[논문리뷰] Leveraging small language models for Text2SPARQL tasks to improve the resilience of AI assistance
Paper Review

몇 백억 파라미터의 모델이 등장하는 현 시점에서 10억 파라미터 이하의 모델, 그것도 오픈소스 모델만을 활용한 Text2SPARQL 맞춤 태스크를 실험하는 논문이다. Text2SPARQL fine-tuning 방법을 명확하게 설명하진 않았지만, 작은 모델의 활용 가능성을 확인할 수 있었다.
🧩 Introduction
ChatGPT이후, 여러 대기업에서는 LLM과 같은 생성형 AI가 스마트폰과 같이 일상생활의 자연스러운 일부가 될 것이라 예측하며 다양한 개발을 하고 있다. 현 시점에 다양한 벤치마크 데이터셋을 활용한 평가가 진행되고 있으며 Huggingface 리더보드에서는 매일 새로운 기록을 갱신한 모델들이 등장한다. 그러나 이러한 평가는 모두 자연어를 처리하는 분야, 즉 다음 문장을 만들거나 QA, 텍스트 요약과 같은 태스크를 기반으로 한다.
선행 연구 중에는 LLM이 지식그래프와 상호작용하고 지식 엔지니어링 작업을 지원하는 능력을 평가하는 테스트가 있었다. 평가 결과로 GPT4나 Claude와 같은 플래그쉽 모델들은 괜찮은 성능을 보였고 이후 Turtle 형식의 그래프 처리에서도 지속적인 개선을 보였지만, 그럼에도 다음과 같은 주의사항들이 있다고 한다.
- 테스트한 사업용 LLM들은 모두 외부에서 호스팅되기 때문에(API를 사용하는 케이스) 사용자의 데이터 보호와 관련된 문제가 발생할 수 있음
- 모델의 사이즈가 굉장히 크기 때문에 로컬에서 운영하는 것은 엄청난 비용이 발생함. 연구 기관에서 이 모델들을 훈련시키는 것도 쉽지 않음
- 이런 상업용 모델들 조차도 SPARQL 쿼리를 작성하거나 RML 매핑 생성 등을 여전히 어려워하고, 추가적인 fine-tuning이 필요함
- 제3자 플랫폼에서 호스팅된 LLM 서비스를 사용할 경우, 갑작스러운 가격변경이나 인프라 장애들에 대한 문제가 있어 의존성 문제가 존재함
따라서 본 논문에서는 LLM을 사용해여 해결하려는 단일 문제가 있을 때, 작은 모델로도 유사한 성능을 달성할 수 있는 방법에 대해 질문하며, 자연어 질의를 SPARQL 쿼리로 변환하는 태스크를 진행한다고 한다.
🧩 Related Work
최근 Text2SPARQL은 대부분 fine-tuning을 기반으로 한다. 예를 들어, OpenLLaMA는 생명과학 KG를 통해 의미있는 변수 이름과 인라인 주석을 제공하기 위한 방법론이며, LLaMA를 Wikidata로 fine-tuning하여 SPARQL 쿼리를 생성하고자 한 논문도 있었다. 본 연구는 이 두 연구에서 사용한 7B 모델보다 더 작은 모델을 사용해서 효율성을 높이고자 한다.
작은 모델의 가능성을 보여준 연구도 있었는데, SQLCoder-7B는 SQL생성헤서 GPT4보다 좋은 성능을 보였다는 점에서 특정 작업에 특화된 작은 모델은 범용적인 대형 모델을 이길 수도 있다는 것을 알 수 있다. 한편, 기존 연구 중에는 특정 모델에 특화된 연구만 진행해서 다른 모델들과의 체계적인 성능 비교를 하지 않았으므로, 본 연구에서는 어떤 모델, 특히 작은 모델을 사용해서 최적의 성능을 내는 방법을 알아보고 이유를 탐색해본다.
🧩 Experimental Setup
3.1 Model families
Steam Hard-and Software Survey에 따르면, 57.22%의 사용자는 8GB의 VRAM GPU를 사용한다고 하며, 이는 1B 모델을 돌리기에 충분한 성능이라고 한다. 따라서 본 연구는 1B 이하의 모델 중에서 누구나 사용할 수 있는 Huggingface에 완전 개방된 모델들만 사용하며, 선정한 3개 family 모델과 파라미터 사이즈는 다음 표와 있다.

1️⃣ T5 and Flan-T5
T5(Text-To-Text Transfer Transformer)는 2020년 구글에서 개발한 모델이다. 기본 모델은 2200만 파라미터로 구성되며, 텍스트 분류나 감성 분류와 같은 모든 NLP 태스크를 하나의 모델에서 진행하고 싶다는 목적하에 개발되었다. 2022년에는 성능을 강화한 FLAN-T5(Fine-tuning Language Models)를 공개했다.
2️⃣ BART
BART는 2019년 Facebook에서 공개한 1390만 파라미터의 모델로, BERT 기반의 인코더와 GPT 기반의 autoregressive 디코더로 구성된다. 2020년에는 다국어 버전인 mBART를 출시하고, KG기반으로 fine-tuning된 다국어 관계 추출 mREBEL도 존재한다. BART는 기본적으로 세부적인 태스크를 위해서 추가적인 fine-tuning이 필요한 사전학습만 진행된 모델이다.
3️⃣ M2M100 and NLLB-200
2020년에 공개된 M2M100은 100개 언어의 다대다 번역을 위한 모델이다. 기본 모델은 13억 파라미터로 구성되지만, Huggingface에 distilled 버전인 M2M100-418M 모델이 존재한다. 또한 2022년 공개된 33억 파라미터의 NLLB-200(No Language Left Behind)모델의 distilled 버전인 NLLB-200-Distilled-600M 모델도 포함한다.
3.2 Datasets used for Fine Tuning and Evaluation
평가를 위해 서로 다른 도메인과 복잡도를 가진 데이터셋을 사용한다. 우선 Organizational Graph와 CoyPu graph는 GPT4를 활용해서 자연어 질문과 SPARQL쿼리 매칭셋, 쿼리의 예상 결과를 생성한다. 생성된 SPARQL를 실행 실행해서 예상 결과와 같은 경우만 남긴다. 이후 남은 질문들을 다시 GPT4에 넣어서 패러프레이징을 통해 augmentation을 진행해서 결과적으로 하나의 SPARQL 쿼리 당 2개의 자연어 질문을 만든다고 한다.
1️⃣ Organizational Graph
이 작은 사이즈의 KG는 기존에 있는 어휘를 사용하여 조직의 부서와 직원을 표현한다. Prefix 정의는 쿼리의 상단에 이미 존재한다고 가정해서 추가로 생성하지 않도록 하고, 쿼리 자체를 생성하는 것에만 집중할 수 있도록 했다고 한다. GPT4를 사용해서 총 69개의 데이터포인트(자연어-SPARQL 쿼리 튜플과 예상 결과를 하나의 데이터포인트라고 표현한 듯)를 생성했고, 53개는 훈련용으로 16개는 테스트용으로 사용했다고 한다.
2️⃣ A subset of the CoyPu graph
CoyPu 프로젝트는 공공인프라, 무역과 협정, 재해와 분쟁 등 사건과 기타 다양한 소스 등을 대규모 지식그래프로 통합하여 기업의 공급망 회복력을 향상시키는 것을 목표로 한다. 이 KG를 통해 기업은 단일 실패 지점을 식별하고 리스크 완화 전략을 수립하며 실제 비즈니스에 직접적 도움을 얻을 수 있다고 한다. 학술적 특징이 강한 다른 두 데이터셋과 달리, CoyPu 데이터는 실제 비즈니스 문제 해결 특성이 있다. 한편, 대규모 사이즈의 일부 subset을 추출하는 것이 쉽지 않다는 한계가 있으며, 이는 향후 연구 과제로 둔다. 총 131개의 튜플을 생성하여 훈련용으로 105개를 사용하고, 테스트용으로 26개를 사용한다.
3️⃣ QALD10
QALD(Question Answering over Linked DATA)는 표준 벤치마크 데이터셋으로 Wikidata 기반의 SPARQL 쿼리와 다국어 질문을 포함한다. 이 연구에서는 영어만 사용한다고 한다. 한 가지 어려움에 대해서도 설명하는데, 예를 들어 'Barack Obama'를 wikidata의 entity ID인 'Q76'으로 매핑을 해야 하는데, 동명이인이나 중의성이 있기 때문에 이 방법이 명확하지 않았다고 한다.
3.3 Fine-tuning
모든 평가 데이터세트에 대해 Pytorch를 사용해서 100 에포크의 fine-tuning을 진행한다. 단일 fine-tuning 만으로는 통계적 유의성을 설명하기 부족하므로 독립적으로 10번 실행하고, 각 훈련마다 정해진 random-seed를 사용해서 재현가능하도록 했다. 예를 들어, 각 실행은 R01~R10까지 아이디를 부여하고, ID의 SHA512 해시값을 계산해서 해시값의 앞 8자리를 시드로 사용하는 것이다.
🧩 Results
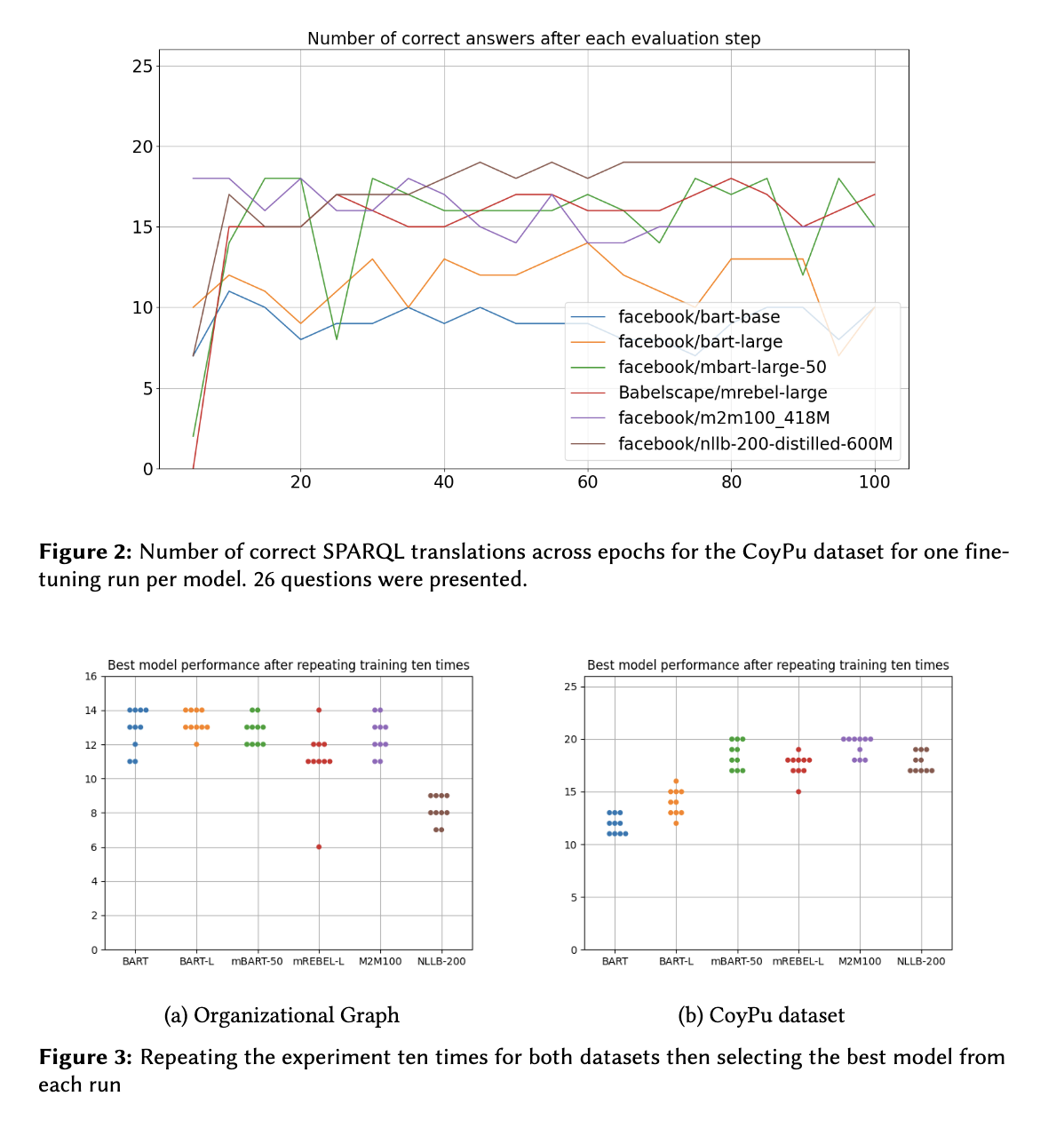
평가 결과에는 최소한 한 개 이상 올바른 쿼리를 생성한 모델만 포함했고, T5 family는 이 과정에서 제외되었다. 평가 방법론으로는 5 에포크마다 학습을 멈추고, 생성된 SPARQL 쿼리로 직접 실행한 뒤 결과가 정답과 일치하는지 확인한 뒤 훈련을 재개랬다고 한다. 이러한 방법은 단순히 최종 결과만 확인하는 것이 아니라 학습 전체 과정을 보여줘서 더 큰 인사이트를 발견할 가능성이 있다.
4.1 Organizational Graph
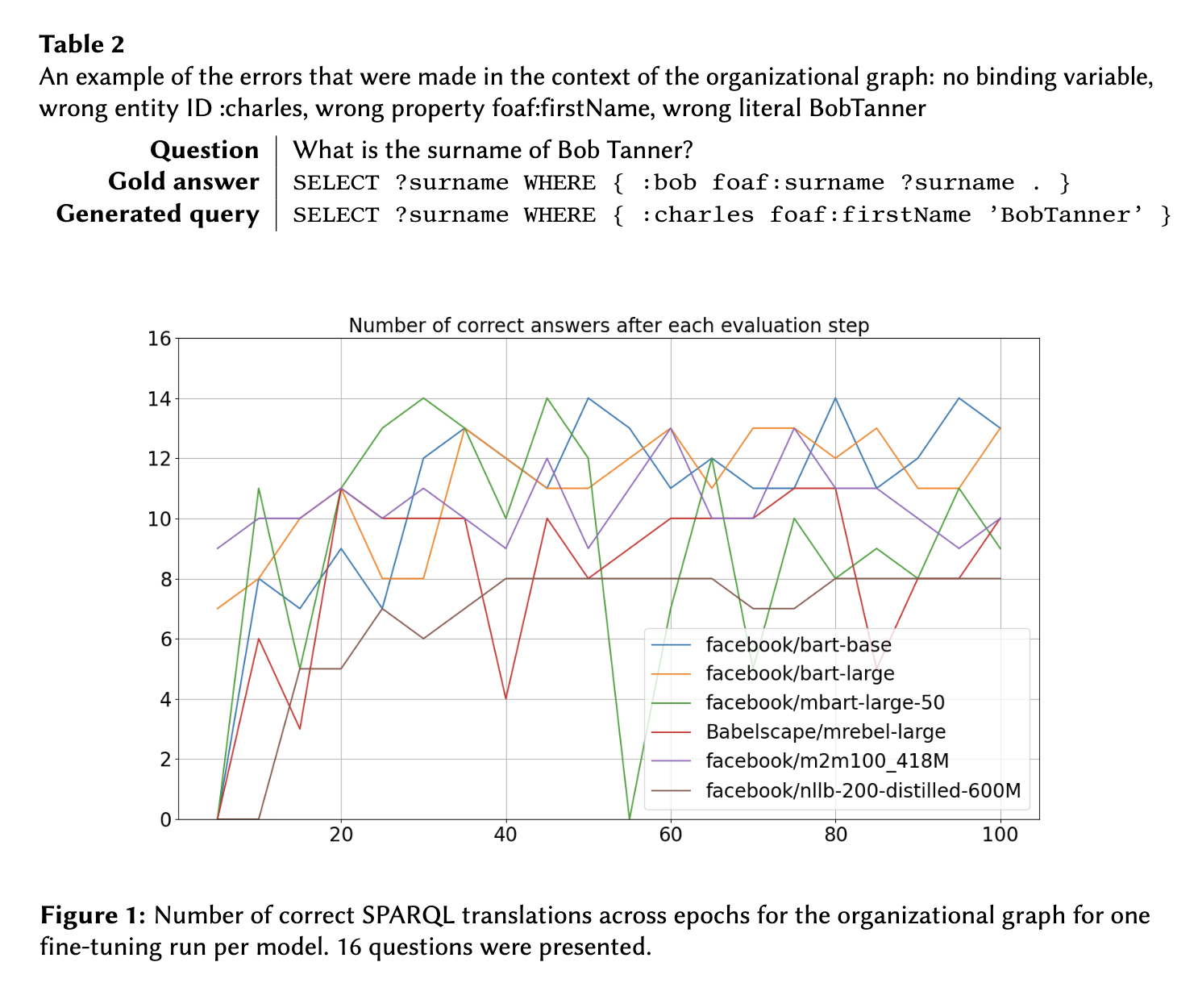
위 그래프를 보면, 모든 모델은 100개의 에포크 중 최고의 성능을 보인 경우, 16개의 질문중 11개 이상의 정답을 생성하며 어느 정도 학습이 잘된 결과를 보여준다. 그러나 성능이 일정하지 않고 편차가 크고, 훈련 데이터 순서에 따라 성능이 약간 변동된다고 한다.
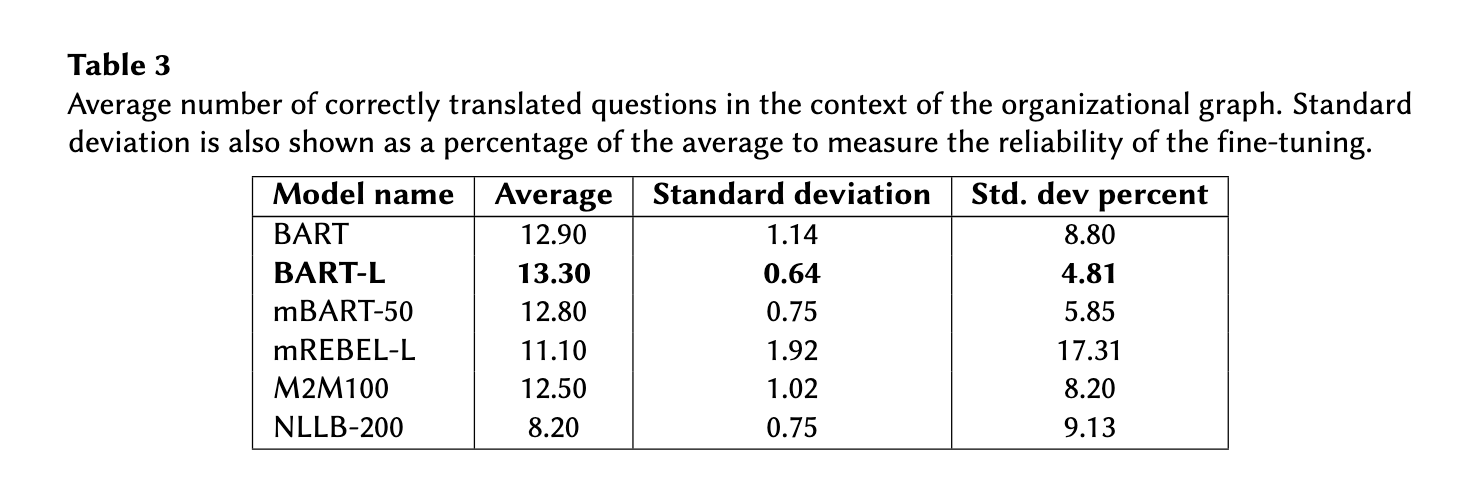
최고 성능을 보인 모델은 BART-L이고, 모든 크기에서 우수했다. 이를 통해 모델 사이즈보다 아키텍쳐가 더 중요할 수 있음을 확인할 수 있다. 또한 대부분의 경우 쿼리되지 않는, 즉 문법적으로 오류가 있는 쿼리는 거의 생성하지 않았고 엔티티나 속성의 의미를 잘못 파악한 오류가 많았다고 한다. 예를 들어, 위 Table2를 보면, foaf:surname이라는 속성을 사용해야 하는데, foaf:firstnName을 사용하거나 'Bob Tanner'의 엔티티를 :bob으로 생성해야 하는데 'BobTanner'로 생성하는 등의 오류를 발생하고 있다.
4.2 CoyPu
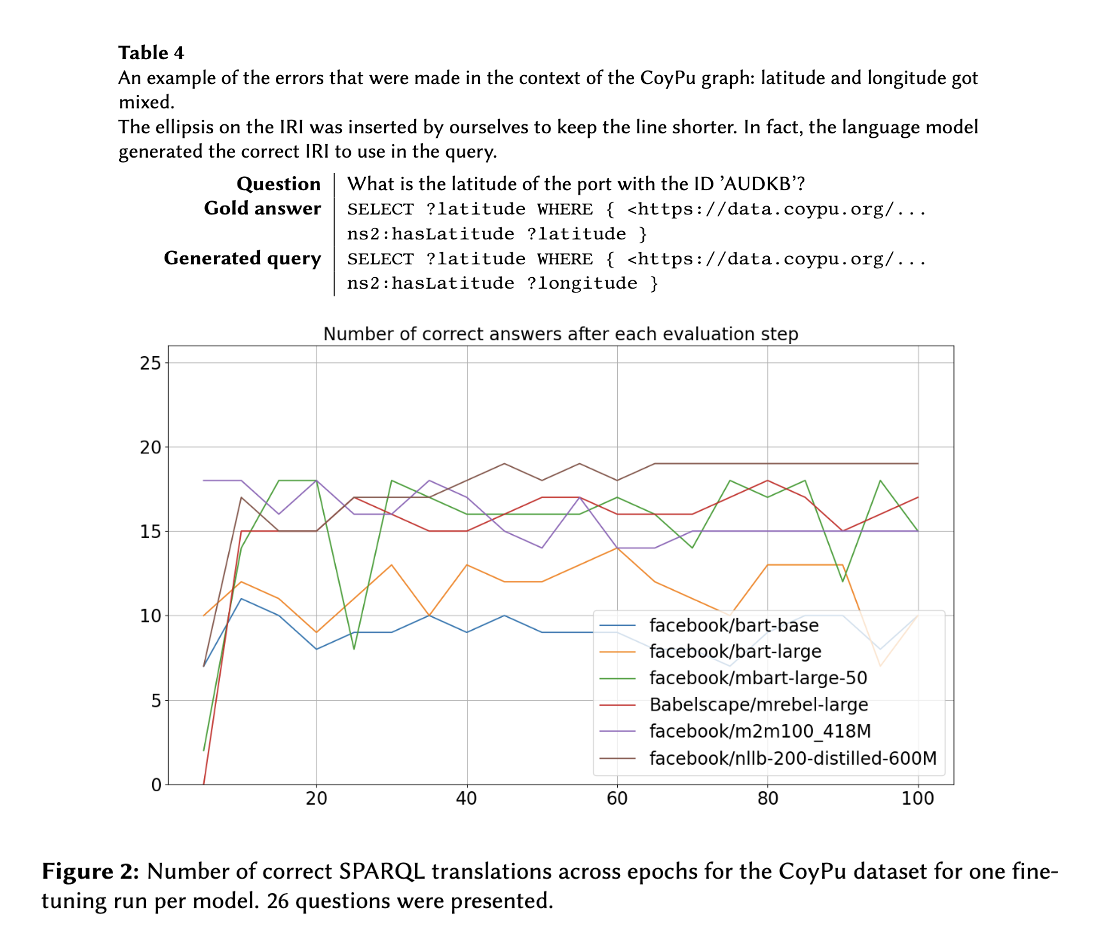
CoyPu 데이터에서는 Organization Graph 보다는 편차가 덜 크게 나타났고 M2M100이 BART-L보다 성능이 뛰어났다.

BART-L의 경우 구문적 오류는 많지 않았지만, 공급망 도메인 용어를 잘 생성하지 못했고, M2M100의 경우 문법적 오류가 많았다고 한다.
4.3 QALD10
위에서 언급했든 QALD10 데이터셋은 위키데이터의 ID와 매핑되어야 한다는 점에서 어려움이 있다. 또한 쿼리에 필요한 모든 prefix를 정의하도록 요구하기 때문에 앞서 두 데이터셋에 비해서 복잡성이 추가되기도 했다. 성능을 보면, 가장 성능이 좋았던 M2M100-418M은 394개 질문 중 104개, 즉 26%만 검색 가능한 SPARQL을 생성했으면, 이중 51개는 빈 결과를 반환했고 실제로 정답은 0개였다. 다른 모델도 비슷한 성능을 보이며 결과적으로 QALD10에서는 정답률이 0% 다고 한다.
결론적으로 작은 모델들이 현실적인 복잡성을 가진 데이터셋에서는 실용적이지 않음을 보여주며, 여전히 Entity Linking과 같이 복잡한 스키마 처리가 어렵다는 것을 확인할 수 있었다.
🧩 Conclusion and Future Work
본 연구에 따르면, Text2SPARQL 태스크에서 BART나 M2M100 패밀리의 성능이 우수했고 다음 세 가지의 향후 연구 방향을 제시한다.
우선 모델 크기의 기준을 재정의할 필요가 있다. 현재 10억 파라미터의 모델로 제한해서 태스크를 진행했는데, 모델의 크기와 SPARQL 생성 능력 간의 관계를 다시 탐색할 필요가 있다. 또한 fine-tuning 모델에 RAG 기법을 결합하여 응답 성능을 높일 수 있는 방법에 대한 연구도 필요하고, 모델의 아키텍쳐를 수정할 수도 있다. 기존 레이어를 수정, 추가하거나 오픈 소스 데이터셋을 활용해서 처음부터 Pre-training을 진행하는 방법도 있다. 한편, 여전히 데이터셋을 생성하는 과정에서 GPT4를 사용했다는 점에서 Falcon이나 Bloom과 같은 오픈소스를 사용해서 완전히 독립적으로 로컬에서 시행하는 파이프라인을 구축할 수도 있다.
