
text2sparql을 할 때, fine-tuning을 하지 않고 성능을 높일 수 있는 방법으로 one-shot 기법을 적용한 SPARQLGEN을 제안하는 논문이다. 이때 one-shot에는 다음 3가지의 정보가 포함된다.
- 질문
- 질문을 답변하는데 필요한 RDF subgraph
- 다른 종류의 질문과 올바른 정답 세트
여기서 필자의 포커스는 어떻게 RDF subgraph 효율적으로, 정확한 값을 뽑아낼 수 있는지 이다.
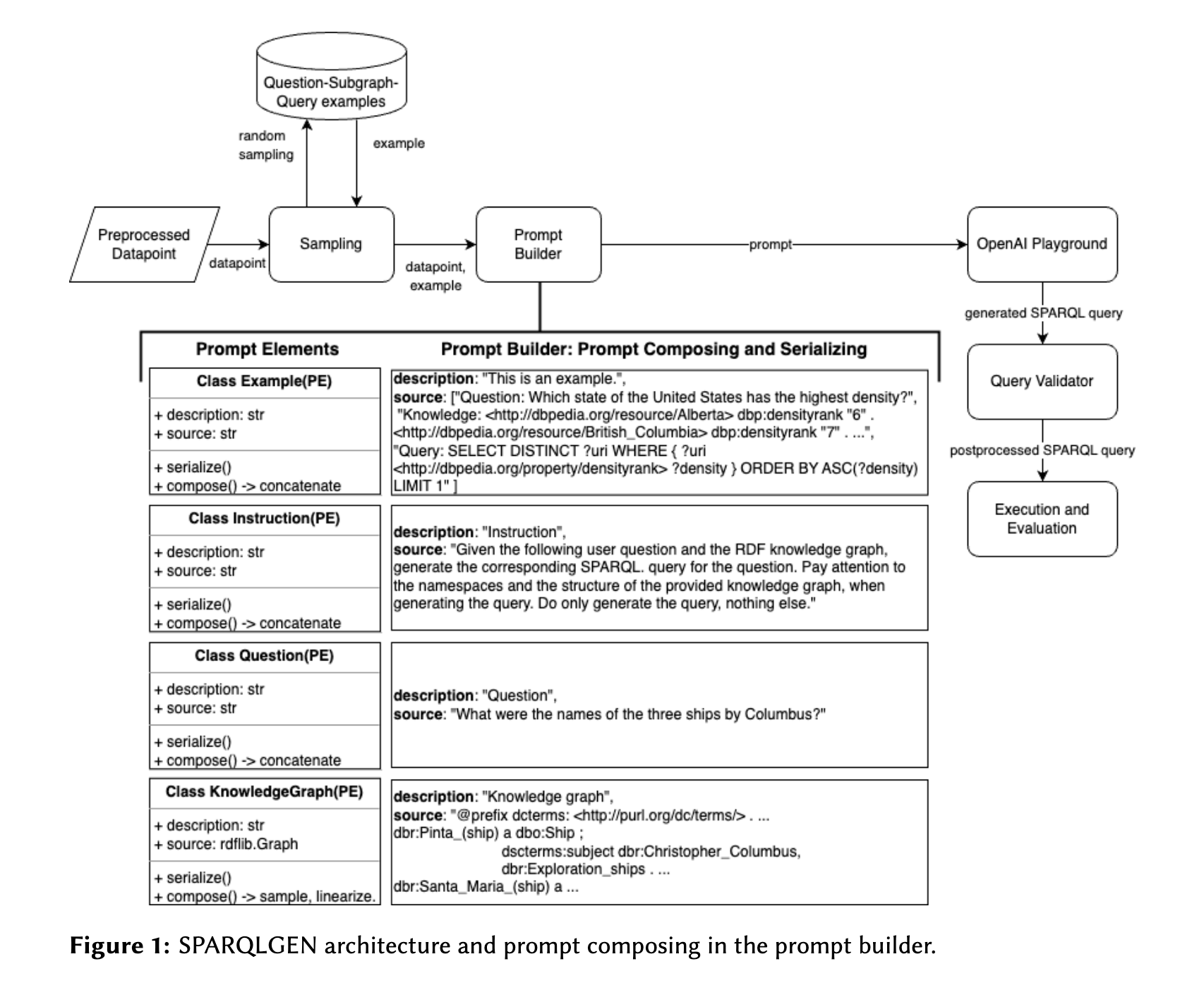
SPARQLGEN은 크게 3가지의 단계로 구성된다.
- Retrieving context to populate prompt elements: 프롬프트의one-shot에 넣어줄 정보를 가져오는(검색하는) 단계
- Composing and executing the prompt: 프롬프트를 구성하고 실행하는 단계
- Removing hallucinations and validating the query: 환각 현상이 일어난 정보를 삭제하고 쿼리를 검증하는 단계
1번 단계에서는 subgraph에 해당하는 정보와 sample qa 세트를 가져오는 과정이 필요하다. 이때의 subgraph는 다시 세 단계를 통해서 가져온다.
- 주어진 질문에 대한 정답 SPARQL 쿼리에서 모든 수정자를 제거하고, 가장 단순한 형태인
SELECT *쿼리로 변환하여 해당 쿼리의 모든 변수에 대한 가능한 결과값을 얻는다. - 쿼리에서 각 entity, relation, variables를 포함하는 개별 triples를 추출한다.
- 앞서
SELECT *에서 얻은 결과값을 사용하여 추출된 triple 내의 변수를 실제값을 대체한다.
이 단계를 거치면 해당 질문에 필요한 정보만 포함된 sub graph를 구성할 수 있다.
여기서 말하는 주어진 질문에 대한 정답 SPARQL 쿼리는 어떻게 가져오는 걸까? sampling을 한다고 이해했는데, 단순 sampling이 아니라 질문에 맞는 쿼리를 sampling? 어떻게..? 이해를 못했다
prompt를 구성하는 방식이나 structure는 참고할 수 있을 듯

궁금한 건 많지만, 천천히 알아가는 중입니다