
- 스터디 책: Hands-On Entity Resolution
- 깃헙: https://github.com/mshearer0/HandsOnEntityResolution
이전 챕터에서는 GCP를 통해서 대용량 데이터의 entity resolution 방법을 설명했다(물론 실습 과정에서 실패했다). 교안에서도 이 작업은 사전 세팅 작업이 까다롭다고 설명하고, 따라서 이번 챕터에서는 cloud 기반의 entity resolution API를 활용한 방법을 소개한다.
Google의 Enterprise Knowledge Graph API를 사용하며, 이전 챕터에서 사용한 데이터들을 동일하게 사용한다.
Introduction to BigQuery
구글 빅쿼리는 구글 클라우드 플랫폼에서 제공하는 서버리스(Serverless) 기반의 완전 관리형 데이터 웨어하우스로, 페타바이트(PB) 규모의 방대한 데이터를 몇 초 또는 몇 분 만에 분석하고 처리할 수 있도록 설계된 강력한 서비스라고 한다.
쉽게 이해하면, 분석과 쿼리를 하기 위해서 데이터를 저장하는 DB의 역할과 DB에서 바로 분석하고 쿼리를 하는데 이때 클라우드 서버를 활용해서 수행하므로 로컬 리소스 제약 없이 수행할 수 있다는 특징을 갖는다고 볼 수 있다.
우선 사용하기 위해서는 이전에 했던 것처럼 프로젝트를 생성해야 한다. 이후 BigQuery에 들어가서 '데이터세트'를 생성한다.
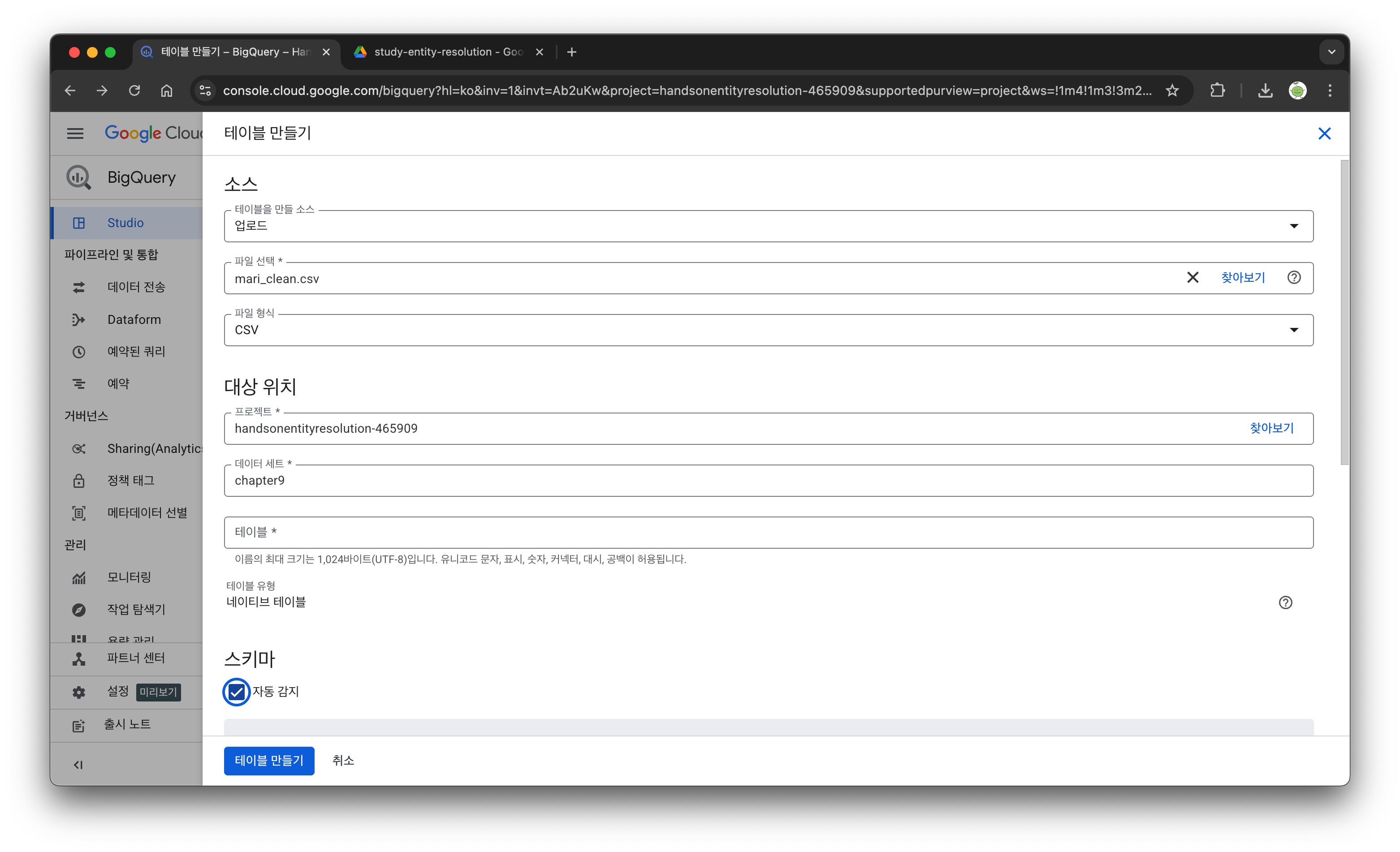
이제 필요한 데이터를 업로드 해줘야 한다. 테이블 생성을 통해서 mari_clean.csv와 basic_clean.csv를 각각 업로드 해주고, 스키마를 자동감지를 선택한다.
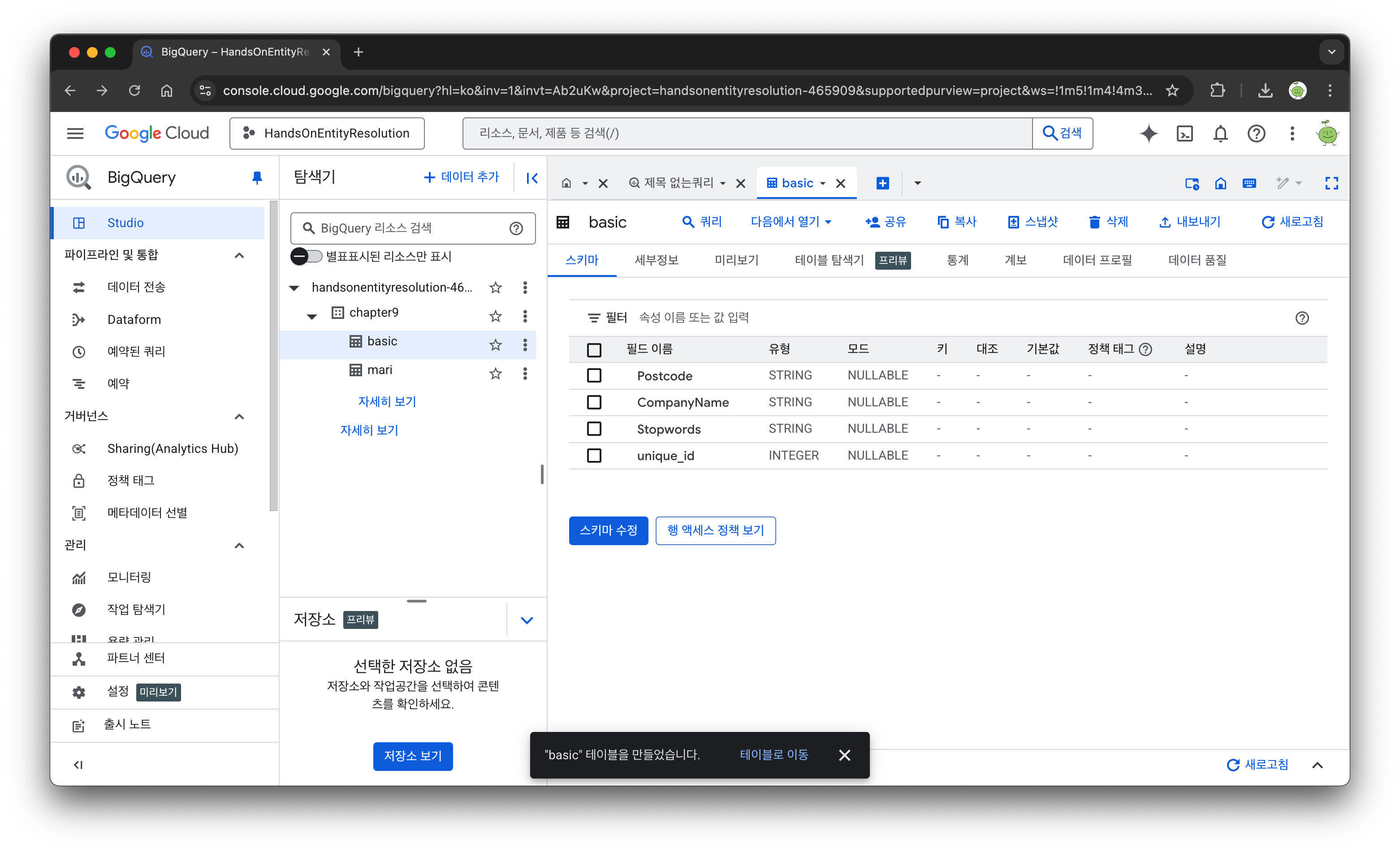
두 개의 데이터를 업로드 한뒤 확인해보면 이렇게 필드 이름이 자동으로 감지되어 나타나는 것을 볼 수 있다.
Enterprise Knowledge Graph API
Google Enterprise Knowledge Graph API는 구글의 데이터를 활용하여 학습한 AI를 활용하여 entity resolution을 진행하는 'Entity Reconciliation' 이라는 서비스를 제공한다. 이때, hierarchical agglomerative clustering을 사용한다는데, 이는 bottom-up 방식으로 클러스터링을 하는 기법을 의미한다. 즉, 개별 엔티티들이 주위에서 비슷한 것들끼리 하나 둘 모여서 최종적으로 하나의 클러스터를 형성하는 방식이다.
Schema Mapping
'스키마 매핑' 버튼을 누른 뒤
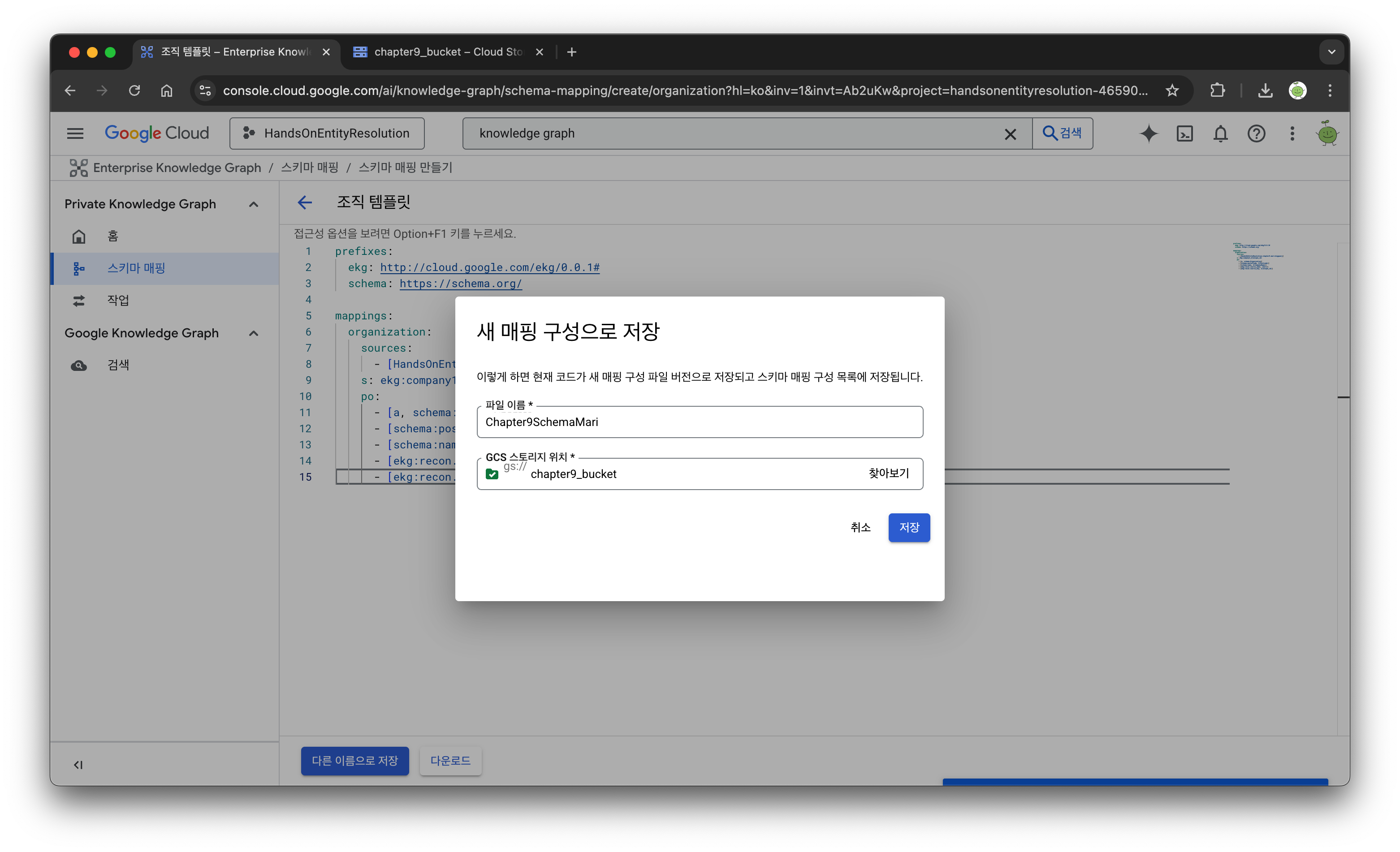
Organization 스키마를 basic, mari 각각 생성해서 프로젝트의 버킷에 저장한다. 스키마 정보는 교안 깃헙에 있으니 참고하면 된다.
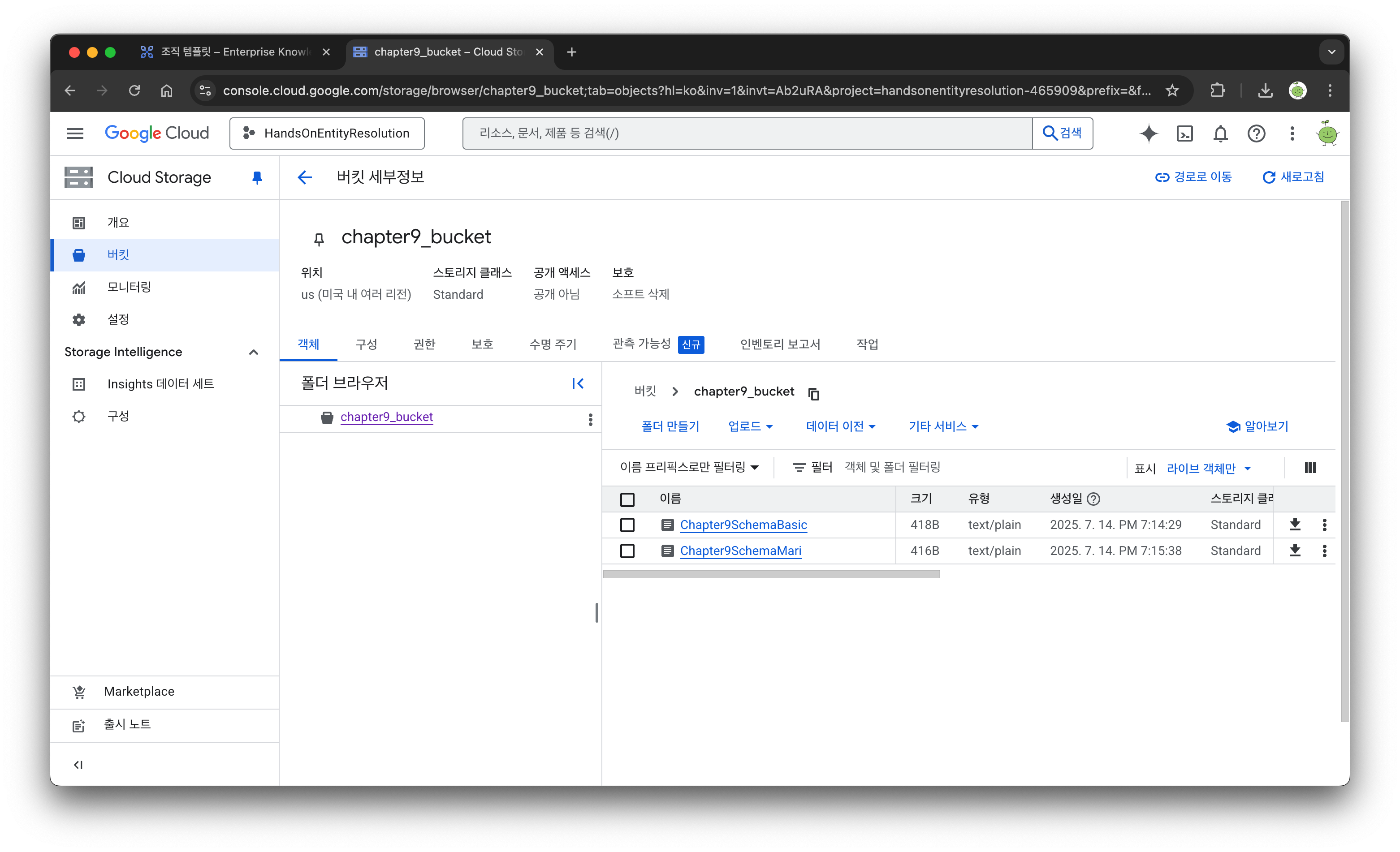
버킷에 확인해보면 스키마 파일이 정상적으로 잘 저장되어 있는 것을 볼 수 있다.
Reconciliation Job
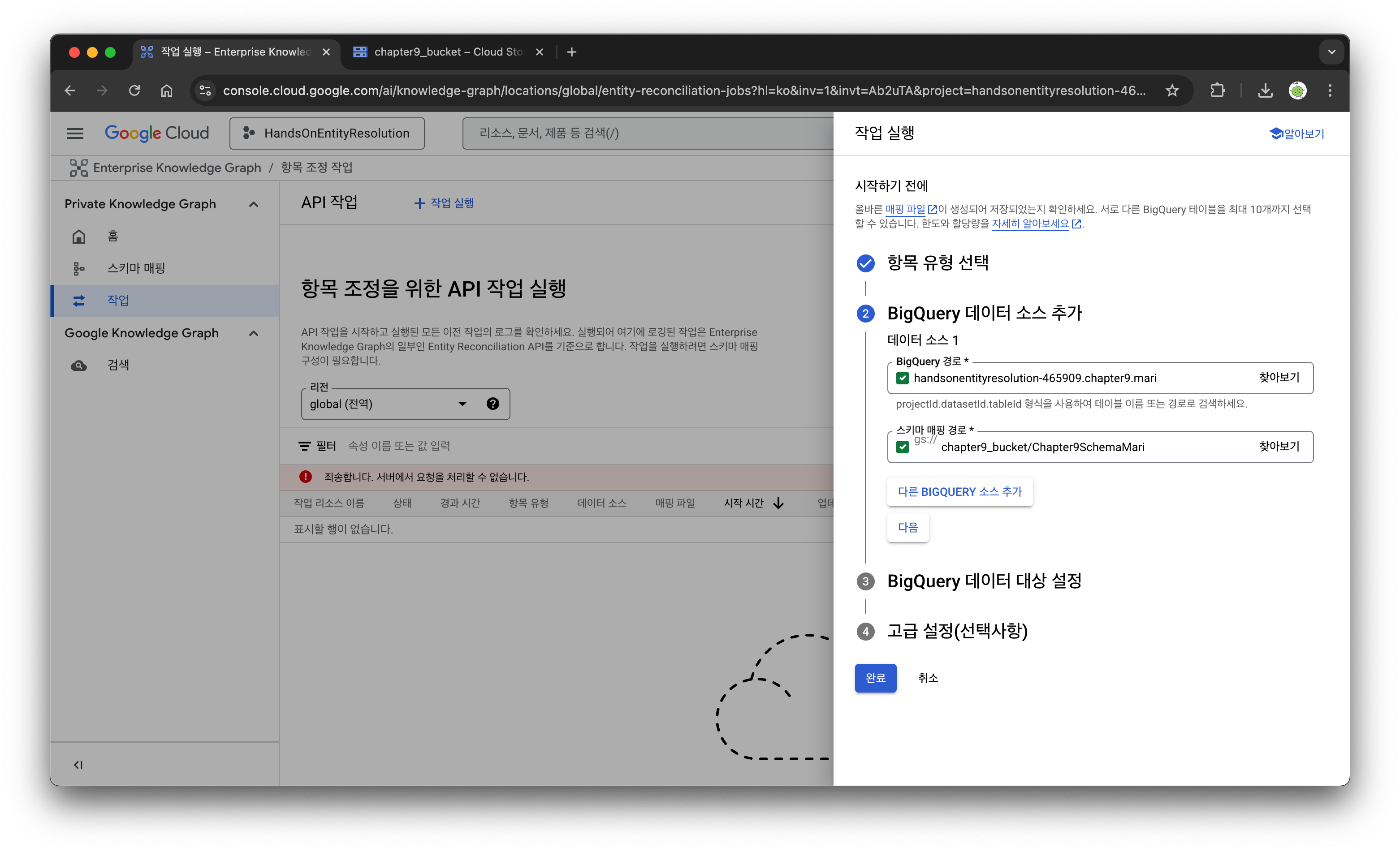
(개인 프로젝트 경로이지만, 이미 삭제한 상태임)

이런식의 에러가 발생했는데, 위 경로로 들어가서 API 사용 버튼을 눌러주니 아래와 같은 확면이 떴고, 다시 완료 버튼을 눌러서 성공했다.
데이터 양이 많아서 작업이 완료되는데 꽤 시간이 걸릴 것으로 예상했다.
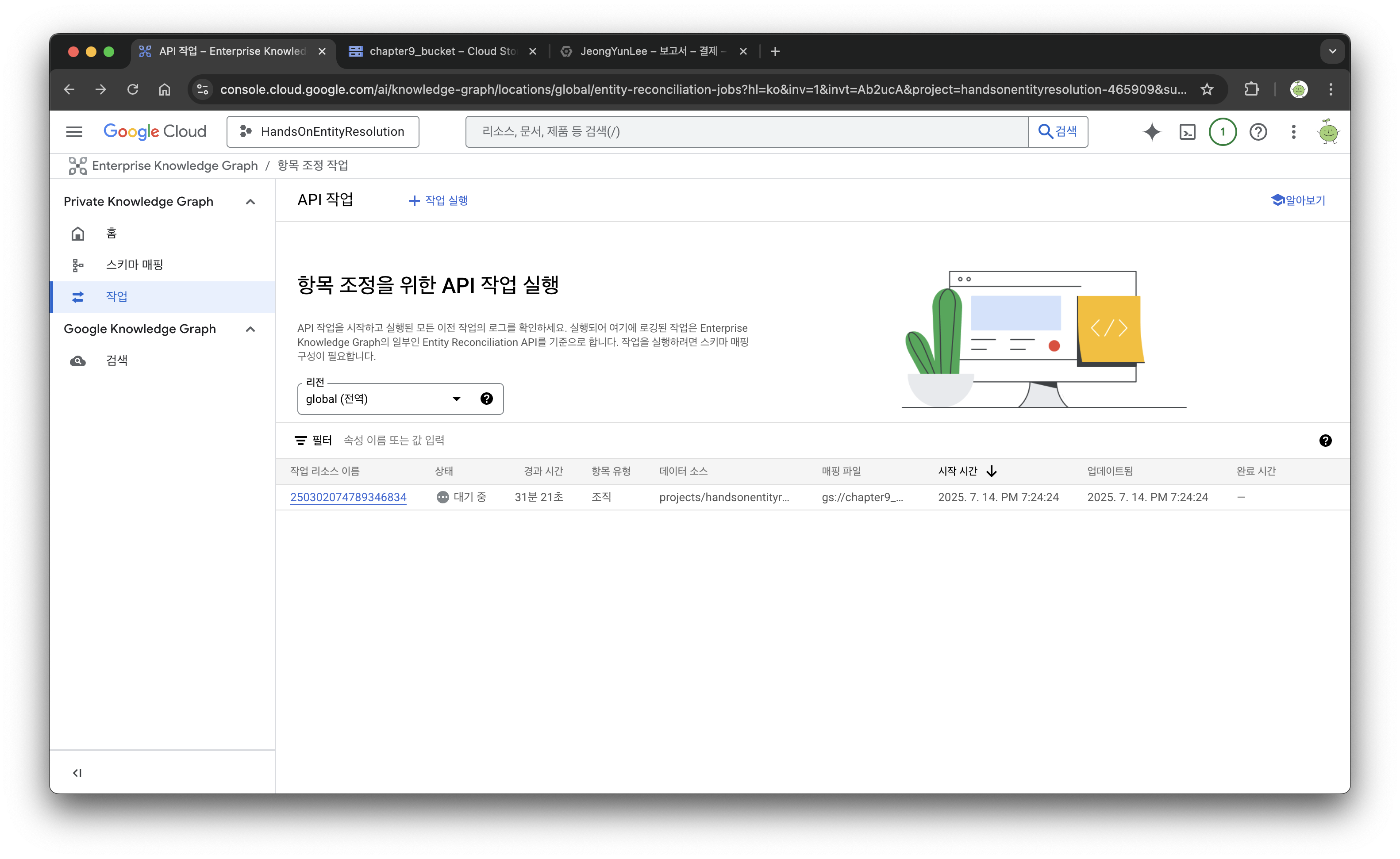
다만...30분동안 대기중이 뜨고 있고, 실제로 작업이 잘 진행되고 있는지 확인할 수 있는 방법이 없었다. 아마도 작업 중인 상태인것으로 추정되지만, 과금을 막기 위해 일단 정지시켰다.
교안에 따르면, 작업이 완료되면 BigQuery에 작업 결과 테이블이 생성되고 SQL 쿼리를 통해서 분석을 진행한다. 우선 작업이 완료되지 않았기 때문에 그 이후의 내용은 보류로 남겨두었다.
