
스터디 책: Building Knowledge Graphs
chapter3는 neo4j를 활용하여 실제 데이터를 입력하고 쿼리하는 방법을 다룬다. neo4j는 desktop 버전과 클라우드 기반으로 사용하는 neo4j aura가 있는데, 이번 실습은 desktop을 기준으로 한다.
설치 없이 웹에서 테스트 하는 aura를 사용했다.
aura의 사용법도 간단한데, 이 링크로 접속해서 몇 가지 정보를 입력하면 Free instance가 생성되고 아래와 같은 화면이 나온다. 사이드 바에 있는 Query 탭을 클릭하면 입력창이 나오고, 그 입력창에 교안의 쿼리를 치면서 실습을 시작하면 된다.
The Cypher Query Language
Cypher는 Neo4j에서 만든 선언적(declarative) 패턴 매칭 기반 그래프 질의 언어로, 현재 ISO에서 GQL(Graph Query Language) 표준 제정이 진행 중이다. Cypher의 핵심 목표는 사람이 이해하기 쉽고 표현력이 풍부한 언어를 만드는 것으로, 사람들이 상자와 화살표로 다이어그램을 그리는 데 익숙하듯, 그래프 질의도 시각적이고 직관적으로 표현될 수 있어야 한다는 점에 착안했다고 한다.
🧩 CREATE, MATCH
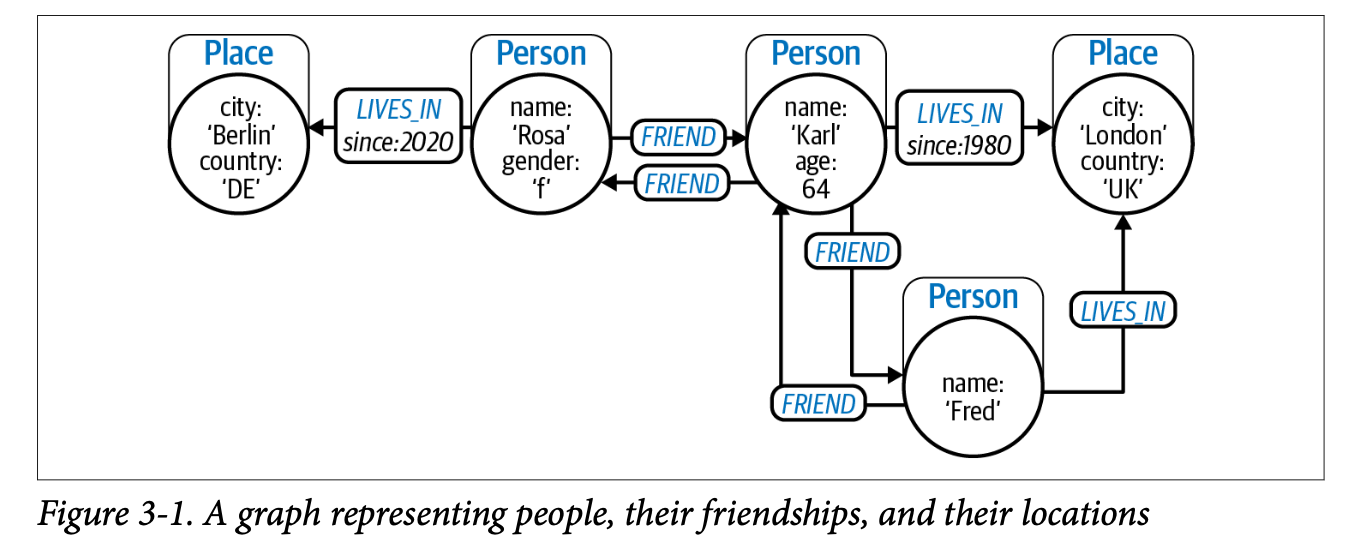
Chapter1에서 다룬 이 그래프를 예시로 Cypher 쿼리 실습을 진행한다. 이때 'Rosa'라는 이름을 가진 PERSON이 'Berlin'이라는 도시의 Place에 산다는 걸 표현하면 (:Person {name:'Rosa'})- [:LIVES_IN]->(:Place {city:'Berlin', country:'DE'})와 같다. 각각의 노드는 () 안에 표현하고 그 안에 레이블을 적고 속성들은 {}안에 key-value 형태로 표현한다. 또한 관계는 []로 적고 각 노드의 방향성을 나타내는 노드의 가운데 적어주면 된다.
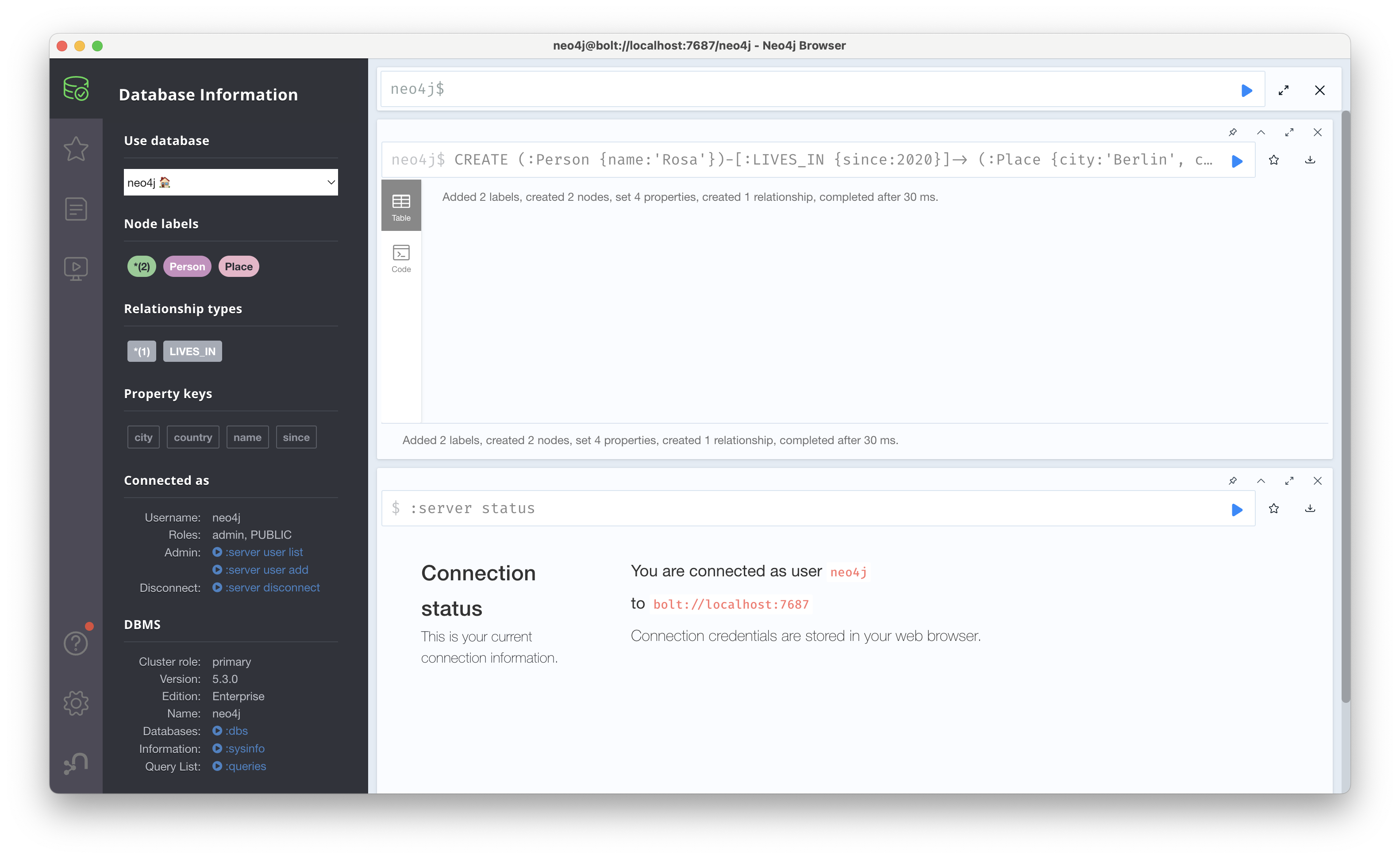
이렇게 구성한 subgraph는 CREATE (:Person {name:'Rosa'})-[:LIVES_IN {since:2020}]-> (:Place {city:'Berlin', country:'DE'})를 통해 생성할 수 있고, 아래와 같이 좌측 Database Information에 각각 Nodes와 Relationships가 생성된 걸 확인할 수 있다.
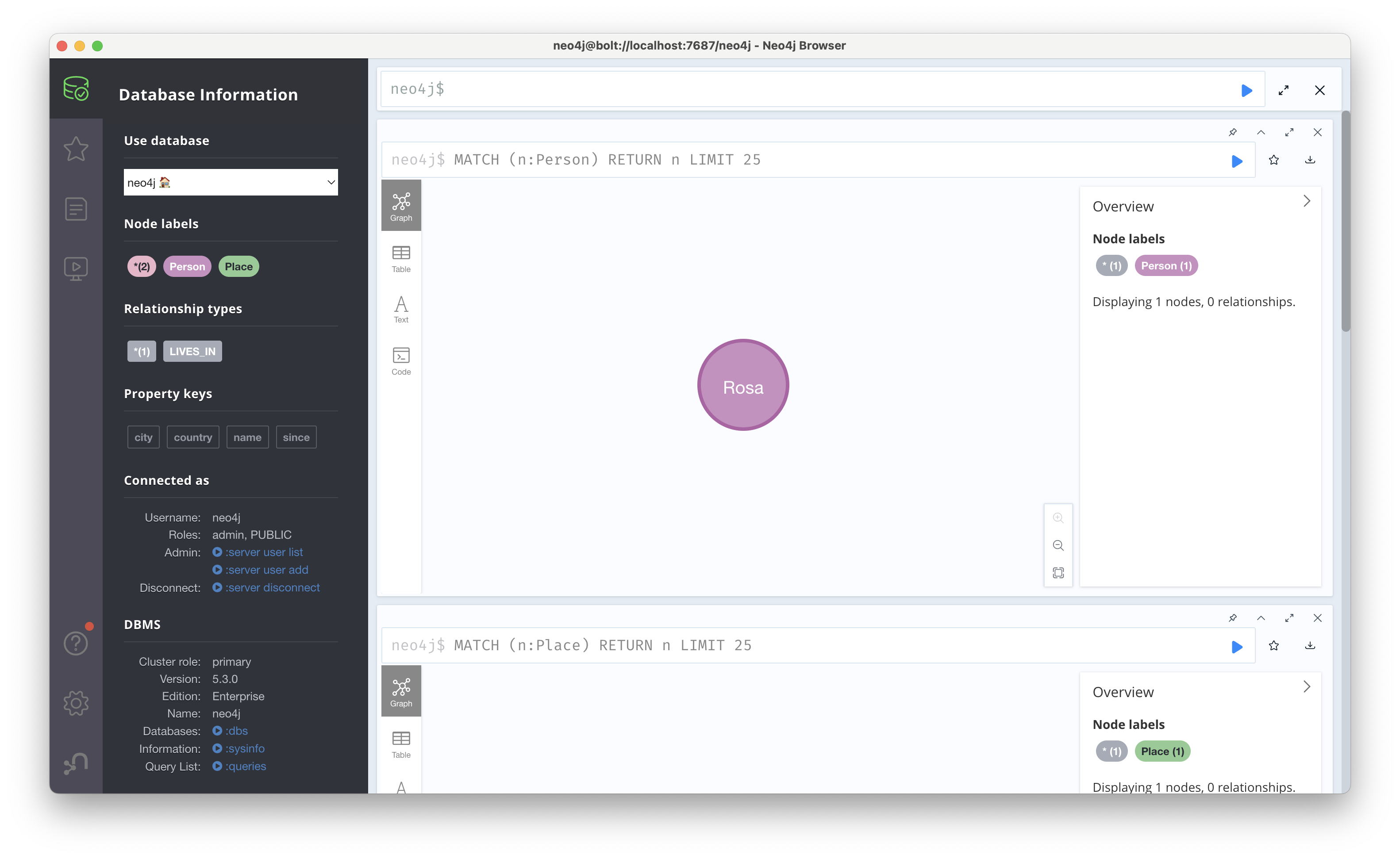
데이터를 로드한 뒤에는 Cypher의 MATCH 키워드를 사용해 질의를 수행한다. MATCH는 사용자가 정의한 패턴을 실제 지식 그래프와 비교하는 역할을 한다. 예컨대 MATCH (n:Person) RETURN n은 Person이라는 레이블을 가진 모든 노드를 n이라는 변수에 할당해서 출력한다는 의미이다. 쿼리 결과를 그래프로 보면 다음과 같이 Rosa 노드가 출력된다. 현재는 노드가 하나 뿐이라 상관없지만, 데이터 사이즈가 커지면 쿼리 시간이 길어질 수 있으므로 LIMIT를 추가해서 제한을 두는 것이 좋다.
🧩 DELETE, MERGE
CREATE는 항상 새로운 데이터를 생성하기 때문에 동일한 쿼리를 2번 생성한다면 동일한 노드가 2개 생기게 된다. 따라서 생성한 노드와 관계를 삭제하기 위해서는 DELETE혹은 DETACH DELETE를 사용하면 된다.
MATCH (n) DELETE n;: 매칭된 모든 노드 삭제. 노드에 연결된 관계가 남아 있으면 에러 발생
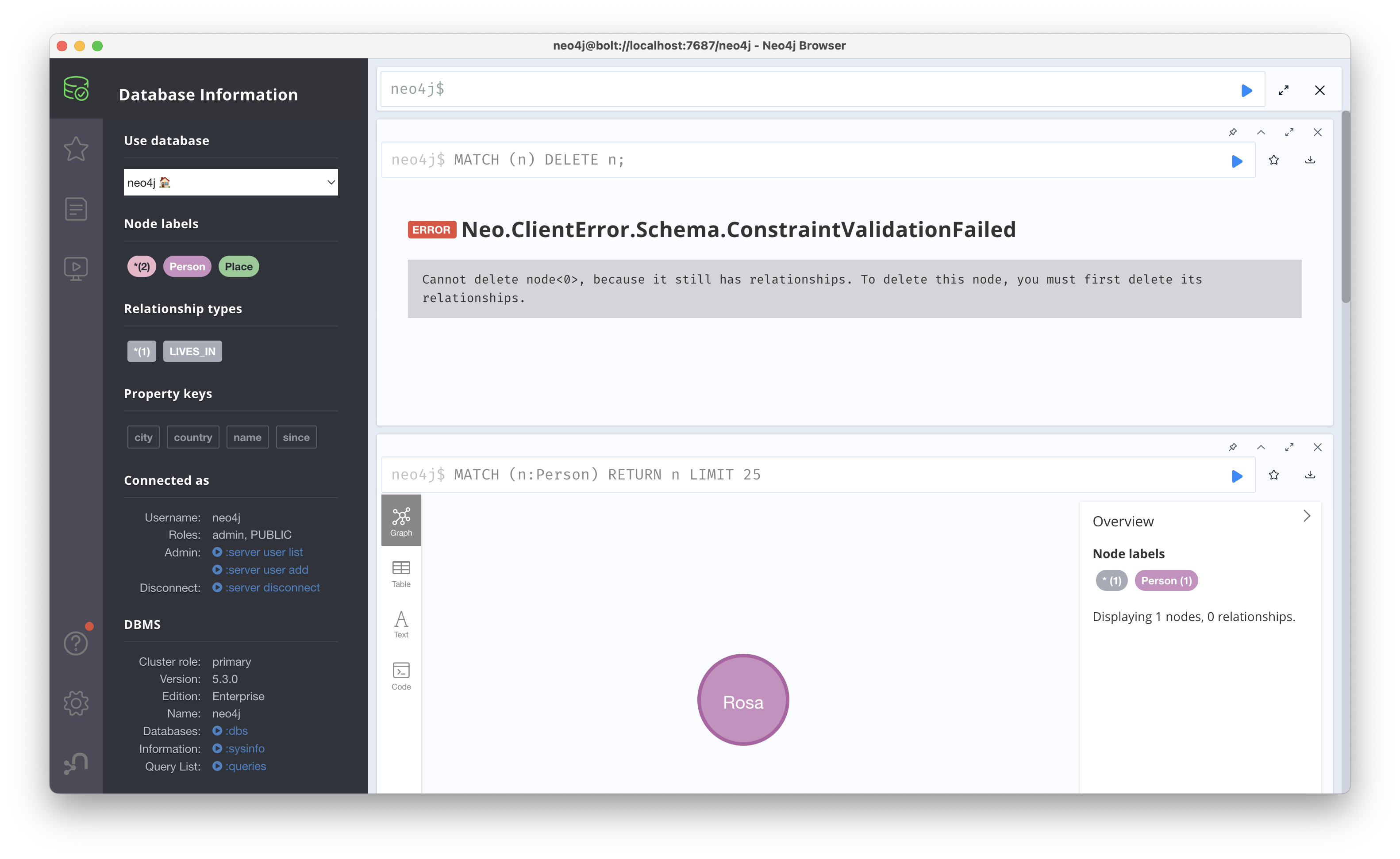
MATCH (n) DETACH DELETE n;: 모든 노드와 관계를 한번에 삭제
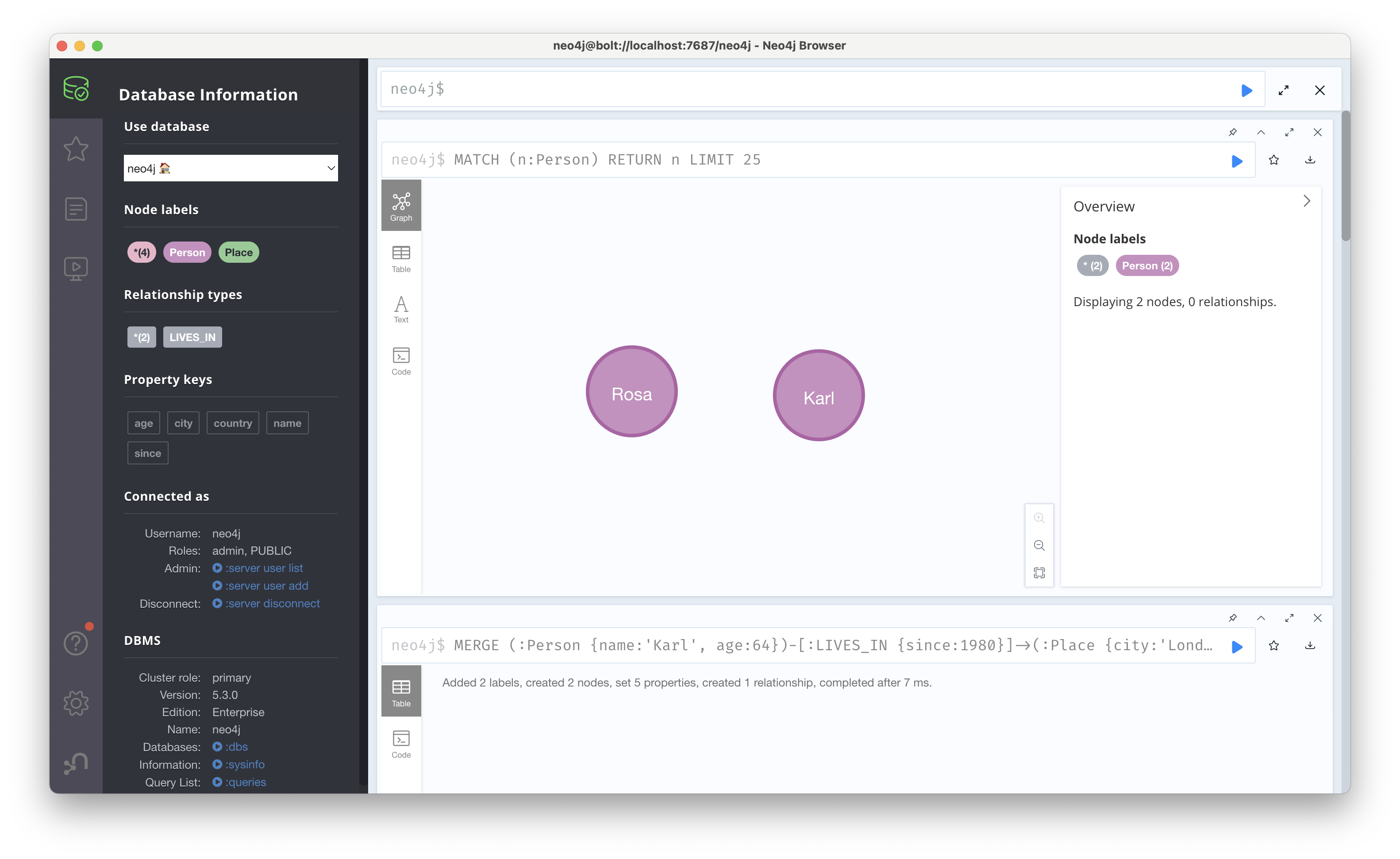
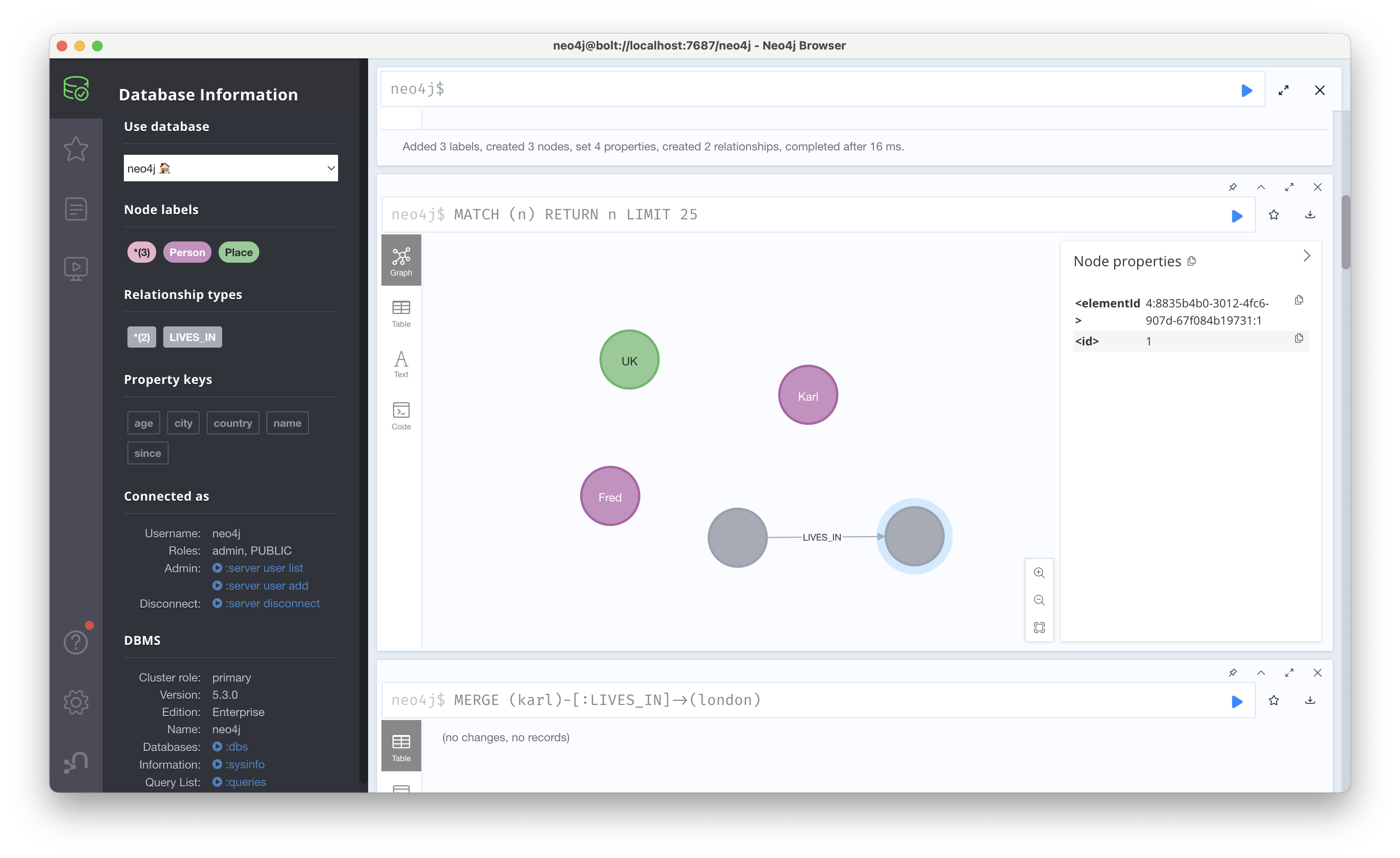
그러나 매번 중복되는 노드와 관계를 찾아서 삭제해줄 순 없다. 따라서 MERGE를 통해 지정된 패턴 전체가 존재하지 않을 때만 레코드를 삽입하면 된다. 우선MERGE (:Person{name:'Karl', age:64})-[:LIVES_IN {since:1980}]->(:Place {city:'London', country:'UK'})를 실행하면 Karl에 해당 노드가 없었기 때문에 CREATE와 동일하게 동작하고, 아래와 같이 새로운 노드가 추가된다.
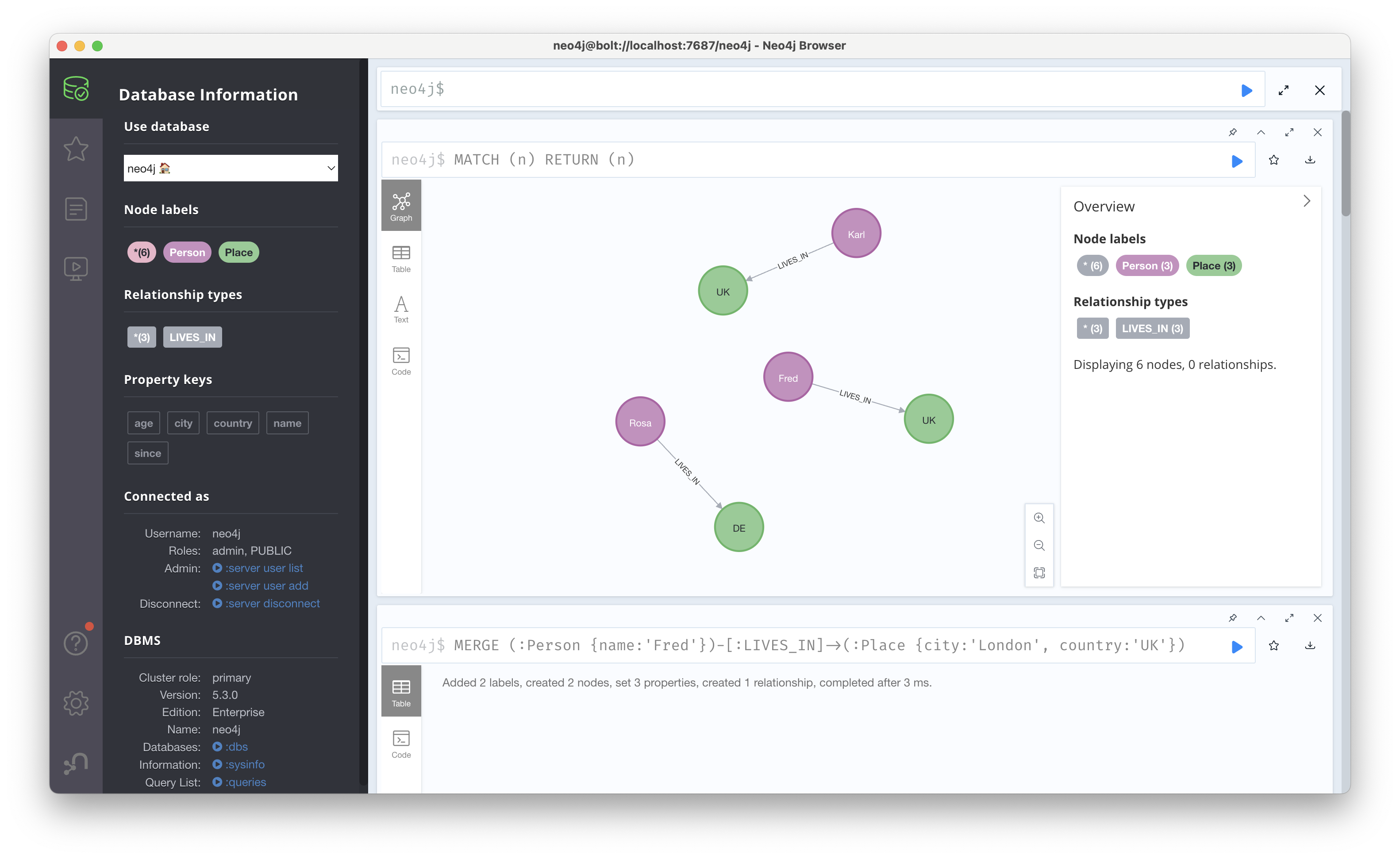
이제 새로운 Fred라는 UK에 사는 인물을 추가해보자. MERGE (:Person {name:'Fred'})-[:LIVES_IN]->(:Place {city:'London', country:'UK'})를 실행하면 기존의 London 노드와 연결되어야 하지만, 실제로는 아래와 같이 각각의 London 노드가 생성된다. 이는 MERGE의 특성 때문인데, 완벽하게 일치하는 노드와 관계를 다시 생성하려는 경우에는 생성되지 않지만, 그렇지 않는, 지금과 같이 Fred라는 새로운 인물이 관계를 표현하는 경우에는 London이 중복된다고 해도 새로운 노드로 생성한다. 실제로 위에서 실행한 MERGE ~~ 코드를 다시 실행하면, CREATE를 사용했을 때와 달리 동일한 노드가 중복해서 생성되진 않는다.
그럼 우리가 원하는 것 같이 중복된 'London'이라는 노드가 하나만 생기게 하려면 어떻게 해야 할까? DETACH DELETE로 깔끔하게 지운뒤 다음 쿼리를 한번에 실행하면 된다.
MERGE (london:Place {city:'London', country:'UK'})
MERGE (fred:Person {name:'Fred'})
MERGE (fred)-[:LIVES_IN]->(london)
MERGE (karl:Person {name:'Karl'})
MERGE (karl)-[:LIVES_IN]->(london)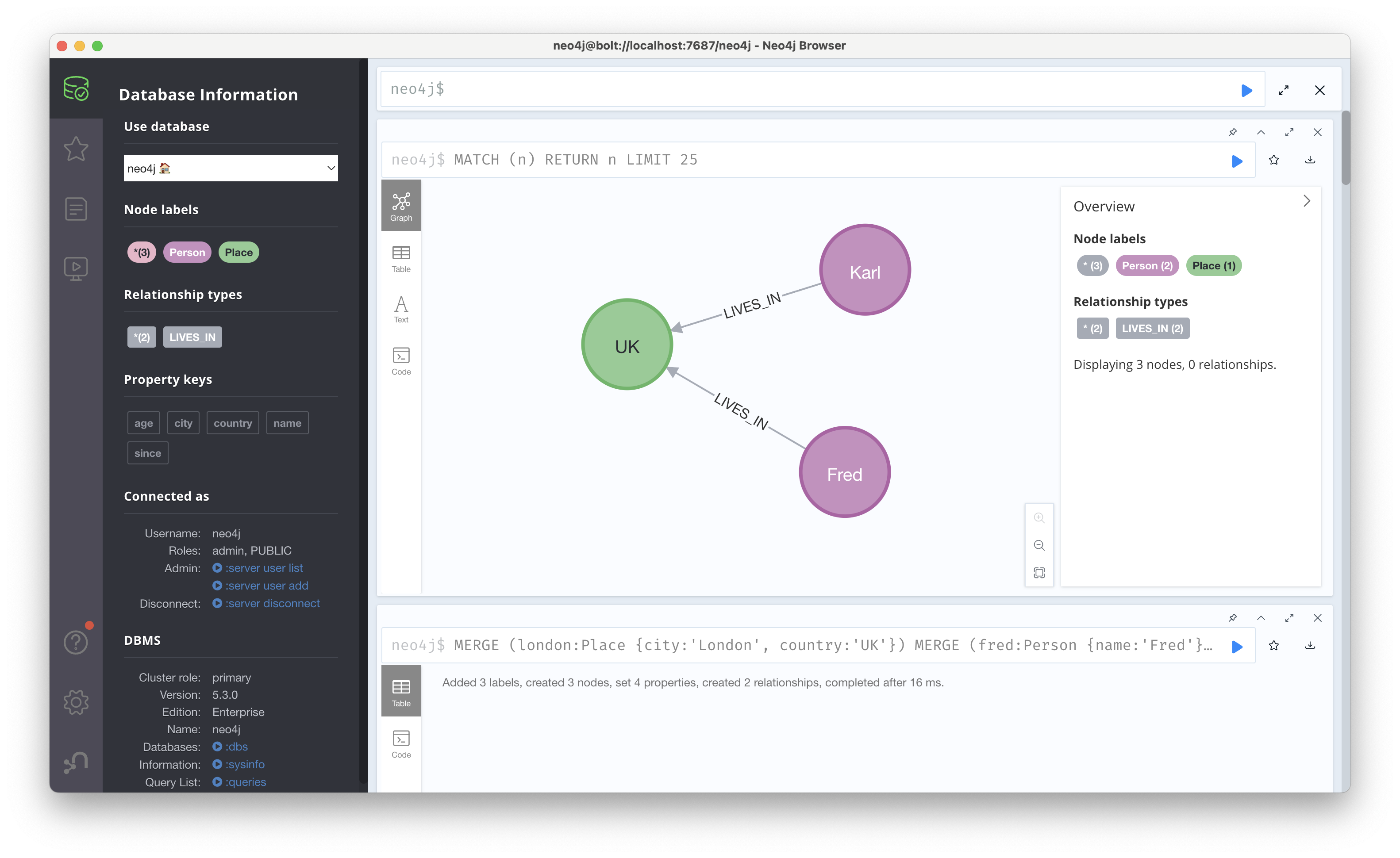
🚨 존재하는 노드에 추가로 연결하려면?
처음이 위 코드를 하나씩 실행했더니 이런식으로 새로운 빈 노드가 생기고 관계를 정의했다. 이유를 ChatGPT에 물어보니, 동일한 트렌젝션(?)에서 실행해야 동일한 노드에 대한 인식이 가능하다고 한다. 그럼 만약에 새로운 사람이 생기고 그 사람이 London에 산다고 연결해주려면, 어떻게 해야하지? 라는 의문이 들었다.지금까지 아는 바로는, 아래와 같이 존재하는 노드에 대해서 다시 변수를 정의한 뒤, 연결해주면 된다는 것이다. 다만, 만약 기존 노드의 속성이 엄청 많다면, 이걸 다시 다 정의해줘야 하나? 거기까진 아직 모르겠다
// 기존의 노드를 변수로 정의 MERGE (berlin:Place {city:'Berlin', country:'DE'}) // 새로운 Person 노드 Cathy 생성 MERGE (cathy:Person {name:'Cathy'}) // Cathy가 Berlin에 거주하도록 관계 생성 MERGE (cathy)-[:LIVES_IN]->(berlin)
🧩 SET, REMOVE
만약 생성한 노드의 정보를 수정하거나 삭제하고 싶다면 SET과 REMOVE를 사용하면 된다.
-
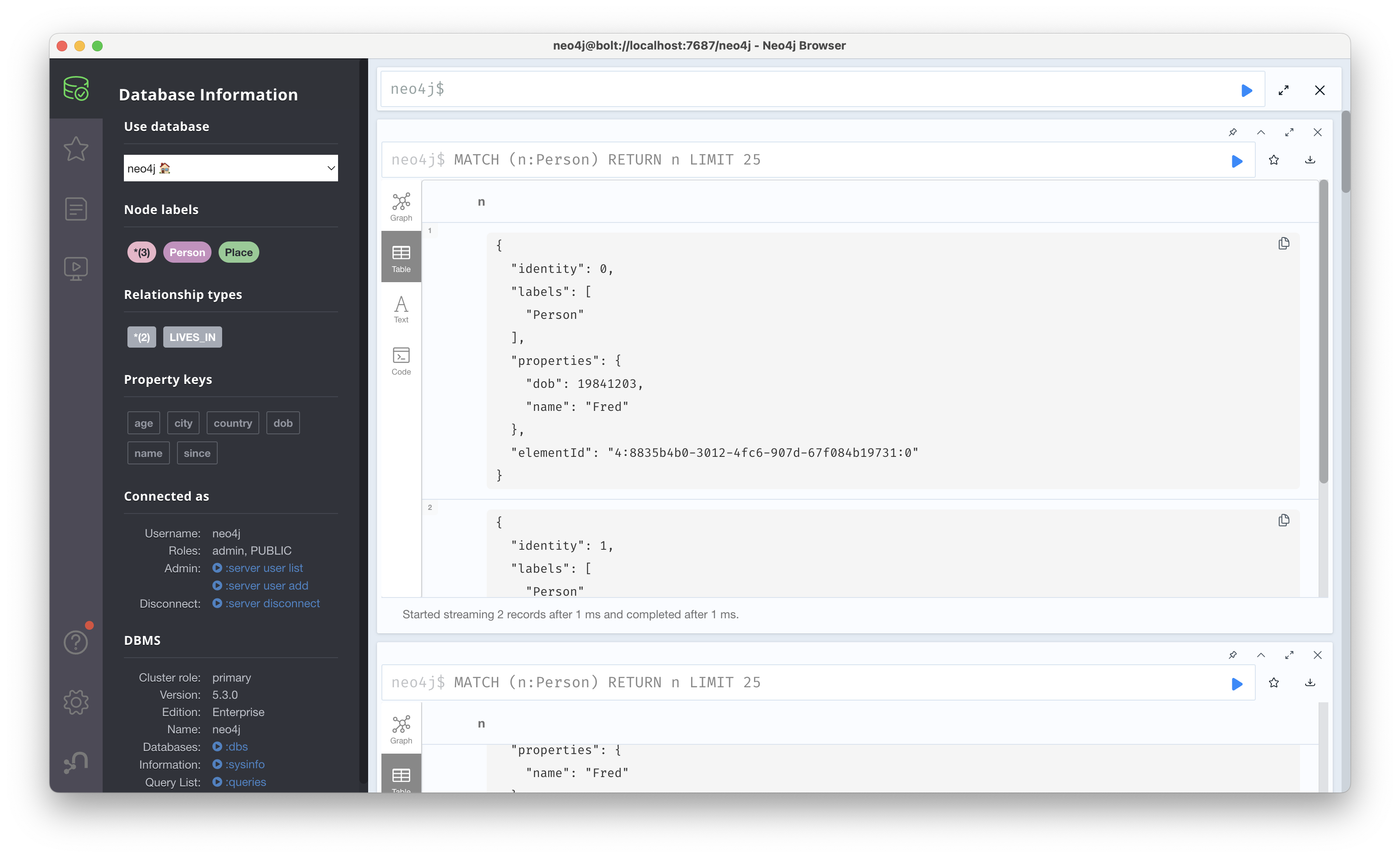
MATCH (p:Person) WHERE p.name = 'Fred' SET p.dob = 19841203: Fred의 속성 중 dob(date of birth)를 추가하는 쿼리이다. 추가하면 아래와 같이 Fred노드에 속성이 추가된 것을 확인할 수 있다.
-
MATCH (p:Person) WHERE p.name = 'Fred' REMOVE p.dob: 노드의 속성이나 레이블은 이렇게 삭제하면 된다.
🧩 WHERE
WHERE는 쿼리할 때 조건을 주기 위해서 사용하는 구문이다. 아래 예시를 통해 사용 방법을 이해할 수 있다.
- 특정 문자로 시작하는 문자 찾기:
MATCH (n:Person) WHERE n.name STARTS WITH 'Ka' RETURN n - 관계 조건:
MATCH (p:Person) WHERE NOT (p)-[:KNOWS]->(:Person {name:'Karl'}) RETURN p - 리스트 포함 여부:
MATCH (n:Person) WHERE n.name IN ['Rosa','Karl'] RETURN n - 복합 절:
MATCH (p:Person)-[:LIVES_IN]->(:Place {city:'Berlin'}) MATCH (p)-[:FRIEND*1..2]->(f:Person) WHERE f <> p RETURN f
🧩 CALL (APOC Procedure library)
Neo4j에서는 함수와 procedure(라이브러리를 사용하거나 사용자가 정의할 수 있음)를 사용하여 지식그래프를 조작이 가능한데, procedure는 특정 작업을 수행하는 명령 블록으로, CALL 구문을 사용해 여러 출력 값을 반환할 수 있다. 예를 들어, CALL db.schema.visualization()는 그래프에 존재하는 노드와 관계, 속성 구조를 시각적으로 보여준다.
APOC(Awesome Procedures On Cypher)는 이런 procedure를 모은 라이브러리로, 반복적이거나 복잡한 작업을 간단하게 수행할 수 있다. 설치 방법은 Project를 선택하면 오른쪽에 Plugins 탭이 나오는데, 여기서 APOC를 선택하고 Install and Restart를 클릭하면 끝이다.
예를 들어, apoc.atomic.concat 프로시저는 특정 노드의 속성 문자열을 연결하는 기능을 제공하는데, 아래 쿼리와 같이 ‘Fred’에 ‘dy’를 연결해 ‘Freddy’로 바꾸는 작업을 수행할 수 있다.
MATCH (p:Person {name:'Fred'})
CALL apoc.atomic.concat(p,"name",
'dy')
YIELD oldValue, newValue
RETURN oldValue, newValue;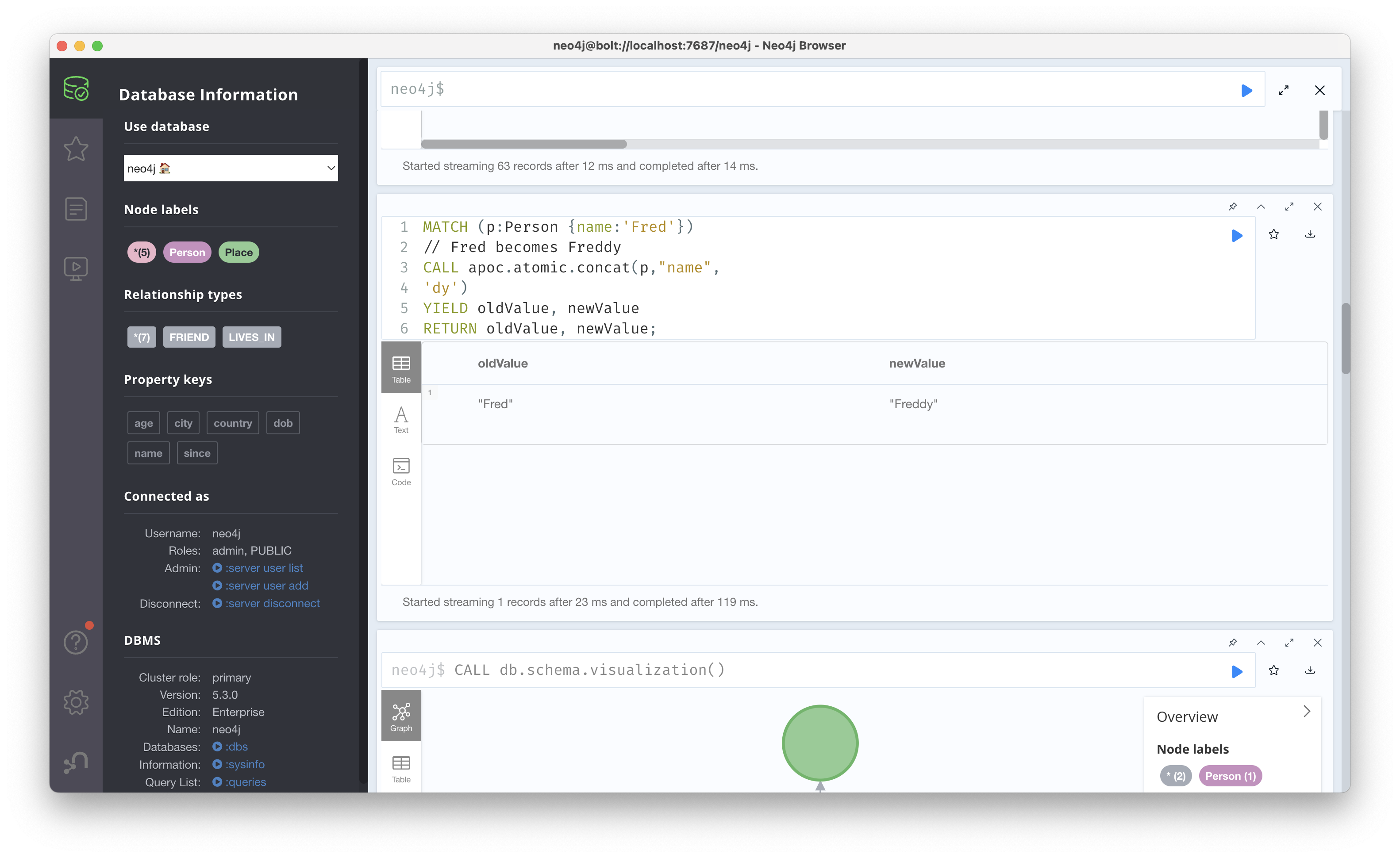
만약 RETURN을 통해 사용할 경우, CALL 없이 쿼리 내에서 바로 RETURN apoc.date.convert(datetime().epochSeconds, "seconds", "days")와 같이 사용할 수 있다.
🧩 EXPLAIN, PROFILE
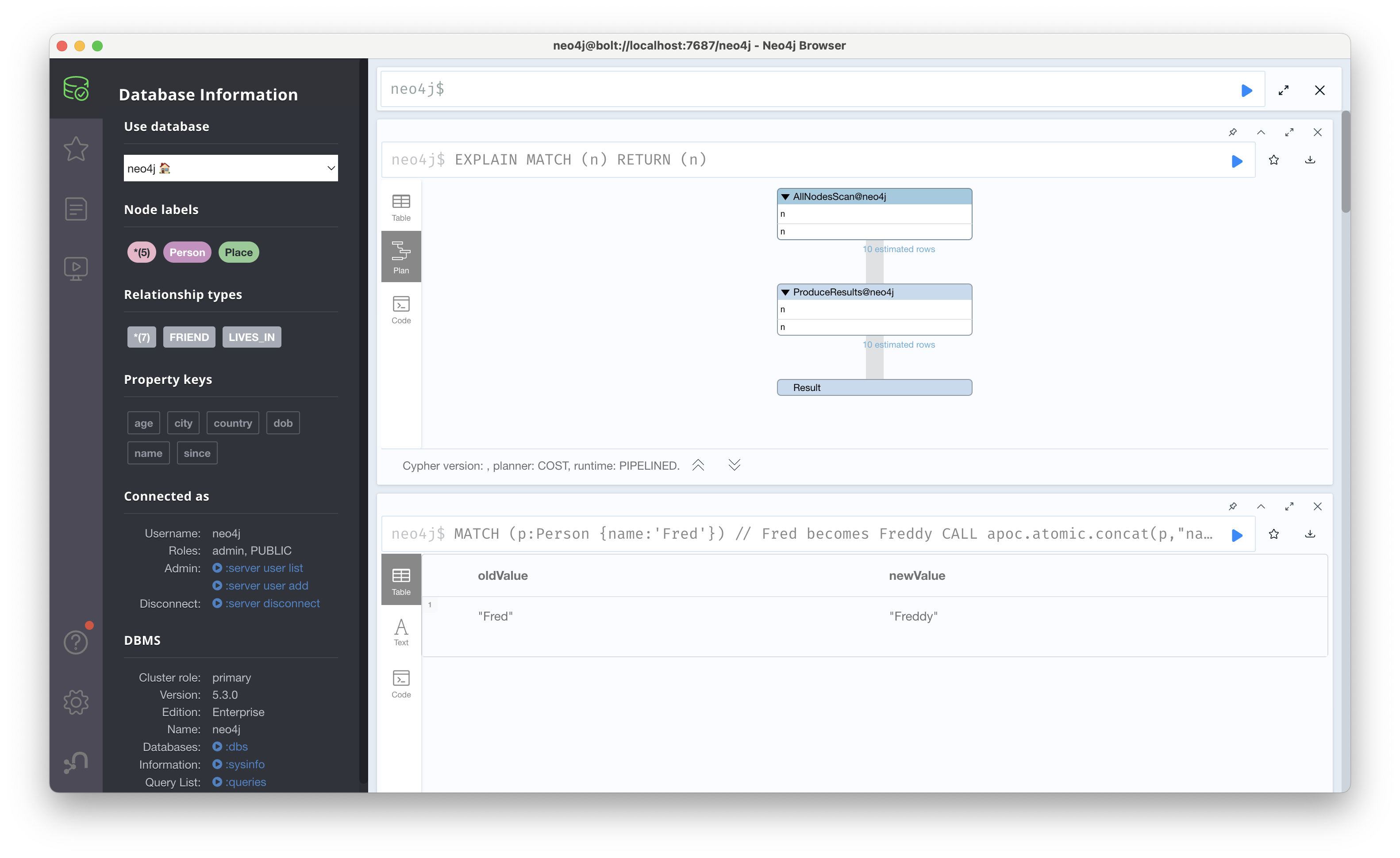
EXPLAIN은 쿼리를 실제로 실행하지 않고, 쿼리 플랜을 시각적으로 보여준다. 즉, 데이터베이스가 쿼리를 어떻게 처리할지 미리 확인할 수 있으며, 이를 통해 불필요하게 많은 데이터(DB hits)가 쿼리를 통해 흐르는 것을 사전에 파악할 수 있고, 특히 데이터 사이즈가 큰 경우 유용하게 사용할 수 있다.
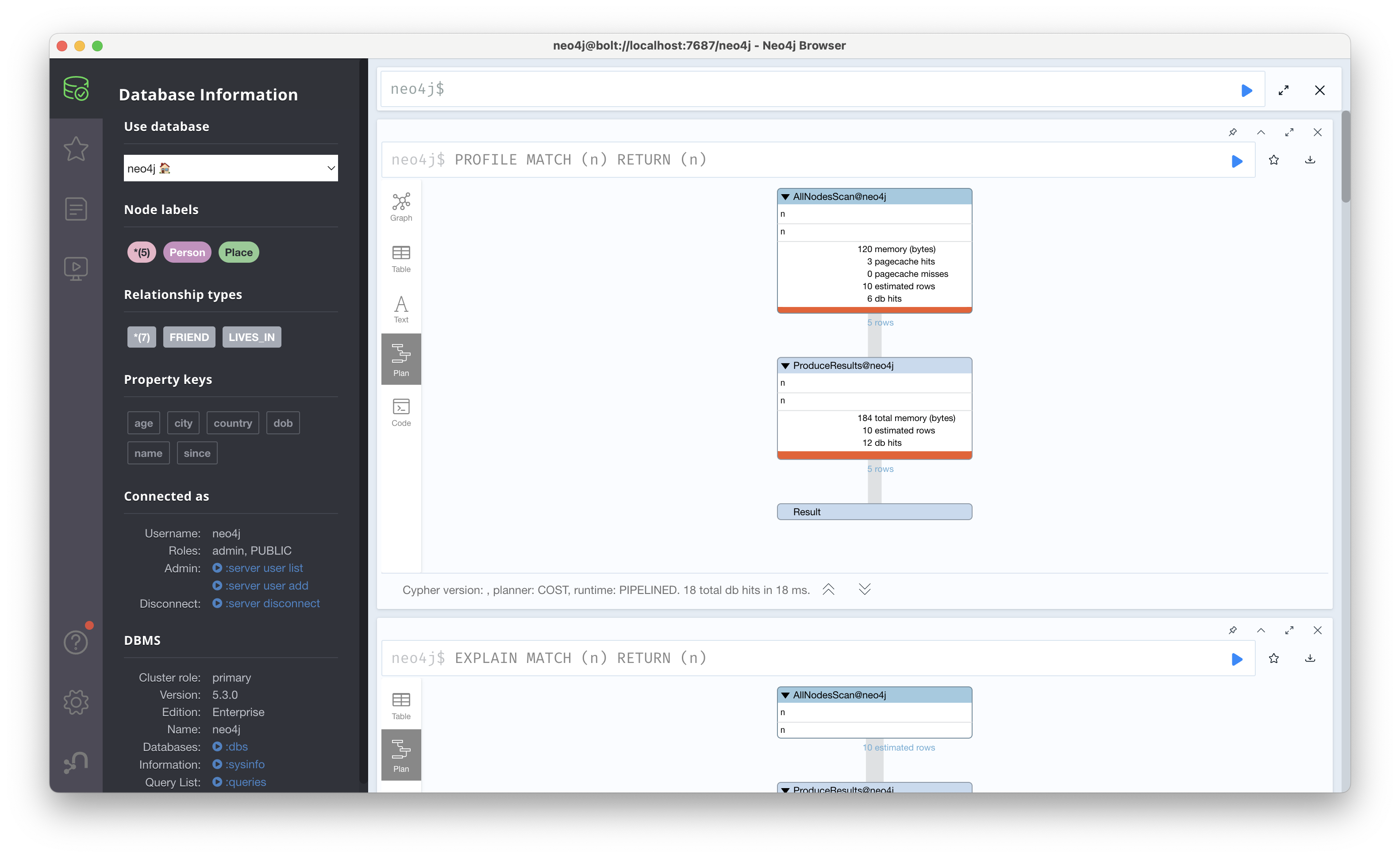
PROFILE은 쿼리를 실제로 실행하면서 그 동작을 분석한 결과를 보여준다. 실행 중인 쿼리가 실제 그래프에서 어떻게 처리되는지 확인할 수 있고 각 연산자가 소비하는 시간과 DB hits를 보여준다. 이를 통해 쿼리 성능 병목 지점을 찾고, 필요 시 쿼리를 리팩토링하거나 인덱스를 추가하여 성능을 개선할 수 있다.
1️⃣ Graph Local Queries
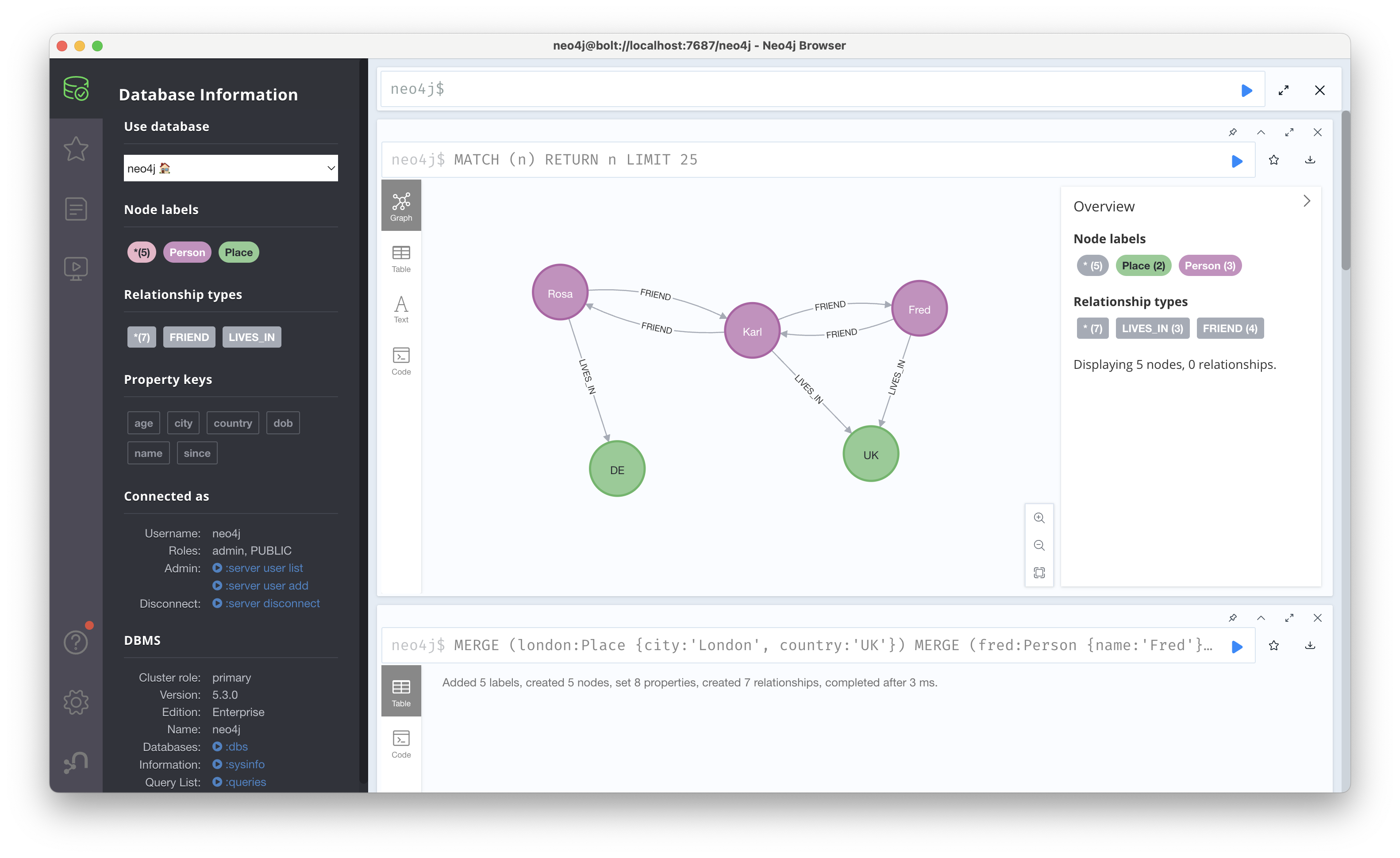
MERGE (london:Place {city:'London', country:'UK'})
MERGE (fred:Person {name:'Fred'})
MERGE (fred)-[:LIVES_IN]->(london)
MERGE (karl:Person {name:'Karl'})
MERGE (karl)-[:LIVES_IN]->(london)
MERGE (rosa:Person {name:'Rosa'})
MERGE (berlin:Place {city:'Berlin', country:'DE'})
MERGE (rosa)-[:LIVES_IN {since:2020}]->(berlin)
MERGE (fred)-[:FRIEND]->(karl)
MERGE (karl)-[:FRIEND]->(fred)
MERGE (karl)-[:FRIEND]->(rosa)
MERGE (rosa)-[:FRIEND]->(karl)이제 위 쿼리를 통해 생성한 그래프를 쿼리하는 내용을 다뤄보겠다. local query는 지식그래프의 일부 특정 노드나 관계에 바인딩하여 실행하는 쿼리로, 그래프 전체를 탐색하는 것이 아니라 특정 노드나 관계를 기준으로 주변 정보만 조회하는 방식이다. 예를 들어, '베를린에 사는 사람들은 누가 있을까?'에 대해서는 MATCH (p:Person)-[:LIVES_IN]->(:Place {city:'Berlin', country:'DE'}) RETURN p와 같이 쿼리할 수 있다.
local query는 경로의 길이를 조건으로 줄 수도 있다. 예를 들어, Rosa의 친구의 친구를 쿼리하고 싶다면 MATCH (:Person {name:'Rosa'})-[:FRIEND*2..2]->(fof:Person) RETURN fof와 같이 쿼리할 수 있다. 그러나 이 쿼리는 Rosa도 함께 포함하게 되므로 MATCH (rosa:Person {name:'Rosa'})-[:FRIEND*2..2]->(fof:Person) WHERE rosa <> fof RETURN fof과 같이 WHERE절을 추가해서 결과를 제한할 수 있다. 이때 <>의 의미는 시작 노드(rosa)와 fof가 같은 노드가 되지 않도록 한다는 의미이다.
graph local query는 탐색 속도가 빨라서 실시간 쿼리에도 적합하고, 반복적 재귀 JOIN도 RDB대비 효율적이라는 장점이 있다.
2️⃣ Graph Global Queries
global query란 특정 노드나 관계에 한정하지 않고 그래프 전체를 대상으로 하는 쿼리를 의미한다. 예를 들어, 가장 많은 사람이 사는 도시를 찾기 위해서 MATCH (p:Place)<-[l:LIVES_IN]-(:Person) RETURN p AS place, count(l) AS rels ORDER BY rels DESC와 같이 LIVES_IN으로 연결된 관계에서 가장 개수가 많은 도시를 찾는 쿼리 등이 해당한다. 통계나 집계 등의 목적으로 사용되며, 'count(), avg(), max(), min(), sum()' 등의 연산자가 주로 사용된다는 특징이 있다.
한편, 그래프가 크면 탐색 범위가 넓기 때문에 명시적으로 레이블과 관계를 지정해야 쿼리의 효율성이 높아진다. 예를 들어 MATCH (p:Place)<-[l:LIVES_IN]-(:Person) RETURN p, count(l)와 같은 쿼리에서 (:Person)을 쓰지않고 빈칸으로 두면 모든 노드를 대상으로 LIVES_IN 관계가 성립하는지 확인해야 해서 쿼리의 효율성이 매우 떨어진다. 관계를 명시하는 것도 이와 같은 이유로, 그래프의 구조를 알고 있다면 쿼리에 반드시 명시해주는 것이 권장된다고 한다.
정리하면, local query와 global query는 구조는 비슷하지만, global이 더 넓은 범위를 다루고 합, 정렬 등과 같은 통계적 연산을 수행한다는 차이가 있다.
Neo4j Internals
Neo4j를 사용함에 있어 동작 원리를 데이터베이스 전문가만큼 알 필요는 없지만, 약간의 지식을 갖고 있는 것이 유리하다고 한다. 그래프 DB의 주요 동작 원리는 크게 (1) 데이터 쿼리(빠르고 효율적인 탐색을 목표로 함)와 (2) 데이터 저장(안전성과 ACID 트렌젝션 보장)으로 구분된다.
1️⃣ Query Processing
쿼리의 효율성을 높이기 위해서는 한 노드에서 다른 노드로 이동하는 과정, 즉 traversal을 빠르고 효율적으로 수행해야 한다. Neo4j는 이를 위해 그래프의 구조(노드와 관계)와 속성을 따로 저장한다고 한다.
- 그래프 구조: 노드와 관계를 다시 분리해서 저장하고 고정된 길이로 저장됨. 각 노드는 연결된 관계들의 시작점을 알고 있고 각 관계는 출발/도착 노드를 알고 있으므로 별도의 인덱스가 필요 없이 바로 다음 노드로 이동할 수 있어 탐색이 빠름(Index-free adjacency). 탐색 시간복잡도는 O(1)
- 속성(property): 다양한 타입을 지원해야 하므로 별도의 리스트 구조로 저장. 읽을 때는 속성의 개수에 따라 시간이 늘어나는 O(N) 특성을 가지고 쓸때는 O(1)
따라서 성능을 높이려면 속성보다 그래프 구조를 우선 탐색한 뒤 필요한 경우에만 속성을 조회하는 것이 바람직하다.
또한 성능을 좌우하는 중요한 요소는 하드웨어인데, 속성이 메모리에 올라와 있으면 접근 비용이 줄어들기 때문에 충분한 RAM을 확보해 전체 그래프가 메모리에 올라오도록 하는 것이 이상적이라고 한다. HDD 같은 느린 저장장치는 피하고,SSD와 넉넉한 메모리를 사용하는 것이 필수적이다.
2️⃣ ACID Transactions
다른 데이터베이스처럼 neo4j도 트랜젝션 기반의 입력을 사용한다. 이때 트랜잭션(Transaction)이란 데이터베이스에서 하나의 논리적 작업 단위를 의미하며 이 단위는 반드시 ACID(원자성, 일관성, 고립성, 지속성) 특성을 보장한다.
- Atomicity (원자성)
- 트랜잭션 안의 작업은 모두 성공하거나, 전부 실패
- 중간에 에러가 나면 해당 트랜잭션의 모든 변경사항은 취소(rollback)됨
- Consistency (일관성)
- 트랜잭션 전후에 데이터는 항상 DB 제약조건(유니크 제약, 참조 무결성 등)을 만족해야 함
- Isolation (고립성)
- 동시에 여러 트랜잭션이 실행되더라도, 서로 간섭하지 않고 독립적으로 처리됨
- Durability (지속성)
- 트랜잭션이 성공적으로 커밋(commit)되면, 그 변경사항은 DB에 영구적으로 저장됨
Neo4j는 Write-Ahead Log(사전 기록 로그) 방식을 사용한다. 즉, 데이터베이스에 업데이트될 내용을 먼저 디스크에 순차적으로 기록(log) 한 뒤, 실제 그래프 데이터에 적용한다. 따라서 중간에 전원이 꺼지는 등의 장애가 발생해도, 로그에 완전히 기록된 트랜잭션은 복구할 수 있고, 일부만 기록된 불완전한 트랜잭션은 안전하게 폐기된다. 또한 neo4j는 여러 서버에 걸쳐서도 ACID 트랜젝션을 유지하며, 각 서버의 트랜젝션 로그를 묶어서 함꼐 유지하는 Raft 알고리즘을 사용한다고 한다.
