
이 챕터에서는 LLM을 사용해서 비구조적인 문서 기반의 데이터를 그래프로 변환하고, 이를 RAG 프로세스에 적용하는 본격적인 GraphRAG를 다룬다. 참조데이터를 얻을 때, 구조화된 형태의 DB에서 쿼리하는 것의 필요성은 이전 Chapter4에서 다룬 적이 있다. 이때 중요한 포인트는 문서에서 어떻게 그래프로 표현할 구조적인 정보들을 추출할 지에 대한 부분인데, 이는 결국 '그래프 자동 구축'과도 연결된다.
사실 이 교안에서도 다루고, Neo4j와 같은 상용 그래프 DB에서도 그래프 자동 구축에 대해서 많이 시도하고 있지만, 개인적으로 완성도나 정확도 측면에서는 아직 개선이 필요하다고 생각한다. 특히 property graph(LPG)가 아닌 RDF 기반의 그래프의 경우, 사용하는 표준어휘의 전체 구조와 맥락을 파악하는 측면에서 더더욱 한계가 있다.
(+) 어쩌면 특정 도메인에 vertical한 관점으로 접근하면, 오히려 이전에 ML 기반으로 적용했던 information extraction을 사용하고, 이 과정에서 인간의 판단이 필요한 부분들에 LLM을 부분적으로 사용하는 방법은 어떨까하는 생각이 들었다.
Extracting structured data from text
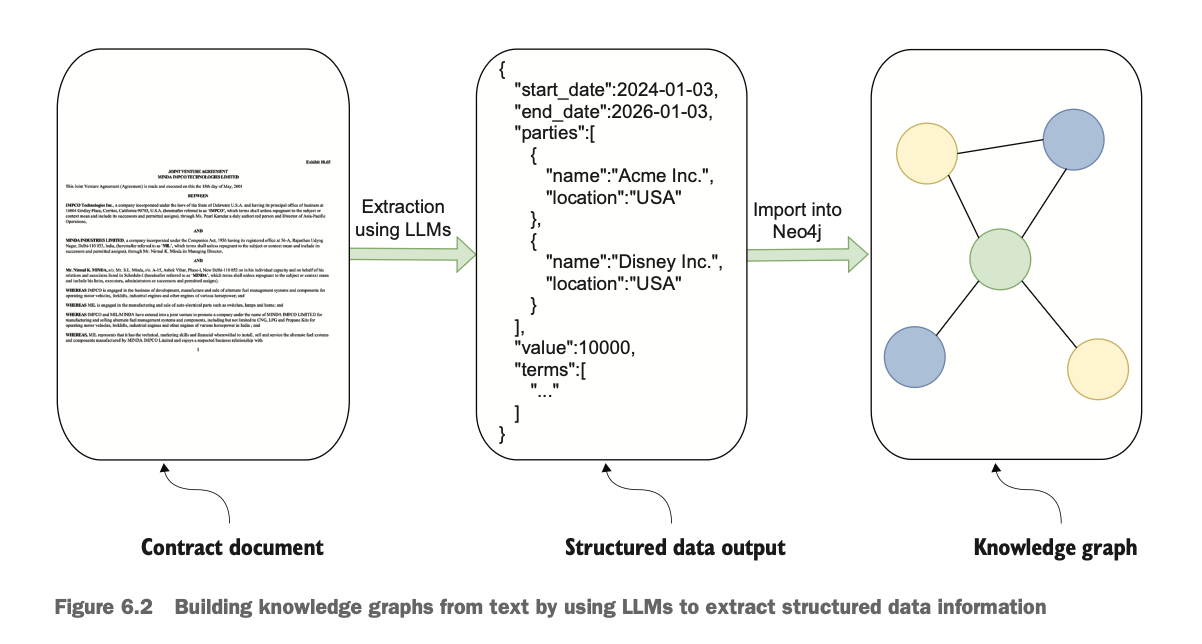
실습에서는 계약과 관련된 기업의 문서 중 오픈데이터인 CUAD 데이터셋을 사용한다. 실습 코드(ch06.ipynb)와 데이터셋(license_aggrement.txt)은 깃헙에 있다.
1️⃣ Structured Outputs model definition
LLM이 구조적인 답변을 도출하도록 하기 위해서 OpenAI API에서 제공하는 Structured Outputs를 사용할 수 있다. 파이썬에서는 Pydantic 라이브러리를 사용해서 스키마를 정의할 수 있는데, 데이터의 특성에 따라서 String, Number, Boolean, Integer, Object, Array 등의 타입을 설정해주면 된다. 아래와 같은 정의를 해주면 날짜는 반드시 'yyyy-MM-dd' 형식의 str로 도출되게 된다.
from pydantic import BaseModel
class CalendarEvent(BaseModel):
name: str
date: str = Field(..., description="The date of the event. Use yyyy-MM-dd format")
participants: list[str]이런 방식을 사용해서 노드, 속성, 관계를 추출하는 과정에서 각각의 형식을 지정해줄 수 있다. 코드에서는 Location, Organization을 string 타입으로 추출하기 위해 Class로 정의하고 있다. 예를 들어, Location의 경우 각각의 속성(address, city, state, country)은 어떤 특성을 갖는지 LLM이 이해할 수 있도록 description을 작성했고, Organization도 유사한 방식으로 진행한다. Contract에서는 속성별로 mandatory, optional 조건을 추가하거나 특정 속성에 대해 허용가능한 값을 enum 파라미터를 사용해서 구체적인 범주를 명시하여 LLM이 더욱 정확하게 판단할 수 있도록 하는 방법을 설명한다.
한편, 교안에서도 언급되지만, 개별 속성과 관계들을 정의하는 과정은 도메인 전문 지식이 필요한 분야이므로 전문가에게 리뷰를 받을 필요가 있다.
2️⃣ Structured Outputs extraction request
system_message = """
You are an expert in extracting structured information from legal documents and contracts.
Identify key details such as parties involved, dates, terms, obligations, and legal definitions.
Present the extracted information in a clear, structured format. Be concise, focusing on essential legal content and ignoring unnecessary boilerplate language."""
def extract(document, model="gpt-4o-2024-08-06", temperature=0):
response = client.beta.chat.completions.parse(
model=model,
temperature=temperature,
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": document},
],
response_format=Contract,
)
return json.loads(response.choices[0].message.content)이제 시스템 메세지를 통해서 추출 LLM을 정의하고, 위에서 정의한 정보들을 기반으로 추출을 실행한다. 시스템 메세지는 LLM이 원하는 결과를 도출하게 하기 위해서 중요한 역할을 하는데, 이 과정은 trial and error, 즉 여러 시행 착오를 거치며 휴리스틱하게 진행해야 한다.
추출된 결과는 다음과 같다.
{'contract_type': 'Licensing Agreement',
'parties': [{'name': 'Mortgage Logic.com, Inc.',
'location': {'address': 'Two Venture Plaza, 2 Venture',
'city': 'Irvine',
'state': 'California',
'country': 'US'},
'role': 'Client'},
{'name': 'TrueLink, Inc.',
'location': {'address': '3026 South Higuera',
'city': 'San Luis Obispo',
'state': 'California',
'country': 'US'},
'role': 'Provider'}],
'effective_date': '1999-02-26',
'term': "1 year, with automatic renewal for successive one-year periods unless terminated with 30 days' notice prior to the end of the term.",
'contract_scope': 'TrueLink grants Mortgage Logic.com a non-exclusive license to use the Interface for origination, underwriting, processing, and funding of consumer finance receivables. TrueLink will provide hosting services, including storage, response time management, bandwidth, availability, access, backups, internet connection, and domain name assistance. TrueLink will also provide support services and transmit credit data as permitted under applicable agreements and laws.',
'end_date': None,
'total_amount': None,
'governing_law': {'address': None,
'city': None,
'state': 'California',
'country': 'US'}}3️⃣ Contructing the graph
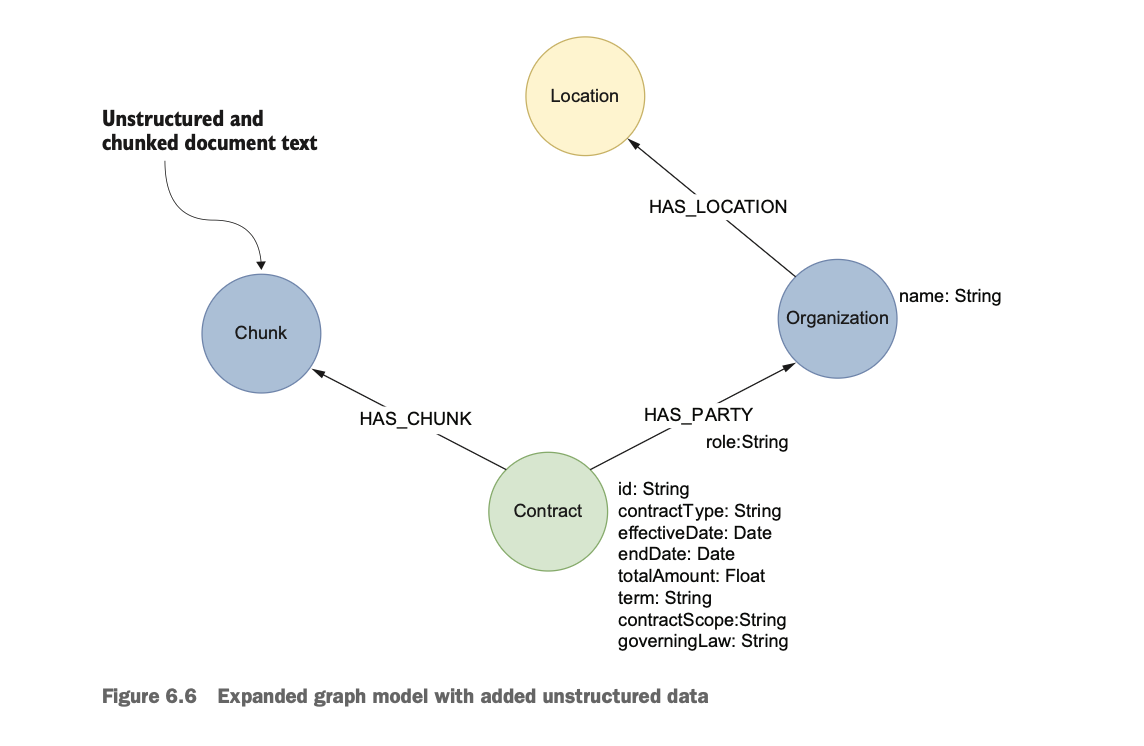
이제 추출한 데이터들을 Neo4j에 임포트하면 그래프DB를 구축하는 과정은 완성된다. 임포트는 Cypher 쿼리를 사용해서 개별 노드에 UUID를 통한 유니크한 아이디를 붙여주고 노드와 관계를 연결한다.
이후 과정으로는 Entity Resolution이 필요하다. 사실 ER은 추출하고 DB에 넣기 전에 진행해도 되고, DB에 넣고 진행해도 되는데 교안에서는 후자의 방법으로 설명하고 있었다. 예를 들어, 동일한 엔티티에 대해 (1) UTI Asset Management Company (2) UTI Asset Management Company Limited (3) UTI Asset Management Company Ltd 이런식으로 표현방법이 다르면, 현재는 모두 다른 노드로 표현되게 된다. 따라서 이들을 하나의 노드로 합쳐주는 과정이 필요한데, 저자는 이 방법은 도메인별로 다를 수 있고, one-size-fits-all 솔루션은 존재하지 않는다고 설명한다. 가장 효과적인 방법으로는 도메인 온톨로지를 사용하거나 규칙 기반으로 합치는 방법 혹은 클러스터링 등을 수행할 수 있다.
추가로, 위 그래프 이미지에서 Chunk를 연결한 부분과 같이 기존의 문서에서 해당 노드와 연결되는 Chunk 부분을 가져와서 연결해줄 수도 있다. 이는 문서를 구조화하는 과정에서 어쩔 수 없이 발생하는 정보 손실이나 맥락의 부재 등을 보완할 수 있는 방법이다.
