
- 스터디 책: Hands-On Entity Resolution
- 깃헙: https://github.com/mshearer0/HandsOnEntityResolution
- 실습 코랩 코드: https://colab.research.google.com/drive/1Ca9PV65xnG3VxWBdPwISaPSZ-tdGlwPC#scrollTo=SEyCvAMjTHCi
Chapter2에서 데이터 정제를 마친 뒤, exact matching까지 진행했다. 데이터의 퀄리티가 높은 경우 여기까지만 진행해줘도 충분하겠지만, 현실 세계의 데이터는 대부분 그렇지 않다. 따라서 보다 매칭률을 높이기 위해 approximate matching techniques를 적용할 수 있는데, 예를 들어 출생일 앞뒤 며칠 정도의 오차나 위치의 오차 범위, 혹은 유사한 의미를 갖는 텍스트 등을 고려하는 것 등을 의미한다. 물론 이 경우 정확성이 낮아질 가능성도 존재한다.
해당 챕터에서는 entity resolution 성능을 높이기 위해서 자주 사용되는 텍스트 매칭 테크닉들을 소개한다.
Edit Distance Matching
1️⃣ Levenshtein Distance
레벤슈타인 거리는 텍스트 매칭에서 자주 사용되는 알고리즘으로, 두 문자 a와 b 간의 수정 횟수를 기준으로 문자열 유사도를 파악하는 기법이다. 예를 들어, 'Michael'과 'Micheal'은 두 개의 글자, e와 a가 다르기 때문에 최소한 2번의 수정이 필요하므로, jf.levenshtein_distance('Michael','Micheal')의 결과는 2가 된다.
2️⃣ Jaro Similarity
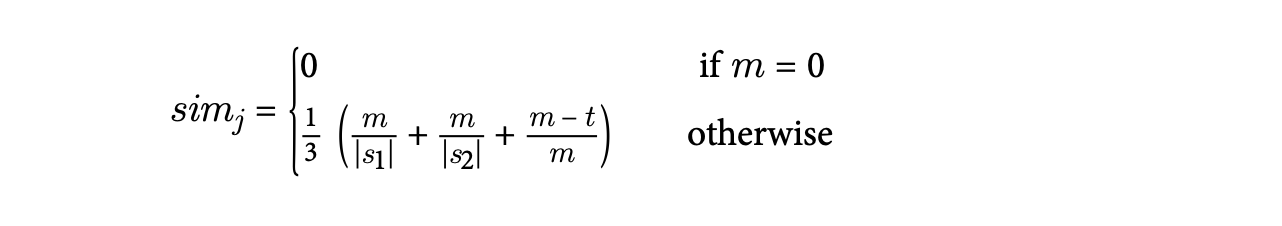
Jaro 유사도는 위와 같은 수식으로 계산된다. s1은 s1 문자열의 길이를 의미하고 m은 매칭되는 문자의 수아며, t는 문자열 내에서 순서를 바꿔야 하는 수를 의미한다. 또한 s1과 s2가 완전히 일치한 경우에는1이 되고, 하나도 일치하지 않은 경우 0을 도출하게 된다.
위에서 살펴본 'Michael'과 'Micheal' 예시를 Jaro 유사도를 통해 계산해보면, s1과 s2는 모두 7이고, 일치하는 문자인 m=7(순서 제외 문자 자체는 모두 동일하므로), 차이는 a와 e의 순서이므로 t=1이 된다. 따라서 위 수식을 통해 계산하면 다음과 같다.
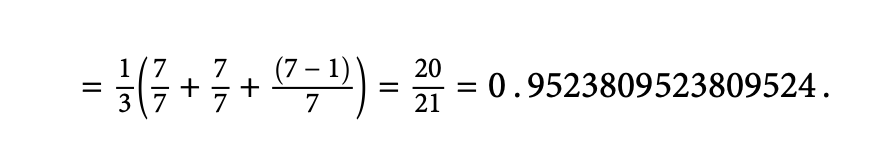
3️⃣ Jaro-Winkler Similarity
Jaro-Winkler 유사도는 시작하는 문자가 유사할 수록 문자열의 유사도가 높다는 가정을 기반으로 만들어진 계산법이다. s1과 s2가 있을 때, 앞에서 부터 일치하는 문자열의 수인 공통 접두사는 l로 표시하고, 가중치 p는 일반적으로 0.1을 부여한다(반드시 0.25보다는 커야함).
'Michael'과 'Micheal'은 앞에서부터 'Mich'까지가 일치하기 때문에 prefix length인 l=4가 된다. 앞서 Jaro 유사도의 결과 20/21이 도출되었으므로, Jaro-Winkler을 계산하면 다음과 같다.
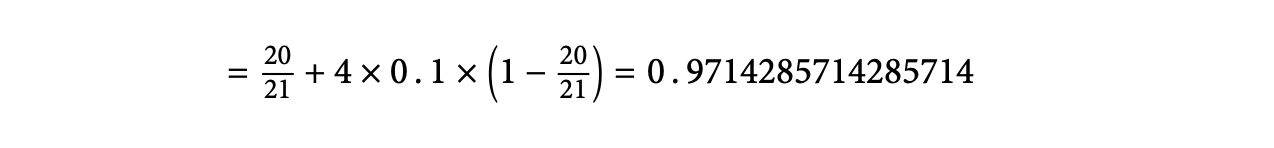
특히, Jaro-Winkler은 문자의 대문자 소문자도 구분하기 때문에 비교할 때 이를 유의해야 한다는 특징이 있다.
Phonetic Matching
수정 거리 매칭의 대체제는 단어가 어떻게 발음되는지를 비교하는 표음식 매칭이다. 대부분은 표음식 매칭 알고리즘은 영어 발음을 기반으로 한다.
4️⃣ Metaphone
Metaphone 알고리즘은 문자열들을 발음의 유사도를 비교할 수 있도록 인코딩하는 방식이다. 예를 들어, 'th'는 '0', 'sh'와 'ch'는 'X' 등으로 매칭하는 것이다. 따라서 'Michael'과 'Micheal'은 모두 'MXL'로 인코딩 되어서 발음상 유사성을 갖는다는 것을 확인할 수 있다.
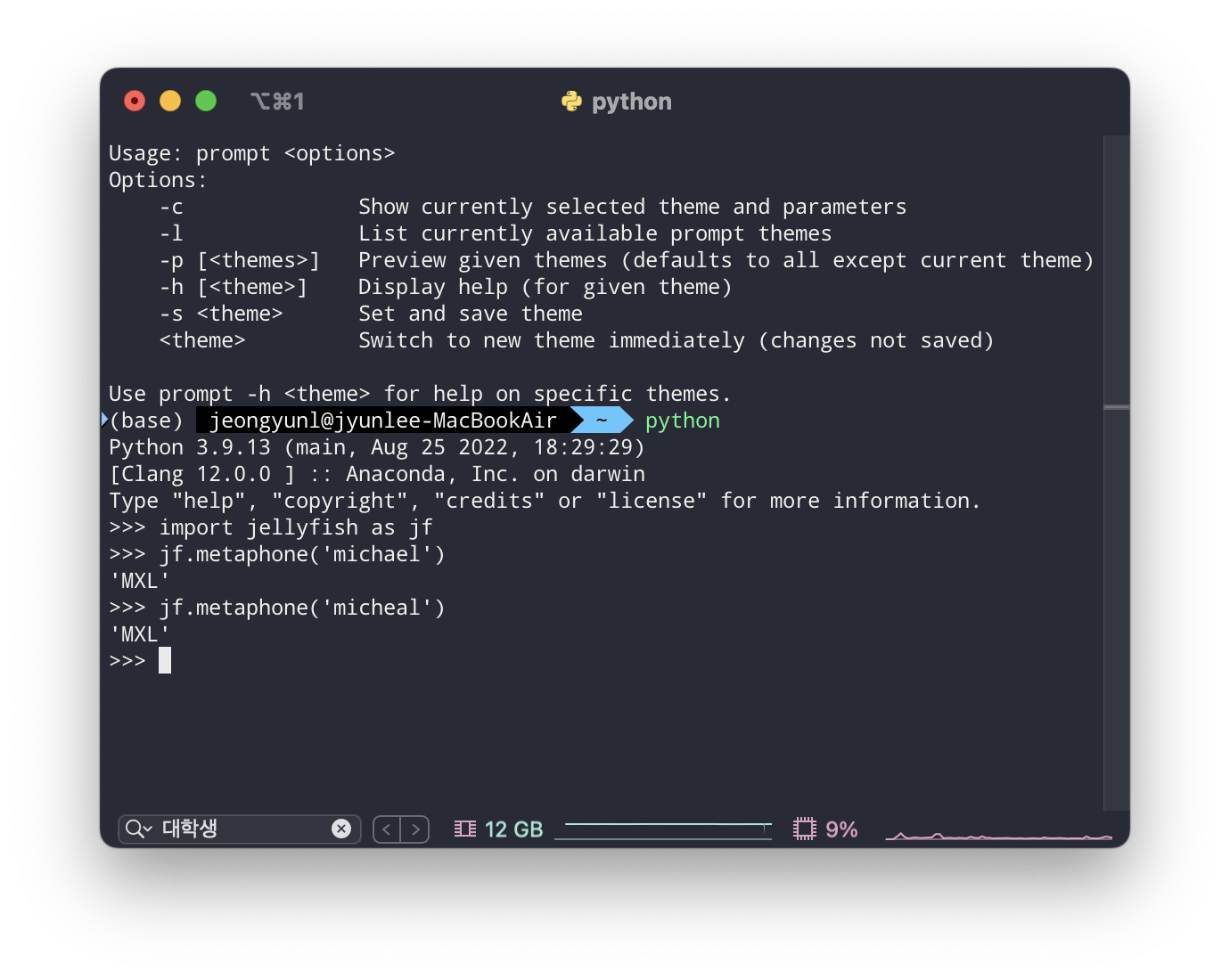
5️⃣ Match Rating Approach
MRA는 Metaphone처럼 발음 기반의 코드를 생성하지만, 단순히 코드가 같은지만 비교하는 것을 넘어 두 코드 사이의 유사도를 구체적인 '등급(Rating)'으로 계산하는 점이 특징이다.
Comparing the Techniques
위에서 설명한 5개의 기법을 활용해서 이제 다음 mylist = ['Michael','Micheal','Michel','Mike','Mick'] 리스트의 단어들을 2개씩 매칭해서 비교하면 다음과 같은 결과표를 도출할 수 있다.
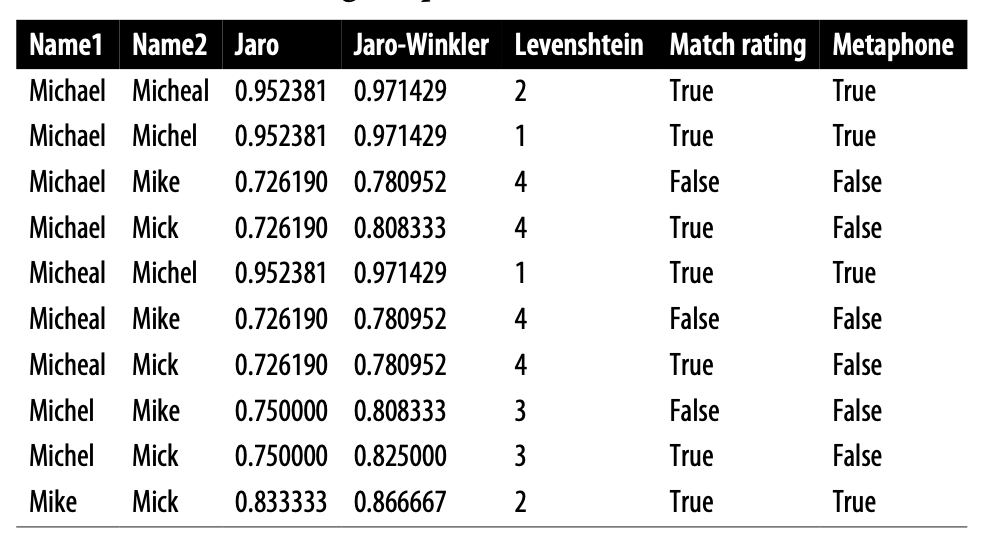
결과를 보면, 어떤 알고리즘이 가장 뛰어나다고 판단할 순 없으며 목적에 따라서 적절한 기법을 사용해야 한다. 본 교안에서는 Jaro-Winkler 유사도 알고리즘을 기준으로 사용한다.
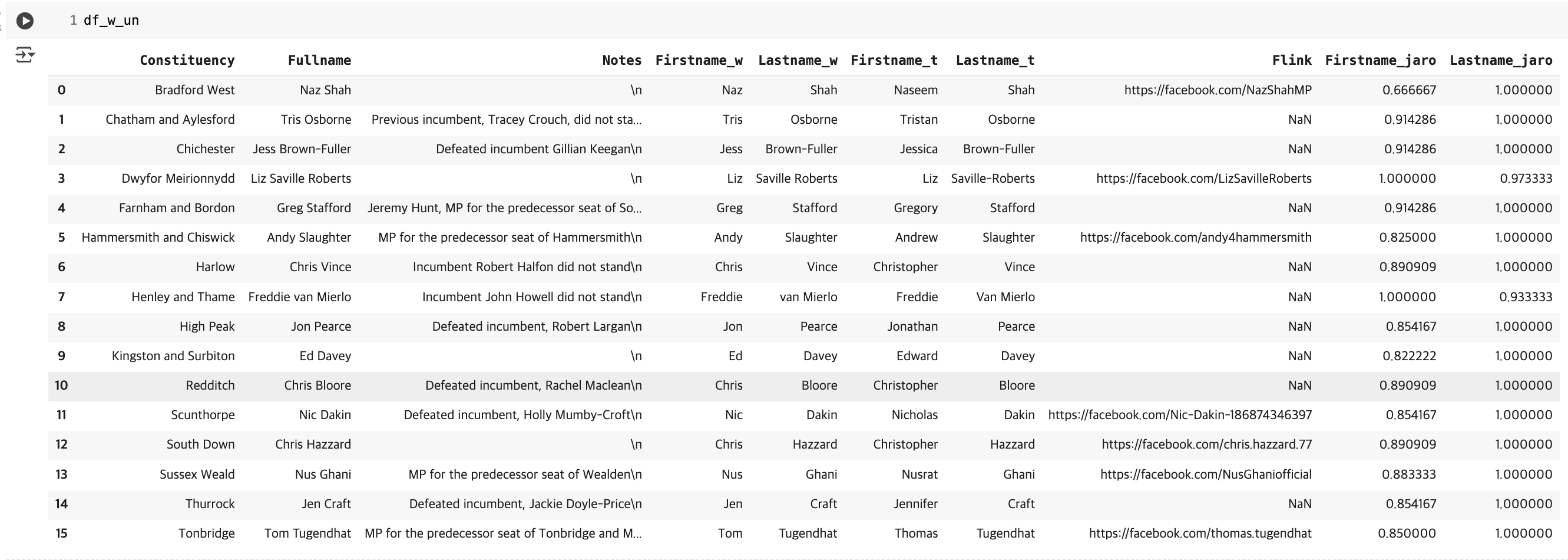
Chapter2에서 있었던 16개의 매칭되지 않은 행들을 가져와서 Firstname과 Lastname을 각각 Jaro-Winkler로 계산한 결과이다. 계산 결과를 보면 모두 0.8 이상의 값이 도출되어 높은 유사도를 보인다.
Chapter2에서부터 진행한 데이터 매칭 방식을 다시 정리해보면, 강력한 연결 키인 Constituency를 기준으로 매칭을 한 뒤, First name과 Last name이 불일치하는 경우 16개를 도출했다. 이후 이 16개를 Jaro-Winkler로 계산해보니 모두 0.8 이상의 높은 유사도를 보이고 있으므로 이들은 모두 유사할 가능성이 높은 인물로 판단할 수 있다. 그러나 현실 세계에서는 Constituency와 같은 강력한, 즉 고유값인 연결키가 존재하지 않을 가능성이 높다.
따라서 First name과 Last name만 활용해서 가능한 모든 쌍을 생성한 뒤, 이들을 유사도 함수를 통해서 비교하는 방법을 진행한다. 이는 다소 연산량이 많지만, 보다 실제 데이터의 특성에 적합한 방법일 수 있다.
Fully Similarity Comparison
cross = df_w.merge(df_t, how='cross',suffixes=('_w', '_t'))
cross['Firstname_jaro'] = cross.apply(lambda x: True if jf.jaro_winkler_similarity(x.Firstname_w, x.Firstname_t)>0.8 else False, axis=1)
cross['Lastname_jaro'] = cross.apply(lambda x: True if jf.jaro_winkler_similarity(x.Lastname_w, x.Lastname_t)>0.8 else False, axis=1)우선 650행의 모든 조합쌍을 계산하여 650*650 = 422,500개의 행을 생성한다. 이후 Jaro-Winkler를 통해 유사도를 계산하고 임계값 0.8을 넘는 경우는 True로 표기한다.
tp = cross[(cross['Firstname_jaro'] & cross['Lastname_jaro']) & (cross['Constituency_w']==cross['Constituency_t'])]
len(tp)이후, Wikidata와 TheyWorkforYou의 Constituency가 동일하면서 동시에 이름의 유사도도 0.8 이상인 행, 즉 true positive를 추출하면 649행이 나온다. 1개 행을 제외하고 모두 매칭되었다는 것을 의미한다.
fntn = cross[(~cross['Firstname_jaro'] | ~cross['Lastname_jaro']) & (cross['Constituency_w']==cross['Constituency_t'])]
len(fntn)매칭되지 않은 한 개의 행은 Constituency는 동일하지만, 이름의 유사도가 낮은 경우인데, 'Naz Shah'와 'Naseem Shah'이다. 개인적으로 판단했을 때는 동일한 이름으로 볼 수 있다고 생각한다.

Measuring Performance
계산 결과를 통해 평가해보면, Recall은 649/(649+1) = 0.9984615384615385 이고, Precision = 649/(649+14) = 0.9788838612368024이 된다. 또한 Accuracy는 (649+1)/(649+1+14+1) = 0.9774436090225563로 계산할 수 있다.
앞서 exact matching을 했을 때와 수치를 비교하면 다음과 같다.
| Exact match | Approximate match | |
|---|---|---|
| Precision | 100% | 99.8% |
| Recall | 97.5% | 97.8% |
| Accuracy | 97.5 | 97.7% |
결과적으로, 매칭 작업을 할때 이름의 Last name, First name 중 어떤 부분에 가중치를 줄 지 결정하고, 유사도를 판단하는 임계값을 설정함으로써 매칭의 정도를 조절할 수 있다. 실제로, 위 데이터에서 First name은 1.85번 고유한 값이 등장하고 Last name은 1.16로, First name이 더 중복이 많다는 것을 알 수 있다. 따라서 매칭을 할 때 더 중요한 정보가 되는건 Last name이 될 수 있다.
이러한 분석을 바탕으로, 다음 챕터에서는 각 속성의 중요도에 따라 가중치를 부여하고, 이를 조합하여 전반적인 'match confidence score'를 생성하는 확률적 기법에 대해 알아본다고 한다.
