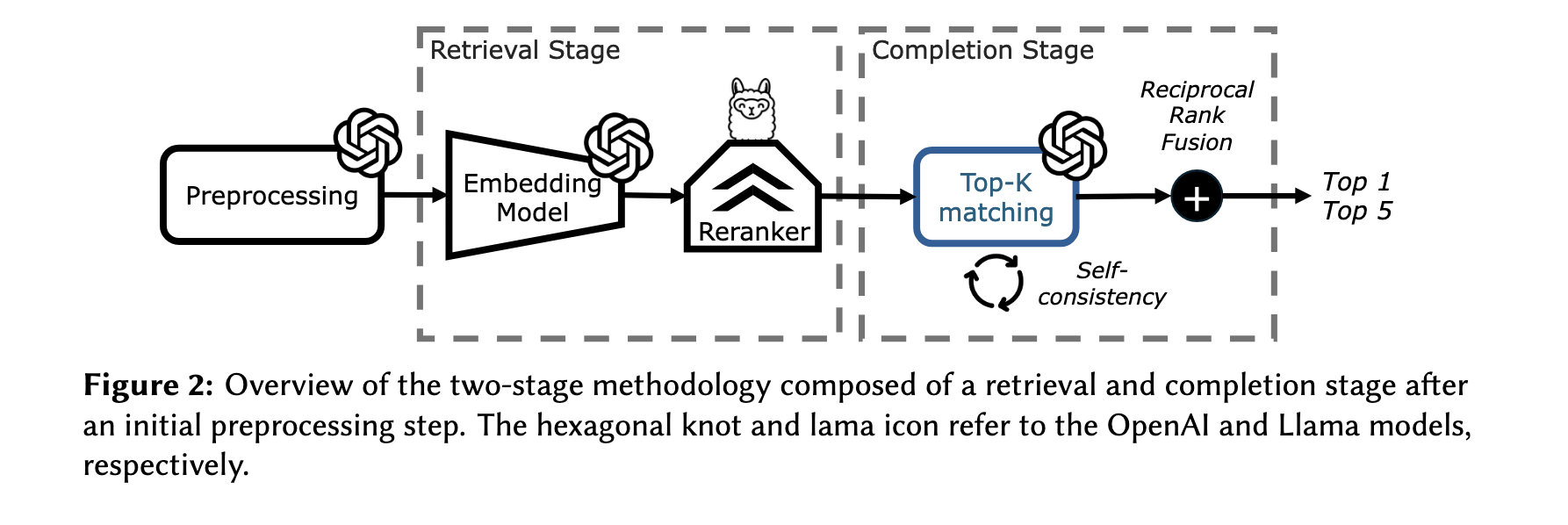
4.1 Preprocessing
4.1.1 Enriching of vocabulary
각각의 어휘의 항목은 개념 또는 속성을 나타내는데, 이 항목들을 GPT-4o를 활용해서 영어로 번역하고 문법적 오류 수정, 약어 변환, 적절한 유형으로 변경 등의 작업을 진행한다. 이를 통해 항목 자체만으로도 의미가 명확해지도록(seld-explanatory)할 수 있다. 이 작업은 한번에 100개씩 쪼개서 실행한다고 한다.
Input: prompt(label=‘ept itm’)
Output: ‘European Poker Tour (EPT) In The Money (ITM)’이걸 프롬프트 기반으로 zero-shot으로 진행하면 오류가 없을까?
또한 컬럼에 어휘를 부여하는 과정은 임베딩 벡터로 진행되기 때문에, 임베딩을 위해서 풍부한 설명 정보가 필요하다. 기존의 description에 설명된 내용을 보다 명확하게(e.g. 'Season'이라면 계절을 의미하는지, 스포츠 시즌을 의미하는 지 등) 수정한다. 이 작업은 Dataset1에 대해서만 진행하면 된다(Dataset2는 이미 생산 과정에서 품질을 고려함).
4.1.2 Enriching of table metadata
다음은 테이블 메타데이터를 수정하는 단계로, 다음과 같이 서술식으로 {컬럼명} {관계} {테이블명} 의 형태가 되도록 만들어준다. 이 작업 역시 GPT-4o를 활용한다.
Input: prompt(column=‘Height (m)’, table_name=‘Mountain’) Output: ‘Height in meters of a mountain’4.2 Retrieval Stage
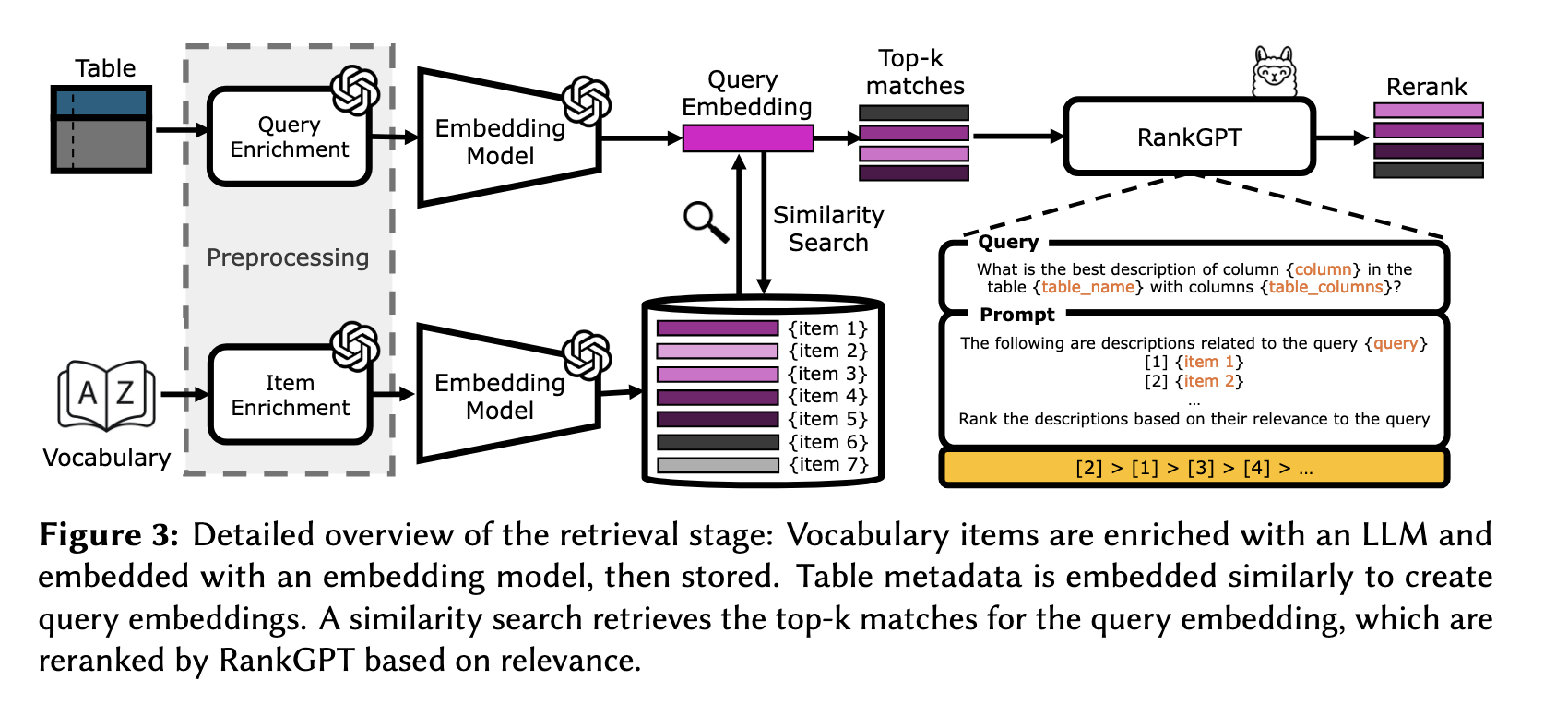
검색 단계는 임베딩과 리랭킹을 포함한 advanced RAG로 구성된다. 앞서 table과 어휘 각각 진행한 enrichment 결과를 임베딩하고, 개별 쿼리 임베딩 당 가장 유사한 어휘 임베딩을 Top-k개 검색한다. 이후, RankGPT를 통해 리랭킹해서 최종 결과를 도출하는 방식이다.
4.2.1 Embedding model
임베딩 모델을 OpenAI의 text-embedding-large-3를 사용하여 3072차원으로 변환하였다. 유사도는 Cosin simialrity를 적용했고, 상위 150개를 검색한다고 한다. 150개라는 숫자는 비용을 고려해서 선택되었는데, Dataset1에서는이 수가 충분했지만, Dataset2에서는 부족했을 수 있다고 한다. 즉, Dataset2는 어휘 수가 많고 유사 항목이 많아서 상위 150개만 선택하는게 부족할 수 있다는 말이다.
일반적으로 유사도 항목의 개수를 정할 때 실험적으로 결정하는게 가장 정확하며, 이를 위해 validation set이 필요하다. 그러나 해당 데이터셋의 검증 데이터수가 매우 적거나 부족해서 이런 실험은 할 수 없었고, 경험적으로 150개가 적당하더라...라는 결론을 내린 것이다.
4.2.2 Reranker
선택된 상위 150개의 어휘는 임베딩 모델에 의존적인 결과이기 때문에, 이 결과와 실제 대상(컬럼)을 Reranker를 기반으로 논리적 관련성을 더 정교하게 파악하고자 했다. Reranker는 오픈소스인 Llama-3-70B를 기반으로 한 RankGPT를 사용했다. Figure3에서 볼 수 있듯, 쿼리에는 대상 컬럼, 테이블 명, 테이블의 컬럼들을 넣어주고, prompt에 추출한 150개의 어휘들을 넣어준 뒤 다시 관련도 기반으로 출력하도록 한다. 이때 입력값 길이의 한계가 있으므로, 150개의 어휘를 한번에 넣어주지 않고 sliding window(e.g. 한 번에 20개씩 보고 10개씩 겹치면서 순회) 기법으로 일부씩 나눠서 연산을 진행했다고 한다.
Dataset의 DBpedia 어휘의 경우, 품질 문제가 있어서 단순한 label과 description만으로는 정확한 의미 파악이 어려웠다고 한다. 따라서 domain이 owl:Thing과 같이 너무 일반적인 경우나 range가 xsd:string과 같이 단순한 타입인 경우를 제외하고는 아래와 같이 domain, property, range 부분을 추가해줬다고 한다.
Dataset 1: [<domain>, <property>, <range>] <description>
> [Person, birthPlace, Place] The place where a person was born.4.3 Completion Stage
4.3.1 Top-k matching
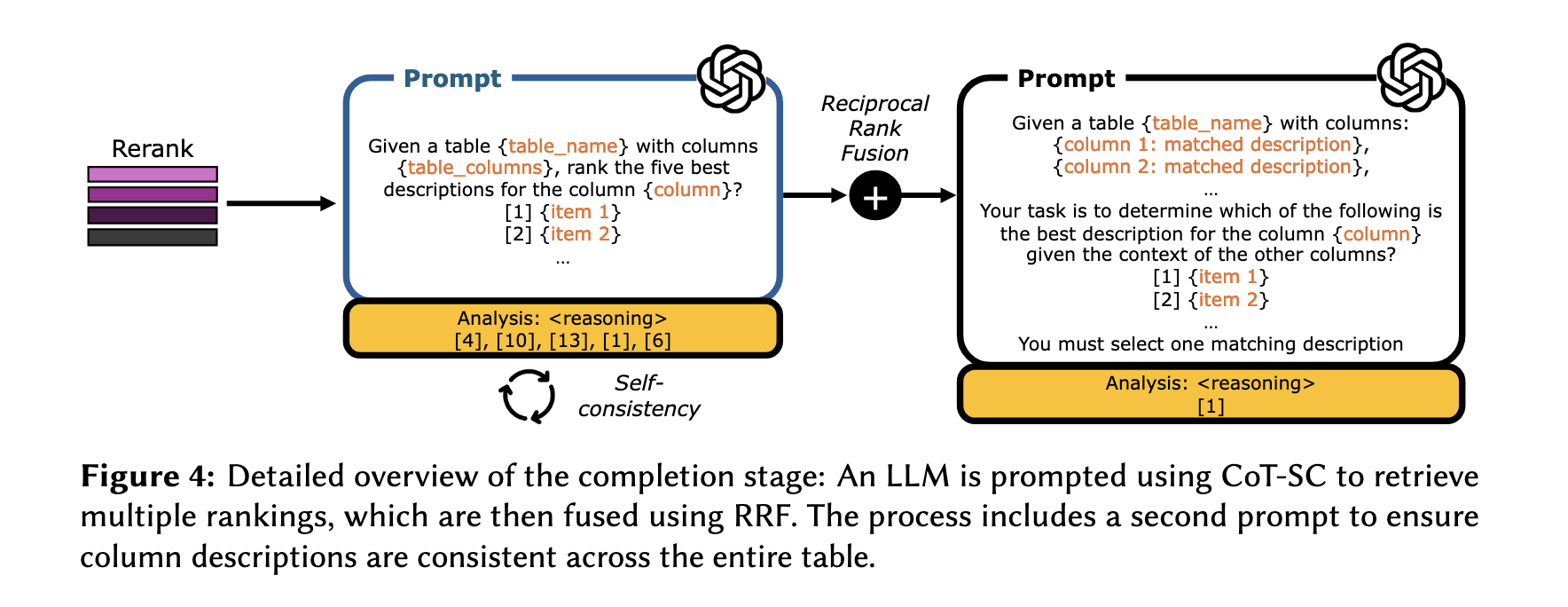
RankGPT를 통해 30개를 다시 추출한 뒤, 최종적으로 top1과 top5를 얻기 위해 GPT-4o를 zero-shot으로 사용했다고 한다. 이때 프롬프트에는 CoT와 SC기법을 적용했고 최종적으로 RRF를 통해서 통합 랭킹을만들었다. COT-SC는 classification 테스크에서 일반적으로 많이 사용되는 기법으로, 여러개의 샘플을 반복적으로 추출한 뒤, 다수결을 통해서 결과를 도출하는 방법이다. 이때 샘플 추출은 무작위로 섞어서 진행해서 편향성을 없애고, 결론을 free text로 생성한뒤 정규표현식을 통해서 실제 정답값을 추출했다고 한다.
보충설명을 하자면, CoT를 썼다는 건 사고를 단계별로 진행하도록 프롬프팅을 했다는 의미이고 SC, 즉 Self-Consistency를 사용했다는 건 같은 질문에 대해 여러번 답변하도록 해서 그 중에 가장 많이 나오는 답변을 다수결로 선택하는 방법이다. 이 기법은 일관성있는 판단을 가능하게 한다.
이후 진행하는 RRF는 COT-SC를 통해 출력된 결과들을 종합하는 방법이다. 랭킹 리스트를 점수 기반으로 재계산하여 최종 순위를 얻는 것이다.
예를 들어 A 컬럼의 유사한 항목 top-5를 추출하는 작업을 3번 반복하면, 총 15개의 항목이 있을 것이다. 개별 항목별로 각 단계의 순위를 반영한 계산값을 도출한 뒤 다시 랭킹을 하면 15개의 항목을 줄세울 수 있다. TF-IDF를 계산하는 방식을 떠올려보면 쉽게 이해할 수 있다.
4.3.2 Table matching
figure4의 우측 프롬프트를 보면, 맵핑의 정확도를 높이기 위해 테이블 별로 컬럼 설명의 일관성을 확보하려는 단계를 추가하고 있다. 앞 단계에서 뽑힌 top-5에 대해서 해당 열이 속한 테이블의 정보를 기반으로 다시 맥락을 파악하는 것이다. 예를 들어 'ID'라는 컬럼이 있을 때, 고객들의 정보와 관련된 테이블이라면 'userID'일 가능성이 높을 것이다. 이때는 CoT를 적용하지 않고 temperature을 0.0으로 두어 안정적인 결과가 도출되도록 했다고 한다.
4.4 Non-contextual Methodology
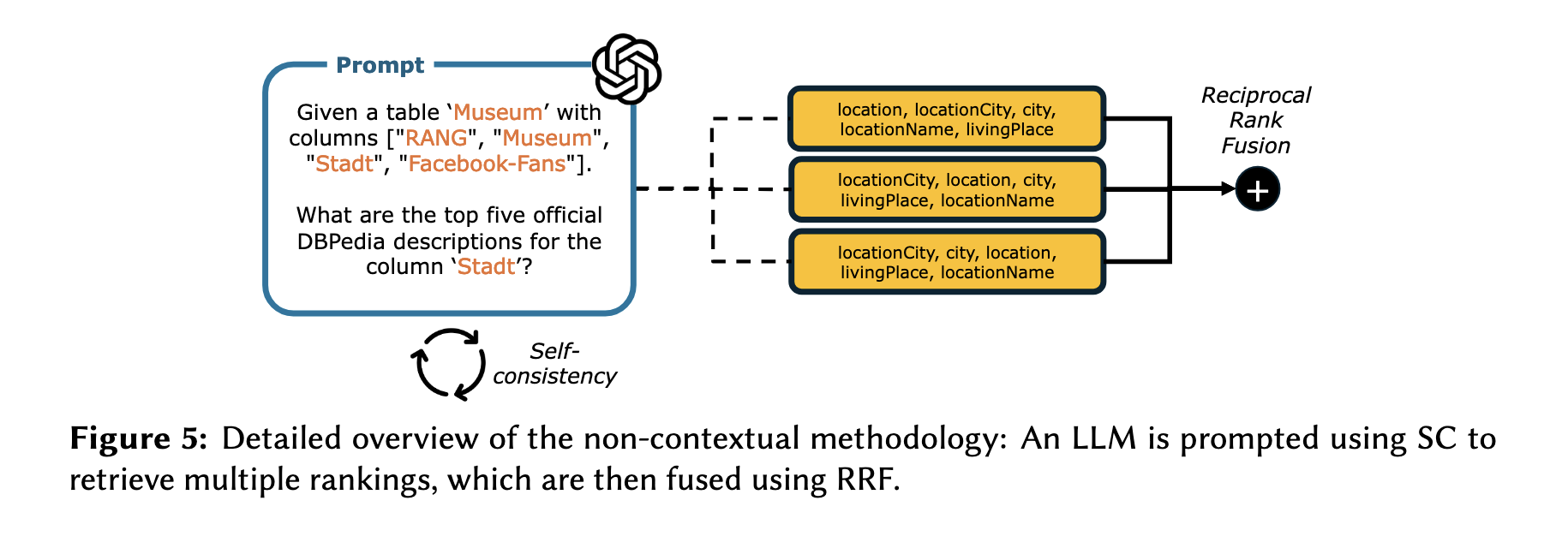
Retrieval과 Completion 단계에 추가로 비-맥락적 기법도 적용했는데, 즉 그냥 테이블의 컬럼을 넣어주고 적합한 DBPedia의 속성값을 추천해주도록 하는 방법을 의미한다. 이는 LLM의 성능을 파악하기 위한 목적으로, SC와 RRF를 기반으로 진행했다고 한다.
5️⃣ Results
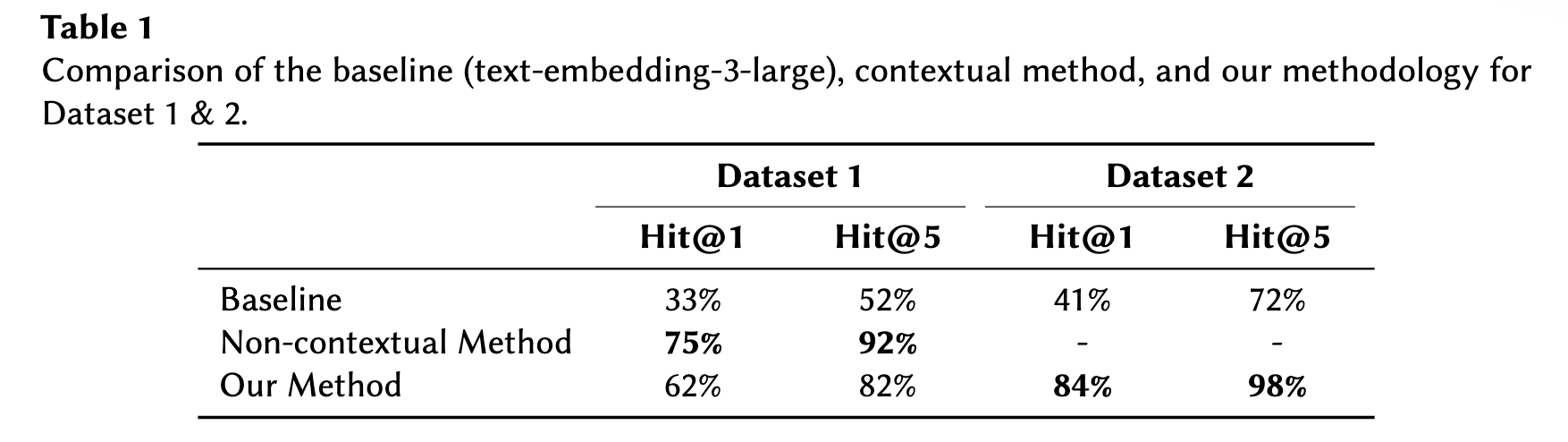
평가는 Hit@k (k=1, k=5)로 진행되었고, 상위 k개 중 하나라도 정답이면 1, 그렇지 않으면 0으로 평가된다. Table1을 보면, DBpedia와 같이 사전에 정의된, 일반적인 KG의 속성의 경우 Non-contextual 기법으로도 높은 성능을 보였고, 연구의 기법은 Dataset2에는 적합했다는 결론을 내릴 수 있다.
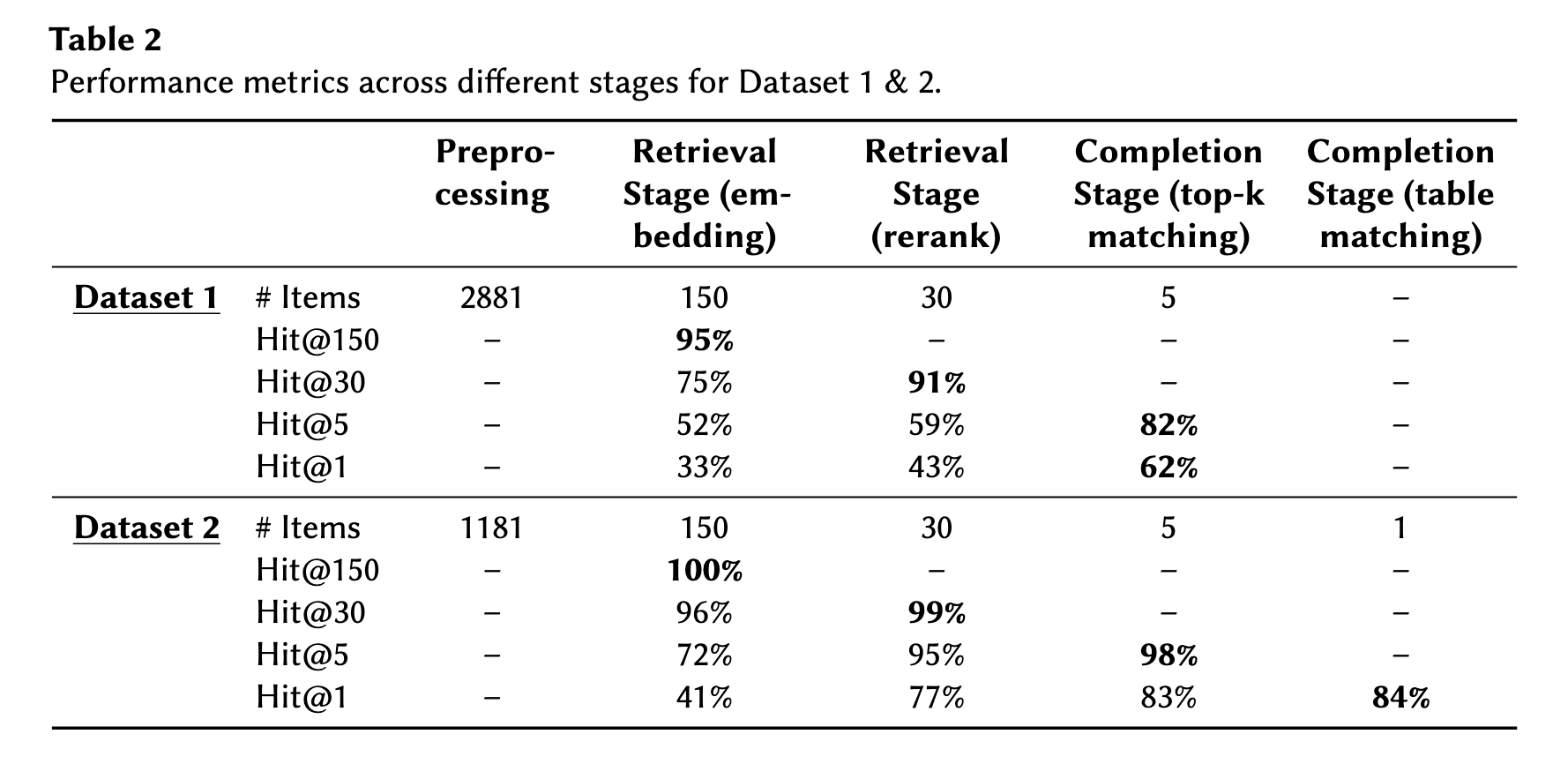
단계별로 성능을 보면, Dataset1과 Dataset2는 이미 임베딩 단계에서 높은 성능을 보였고, 정밀도를 높이는 이후 과정을 진행했을 때도 성능이 큰폭으로 떨어지진 않았다고 한다. 특히 Hit@1을 했을 때도 84% 정도의 성능은 유지됐다.
6️⃣ Discussion and Future work
LLM을 기반으로 컬럼의 개념을 라벨링하는 것의 장점을 세 가지로 제시한다.
- 사람은 전체 KG의 개념을 파악하지 못하고 있을 수 있지만, LLM은 메모리 기반으로 가능함
- 사람의 맵핑 기준은 달라질 수 있지만, 모델은 항상 같은 기준을 적용할 수 있음
- LLM은 도메인 지식이 없어도 메타데이터의 전문 용어를 맥락상으로 해석할 수 있음
논문에서도 인스턴스 예시를 일부 넣어주는 것은 성능 향상에 도움이 된다고 언급한다. 또한 Dataset2 작업 전체에 약 50$ 정도의 비용이 소요됐는데, reranking 단계에서 window size를 조절하거나 더 저렴한 임베딩 모델을 쓰는 등의 방식으로 비용을 절감할 수 있다고 한다.
.
.
.
만약 테이블 데이터의 description 정보가 추가로 주어진다면 더욱 문맥을 반영한 라벨링이 가능하지 않을까? 추가로 드는 의문은, 테이블 데이터들을 맵핑할 어휘들은 사전에 어휘 목록을 구축해야 하는데, 그 범위에 대한 구성까지 자동화할 수 있을지, 그 결과는 어떻게 검증해야 할지 등과 관련된다. 예를 들어, 문화재 데이터의 경우, '시대'라는 컬럼이 존재하는데 이를 표현할 수 있는 속성에 대하여 연구자가 직접 생산한다면 모르겠지만, 그렇지 않다면 존재하는 표준 어휘 중에서 열심히 서칭해서 선택되어야 한다. 이 서칭의 범위가 일반 LLM은 얼마나 넓을까? 혹은 얼마나 깊이 고민해서 적절한 속성값을 부여할까?
관련 논문을 더 읽어봐야 할거 같다ㅎㅎ😎🤨
