🧩 Agentic RAG 란?
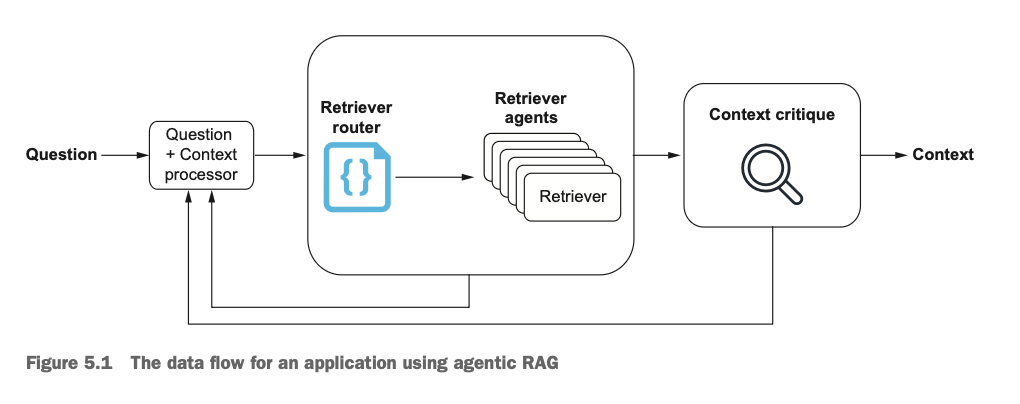
에이전틱 RAG 시스템은 기존 RAG의 외부의 참조데이터를 가져와서 답변을 생성한다는 틀을 동일하지만, 이 참조데이터를 가져올 때 에이전트가 활용된다는 특징이 있다. 위 그림에서는 Retriever router로 표현되는데, 질문의 특성에 따라 달라지는 참조데이터의 출처나 이를 수행하는 모듈/도구 선택을 에이전트를 통해 판단하도록 하는 것이다. 이때 router는 ReACT와 같이 CoT와 추론할 수 있는 프롬프트를 기반으로 구성된다. 이 챕터에서는 간단하게 적절한 retriever를 선택하는 에이전트를 구축하지만, 이를 고도화하면 답변 생성을 위한 계획을 세우거나 더 복합적인 추론 과정을 수행할 수 있다.
에이전틱 RAG 시스템의 주요 구성요소는 다음과 같다.
- Retriever router
: 사용자의 질의에 맞는 retriever를 판단하는 router이다. 예를 들어, '프랑스의 수도는?'과 같은 질문이 있고, 선택할 수 있는 retriever가 (1) capital_by_country(나라이름으로 수도이름을 반환) (2) country_by_capital(수도이름으로 나라이름을 반환) 두개 라면, (1)번을 선택하는 것이 적절하다. - Retriever agents
: 실제로 참조 정보를 찾아서 가져오는 retriever를 의미한다. 데이터에 따라 벡터DB를 사용한 유사도 기반의 방법이나 RDB 등에서 쿼리(text2cypher)를 통해 가져오는 방법을 사용할 수도 있다. - Answer critic
: 참조 정보를 종합해서 생성된 답변이 적절한지 확인하고 최종적으로 답변을 제공할지 판단한다. 적절하지 않을 경우, 질문을 재작성하는 방식 등을 통해 더 적절한 retriever를 선택하는 방법을 적용할 수 있다.
에이전틱 RAG은 참조해야 하는 데이터가 많거나 복잡한 경우 고도화된 router를 사용해서 최적의 도구를 선택할 수 있따는 점에서 유용하다.
🧩 Agentic RAG 실습
실습 코드는 [깃헙](https://github.com/tomasonjo/kg-rag/blob/main/ notebooks/ch05.ipynb)의 'ch05.ipynb'에 있다. 데이터는 기본 Movies datasets를 사용한다.
Implementing retriever tools
우선 사용할 retrievers를 정의해야 하는데, 실습에서는 템플릿을 사용해서 Cypher 쿼리를 생성하는 도구 2개와 text2Cypher 도구 1개를 사용한다. 정의한 구조와 프롬프트는, 'ch05_tools.py'에서 확인할 수 있다.
text2cypher_description = {
"type": "function",
"function": {
"name": "text2cypher",
"description": "Query the database with a user question. When other tools don't fit, fallback to use this one.",
"parameters": {
"type": "object",
"properties": {
"question": {
"type": "string",
"description": "The user question to find the answer for",
}
},
"required": ["question"],
},
},
}
def text2cypher(question: str):
"""Query the database with a user question."""
t2c = Text2Cypher(neo4j_driver)
t2c.set_prompt_section("question", question)
cypher = t2c.generate_cypher()
try:
records, _, _ = neo4j_driver.execute_query(cypher)
return [record.data() for record in records]
except Exception as e:
return [f"{cypher} cause an error: {e}"]하나만 예시로 보자면, text2Cypher를 수행하는 retriever를 LLM router가 선택 과정에서 이해할 수 있도록 description을 넣어주고, Neo4J driver를 연결해서 실제로 쿼리를 해오는 구조로 구성된다.
이런식으로 구성한 도구들은 아래와 같이 tools에 종류별로 할당하고, llm_tool_calls가 있을 때, 즉 LLM이 도구를 호출했을 때 적절한 도구를 수행해서 output을 얻는 방식으로 진행된다.
import ch05_tools
tool_picker_prompt = """
Your job is to chose the right tool needed to respond to the user question.
The available tools are provided to you in the prompt.
Make sure to pass the right and the complete arguments to the chosen tool.
"""
tools = {
"movie_info_by_title": {
"description": ch05_tools.movie_info_by_title_description,
"function": ch05_tools.movie_info_by_title
},
"movies_info_by_actor": {
"description": ch05_tools.movies_info_by_actor_description,
"function": ch05_tools.movies_info_by_actor
},
"text2cypher": {
"description": ch05_tools.text2cypher_description,
"function": ch05_tools.text2cypher
},
"answer_given": {
"description": ch05_tools.answer_given_description,
"function": ch05_tools.answer_given
}
}
def handle_tool_calls(tools: dict[str, any], llm_tool_calls: list[dict[str, any]]):
output = []
if llm_tool_calls:
for tool_call in llm_tool_calls:
function_to_call = tools[tool_call.function.name]["function"]
function_args = json.loads(tool_call.function.arguments)
res = function_to_call(**function_args)
output.append(res)
return output Implementing the retriever router
사용자의 질문은 여러개의 질문으로 구성될 수 있으므로(e.g. 프랑스의 수도는 어디고 인구가 몇일까?) 이런 질문들을 분리해서 하나씩 참조 데이터를 가져오면 더욱 정확도를 높일 수 있다. 따라서 아래와 같이 질문을 분리한 뒤 순차적으로 실행하고, 각각의 답변을 json 형태로 관리하는 로직을 추가할 수 있다. 즉, '프랑스의 수도?'라는 질문을 통해 답변을 먼저 찾고 '파리의 인구?'라는 질문으로 두번째 답변을 찾아서 이를 종합하는 것이다.
이 부분이 가장 인상적이었다. 실제로 사용자는 n개의 질문을 섞어서 할 수 있는데, 한번의 retrieve는 답변 생성에 한계가 있기 때문이다. 처음부터 질문을 분리하고, 심지어 이 꼬리 질문과 답변을 다시 그 다음 꼬리 질문이 참조할 수 있도록 하는 방식은 효과적일 것 같다.
query_update_prompt = """
You are an expert at updating questions to make the them ask for one thing only, more atomic, specific and easier to find the answer for.
You do this by filling in missing information in the question, with the extra information provided to you in previous answers.
You respond with the updated question that has all information in it.
Only edit the question if needed. If the original question already is atomic, specific and easy to answer, you keep the original.
Do not ask for more information than the original question. Only rephrase the question to make it more complete.
JSON template to use:
{
"question": "question1"
}
"""
def query_update(input: str, answers: list[any]) -> str:
messages = [
{"role": "system", "content": query_update_prompt},
*answers,
{"role": "user", "content": f"The user question to rewrite: '{input}'"},
]
config = {"response_format": {"type": "json_object"}}
output = chat(messages, model = "gpt-4o", config=config, )
try:
return json.loads(output)["question"]
except json.JSONDecodeError:
print("Error decoding JSON")
return []이제 실제로 질문에 따른 retriever를 라우팅하는 부분으로, query_update를 통해서 질문을 분리하고, route_question을 사용해서 적절한 도구를 활용하여 참조데이터를 얻는다. 그리고 최종 답변 생성을 위해 다시 LLM에 넣어주는 구조를 도출한다.
def route_question(question: str, tools: dict[str, any], answers: list[dict[str, str]]):
llm_tool_calls = tool_choice(
[
{
"role": "system",
"content": tool_picker_prompt,
},
*answers,
{
"role": "user",
"content": f"The user question to find a tool to answer: '{question}'",
},
],
model = "gpt-4o",
tools=[tool["description"] for tool in tools.values()],
)
return handle_tool_calls(tools, llm_tool_calls)
def handle_user_input(input: str, answers: list[dict[str, str]] = []):
updated_question = query_update(input, answers)
response = route_question(updated_question, tools, answers)
answers.append({"role": "assistant", "content": f"For the question: '{updated_question}', we have the answer: '{json.dumps(response)}'"})
return answershandle_user_input는 아래의 최종 실행 함수인 main에서 사용된다.
main_prompt = """
Your job is to help the user with their questions.
You will receive user questions and information needed to answer the questions
If the information is missing to answer part of or the whole question, you will say that the information
is missing. You will only use the information provided to you in the prompt to answer the questions.
You are not allowed to make anything up or use external information.
"""
def main(input: str):
answers = handle_user_input(input)
critique = critique_answers(input, answers)
if critique:
answers = handle_user_input(" ".join(critique), answers)
llm_response = chat(
[
{"role": "system", "content": main_prompt},
*answers,
{"role": "user", "content": f"The user question to answer: {input}"},
],
model="gpt-4o",
)
return llm_responseImplementing the answer critic
위 main 함수에서 아직 언급하지 않은 부분은 질문을 분리해서 각각 참조 정보들을 얻고, 이들을 종합해서 최종적으로 생성한 답변이 원질문에 적절한지를 판단하는 critique_answers이다. 이를 통해 hallucination이나 중간 과정에서 생길 수 있는 정보 오류, 손실 등을 방지할 수 있다. 만약 답변이 적합하지 않다면, LLM은 new question 리스트로 다시 플로우를 분기해서 누락된 정보를 가져오도록 만든다.
answer_critique_prompt = """
You are an expert at identifying if questions has been fully answered or if there is an opportunity to enrich the answer.
The user will provide a question, and you will scan through the provided information to see if the question is answered.
If anything is missing from the answer, you will provide a set of new questions that can be asked to gather the missing information.
All new questions must be complete, atomic and specific.
However, if the provided information is enough to answer the original question, you will respond with an empty list.
JSON template to use for finding missing information:
{
"questions": ["question1", "question2"]
}
"""
def critique_answers(question: str, answers: list[dict[str, str]]) -> list[str]:
messages = [
{
"role": "system",
"content": answer_critique_prompt,
},
*answers,
{
"role": "user",
"content": f"The original user question to answer: {question}",
},
]
config = {"response_format": {"type": "json_object"}}
output = chat(messages, model="gpt-4o", config=config)
try:
return json.loads(output)["questions"]
except json.JSONDecodeError:
print("Error decoding JSON")
return []최종적으로 아래와 같이 2개의 질문을 묶어서 질의했을 때도 정확하게 답변을 잘 도출하는 것을 확인할 수 있다.