
- 스터디 책: Hands-On Entity Resolution
- 깃헙: https://github.com/mshearer0/HandsOnEntityResolution
Chapter2는 Data Standardization 실습 파트이다. 실습 코드는 깃헙에 있으며, 코랩에서 개인적인 테스트를 진행했다. 아래 내용에서 언급되지만, 교안은 2019년을 기준으로 하고, 필자의 실습은 2024년 총선 결과를 기준으로 진행된다.
Data standardization은 entity resolution을 진행할 때, 데이터가 일관된 형식이 되고 모든 이상치가 제거되거나 수정되도록 수정하는 과정을 의미한다. 해당 챕터에서는 실제 데이터를 활용한 실습을 진행한다.
1️⃣ Sample Problem
분석 목표는 영국 하원들의 재석 성공에 영향을 미치는 요인들을 조사하기 위함이며, 특히 소셜미디어 활동이 활발할 정치인들이 재선에서 더 성공적일 것이라는 가설을 세운다.
이 가설을 위해 활용하는 데이터는 2개인데, 우선 위키피디아 데이터의 경우, 2019년에 당선된 국회의원 목록과 재선여부를 포함하지만, 소셜미디어 링크를 제공하진 않는다. 반면, TheyWorkForYou에서는 facebook url을 제공하지만, 재선여부를 제공하진 않으므로, 두 데이터를 병합해서 새로운 인사이트를 얻을 수 있다.
한편, 데이터셋은 선거구 이름도 포함하고 있지만, 2019년 총선 이후 여러 차례 보궐선거가 실시되어 새로운 의원들이 당선되었기 때문에 이들을 포함시켜서는 안된다는 것을 유의해야 한다.
2️⃣ Acquiring Data
사용한 데이터는 크게 Wikipedia와 TheyWorkForYou이며, Facebook 링크를 추가로 사용한다.
Wikipedia data
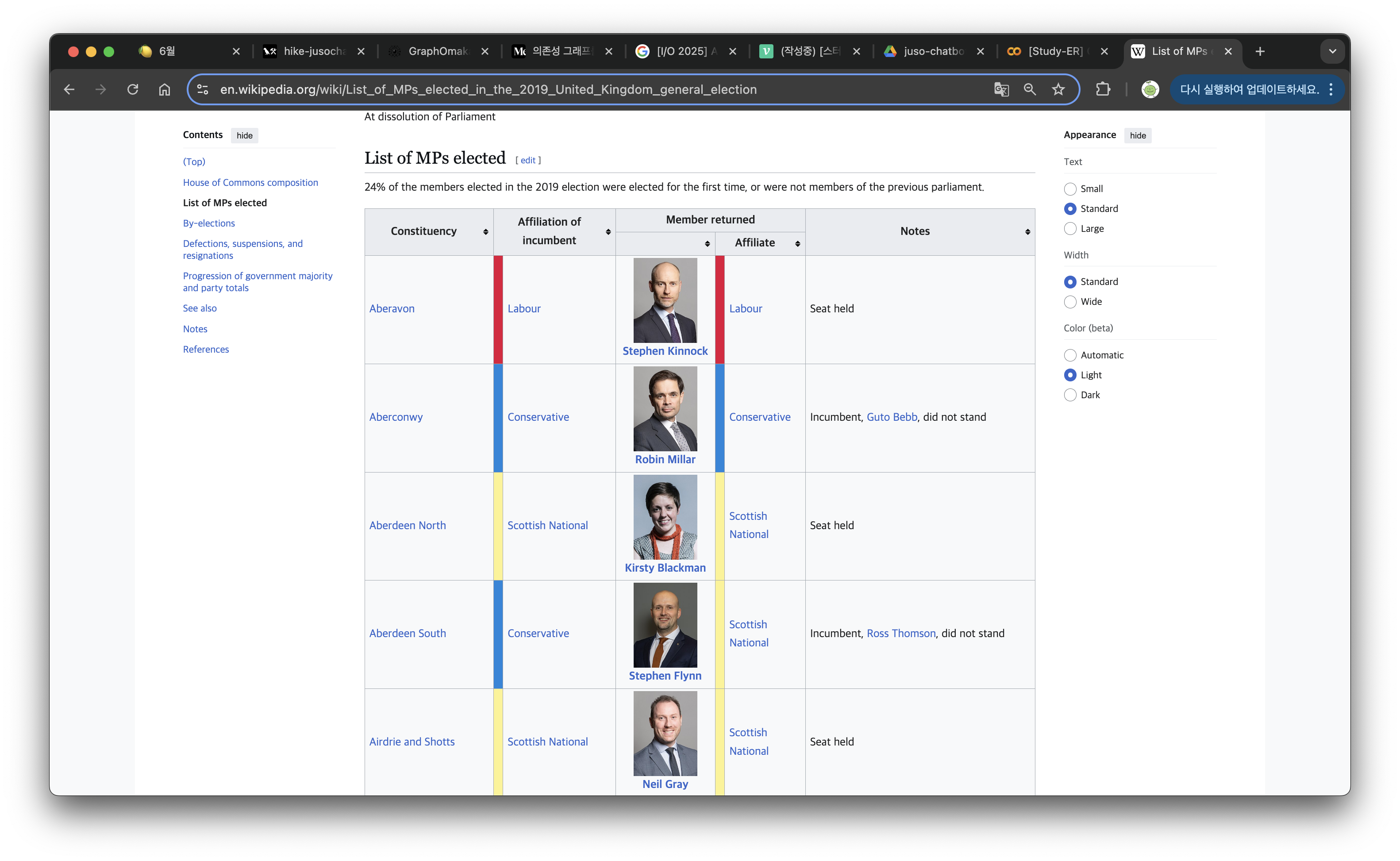
위키피디아 데이터는 2019년 영국 총선에서 선출된 국회의원 명단을 사용한다. 이 링크에 들어가보면 html 테이블 데이터가 있으므로 이를 request와 bs4를 통해서 뽑아온 뒤, 테이블 태그들을 기준으로 dataframe으로 변환한다.
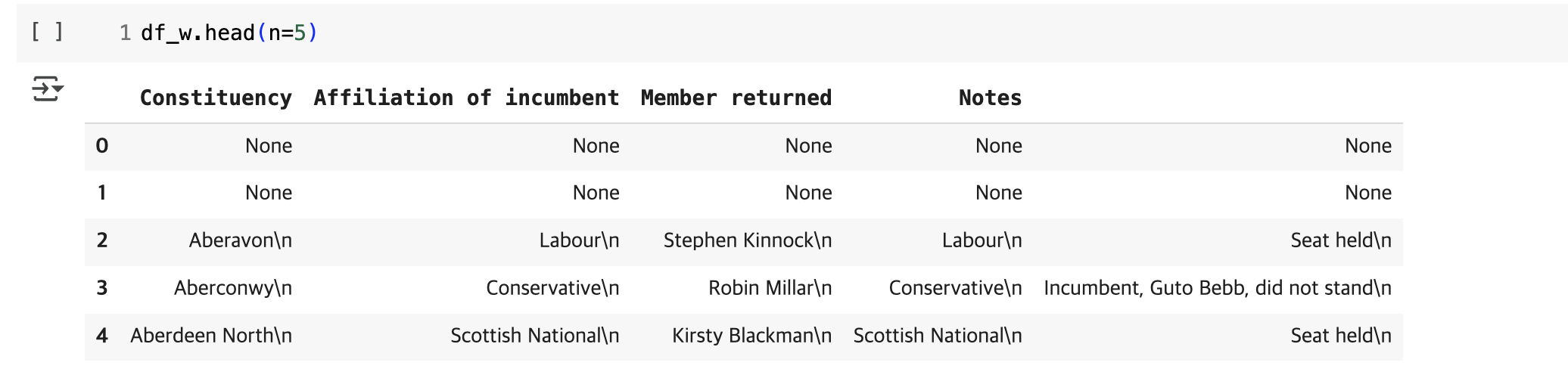
이후 불필요한 컬럼과 None인 행을 삭제한다.
TheyWorkForYou data
TheyWorkForYou에서는 csv 다운로드 링크를 제공하므로, url로 다운받으면 된다.
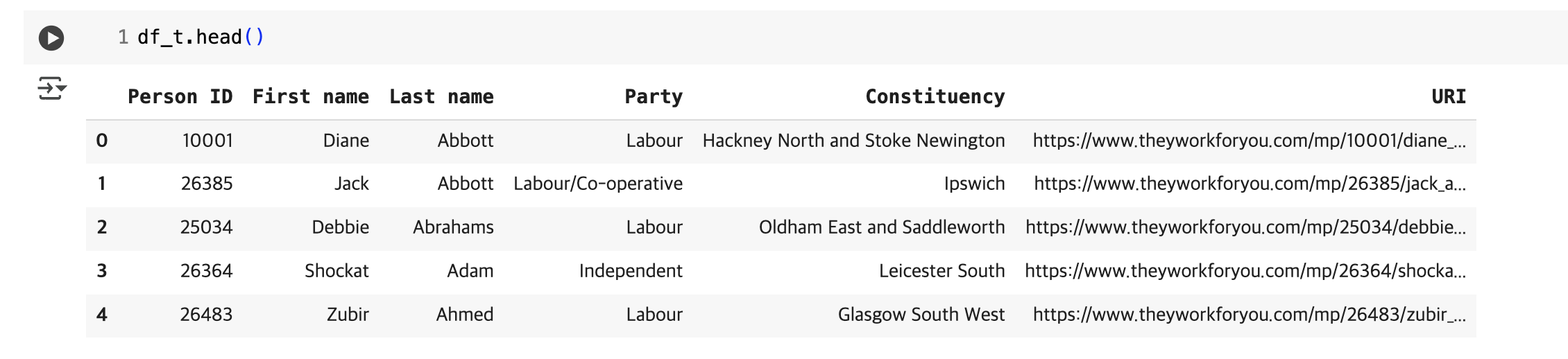
Adding Facebook links
위키피디아에서 테이블을 추출한 방법과 동일하게, TheyWorkForYou에서 facebook.com이 포함된 url을 추출하는데, 이때 링크가 공식 facebook 계정인 'https://www.facebook.com/TheyWorkForYou'로 연결되어 있는 경우 null을 반환한다.
3️⃣ Cleansing Data
TheyWorkForYou 데이터는 이미 정제가 잘 되어 있기 때문에 컬럼명만 표준화해준다. Wikipedia data의 경우 (1) 컬럼명 표준화 (2) null 제거 (3) \n 문자 제거 (4) Fullname을 공백 기준으로 'Firstname'과 'Lastname'으로 분리하기 등의 전처리를 진행한다.
4️⃣ Attribute Comparison
비교 데이터셋의 사이즈가 작기 때문에 record blocking은 건너뛰고, 바로 Firstname, Lastname, Constituency를 대상으로 exact matching을 실시한다. 이때 exact matching은 세 컬럼을 기준으로 merge를 하면 된다. 교안에서는 2019년 기준의 결과가 있기 때문에 실제로 돌린 코드와 일부 차이가 있었다.
우선, 다음과 같이 세 컬럼을 기준으로 머지하면, 177행만 매칭이 된다.
print(len(df_w.merge(df_t, on=['Constituency','Firstname','Lastname'])))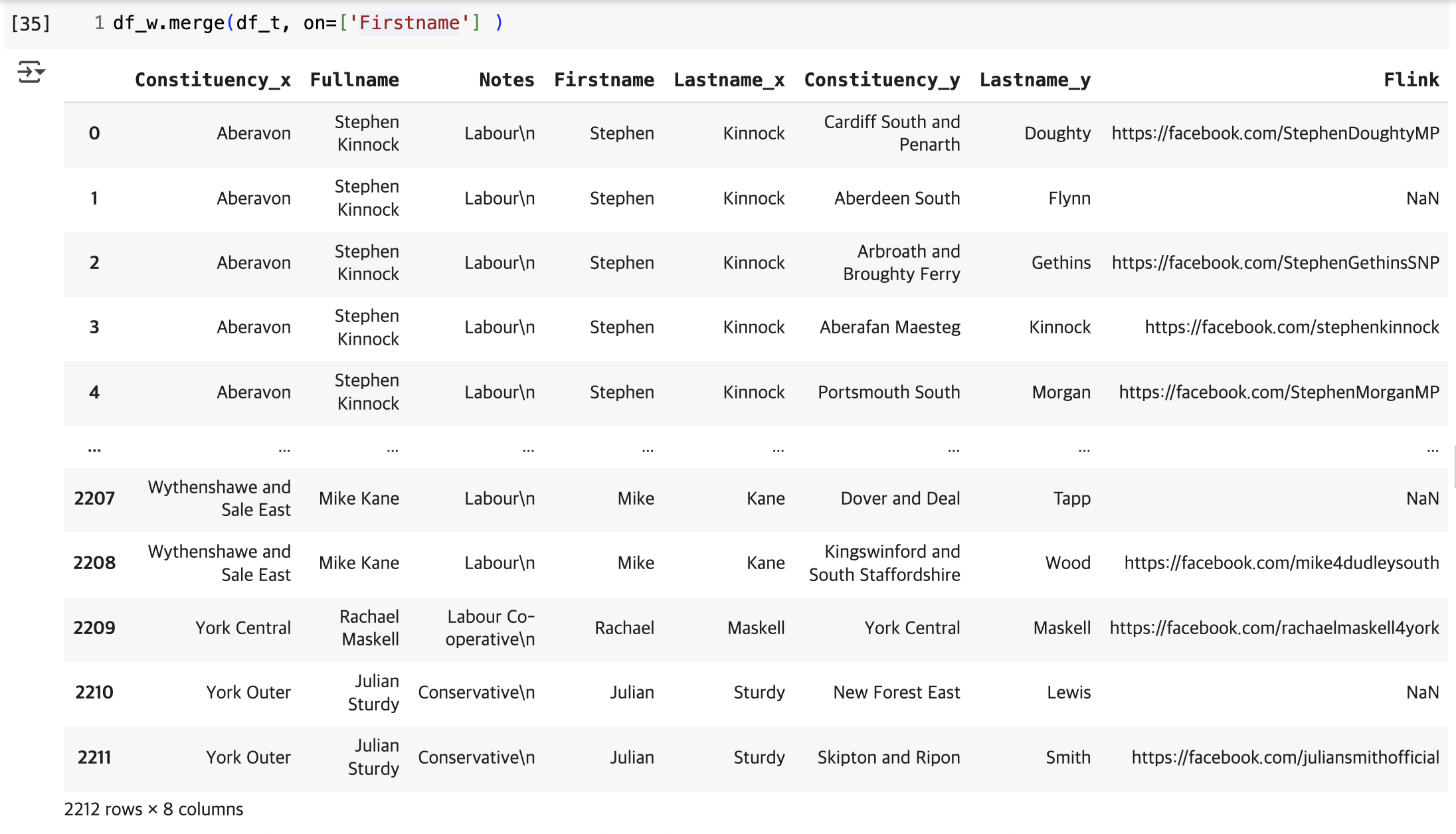
기준 컬럼을 바꿔가면서 머지해보면, Firstname으로만 한 경우 2212행이 생성되는데, 이는 동일한 이름을 가진 사람이 다수 있기 때문이다. 실제 머지된 위 테이블을 보면, Firsname 외에 Lastname은 _x와 _y가 붙은 값이 다른 경우를 볼 수 있다. 즉, 동일한 개체가 머지되지 않았다는 것을 알 수 있다.
한편, 교안에서는 두 데이터베이스의 Consituency가 매칭되지 않는 경우가 약 50건 정도 있었는데, 현재 데이터에서는 650건 중 438건만 매칭이 되고, 이외는 매칭이 되지 않았다. 이유를 생각해보니, TheyWorkForYou 데이터는 2024년 기준이고, 위키데이터는 2019년 기준이라는 걸 확인했다. 따라서 위에서 수집한 위키데이터 데이터를 2024로 수정하고 다시 처음부터 진행했다(크롤링하고 df로 변환하는 과정에서 에러가 있어서 실습 코드를 일부 수정했다).
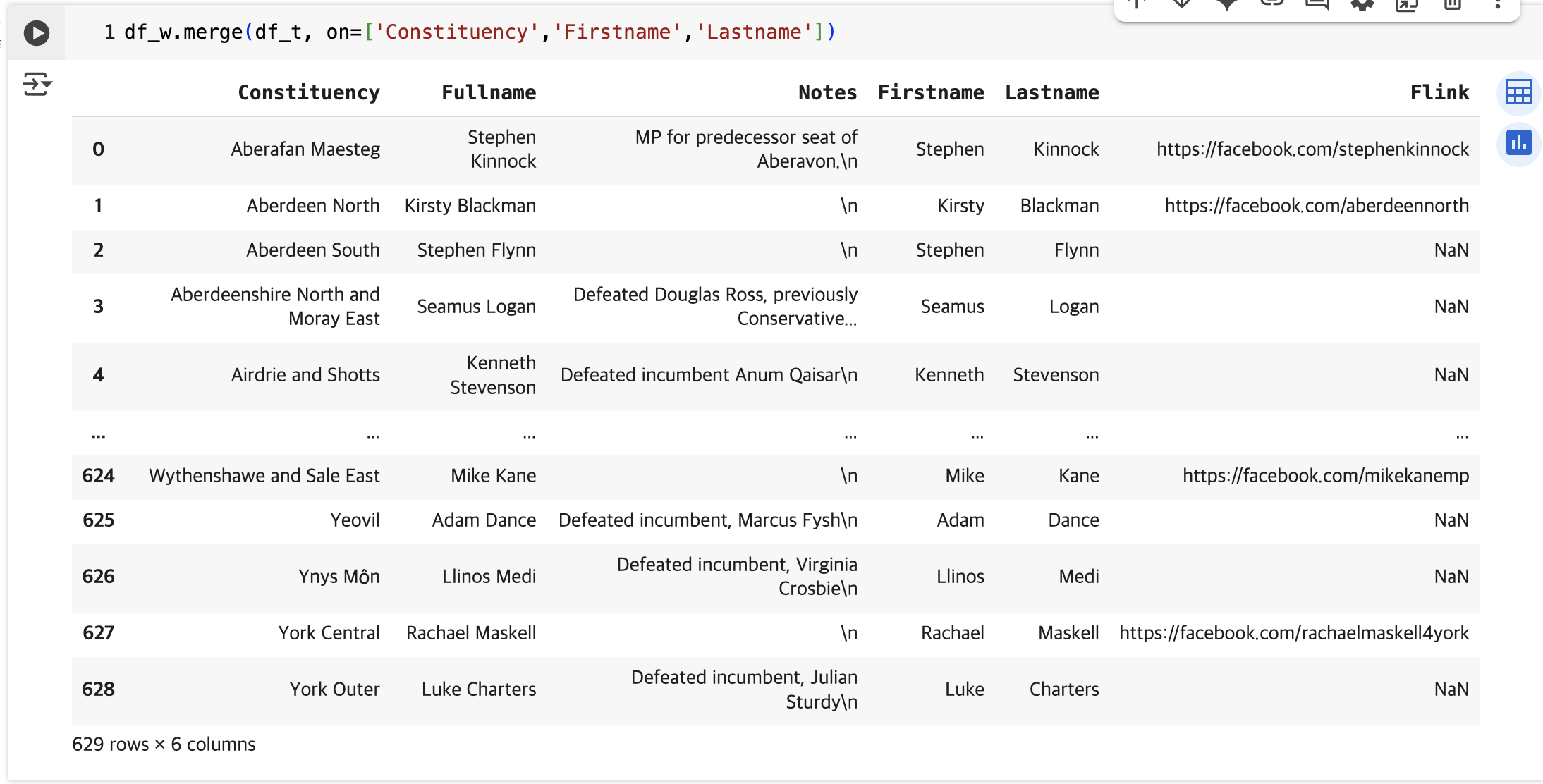
다시 실행하니 650행 중 629행이 매칭됐다.
Constituency

매칭되지 않은 Constituency는 딱 한개 였고, 위와 같이 'The'와 'the'의 대소문자가 일치하지 않은 문제였다. 'South Holland and the Deepings'로 통일시켜주었다.
Fullname
이후 Constituency를 기준으로 merge 한뒤, 이름이 완전히 일치하지 않는 경우는 Runcorn and Helsby 선거구 딱 1개 였다. 이는 둘 줄 하나는 틀린 정보를 제공한다고볼 수 있다.

TheyWorkForYou에 검색해보면 Runcorn and Helsby의 의원은 2025년 5월에 바뀐 것 같다. 따라서 Sarah Pochin으로 모두 통일시켜주었다. (아래 통계를 낼 때는 틀린 케이스를 1로 계산해줌)
Firstname, Lastname
Firstname이 2개 이상인 경우, 가장 첫 번째만 남긴다. 이후 Firstname은 같은데 Lastname은 다르거나 혹은 그 반대의 경우는 다음과 같은 코드로 확인할 수 있다. 이 결과 총 16행이 나왔다.
df_w_inner[(df_w_inner['Firstname_w'] == df_w_inner['Firstname_t']) & (df_w_inner['Lastname_w'] != df_w_inner['Lastname_t']) |
(df_w_inner['Firstname_w'] != df_w_inner['Firstname_t']) & (df_w_inner['Lastname_w'] == df_w_inner['Lastname_t'])]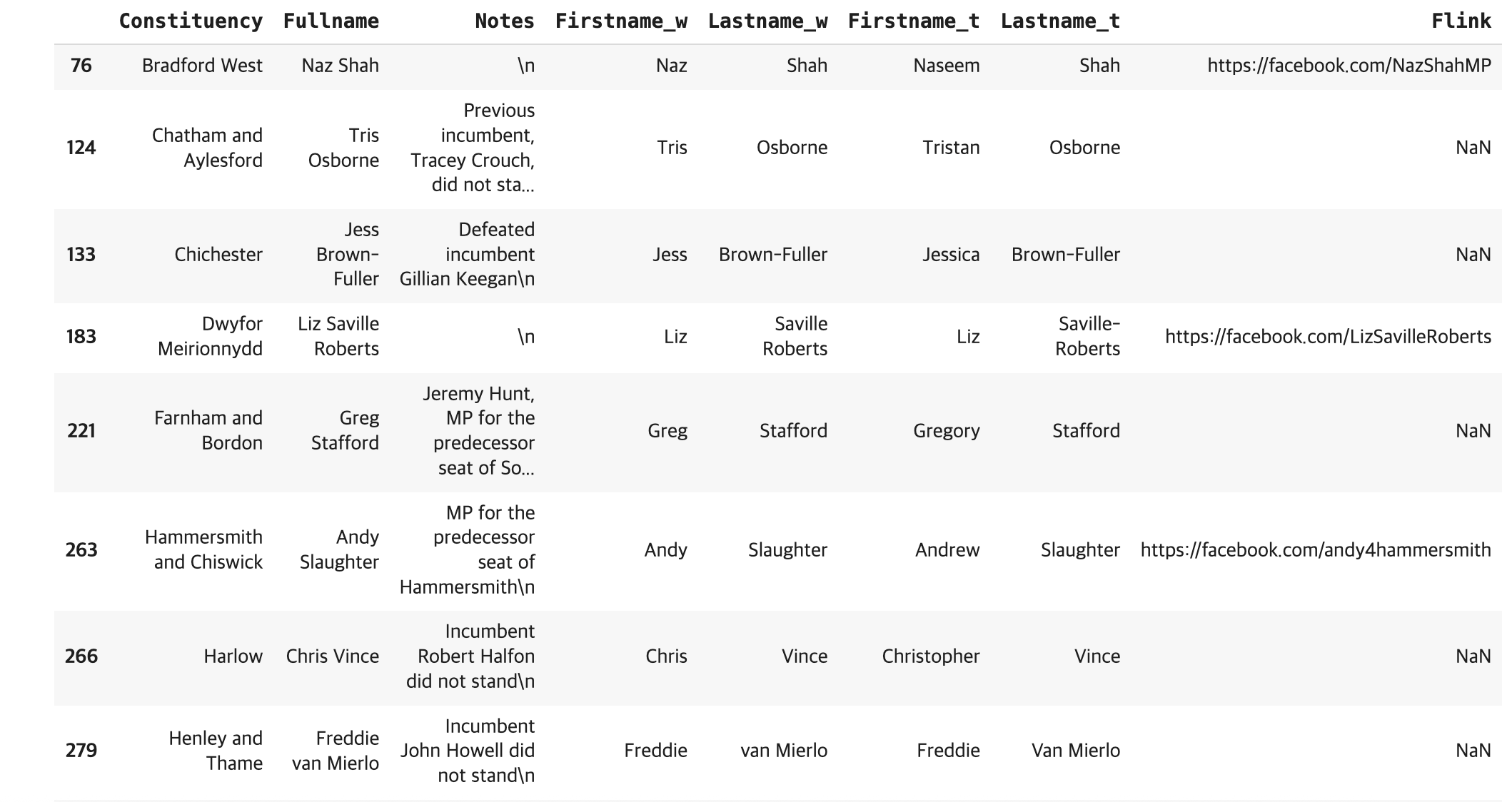
케이스를 하나씩 보면 대부분 대소문자 혹은 이름 전체를 표기하지 않고 일부만 표기한 경우들이라는 것을 확인할 수 있다. 예를 들어 'Tris'는 'Tristan'의 약어 표현일 가능성이 높다. 그러나 이는 추측이기 때문에 일단 이 16행은 수정하지 않고 남겨둔다.
5️⃣ Measuring Performance
True positive matches (TP) = 633
False positive matches (FP) = 0
True negative matches (TN) = 1
False negative matches (FN) = 16
precision을 계산하면 633/(633+0) = 100%이고, recall은 633/(633+16) = 97.5%이다. Accuracy는 (633+1)/650 = 97.5
6️⃣ Sample Calculation
이제 처음에 세웠던 가설을 확인할 수 있는 간단한 계산을 해보겠다. 재선이 경우이면서(Noted에 'Seat head'가 표시되어 있는 경우) Facebook url이 없는 경우는 2개 밖에 나오지 않았다.
# 기존
df_heldwithface = df_resolved[(df_resolved['Flink']!='') & df_resolved['Notes']=="Seat held\n"]
len(df_heldwithface)'Notes' 컬럼의 unique 값을 살펴보니, Seat held라는 단어 뒤에 다른 내용들을 포함하는 경우가 종종 있었다. 따라서 exact mathcing이 아니 contains로 'Seat held'를 포함하는 경우로 아래와 같이 코드를 수정했다.
df_heldwithface = df_resolved[(df_resolved['Flink']!='') & df_resolved['Notes'].str.contains("Seat held")]
len(df_heldwithface)이렇게 수정했음에도 여전히 4개 행 밖에 나오지 않았다. 애초에 재선된 국회의원이(Seat held를 포함하는 행)이 2024년에는 8명 밖에 없었고, 이 중 4명 만이 facebook url을 갖고 있지 않는다는 것이다.
교안의 결과와 다소 달랐지만, 연도가 다르니 다를 수 있다고 생각하고 계속 다음 챕터를 진행하겠다.
