
스터디 책: Building Knowledge Graphs
Organizing Principles of a KGs
앞서 1장에서 KGs는 그래프의 한 가지 타입이며, 인간과 소프트웨어가 이해할 수 있도록 하는 '조직 원칙(organizing principles)'이 필요하다고 언급한 바 있다. 이 장에서는 지식그래프의 여러 조직 원리를 소개하고, 이를 조합하거나 선택하여 점차 정교한 문제 해결로 확장할 수 있는 방법을 설명한다.
'semantics' 라는 단어가 잠깐 언급되는데, 지식그래프에서 시멘틱은 데이터에 맥락과 의미를 부여하는 원리로, principles와 유사한 개념으로 설명된다. 즉, 'making the data smarter'을 통해 재사용, 확장, 추론을 할 수 있도록 만드는 것으로 이해할 수 있다.
1️⃣ Plain Old Graphs
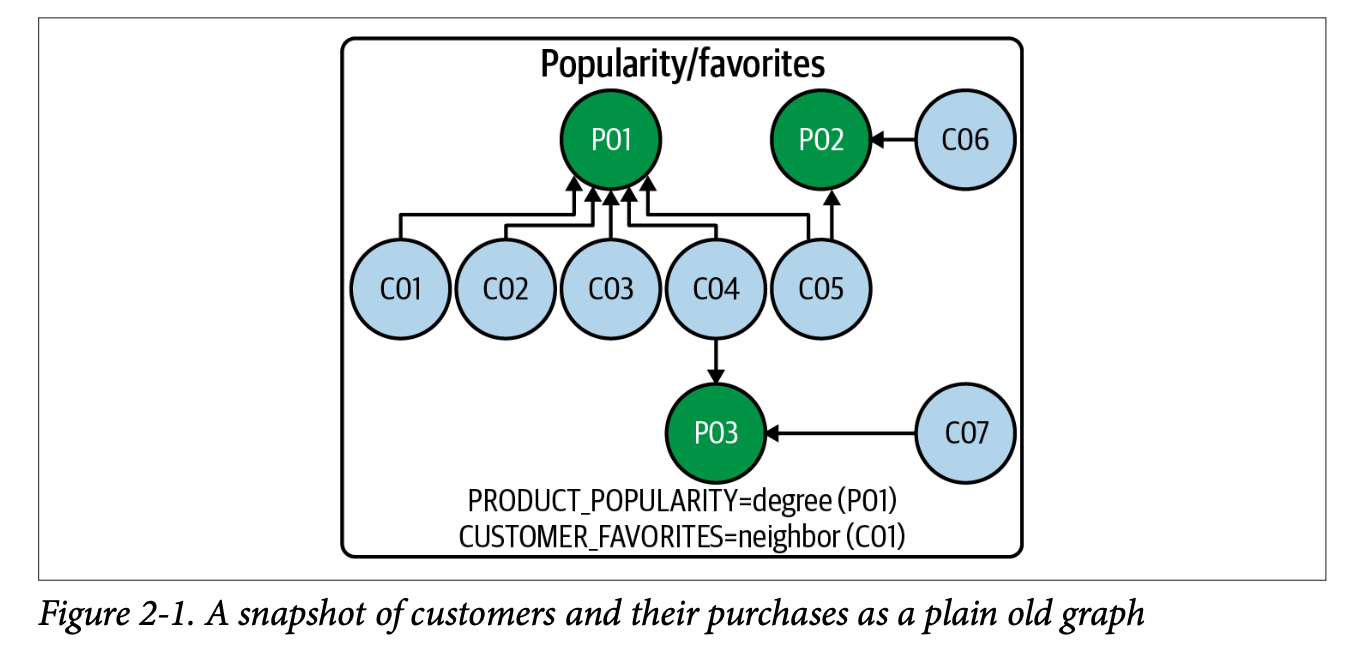
지식그래프와 반대되는 개념의 '그래프'는 정보 해석 방식이 그래프 자체에 포함되어 있지 않고 그래프를 사용하는 시스템 안에 인코딩되어 있다는 점이다. 위 그래프를 예로 들면, 도메인 전문가가 아닌 사람은 그래프만 봤을 때 어떤 의미인지 직관적으로 해석하기 어렵다. P노드가 Product, C노드가 Customer를 의미하고 구매 관계를 표현한다는 의미를 알게 되면 이 그래프를 통해 구매자들의 선호도를 파악하고, 선호도가 높은 상품을 간단하게 파악할 수 있다는 사실을 알게 되지만, 이 정보들은 모두 내재된 상태라는 의미이다.
따라서 스스로 이해할 수 있도록 데이터에 조직 원칙을 적용한 지식그래프는 누구나 의미를 쉽게 이해하고 활용할 수 있다는 장점이 있다.
2️⃣ Richer Graph Models
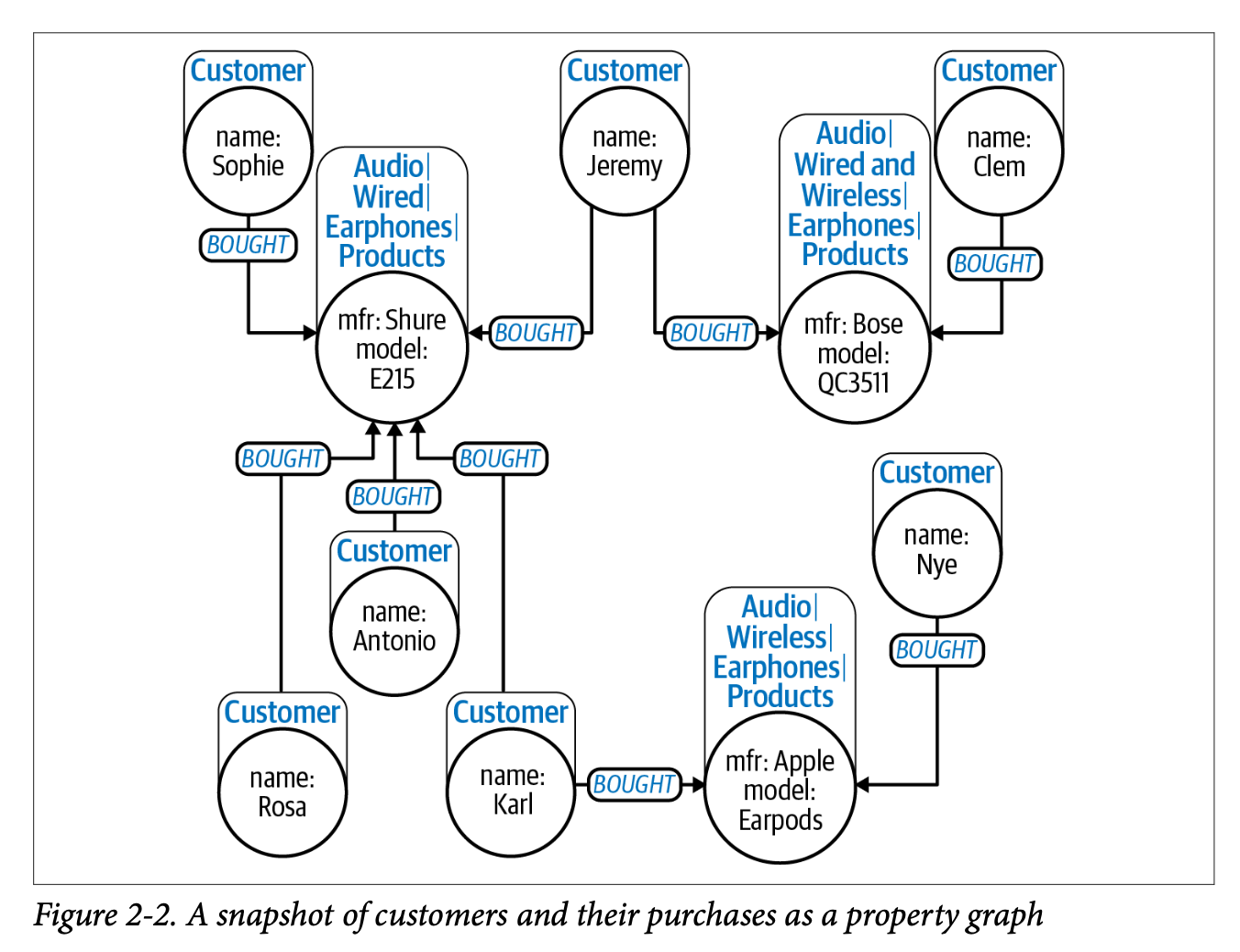
property graph model은 더 구조화된 방식으로, 각 노드와 관계를 그래프 내에서 표현하기 때문에 사람과 소프트웨어는 그래프만으로도 구조를 이해할 수 있다. 책에서는 이를 self-describing을 가능한 방식이라고 설명하고 있다. 데이터 사이언티스트는 도메인 전문가의 도움 없이도 대부분의 내용을 파악할 수 있다.
위 그래프는 여러 제품 특징을 property graph로 표현하고 있는데, 이를 통해 무선 헤드폰만 찾아내기, 전체 제품 수 등과 같은 추출을 간단하게 진행할 수 있다. 그러나 이런 단순한 구성만으로는 추론(reasoning)의 한계가 있으며, 더 강력한 조직 원칙이 필요하다고 한다. 예를 들어, 어떤 제품이 다른 제품으로 대체될 수 있다는 정보는 레이블만으로는 파악하기 어렵기 때문이다.
3️⃣ KGs Using Taxonomies for Hierarchy
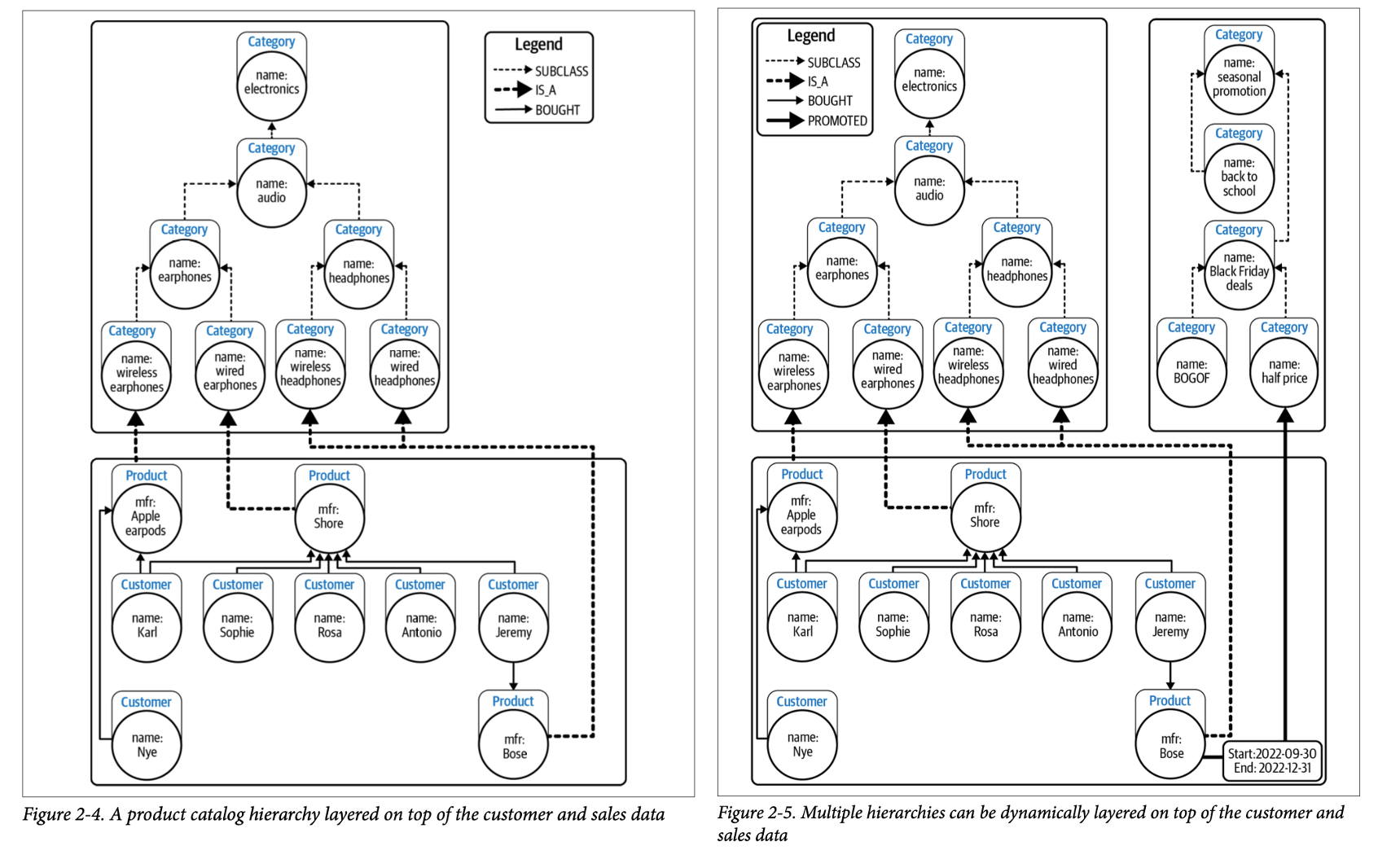
2-2 그래프에는 라벨을 통해서 카테고리(제품, 사람)를 구분할 수 있지만, 레이블 간의 관계는 파악할 수 없다. labeled property graph model의 레이블은 단순히 태그와 같은 역할을 할 뿐, type system 처럼 작동하지 않는다. 따라서 Apple이라는 노드에 :Fruit라는 레이블이 붙었다고 해서 상하위 개념이 자동으로 추론되지 않는다. 이는 RDF 기반의 시멘틱 웹 기술의 그래프와 차이가 있는데, 추론을 지원한다는 장점이 있지만, 복잡도가 높고 연산 비용이 크다는 한계가 있다.
한편, 비즈니스 관점에서는 고객이 찾는 상품이 없다면, 대체제를 제안할 수 있어야 한다. x가 y의 한 종류라는 추론을 하기 위해서는 텍소노미(Taxonomy) 기반의 계층적 분류가 필요하다. 텍소노미는 넓음–좁음(broader–narrower) 또는 일반화–특수화(generalization–specialization) 위계를 통해 범주를 조직하는 분류 방식으로, 더 일반/추상적인 개체는 상단에, 구체적인 개체는 하단에 위치한다. 위 2-4의 상품 그래프를 예시로 들면, Category 노드들을 SUBCATEGORY_OF 관계로 연결하여 계층적으로 구성하고 있다.
figure 2-5의 경우, 다중 카테고리를 사용하여 프로모션 정보와도 연결하고 있다. 즉, 분류체계를 사용하여 데이터의 표현력을 높이고, 엔티티 간의 의미적 유사도를 표준 텍소노미 메트릭(path similarity, Leacock–Chodorow, Wu and Palmer 등)을 적용하여 계산할 수 있게 된다.
4️⃣ KGs Using Ontologies for Multilevel Relationships
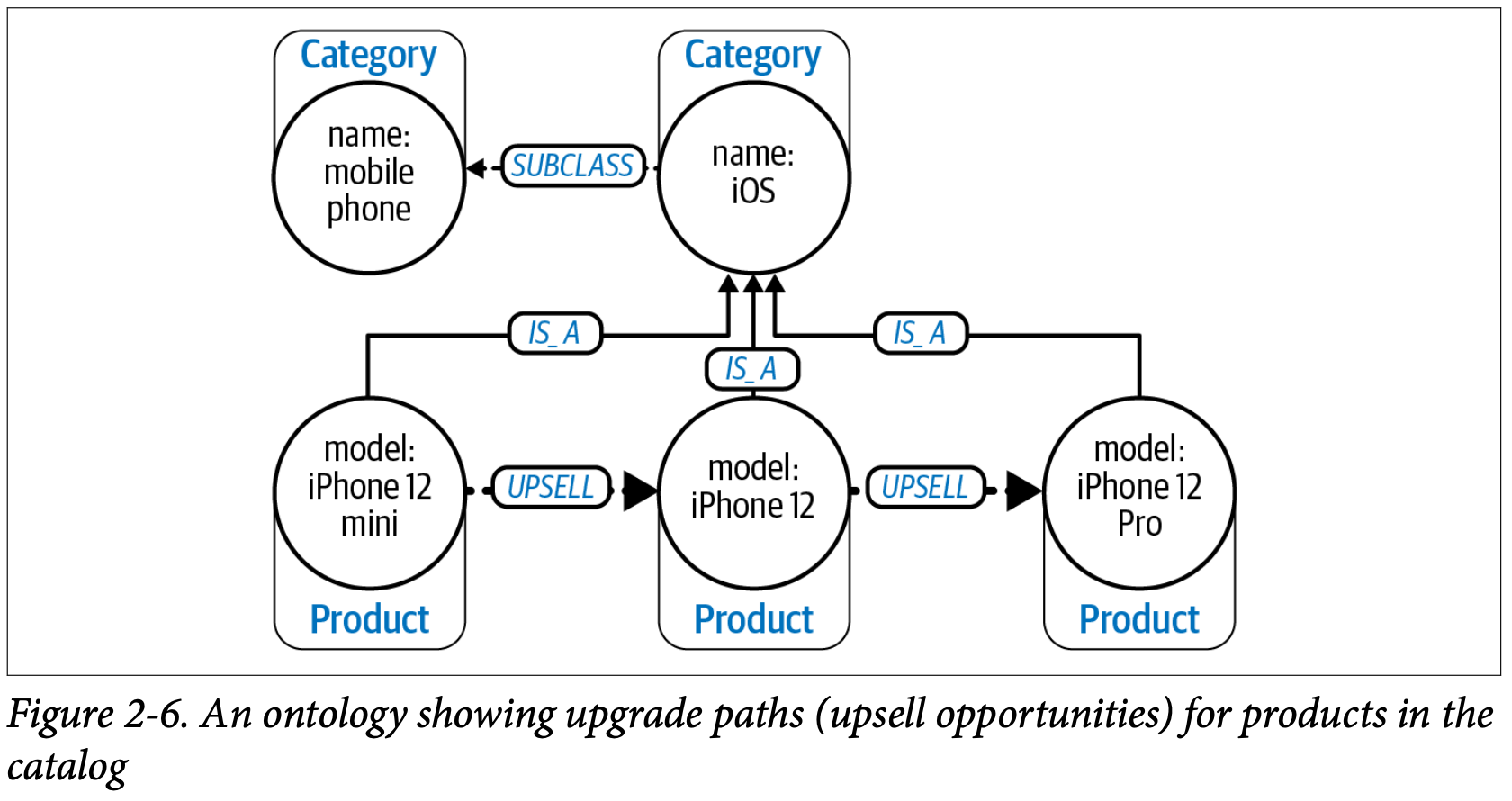
텍소노미(분류체계)를 적용하는 것보다 더 높은 수준의 조직 방법은 온톨로지를 활용하는 것이다. 텍소노미와 같이 온톨로지도 도메인의 타케고리와 관계들을 스키마를 통해 표현하는데, 차이점은 반드시 계층적으로 표현하지 않아도 된다는 점에서 더욱 풍부한 관계를 표현할 수 있다는 것이다.
figure2-6 예시를 보면, iPhone12는 IOS인 mobile phone이라는 카테고리에 포함되는데, UNSPELL이라는 관계를 통해 iPhone12 Pro를 추천할 수 있는 가능성이 생긴다. 즉, 단순히 위아래 관계(상위–하위)뿐 아니라 수평적 관계(horizontal, cross-cutting concerns)까지 탐색 가능한 형태라는 것이다. 다만, 온톨로지를 정교하게 구축할수록 복잡성이 커지는 한계가 있다. 그러나 이를 모듈 방식으로 설계하면, 단계별로 확장하고 관리할 수 있다는 장점이 있다.
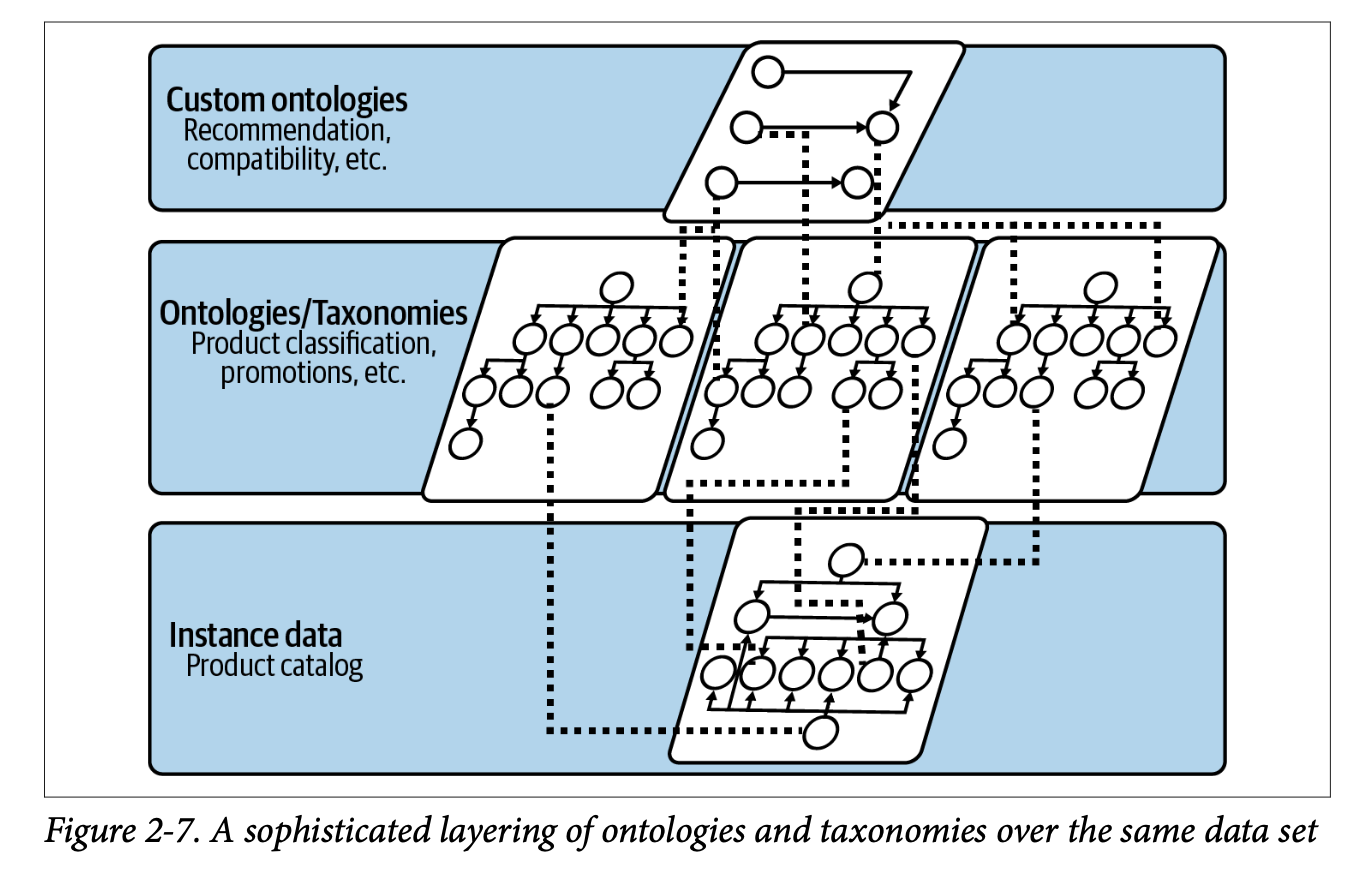
실제로 온톨로지는 여러 계층으로 나눠 설계할 수 있는데, 가장 아래에는 상품 목록과 같은 인스턴스 데이터가 있고, 그 위에는 상품 분류나 프로모션 정보를 담은 텍소노미/온톨로지가 있으며, 최상위에는 추천이나 호환성 같은 맞춤형 온톨로지가 위치한다. 각 계층은 독립적으로 활용할 수도 있고, 결합하여 더 복잡한 추론을 수행할 수도 있다.
단일 온톨로지를 이용하면 특정 제품군 내에서의 상호보완 관계만 추론할 수 있지만, 범도메인(cross-domain) 온톨로지를 적용하면 다양한 제품과 프로모션, 추천 전략까지 아우르는 폭넓은 reasoning이 가능하다. 이는 단순히 '어떤 기기가 서로 잘 어울리는가?'라는 질문을 넘어서 '원하는 것을 최적의 가격으로 어떻게 얻을 수 있는가?'라는 수준의 요구를 지원한다는 것이다.
결국 온톨로지는 지식을 기계가 읽고 활용할 수 있는 형태로 조직해 인간과 소프트웨어 에이전트가 더 정교한 작업을 수행하도록 돕는다. 예를 들어, 온라인 소매업체가 상품 계층 구조를 재고 관리 데이터와 연결한다면, 특정 상품이 품절되었을 때 대체 상품을 제안하거나 더 높은 마진을 남길 수 있는 제품을 추천하는 것이 가능해진다. 이러한 가치는 온톨로지를 통해 비즈니스 로직을 구조화하고 표준화하는 비교적 적은 비용으로 얻을 수 있다.
Which is the Best Organizing Principle for your KG?
지식그래프의 구성 원칙은 그래프로 표현하고자 하는 목적, 의도와 도메인의 특성을 고려해서 선정해야 한다. 한 가지 주의해야 할 점은, 처음부터 지나치게 구체화된 완벽한 모델을 만드는 것은 시간 소모적이며 비효율적이라는 것이다. 작업 과정에서 비즈니스 현실은 달라질 수도 있으며, 실제로 그렇게 구체적인 설계가 필요 없을 가능성도 있기 때문이다. 따라서 점진적이고 반복적인 접근법이 권장되며(Agile 방법론), 초기에는 단순한 Property graph나 텍사노미 등으로 접근하고 필요한 경우에 온톨로지를 설계해도 된다는 것이다.
Organizing Principles: Standards Versus Create your own
온톨로지를 설계한다고 했을 때, 기존의 설계를 활용할 지, 혹은 특정 상황에 맞는 새로운 온톨로지를 설계할 지 결정해야 한다. 다음은 리스트는 가장 널리 사용되는 온톨로지의 일부 예시이다.
- SNOMED CT: 의료 분야의 문서와 리포트 도메인 온톨로지
- LCC(Library of Congress Classification): 미국 의회 도서관의 학술 온톨로지
- FIBO(Financial Industry Business Ontology): 금융과 비즈니스 분야의 온톨로지
- Schema.org: 웹에서 표준으로 사용하기 위한 목적으로 만든 온톨로지
- DCMI(Dublin Core Metadata Initiative): 웹 리소스 등을 설명하기 위한 목적으로 만든 온톨로지
만약 다루고자 하는 도메인이 위 분야에 해당한다면, 새로운 것을 만들지 않고 채택하는 편이 상호 운영성(interoperability) 측면에서 이점을 갖는다. 반면, 기존의 표준 온톨로지가 없거나 완전하게 적합하지 않다면 기존의 것을 참고해서 발전시키거나 새롭게 구축해야 한다. 이때 방법은 우선 자연어로 의미를 서술하는 방법이 있는데, 이는 기계가 이해할 수 없다는 점에서 불일치나 오류가 발생할 가능성이 높다.
다른 방법으로는 RDF Schema, OWL(Web Ontology Language), SKOS(Simple Knowledge Organization System) 같은 표준 어휘를 활용해 온톨로지를 공식적으로 정의하는 것이다. 이 언어들은 단순한 분류와 관계 정의부터 복잡한 클래스와 추론 구조까지 다양한 수준의 표현력을 제공한다. 표준 어휘를 사용하면 소프트웨어가 자동으로 인식해서 추론을 할 수 있다는 장점이 있는데, 예를 들어 OWL을 사용하면 추론기를 통해 원래 데이터에 명시적으로 표현되지 않은 사실을 도출해낼 수 있다. 그러나 비즈니스 환경은 지속적으로 변화하기 때문에, 결국 표준과 맞춤형 확장의 혼합 전략을 통한 접근법이 현실적이라고 한다.
Essential Characteristics of a KG
지식그래프를 구축하는데 반드시 특정 기술이 필요한 것은 아니며, 이 교안에서는 property graph를 중심으로 다룬다. 또한 좋은 그래프는 유연하고 유지 관리가 용이해야 한다. 그래프의 최신성을 반영하기 위해서 끊임없는 수정을 통해 풍부해지는 과정을 거치기 때문이다.
한편, RDF(Resource Description Framework)는 종종 지식그래프 구현의 핵심 차별 요소로 소개되며 지식그래프 개념과 혼동되는 경우가 많다. 그러나 RDF는 데이터를 교환하기 위한 형식으로, 저장이나 쿼리를 최적화하기 위한 모델은 아니다. 앞서 필자는 RDF 그래프라는 표현을 사용했는데, 이는 RDF 트리플(주어–술어–목적어) 구조로 데이터를 표현하는 그래프를 의미하며, Property Graph와 달리 관계에 직접 속성을 부여하기 어렵다는 특징을 갖는다. 즉, 지식그래프를 구축하기 위해 RDF 트리플스토어가 반드시 필요한 것은 아니며, 최근에는 활용 측면에서는 노드와 관계에 속성을 직접 부여할 수 있는 labeled property graph가 더 직관적이고 효율적일 수 있다는 추세가 강하다고 한다.
확실히 LLM 기반으로 그래프를 구축할 때는 RDF기반의 그래프(편의상 표준 어휘를 사용하는 케이스를 포함해서 'RDF기반의 그래프'라고 사용하겠다)보다 property graph가 구축상 이점이 있는 것 같다. 다만 여전히 의문인 점은 구축한 그래프를 활용하는 단계에서도 효율적/정확도가 높은가?라는 부분인데, 아직 명확한 답이 있는 것 같진 않다.
